基于深度主动学习的柬语单文档抽取式摘要方法
2021-04-15余兵兵徐广义莫源源
余兵兵 严 馨* 周 枫 徐广义 莫源源
1(昆明理工大学信息工程与自动化学院 云南 昆明 650500)2(昆明理工大学云南省人工智能重点实验室 云南 昆明 650040)3(云南南天电子信息产业股份有限公司 云南 昆明 650040)4(云南民族大学东南亚南亚语言文化学院 云南 昆明 650500)5(上海师范大学语言研究所 上海 200234)
0 引 言
柬埔寨和中国自古以来就开展了友好交往,是中国重要的双边贸易国之一。随着中国与东南亚交流的日益增多,东南亚语言自然语言处理技术的研究变得尤为重要。柬语在信息处理研究中相对薄弱,自动文本摘要在文本中起着重要作用。自动文本摘要通过分析原始文档从原始文本中提取出重要信息,然后生成简短摘要,可以从原始文本中提取或重写。进入大数据时代后,互联网上出现了大量的文字信息。将自动文本摘要技术应用于新闻领域后,简短摘要可以帮助人们快速获取信息。根据文档的数量,自动文本摘要分为单文档摘要[1]和多文档摘要[2]。单文档摘要是指针对单个的文档,对其内容进行抽取总结生成摘要;多文档摘要是指从包含多份文档的文档集合中生成一份能够概括这些文档中心内容的摘要。根据生成摘要的方法,自动文本摘要主要分为生成式摘要[3]和抽取式摘要[4]。前者是在理解文章语义的基础上,生成简洁的摘要;后者是通过抽取文档中的句子生成摘要,通过对文档中句子的得分进行计算,得分越高代表句子越重要,然后依次选取得分最高的若干个句子组成摘要。虽然抽取式摘要方法在文档摘要方面取得了令人瞩目的成就,但是在句子重要信息评估、冗余信息的过滤、多源信息的篇章组织上仍然面临诸多问题。
国内外对于抽取式文档摘要进行了大量的研究。最早的抽取式摘要基于规则方法。Luhn[5]1958年提出使用机器学习方法以来,自动文本摘要一直是自然语言处理领域的研究热点。传统的基于统计方法的自动文本摘要技术使用词频、句子位置[6]和关键词[7]等基本要素作为评价句子重要性的基准。后来,学者将外部知识引入自动文本摘要任务中,如TF-IDF[8]、TextRank[9]等算法。上述算法可用于挖掘语料库中的隐含知识,改进了自动摘要的效果。Kupiec[10]在基于规则的基础上,将贝叶斯分类器(Bayesian classifier,BC)应用到自动文本摘要任务中。