基于注意力机制的跨分辨率行人重识别
2021-04-13廖华年徐新
廖华年,徐新,2,3,*
(1.武汉科技大学 计算机科学与技术学院,武汉430065;2.武汉科技大学 智能信息处理与实时工业系统湖北省重点实验室,武汉430065;3.武汉大学 深圳研究院,深圳518000)
随着平安城市、雪亮工程、天网工程的推进,视频监控系统得到了发展和普及的同时,视频侦查技术也进入了广泛运用阶段,利用视频智能分析技术,自动地从海量监控数据中对特定的行人目标进行检索、分析、比对的方式正在逐渐取代人工判别。行人重识别[1](person Re-identification,Re-ID)作为智能视频侦查的关键技术之一,在实际应用方面对于预防犯罪、嫌犯追踪和治安管理都具有积极作用。
行人重识别旨在匹配不同监控摄像头视图下相同身份类信息图像,它不仅需要解决同一摄像头下的行人遮挡、姿势、角度、光线等问题,还需注意到不同摄像头之间存在的摄像头规格不同。无约束的成像条件给行人重识别带来了一定的挑战,大多数现有的行人重识别方法都假设查询图像和图库图像具有相似且足够高的分辨率。然而,由于摄像头和行人之间的距离不受约束且不同摄像头之间的参数可能不同,导致行人图像往往具有不同的分辨率,这种分辨率不匹配问题给行人重识别带来了困难。与高分辨率(High Resolution,HR)图像相比,低分辨率(Low Resolution,LR)图像包含的身份细节要少得多,直接跨分辨率匹配图像对将导致性能显著下降。
为了解决分辨率不匹配问题,许多研究者开展了低分辨率行人重识别的研究[2-3],但性能提升不大。随着深度学习的不断发展,引入深度学习概念后的跨分辨率行人重识别任务[4-9]取得了较大的进步。早期的工作主要是通过建立高分辨率图像与低分辨率图像特征之间的映射关系来解决跨分辨率的匹配问题,Jing等[2]设计了一种半耦合低秩字典学习方法构建高低分辨率之间的联系;Li等[3]则是先假设同一行人的不同图像在某个特征空间具有相似的结构,从而得到一个跨分辨率图像对齐网络,将高、低分辨率关系引入到距离度量方法中。但是在无约束的成像条件下,行人图像分辨率是不同且多样的,无法一一对应,查询图像与检索图像分辨率比例并不是一个固定的值,在实际场景中,多个行人图像对之间的分辨率比例多样,早期工作中提出的方法并不适用。
受上述工作的启发,Jiao等[4]提出的图像超分辨率(Super-Resolution,SR)和行人身份识别联合学习方法,通过2、3、4三个尺度的超分辨网络,恢复对应尺度的低分辨率行人图像中对身份识别有效的高频外表信息,解决低分辨率行人重识别问题。Wang等[5]提出将2、4、8三个尺度的超分辨网络级联起来,通过逐步恢复低分辨率图像细节信息,最后与图库图像进行距离度量。尽管这些方法在跨分辨率行人重识别上取得了一定的效果,但这些方法都需要预先定义图像对之间的尺度比例,再通过与之适配的放大因子模块进行图像超分辨率重建工作。
与上述工作不同,受人类视觉注意力机制(Attention mechanism,Attention)[13]的影响,本文提出了基于注意力机制的局部超分辨率联合身份学习网络解决上述问题。具体来说,Attention的目的是辅助网络找到更利于识别的局部,但是即使是同一行人的不同分辨率图像的显著区域也会有一定的差异,因此提出了一个基于注意力机制的跨分辨率行人重识别方法,首先查询图像输入到由编码解码网络组成的Attention网络,目的是得到唯一的且利于识别任务的注意力图;然后通过核动态上采样的方法[14],任意尺度的重建低分辨率图像;最后经过行人重识别网络得到分类结果。本文主要贡献如下:
