深度学习的二维人体姿态估计综述
2021-04-11刘紫琴曾凡智周月霞陈嘉文
周 燕,刘紫琴,曾凡智,周月霞,陈嘉文,罗 粤
佛山科学技术学院计算机系,广东佛山 528000
人体姿态估计是指标注图片或者视频中人体关节点的位置,并对关节点进行最优连接的过程。人体姿态估计可广泛地应用在动作识别[1-2]、人机交互[3]、智能跟踪[4-5]等领域,已成为计算机视觉领域的研究热点之一。人体姿态的多样性、环境的复杂性以及视角的不定性等因素,使人体姿态估计面临着巨大的挑战,受到众多学者的密切关注。
在深度学习应用于人体姿态估计之前,大多采用基于图形结构[6-7]的方法来处理人体姿态问题。因此,基于图形结构方法的可形变部件模型[8-9]应运而生,这些方法需要采用局部检测器,只能为人体关节点之间所有联系中的部分子集建立模型,虽然获得了较高的效率,但受人物遮挡、拍摄角度、图像光照等因素影响较大,表示能力有限。此外,这种传统的方法在特征提取上依赖于人工设定的特征,例如方向梯度直方图(histogram of oriented gradient,HOG)[10]、尺度不变特征转换(scale invariant feature transform,SIFT)[11]、边缘[12]特征等,需耗费大量的人工、时间与精力。
随着人工智能技术的发展,众多深度学习模型被提出,例如卷积神经网络、生成对抗网络、自动编码器、递归神经网络等,这些模型在图像处理领域中取得了比传统非深度学习方法更优越的成绩,在图像分割、目标检测、图像识别等领域取得了显著的成果。近年来,国内外学者们提出了大量的人体姿态估计方法,并给出了一些公开的人体姿态估计数据集,因此利用基于深度学习的方法进行人体姿态估计已成为主要的研究方向。
基于深度学习的人体姿态估计方法可充分地提取图像信息,采用深度神经网络提取更准确的特征,获取人体所有关节点间的联系。这种方法不需要局部检测器以及人工设计特征,不需要设计模型的拓扑结构与关节点间的交互,利用神经网络在定位与分类上的突出表现,获取更精确的人体关节点位置。
二维的人体姿态估计作为描述人体姿态以及识别人体行为的基础,二维人体关节点坐标与骨骼信息可直接影响三维人体姿态估计的结果。本文将二维人体姿态估计主要分为单人姿态估计与多人姿态估计两种,对算法进行梳理与分析。
1 单人姿态估计
单人姿态估计可以看作是给定人数,确定人物位置的关节点定位问题,只需对图像中给定的单人进行关节点的定位。单人姿态估计算法在训练模型时往往采用有监督的训练方法,因此按照真值(ground truth)的类型不同可将基于深度学习的单人姿态估计方法分为基于坐标回归以及基于热图检测。
1.1 基于坐标回归
基于坐标回归的单人姿态估计算法通过提取图像特证,直接得到人体关节点的坐标信息。其根据不同的姿态表示主要分为关节点表示与骨骼表示,其中采用关节点作为姿态表示的方法主要分为多阶段直接回归与迭代误差反馈两类,具体分类如图1所示。
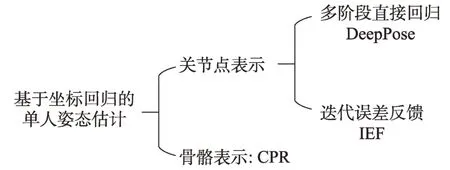
Fig.1 Classification of coordinate based regression for single-person pose estimation图1 基于坐标回归的单人姿态估计分类
1.1.1 关节点姿态表示
Toshev 等人[13]提出DeepPose 算法,将深度学习应用到人体姿态估计,将姿态估计表述为关节点直接回归的问题。在初始阶段,采用深度神经网络(deep neural networks,DNN)[14],基于全图像上下文粗略推测出关节点的位置,但其在细节表现方面的能力有限;随后训练额外的DNN 回归量来预测关节点位置从前一阶段到其真实位置的位移,裁剪出所预测关节点邻域的局部图像作为下阶段回归的输入,在保持输入图像大小不变且计算参数不增多的情况下,设计级联姿态回归器以获得精度更高的关节点位置,其网络如图2 所示。
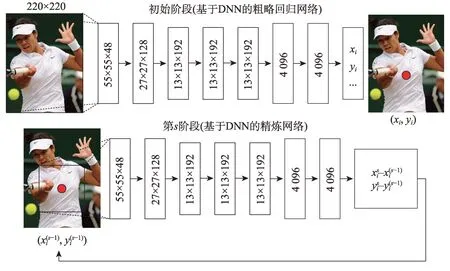
Fig.2 Network architecture of DeepPose图2 DeepPose网络架构图
多阶段直接回归方法虽然可以学习输入空间的丰富表示,但无法在输出空间对依赖关系进行显示的建模。人体存在部分肢体比例相互约束,身体左右对称,关节限制(如肘部不能向后弯曲)等特征,二维人体姿态是复杂且高度结构化的。Carreira 等人[15]基于GoogleNet[16]提出了一个迭代误差反馈框架(iterative error feedback,IEF),引入自上而下的反馈,将分层特征提取器的表达能力扩展到输入和输出空间,并不是直接预测输出结果,而是预测当前估算值的偏移量并进行迭代校正;对人体结构关系建模,更容易地确定可见的关节点,并估计被遮挡的关节点,迭代误差反馈框架如图3 所示。