Galley[11]利用条件随机随机场(Conditional Random Fields,CRF)进行句子二分类任务,抽取单文档摘要。Zhang等[12]提出了支持向量机来建模抽取式摘要。Conroy等[13]将隐马尔可夫模型(Hidden Markov Model,HMM)应用于文档摘要中,将句子在文档中的位置、句子内的单词数和句子单词与文档的相似度作为特征,取得了良好的效果。上述基于规则和机器学习方法仅计算一些文本简单特征,仅依赖于人工经验和规则,并且不考虑文档中文本之间的联系,所以最终结果并不令人满意。
随着深度学习的发展,被广泛应用于自然语言处理的许多任务中。Svore等[14]借助神经网络的方法进行自动摘要任务,并且比在DUC任务上的常规方法效果更好。Nallapati等[15]使用单词和句子两个级别的RNN(Recurrent Neural Networks)[16]将文档用向量进行表示,最后对原始文本中的每个句子进行分类,以确定句子是否出现在摘要中,从而实现自动文本摘要的任务。Narayan等[17]将Seq2seq框架应用于提取文档的摘要。在编码器端,使用卷积神经网络CNN(Convolutional Neural Networks)[18]将句子表示为向量,使用解码器实现句子的抽取任务。
为了解决柬埔寨语在使用深度学习方法做单文档抽取式摘要语料标注不足的问题,提出了一种将主动学习和深度学习相结合的方法。利用主动学习抽样策略选择出需要标注的文档,交给专家标注,经过标注后放入到训练集中,然后结合深度学习中编码器解码器模型重新训练模型抽取得到摘要。实验结果表明,该方法能够有效地提升柬语单文档摘要的质量。
1 方法设计
1.1 模型流程
本文采用了一种单文档抽取式摘要模型,引用了文献[19]使用的CNN-LSTM-LSTM神经网络模型来抽取单文档摘要。模型的具体流程如下:(1) 对从柬语各大官方网站爬取的新闻文档进行分词、去噪等预处理,得到大约5 000份新闻文档;(2) 使用单层的卷积神经网络CNN对句子进行编码,获得句子级别的特征,将其输入到递归神经网络LSTM[20]得到文档级别的表示;(3) 使用长短时神经网络LSTM和注意力机制[21]解码器抽取句子得到单文档摘要;(4) 根据主动学习抽样策略,选择需要手动标记的样本,交给专家进行标注,在标注后结束后添加到训练集中,重新训练模型,迭代循环。抽取流程如图1所示。
