深度学习单帧图像超分辨率重建研究综述
2021-04-17曲延云李翠华王菡子
曲延云,陈 蓉,李翠华,王菡子
(1.厦门大学信息学院,福建 厦门 361005;2.西藏民族大学信息工程学院,陕西 咸阳 712082)
单帧图像超分辨率重建(single image super-resolution reconstruction,SISR)技术是指将一幅低分辨率(low-resolution,LR)图像重建成一幅高分辨率(high-resolution,HR)图像的过程,有着广泛的应用,常被应用于医疗成像、卫星遥感、公共安全监控、多媒体通讯等领域.
SISR是一类典型不适定问题.首个基于深度学习的超分辨率卷积神经网络(super-resolution convolutional neural network,SRCNN)[1]通过学习大量的外部图像数据集,实现了一种端到端的解决方案,避免了繁琐的图像预处理过程,也为后续众多的SISR模型奠定了研究基础.SRCNN在定性和定量指标上都超过传统SISR方法,取得突破性增益值.目前,基于深度学习的SISR方法进入快速发展期,大量的研究成果已发表在国际计算机视觉、图像处理与信号处理领域的顶级会议和期刊上.不仅如此,还出现了多篇基于深度学习的SISR综述性论文:2017年,孙旭等[2]从网络类型、网络结构、训练方法等方面综述了现有SISR技术的优势与不足, 梳理了基于深度学习的SISR的发展脉络.2019年,Wang等[3]从有监督、无监督和典型应用领域三个方面,全面阐述了基于深度学习的SISR技术.同年,Yang等[4]从基于深度学习的SISR的两类核心问题(神经网络结构和目标优化函数)出发,对每一类都建立一个基准,总结关键问题并给出关键解释和分析.2020年,唐艳秋等[5]从模型类型、网络结构、信息传递技术等方面详述了各种深度学习SISR方法.
自2010年起,厦门大学信息学院视频和图像处理实验室在SISR上进行了深入的研究[6-18],催生了一批深度学习的重要成果:利用深度玻尔兹曼机(RBM)进行SISR研究[14],是利用深度学习解决SISR问题最早的论文之一;提出深度耦合自编码网络[15]求解SISR问题,SISR效果达到当时最好水平;将几何统计和图像统计先验联合建模结合到深度自编码耦合神经网络中,进一步提升SISR的性能[16];随着深度学习的发展,本实验室也紧跟科研热点,利用生成对抗网络(generative adversarial network,GAN)结合注意力机制进行SISR,实现主、客观图像质量的同步提升[17];另外,本实验室还关注SISR深度学习架构的模型压缩问题,提出了LatticeNet[18],用快速傅里叶变换的蝶式结构替换深度CNN的残差结构,减小了模型的规模,同时保证了SISR的性能.
SISR技术将LR图像映射到HR图像上时,尽管低频信息丢失少,但是高频信息因图像质量下降被大量丢弃,为了获得高精度且具有真实纹理的SISR结果,面临如下两大挑战:
1)建立合成的成对数据集上的LR-HR图像的映射模型.这类挑战的核心问题是如何设计深度网络模型学习有效的LR-HR图像映射关系,补全HR图像中丢失的高频信息.根据LR-HR图像映射模型构建中所利用的监督信息的多少,将深度SISR模型分为3大类:有监督SISR、弱监督SISR和无监督SISR.有监督SISR需要成对的数据集,重建效果佳,是研究合成数据下SISR的主流方法,研究成果众多.
2)建立面向真实场景的SISR自适应模型.将在合成的成对数据集上训练得到的SISR模型应用于真实图像测试时,往往性能大幅下降,不能满足真实场景的应用需求.为了能获得良好的重建性能,研究面向真实场景的SISR成为必然需求,本文称之为不成对的SISR.这类挑战的核心问题是在真实成对LR-HR图像对获取困难的情况下,如何建立SISR模型.
在整理、分析当前有代表性的SISR方法后发现:上述提及的综述性论文多从建立SISR模型的实现技术上对其进行分类,多探讨如何建立良好的LR-HR图像映射关系,缺乏或较少描述面向真实场景的SISR技术及其应用情况,内容不够全面.本文在上述研究的基础上,从有监督SISR方法和不成对SISR方法入手,对深度SISR方法做深入分析和整理.同时,为了更好地了解SISR技术在各个领域的应用价值,介绍了基于领域的SISR存在的问题和代表性方法.
按照不同的网络结构可将有监督SISR方法分成基于CNN、GAN、网络结构搜索(neural architecture search,NAS)的SISR.根据训练样本的产生方式,不成对的SISR可分为零样本SISR、弱监督SISR、自监督SISR.因此,本文内容安排如下:第1节和第2节分别介绍有监督SISR方法和不成对SISR方法;第3节探讨基于领域的SISR;第4节给出总结与展望.
1 有监督的深度SISR方法
本节将有监督的深度SISR方法分成基于CNN、GAN和NAS的SISR方法,具体划分如图1所示.

图中英文缩写的注释见附录表S1(http:∥jxmu.xmu.edu.cn/upload/20210313.html).
1.1 基于CNN的SISR方法
CNN是一种前馈神经网络,采用局部连接和共享权值的方式,一方面减少权值的数量使得网络易于优化,另一方面降低过拟合的风险.基于CNN的SISR方法的发展过程可分为SRCNN及其改进算法和残差结构及其改进算法.前者是SISR研究中具有里程碑意义的工作,为后续的基于深度学习的SISR算法奠定了基础;后者以提升SISR的模型精度为主要任务,通过改进网络结构,联合多种网络模块,形成了许多的优秀成果.此外,为了减少模型参数,提高模型的重建速度和在手机等智能终端的可适用性,轻量化网络的SISR方法也被提出.