1)提出了基于通道和空间注意力机制的跨分辨率行人重识别方法。该方法主要意图在通过关注和比较不同分辨率行人图像对相同位置的显著区域,然后利用自编码网络的学习,得到任意分辨率行人图像的利于识别的局部区域。
2)使用任意上采样因子的跨分辨率重识别方法,使得网络能够处理任意低分辨率的查询图像的重建。经过注意力机制得到的局部区域能够被重建到与图库图像同一分辨率。
1 相关工作
由于在真实场景下,背景[15]、姿态、照明[16]、视角、相机[17]等条件变化很大,在无约束的成像条件下,人的图像分辨率的变化可能是最常见的,匹配不同分辨率的行人样本需要行人重识别算法关注不同的视觉特征。例如,图1展示了某商场不同摄像头下的行人图像,在高分辨率的图像样本中,可以通过发型或者衣服标志来区分不同行人,如C分别与A、D进行匹配,可以得出A和C是同一行人,D为不同行人。但在低分辨率图像样本中人眼都无法观察到这些细节,比如B难以判定和A、C是否为同一行人,对于机器而言这些用于区分行人的标识在低分辨率图像中是不可用的,ReID方法需要借助于剪影或全局纹理来进行可靠的匹配。而且,同一个人的高分辨率和低分辨率样本的差异甚至可能比不同人在相似分辨率下的样本差异更大。因此,需要对ReID方法进行专门的处理,以处理人物图像的跨分辨率变化。
解决行人重识别方向中的分辨率问题,最简单的方法是使用更大的数据集覆盖尽可能多的分辨率比例,从而构建高低分辨率之间的关系,但是这需要大量的数据和标注,且难以罗列出所有的分辨率比例场景。
1.1 学习低、高分辨率图像的关系

图1 跨分辨率行人图像Fig.1 Cross-resolution pedestrian image
早期的工作主要是学习低、高分辨率图像之间的映射关系。2015年,Jing等[2]使用字典学习的方法学习低、高分辨率图像之间的映射函数,通过得到的映射函数实现1/8尺度(低分辨率、高分辨率图像分辨率比为1∶8)的LR图像与HR图像之间的转换;Li等[3]通过寻找给定的1/4尺度的低、高分辨率图像在某特征空间中的对齐关系计算图像对之间的距离,从而判断是否为同一行人,这种做法必须满足同一行人的不同图像应该在某个特征空间具有相似的结构这一假设;Wang等[6]提出了将尺度渐变曲线投影到特征空间分类,解决多低分辨率行人重识别问题;Chen等[7]通过对低、高分辨率图像的特征分布进行对齐,解决跨分辨率行人重识别问题。但这几种方法只涉及到粗糙的外观信息和身份信息,丰富的高分辨率图像的细粒度细节在学习过程中被丢弃了。
1.2 级联图像超分辨率
利用图像超分辨率可以恢复图像信息,解决细粒度区别信息丢失的问题。Jiao等[4]提出了超分辨率和行人身份识别联合学习方法,能够通过增强低分辨率行人图像中对身份识别有用处的高频外表信息解决低分辨率行人重识别问题中的由于分辨率不同带来的信息量差异的问题。Wang等[5]提出了级联超分辨网络通过逐步恢复低分辨率图像细节再与图像检索库中的高分辨率图像匹配。Li等[8]在低分辨率图像和高分辨率图像中提取的特征表示上添加了一个对抗损失用来学习分辨率不变的表示,同时通过端到端的方式恢复低分辨率输入图像中缺失的细节。尽管这些方法带来了一些性能提升,但它们需要对预先定义的超分辨率模型进行培训,然而实际问题中查询和图库图像之间的分辨率差异通常是未知的,即无法预先定义图像对之间分辨率差异的倍数,并且梯度在这样一个级联的重模型[18]中反向传播的难度要大得多,因此这类方法存在模型训练效果不佳的问题,直接使用超分辨率模型不太适合ReID任务。