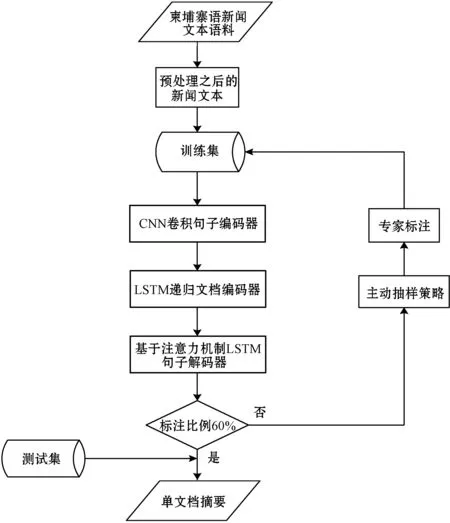
图1 基于深度主动学习的柬语单文档抽取式摘要流程
1.2 卷积句子编码器
卷积神经网络是深度学习中神经网络的进一步发展,并已广泛应用于自然语言处理、计算机视觉等领域。卷积神经网络包括多个特征提取层和非线性特征映射层。特征提取层是网络中的卷积层,输入语句在网络中进行卷积滤波以获得句子特征。非线性特征映射层是网络中的激活层。采用卷积神经网络对句子进行表示,首先对句子进行编码。对于每个句子S,使用CNN提取句子级别的特征。d表示词嵌入的维数,由n个词序列组成的文档句,用矩阵W∈Rn×d表示,在矩阵W和宽度为C的卷积核K之间应用卷积,表示为:
(1)
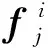
(2)
式中:Si,K表示第i个句子特征在卷积核K的作用下经过最大池化的值。利用不同宽度的多个核来获得一组不同的句子向量。最后,将这些句子向量相加,得到最终的句子表示。
1.3 递归文档编码器
在文档层次上,使用递归神经网络将句子向量序列组合成文档向量。长短时记忆网络LSTM是一种特殊的循环神经网络类型,其可以学习长期依赖信息。LSTM将每一个重复的神经网络模块视为一个细胞,通过门结构来控制细胞状态,门是一种让信息选择性通过的方法,包含一个sigmoid层和一个乘法操作,sigmoid层的输出决定了每个部分有多少可以通过。给定文档D=(s1,s2,…,sm),时间步长t处的隐藏状态ht更新为:
(3)
(4)
式中:st是当前时间步的输入;ht-1是上一个时间步的隐藏层状态;it、ft、ot分别表示当前步的输入门、遗忘门和输出门;σ表示sigmoid函数;ct表示细胞更新状态;tanh为激活函数;ht为当前步LSTM隐藏层的状态;W是一个可学习的权重矩阵。
1.4 句子提取器
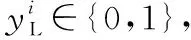
(5)
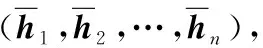
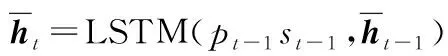
(6)
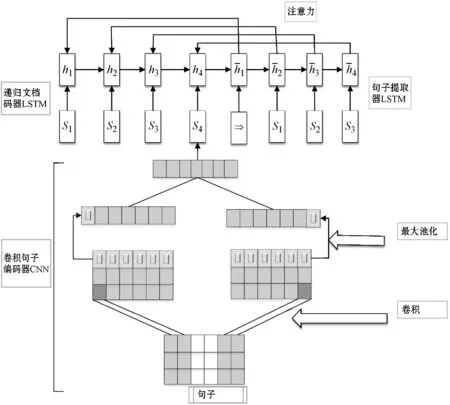
图2 CNN-LSTM-LSTM神经网络模型结构示意图
2 主动学习