1.1.1 SRCNN及其改进算法
1)SRCNN[1]
SRCNN是Dong等[1]提出的基于深度学习的SISR模型的开山之作,它包含3个部分:LR图像特征提取层、LR-HR特征映射层、HR图像重建层,每个部分均采用一层卷积层实现.网络实现过程:将LR图像插值放大到指定倍数作为网络输入,经过3层卷积操作,输出重建后的HR图像.之后的SISR算法通常均包含这3个部分,一般使用1~2层卷积处理输入图像得到LR图像特征,使用多个卷积、ReLU激活操作等学习LR-HR图像的映射关系,使用卷积操作将HR图像特征重建为HR图像.
SRCNN是一种端到端的解决方案,输入和输出都不需要进行任何处理,采用L2范数的像素损失作为计算重建HR图像和原始HR图像在像素点上差异的指标,其目标优化函数为
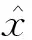
2)ESPCN[19]
将插值LR图像作为深度SISR模型网络训练的输入,会占用大量的内存空间,而且插值图像本身也会带来一些不真实的细节信息.为了降低训练过程的内存消耗,Shi等[19]提出ESPCN,它将LR图像作为网络输入,在合成数据集中,LR图像由原始HR图像经过插值算法如双三次插值下采样等,加入一定的噪声后得到.与SRCNN一样,ESPCN只有3层,前两层是普通卷积操作,最后一层使用一组上采样滤波器称为亚像素卷积操作,实现图像重建.
3)FSRCNN[20]
Dong等[20]也认为将LR图像作为SISR模型网络的输入能极大地降低训练时间和计算消耗,因此提出SRCNN模型的加速改进版本FSRCNN[20].该方法在网络末端采用反卷积操作实现图像重建.此外,FSRCNN在网络的特征映射层采用一个具有紧凑对称的沙漏形状结构,可学习到更为复杂的LR-HR图像映射关系.
此后,形成两类SISR框架:分别是以SRCNN为代表的前端上采样SISR框架[21-22]、以ESPCN和以FSRCNN为代表的后端上采样SISR框架[23-25],而后端上采样SISR框架因计算复杂度低、重建精度高得到广泛应用.
1.1.2 残差结构及其改进算法
1)全局和局部的残差学习
VDSR[21]是第一个提出用全局残差学习思想(即长跳跃连接)解决SISR问题的深度模型,它使用20层卷积学习LR-HR图像的映射关系,在Set5数据集上重建放大倍数为2,3,4的图像时,其重建精度(峰值信噪比(peak signal-to-noise ratio,PSNR)指标)比SRCNN分别提升0.87,0.91和0.87 dB.He等[26]提出了残差网络(ResNet),实验证明,ResNet的残差结构能有效地提升模型精度.SRResNet[27]延续了VDSR的全局残差学习思想,用堆叠的多个ResNet残差模块学习图像的局部残差信息,其网络深度达到54层,模型精度较VDSR更高.
此后,VDSR的全局残差学习和SRResNet的局部残差学习模块被广泛应用到SISR研究中.Lim等[28]在SRResNet模型的基础上提出EDSR模型,用去掉批归一化(batch normalization,BN)层的ResNet模块减少模型参数,并通过堆叠32个残差模块极大地提升了模型的重建精度.
2)残差学习与递归学习
DRCN模型[22]采用递归学习的方法,在多层网络上共享参数,减少了模型的参数量;在此基础上,结合全局、局部的残差学习,构建了残差递归学习网络DRRN[29],其重建性能优于DRCN.MemNet[30]利用长时记忆模块,每个记忆模块包含一个递归单元和一个门控单元,门控单元在递归单元之后,用于控制输出特征所占的权重;并使用80层网络最大限度让记忆信号在网络中流动,取得了良好的重建性能.递归学习减少了模型的参数量,但由于网络层数数量巨大使得它的计算复杂度剧增.
3)残差学习与密集连接
密集连接将网络中的每一层都和后面的所有层以前馈方式连接,促进了特征之间更好地融合,也使重建精度大幅提升,但参数量也随之增加.SRDensNet[31]用DenseNet[32]提出的密集连接,去掉其中的BN和池化层,将浅层、中层的特征全部输入到高层中,增强的特征使模型精度得到有效提升;RDN[24]模型、RRDB[33]模型也都使用了残差和密集连接模块.不同的是,RDN对每个残差密集模块中的特征进行局部特征融合和局部残差学习.RRDB模型首先对1个密集模块做残差学习形成新的残差基本模块,然后将3个残差基本模块做残差学习形成的Residual-in-Residual密集模块,这种密集残差模块相比残差或密集模块的简单堆叠,它的重建精度更高,当然计算复杂度也随之增大.为了降低模型的计算复杂度,CARN[25]模型为一种快速、精确、轻量化的SISR结构,对残差块进行局部(级联块内,残差块间)和全局的融合(级联块间),其中级联结构类似于在残差块间进行密集连接.CARN共9个残差块,分成3组,即3个级联块,在进入级联块前,用1×1的卷积做特征融合.不同于RDN使用3×3的卷积核,CARN使用1×1的卷积核减少了模型的参数.
4)残差结构与迭代上下投影
DBPN[34]使用迭代上投影和下投影操作的方式获取图像的不同特征,将这些特征融合后用于图像重建,是迭代上下投影SISR框架的代表.它的创新在于提出上投影模块和下投影模块,上投影模块先将LR图像进行反卷积放大得到HR特征图,再将该HR特征图进行卷积下采样得到一个LR特征图,最后将得到的LR特征图和最初的LR图像进行残差运算,得到新的特征图.下投影模块与上投影模块类似,操作相反.不同分辨率的图像特征进行融合,可以获得更多的信息,有助于促进SISR性能的提升.
5)残差学习与注意力机制
在通道中加入注意力机制能获取更有效的通道特征.RCAN[23]堆叠多个残差模块形成卷积组,在卷积组的每个残差模块中都加入通道注意力,并通过多组串联,每组使用短跳跃连接的方式有效避免了梯度消失的问题.Dai等[35]提出非局部增强注意残差组结构,命名为SAN,它用非局部操作获取长距离空间上下文信息,并用带二阶残差注意的局部源残差注意力组学习局部特征表示.PANet[36]使用金字塔注意力,建立不同大小特征之间的长区域依赖.通道注意力、二阶残差注意力、金字塔注意力等的加入,改进了网络特征,也提升了重建精度.
