基于深度多模态特征融合的短视频分类
2021-04-13张丽娟崔天舒井佩光苏育挺
张丽娟,崔天舒,井佩光,苏育挺
(天津大学 电气自动化与信息工程学院,天津300072)
伴随着智能手机和移动互联网的迅速普及,短视频作为一种新型的用户生成内容,已经广泛出现在各个社交平台上,如抖音、Instagrm 和Vine。据抖音官方数据显示,截至2020年1月5日,其日活跃用户数已经突破4亿。与传统意义上的长视频相比较,短视频的时间长度通常被限制在2 min以内,这使得人们更容易获取和分享这些视频。除此之外,短视频丰富的内容和多样的表现形式为受众提供了更优质的用户体验,是短视频受欢迎的另一个原因。
已有的短视频内容分析相关研究主要包括场景估计[1-3]、短视频的流行度预测[4]及短视频的推荐[5-6]等。例如,Zhang等[1]利用短视频的文本、音频和视觉模态特征解决多媒体场景分类的问题。Wei等[2]采用多模态特征融合的神经网络(Neural Multimodal Cooperative Learning,NMCL)解决短视频场景分类的问题。Nie等[3]致力于分析声音模态对于短视频场景类别预测的影响。Jing等[4]通过提出一种新颖的低秩多视角学习框架解决短视频的流行度预测问题。Liu等[5]基于多模态特征融合的角度提出用户-视频联合注意力网络(User-Video Co-attention Network,UVCA)解决短视频的推荐任务。Shang等[6]提出了面向短视频大数据的推荐系统实现短视频的推荐。本文致力于解决短视频标签分类问题。
近年来,随着计算机视觉领域理论的飞速发展和图像相关任务的理论日益成熟,人们越来越多地去解决视频相关的问题而不是图像。从传统的人工处理获取视频特征到现在依赖于神经网络提取视频的特征,从原来小范围的数据集到现在大范围的数据集,视频分类领域的研究已经取得了巨大的进步。现有多模态特征融合的视频分类算法主要通过提取不同模态的特征并进行直接融合以解决分类问题,然而,该视频分类算法普遍针对的是传统长视频,不能直接应用于短视频的分类,主要原因有:①与传统意义上的长视频相比,短视频的时间长度通常只有1~2 min,所以需要在有限时间长度、有限内容的视频中提取出对分类重要的特征。②短视频的来源广泛,表现形式多样,所以短视频相比较长视频,具有更高的信息复杂度和冗余度。③现有的特征融合方法多利用多模态特征之间的公共部分,而忽略了不同模态特征之间的私有部分。综上所述,现在的视频分类算法并不适合解决具有“时短”特性的短视频分类任务。
针对上述问题,本文提出了一种端到端的基于深度多模态特征融合的短视频分类算法,搭建基于音频模态的私有域、视觉模态的私有域及音视觉模态的公有域组合而成的域分离网络,使用相似性损失函数探寻不同模态由公有域网络提取到的特征相似性,使用差异性损失函数探寻同一模态私有域网络和公有域网络提取到的特征差异性,并使用分类损失指导视频全局特征的分类。大量实验结果表明,本文算法可以很好地解决短视频的分类问题。
1 相关工作
本文主要从以下2个角度进行阐述:①深度特征学习,主要介绍利用深度卷积网络实现对短视频模态特征提取的相关工作;②多模态特征融合,简单介绍传统特征融合方式和现在普遍的特征融合方式。
1.1 深度特征学习
早期的视频特征提取方法采用2D卷积网络学习视频的每一帧特征,该方法的灵感来源于图像处理,然而其忽略了连续视频帧之间的时间关联性。为了保留时间相关性,现有很多方法通过聚合视频的帧特征作为一个整体的视频特征表示。Long等[7]提出注意力簇网络(Attention Cluster Network,ACN),通过采用注意力单元将视频的局部特征聚合成视频的全局特征。Ma等[8]通过设置每一时刻的特征和前一个时刻特征按权重进行加权实现特征融合,从而实现视频分类。近年来,为了充分利用视频的时空特征,3D卷积网络被提出用于学习视频的连续帧特征而非单一的视频帧特征,3D卷积网络的输入参数在保留了视频批量大小、视频通道、视频帧宽度和视频帧高度4个参数的基础上,增添了视频深度这一参数,用于记录每一个视频帧序列内的视频帧数量。Tran等[9]提出C3D网络,利用3D卷积提取连续帧序列的时空域特征,并在视频分类准确率上取得了巨大的突破。近年来,以3D卷积为基础推出的一系列视频特征提取方法被广泛地应用在视频分类、跟踪、分割等领域。例如,Carreira等[10]提出I3D网络,通过在3D卷积网络基础上增加网络宽度的方式提高网络分类性能。Hara等[11]则将原本应用在2D卷积网络的ResNet延伸扩展到3D卷积网络,通过提出ResNet3D以解决视频分类的相关问题。Feichtenhofer等[12]提出了SlowFast Network,整个网络通过构建快慢2个3D卷积网络去获取视频的全局特征。
