动态社区发现方法研究综述
2021-04-11端祥宇孟凡荣
端祥宇,袁 冠,2+,孟凡荣
1.中国矿业大学计算机科学与技术学院,江苏徐州 221116
2.矿山数字化教育部工程研究中心,江苏徐州 221116
复杂网络是对复杂系统进行抽象。其中节点是代表复杂系统中的个体,节点之间的边表示个体之间根据某种规则形成的联系。随着社交平台的多元化发展,社交媒体用户不断增加,社交网络已经逐渐成为最具挖掘价值的复杂网络之一。社交网络的一个重要特征是社区结构。虽然社区的概念依然没有一个明确的定义[1],但多数文献中都认为社区是对网络的分解与划分,将网络划分成多个集合,集合内部的节点连接密集,集合之间连接稀疏[2],使得社区具有高内聚、低耦合的特性。
社区发现是研究网络社区结构必不可少的技术,采用有效方法将社交网络中潜在的社区挖掘出来。目前,对社区发现方法的研究越来越多,在DBLP(database systems and logic programming)上以community detection 为关键词搜索公开发表的相关论文,可以发现学术界对社区发现的研究成递增趋势,社区发现已经逐步成为复杂网络分析中的重点研究方向之一(如图1 所示)。通过对社交网络进行社区发现,可以分析社区结构、计算节点影响力、寻找核心节点、进行兴趣推荐等。
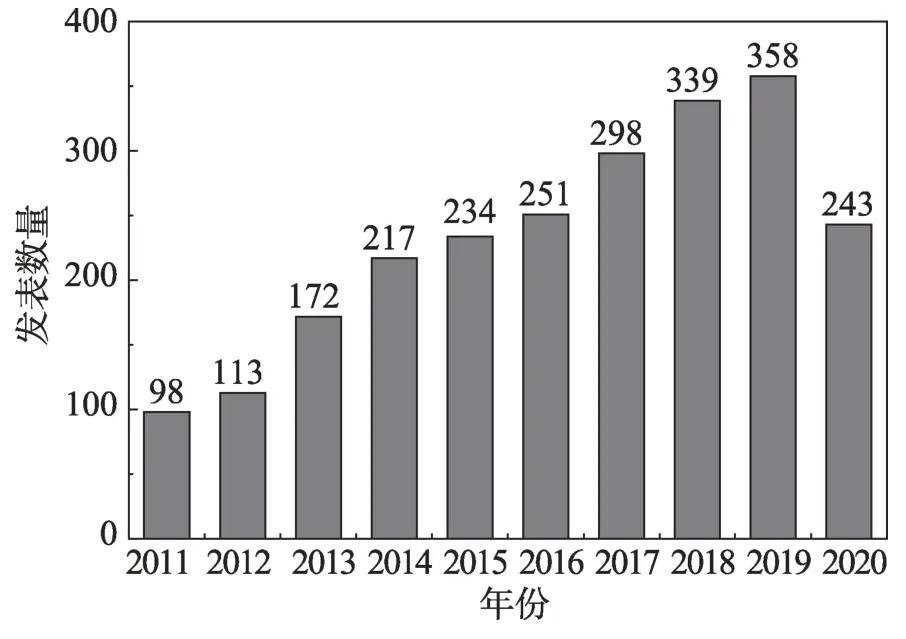
Fig.1 Papers on community detection published in DBLP from Jan.2011 to Oct.2020图1 2011.01—2020.10关于社区发现论文的统计(DBLP)
社交网络的社区发现算法主要分为静态社区发现方法和动态社区发现方法。目前关于复杂网络的社区发现方法的研究主要集中在静态方法。传统的静态社区发现一般分为两类,一类是非重叠社区发现,另一类则是重叠社区发现。前者使得网络中的每个节点仅属于一个社区,不存在任何节点同时属于两个或两个以上社区的情况[3],而后者则相反。非重叠社区发现算法主要包括基于图分割的算法[4-6]、基于层次聚类的方法[2,7-8]、基于模块度(modularity,Q)的优化算法[9-10]、基于标签传播的算法[11]、基于模型推断的方法[12]等。重叠社区发现算法主要包括基于团过滤的方法[13-15]、基于边划分的方法[16]、基于局部扩展的方法[17]、基于模糊检测的算法[18]、基于马尔可夫链的方法[19]等。
多数复杂网络中节点和边的数量随时间动态变化,因此动态社区发现逐渐成为研究社区结构的主要方向。社交网络具有交叉性和时序性,即随着时间的推移,不同的社区的节点和边相互交叉变化,部分节点和边的增加与删除,会导致一些社区出现消失、增长、收缩、合并等现象,从而影响社交网络的质量[20]。常见的动态社区发现方法有基于经典聚类方法的社区发现、基于动力学的社区发现、基于统计模型的社区发现以及基于启发式方法的社区发现方法(详细介绍见第2 章)。
动态社区发现具体研究框架如图2 所示。
1 相关工作
本章首先介绍相关符号的定义,然后通过网络级别的行为演化和节点级别的行为演化分析目前主要动态社区发现的研究方法。
1.1 相关定义
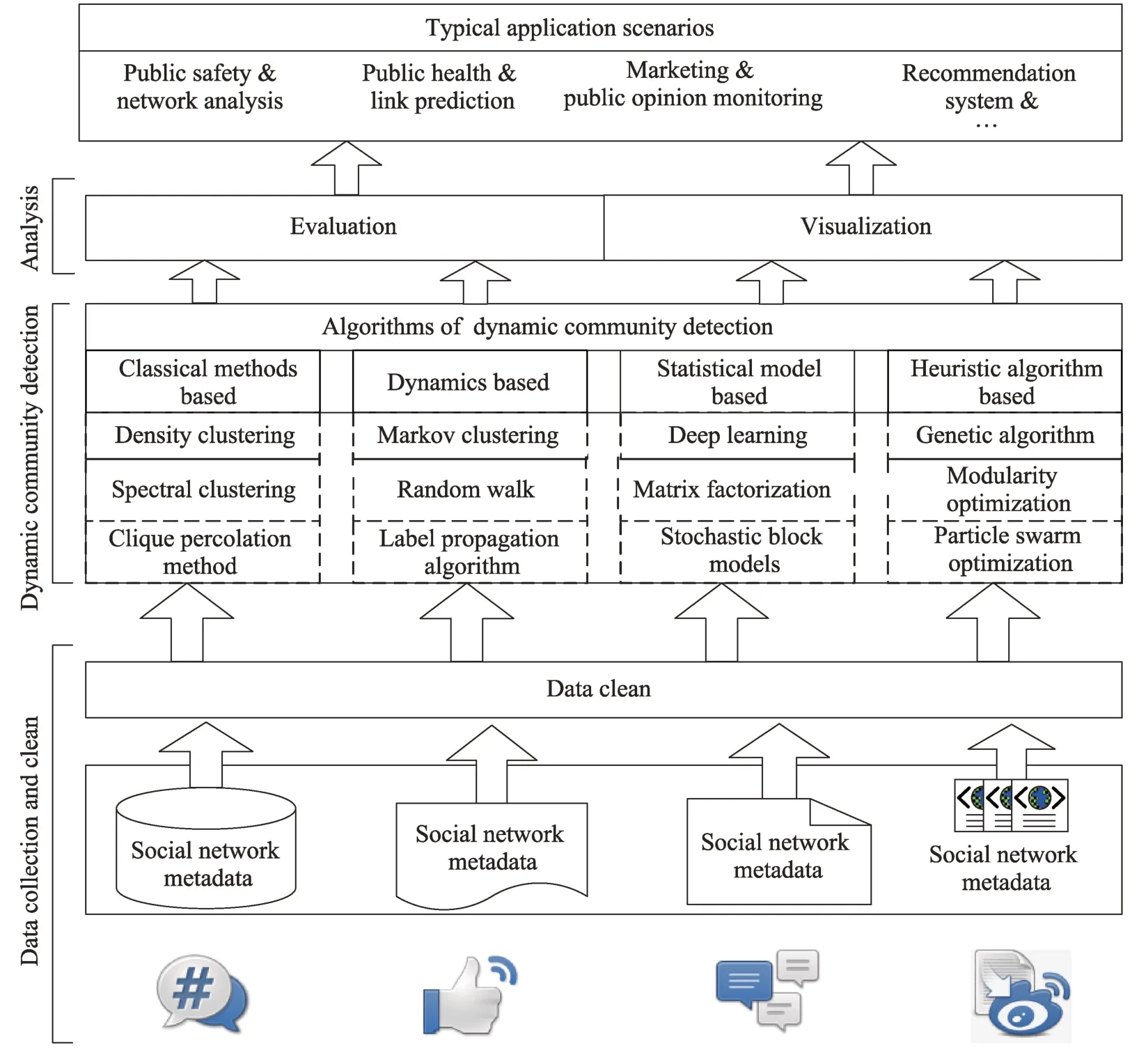
Fig.2 Framework of dynamic community detection图2 动态社区发现结构图
定义1(复杂网络)复杂网络可用图G=(V,E)表示,其中V代表节点的集合,E代表边的集合。边e=(u,v)∈E表示两个节点u,v∈V之间的相互联系。复杂网络的社区发现本质上是对图中的节点进行聚类划分,n表示节点数量,m表示边的数量。与节点v关联的边的数目称为节点v的度,记为d。
定义2(动态网络)动态网络G可以由一系列离散的快照网络表示,即G={G0,G1,…,GT},其中T表示划分的快照网络的数量。快照网络Gt=(Vt,Et),0 ≤t≤T表示节点集V和边集E在当前时间t出现的快照图。