与大多数深度学习任务类似,对于柬语在使用深度学习方法做单文档摘要时,存在着语料标注不足的问题,需要人工标注,而人工标注的成本很高。主动学习旨在通过抽样策略选择要标注的文档来改善此问题,希望以较少的标注获得更好的性能。为此,本文考虑了交互式获取标注的方法。主动学习的过程由多轮组成,在每一轮学习的开始,主动学习算法选择要标注的文档。在收到标注后,通过增强数据集上的训练来更新模型参数,并进入下一轮。假设标注文档的成本与文档中句子数成正比,并且所选文档都需要标注。主动学习抽样策略是主动学习算法的关键所在,常用的主动学习抽样方法有最小置信度方法、最大归一化对数概率方法等。
1) 最小置信度方法(Least Confidence,LC)。该方法原理是求出模型输出概率积的最大值,即标注序列的概率积。概率积越小说明不确定度越大,根据概率积的大小对未标记的样本进行升序排序,以此抽取出需要手工标记的样本,计算式表示为:
(7)
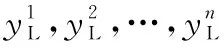
2) 最大归一化对数概率算法(Maximum Normalized Log-Probability,MNLP)。基于最小置信度的方法倾向于选择长度较长的文档,根据式(7)对未标记的样例进行升序排序相当于式(8)对未标记的样例排序,计算式表示为:
(8)
由于式(7)倾向于选择长度较长的文档,式(8)包含对句子的求和,长度较长的文档需要更多的标注工作,因此提出了最大归一化对数概率算法,该方法的原理计算出预测中序列的最大概率值的对数和,并进行归一化,根据概率值对数和的大小对未标记的样本进行升序排序,计算式表示为:
(9)
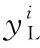
3) 随机选择采样(Random Sampling)。随机选择采样是从未标记的样例中随机选择一部分样例。随机选择采样可视为监督学习中的样本选择方法。实验将监督学习方法与上述两种主动学习采样策略进行了比较,验证了主动学习方法的有效性。
本文使用的主动学习方法是最大归一化对数概率方法。具体过程如下:随机抽取出1%的训练数据进行人工标注,构建CNN-LSTM-LSTM的单文档抽取摘要模型;使用该模型并使用最大归一化概率算法抽取出2%的训练数据进行手动标记并再次训练模型,迭代此过程直到标注数据达到训练集的60%,达到本文主动学习设置的停止条件。
3 实 验
3.1 语料获取