1.3 多任务学习
为了解决超分辨率任务和ReID任务之间模型效果训练不佳的问题,受到低分辨率人脸识别工作[9-10]的启发,Cheng等[11]提出了一个正则化方法将超分辨率、ReID任务联系起来,让超分辨率作为ReID任务的辅助任务,通过这种有效的结合训练方式解决训练不佳的问题。然而这种方法也是无差别的恢复低分辨率图像中缺失的信息,不仅使得超分辨率任务的计算量庞大,而且低分辨率图像中的部分不利于识别的信息被恢复也给行人匹配引入了干扰。Mao等[12]通过区分行人图像的前景和背景信息解决了此问题,但这种简单的划分行人为前景和其他物体为背景可能会丢失背景中的有用信息,比如路标、特色建筑、随身物品等。
针对以上问题,本文提出了基于注意力机制的跨分辨率行人重识别方法,利用空间、通道双重注意力机制的特性,得到查询图像中利于身份识别的局部区域,采用动态地预测上采样滤波器权重的方法解决任意放大因子的图像重建任务,精准获取行人图像中缺失的身份识别信息。
2 主要方法
许多前期工作在行人重识别网络前加入了图像超分辨率网络,以恢复低分辨率图像中的信息。这种方法可以通过对低分辨率图像的重建恢复高频细节,但是也放大了其他信息的干扰。受文献[19]的启发,本文提出基于注意力机制的局部跨分辨率联合身份学习网络,其网络架构主要由2部分组成:注意力模块和任意尺度超分辨率模块。通过一个自编码器,跳跃连接训练ID损失和注意力损失,逐步学习分辨率不变的特征,得到注意力模块融合得到的前景等显著区域信息,再通过任意尺度超分辨率模块对该部分进行重建,输出特征以此来计算交叉熵损失。
与文献[20]不同的是,本文首先利用编码解码网络学习分辨率不变特征,不同分辨率图像经过编码网络学习得到中间特征fc,经过解码网络得到特征F;然后将特征F输入到通道注意力模块中经过一系列操作得到权重系数和特征F′,特征F′输入到空间注意力模块中得到相应的权重系数和融合特征,即一个包含身份区分信息的局部特征图。网络结构模型如图2所示,本文将从2方面进行具体的阐述。
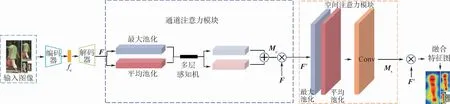
图2 注意力网络框架Fig.2 Framework of attention network
2.1 通道注意力机制
通道注意力的作用是得到有利于识别的特征信息,利用特征的通道间关系生成通道注意图。由于特征图的每个通道都被认为是特征检测器,通道的注意力都集中在对输入图像有意义的地方。为了有效地计算通道注意力,压缩了输入特征图的空间维数,对于空间信息的聚合,一般采用平均池法。具体的流程如图2所示,本文查询图像x首先会经过自编码器得到特征F,分别经过全局最大池化和全局平均池化,再经过多层感知机输出特征,进行向量相加操作,生成一个通道注意力图Mc,与做乘法操作的结果输入到空间注意力模块。Mc为
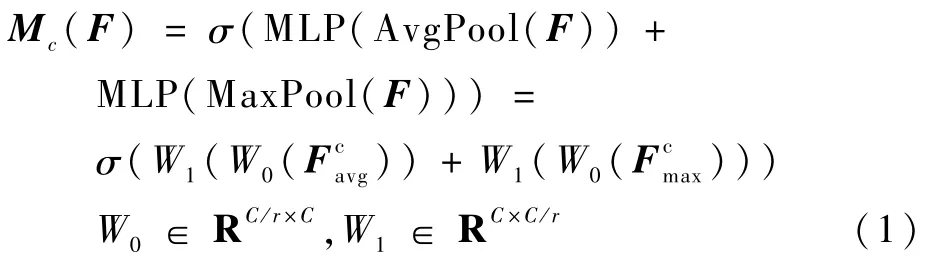
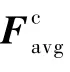