定义3(动态社区)动态社区发现是在连续的时间快照中找到一系列相似的社区。动态社区可以看作是由按照时间快照时序排列的社区集合组成,即C={C0,C1,…,Ct,…,CT},t∈T,0 ≤t≤T。在第t时刻的快照网络中检测到的k个社区可以表示为,0 ≤s≤k。文中使用的部分符号如表1 所示。

Table 1 Notions and descriptions表1 符号及描述
1.2 动态社区演化
关于社区的动态演化,Qiu 等[21]提出了事件驱动的网络建模框架。基于该框架设计了一个基于事件驱动的演化增长模型,融合节点的度(依附)和节点间的距离(位置)作为动态社区演化的参考因素。他们还提出了网络级的行为演化以及节点级的行为演化两种概念,是社区的动态演化的重要参考。
1.2.1 网络级行为演化
网络级的行为演化是指在社区范围内定义社区的变化行为,称为“事件(event)”[22]。有多项研究[7,23-25]定义了在网络演化过程中出现的相关事件。图3 所示是Dakiche 等[22]综合上述文献后,对事件定义进行的简化。
出生(birth),在特定时间形成一个新社区。
消失(death),一个社区消失。
增长(growth),社区有一些新成员(节点)加入。
收缩(shrink),一个社区失去一些成员。
合并(merge),几个社区合并形成一个新社区。
拆分(split),将一个社区划分为几个新社区。
重现(resurgence),一个社区消失一段时间后重新出现。
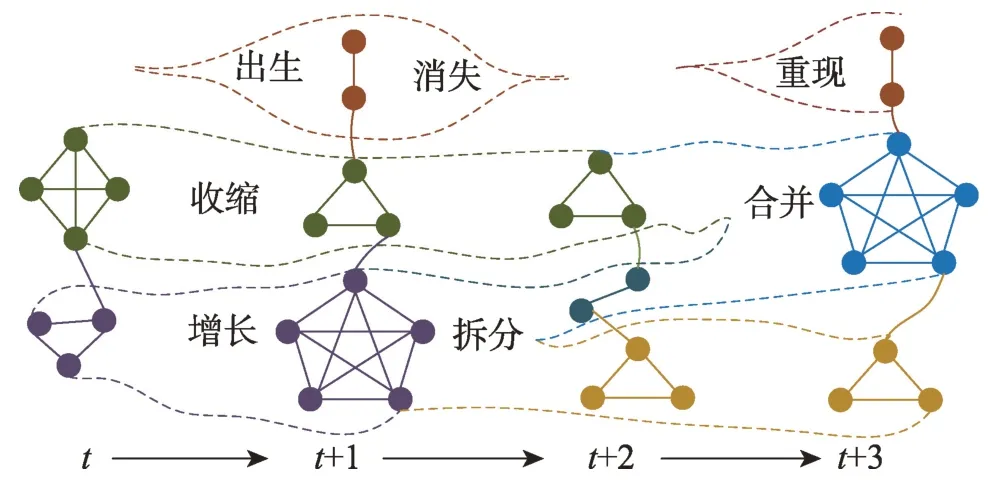
Fig.3 Evolution of events over time图3 随时间发展的事件的演化过程
Asur 等[23]设计了一个基于事件的框架来描述交互网络的演变,并对社区之间的拆分、合并、连续、形成和消失等关键事件进行定义,同时又关注于节点在社区中出现、消失、加入、离开等行为的定义。该框架将演化过程中社区和节点行为相结合,分析了合著者网络和临床数据网络中的相关社区和主题演变,取得了良好的效果。但是该方法分配事件的条件过于严格,容易导致部分事件难以识别。Bródka等[24]引入收缩和增长等事件的定义,设计了基于组演化的社区发现方法,使用决策树将“组”的类型与事件进行匹配,解决了上述问题并提高了社区发现的速度。该方法比Asur等[23]方法快50 倍以上。
Cazabet 等[26]提出iLCD(intrinsic longitudinal community detection)算法,根据网络拓扑结构的变化,对前一个快照网络的社区进行更新、合并、生成新社区来发现当前快照网络的社区结构。该算法能够在动态网络中进行重叠社区发现。Zhao 等[27]将网络中随时间改变的部分定义为增量元素,并认为各种子图组成增量元素,根据子图之间的关系和先前时间片中社区的关系,将其分为完全独立、完全包含、混合新旧节点以及多包含等四种类型的子图,并通过判断增量元素类型从而更新社区或形成新的社区,用于动态发现社区。
Gao 等[28]提出了基于领导者节点的演化社区发现算法,通过Top Leader 社区发现算法将初始网络进行划分后,对社区进行分裂以及合并操作。Xin 等[29]将网络分为生成、分裂、合并和生存4 种群落演化,并使用相应算法分别对4 种演化进行研究。He 等[30]通过将大型网络分解,构造出小型网络,提升社区发现的准确性和速度。
Gou 等[31]关注社区的扩展和合并,设计了动态加权网络中的演化社区结构发现算法,但是该算法的缺陷在于每个演化步骤中都需要人为设定阈值,不同的阈值设定对算法的结果具有较大的影响。张高祯等[32]借鉴模块度优化算法的思想,解决了上述问题,并对Guo 等[31]算法中扩展社区、合并社区的步骤进行了优化,最终在模块度质量上优于上述算法。
