基于Apriori算法的高职院校毕业生就业情况分析
2021-04-11罗明全
罗明全
(泸州职业技术学院,四川泸州 646000)
1 引言
目前,随着信息化建设的不断深入,各高职院校存储了大量、复杂的毕业生成绩和就业信息数据,如何从中挖掘出有价值的信息,成为高职院校的重要研究课题。本文对泸州职业技术学院信息工程学院近5届毕业生在校成绩和就业相关数据进行挖掘分析,获得一批可以为人才培养方案修订和就业指导工作开展提供决策依据的有价值信息。
2 数据挖掘及关联规则的基本概念
从海量数据中挖掘出潜在、有用知识的过程被称为知识发现(KDD),在这个过程中,数据挖掘(Data Mining)是至关重要的一环。数据挖掘是利用特定算法,自动或半自动地发现有意义的数据模式。
关联规则(Association Rule)是数据挖掘的一个重要技术,其目标是发现数据项集之间的关联关系或相关关系。关联规则挖掘的一个典型例子是购物篮分析,通过分析“购物篮”哪些商品频繁地被顾客同时购买,发现不同商品之间的关联,得出顾客的购物习惯,从而帮助零售商调整商品货架布局以及开发更好的营销策略[1]。
关联规则是形如X Y的蕴涵式,其中X为关联规则的先导,Y为关联规则的后继,以下为关联规则的几个重要概念。
(1)事务
一个数据实例表视为一个数据集,每一条记录为一个事务,使用D表示数据集,|D|表示数据集中事务数。
(2)项集与频繁项集
一个数据表中,每个属性字段具有一个或多个不同的值,每个取值称为项,这些项的集合称为项集,k-项集指包含k个项的项集,记为Lk。

(3)关联规则支持度与置信度

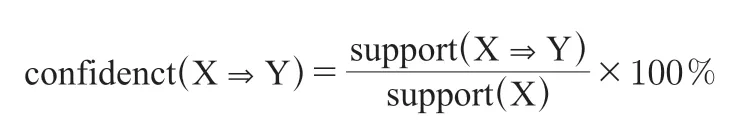
(4)强关联规则
在数据挖掘中,为衡量关联规则在整个数据集中的统计重要性和关联规则的可信程度,需要设置最小支持度阈值min_sup和最小置信度阈值min_conf。

3 Apriori算法实现
Apriori算法是一种常用于挖掘数据关联规则的算法,使用该算法可筛选出满足强关联规则的频繁项集,Apriori算法主要由两个阶段构成:提取频项集和产生强关联规则。
(1)Apriori算法流程
以高职院校毕业生在校表现及就业信息数据挖掘为例,Apriori算法流程如下。
输入:毕业生在校成绩及就业信息数据集D、最小支持度min_sup、最小置信度min_conf。
输出:毕业生在校成绩与就业的关联规则。
Step1:扫描数据集,统计k=1项集及其支持度support(X),比较support(X)与min_sup,若support(X)≥min_sup,则X为频繁1-项集L1。
Step2:判断频繁k-项集Lk是否为空,为空则转到Step6,否则转到Step3。
Step3:将频繁k-项集连接,产生候选(k+1)-项集Ck+1。
Step4:扫描原始数据集,计算出每个候选项集c的支持度support(c),若support(c)≥min_sup,则c属于频繁(k+1)-项集,否则为不满足条件的候选项应删除,产生频繁(k+1)-项集Lk+1。
Step5:k=k+1,返回Step2。
Step6:计算频繁项集L=∪kLk。
Step7:比较频繁项集L中的频繁项与min_conf,得出毕业生在校表现与就业之间的强关联规则。
(2)Apriori算法程序实现
本文使用PHP作为程序开发语言,Apriori类成员如下:



4 基于Apriori算法的数据挖掘应用
本文所使用的数据是泸州职业技术学院信息工程学院近5届毕业生在校期间课程成绩和就业信息数据,课程成绩包括毕业生在校期间每学期各科目成绩和综合素质测评成绩,就业信息数据包括毕业去向、单位性质、工作职位类别等[2]。
4.1 数据预处理
在数据挖掘之前,对数据进行预处理,主要包括以下内容。
(1)数据变换与集成:由于不同专业课程存在差别,通过属性与属性的连接构造新属性用于后续的数据挖掘计算,毕业生各学期英语、高数成绩的算术平均值构造为“文化课程”新属性,专业课程成绩的算术平均值构造为“专业课程”新属性,各学期的综合素质测评成绩的算术平均值构造为“综合素质”新属性。以学号为唯一字段,将教务系统和就业管理系统的数据结合起来并统一存储。
(2)冗余数据和缺失的处理:数据集成后,不避免出现冗余数据,如学号、年级、性别等,所有冗余数据全部删除,可节约内存并提高运算效率。个别毕业生毕业时未就业或未填报就业数据,致使毕业去向、单位性质、工作职位类别等数据项缺失,处理方式为一律舍弃。
(3)数值数据离散化处理:毕业生的成绩数据均为数量属性,我们将各成绩属性离散化处理,对文化课程、专业课程、综合素质成绩采用统一的量化标准,分为良好和一般两个等级,85分及以上为良好,值使用1表示,低于85分为一般,值使用0表示。
4.2 关联规则挖掘
将经数据预处理后的数据存入数据库中,使用Apriori算法的挖掘程序,我们设置min_sup=5%,min_conf=60%,搜素数据库,得到强关联规则如下所示。
(1)专业成绩(良好)→就业行业(信息传输、计算机服务和软件业),support=41.2%,confidence=80.5%。
(2)专业成绩(一般)∩综合素质(良好)→职位类别(商业和服务业),support=6.3%,confidence=71.4%。
(3)文化成绩(良好)→就业方向(专升本),support=5.2%,confidence=63.1%,同时就业方向(专升本) →文化成绩(良好),confidence=87.4%。
4.3 关联规则分析
规则1表明,在校期间专业成绩好的毕业生就业行业为IT行业,一定程度上表明,现开设的专业课程较为合理。
规则2表明,专业成绩一般但综合素质较强的毕业生偏好从事商业和服务业工作。
规则3表明,文化成绩达到良好的毕业生偏好专升本,同时,大多数专升本成功的毕业生在校期间文化成绩达到良好水平。
5 结语
本文利用关联规则及Apriori算法对毕业生在校期间各项成绩和就业数据进行了挖掘和分析,分析得出:高职学生的毕业去向与在校期间的学习和表现存在较大的关联性。在就业指导中,根据学生在校表现情况,指导学生正确自我认知,确定合适的就业目标,同时向招聘单位进行精准的人才推荐,进一步提高就业率,促进优质就业。