6)残差学习与多路径学习
多路径学习从多个路径抽取图像不同方面的特征,这些路径在传播中彼此交叉,因此能极大地增加特征抽取的能力.LapSRN[37]使用多路径的金字塔重建方式,即每个特征抽取路径从粗到细地预测子带残差,各个图像重建路径分别重建2,4,8倍的HR图像,该框架常被称为级联上采样SISR框架的代表.类似于LapSRN,ProSR[38]也采用了金字塔重建方式,同时重建2,4,8倍放大任务,并提出密集压缩模块,将密集模块、压缩单元串联后进行残差学习,密集压缩模块提升了模型的重建精度.DSRN[39]在LR图像块和HR图像块上同时抽取LR和HR空间的信息,形成两个路径,对应层上不断交换信息以提升学习能力.PixelSR[40]使用条件路径和先验路径,分别获取图像的全局结构和生成像素的连续依赖.局部的多路径学习中,MSRN[41]受到Inception[42]模块的启发,采用多尺度特征(卷积核为3×3和5×5)模块抽取多种特征,串联特征后,再用1×1的卷积核输出.CFSNet[43]使用主模块路径和调优路径,通过耦合操作将两个路径上的特征进行融合.MDSR[41]使用单个网络特定尺度的多路径学习策略处理SISR问题,让2,3,4倍SISR任务同时进行训练,其重建精度普遍比某个单尺度的训练方法高.多路径学习为残差学习提供了更多新的、可能的结合方式.
7)残差学习与非局部、多尺度相似性
将图像本身的特性(如非局部相似性、多尺度相似性等图像先验知识)加入残差模块可引导SISR.基于此,Wang等[44]提出NLNN,但是NLNN的参数计算量大,需要占用大量的计算资源.为此,Liu等[45]从减少参数量和保持性能的角度出发,将NLNN改进后提出NLRN.CSNLN[46]将多尺度、非局部等特性结合,提出尺度内的非局部和尺度间的非局部模块.在NLRN的基础上改进得到的残差非局部注意力模块RNAN[47],联合残差学习、非局部、注意力机制等,得到不错的SISR效果.
通过梳理发现:在全局和局部残差学习的基础上,若联合其他网络模块,如递归学习、密集连接、迭代上下投影等能极大提升模型的重建精度,同时也可能大幅增加参数量;若联合新的学习机制,如注意力机制、多路径学习、非局部相似性、多尺度相似性等获取更多的图像或通道内部的有效特征,有助于提升SISR模型性能.图2给出了几种网络模块的示意图.

图2 网络模块示意图
1.1.3 轻量化网络
1)轻量化卷积
为了提升性能和速度,一些基于普通卷积改进的轻量化卷积被提出,如空洞卷积、组卷积、分离卷积等.IRCNN[48]在标准的卷积中注入空洞卷积,使感受野增大2倍,取得了更高的精度.受到MobileNet[49]和Inception[42]的启发,CARN[25]模型使用组卷积,将数据分成多组,每组使用不同的卷积串联起来,并行运算每个组,从而减少参数和提升速度,但也牺牲了一部分的性能.分离卷积需要使用Depthwise卷积和Pointwise卷积,前者对输入的一组特征分组单独计算出各自的新特征图,后者将新特征图合并成一组.针对图像恢复任务,Lahiri等[50]提出LW-CNN,它在Inception模块的启发下,设计了轻量化模块LIST(light spatial transition)代替普通卷积,LIST实例化后,参数减少至CNN的1/25~1/13,极大地减少了模型参数和计算量.不仅如此,LW-CNN还提出改进的空洞卷积,在组卷积的启发下,将通道进行改组,设计出分组的搅动空洞卷积(grouped shuffled atrous transition,GSAT)模块,与普通的空洞卷积相比,参数量减少至原来的1/8.实验发现将LIST模块替代可分离卷积,用于亚像素上采样卷积层,既能降低模型参数,又能保证良好的重建精度.
2)信息蒸馏(通道分离)
IDN[51]使用多个信息蒸馏模块提升深度网络的特征学习能力,每个模块包含一个提升单元和一个压缩单元.提升单元混合了长路径和局部短路径两种特征,压缩单元则使用卷积操作实现压缩和维度缩减.IMDN[52]在IDN的基础上实现了多层次的信息蒸馏模块,每个模块的输入特征经过3次卷积和通道分离操作后,再用Concat连接3次的特征,连接后的特征又经过对比意识通道注意注意力层处理,最终用1×1卷积运算实现特征压缩.IMDN比IDN具有更高的重建精度,但参数量只增加了15万.
1.2 基于GAN的SISR方法
GAN是以两个神经网络相互博弈的深度学习方法,可用于有监督和无监督学习,本小节介绍有监督GAN的SISR方法,而无监督GAN的SISR方法将在不成对的SISR方法部分介绍.基于GAN的SISR方法可分为大放大因子GAN的SISR方法、逐级重建GAN的SISR方法、带先验知识GAN的SISR方法.
1.2.1 大放大因子GAN的SISR方法
1)SRGAN
SRGAN[27]首次利用GAN[53]来训练SISR模型,该模型同时训练生成器和判别器.其中:生成器为基于CNN的SISR网络,输入图像加入随机噪声后送入该网络进行模型训练,输出HR图像;判别器为普通的二分类网络,对比原始HR图像来判别生成的HR图像是否为真实图像,是则输出1,否则输出0.为了得到良好的重建效果,它使用了两阶段重建.首先,单独训练基于像素损失的SISR模型(命名为SRResNet);然后,将生成器和判别器做联合训练,训练基于像素损失、内容损失和对抗损失.判别器作为监督,使得生成器的重建图像细节变多,但也生成了一些不真实的噪声.
