多联机系统故障类型识别及故障细化诊断模型研究
2021-04-17李正飞丁新磊陈焕新王誉舟
刘 倩 李正飞 丁新磊 陈焕新 王誉舟 徐 畅
(华中科技大学能源与动力工程学院 武汉 430074)
公共建筑中暖通空调系统的运行能耗约占建筑能耗的60%[1],而由于暖通空调系统性能下降及故障造成的能源浪费约占商业建筑总能耗的15%~30%。多联机空调系统相比于传统的中央空调系统,具有节能、控制先进等优点[2],自90年代引入我国后,得到了迅速发展。由于多联机系统管路复杂繁琐、运行工况多变,经常会发生各类故障,如四通阀故障、制冷剂泄漏、电子膨胀阀卡死和泄漏、冷凝器脏污等。一旦发生故障,不仅会破坏空调系统的正常使用,降低用户使用舒适度,还会因故障的发生造成不必要的能源浪费[3-6]。
针对多联机系统常见典型故障,本文选择3种会引起较大损失的故障进行研究,即四通阀故障、电子膨胀阀故障、制冷剂充注量故障。四通阀可以调节制冷剂流向,从而实现制热制冷运行模式的自由切换,若发生故障将不能满足系统不同季节、不同功能房间的制冷制热需求;电子膨胀阀为系统的节流部件,发生故障后会影响室内机制冷剂流量的分配,使系统无法满足不同负荷下室内的舒适度要求;制冷剂作为制冷系统内部的传热介质,过少或过充都会影响系统内部的阻力特性和换热特性,并最终影响系统的制冷循环性能。及时发现故障,并完成故障类型识别和故障细化诊断,有助于及时修复系统,避免持续不必要的能量损耗。
针对暖通空调系统的故障检测和诊断的研究相对于信息行业等起步较晚,但目前也逐步发展起来,随着大数据时代的到来,基于数据挖掘的故障诊断方法也逐渐应用于暖通空调领域[7-11]。N.Kocyigit[12]利用模糊推理系统和人工神经网络对某蒸气压缩制冷实验装置进行故障诊断,可有效诊断该系统中的8类故障。S.A.Tassou等[13]设计了一种基于人工智能和实时性能检测的制冷剂泄漏故障诊断与检测系统,可有效区分制冷剂充注量的稳态、过充和泄漏的状态发生。Han Hua等[14]针对制冷剂充注量泄漏、过充以及系统级别的机油过量诊断问题,提出一种经交叉验证优化的最小二乘支持向量机(LS-SVM)模型,相比于未优化的单类算法模型具有更优良的性能。M.Stylianou[15]提出一种采用统计模式识别算法的诊断模型,可诊断冷水机组的4种故障类型。石书彪等[16]建立了神经网络模型,针对冷水机组不同工况下不同程度的7种典型故障进行检测和诊断,并进行优化提高诊断正确率。
上述研究表明,现阶段针对多联机系统的故障检测与诊断研究多是侧重于系统的典型故障[17-18]或单一故障,对于系统关键部件的故障研究还不够深入。此外,对于多类故障诊断的研究,也未能实现对各类故障进行进一步的细化诊断。故针对上述问题,本文提出一种基于线性判别分析和随机森林的多故障诊断策略,可以在完成故障类型识别后,进一步对各类故障中不同的故障表现形式实现细化诊断。
1 线性判别分析及随机森林原理
1.1 线性判别分析
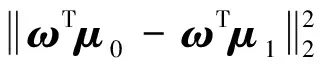
(1)
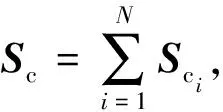
(2)
若原始数据集的类别数为N,而转换矩阵W是运用拉格朗日乘子法Sc-1SbW=λW进行特征值求解得到的,W∈Rd×(N-1),其秩为N-1,所以降维后有效特征个数不会大于N-1。