1.2.2 节点级行为演化
节点级的行为演化主要从节点变化的角度来探索动态网络中社区的相关变化,包括以下四种情况:
(1)节点增加,新的节点加入当前网络;
(2)节点减少,一些现有节点离开当前网络;
(3)边增加,一些节点之间建立新的联系;
(4)边减少,一些节点之间断开现有联系。
Agarwal等[33]就是将节点级的行为演化融入到算法之中,将算法分为节点添加、节点删除、边添加和边删除四种情况及对应方法。Cordeiro 等[34]关注于新增或删除的节点和边所在的社区,运用局部模块度最大化思想,仅对改变的元素重新划分社区,不对其他元素进行操作,大大提升了运行效率。
郭昆等[35]将当前时间的新增节点、消失节点以及邻居变化节点等定义为增量节点。通过节点的变化和节点间的距离来调整生成新社区。Duan 等[36]通过k-团过滤算法将初始网络划分成k个团,通过分析团与团之间边和节点的增减,使用局部深度优先搜索森林更新技术,以及增量k-clique算法进行聚类。
蒋盛益等[37]同样关注于节点行为的演化,提出一种基于增量式谱聚类的动态社区自适应发现算法,采用归一化图形拉普拉斯矩阵,以上一个时间片网络的社区特征为基础,采用调整的链接相关线性谱聚类进行动态社区发现。Ning 等[38]同样提出了一种基于谱聚类的动态网络社区发现算法,将动态网络的变化分为节点之间相似度的变化和增删节点,并用关联向量和关联矩阵表示动态变化,通过增量谱聚类算法得到动态网络的社区结构。
Xie 等[39]专注于追踪快照图中由于边的改变而造成变化的节点,提出一种用于动态社区发现的增量标签传播算法。文中采用标签传播算法对快照网络进行迭代更新。该算法在加权网络和有向网络上具有更好的普适性。Xin 等[40]使用一种自适应随机游走采样的动态社区发现算法来实现对动态网络社区的更新,从节点级行为演化角度将网络的变化进行划分,将网络中的产生变化的节点及其相邻节点、与产生变化的边所连接的节点加入到队列中,用随机游走采样算法对队列中节点进行计算,从而完成社区的更新,提高了社区发现效率。
2 动态社区发现方法
动态社区发现方法可以分为四种,分别是基于经典聚类方法、基于动力学的方法、基于统计模型的方法以及基于启发式的方法。表2 对典型动态社区发现的论文、采用的算法以及时间复杂度进行了总结归纳。主要参数p表示算法的迭代次数,l表示局部搜索迭代的次数,x、y是常量。
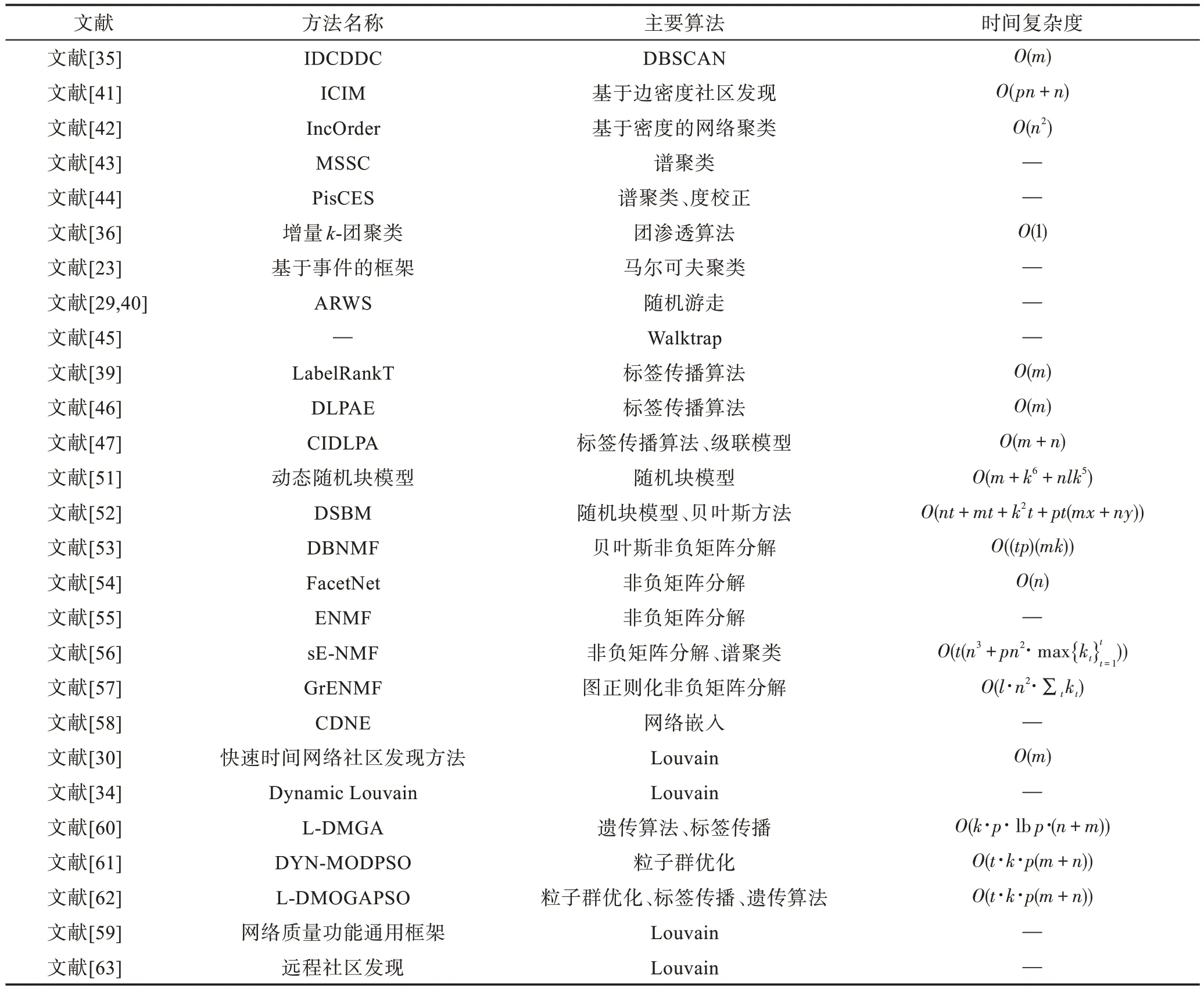
Table 2 Introduction of dynamic community detection methods表2 动态社区发现方法的介绍
2.1 基于经典聚类方法的社区发现
经典聚类方法,如密度聚类[35,41-42]、谱聚类[43-44]、派系过滤算法[36]等常应用于静态社区发现中。本节主要探讨经典聚类算法与动态社区发现的结合。
郭昆等[35]利用基于密度的方法发现社区增量变化过程。首先,基于改进后的DBSCAN(density-based spatial clustering of applications with noise)生成初始社区,并根据边变化率和余弦相似度确定相邻时刻下发生变化的邻居节点,同时根据节点的直接邻居和间接邻居的影响,调整邻居节点的社区归属。最后,通过迭代更新模块度增益实现社区合并,以及更新当前社区。方法在Enron 和人工数据集上有出色表现。
朱腾云[41]首先利用边密度在静态网络中识别相关社区,然后依据静态算法提出基于边密度和改进模块度的增量动态社区算法。利用静态算法生成初始社区,并根据相邻时刻增量对邻居节点社区归属度的影响进行计算,结合网络的历史拓扑结构在Enron 和人工数据集上进行社区发现,结果表明其效果在标准化互信息(normalized mutual information,NMI)和运行速度上优于传统算法。