2.2 空间注意力机制
将通道注意力模块的输出特征图作为本模块的输入特征图。空间注意是通道注意的补充,如图2右侧所示,首先做一个基于通道的最大池化和平均池化,然后将结果基于通道做连接操作,通过一个卷积降维成单通道,最后激活生成空间特征Ms,并与本模块的输入特征做乘法,得到最终的生成特征。通过对通道注意特征的应用池化可以有效地突出显示信息区域[21]。Ms的计算方式为

式中:f表示在注意力模块的最后经过7×7的卷积操作。空间注意力机制的输出需要与整个模块输入的特征F做一个乘法操作,得到最后的融合特征图。
2.3 图像超分辨率
由于复杂的实际场景和无约束的成像条件,获取到的行人图像并不一定是相近的分辨率,往往获得的分辨率跨度比较大,因此无法预先定义一个尺度因子解决所有场景的图像重建问题。对于跨分辨率行人重识别而言,如何将任意分辨率的查询图像转换至与图库图像为同一分辨率是关键。受文献[22-24]启发,采用一个动态的上采样模块代替传统的放大模块[14],动态的预测上采样滤波器的权重,然后用这些权重生成高分辨率图像,即能够以任意的上采样因子放大任意的查询图像。
首先通过特征学习[25]模块提取到特征,对于超分辨率图像中的每一个像素,都是由查询图像在像素上的特征和对应的滤波器权重决定的。通过FLR和ISR之间的映射函数—上采样模块,得到最终的超分辨率图像。
上采样模块需要一个特定的卷积核或滤波器映射(i1,j1)和(i,j)的值,映射函数如下:
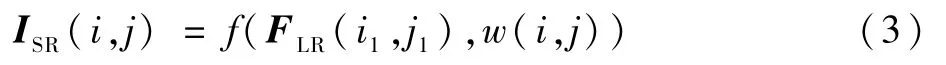
式中:ISR(i,j)为超分辨率图像在(i,j)的像素值;f(·)表示计算像素值的特征映射函数;w(i,j)为像素点(i,j)的权重预测模块(与式(5)相对应);FLR(i1,j1)表示在低分辨率图像中像素点(i1,j1)的特征向量。
对于超分辨率图像中的每个像素(i,j),可以通过一个投影转换函数T得到:
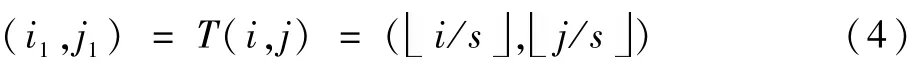
具体的可以看作一种可变步长机制,比如说当尺度因子s为2时,一个(i1,j1)像素决定超分辨率图像上的2个点。若尺度因子为非整数的1.5,则一些像素决定2个像素,一些像素决定一个像素。无论如何,每一个超分辨率图像上的像素都能找到一个(i1,j1)。
确定查询图像和超分辨率图像之间的位置关系后还需要得到两者之间特定的权重以及偏移量,可以通过如下公式得到:
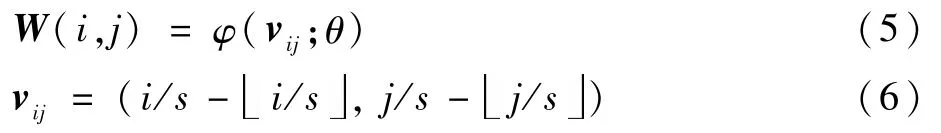
式中:W(i,j)为超分辨率图像上像素(i,j)对应的卷积核权重;vij为和(i,j)关联的向量;φ为权重预测网络;θ为权重预测网络的权重。
最后需要获取(i1,j1)像素点的像素值。其特征映射表述为
将输出的超分辨率图像与图库图像输入到基线网络[26]中得到最后的匹配结果。
3 实 验
3.1 实验环境和数据集
实验是在2块TITAN Xp GPU上进行的。该网络基于Pytorch框架,网络基本结构为Res-Net[26],基线网络参考了文献[12],并使用Adam优化器优化参数并将原始学习速率设置为10-3。通过3种主流的数据集对本文方法进行评价:Market1501[27]、CUHK03[28-29]和CAVIAR[30]。首先对这3个数据集以及相应评价标准进行说明。