2)ESRGAN
为了提升SRGAN模型的重建精度,ESRGAN[33]模型做了两个方面的改进:改进了生成器的结构,提出一种有更高重建精度的RRDB生成器;增强了判别器的判别能力,使用相对判别器估算输入图像为真实和非真实的可能性,即预测真实图像比假图像更真实的概率.与SRGAN模型相比,在大部分的标准测试图像上,ESRGAN模型能在保持较好细节的同时使重建图像中的噪声变少.
1.2.2 逐级重建GAN的SISR方法
LapSRN[37]采用金字塔逐级重建方式,获得了不错的重建性能.为了得到逼真的图像纹理,Karras等[54]使用GAN的方式训练,提出基于逐级式GAN的SISR网络ProGAN.该网络逐级重建长宽同为4,8,16,32,64,128,256,512,1 024的多尺度、高倍数的重建图像;为了提高生成器模型生成数据的多样性,在判别器的最后一层加入了最小批判别性(minibatch discrimination);同时,为了提高训练的稳定性,使用了像素归一化.关于上采样和下采样,与之前的GAN所采用的反卷积、卷积操作(步长为2,卷积核为3×3)不同,ProGAN采用2×2 元素复制和平均池化;与LapSRN相比,ProGAN在同级重建结果上平均提升了0.05~0.13 dB.
1.2.3 带先验知识GAN的SISR方法
带先验知识GAN的SISR方法将图像中不同物体结构或目标分割的先验知识融入深度网络,作为深度网络的监督信号,训练基于像素损失、感知损失、先验知识等的GAN网络,引导深度网络重建出真实的细节和纹理.
1)SFT-GAN
先验纹理对SISR重建的影响非常大,Wang等[55]通过实验发现:草地的先验用于重建草地和墙壁,结果差别很大;用草地先验重建草地,获得非常真实的纹理,而重建墙壁却会让墙壁显得非常不真实.为了获得真实的纹理和细节,Wang等[55]提出SFT-GAN,以图像的分割掩码作为SISR的先验知识,指导SISR中不同区域的纹理重建.具体来说SFT-GAN在生成器中使用了多个残差模块,残差模块中的卷积层前都加入一层SFT层.每个SFT层,以条件网络特征图作为输入,使用简单的卷积与残差模块中的输入特征图进行调制,学习出参数,最后应用仿射变换自适应地学习到新的特征图.其中,条件网络特征图由不同区域的分割语义图经过几层卷积的特征学习后得到.所有的SFT层都共享一个条件网络特征图.这样,基于先验纹理的超分网络就能针对不同的区域重建不同先验的真实纹理.
2)FSRGAN
Chen等[56]充分利用人脸图像的几何先验信息,提出一种端到端的深度人脸SISR网络FSRGAN.其生成器网络为FSRNet,首先构建粗的SISR网络生成粗的HR图像,然后送入精细的SISR网络得到更为精准的HR图像.精细SISR网络包含一个精细SISR编码器、一个先验信息网络和一个精细SISR解码器,编码器生成HR图像特征,先验信息网络估计面部热力图和人脸解析图,最终解码器从图像特征和先验信息中恢复出HR图像.FSRGAN结合多种人脸先验,从粗到细的重建方式有效提升了人脸SISR的性能.FSRNet和FSRGAN模型在人脸对齐和人脸解析任务中均有不错的表现,而FSRGAN模型具有更精细的图像纹理.
1.3 基于NAS的SISR方法
NAS[57]是一类目前最新的方法,它使用强化学习寻找最优网络,可减少人工对模型设计的影响.这类方法先定义一个搜索空间,使用相应的控制器处理搜索,经评估后输出重建结果,通过网络训练自动调整,直到网络收敛得到良好的重建结果为止.基于NAS的SISR方法通常会将多个CNN SISR方法嵌入整体网络的学习中,一般情况下,会优于其中的一种或多种CNN SISR方法的简单组合.
MoreMNAS[58]是最早将NAS应用到SISR任务中的模型,含3个基础成分:基于细胞的搜索空间、基于NSGA-Ⅱ的相关多目标的模型生成控制器和返回多反馈的评估器.
在MoreMNAS的启发下,多种基于NAS的SISR方法被提出.FALSE[59]利用一个混合的控制器和一个基于细胞的弹性空间,增强宏观和微观的搜索.ESRN[60]则将搜索空间的细胞替换为目前最优秀的3种不同的密集残差模型,减少不必要的搜索.HNAS-SR[61]是一种解决真实SISR层次化搜索的结构系统,使用层次化的方式构建搜索空间和控制器.搜索空间使用多个普通细胞和上采样细胞,其中,普通细胞中集合了如空洞卷积、分离卷积、迭代上下投影、残差通道注意力等模块,上采样细胞则集合了区域插值、邻近插值、双线性插值、亚像素层、反卷积层等.控制器则分别构建细胞层控制器和网络层控制器.不同细胞都使用长短期记忆法自动选择每一层的结点,经过处理后输入到层次化的网络层控制器中.
1.4 目标优化函数、数据集与评价标准
1.4.1 目标优化函数
目标优化函数通常也称为损失函数,用于判别生成HR和原HR图像的差异,引导深度SISR网络的重建结果.不同的损失函数重建结果不同,好的目标优化函数通常都能让SISR模型快速收敛,重建出具有高精度和接近真实世界的图像纹理的图像.
基于CNN的SISR通常采用像素损失计算重建HR和原始HR图像在像素点(x,y)上的差异,有代表性的像素损失有L1范数损失、L2范数损失、Charbornier函数损失[37],分别简称L1、L2和Charbornier损失.基于NAS与基于CNN的SISR方法使用的目标优化函数基本一致.
基于GAN的SISR模型通常采用对抗损失和感知特征损失相结合的方式来训练.对抗损失常用于判别GAN生成器生成的SISR图像的真实性,真实输出1,否则输出0.感知特征损失计算重建HR和原始HR图像在图像高层语义上的差异,通常采用VGG预训练模型的中层特征判断两者之间的差异性.此外,与感知特征损失相似,纹理损失也使用VGG预训练模型计算重建HR和原始HR图像的像素点在网络某层特征上的相关性.