1.1.2 骨骼姿态表示
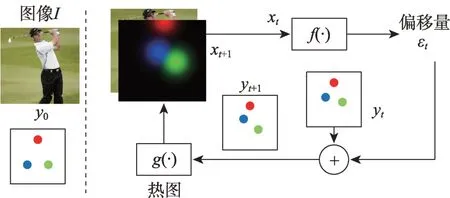
Fig.3 Framework of iterative error feedback图3 IEF 迭代误差反馈框架
在以上基于回归的工作中,大多只简单地降低每个关节点位置的误差,忽略了姿态的内部结构,导致关节点间的依赖性没有被很好利用,骨骼信息相较于关节点更原始与稳定,且更容易学习。Sun 等人[17]提出了一个结构感知的回归方法(compositional pose regression,CPR),采用一种重新参数化的骨骼姿态来代替关节点,利用关节的连接结构定义一个组合的损失函数对骨骼之间的相互依赖关系进行编码,这种方法不仅适用于人体二维姿态估计,更可推广到人体三维姿态估计。
总体而言,这种直接从输入的RGB 图像回归坐标位置的映射是高度非线性且缺乏鲁棒性的,在人体二维姿态估计的工作中,更多用到基于热图检测的方法。
1.2 基于热图检测
基于热图检测则先获取人体关节点热图,其像素值表示该关节点在此位置的概率,再获取关节点定位信息。基于热图检测的单人姿态估计方法主要分为三大类:引入人体结构先验、设计网络结构、引入时间约束。具体分类如图4 所示。
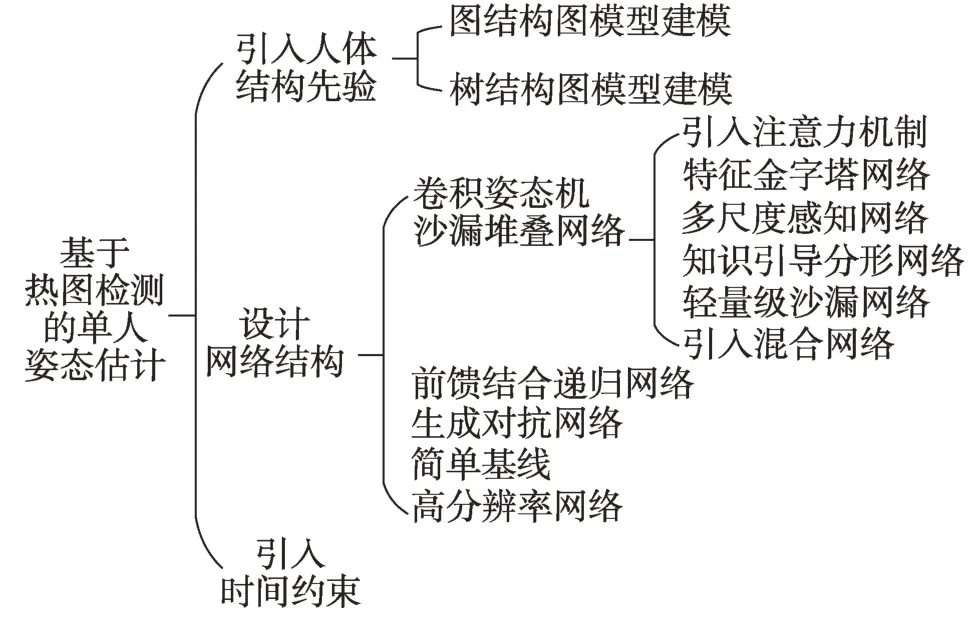
Fig.4 Classification of heat map detection for single-person pose estimation图4 基于热图检测的单人姿态估计分类
1.2.1 引入人体结构先验
Tompson 等人[18]采用深度卷积网络与图形结构模型相结合的方式,提出由深度卷积网络与马尔科夫随机场(Markov random field,MRF)[19]组成的混合模型。第一阶段是基于卷积神经网络的人体关节点定位,采用重叠的感受野以及多分辨率输入,尽可能地减少网络冗余,输出关节点热图;通过验证集发现存在许多假阳性的关节点热图以及不符合人体解剖学的姿态。在第二阶段,采用改进的马尔科夫随机场空间模型来约束关节点的相互联系,每个关节点都以与其他关节成对的方式来创建全连接图。最后,将第一阶段的关节热图检测器与第二阶段的空间模型合并到统一的模型中,先训练关节检测器并存储输出的热图,再使用这些热图来训练空间模型,最后将训练好的关节检测器与空间模型相结合对整个网络进行反向传播。然而传统的卷积神经网络包括池化层与子采样层,虽可以减少计算量,并引入不变性防止过度训练,但也降低了定位的精度。为此,Tompson 等人做了相应的改进[20],对卷积神经网络使用增加的池化量来提高计算效率,可以在不增加大量计算的情况下获得较高的空间精度。Isack 等人[21]提出轻量化姿态估计模型RePose,采用类似于传统的基于部件模型的方法,引入人体运动学结构约束;采用端到端的训练方式学习几何先验,通过传播低分辨率的卷积特征来更新细化关节点或身体部位姿态信息。
由于结合马尔科夫随机场的网络卷积核较大,训练规模大,Yang 等人[22]采用树结构图模型对人体关节点间联系进行建模,以简化图结构网络。基于条件随机场(conditional random field,CRF)[23]构建的树状模型,采用混合训练模型,结合深度卷积网络与树型结构模型进行端到端的训练。
1.2.2 设计网络结构
(1)卷积位姿机。Wei 等人[24]提出了一种基于序列化的网络结构卷积位姿机(convolutional pose machines,CPM),网络如图5 所示。以Pose Machines[25]算法作为基础,通过卷积架构的顺序组合学习隐式空间模型,设计和训练这种架构以系统学习图像特征和图像相关空间模型以进行结构化预测;CPM 的每个阶段以上一阶段生成的图像特征和置信图作为输入,置信图为后续阶段每个关节点的位置空间不确定性提供了可表达的非参数编码,从而使CPM 可以学习丰富的隐式空间模型;根据计算每阶段置信图以及标签的损失更新该阶段的参数,来加强中间监督以解决训练中梯度消失的问题。
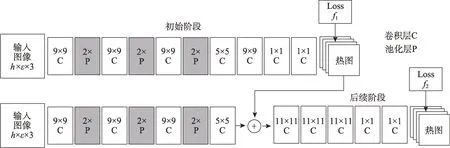
Fig.5 Network architecture of convolutional pose machines图5 CPM 网络架构图