本文中所使用的实验语料,主要来源于人工收集和网页爬取相关主题新闻等方式获取的新闻文档语料,主要来源于柬埔寨新闻日报网。所采集到的语料涵盖了众多领域,例如政治、体育和军事等。利用实验室分词平台进行分词预处理,并且通过主动学习抽样策略挑选出了定量的文档,通过专家标注得到了包括大约5 000份柬埔寨语新闻文档和大约3 800篇带有标注的文档。其中80%的新闻文档用于训练,20%用于测试。具体语料集分配如表1所示。

表1 柬埔寨语单文档抽取式摘要的语料集
3.2 评价指标
ROUGE评测机制已被证明与人类评测类似,所以本文选择的自动评价工具为现在最为主流的评价工具ROUGE评测,其评测原理采用召回率来作为指标。ROUGE-N基于摘要中n元词(n-gram)的共现信息来评价摘要,是一种面向n元词召回率的评价方法。ROUGE-L基于生成的摘要与参考摘要中的最长公共子序列(Longest Common Subsequence)评价摘要。即生成的摘要和参考摘要最长公共子序列越长,生成的摘要质量越高。本文采用了一元召回率(R1)、二元召回率(R2)和最长公共子序列的召回率(RL)作为本文摘要的评价指标。计算式表示为:
(10)
式中:n表示n-gram的长度;RS表示参考摘要;Countmatch(n-gram)表示生成摘要和参考摘要中同时出现n-gram的个数;Count(n-gram)表示参考摘要中出现n-gram个数。
3.3 实验结果分析
为了验证本文提出模型的合理性,针对柬语的抽取式单文档摘要任务进行了2组对比实验,且这2组对比实验都是在上述语料集上进行的,且评价指标相同。
1) 实验一:主动学习抽样算法效果的比较。为了验证本文提出的主动学习算法的效果,对第2节的主动学习算法进行了比较,将随机选择采样方法作为基线,与两种主动学习算法作为对比,用来验证主动学习算法结合CNN-LSTM-LSTM模型的性能。两种算法都以相同的1%的原始训练数据和随机初始化模型开始,在每一轮中,每个算法从其余的训练数据中选择需要标注的文档,并将这些文档添加到训练集中。算法在其增强训练数据集上对模型参数进行50次随机梯度下降更新。本文通过测试数据集上的R1、R2和RL值来评估每种算法的性能,实验结果分别如表2、表3和表4所示。
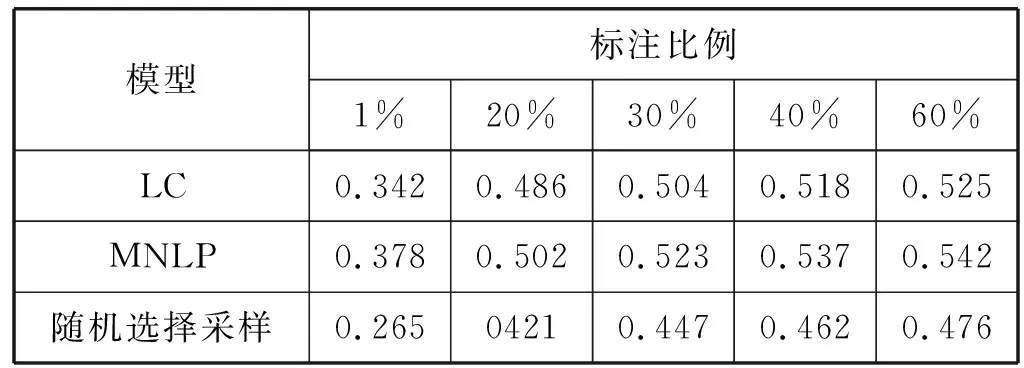
表2 主动学习算法抽取摘要的R1分值对比结果