Sun 等[42]提出了基于增量的密度聚类算法Inc-Order。算法分为在线和离线两部分。在线阶段中,通过引入核心连接相似性的概念,从动态网络中构造基于密度聚类的核心连接链,并实时维护该连接链。离线阶段则是从核心连接链中提取所有高于相似度阈值的结果序列,使用模块度优化的方法从序列中提取社区。该算法在静态和动态数据集的划分上取得了很好的效果。Qin 等[43]提出了一种多相似谱聚类方法,将快照网络构造为多个相似性矩阵。为了保持相邻快照之间的演化的动态性,该方法采用动态协同训练方法来进行不同相似性度量聚类,这能够保留社区结构的历史信息。此外,他们还提出一种自适应方法来估计目标中的时间平滑参数。算法在真实数据集和人工数据集上的NMI 值高于对比算法,而误差平方和低于对比算法,具有良好的动态社区划分性能。Liu 等[44]提出全局谱聚类的概念,将当前网络与前后时间网络的前导特征向量平滑连接,目的在于通过合并有关网络演化的可用信息来改善社区发现方法。又设计一种全局社区发现方法,采用特征向量的平滑性建立连续社区,并且通过演化谱聚类和度校正的方法将时序网络中的信息聚类,用于增强对各个时间片的推断。算法在恒河猴大脑基因表达数据上展示了优良的性能,为分析恒河猴的相关习性提供了有力支持。
Duan 等[36]设计增量k-团聚类算法对动态网络进行社区发现。方法采用变化流模型,将派系过滤算法应用深度优先遍历森林进行改进。从节点级行为演化角度出发,进行动态社区发现。该算法在DBLP和Enron 数据集上的运行速度较相应静态算法有很大的提升。但该算法的缺点在于需要设置固定系数,并且在实验中仅选取运行时间作为评价标准,无法确定最终生成的社区结构的质量。
2.2 基于动力学的社区发现
复杂网络与图论的区别在于图论仅仅只是研究网络的静态结构,而复杂网络还具有动力学特性。随机游走、游客漫步、流行病传播等都是网络的动力学过程。在这些动力学过程中,也有不少用于动态社区发现的方法,如马尔可夫聚类[23]、随机游走方法[29,40,45]和标签传播算法[39,46-47]等。
Asur 等[23]提出了一种基于匹配方法的社区事件识别算法,主要采用位运算对时序社区成员矩阵进行计算,大大减少了运行时间。采用马尔可夫聚类算法对快照网络进行社区划分,在连续快照中比较了每个可能社区对的大小和重叠性,并确定这些社区的事件。该方法在DBLP 数据集和临床实验数据集的特征描述和事件推理中具有较好的性能。同时为链接预测场景中的应用提供了良好的结果。
Xin 等[29,40]提出自适应随机游走采样(adaptive random walk sampling,ARWS)方法,进行动态社区发现。随机游走采样方法解决了由固定随机游走引起的不稳定性问题,实现了对象的非均匀随机游走。此外,还采用ARWS 算法使受影响的节点自适应地找到新近的邻居和变化的社区。ARWS 采用局部社区发现与动态自适应调整相结合的方法,仅在动态事件发生时来更新受到影响的节点和社区。但是算法具有过多的参数,不同参数值对社区发现结果影响较大。
Jdidia 等[45]对Infocom 会议的共同作者网络进行了分析。他们从不同的快照构建一个网络,并使用经典的社区发现算法Walktrap[48]进行社区发现,同时引入Infocom 会议委员会成员来进行数据分析。Xie等[39]在标签传播算法LabelRank[49]的基础上提出了一种增量算法LabelRankT。网络更新后,算法重新初始化已更改节点的标签,并重新应用LabelRank 算法来更新标签概率分布。真实网络上的结果表明,LabelRankT 的计算成本远低于同类算法,并且提高了网络结构的质量。
Liu 等[46]提出了一种基于标签传播算法的动态网络演化聚类新方法。每个节点的社区标签由其邻居确定,同时采用与网络结构相关的特殊顺序来更新节点标签,并且为每个标签分配一个归属因子,其中节点标签之一被视为主要社区,其他标签被视为次要社区的一部分。通过迭代更新节点标签,每个节点最后可以保留一个或多个社区标签。这样能够检测动态网络中不重叠和重叠的社区。该算法在真实网络上的静态和动态的社区划分均表现良好。