(2)沙漏堆叠网络。与CPM 的顺序卷积结构不同,Newell等人[26]提出了一种基于编码器和解码器的堆叠沙漏新型卷积网络结构(stacked hourglass networks,SNH),如图6 所示。堆叠前的沙漏模块如全卷积网络(fully convolutional networks,FCN)[27],包含若干残差模块[28],可以在多个分辨率上处理空间信息以进行关节点预测;将多个沙漏堆叠,前一个的输出作为后一个的输入,将重复的自底向上(从高分辨率到低分辨率)、自顶向下(从低分辨率到高分辨率)的处理与中间监督相结合,能够重新评估整个图像的初始估计和特征,以提高网络的性能。
此外,还有许多基于沙漏堆叠网络做出改进的工作,Chu 等人[29]在沙漏堆叠的网络结构基础上,引入了注意力机制,将具有多上下文注意机制的卷积神经网络整合到端到端的人体姿态估计框架中,从多种分辨率的特征中生成热图,以此关注人体的整体一致性;利用条件随机域对热图中相邻关节点的关系进行建模,来关注身体不同部位的细节描述,进一步将人体的整体特征与身体部位特征结合起来;设计了新型的沙漏残差模块(hourglass residual units,HRUs)来增加网络的感受野,可以学习和组合具有不同分辨率的特征。
Yang 等人[30]基于沙漏堆叠网络设计了一个金字塔特征模块(pyramid residual module,PRMs)代替沙漏网络的残差模块,来提升深度卷积神经网络在尺度上的不变性;提出将当前权值初始化方案推广到多支路网络结构的理论推导。
Ke 等人[31]基于沙漏堆叠网络提出了一种用于人体姿态估计的多尺度结构感知神经网络(multi-scale structure-aware network,MSSA),采用多尺度监督网络(multi-scale supervision network,MSS-net)加强语义特征学习来融合多尺度的特征,并设计多尺度回归网络(multi-scale regression network,MSR-net)优化人体整体的结构,多尺度监督网络与多尺度回归网络都是利用结构感知损失从多尺度特征中学习人体骨架结构,针对复杂场景中恢复遮挡关节点时具有很强的先验性。
Ning 等人[32]提出一个知识引导的姿态分形网络,采用沙漏堆叠网络的思想和Inception-ResNet[33]模块构建分形网络,以捕获姿态模型中人体关节之间的多尺度依赖关系;在训练过程中,将传统的霍夫变换特征和梯度方向直方图作为先验知识引入到深度卷积神经网络中,以防止关节点的错误连接。
Zhang 等人[34]提出了一个快速姿态估计模型(fast pose distillation,FPD),构建轻量级的沙漏堆叠网络,将堆叠的沙漏模块数量减少一半,仅采用4 个沙漏模块,以降低网络复杂度;引用知识蒸馏的原理,预先训练好一个强大的教师姿态模型,如原始的沙漏堆叠网络,将潜在的知识从教师模型转移到轻量级网络中,以在计算预算有限的情况下提升模型性能。
Bulat 等人[35]提出结合沙漏堆叠网络与U-Net[36]的混合网络结构,以降低原始沙漏堆叠网络模型大小与复杂度;设计了一种门控机制来控制模块内每个通道的数据流,这种算法相较于原始沙漏堆叠网络速度提升两倍以上,且模型性能没有下降。
(3)前馈结合递归网络。Belagiannis 等人[37]提出了一种人体姿态估计的递归模型,将前馈模块与递归模块相结合,其中递归模块可以迭代地捕获上下文信息以提高性能,并可以以端到端、从零开始对模型进行训练,加入辅助损耗,提高关节点估计精度。
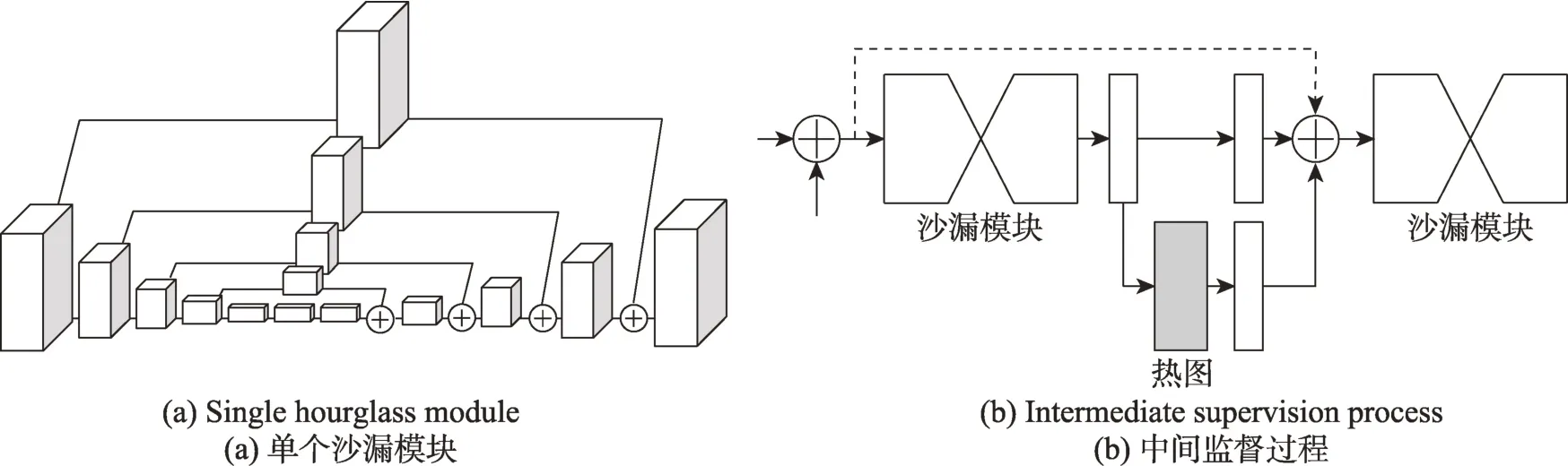
Fig.6 Architecture of stacked hourglass networks图6 堆叠沙漏网络结构
(4)生成对抗网络。Chen 等人[38]采用生成对抗网络(generative adversarial nets,GANs)策略[39],针对单目图像中人体关节点遮挡与人体重叠影响姿态估计准确性这一问题,结合人体骨架结构先验,提出了一种新的基于结构感知的卷积网络来隐式地在深度网络训练中考虑人体先验信息,设计一个堆叠的多任务网络来预测姿态热图和遮挡热图,以预测更真实的姿态;网络包括姿态生成器、姿态鉴别器和确信度鉴别器,姿态生成器由两个沙漏模块组成,共生成32 张热图,包括对16 个关节点的检测热图以及对应的遮挡预测,姿态鉴别器与确信度鉴别器用以区分不满足身体约束关节点。Chou 等人[40]也提出使用生成对抗的策略解决拥挤场所关节遮挡问题,网络同样包括姿态生成器与鉴别器,且都为一个沙漏网络,姿态生成器生成关节点热图,鉴别器采用热图与RGB 图像作为输入,并将其解码为一组新的热图,以区分真实的热图和虚假的热图。吴春梅等人[41]提出了深度卷积生成对抗模型(deep convolution generative adversarial network,DCGAN),对生成对抗网络的生成器与判别器结构进行了优化,基础结构也为沙漏网络,用以编码第一层次结构(亲本)与第二层次结构(子本)间的人体空间关系,采用残差模块与线性模块对沙漏网络的输入和输出进行预处理与后处理,获取置信度得分图;引入了新的损失函数来规范亲本与子本间的关系;设计分层对抗网络(hierarchical adversarial network,HAN)和层次感知损失以提高身体各个部位位置的估计精度。