1)计算每一类别特征的均值向量;
2)分别计算各类内散布矩阵Sc和类间散布矩阵Sb;
3)计算矩阵Sb/Sc的特征值及对应的特征向量;
4)选取前k个特征值所对应的特征向量,构造一个k维的转换矩阵W;
5)将原样本通过转换矩阵映射到新的特征空间,其维度为k。
若原始数据集的类别数为N,而转换矩阵W是由Sc-1SbW=λW进行特征值求解得到的,其秩为N-1,所以降维后有效特征个数不会大于N-1。
1.2 随机森林
随机森林(random forest,RF)是一种以决策树(decision tree,DT)作为基分类器的集成学习算法[20]。“随机”体现在两个方面,一是随机选取样本,二是随机选取特征,例如一个集合含有S个样本,M个特征。森林中的每棵树都有放回的随机抽取部分样本作为训练样本,并有放回的随机选取m0(m0≤M)个特征作为这棵树的分枝依据。此方法可以构建出多棵树,而最终结果是综合“森林”中所有“树”的结果得到的,而且森林中的树不断通过选用更好的特征进行分枝,从而使性能更优良。随机森林算法的具体实现过程如下:
1)原始数据集S个样本应用bootstrap有放回地随机抽取K个新的自助样本集,并由此构建K棵分类树,每次未被抽取到的样本组成了袋外数据;
2)设有M个特征,则在每一棵树的每个节点处随机抽取m0个特征,然后在m0中选择一个最具有分类能力的特征,变量分类的阈值通过检查每一个分类点确定;
3)每棵树完全生长,不做修剪;
4)用生成的随机森林分类器对新的数据进行判别,分类结果按照投票结果确定。
2 实验装置及数据获取
实验使用一台额定制冷量为28 kW,制冷剂为R410A的“一拖五”多联机系统,如图1所示。该系统主要由压缩机、电子膨胀阀、室外机、室内机等四大基本部件组成。其标称制冷剂充注量为9.9 kg。多联机系统采用密封涡旋压缩机,系统中设置有多个传感器,用来测量压力和温度等,部分测点已在图1中标出。

图1 实验多联机系统
实验中设有故障实验和正常实验,运行工况分为制冷和制热工况,共包括已知故障3种,通过人为引入故障的方式使系统进行故障运行。电子膨胀阀分为卡死故障和泄漏故障,电子膨胀阀的开度大小定义为当前开度除以最大开度的百分比,对于电子膨胀阀卡死故障实验,将运行中的内机的开度固定在0或100%,对于电子膨胀阀泄漏故障实验,将关机的一台内机开度设定为50%,这样电子膨胀阀的开度不再随着负荷的变化而自动调整;对于四通阀故障,将驱动换向阀的驱动电机人为掉电或人为损坏四通阀以模拟四通阀故障,这样换向阀就不能再有效改变制冷剂的流动方向;为了获得制冷剂充注量不足和过量实验数据,人为将制冷剂充注量水平充注为标准制冷剂充注量的一定百分比。针对不同的故障设计相关实验,记录当前工况下的所有数据,并从中选取18个特征变量的数据,具体如表1所示。其中,目标运行能力是指多联机机组在当下运行工况下理论上可以提供的制冷能力,本机运行能力=(目标运行能力/系统总运行能力)×100%。

表1 特征变量及其符号
具体故障类型及样本数量汇总于表2中。正常工况、四通阀故障、电子膨胀阀故障及制冷剂充注量故障的故障类型标签分别为L0、L1、L2、L3,并对3类故障的故障类型进行详细划分。故障细化后标签如表2所示。实验采集了3 d的所有运行数据,每间隔3 s采集一次数据,共获取156 068组数据,各类故障样本容量足够,为故障诊断模型的建立提供保障。

表2 故障标签及样本数量
故障数据种类繁多,在实际运行过程中,样本中含有部分异常值,因此,首先需要将样本集中的异常值进行剔除,以进一步提高模型诊断可靠性。其次,由于多个变量之间的量纲不一,其差异会对后续的故障诊断产生影响,故需要用到数据标准化消除该差异。本实验采取对数据进行最大最小归一化处理。
3 故障检测和诊断策略
本文提出的多联机系统多类故障检测和诊断策略结合了线性判别分析和随机森林算法,流程图如图2所示,除完成原始数据采集和预处理外,该策略主要包括两个部分,一是故障类型识别模型的训练和测试,二是单类故障细化诊断模型的训练和测试。具体流程为:

图2 多联机系统多类故障诊断策略流程图
1)通过设置实验系统操作参数使多联机系统处于正常、四通阀故障、电子膨胀阀故障、制冷剂充注量故障状态,并借助温度、压力传感器等采集原始数据;
2)原始实验数据剔除异常值,并进行最大最小归一化预处理;
3)将原始数据集按照7∶3划分为训练集A和测试集B;并将划分出的训练集A按照故障类型划分为四通阀故障集a、电子膨胀阀故障集b、制冷剂充注故障集c;
4)设置随机森林模型的参数值,利用训练集建立故障类型识别RF模型;
5)对训练集a、b、c使用线性判别分析进行降维处理,提取关键特征向量;
6)利用降维后的训练集,建立针对3种故障类型的故障细化诊断模型a、b、c;
7)将测试集B输入至训练好的RF模型中,输出故障类型识别结果;
8)将上一步识别出故障类型的样本输入至对应的故障细化诊断模型中,实现对各类故障中不同故障表现形式的细化诊断。
4 故障类型识别及细化诊断结果
4.1 故障类型识别结果
本文结合线性判别分析和随机森林进行多联机系统多类别故障诊断,首先通过建立的随机森林模型完成故障类型识别,然后根据故障类型识别的结果,自适应的输入不同的故障细化诊断模型中进行下一步诊断。
实验所采集的原始数据集经过预处理后按照7∶3的比例划分为训练集A和测试集B,训练集A用来训练出故障类型识别模型,测试集B对该模型诊断性能进行检验测试。测试集输入故障类型识别模型时,整体的故障类型识别准确率达到99.99%,可见识别错误的样本数极少。为便于观察故障类型识别结果的样本分布,进一步对结果进行了可视化,如图3所示。由图3可知,正常运行工况、电子膨胀阀故障及四通阀故障均能全部正确识别,而制冷剂充注量故障的27 335个测试样本中仅有4个样本被错误识别为正常样本,这表明随机森林模型据不同类型故障数据的差异,学习到极好的分类规则,进而实现故障类型识别。该模型在测试集上几乎可完全准确的识别3类故障及正常运行样本数据,具有良好的故障识别能力及鲁棒性。