MLRMarket1501:数据集包括了来自6个不同摄像机拍摄的1 501个行人。使用了DPM方法,将视频中的行人裁剪出来。数据集划分为训练集和测试集,其中训练集有751人,共12 936张图片;测试集有750人,查询图像3 368张,图库图像19 732张。然而该数据集所有图像分辨率被处理至统一的大小128×64。因此通过下采样的方法将数据集中的图像处理为原尺度的1、1/2、1/4、1/8、1/16五种尺度。
MLRCUHK03:在实验中采用了新的数据集协议,新协议将CUHK03数据集分为类似于Market1501的划分方法,将来自10个摄像头的1 467个行,划分为由767个身份和700个身份组成的训练集和测试集。数据集提供2种标注:第1种是人类手工标注行人框,第2种是通过DPM方法检测得到行人框。虽然数据集中图像分辨率是多样的,但分辨率跨度不大,且其中尺度较低的图像相较于低分辨率数据集分辨率偏高,因此通过下采样的方法将数据集中的图像处理至原尺度的1、1/2、1/4、1/8、1/16五种尺度。
CAVIAR:数据集包含由2台摄像机捕获的72个身份的1 220张图像。丢弃了22个只出现在相机中的人,将剩下的人分成2部分,这2部分的身份标签没有重叠。
3.2 结果分析
在本文实验中,为了评价Re-ID的方法,计算出所有候选数据集的累积匹配曲线[27](Cumulative Matching Characteristics,CMC)的Rank1和Rank5。表1和表2展示了本文方法与主流的跨分辨率行人重识别方法在3个数据集上的实验结果对比。表中最佳的2个结果分别用加粗和下划线形式突出显示。
在Market1501数据集上,本文方法和其他主流方法的定量结果对比如表1所示。对比近年来效果较好的行人重识别方法[31],以及大部分跨分辨率行人重识别方法,其中INTACT为近年来处理跨分辨率行人重识别问题的性能最优的方法,该方法为基于多任务学习的方法,通过正则化改进方法,使得模型训练更简单,其Rank1和Rank5分别为88.1%和95.0%,而本文方法获得了90.2%和94.3%,Rank1准确率提高了2.1%,优于前面对比的方法。除了客观数据的对比,还在Market1501数据集上分别进行了实验,由图3可以看出RIPR[12]中几个不匹配样本的例子,使用本文方法得到了解决。图3中三角标“△”是指不匹配的样本,“1”、“2”和“3”对应于前3个检索到的图库样本。

表1 现有方法在Market1501和CUHK03数据集上的定量结果对比Table 1 Quantitative r esult comparison of existing methods on Market1501和CUHK 03 datasets%
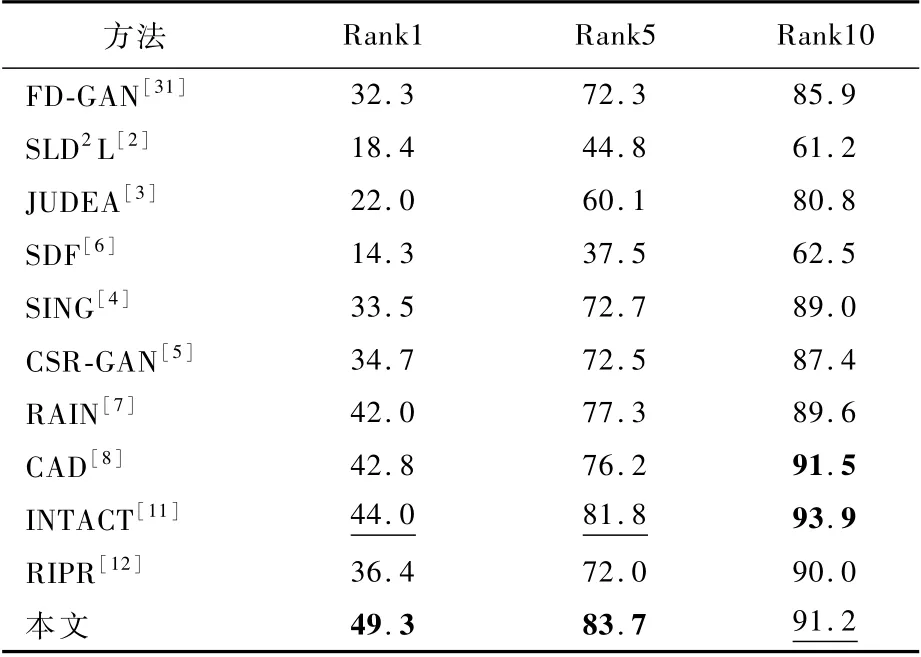
表2 现有方法在CAVIAR数据集上的定量结果对比Table 2 Quantitative result comparison of existing methods on CAVIAR dataset %

图3 各模型主观性能对比Fig.3 Subjective performance comparison of various models