Sattari 等[47]提出了一种基于标签传播算法和级联信息扩散模型的方法用来发现重叠社区。首先为每个节点分配一个标签,计算节点邻居的强度,并根据强度决定每个节点的两个状态,这两个状态可以根据节点的影响度或不影响度来区分节点。然后计算邻居投票的最大标签并发送给节点,根据归属因子划分社区。该算法在真实数据集和人工数据集上都有很好的划分性能,模块度和标准化互信息均高于对比算法,但是在运行速度上慢于其对比方法。
2.3 基于统计模型的社区发现
基于统计模型的社区发现主要包括三种方法[50]:一是使用或扩展随机块模型[51-52],采用最大似然估计对模型进行优化;二是利用矩阵分解来解决社区发现问题[53-57];三是基于深度学习的社区发现模型[58]。
Xu 等[51]将静态网络随机块模型扩展到动态网络中,提出了一种状态空间模型。作者在初始时刻使用谱聚类进行社区发现,并且将扩展的卡尔曼滤波器和局部搜索策略组合,这样能够以接近最佳的方式拟合模型。Yang 等[52]将随机块模型在时间信息上进行扩展,使用转换矩阵明确地建立了节点随时间变化的模型,该转换矩阵指定了对于所有在时间t的i类节点在t+1 时刻转换为j类的概率,并将Gibbs 采样和模拟退火算法结合来拟合模型。该方法对Enron 数据集进行分析,并结合实际情况对比,最终该算法能够获得较好的推断结果。
Wang 等[53]提出了动态贝叶斯非负矩阵因式分解概率模型,这属于具有概率解释的演化聚类方法。该模型不仅可以基于每个快照网络中节点的概率成员资格来给出重叠的社区结构,而且可以基于自动相关性来自动确定每个快照网络中的社区数量。文章又提出一种基于乘法更新规则的梯度下降算法用来优化目标函数。该算法在动态合成网络和一些真实时间网络上具有更好的性能。
Lin 等[54]提出了FacetNet(a framework for analyzing communities and evolutions in dynamic networks)框架,将社区结构分析和演化相统一,并考虑到历史社区结构对当前社区的影响。该框架能够发现同时使观测数据和时间演变的拟合最大化的社区,并且以非负矩阵分解的方式统一分解了社区及其演化,并且提出了一种具有较低的时间复杂度迭代算法,可以保证获得局部最优解。FacetNet 在合成网络和真实网络中具有很快的处理速度,有较好划分结果,但其划分结果的质量依赖于网络中社区的数目。
Gao 等[55]提出了一种使用非负矩阵分解的新型动态社区检测模型(evolutionary nonnegative matrix factorization,ENMF),该模型通过引入转移矩阵,将复杂网络的动力学与时间成员信息相结合用以检测社区结构,可以在保证检测社区的质量的情况下跟踪时间演化。但是该框架的缺陷在于假设社区及其节点的数量不会随时间的发展而变化,与现实的社交网络的变化有较明显的差距。
Ma 等[56]提出了两个用于检测动态社区的演化非负矩阵分解框架,该框架中保留了聚类质量和聚类成员资格。文章首先证明了ENMF、演化模块密度和演化谱聚类优化之间是等价的,并根据等价性来扩展理论。接着提出了一种结合ENMF和谱聚类的半监督的ENMF,将先验信息集成到算法的目标函数中,能够在不增加时间复杂度的情况下选择局部最优解。此外,Ma等[57]又进一步提出了图正则化演化非负矩阵分解(graph regularized evolutionary nonnegative matrix factorization algorithm,GrENMF)算法进行动态社区发现。该算法将时间成本引入到算法的总体目标函数作为正则化器,用于平衡快照成本与时间成本。同时文中又证明了GrENMF 与ENMF、演化谱、Kmeans 和模块度密度算法是等价的。算法实施到三个人工数据集和两个真实世界数据集中,表明该算法没有增加额外的时间复杂度。
