基于组合Stacking的心脏病患病情况评估模型研究
2021-04-18曹菲菲
曹菲菲
摘要:心脏病是对人类生命的一个威胁,如何发现被提早预防就显得尤为重要。以心脏病数据集为研究对象,对数据集进行简单介绍,对分类特征值和连续特征值与患病情况的关系进行分析;分别构建单一评估模型,如随机森林、人工神经网络、支持向量机、K最近邻等,分另0对患病情况进行预测,结果表明人工神经网络预测效果最好,准确率为87.6%;我们采用组合Stacking模型后,发现组合Stacking模型的准确率为92.7%,比人工神经网络提高大约5%,而且通过训练集和测试集上各评价指标的比较发现,组合Stacking模型具有很好的泛化性能.
关键词:心脏病;单一评估模型;人工神经网络;组合模型Stacking;评估模型
中图分类号:TPl81 文献标志码:A
心脏病是人类健康的最大威胁,全世界1/3人口死亡由心脏病引起。我国每年有几十万人死于心脏病,对心脏病的研究显得尤为重要。如果可以通过提取人体相关的体测指标,对心脏病患病情况进行预测,将对预防心脏病起到至关重要的作用。
对心脏病的病症及原因进行了一定的检索,有李广平所著的实用临床心脏病诊断治疗学;弓孟春和严晓伟对欧洲心脏病学会2008年版心力衰竭的诊断和治疗指南解读;李世军和司全金对2017年欧洲心脏病学会外周动脉疾病诊断与治疗指南解读;刘江生对我国康复心脏病学的发展及现状的研究等。对心脏病患病情况的预测研究主要有:Krishnaiah V,NarsimhaG,Subhash N使用数据挖掘技术和智能模糊方法对心脏病患病情况进行预测研究;Palaniappan s,AwangR提出使用决策樹和神经网络对心脏病患病情况进行预测,并对预测结果进行决策制定;Thomas J,PrincyR T使用决策树、K最近邻、朴素贝叶斯和神经网络斡分类技术对心脏病患病情况进行预测;Ramachandran,s使用弗雷明汉模型对心脏病患病情况进行预测;Kan-chan B D,Kishor M M基于构件分析原理在特殊疾病上使用机器学习算法对患病情况进行预测研究;Giardina M,Azuaje F,Mccullagh P等人提出一种用于预测2型糖尿病患者冠心病并发症的监督学习方法对此病的患病情况进行预测。
本论述选取UCI的开源数据集Heart_Disease(https://archive.ics.uci.edu/ml/datasets/Heart+Disease),使用组合模型Stacking对心脏病患病情况进行预测,我们的贡献是将一些初级分类器如用决策树、K最近邻、朴素贝叶斯和神经网络等进行组合,并使用简单的线性模型如逻辑斯蒂回归作为次级分类器,采用这种方法不仅使模型的准确率提高,而且模型的泛化性能也得到提高,我们认为这在分类预测中是非常重要的。