1.4.2 数据集
数据集可用于深度SISR方法的训练、验证和测试.训练集、验证集通常用于深度网络学习LR-HR的有效映射关系;标准测试集有助于SISR方法的重建性能对比.现有的SISR的标准数据集有:Set5[62]、Set14[63]、BSD100[64]、Urban100[65]、Manga109[66]、DIV2K 2017[67]、DIV2K 2018[68]、DIV2K 8K[69]、RealSR[70]、General-100[20]、PIRM[71]、T91[72]、ImageNet[73]、Flickr2K[33].数据集图片包括动物、建筑、草地、山、植物、天空、水、食物、风景、人物等.其中:Set5[62]、Set14[63]、BSD100[64]、Urban100[65]、Manga109[66]为SISR任务的常用测试集;General-100[20]、BSD200[64]、T91[72]为传统SISR任务的训练集;DIV2K 2017[67]、DIV2K 2018[68]、DIV2K 8K[69]、ImageNet[73]、Flickr2K[33]常用于深度SISR任务的训练集,前3个也提供SISR任务的验证测试集.
以上的标准数据集都可以应用到有监督的深度SISR方法(基于CNN、GAN、NAS的SISR方法)的训练和测试,而对于需要重建真实纹理(特别是基于GAN的SISR方法)的评测时,一般使用PIRM[71]、RealSR[70]等测试数据集.
1.4.3 评价标准
SISR方法使用图像评价指标(image quality assessment,IQA)来评判重建图像的质量好坏.现有的IQA可分为3类:全参考图像评估、无参考图像评估和主观质量评估.其中,全参考和无参考的图像质量评估均为客观评价指标,通过比较重建和原始HR图像的像素或图像纹理结构差异得到.当它们的差异性越小时,其评价指标的值也越高或越低.
全参考图像质量评估有PSNR、结构相似性(structural similarity,SSIM)、感知图像块相似性(learned perceptual image patch similarity,LPIPS)[74];无参考图像质量评估有自然图像质量评估(natural image quality evaluator,NIQE)[75]、主观指标(perceptual index,PI)[71];主观质量评估有平均主观得分(mean opinion score,MOS)[27].除了LPIPS和PI外,其他的评价指标值越高均表示差异性越小.
1.5 讨论与分析
3类SISR方法(CNN、GAN、NAS)都强调建立有监督的深度SISR模型学习出好的LR-HR映射关系.基于CNN的SISR方法一直以来都是有监督SISR的研究重点,本文从SRCNN及其改进算法、残差结构及其改进算法、轻量化网络3个方面介绍其代表性算法,详细阐述了每类代表性方法中的核心模块.基于GAN的SISR方法选取了大的放大因子、逐级重建、带先验知识3类的代表性算法并做详细分析.基于NAS的SISR方法是近两年才兴起的深度网络结构,在SISR上刚刚起步,本文对其为数不多的几类方法做了介绍.比较总结上述3类SISR方法(表1)发现:

表1 3类有监督的SISR方法的比较分析
1)基于CNN的SISR方法占据主流,基于GAN的SISR方法次之,基于NAS的SISR方法研究成果较少.
2)基于CNN的SISR关注于重建精度或重建速度,基于GAN的SISR关注于实现丰富图像纹理和逼真视觉效果,而NAS关注如何让多个已有SISR模型的模块能够实现复用,并获得高精度的SISR.
3)从重建精度的的角度来说,在基于NAS的SISR方法出现前,基于CNN的SISR方法的重建效果最好;但是基于NAS的SISR方法需要使用多块GPU、消耗大量的计算资源和很长的训练时间,对没有GPU资源的研究者很不友好.与CNN的SISR方法相比,基于GAN的重建精度低.在重建速度方面,轻量化CNN的SISR方法最快,其次为基于GAN的SISR方法,基于NAS的重建速度最慢.
4)在重建视觉效果上,基于CNN和NAS的SISR都不如基于GAN的SISR方法.基于GAN的SISR方法通常会使用基于CNN的SISR方法作为生成器,但判别器会去掉很多看起来很虚假的生成图像,而保留看起来更为逼真纹理和具有丰富细节的重建图像.
2 不成对的深度SISR方法
真实场景中,极难获取LR-HR图像对,如何构建真实SISR数据集存在极大的困难.按照训练样本的产生方式,现有的不成对的深度SISR方法可分为零样本的、弱监督的、自监督的SISR方法.
2.1 零样本SISR方法
基于LR图像中的自身内部统计信息对图像重建具有决定性影响的思想,Shocher等[76]提出零样本SISR方法ZSSR(zero-shot for super-resolution),该方法是深度无监督SISR的开创性工作.ZSSR不需要预训练,只需要在测试阶段训练用于测试的LR图像,学习该LR图像的内部特征.训练过程:首先将测试LR图像裁剪成固定大小的多个训练小图,形成多个成对图像集.其次使用已知下采样核时,采用和EDSR等相似的有监督训练方法;使用未知下采样核时,采用Michaeli等[77]所用的核估算方法估算正确LR图像后,再进行训练.在理想情况下,ZSSR可以和有监督预训练方法得到相当的结果;而在非理想情况下,能比它们取得更好的结果.其不足之处是需要长时间的测试,原因在于测试一张图像前必须先进行在线训练.
受到ZSSR[76]和元迁移学习的启发,Soh等[78]提出元迁移学习的零样本SISR(MZSR)方法,利用元迁移学习使参数快速适应于新的任务,用ZSSR方法对新任务中的图像做模糊核降质后做SISR,用不同的模糊核代表不同的任务.训练过程:先做有监督训练,然后用元迁移学习方式建立不同模糊核和不同任务之间的关联,之后采用ZSSR的核估计方法来估计下采样核生成LR,最后在元学习阶段的参数帮助下,根据具体图片更新参数得到适用于特定图像的参数.与ZSSR相比,它考虑了离线训练模型的优势,借助元学习来更新参数,因此能做到快速灵活轻量且无监督,适用于真实场景.