Ma 等[58]提出了一种社区感知的动态网络嵌入方法(community-aware dynamic network embedding method,CDNE),并且实施在合成网络和真实网络中,并且都取得了较好的性能。该算法首先将动态网络嵌入问题建模为使整体损失函数最小化,采用Genlouvain[59]进行社区结构的发现,使用K-means 将其分为小社区,采用堆叠式深度自编码器算法来解决最小化问题,从而获得节点的低维表示。又提出了一种社区感知平滑技术,采用了时间正则化来保持动态网络中社区的平滑动态。CDNE 对两个合成网络和九个现实世界动态网络进行分析,结果表明在网络重建、链路预测、网络稳定和社区稳定方面都具有较好的性能。
2.4 基于启发式算法的社区发现
启发式算法基于优化的思想,将随机算法与局部搜索算法相结合。社区发现算法中主要采用遗传算法[60]、粒子群优化算法[61-62]、模块度优化[30,34,59,63]。
Niu 等[60]将动态社区发现转化为一个多目标优化问题,设计了一种基于标签的动态多目标遗传算法,用来检测具有最大化快照质量和最小化时间成本两个目标的动态网络中的社区结构。文中将标签传播算法集成到遗传算法中,获得了理想的聚类结果。同时在人工网络和真实网络中采用模块度来最大化快照质量以及采用NMI 使时间成本最小化,使结果都高于其对比算法,具有较好的社区发现性能。
Gao 等[61]提出了一种基于分解的多目标离散粒子群优化算法来发现动态结构。该方法采用模块度优化来测量当前时序的社区结构质量,同时也使用优化的NMI 去计算两个连续时间步的社区结构相似性。在人工数据集和真实数据集的多次实验结果表明该算法在模块度和NMI 的结果优于作者所采用的对比算法。但是该算法造成粒子过早收敛和多样性不足等缺陷。为了弥补这两种缺点,Wang 等[62]通过提出基于演化聚类框架和标签的群体智能方法,采用融合标签传播和遗传算法改进的离散粒子群算法,引入模块度和NMI 来评估社区发现的准确性。算法使用改进的标签传播算法来确定粒子位置,采用遗传算法进行粒子处理,利用粒子群优化选择最优解。该算法在人工合成网络和真实世界网络中的实验结果优于其对比算法,取得了良好的社区划分效果。
He 等[30]提出了一种用于时间网络中动态社区检测的快速算法,该算法利用了先前时序中的历史社区信息,通过历史社区结构构造一个小型网络,采用Louvain[64]算法来检测新网络中的社区。通过对真实和合成的时态网络的实验研究表明,该方法的运行速度远远快于传统方法。Cordeiro 等[34]提出了一种可以在添加或删除节点和边后始终使社区结构保持为最新状态的方法。该方法通过执行局部模块度优化对Louvain 算法进行修改,仅对那些节点和边变化的社区执行最大化模块度增益,保持网络的其余部分不变。在实验中作者将传统静态Louvain 算法作为基准算法,在真实数据集上对比了其他动态和静态算法,结果取得了较好的实时社区划分效果。
Mucha 等[59]创建了一个能够在两个不同的连续时间步长之间连接相同的节点的网络,使用Louvain算法来优化模块度。该方法在真实网络中展示了强大的分析功能,对真实网络数据集的分析较为准确。而Aynaud 等[63]使用了Louvain 算法的优化版本,在整个快照集或子集上最大程度地优化了一组节点的平均模块度,其主要目的是在网络中寻找连贯的、模块度最优的社区。该算法实施在动态数据集mrinfo 上,研究了节点的变化、模块度随时间的变化以及全局和瞬时结构的差异,与其采用的对比算法相比,都取得了较好的性能评价。
2.5 方法比较
本节将从各种方法的主要采用算法和相关算法特点方面对基于聚类方法、基于动力学、基于统计模型以及基于启发式算法等四种类型的社区发现方法进行比较分析,如表3 所示。