图3 测试集故障类型识别结果样本分布
故障类型识别模型能较好的识别这3类故障是因为3类故障间的差异性显著[21],四通阀故障为室外机故障,电子膨胀阀故障为室内机故障,而制冷剂充注故障为系统故障。多联机系统在进行制冷、制热模式切换时发生四通阀故障,制冷剂流向偏离预期流向,会对系统冷凝压力、压缩机吸气温度及排气温度等产生显著影响;电子膨胀阀通过调节制冷剂流量控制内机负荷,发生故障主要对故障室内机参数产生影响,但由于该故障会影响不同流向的制冷剂流量,所以系统的冷凝压力及蒸发压力等参数也会发生变化;制冷剂过充或不足会显著影响系统内制冷剂温度的大小,如压缩机排气/吸气温度,气液分离器进管/出管温度等参数均会有所变动。
4.2 故障细化诊断结果
该多联机系统监测了数个变量,根据以往的实验和研究,最终选择了包括室外环境温度在内的18个变量,即原始数据的输入为18维。对于不同类型的故障,反映其状态的最优特征向量之间存在差异,所以在经过故障类型识别后,可以对不同类型的故障进行LDA特征提取,选取对应的最优特征维数。LDA是一种特征抽取方式,通过线性的特征抽取所生成的新特征进行数据降维,使得原始数据映射到低维空间,而生成的新特征不再具有物理意义。
本文根据单个特征对故障诊断的贡献率和多个特征对故障诊断的累计贡献率选取特征参数和特征空间维度。单个特征区分贡献率是指单个所选投影向量对应的特征值占所有特征值之和的比例,特征值反映对应的特征向量的重要程度;累计区分贡献率是指所选全部投影特征向量对应的特征值之和占所有特征值之和的比例。从训练集A中划分出3类故障集a、b、c,并作为3类故障细化诊断模型的训练集。根据原理中提到的,LDA降维最多降至类别数k-1的维数,而四通阀故障详细划分为四通阀掉电和失效两类,是典型的二分类问题,利用LDA进行降维只能保留一个特征向量,即唯一保留一个特征向量,其对故障区分贡献率为100%。此外,对电子膨胀阀故障、制冷剂充注故障进行LDA特征抽取,并观测这两类故障在其对应的训练集上的单个特征区分贡献率及累计区分贡献率,结果如图4所示。
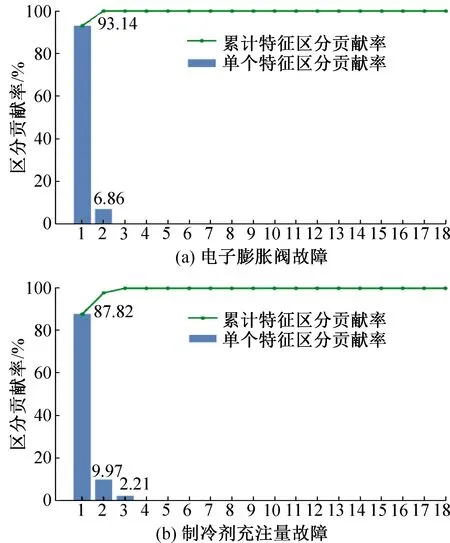
图4 两类故障训练集LAD降维单个特征区分贡献率及累计区分贡献率
电子膨胀阀故障含有泄漏、全开卡死及全闭卡死3种故障形式,利用LDA进行数据降维最大可降至2维,保留两个特征向量,第一特征向量区分贡献率为93.14%,第二特征向量的区分贡献率为6.86%,累计可达100%;制冷剂充注故障被划分为4个充注水平,利用LDA进行数据降维最大可保留3个特征向量,第一特征向量的区分贡献率为87.82%,第二特征向量的区分贡献率为9.97%,而第三特征向量的区分贡献率仅有2.21%,累计可达100%。对于上述两种故障,第一特征均对故障区分具有最大贡献,而后面的特征对故障区分的贡献相对较小,但仍能在一定程度上提高故障的诊断性能。为获得诊断性能及鲁棒性更好的故障细化诊断模型,电子膨胀阀故障诊断模型保留两个特征,制冷剂充注故障诊断模型保留3个特征。
由于随机森林本身可以对数据集进行特征重要性排序和特征选择,经过计算,若是保留和LDA降维处理后相同的维数,四通阀故障训练集a中第一特征为化霜温度;电子膨胀阀故障训练集b第一、第二特征分别为模块低压(蒸发压力)、气液分离器进管温度;制冷剂充注故障训练集c第一、第二、第三特征分别为模块高压(冷凝压力)、气液分离器出管温度和EXV开度。在保留相同维度,随机森林模型参数一致的条件下,两种特征选择方式下训练集上故障细化诊断正确率如图5所示。由图5可知,LDA特征抽取相比于随机森林本身的特征选择在一定程度上可以提高随机森林故障细化诊断模型的性能,最终确定的维度使得映射后的特征空间具有最小的类内离散度和最大的类间离散度。这一步能有效降低原始数据的输入维度,以便于建立简单有效的模型,在降低时间成本的同时,可以避免模型过拟合问题。

图5 LDA降维后RF模型在训练集上的诊断结果
测试集B中的样本经过故障类型识别后,依据识别结果将3类故障样本分别集合到3个小测试集中(即四通阀故障测试集d,电子膨胀阀故障测试集e,制冷剂充注故障测试集f),3个小测试集根据自身故障类型自主选择对应的随机森林诊断模型,进行下一步的故障细化诊断。3类故障细化诊断的结果分别如表3、表4、表5的混淆矩阵所示。

表3 测试集中四通阀故障细化诊断结果
由表3可知,四通阀掉电故障诊断准确率为97.52%,四通阀失效故障诊断准确率为91.10%,可见四通阀掉电相比于一般失效故障更容易被检测出来,而一般失效故障的训练样本数相对较少,会对模型的诊断性能产生一定影响。
表4中电子膨胀阀故障的3种形式的诊断准确率均达到100%,其中EXV泄漏问题对开度这一参数的影响也不同于全闭卡死和全开卡死,3种故障的表现形式间存在明显差异,该随机森林模型能准确无误的识别出这3种故障形式。