(5)简单基线。Xiao 等人[42]提出简单的姿态估计基线(simple baselines),来降低算法的复杂度,在沙漏残差模块中加入几层反卷积,将低分辨率的特征图扩张为原图大小,以此预测关节点热图,网络如图7所示。
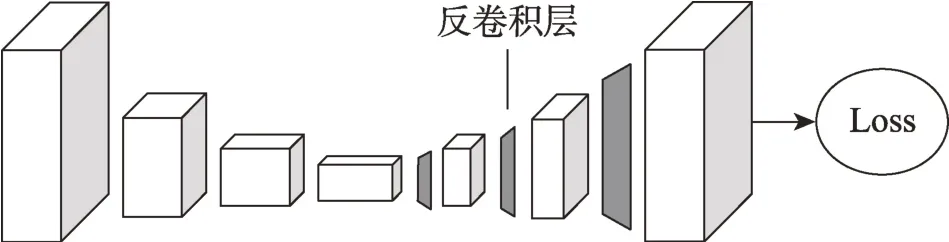
Fig.7 Network architecture of simple baselines图7 简单基线网络结构
(6)高分辨率网络。针对沙漏堆叠网络在处理过程中需要将低分辨率恢复到高分辨率,Sun 等人[43]于2019 年提出一个并行连接的高分辨率网络(highresolution networks,HRNet)来代替大多数现有的串联方案,如图8 所示。这种方法能够保持高分辨率,而不是通过从低到高的过程恢复分辨率,执行重复的多尺度融合以提升高分辨率表示。
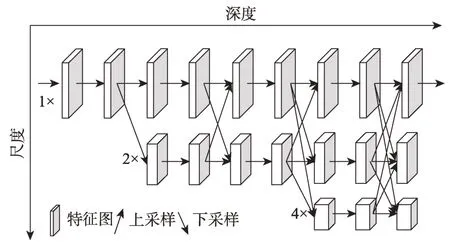
Fig.8 Architecture of high-resolution networks图8 高分辨率网络结构
1.2.3 引入时间约束
针对视频流的二维人体姿态估计,由于在时间相近的视频帧之间存在着很强的姿态位置依赖性,Pfister 等人[44]将光流思想[45]应用到二维姿态估计,输入视频当前帧与相邻帧,通过全卷积网络获取这些帧的关节点热图,采用光流来对齐相邻帧与当前帧的关节点预测热图;最后使用参数化合并层学习将相邻帧关节点热图合并为整体的置信度图。Luo 等人[46]结合长短期记忆网络(long short-term memory,LSTM)的思想[47],首先对多阶段的卷积神经网络施加权值共享方案,建立新的递归神经网络以加快视频调用网络的速度;采用LSTM 网络来学习视频帧间的时间依赖性,及时地捕捉关节的几何关系以提高关节点预测的稳定性。Artacho 等人[48]提出了人体姿态估计框架(unified human pose estimation,UniPose),基于“瀑布式”的空间池架构,结合多尺度特征表示与大视野(fields-of-view,FOV)以增大网络感受野,利用上下文信息预测关节点;采用LSTM 网络处理视频相邻帧,可将其扩展至视频的人体姿态估计。
总体而言,基于热图检测的方法可以很好地处理多模式的输出,在高精度区域也可保持较高的准确率,在二维姿态估计工作中更常用基于热图检测的方法,相关算法优缺点比较如表1 所示,其中引入时间约束的方法无分类展开,因此算法一栏处为空白。
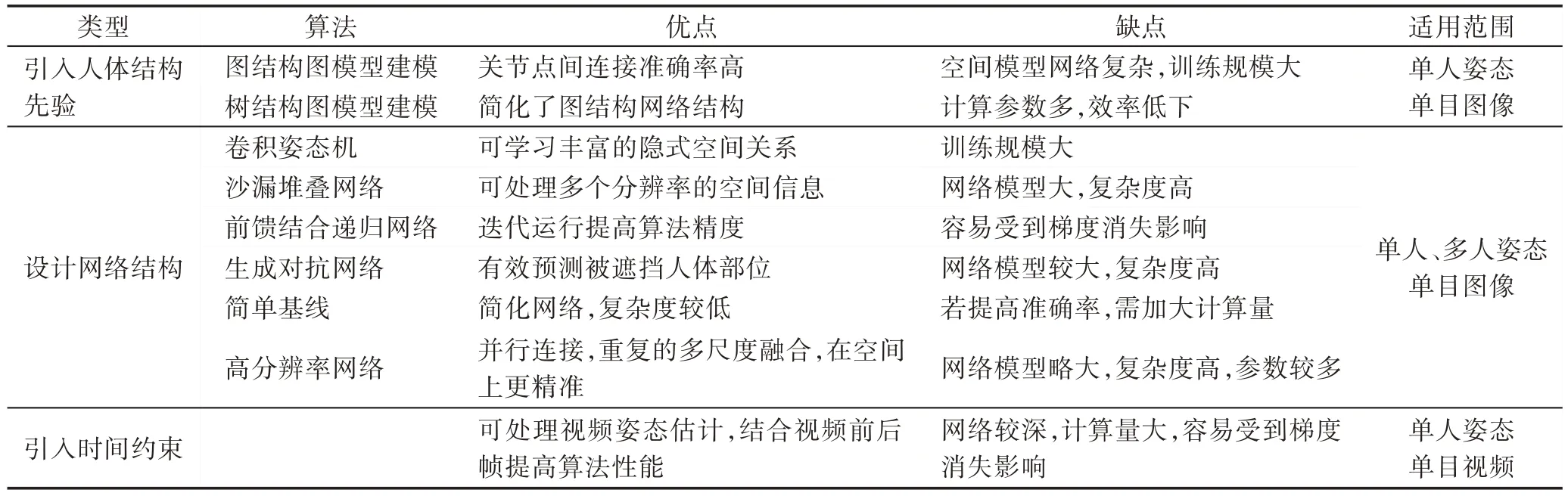
Table 1 Comparison of heat map based detection algorithms表1 基于热图检测算法对比

Table 2 Comparison of single-person pose estimation algorithms表2 单人姿态估计算法对比
1.3 小结
基于坐标回归与基于热图检测的方法各有优缺点,如表2 所示。由于基于坐标回归方法存在显著的局限性,缺乏鲁棒性,基于热图检测方法采用以关节点位置为中心的二维高斯分布表示关节点位置,具有较高的鲁棒性,仍是一种主流的方法。
2 多人姿态估计
基于深度学习的二维多人姿态估计,由于图像中人物的数量以及位置都是未知,需要完成检测与分组两种任务,相较于单人姿态估计任务难度更大。多人姿态估计根据算法步骤的不同主要可分为二步法(two-stage)和一步法(single-stage)两类。
2.1 二步法多人姿态估计
二步法的多人姿态估计采用两个步骤获取人体关节点,根据检测与分组步骤顺序的不同主要分为自顶向下(top-down)与自底向上(bottom-up)的两种方法,二步法的多人姿态估计具体分类如图9 所示。
2.1.1 自顶向下
自顶向下的方法主要有两部分构成:人体检测器与单人姿态估计器,首先采用检测器检测框出人体,再对框出的人体做类似单人姿态估计的操作,算法流程如图10 所示。
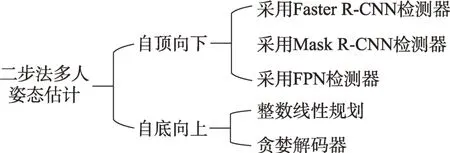