1数据描述
1.1数据集介绍
此数据集包含303个心脏病检查患者的体测数据,包含13个特征和一个目标,为了便于理解,我们将特征重新命名,其具体的特征及介绍见表1所列。
1.2分类特征值与患病情况的比率关系
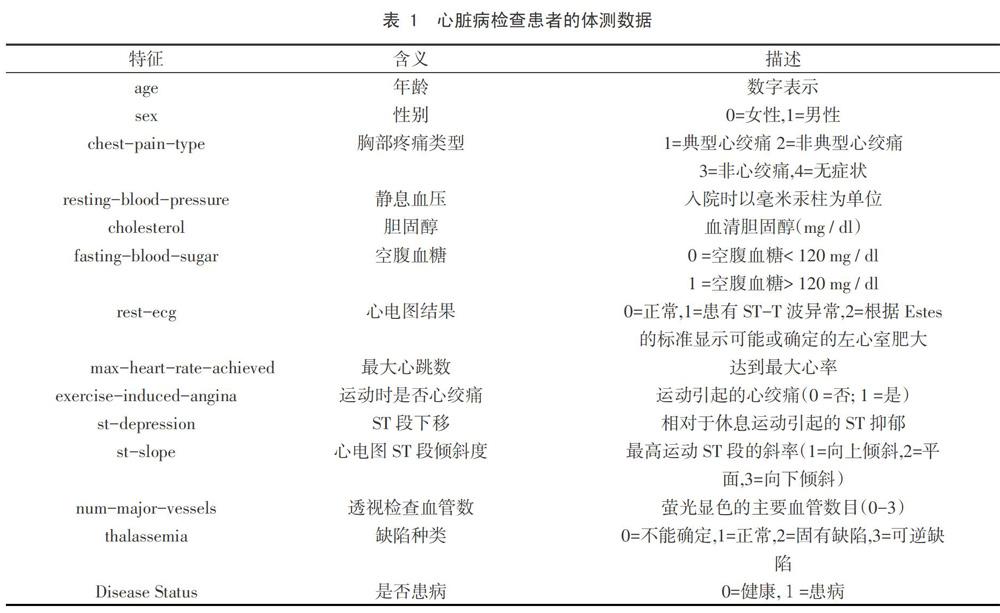
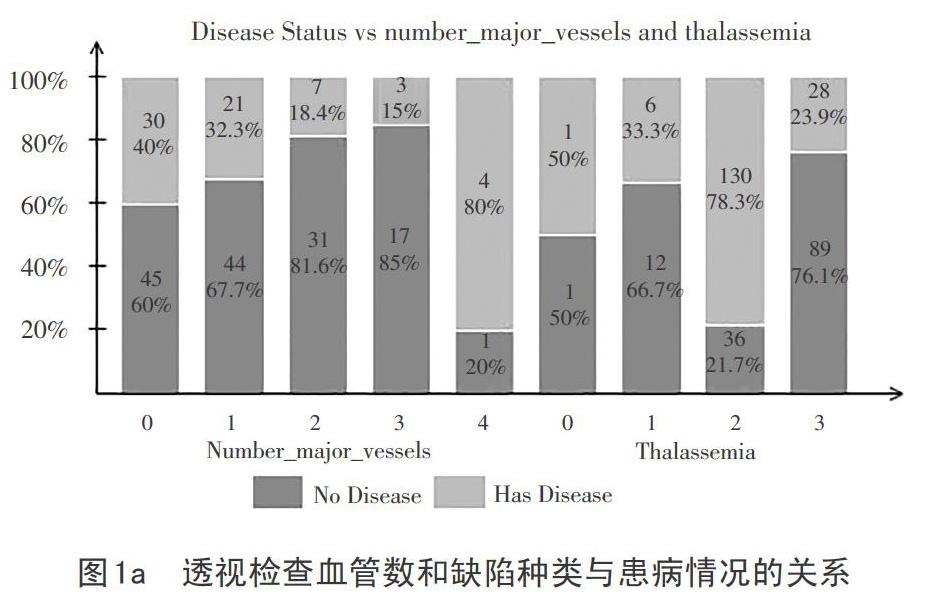
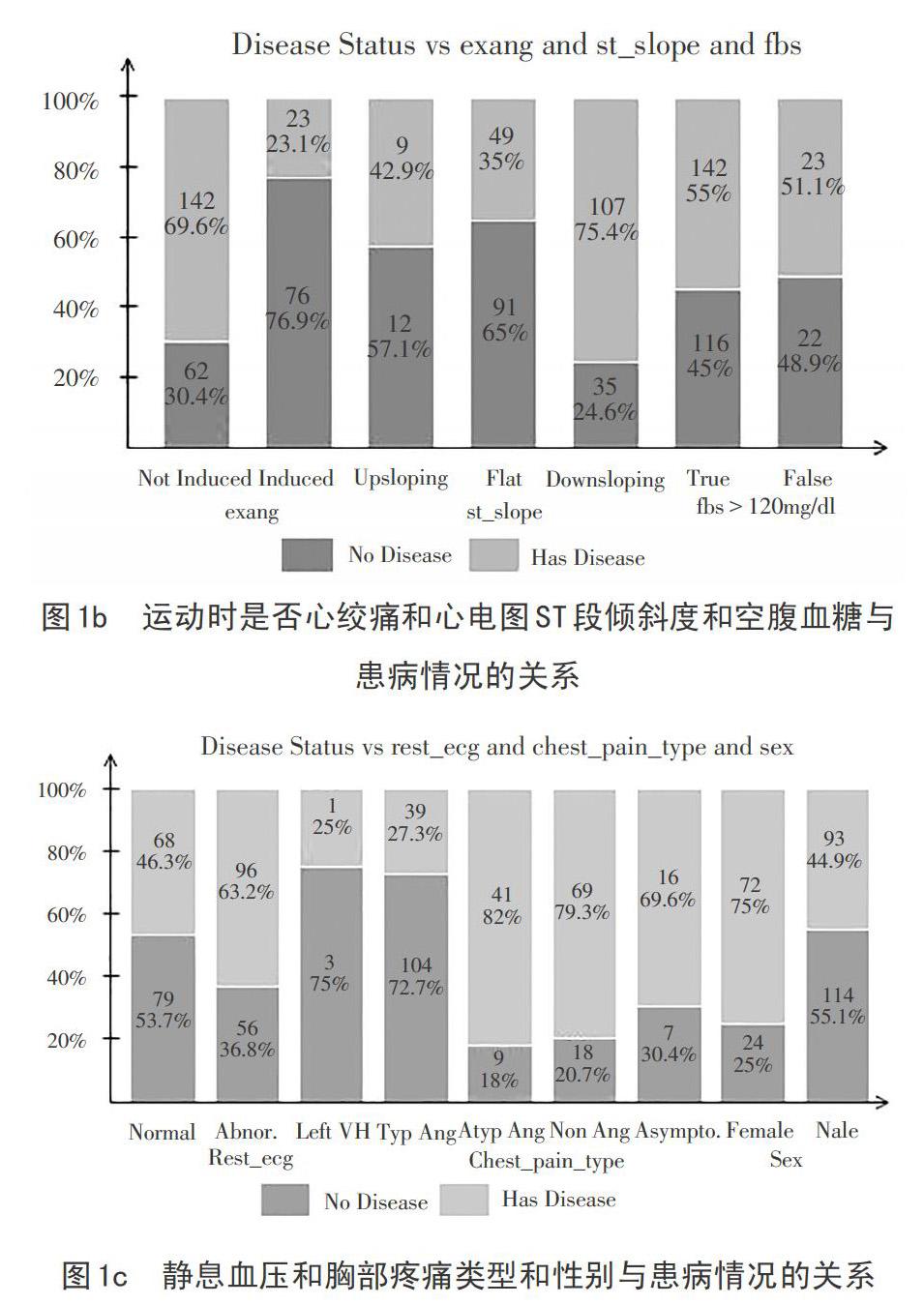
图1中a,b,c分别描述了8种分类特征值与患病情况之间的关系,图中的数字和百分数分别表示该种特征值患病与否的数量与比例,为了表示方便,将某些特征名在标注时进行了简写,如exang表示运动时是否心绞痛,其他简写类似,从表1中可以找到其对应的全称.从图1可以清楚看出各分类特征值在患病情况中占的比例,当透视检查血管数越多,不患病的比例越高;对于缺陷种类,有两位受试者不能确定,在后面的建模中,会将其删去,当受试者的缺陷种类为固有缺陷时,患病比例大大提升;当运动引起心绞痛时,不患病比例的人数增多;当心电图sT段=向下倾斜时,患病人数比例增多;不管空腹血糖是否大于120mg/dl,其患病与不患病人数都差不多;当心电图显示患有ST-T波异常时,患病人数比例增多;对于这四种胸痛类型,都有较高的患病比例;性别显示女性相比男性有更高的患病比例。
1.3连续特征值及患病情况的分布
对连续特征值进行可视化结果如图2所示。其中年龄,静息血压、最大心跳数和胆固醇呈近似正态分布,年龄在50至60岁之间的受试者患心脏病的频率最大,目标患病情况的分布基本均衡,这在分类预测中是非常重要的;而sT段抑郁呈明显的右偏分布,大量受试者分布在0-1之间。
2方法
1992年Wolpert提出集成学习Stacking算法,主要组合多个不同学习器提高预测效果。Stacking算法分为初级学习器和次级学习器两部分,其原理如图3所示。
组合学习Stacking算法先将数据集分为训练集(Training Data)和测试集(Test Data),具体训练过程如下。
2.1第一层初级学习器
训练集采用5折交叉验证,其中训练模型数据集(Learn)占4/5,验证模型的数据集(Predict)占1/5;首先选择第一个单一评估模型Model 1,用数据集(Learn)训练模型,将训练好的模型对数据集(Predict)进行预测,经过第一次交叉验证后,预测结果记为a1,同理训练模型对测试集(Test