2.2 弱监督SISR方法
为了处理未定义的图像降质过程,研究者们开始研究弱监督学习SISR方法,主要有学习降质过程的两阶段训练、Cycle-in-cycle网络、自然图像特征约束.
1)学习降质过程的两阶段训练.代表方法为Bulat等[79]提出的两阶段处理方法.第一阶段学习图像降质过程.真实HR图像加入服从正态分布的随机噪声,通过HR-LR GAN中的生成器生成降质后的LR图像,通过判别器判断所生成的LR图像与真实LR图像的图像分布是否一致.第二阶段训练图像超分重建模型,通过LR-HR GAN的生成器产生最终的超分结果,通过判别器判断所生成的SISR图像与真实HR图像是否一致.两个阶段的GAN网络的损失函数都使用了像素损失和对抗损失.沿着这一思路,DASR[80]也使用两个阶段的训练方法,提出领域距离敏感的训练策略用于判别生成LR图像和真实LR图像之间的距离,增强对生成LR图像的约束.
2)Cycle-in-cycle网络.在循环GAN(CycleGAN)[81]的启发下,CinCGAN(Cycle-in-cycle GAN)模型[82]使用4个生成器和2个判别器,制造了2个CycleGAN,分别用于学习噪声LR图像到干净LR图像、干净LR图像到干净HR图像的映射关系.第一个CycleGAN,输入噪声LR图像到生成器中,输出一个真实干净的有连续分布的LR图像;第二个CycleGAN,输入干净LR图像到生成器中,输出一个干净的HR图像.两个网络都使用相同的损失函数,如对抗损失、循环一致性损失和实体损失,用于引导循环连续性、分布连续性和实体映射.
3)自然图像特征约束.DSGAN[83]在小规模按比例缩小的图像中引入自然图像特征,使用GAN网络训练不成对的HR图像,生成具有与原始图像相同特征的LR图像.构建HR-LR数据集后,将低图像频率和高图像频率分开,并在训练期间对其进行不同的处理.由于低频信息可以通过下采样操作保留,对抗训练主要学习丢失的高频信息(即细节、边缘等信息).使用颜色损失和感知损失约束生成LR图像,减少与双三次下采样LR图像之间的差异,纹理损失约束生成LR图像,让它保持和GAN网络中的隐藏图像有相同的纹理特征.
2.3 自监督SISR方法
自监督学习的核心是自动产生数据标签,通常使用一个或多个自动打标签的辅助任务,借助这些辅助任务自动生成标签.Menon等[84]提出的生成模型潜空间探索自监督照片上采样(photo upsampling via latent space exploration,PLUSE)方法是第一个用自监督方法来生成真实且下采样正确的LR图像.它将先验施加到隐藏模型Z上,使用生成网络生成HR图像,然后将其下采样后生成的LR图像,计算其和原始LR图像的下采样损失(即生成HR图像降采样之后得到的LR图像和原始LR图像间的距离),再更新隐藏模型Z.生成模型的潜在空间是有趋向性的,根据训练集,某些属性的可能性多,生成结果好,某些属性的可能性少,有可能导致伪影或不真实.基于这一情况,针对模型的潜在空间增加高斯先验约束项,使得潜在空间的概率分布符合生成网络预期.
2.4 讨论与分析
3类不成对的深度SISR方法(零样本的、弱监督的、自监督的SISR方法)都可以用于解决真实图像中缺乏LR-HR图像对的问题,总结后发现:
1)在实现方式上,零样本SISR方法也是无监督SISR的一种,它使用自身图像做下采样形成不同放大因子的图像对,训练SISR模型,训练过程不需要任何外部数据集;弱监督SISR方法使用少量的图像对,先学习图像的降质过程,然后用训练好的降质模型产生LR-HR图像对,最后用类似有监督的深度SISR方法训练生成的LR-HR图像对;自监督SISR方法用一个或多个自动生成图像标签的方式得到真实且正确的下采样图像,得到LR-HR图像对后,再用此训练有监督的SISR模型.
2)在用户体验上,零样本SISR方法从自身获取LR-HR图像对,只能在测试的同时做模型训练,因此重建一张图像需要比其他离线模型更长的时间;弱监督和自监督SISR方法都先使用深度网络产生新的LR-HR图像对,网络训练后生成SISR模型,测试时使用该模型就不需要太长的测试时间.三者相比,零样本SISR方法的用户体验不会太好,而弱监督和自监督SISR方法的运行时间与模型参数多少有关,参数较多时运行时间较长,反之较短,相比零样本SISR方法,它们的用户体验相对较好.
3)在重建效率上,零样本SISR方法的数据集较少,训练时间不会太长,基于自身样本训练,重建结果一般也较好,时间成本低.自监督SISR方法生成样本的真实性更好,重建结果也相对较好,但是整体的实现复杂度高,时间成本也高.弱监督SISR方法比自监督SISR方法的实现难度和时间成本低一些,重建结果不如自监督SISR方法.总的来说,弱监督SISR方法的重建效率介于零样本SISR方法和自监督SISR方法之间.
3 SISR方法的典型应用
本节介绍SISR的典型应用领域包括人脸、医学、遥感、雷达和小目标等.
3.1 人脸SISR
人脸信息具有唯一性和普遍性等,使用人脸信息作为身份确认的相关技术日益成熟,并广泛应用到身份信息比对、视频侦查、行动路径追踪上.但是LR的人脸图像,因为图像特征缺失较多,无法应用于后续的人脸识别工作中.