Fig.9 Classification of two-stage for multi-person pose estimation图9 二步法多人姿态估计分类
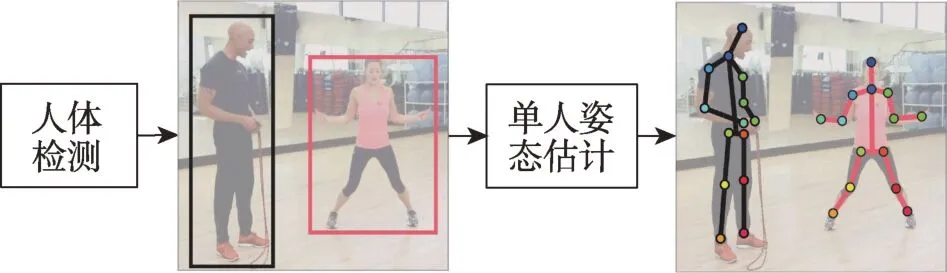
Fig.10 Flow chart of top-down图10 自顶向下算法流程
人体检测框的误检与冗余等可直接影响后续单人姿态估计效率,因此自顶向下的方法侧重于检测器的研究,常用的人体姿态检测器有Faster R-CNN(faster region-convolutional neural networks)[49]、Mask R-CNN(mask region-convolutional neural networks)[50]、特征金字塔网络(feature pyramid networks,FPN)[51]等,可结合不同的单人姿态估计算法。表3 列出各自顶向下算法人体检测器与单人姿态估计器的主网络。
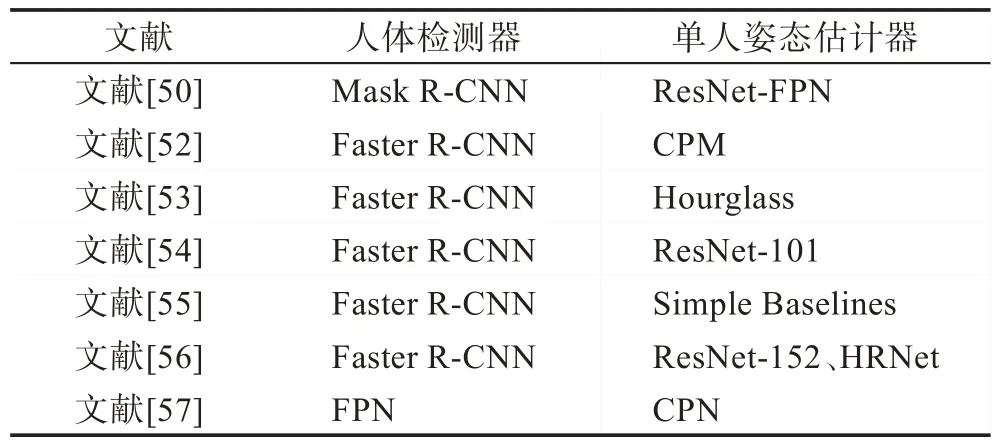
Table 3 Backbone networks of top-down methods表3 自顶向下算法主网络
(1)采用Faster R-CNN 人体检测器。Iqbal等人[52]采用Faster R-CNN 检测器,首先检测框出人体;再基于CPM 网络对人体框中人体进行单人姿态估计获取一组候选的关节点,对候选的关节点进行全连接,最后通过整数线性规划(integer linear programming,ILP)获得最终的关节点及其连接。
Fang 等人[53]提出了一个新的区域多人姿态估计框架(regional multi-person pose estimation,RMPE),首先采用Faster R-CNN 作为人体检测器,设计对称式变压器网络(symmetric spatial transformer network,SSTN)获取高精度的人体检测框以及参数式非极大抑制(non-maximum suppression,NMS)解决检测框冗余问题;基于沙漏堆叠网络进行单人姿态估计,设计姿态引导生成器(pose-guided proposals generator,PGPG)来增加训练样本。
Papandreou 等人[54]提出了一种简单而有效的自顶向下方法,在第一阶段,采用Faster R-CNN 检测器预测人体位置与大小,结合非极大抑制(NMS)与人体关节点相似度(object keypoint similarity,OKS)来减少人体框检测误差;第二阶段,基于ResNet-101 CNN[28]网络,首先对第一阶段检测出的人体框进行图像分割,将其调整为统一的长宽比及大小,再预测人体框中关节点热图和其偏移量,通过聚合热图和偏移量获得高精度的关节点预测。
Li等人[55]同样采用Faster R-CNN 检测器,基于简单基线单人姿态估计的思想,改进了RMPE,提出CrowdPose 以解决拥挤场景下的人体姿态估计问题,联合候选单人姿态估计,对目标关节点和干扰关节点设置不同的损失值,来对每个关节点进行多峰预测以在人体检测框不准确的情况下获取较准确的关节点;提出全局最大关节点关联,表示关节点间的连接关系与概率,这种方法对拥挤场景中不可避免的冲突具有较强的鲁棒性。
Zhang 等人[56]以Faster R-CNN 作为人体检测器,采用编解码器网络结构,设计了高效的级联上下文混合器(cascaded context mixer,CCM),可学习空间上下文信息以检测关节点;制定了三种有效的训练策略,提出了联合训练策略和知识提取的方法对大量未标记样本进行知识蒸馏,以及一种人体检测挖掘策略来迁移人体实例在训练和测试之间的不一致性;最后,制定了四种后处理:抛物线近似、非极大抑制Soft-NMS、对热图进行高斯滤波、对热图进行翻转操作,用以细化关节点的检测。
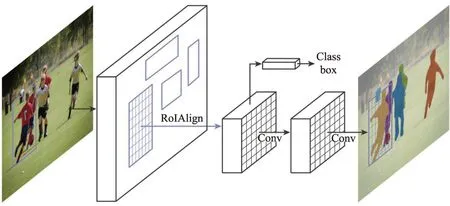
Fig.11 Mask R-CNN for instance segmentation图11 Mask R-CNN 的实例分割
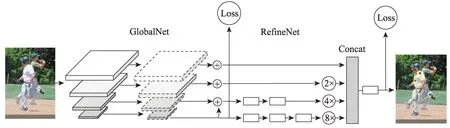
Fig.12 Architecture of cascaded pyramid network图12 级联金字塔网络结构
(2)采用Mask R-CNN 人体检测器。He 等人[50]提出了新的对象实例分割框架Mask R-CNN,如图11 所示。实例分割需要检测出目标的位置并且对目标进行分割,结合目标检测算法Faster R-CNN 与语义分割算法(FCN)[27]。在第一阶段,与Faster R-CNN 相同,为候选区域生成网络(region proposal network,RPN);第二阶段,添加了一个分支以预测每个感兴趣分割区域(region of interest,RoI)的掩码,提出了新的RoIAlign 策略,采用双线性插值来更精确地获取每个区域相应特征。