Data)预测结果为b1,经过5此交叉验证,训练集得到预测结果(a1,a2,a3,a4,a5),将其合并为矩阵A1;测试集预测结果(b1,b2,b3,b4,b5),对各部分预测值对应相加求均值,结果记为矩阵B1,以上步骤为Stacking中第一个基本学习器为Model 1的完整算法流程,同理计算n个不同模型,最终训练集的预测结果矩阵为A=(A1,A2,A3,…,A5),测试集的预测结果矩阵为B=(B1,B2,B3,…,B5)。
2.2第二层次级学习器
矩阵A为训练集,矩阵曰为测试集,构造简单的逻辑斯蒂回归模型,其中第j个单一评估模型Model.j对第i个训练样本点的预测值,作为新的训练集中第i个样本的第i个特征值,即解释变量为不同模型的预测值,被解释变量为实际的变量值。
采用组合模型Stacking算法,具体流程图如图4所示,首先对数据集进行数据预处理,并将数据集按4:1比例随机分为训练集和测试集,然后第一层初级学习器,选择单一非线性结构的评估模型,如随机森林、Gra-dientBoosting、KNN、SVM、人工神经网络等,采用5折交叉验证,计算得到训练集和测试集的矩阵为A和B;第二层为次级学习器,将举证A和B组合成新的矩阵为D=(A,B)T,即将5个单一评估模型的预测结果作为新特征,且矩阵A和B分别为训练集和测试集,心脏病患病情况target为因变量,构建简单的逻辑斯蒂回归模型,其评估模型如图4所示。
3结果
3.1评估指标
构建心脏病患病情况评估模型之前,需要将数据划分为训练集和测试集,其中训练集用来训练评估模型,测试集用来测试评估效果。一般为了评估模型稳健性,采用K折交叉验证法,该方法将数据分成K份样本集,每次将其中一份作为测试集,剩余的K=1份作为训练集,如此重复K次,并计算K个预测结果的均值作为最终预测结果。
本论述通过5折交叉验证,随机分配训练集和测试集,对测试集的心脏病患病情况进行预测评估,其中评估指标主要有以下三种,敏感性(sensitivity)、特异性(specificity)、准确率(Accuracy)和F1 Score,敏感性和特异性是心脏病诊断测试常用的指标.分别对预测结果评估分析,下面给出它们的计算公式:
3.2单一评估模型预测
首先对每个单一模型进行训练,得到最优模型,再进行预测,所有这些工作我们通过编程语言Python来完成。
对于随机森林分类器,通过网格搜索法确定参数的最优组合为最大深度(max_depth)设置为5,建立子树的数量(n_estimators)设置为50,由于心脏病数据集合特征数量都较小,其他参数使用默认值;对于支持向量机分类器,选择高斯核函数(RBF)进行预测时模型表现最好;对于梯度提升分类器,定义损失函数为指数损失函数,学习速率(Eearning_rate)为0.03,需要拟合的树的數量(n