基于经典聚类方法的动态社区发现方法主要是将静态社区发现中的经典社区发现方法进行改进,主要代表算法是密度聚类算法、派系过滤算法以及谱聚类算法等。
经典聚类算法都是专注于网络自身的结构特性,对网络结构的相关属性进行节点聚类。基于密度聚类的方法是通过使用密度聚类相关算法在有噪音的数据中发现各种形状和各种大小的簇。在谱聚类中,其主要思想是将所有数据作为空间中的点,这些点之间用带有权重的边连接起来。距离较远的两点之间的边权重较低,而距离较近的两点之间的边权重较高,通过对节点和权重边生成的图进行切图,使不同子图之间的边权重和尽可能得低,子图内部的边权重和尽可能得高,从而达到聚类的目的。而派系过滤算法主要思想是首先搜索所有具有k个节点的完全子图,然后建立以k-团为节点的新图,若在该图中两个k-团有k-1 个公共节点,则在新图中两个团之间建立一条边。最终在新图中,每个连通子图代表一个社区。

Table 3 Comparison of dynamic community detection methods表3 动态社区发现方法的比较
基于动力学的动态社区发现方法主要依据网络传播的动力学特点,采用如马尔可夫链、标签传播算法、随机游走等方法进行动态网络的社区划分。
动力学算法的最大特点是随机性,因此社区发现得到的结果有时会有一些差异,许多次实验将结果取平均值。当采用马尔可夫方法时,主要是利用其性质,即当一个随机过程在给定现在状态及所有过去状态情况下,其未来状态的条件概率分布仅依赖于当前状态。随机游走同样具有马尔可夫链的性质,即每一步具有“无记忆”的特性,每一次变化都不会影响别的变动。标签传播算法是一种自底向上的迭代算法。主要思想是在初始时刻对每一个节点分配一个标签,在之后的迭代过程中,每个节点都将与它相连的邻居里面数量最多的标签作为该节点的新标签,直至整个网络的节点标签都不再变化。
基于统计模型的动态社区发现方法,主要是采用随机块模型、矩阵分解以及深度学习等方法。
统计模型最大的特点是将线性代数和概率论等数学模型及规律应用于动态社区发现,有数学理论支撑,可解释性强。随机块模型是随机图的生成模型,能够生成网络,主要以概率向量为依据,将网络中的每个节点分配相应社区。矩阵分解算法中,非负矩阵分解是最为常用的算法,该算法简便、可解释性强、存储空间少,能在降维的过程中保存较好的信息完整性。深度学习方法中网络嵌入方法为每个节点输出一个特征向量,从而将相似的节点嵌入到一个低维稠密的向量空间中,这些节点表示保持了原来的网络结构特性。
基于启发式算法的动态社区发现方法主要是将相关优化的算法应用于动态网络。采用的算法包括遗传算法、粒子群优化算法以及模块度优化算法等。
启发式方法的特点就是采用优化的思想,逐步求解最优解,但在计算效率上可能不是最优。遗传算法是一种基于群体进化的计算模型,它通过群体的个体之间选择(繁殖)、交叉和变异这三个基本的遗传算子的遗传操作来实现,从而逼近问题的最优解。粒子群优化是一种基于群体智能的全局随机寻优算法,算法为每个微粒给定位置和速度,每个微粒通过更新速度来更新其自身的位置。通过迭代搜索,种群可以不断地找到更好的微粒位置,从而得到优化问题的较优解。Louvain 算法是基于模块度优化的常用算法,主要是通过模块度来衡量社区的紧密程度,可在大型静态网络上进行快速、高效和健壮的社区发现。主要思想是若一个节点加入到某一社区中会使得该社区的模块度有最大程度的增加,则节点就属于该社区。若加入其他社区后,模块度没有增加,则留在当前社区。
3 评价标准与数据集
3.1 评价标准
3.1.1 模块度
模块度是衡量网络或图形结构的一种方法,旨在测量网络划分为模块(社区)的强度。具有高模块度的网络在模块内的节点之间具有密集的连接,而在不同模块内的节点之间具有稀疏的连接。模块度多被用来评价对未知社区结构划分后的社区分类结果的好坏。