(3)采用FPN 人体检测器。Chen 等人[57]采用特征金字塔网络检测人体,并提出了新的级联金字塔网络结构(cascaded pyramid network,CPN)作为单人姿态估计器,以缓解单人姿态估计中关节点遮挡等难题,该网络包括两个部分GlobalNet 和RefineNet。GlobalNet 为功能金字塔网络,可简单地定位关节点,但无法准确识别被遮挡关键点;RefineNet 为细化网络,与沙漏模块末端的上采样特征不同,其将金字塔网络的多尺度特征串联起来,通过扩大感受野优化对遮挡关节点的检测,CPN 网络分为多个阶段,第一个阶段会产生初步的关键点的检测效果,接下来的阶段均以前一个阶段的预测输出和从原图提取的特征作为输入,以提高关节点的检测精度,其网络结构如图12 所示。
2.1.2 自底向上
自底向上的方法也主要由两部分构成,人体关节点检测器和关节点候选分组。首先采用检测器定位出图像中所有人的关节点,再对关节点空间建模,最后对关节点进行最优分组,具体算法流程如图13所示。自底向上的方法重点关注关节点分组算法的设计,主要有整数线性规划与基于贪婪解码两种。
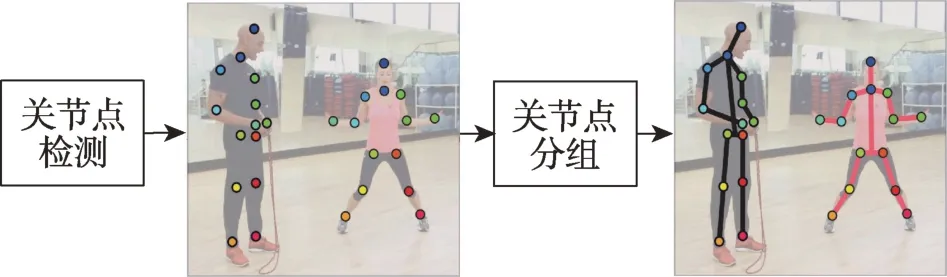
Fig.13 Flow chart of bottom-up图13 自底向上算法流程
(1)整数线性规划。Pishchulin 等人[58]提出了一种联合解决检测和姿态估计的方法Deepcut,首先采用改进的Fast R-CNN[59]检测图像中所有人体的关节点,组成候选关节点密度图;然后标记检测出的关节点,以确定关节点对应的人体部位;再通过讨论候选关节点的聚类,采用整数线性规划进行优化,有效地进行非极大值抑制将属于同一个人的关节点归为一类;最后结合标记的关节点以及归类好的关节点,对关节点进行最优连接获取多人姿态信息。
针对关节点密度图的聚类以及优化算法复杂度较高,Insafutdinov 等人[60]改进Deepcut提出了Deepercut 算法,采用更深的残差网络Resnet 获取人体关节点,提高了检测精度;采用图片约束成对关系(imageconditioned pairwise terms)来减少众多候选区域的关节点,降低了计算量,提高了效率与鲁棒性。
(2)贪婪解码器。Cao 等人[61]提出了姿态估计方法OpenPose,首先采用VGG-19[62]提取图像特征,将特征输入到一个双分支网络,两个分支都为类CPM的顺序循环迭代网络,分别获取关节点置信图以及部位亲和域(part affinity fields,PAFs),部位亲和域为一组二维向量场,用于编码图像中肢体部位的位置与方向;将关节点的最优连接简化为最大权重二部图匹配问题,对关节点进行聚类构成关节点二部图,对部位亲和域关节点间的向量场进行积分,积分结果表示关节点连接的权重,最后采用匈牙利算法进行最优化匹配,获取所有关节点间连接,关节点二部图如图14 所示。
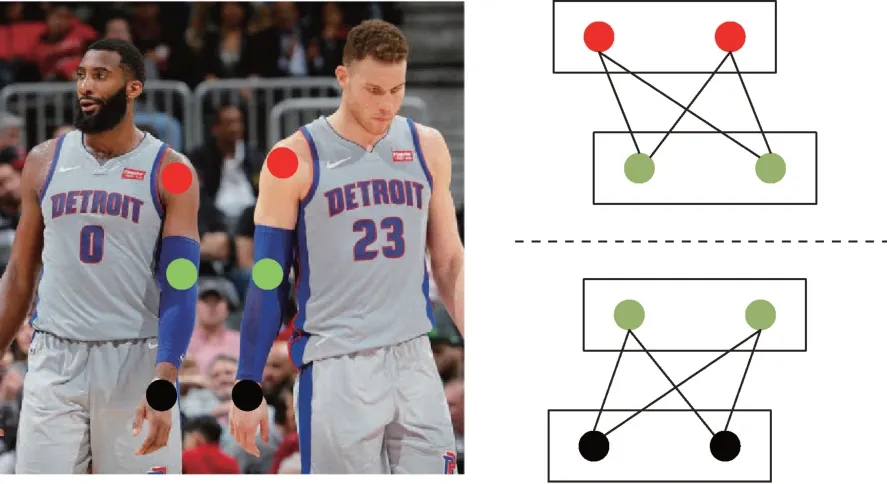
Fig.14 Bipartite graphs of joints图14 关节点二部图
Newell等人[63]提出关联嵌入标签算法Associative Embedding,以端到端的方式联合关节点检测与分组,首先采用沙漏堆叠网络同时生成每个关节点的热图,并在每个关节的像素位置生成一个标记,即对应的嵌入标签(embedding tag);再通过比较检测的标记值和按照欧氏距离匹配足够接近的标记值,对人体关节点检测进行分组。
Sekii[64]提出姿态建议网络(pose proposal networks,PPNs),结合YOLO[65]目标检测的思想,与大多基于热图的像素级别检测不同,采用网格的形式检测关节点位置与关节点连接信息;采用类似于部位亲和域的二部图匹配方法,独立确定相邻关节点的匹配,为了降低计算成本,使用感受野较窄且相对较浅的网络,采用CNN(convolutional neural networks)估计的部分关联得分来隐式建模不相邻关节点间的关系。
Papandreou 等人[66]提出了一个结合姿态估计与实例分割的多任务网络PersonLab,采用残差网络预测每个人各关节点的联合热图、关节点偏移量以及人体分割掩模;利用基于树形运动学图的贪婪解码算法将关键点分组到人体检测实例中。