针对人脸LR问题,人脸图像先验与深度网络,特别是与GAN的结合,能有效提升人脸SISR的质量.Song[85]使用两阶段CNN,先生成人脸的轮廓结构,再从HR图像恢复出HR的人脸局部结构,最后将整体与局部信息结合生成清晰的人脸图像.Yu等[86]引入GAN生成8倍放大的人脸图像,使用判别网络的监督反馈重建多姿势多面部表情的LR图像.该方法提升了过小的LR图像尺寸在高倍数放大时的重建精度.Chen等[56]提出一种端到端的深度人脸SISR网络FSRNet,使用从粗到细的方式构建多个HR图像,结合多种人脸先验,有效提升了人脸SISR的性能.同时,采用对抗损失训练的FSRGAN,比FSRNet具有更精细的重建细节.Xin等[87]结合人脸纹理特征、形状特征、语义特征得到人脸SISR的残属性关注网络(residual attribute attention network,RAAN),该网络包括纹理预测网络(texture prediction network,TPN)、形状生成网络(shape generation network,SGN)和属性分析网络(attribute analysis network,AAN),用TPN特征引导TPN和SGN特征的整合.SGN使用编码-解码网络,先将图像下采样编码,解码后恢复成原始尺寸,中间加入跳层连接.TPN用了残差思想和空洞卷积,用更大的感受野获取更好的纹理特征.AAN先对特征映射进行属性编码,之后用全连接提取纹理和形状特征的注意力.Yu等[88]针对超低尺寸的人脸SISR存在的严重图像失真甚至性别反转等问题,采用其面部属性信息补充残差图像或特征图以减少面部SISR的歧义,开发了一个嵌入属性信息的上采样网络,该模型对分辨率为16×16的LR人脸图像进行重建时,能有效减少一对多映射的不确定性.Fan等[89]改进了残差单元和网络结构,增强了内卷积层间的信息流,充分利用人脸特征信息,提高了模型细节还原能力.
3.2 医学SISR
在医学影像中,超声、磁共振成像(magnetic resonance imaging,MRI)、计算机断层扫描(computed tomgraphy,CT)、正电子发射断层成像(positron emission tomography,PET)图像在医学领域中发挥着举足轻重的作用.LR的CT、MRI、PET图像清晰度低,存在伪影和容积效应,容易掩盖病灶耽误治疗,也会给医生诊断病情带来干扰.
随着SISR技术的发展壮大,医学SISR也逐步趋于成熟.鉴于医学图像缺乏正确的LR-HR图像对,为了重建出更为真实的图像,研究者们多采用GAN技术解决这类问题.Armanoius等[90]从pix2pix得到启发,提出基于GAN框架的MedGAN用于PET与CT的转换、MRI动作纠正和PET去噪.You等[91]在CycleGAN[81]的启发下,提出一个综合的基于GAN的框架,解决2倍放大的单切片CT SISR.但其需要LR-HR图像对,并且只能作用于小块的CT区域上,不能应用到整个CT切片图像.Chen等[92]先通过3D密集连接SISR网络DCSRN(densely connected super-resolution networks),重建脑部MRI的HR特征,之后使用一个GAN框架[93]引导DCSRN训练,进一步增强SISR的质量.Mardani等[94]提出基于压缩感知的GAN用于恢复更好的图像纹理.为了满足更高的可视化需求下,Gu等[95]为了解决胸部CT和脑部MRI的SISR问题,基于GAN技术提出深度全热图注意力网络作为网络生成器,联合内容损失、对抗损失、对抗特征损失组成多任务损失用于GAN网络的训练.通过若干个有经验的放射线学者打分,验证了该方法在临床上的有效性.
除了GAN之外,零样本SISR方法也被用于应对CT图像样例不足的问题.Zhang等[96]提出基于SISR和去模糊的迭代重建框架,使用零样本SISR网络协同CT领域知识和深度模型在LR CT图像的重建上的结果甚至优于其他HR CT图像结果.
3.3 遥感SISR
遥感图像通过拍摄目标辐射、反射和漫射的电磁波信号得到.卫星光学成像得到的遥感图像可提供丰富的地球表面信息,且探测范围大,受地面限制少,比普通相机获得的信息量大很多.在土地覆盖分类、城市经济水平估计、资源勘测等方面具有广泛的应用.CNN被成功应用到遥感图像重建中,通过深度网络重建HR遥感图像特征.Lei等[97]提出结合局部和全局特征LGCNet(local-global combined networks)的SISR模型重建遥感图像,取得良好的重建效果.Xu等[98]构建局部和全局的深度记忆连接CNN的SISR模型,将遥感图像的图像细节与环境信息结合起来.为了增强网络的特征表达能力,Gu等[99]在网络中增加了一个挤压和激励模块提升网络的特征提取能力,Dong等[100]使用增强的残差块和残差信道注意力得到多级遥感特征信息.针对单尺度的卷积操作很难获取地表目标的多尺度特征的问题,Lu等[101]提取不同大小的补丁作为多尺度信息输入深度学习网络,通过融合不同尺度的高频信息得到更丰富的目标特征.Zhang等[102]提出多尺度注意力模块,融合多尺度特征得到更有力的特征表示,同时结合自适应场景SISR的策略,描绘不同场景下的结构化特性.
3.4 雷达SISR
合成孔径雷达(synthetic aperture radar,SAR),是一种微波成像传感器,它不受云、雨、雾以及光照等天气因素的影响,可以实现全天时、全天候对地观测.SAR成像技术能够主动获取目标空间信息,在航空航天、环境监测及防震减灾、资源勘探等方面有着广泛应用.
深度学习技术在SAR方面的研究已取得一定的成果:杨亚霖[103]设计了残差学习和稠密连接结合的双通道耦合网络双通道耦合网络(bi-path network coupling for super-resolution,BPNCSR),提升了雷达探墙系统成像中图像的纹理重建和细节恢复.在BPNCSR的基础上,又设计了雷达图像重建架构RadarNet(radar network),利用CNN对雷达多次扫描的重复区域进行特征提取,结合残差稠密算法抑制墙体回波和噪声信息,最后通过特征融合模块对多路输出特征进行融合,实现了整个目标图像的特征重构.对于3D SAR的SISR,Gao等[104]提出一种基于深度网络的线性光谱估计算法,使用深度展开网络进行前向反馈矩阵向量的计算和元素间的非线性特征学习,与传统方法相比,它大大减少了计算量,并在噪声和模型误差上具有较高的鲁棒性.