然而,相比较传统的2D卷积网络,3D卷积网络需要更大的参数量及存储空间。为了解决该问题,Qiu等[13]通过构建P3D网络,将3D卷积核用空间域的2D卷积及时间域1D卷积进行联合表示。Tran等[14]运用R2+1D网络将3D卷积网络分解为独立的空间和时间模块。Xie等[15]在S3D-G网络中采用(2D+1D)的卷积核代替I3D中的卷积核。
为了提高短视频分类的性能,本文采用3D卷积网络作为特征提取网络,同时还分别应用到公有域网络和私有域网络中,实验结果证明了该网络架构的普适性和有效性。
1.2 多模态特征融合
区别于传统的图像分类等任务,视频分类问题可利用的信息除了视觉信息外,还包括音频信息、光流信息及轨迹信息等多种模态信息。
传统的多模态特征融合策略大致分为前期融合和后期融合2种方式。前期融合通常将每个独立的模态特征拼接成一个全局特征,并且将这个全局特征放入分类器中进行分类[16]。例如,D’Mello和Kory[16]通过直接拼接音频模态特征和视觉模态特征获得视频的全局特征实现情感检测。后期融合则采用一些特定的数学方法去融合来自不同模态特征的判断得分,如平均、加权等操作。然而这些方法都忽视了不同模态特征在特征空间的关联性,而且在融合方式上也缺乏更有效的指导。
为了克服传统特征融合方法的缺陷,越来越多的人致力于寻找新的解决方案以提高分类的性能,代表性的方法包括联合学习、子空间学习、深度多模态特征学习等。联合学习是一种经典的用于多模态特征融合的半监督学习方法,该学习方法会对有标签的样本独立地训练每个模态的特征。针对于无标签的数据,整个学习过程会从每个独立的模态网络挑选标签置信度最高的无标签数据加入到训练网络。联合学习的优点在于:每次对于单一模态网络中数据的更新会参考其他模态的置信度。然而这种方法的实现依赖于训练集中每个短视频不同的模态信息针对每一个类别的预测具有很高的置信度,这种要求对于短视频是很难实现的。
子空间学习是另一类用于多模态特征融合的常见学习方法[17-19]。子空间学习的假设在于不同模态的特征会享有一个公共的子空间。例如,典型相关分析方法(Canonical Correlation Analysis,CCA)[17,19]通过最大化不同模态的特征向量在潜在子空间上的关联性实现特征的融合及降维。Zhai等[17]在共享子空间中从多视角角度进行多视角度量学习。Franklin[19]将典型相关分析方法应用在数据挖掘和预测等领域。除了典型相关分析方法,采用深度网络进行特征提取和融合也成为了子空间学习常用的方法之一。Feichtenhofer等[18]借助双流卷积网络(Convolutional Two-Stream Network,CTSN)探寻不同模态信息在特征空间的向量表示并进行特征融合。Wang等[20]则在此基础上使用时域分割网络(Temporal Segment Network,TSN)提取不同视频片段的特征,并根据不同片段在不同模态特征空间的分类得分,采用分段函数叠加分类得分且融合不同模态的分类得分,最终实现对视频的分类。
受到子空间学习的启发,本文从特征表示空间的角度解决短视频分类问题,重点在于将特征空间划分为不同模态的私有域和所有模态的公有域,整个特征空间的数目取决于模态的数量。
2 深度多模态特征融合分类算法
本文算法框架如图1所示。图中:Hpa表示音频模态的私有域特征,Hpv表示视觉模态的私有域特征,Hsa表示音频模态的公有域特征,Hsv表示视觉模态的公有域特征。本节将对设计的短视频分类算法进行详细介绍,具体从特征提取网络、相似性损失函数、差异性损失函数及分类损失函数4个方面进行描述。
2.1 特征提取网络
为了挖掘短视频视觉及音频模态的时域信息,本文利用3D卷积网络分别获取视频的视觉模态和音频模态各自的私有域特征及视觉模态和音频模态的公有域特征。针对视觉模态,按照224×224的尺寸从短视频中提取连续的32帧视频帧序列;针对音频模态,先通过从整个短视频中按照等间隔将短视频分为32个视频片段,再提取这32个视频片段的音频片段并将其转换成为频谱图表示这段音频的变化规律。需要注意的是,频谱图相比较视频帧而言只具有单通道。通过对比不同3D卷积网络的准确性和训练的复杂度,决定采用I3D网络作为特征提取网络,在该网络的基础上微调了网络的输出通道,增加了平均池化层,删除了最后用于分类的全连接层,最终输出的特征向量维度为512维。
在网络整体结构设计上,本文将整个网络按照特征提取的角度划分为视觉模态信息的私有域网络、音视觉模态信息的公有域网络及音频模态信息的私有域网络3个模块。通过降低整体损失函数的数值来优化网络模型的参数,实现短视频的特征提取和分类。整个损失函数的实现包含3部分:①相似性损失LS,用于探寻不同模态间(即视觉模态信息公有域特征和音频模态信息公有域特征)的相似性;②差异性损失LD,用于衡量同一模态内的差异性,即视觉模态信息的私有域特征和公有域特征之间及音频模态信息的私有域特征和公有域特征之间;③分类损失LC,用于将最后获得的融合后的全局特征进行分类。整个损失函数表示为