Osokin[67]在OpenPose 的基础上提出了轻量级的方法Lightweight OpenPose,采用MobileNet v1[68]替换VGG-19 提取图像特征;将双分支网络权值共享以减少计算量,在最后两个卷积层再分出两个分支分别预测关键点定位和部位亲和域;最后结合空洞卷积的方式优化了OpenPose。
Kreiss 等人[69]针对分辨率较低的拥挤场景提出PifPaf 算法,算法主网络为残差网络,其中部位强度场(part intensity field,PIF)分别预测关节点置信图、偏移量、损失函数参数以及关节点尺度信息以获取人体关节点位置;部位关联域(part association field,PAF)对于预测的每个关节点,寻找距离最近的关节点并连接;最后基于贪婪解码算法,确定置信度最高的关节点,采用PAF 依次对关节点进行连接,由于PAF 的编码方式能够在低分辨率映射中存储细粒度信息,使该算法适用于低分辨率图像。
Cheng 等人[70]在高分辨率网络HRNet 基础上做了改进提出了HigherHRNet网络,以HRNet为主干增加了一个高效的反卷积模块,采用多分辨率训练和热图聚合策略,可预测具有尺度感知的热图,提高了关节点预测效率且精确度远高于HRNet,网络如图15所示,再采用关联嵌入标签算法对关节点进行分组。
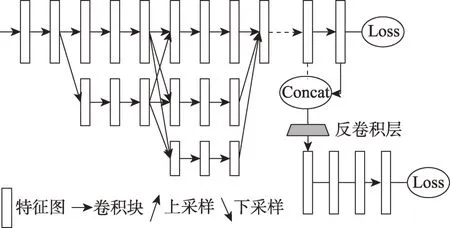
Fig.15 Architecture of HigherHRNet图15 HigherHRNet网络结构
自顶向下与自底向上的多人姿态算法由于算法步骤的差异存在不同的特点,表4 具体列出了这两种方法的优缺点。在对姿态估计精度要求较高的场景下较适合选择自顶向下的方法,对时间效率要求较高的情况下,比如需进行实时的多人姿态估计,更适合采用自底向上的方法。

Table 4 Comparison of two-step multi-person pose estimation algorithms表4 二步法多人姿态估计算法对比
2.2 一步法多人姿态估计
为了简化二步法多人物姿态估计的流程,提高多人姿态估计的效率,Nie 等人[71]于2019 年提出了单阶段的多人姿态器(single-stage multi-person pose machine,SPM),如图16 所示,首先提出了一种新的结构化姿态表示方法(structured pose representation,SPR)来简化人体分割和关节点定位的流程,SPR 采用根节点来确定人体位置,检测人体所有关节点相对于根节点的偏移量,在获取根节点热图后通过回归得到若干个偏移量,即可获取人体所有关节点坐标;针对关节点离根节点较远而导致从图像表示映射到矢量域的偏移估计带来困难的问题,还提出一种分层的SPR,将远距离偏移分解为累积的短偏移,根据关节的自由度和变形程度将根关节和人体关节点划分为四个层次,通过相邻层次关节之间的短距离偏移来识别关节位置;基于堆叠的沙漏网络构建SPM,先降低特征图分辨率,学习抽象语义表示,然后上采样人体关节点定位特征图以重用低层次空间信息来精炼高级语义信息,此外添加偏移回归分支来扩展沙漏网络,用于估计人体关节点偏移量,从而实现高效的单阶段多人姿态估计。
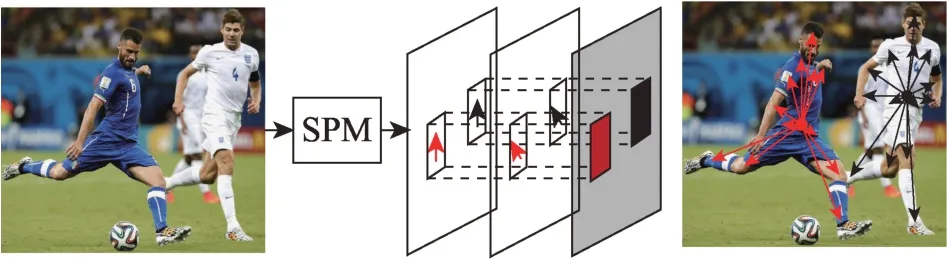
Fig.16 Single-stage pose estimation solution of SPM图16 SPM 单阶段姿态估计方案
2.3 小结
二步法多人姿态估计方法主要分为两个步骤,包括人体框、关节点的检测与关节点分组,算法流程较复杂;一步法的多人姿态估计则不用分步骤,可一步到位获取多人姿态信息,简化了多人姿态估计流程,是一种较新颖的多人姿态估计方法。
3 数据集与评估指标
3.1 国际标准数据集
基于深度学习的人体姿态估计研究需要依赖大量数据来训练模型,数据样本量越大,越多样性,则越有利于开发强鲁棒性的人体姿态估计模型。近年来,许多用于人体姿态估计的数据集也相继被公布,表5 列出了几种国际标准数据集适用类型、标注的关节点数量、样本数量以及数据集来源。
3.2 评估指标
不同的数据集具有不同的特征和不同的任务要求,常用的二维人体姿态估计主要有以下几种:部位正确估计百分比(percentage of correct parts,PCP)[81],为早期姿态估计的评估指标,用于评估肢体的定位精度,若肢体的两个端点在相应真值端点的阈值内,则该肢体被正确定位;关节点正确定位百分比(percentage of correct keypoints,PCK)[82],评估人体关节点定位的准确率,若候选关节点落在真实关节点的阈值像素内,则该候选关节点是正确的;关节点平均精度(average precision of keypoints,APK)[82],通过PCK 评估将预测的姿态分配给真值姿态后,由APK得出每个关节点定位准确的平均精度;对象关节点相似度(object keypoint similarity,OKS)多人姿态估计评价指标,计算真值和所预测人体关节点的相似度。