表4 测试集中电子膨胀阀故障细化诊断结果
由表5可知,4种故障充注水平诊断能力不一,分别为99.87%、98.11%、93.77%、97.41%,其中两种充注过少(泄漏)的情况能被有效诊断出来,制冷剂充注过少相对于过充,在制冷模式下,系统的蒸发和冷凝压力将会有所降低,室外换热器出口制冷剂温度降低;制热模式下,冷凝和蒸发压力有所降低同时压缩机排气温度将会升高,所以两种情况能被有效区分,过充故障8在诊断中有部分诊断为过充故障9,导致故障9的诊断正确率相对于其他3种充注水平要低。同时,其他几种充注水平也被错误诊断为其他充注水平,因为制冷剂充注故障为系统故障,一旦发生会对系统内多个变量产生影响,由于运行时间的不同以及其他原因,导致某些参数的变化接近于其他充注水平引起的变化,从而造成诊断失误。

表5 测试集中制冷剂充注量故障细化诊断结果
故障类型识别后的3类故障的故障细化诊断准确率如图6所示。四通阀故障、电子膨胀阀故障、制冷剂充注故障在测试集上的整体诊断正确率分别为96.12%、100%、97.44%,而训练集上的整体诊断准确率分别为100%、100%、99.99%。由于测试集B在故障类型识别过程中有4个制冷剂充注故障样本被错误的诊断为正常运行工况,制冷剂充注故障测试集上的实际诊断正确率为97.42%,说明故障类型识别过程中的诊断准确率会对后面的故障细化诊断结果产生影响,因此要尽可能保证前面故障类型识别准确。而对于四通阀与电子膨胀阀故障,由于识别准确率较高,因此未对故障详细诊断结果产生影响。上述结果证明,该LDA-RF模型对3种故障的具体故障类型的诊断效果较好,在训练集和测试集上的准确率均在95%以上,说明该模型具有很好的泛化能力。

图6 3类故障细化诊断RF模型在训练集和测试集上的整体诊断结果
本文建立的故障类型识别及故障细化诊断模型可以用于多联机系统多故障并发情况,先完成故障类型识别后,根据故障类型自适应选择最优故障细化诊断模型,解决了不同故障的不同程度导致的故障标签过多,对模型建立和诊断结果造成的负面影响。对于不同故障类型,详细诊断模型的最优参数设置和特征维度差异显著,而且故障类型识别与进一步的细化诊断所需要的特征数据差异很大,前者不同的故障类型之间特征差异显著,后者同一故障类型不同程度之间的特征差异较小,若直接采取统一的诊断模型进行细化诊断而不考虑不同故障之间的差异性,会导致诊断效果不佳。该分层自适应诊断机制综合考虑了这两方面,实现了特定模型对某一故障类型的特定诊断。基于此,可开展针对该模型的用户界面开发[22],实现基本的数据输入、诊断结果输出功能。维护人员可以根据诊断结果对系统进行精准维护修理,例如,对于制冷剂泄漏,该模型能够较为准确的诊断出残余制冷剂充注水平,帮助维护人员判断制冷剂补充量;对于四通阀故障,进一步诊断引发四通阀故障的具体原因,若为掉电只需维护电路状况消除故障,若为失效则需要进行更换。该用户界面的开发和推广有利于节省维护系统更多的人力及维护时间,使系统中由故障造成的能源浪费最小化。
5 结论
本文基于LDA和RF算法提出一种多联机系统多类故障诊断策略。该策略可完成两个任务,一是完成故障类型识别,二是进一步细化诊断每类故障的具体表现形式。故障类型识别基于一般随机森林算法建模,而对于各单类故障的具体表现形式诊断模型,在基于LDA进行降维提取关键特征向量后建立随机森林模型。实验中共有3种故障类型,分别存在2、3、4种详细故障类型,在测试集的验证下,得到如下结论:
1)故障类型识别过程中,3类故障及正常运行工况整体识别率为99.99%,仅制冷剂充注故障27 335个测试样本中的4个样本错误识别为正常工况。说明该模型能有效识别3类故障。
2)采取线性判别分析对原始数据集进行降维处理,四通阀故障、电子膨胀阀故障、制冷剂充注量故障样本集由原先18维分别降至1、2、3维。
3)经过故障类型识别后的测试样本分别输入对应最优故障细化诊断模型中,四通阀故障诊断准确率为96.12%,电子膨胀阀的故障诊断准确率为100%,制冷剂充注量的故障诊断准确率为97.44%。说明该模型对不同类型的故障具有良好的诊断性能。
综上所述,文中建立的随机森林模型可有效完成故障类型识别和具体故障形式的细分诊断,线性判别分析能有效减少数据维度,且对随机森林模型诊断性能的提高有一定帮助。