在CUHK03数据集上,本文方法使用了新的CUHK03协议[29]进行训练,由于CUHK03数据集更接近真实情况,图像是来自于几个月来录制的一系列视频,无约束的成像条件也导致了图像分辨率的多样性。因此本文方法在此数据集上取得了比MLRMarket1501数据集更大的进步。同基于局部超分辨率RIPR[12]方法对比,本文方法Rank1提高了15.9%,进一步说明了只恢复前景区域会丢失背景中有利于识别的信息。相较于性能最优的INTACT方法Rank1和Rank5分别提高了2.8%和0.1%。这些数据都证明了本文方法对在跨分辨率场景的有效性。
CAVIAR数据集是早期行人重识别主流数据集,由于早期的摄像头性能较差,且摄像头分布并不密集,采集数据也比较困难,数据集内图像数量较少,且质量较差,一般的行人重识别方法在这一真实的数据集上性能很差。因此本文方法在此数据集上取得了比上述数据集更大的进步:①同基于单一低分辨率的方法SLD2L、JUDEA对比,本文方法Rank1提高了30.9%和27.3%,体现了任意上采样因子的超分辨率重建在跨分辨行人重识别方法中的优越效果;②与基于级联超分辨率的方法CSR-GAN、SING相比,本文方法Rank1提升了14.6%和15.8%,进一步说明了任意上采样因子的超分辨率重建和级联超分辨率重建相比的有效性;③CAD是基于分辨率不变表示的方法,可以处理未训练过的尺度,本文方法在Rank1上也提高了6.5%,这有力地证明了基于注意力机制的方法和任意尺度因子的超分辨率重建相结合应用于行人重识别方法上对于跨分辨率问题的有效性。
3.3 消融实验
为了验证本文方法的注意力模块和图像超分辨率模块在跨分辨率行人重识别问题上的有效性,采用不同的模型参数进行训练,使用单一查询模式在CUHK03数据集上进行实验。如表3所示,ResNet50为基线模型,CAM 为通道注意力模块,SAM 为 空 间 注 意 力 模 块,Non-Local[32]、SENet[20]是常用于图像分类领域的2个易于集成的注意力模块,对于图像分类有一定的作用,MASR表示任意放大因子的图像超分辨模块。所有的实验均只改变了一个设置,其余设置与本文方法的设置相同。
首先,通过表3中不同注意力模块的性能对比验证通道注意力模块和空间注意力模块联合作用的有效性,单独使用通道注意力模块或者空间注意力模块,都显著地提高了跨分辨率行人重识别的性能,当它们联合使用时Rank1比主流的注意力机制Non-Local、SENet分别提升了8.2%、7.6%。同时,由于空间注意力机制将图像中的空间域信息做对应的空间变换并保留关键信息,进一步挖掘了图像中显著且关键的区域,相比于通道注意力机制更有助于模型鲁棒性的提高,对于模型性能有更加显著的提升。
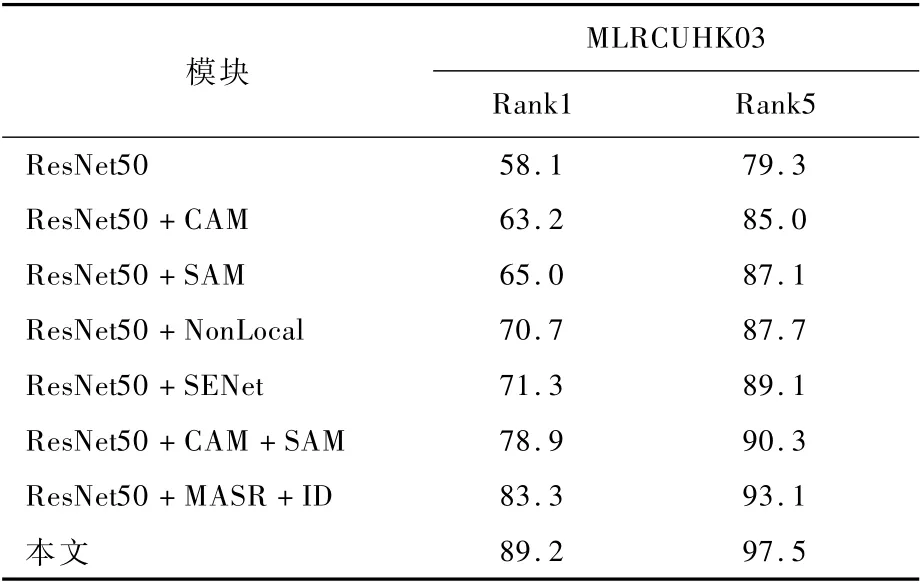
表3 各模块消融实验结果Table 3 Ablation experimental r esults of each module%
4 结束语
本文提出了一个用于跨分辨率行人重识别的方法。使用基于通道注意力机制和空间注意力机制相融合的方法来获取更利于识别的特征和区域,同时解决了不同分辨率查询图像关注区域不同的问题。网络中任意上采样模块在超分辨率重建上的应用极其有力地解决了图像信息恢复过程中由于分辨率多样性导致的网络级联训练困难、计算量大、模型复杂等问题,从而使本文方法适用于更广泛的场景。这2个互补的模块被联合训练来优化行人重识别方法,在3个公开的数据集上与大量先进方法对比取得了最优或次优的效果,充分证明了本文引入的模块的有效性。