estimators)为75,最大深度(max_depth)为5;对于K最近邻分类器,将权重考虑在内,并使用uniform作为权重,使用欧几里得法计算距离,使用10折交叉验证对近邻数K进行选择,在训练集上预测表现最好的K值为10,测试集上预测表现最好的K值为6;对于人工神经网络分类器,使用Relu作为激活函数,学习速率为0.0023,使用交叉熵损失函数作为衡量标准,采用反向传播算法训练模型,当迭代周期(num_epochs)达到7000次时,平均损失达到最小,此时的模型达到最优。对每个单一评估模型进行最优选择后,我们分别将它们运行在训练集和测试集上,得到的结果见表2所列。
由表可知,单一评估模型中人工神经网络分类器的预测效果最佳,其中测试集的敏感率(Sensitivity)为0.85,特异率(specificity)为0.89,准确率(Accuracy)为0.900,其次为随机森林分类器、支持向量机分类器、梯度提升分类器和K最近邻分类器。
3.3组合模型Stacking预测
现在用第3章提出的组合模型Stacking算法对心脏病患病情况进行预测,并与4.2节提到的单一评估模型中预测性能最好的人工神经网络分类器进行比较,最终预测结果如表所示,组合模型Stacking训练集的敏感率(sensitivity)为0.94,而人工神经网络分类器敏感率(sensitivity)为0.865;组合模型Stacking测试集的敏感率(sensitivity)为0.935,而人工神经网络分类器敏感率(sensitivity)为0.89,因此组合模型Stacking的预测敏感率相对人工神经网络提高了4.5%;同理测试集上组合模型Stacking预测特异率提高了6%,准确率提高了2.7%。
组合模型Stacking的预测效果最佳,准确率较高,且具有很好的泛化性能。
4结论与展望
本论述以心脏病数据为例,通过对心脏病患病情况的预测分布建立单一评估模型和组合模型Stacking模型。该模型主要分为初级学习器和次级学习器两层,其中第一层初级学习器将多个不同单一评估模型组合,采用5折交叉验证,有效防止过拟合;第二层次级学习器,建立简单的逻辑斯蒂回归模型,最终发现组合模型Stacking优于单一评估模型,具有较好的泛化能力,值得被推广应用到心脏病患病情况预测中。心脏病一直是患者与医院十分关注的疾病,对心脏病的预防和紧急治疗是当前需要解决的重大问题,希望能在医院安装这种程序,当心脏病潜在患者或者健康人群来医院就诊时,可以使用该程序对这些人群进行心脏病患病情况的评估,对于预测出可能患心脏病的人群,提早告知他们并给予建议多加防范,这也是这个模型提出的意义所在。