在SAR图像水域分割上,分辨率不足致使图像中的陆地与水域边界模糊,影响水域分割精度.陈嘉琪等[105]使用深度残差模型、通道注意力与亚像素卷积提升SAR图像分辨率,提出一种基于亚像素卷积的增强型通道注意力深度残差SISR网络,对滤波后的SAR图像进行水域轮廓提取与精度分析.与传统算法相比,其重建效果与提取精度都有明显提升.针对LR星载SAR图像水域提取精度不足的难题,李宁等[106]融合轻量级残差CNN的SISR技术和传统SAR图像水域分割技术的优点,提出了一种基于局部的SAR图像水域分割方法,显著提升了该水域分割的精度.
3.5 小目标SISR
小目标是指在整个图像中占据像素点较少、分辨率较低的目标,这类目标存在检测率和识别率低的问题,使用SISR技术可提高目标的像素点数量和分辨率,缓解小目标自身存在的不足.
深度学习方面,一些文献提出SISR和目标检测同时进行可减少因像素点增加给SISR带来一些不必要的对象和信息导致模型的训练和测试时间大幅增加的问题.Haris等[107]将目标检测和SISR同时进行,实现了端到端的联合任务训练,但依然有大量的无关图像信息被执行SISR,降低了效率.Krishna等[108]提出将SISR网络加入到FasterRCNN(faster region-based CNN)目标检测框架中,用提升小目标特征的方式提升检测精度,但应用效果并不是太好.Li等[109]认为小目标特征和常规目标特征是具有某种映射关系的,基于SRGAN提出感知GAN(perceptual GAN),用生成器训练包含小目标的图像,生成小目标特征的SISR表示,用判别器来区分小目标的特征表示与常规目标的SISR是否一致,相比于FasterRCNN算法,该方法的小目标检测率取得了明显提升.
另一些算法不对整个图像进行SISR,先检测全图像得到感兴趣区域(ROI),再对ROI做SISR,最后进行目标检测.Bai等[110]提出SOD-MTGAN(small object detection via multi-task GAN),先用通用目标检测算法对整个图像做目标检测,得到许多的ROI,再使用有监督SISR做训练,即ROI作为HR图像,经过下采样若干倍后得到LR图像,模型采用基于GAN的SISR方法.该方法可以与现有的检测器结合使用,但只有ROI的图像忽略了小目标的上下文信息.Noh等[111]认为现有的小目标特征级SISR模型缺乏直接的监督,训练不够稳定,为此提出使用正确的HR目标特征级作为监督信息,能与LR输入特征共享相关的感受野,在小目标检测上超越了上述方法.
除了上述5种基于领域的SISR外,在诸如车牌SISR[112]、监控视频SISR[113]、红外SISR[114]、岩石SISR[115]、壁画SISR[116]、矿井SISR[117]等中,基于深度学习的SISR技术均发挥着巨大作用.基于领域的SISR任务除了使用1.4节所提及的评价标准外,还可结合领域任务的评价指标进行综合评测.
4 总结与展望
迄今,基于深度学习的SISR算法取得了突破性进展,本文从建立LR-HR图像的映射模型和面向真实场景的SISR两类核心挑战出发,重点介绍了有监督和不成对的深度SISR算法.有监督的深度SISR方法按照不同的网络结构又分为基于CNN、GAN和NAS的SISR方法,对每类方法做了详细介绍,并简单概述深度网络的目标优化函数、数据集与评价标准.不成对的深度SISR方法按照训练样本的产生方式分为:零样本、弱监督和自监督的SISR方法,分析其代表性算法的主要特色.基于领域的SISR从几个应用领域,如人脸、医学、遥感、雷达和小目标,简单介绍它们的代表性方法.基于深度学习的SISR方法取得了长足的进展,仍存在一些问题有待解决:
1)网络结构的搜索与模型优化.CNN、GAN、NAS等网络结构在SISR中取得显著成绩,但每类网络结构中依然存在参数量庞大、计算资源占用高等问题,如何进一步优化和改进网络结构,值得进一步研究.同时,探索深度网络训练中新的目标优化函数和新的网络训练方式,提升网络的收敛速度,减少梯度消失和梯度爆炸的问题,也是一项非常有意义的研究内容.
2)网络模块的设计和新的模式识别学习方法的引入.现有的网络模块(如递归学习、密集连接、上下迭代投影等)和学习机制(如注意力机制、多路径学习、非局部相似性、多尺度相似性等)对SISR精度有很好的提升,如何将这些网络模块和学习机制有效组合,或引入更多新颖的网络模块和学习机制(如迁移学习、增量学习、元学习、领域自适应学习)都是很有潜力的研究课题.
3)轻量化的SISR方法.随着手机、平板等移动终端的使用越来越普及,轻量化SISR网络应用于移动终端的需求越来越强烈.如何对现有的轻量化SISR方法做进一步的结构优化,设计具有更高精度、低参数量的轻量化SISR网络是SISR研究的热点.
4)面向真实场景的不成对的SISR方法研究.获取成对的图像集是不成对的深度SISR方法的技术难点,现有的零样本、弱监督、自监督方法虽然提出了一些解决策略,但各有其优缺点,为了得到正确的数据集,训练过程大多过于繁琐,同时它们的重建精度离实际应用还有一定的差距.因此,如何简化模型的训练过程、降低模型的计算复杂度、提升模型的重建精度,这是面向真实场景的SISR的重要研究课题,而不成对的SISR方法是现在及未来的热门研究方向.
5)深度SISR网络与领域先验知识的结合.基于领域的SISR在人脸和小目标图像上取得重大突破,技术相对成熟,但是在医学、遥感和雷达图像上的研究相对较少,主要是因为这几类图像集的获取困难,且LR-HR图像映射关系复杂.特别在真实场景中,数据集构建更为困难,难以满足实际应用,如何将SISR技术应用于领域图像,服务社会将是未来SISR研究的重点.