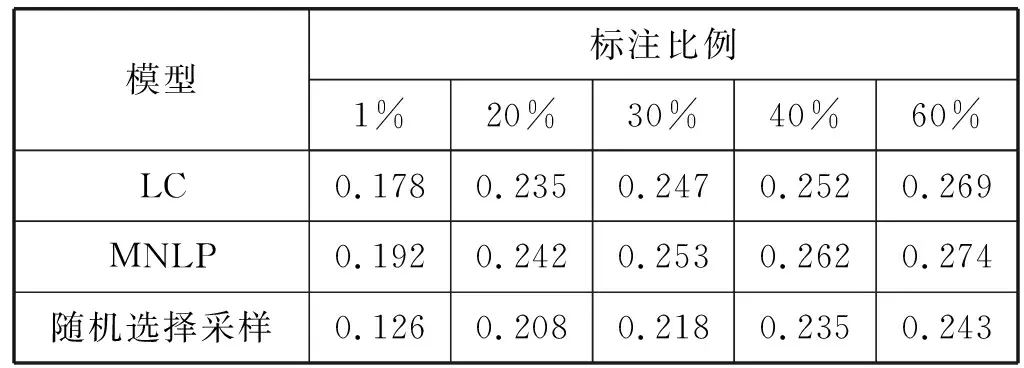
表3 主动学习算法抽取摘要的R2的分值对比结果
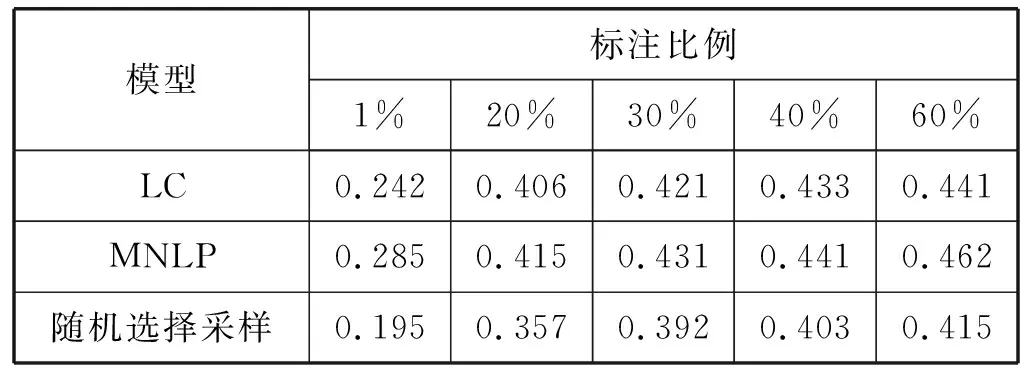
表4 主动学习算法抽取摘要的RL分值对比结果
可以看出,加入了主动学习算法的模型明显提高了神经网络模型的抽取效果。在两种主动学习算法中,MNLP算法的效果较好,R1、R2和RL的分值在同等标注比例下最高。随着标注百分比的增加,三种模型的R1、R2和RL分值都呈现出增长的趋势。可见在使用相同数据当挑选出的文档标注比例为25%时两种主动学习算法的R1、R2和RL值就可以达到随机基线模型的分值,相比较于基准实验,随着标注比例的增加,其R1、R2和RL值明显提升,因此可得在基准模型中加入主动学习算法有利于提高模型的抽取精度。
2) 实验二:为了验证本文提出方法的有效性,本文采用了基于条件随机场[11]和支持向量机[12]的单文档抽取式摘要方法作为对比,在使用相同训练集的情况下,与本文方法的摘要效果相比较,实验结果如表5所示。
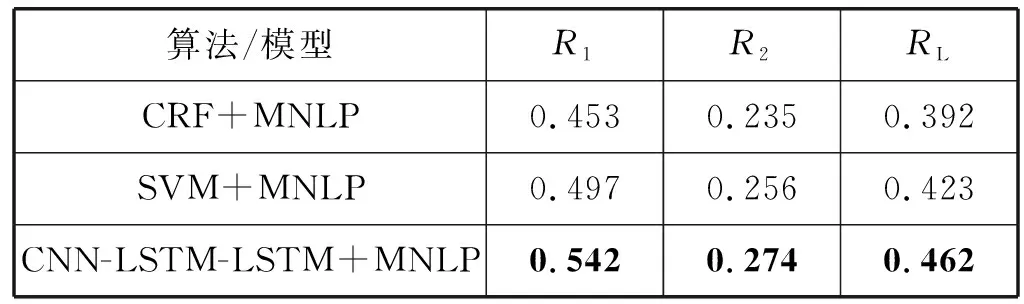
表5 不同模型抽取摘要的对比实验结果
由表5可知,基于深度主动学习模型明显提高了抽取摘要的效果,相较于以前提出的机器学习方法在R1、R2和RL值上都有显著提升。对比方法是在基于句子和单词本身的表层特征进行统计,未能充分利用词义关系、词间关系等特征,本文方法不仅考虑到了文档内的文本之间的关系,挖掘了语料中的隐含知识,而且还提高了召回率。因此可以得出,基于深度主动学习的方法有助于提高柬语单文档抽取的质量。
3.4 摘要生成示例
本节通过示例将文本改进的摘要生成模型抽取得到的摘要与参考摘要进行比较,如表6所示。

表6 摘要生成示例
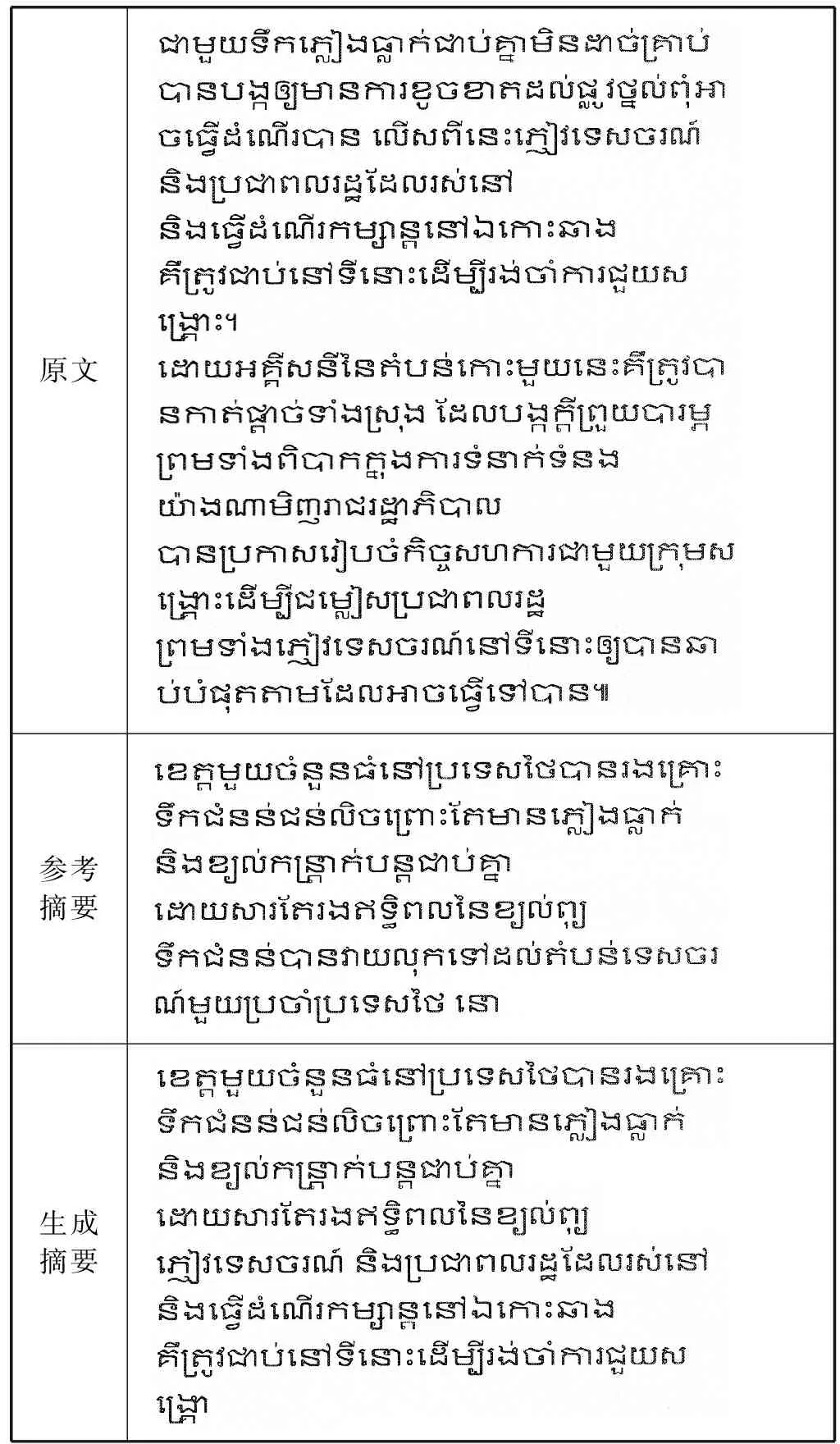
续表6
4 结 语
本文针对柬语在使用深度学习方法做抽取式摘要语料标注不足的问题,在原有深度学习模型的基础上提出了一种将主动学习与深度学习相结合的方法,利用主动学习算法选择定量的文档,获得标注,然后结合深度学习中编码器解码器模型进行训练抽取得到摘要。实验结果表明,该方法与现有单文档抽取式模型相比,召回率得到了有效的提高,改善了柬语单文档抽取的质量。下一步工作将尝试将本文方法应用到多文档摘要任务中,从而进一步提高柬语多文档抽取式摘要的质量。