式中:α用于平衡相似性损失在整个损失中的权重;β用于平衡差异性损失在整个损失中的权重;γ用于平衡分类损失在整个损失中的权重。
2.2 相似性损失
通过构建相似性损失,可以获得视觉模态信息和音频模态信息公有域特征。本文借鉴了被广泛应用在人脸识别的孪生相似性损失去探寻不同模态公有域特征之间的相似性。
孪生相似性损失由Chopra等[21]提出,主要应用于人脸识别领域并取得了良好的效果,在此基础上,越来越多的人致力于孪生网络结构的优化和使用,Zagoruyko和Komodakis[22]优化了孪生网络并且将其应用在图像修复中。Bertinetto[23]、Valmadre[24]等将其使用延展到了目标跟踪,并且获得了理想的效果。受到孪生网络的启发,本文同样提出了基于孪生相似性损失的相似性损失,通过降低相似性损失LS_Siamese的值,实现对模态公有域网络的优化,具体公式为

2.3 差异性损失
本文中,差异性损失被用于探寻单一模态下公有域特征和私有域特征的差异性关系,具体将探讨视觉模态公有域特征和视觉模态私有域特征、音频模态公有域特征和音频模态私有域特征这两部分差异性的关系。
本文认为同一模态内私有域特征和公有域特征差异性主要集中在分布差异性和数值差异性两方面,接下来将以音频模态的私有域特征和音频模态的公有域特征为例,从分布差异性和数值差异性2个角度说明整个差异性损失。
针对分布上的差异,由于 KL(Kullback-Leibler)散度被广泛地应用于评估模型输出的预测值分布和真值分布之间的差异,因此,在实验中将采用KL散度算法计算同一模态分布的差异性。在降低差异性损失LD_KL的过程中,从分布差异的角度实现对模态私有域网络参数的优化,具体公式为

针对在数值上的差异,采用孪生网络差异性损失的方法去探寻差异性是一种可行的方式,在降低差异性损失LD_Siamese的过程中,从数值差异的角度实现对模态私有域网络参数的优化,具体公式为

式中:d为可调节的常数,通过设置常数的数值,调整音频模态私有域特征和音频模态公有域特征在数值上的差异性。实验结果表明,当d数值为3时,学习到的私有域特征更有利于提高短视频分类的准确性。
整个差异性损失的公式为

2.4 分类损失

通过设置分类损失指导整个模型实现分类,本文选择交叉熵损失作为分类损失函数,在降低分类损失LC的过程中,实现对模态私有域网络参数的优化,具体公式为

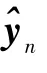
3 数据准备及实验分析
3.1 数据准备
实验数据集选择AI-challenger-mlsv-2018数据集,整个数据集包含大约200 000个短视频,涉及类别有63类。由于研究目标针对的是短视频单标签的分类,此次实验对存在多标签的短视频数据约11 323个进行了排除工作,将处理后的短视频数据按照10∶3的比例划分为训练集和测试集,每个短视频的视频长度不超过12 s。
3.2 实验分析
本节将从实验结果的角度对提出的网络进行系统全面的分析,在整个实验分析中包含以下4种指标:AR(Average Recall)、AP(Average Precision)、Micro-F1、Macro-F1。
3.2.1 网络复杂度
整个网络的实现由于采用的是3个结构相同的3D卷积神经网络分别探寻音频模态的私有域特征、视觉模态的私有域特征、音视觉模态的公有域特征3部分,而不是采用普遍的音频模态特征提取网络和视觉模态特征提取网络2部分,网络模型的参数量和输出的特征总数要高于现在普遍使用的特征融合网络。在时间复杂度上,因为同时要优化3个网络模型的参数及引入相似性损失、差异性损失计算损失,整个网络模型的时间复杂度要高于现阶段的视频分类网络。
对比表1中5种多模态特征融合分类算法(SlowFast Network[12]、C3D(multimodal)、I3D(multimodal)、TSN[20]、CTSN[18])与本文算法在达到网络效果最好时所需要的迭代次数,发现本文算法需要的迭代次数最少,为52次,较为明显地减少了训练次数的时间成本。分析整个优化过程,由于多模态算法通过计算差异性损失和相似性损失,加速了对网络私有域特征和公有域特征的分离,同时也加速了整个网络的收敛和参数的优化。