4 经典算法实验结果对比
分别列出经典的单人姿态估计算法在MPII 数据集上,以0.5 作为容忍度的PCKh@0.5 实验结果,以及多人姿态估计算法在MSCOCO 数据集上AP(average precision)的实验结果以及预测时长,对比各算法的准确率,如表6 与表7 所示。

Table 5 Datasets of human pose estimation表5 人体姿态估计数据集
根据实验数据可知,在单人姿态估计算法中基于热图检测比基于坐标回归的方法关节点定位准确率普遍更高,更具有鲁棒性;在多人姿态估计算法中,一步法由于简化了算法步骤,在时间效率上远胜于二步法。
5 难点分析与发展趋势
近年来,二维人体姿态估计算法已取得显著的成果,但仍然存在许多问题待突破:
(1)算法效率受复杂环境因素影响较大。
光照以及遮挡等问题,在多人姿态估计中易导致人体检测框的误检和冗余,重叠的关节点导致关节点分组的错误;不同视角导致无法正确判断人体比例,影响姿态估计鲁棒性。
针对光照、视角与遮挡等问题,文献[83]提出可以研究肢体遮挡的修复算法,文献[84]提出利用人体动作的连续性解决遮挡问题。此外,单人姿态估计可考虑增大卷积神经的感受野来优化网络,如文献[28]采用堆叠的沙漏模块层来增大感受野;多人姿态估计的自顶向下的方法重点关注人体检测器的研究,减少人体框检测错误与冗余,可提升后续单人姿态估计精度,如文献[48]设计适用于姿态估计的人体实例分割框架Mask R-CNN,提高人体检测精度;多人姿态估计的自底向上方法可研究适合姿态估计的关节点分组方法,如文献[59]的部位亲和域分组方法,文献[85]设计编解码残差的人体关键点分配网络可大大减少由于遮挡以及密集环境对估计结果的影响。
(2)算法复杂无法满足实时预测的要求。
基于深度学习的神经网络运算量较大,且相较于分类任务和检测任务,人体姿态检测需要更高分辨率的输出特征图,其将大大增加算法计算量。
针对改进网络的时候往往会遇到精度提高但是计算量增大,时间效率降低的问题,可采用轻量级网络优化姿态估计算法,将轻量级的网络结合到姿态估计,简化姿态估计网络在保证算法精度的同时提高时间效率,如文献[33]将堆叠沙漏网络的沙漏模块减少一半来简化网络;文献[65]结合已有的轻量级算法MobileNet v1 来优化网络;文献[86]设计了针对姿态估计的轻量级网络。
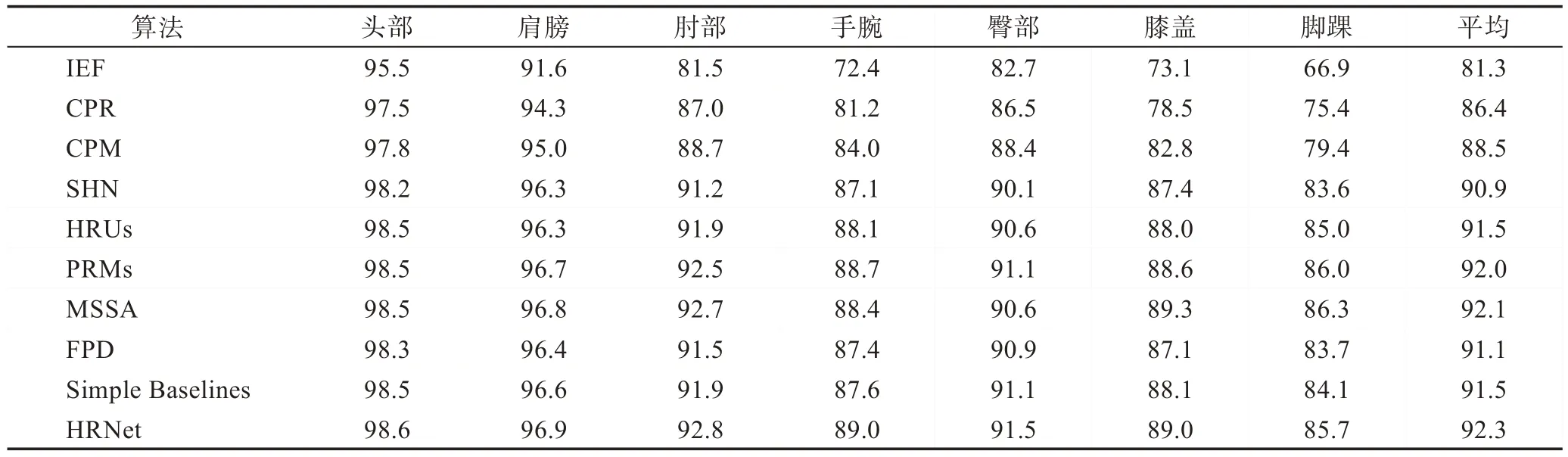
Table 6 Percentage of correct keypoints of single-person pose estimation algorithms on MPII表6 单人姿态估计算法在MPII上的关节点正确定位百分比 %
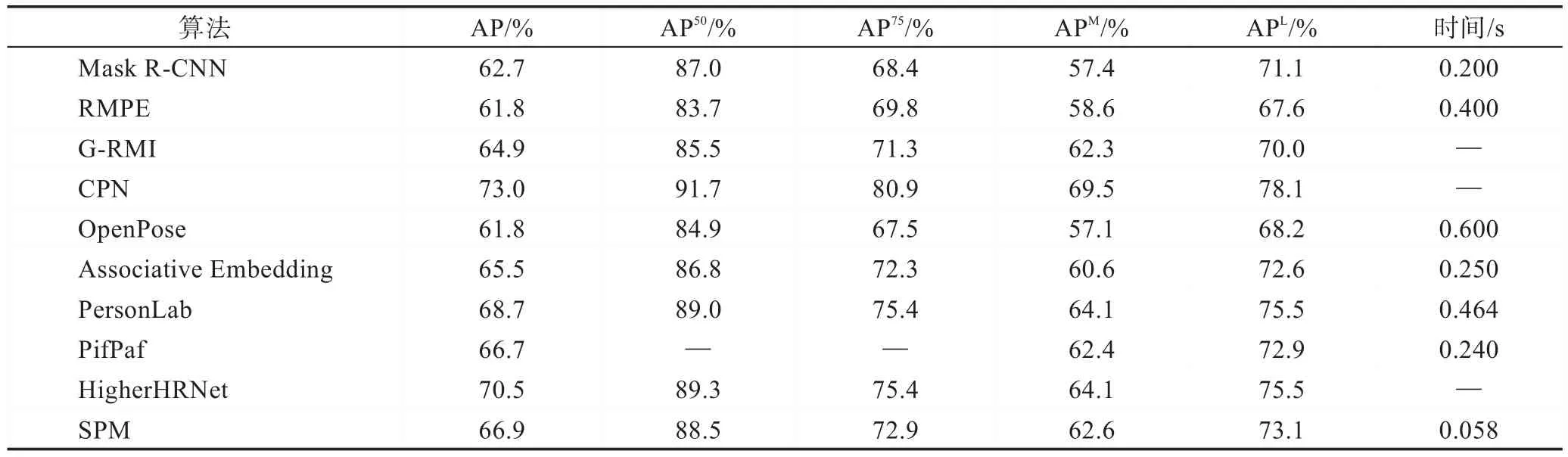
Table 7 Average precision of keypoints of multi-person pose estimation algorithms on MSCOCO表7 多人位姿估计算法在MSCOCO 上的关节点平均精度
(3)人体姿态的变化复杂与多样。
对于人体不同的运动姿态,估计结果精度不同,幅度较大的姿态往往预测准确度较低。
针对人体姿态的高度复杂问题,可设计新的关节点检测方法,如文献[69]采用根节点来确定人体位置,以分层的方式计算关节点到根节点的偏移量;此外还可以引入时间约束,研究姿态的连续性,如文献[42]将光流思想应用于姿态估计来对齐相邻帧与当前帧的关节点热图。
(4)训练数据集不足与分布不均匀。
已有常用的数据集数据足够大,但姿态分布仍不平衡,针对许多不同的场景已提出了相应的数据集,但对于人体灵活的运动,仍无法提出较为全面的数据集。
针对现有数据集无法满足人体姿态多样性,对现有数据集样本进行扩充与丰富仍是人体姿态估计算法研究的重点;此外可研究高效的训练方法,设计弱监督学习、半监督学习等方法来提升训练效率。
6 结束语
二维人体姿态估计作为近年来计算机视觉的研究热点,在动作识别、运动分析、智能监控、无人驾驶、虚拟现实、人机交互与电影动画等领域都取得了广泛的应用。本文对近年来基于深度学习的二维人体姿态估计主要算法按时间发展进行了阐述,并对算法进行了分析与对比,最后探讨了深度学习在二维人体姿态估计中面临的挑战以及未来发展趋势。