表1 不同网络短视频分类性能对比Table 1 Performance compar ison of micro-video classification in different networks
3.2.2 参数对比实验
为了使整个网络的实验性能取得最好,探寻了相似性损失权重α、差异性损失权重β及分类损失权重γ对整个实验的影响。为了简化参数的学习过程,首先在固定分类损失权重γ的前提下,探寻相似性损失权重α和差异性损失权重β对整个实验结果的影响。参数α、β和γ的不同取值对网络性能的影响如图2所示。表明,当固定γ的值时,在调节参数α和参数β的过程中发现,当参数α的值为0.4,参数β的值为0.6时,效果最好。然后固定参数α和参数β的数值,在调节参数γ的数值过程中,发现当参数γ的值为1.2时,提出的网络性能达到最好。
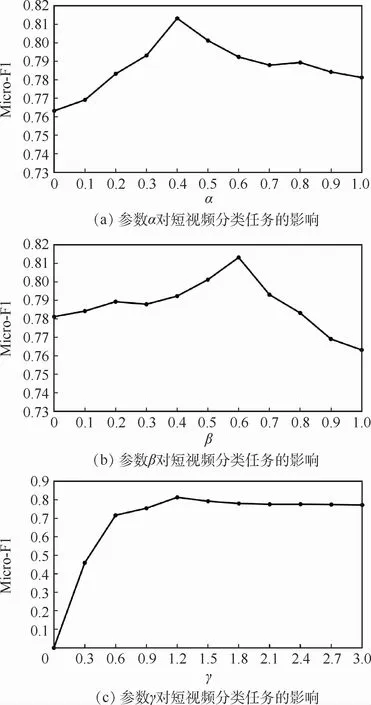
图2 参数α、β、γ不同取值对短视频分类任务的影响Fig.2 Influence of different values of parametersα,β,γon micro-video classification task
3.2.3 实验性能对比
为了证明本文所提模型的有效性,先后对比本 文 模 型 与 C3D[9]、I3D[10]、R2+1D[14]、Res-Net3D[11]、GoogleNet[25]、S3D-G[15]、SlowFast Network[12]、C3D(multimodal)、I3D(multimodal)、TSN[20]、CTSN[18]共11种视频分类算法在AR、AP、Micro-F1、Macro-F1这4项指标下的性能。其中,C3D[9]、R2+1D[14]、ResNet3D[11]、S3D-G[15]、GoogleNet[25]和I3D[10]是常用的单模态特征视频分 类 网 络,SlowFast Network[12]、C3D(multimodal)、I3D(multimodal)、TSN[20]和CTSN[18]是常用的多模态特征视频分类网络。通过观察表1的数据可以发现,本文算法在AI-challenger-mlsv-2018数据集中AR、AP、Micro-F1、Macro-F1取值分别为0.782、0.795、0.813、0.789,这些数据反映了网络在短视频分类任务中的有效性。
3.2.4 消融对比实验
为了验证实验的有效性,表2分别比较了视觉模态特征、音频模态特征、前期融合特征、公有域特征、私有域特征及本文算法所提取的特征共6种特征。
表2中,视觉模态特征、音频模态特征是单独直接将对应的视觉模态信息、音频模态信息输入到I3D网络后得到的分类结果;前期融合是直接将得到的视觉模态特征和音频模态特征融合后得到的全局特征;而公有域特征则是通过公有域网络,经过相似性损失约束得到的视觉模态和音频模态的公有域特征;私有域特征是将视觉模态信息和音频模态信息分别通过各自私有域网络,经过差异性损失约束得到的私有域特征。本文算法则是在得到的私有域特征和公有域特征上,对得到的私有域特征和公有域特征融合得到的全局特征,取得了更好的分类效果。

表2 不同网络短视频特征分类性能对比Table 2 Performance comparison of micro-video feature classification in different networks
4 结 论
1)针对目前短视频分类任务中遇到的主要问题,本文提出了一种基于深度多模态特征融合的短视频分类算法,通过建立相似性损失和差异性损失,探寻短视频中不同模态之间的相似性和同一模态的差异性,将视频的特征空间划分为视觉模态和音频模态的公有域,视觉模态的私有域和音频模态的私有域,获取到视频的不同模态的私有域特征和公有域特征,将其融合作为短视频的全局特征,用分类损失指导短视频的分类。
2)在公开数据集上的大量实验表明,本文提出的算法成功地获取到了视频的不同模态信息在特征空间内的相似性表示和差异性表示,有效地降低了短视频多模态特征融合时的冗余性,提高了短视频分类的准确性,较好地解决了短视频的分类问题。