模块度是Newman 等[9]于2004 年首次提出。为了解决GN(Girvan and Newman)算法无法评价社区发现结果以及不能发现最优社区划分的问题,使模块度具有谱属性,Newman 又在2006 年将其进一步定义[65]。具体公式如式(1)所示:
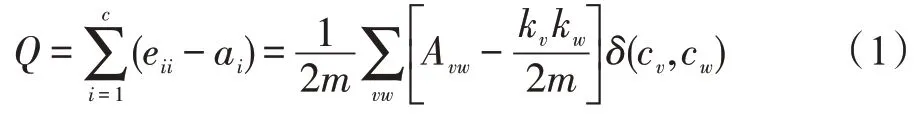
式中,eii表示社团i内部的边占总边数的比例;ai表示连接到社区i中的边占总边数的比例;m表示边数;Avw表示网络中的实际边数;kv表示节点v的度数;表示节点v,w之间存在边的概率。δ(cv,cw)有两个值,当δ(cv,cw)=0 时表示节点v,w不在同一社区,当δ(cv,cw)=1 时,表示节点v,w在同一社区。
模块度的物理意义是网络社区内部的边数目占整个网络中的边数目的比例与在同等社区结构条件下节点间任意连接的边数目占整个网络中的边数目的比例之差的期望值。当模块度为零时,说明网络内部结构与构造的随机模型没有差异,即不存在明显的社区结构特征。模块度的取值范围为[-0.5,1.0),其值越大,表明网络内部的社区结构越强,表示社区质量越高,社区划分效果越好,准确度越高。但在实际应用中,大多数的真实世界网络的模块度都位于[0.3,0.7]之间。
很多文章中将模块度这一评价标准进行拓展,应用在评价不同类型的社区结构中,如Shen 等[66]将模块度拓展到重叠社区的评价上,Gou 等[31]形成了快照质量、历史质量、总质量的评价指标,其主要思想还是使用模块度对社区划分结果进行评价。同时,模块度优化也作为一种基本的社区发现方法,被广泛用于相关的算法研究之中。
3.1.2 标准化互信息
NMI 是基于熵的方法,用于测量当前时序和先前时序之间的社区结构相似性。同时NMI 也是大多数文章用来评价对已知社区结构的数据集划分所得结果的优劣的标准。其公式如式(2)所示:
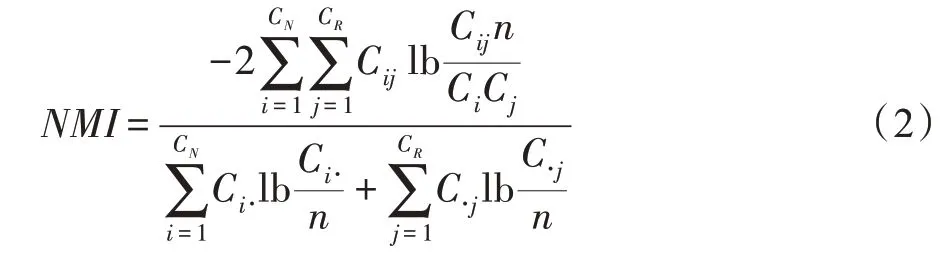
其中,CN表示标准社区结构划分的结果,CR表示算法所得的社区划分的结果,C是一个混合矩阵,Cij表示N中属于社区i的节点也属于R中社区j的数目,Ci⋅(C⋅j)表示矩阵C中行或列元素的总和。
标准化互信息的物理意义是将按标准已划分好的社区与某算法得到的划分结果两者做出对比,消除了相关信息的不确定性及信息关系之间的模糊性[67],较为客观地对标准社区结构与社区划分结果之间的准确度进行评价。NMI 的取值范围是[0,1],当取值为0 时,算法划分结果与实际社区结果完全不同;而当取值为1 时,算法划分结果与实际社区结果完全相同。即NMI 值越大,社区划分的结果越好。但其缺点也显而易见,即NMI 指标需要在标准网络结构已知的情况下使用。
3.1.3 持久性
持久性是Chakraborty 等[68]提出的一种基于节点的社区质量衡量指标,不仅衡量了网络中每个节点保留在原有社区中的程度,还对网络中的社区结构进行质量估计。其公式如式(3)所示:
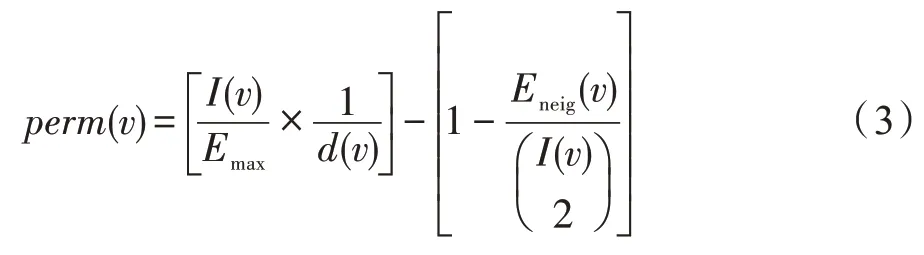
其中,I(v) 是节点v在其社区中的邻居节点数量;Emax(v)是节点v的邻居社区中的最大邻居节点数量;d(v)为节点v的度;Eneig(v)为节点v的在社区内部邻居之间的连接数量。
持久性的物理意义在于将节点的内部连接性、节点的凝聚性和节点的外部最大连接相结合,基于局部顶点度量来量化分析节点与其所在社区、节点与其相邻的社区的关系。持久性的取值范围是[-1,1],其取值越大,表示节点与其所在社区的连接越紧密,当取值为0 时,表示节点与其相邻社区的连接紧密度都相同,需要将该节点划分为单独社区。
3.1.4 其他方法
此外还有不少方法对社区划分结果或算法性能的优劣进行评价。
运行时间是一个非常普遍使用的算法性能评价方法。对同一数据集使用不同的算法进行社区发现,每种方法所花费的时间一定程度上标志着该算法在时间复杂度上的优劣性。好的算法花费时间少,划分结果准确,更能受到用户的青睐;差的算法,花费时间多,划分不准确,就不能成为流行的方法。
另外还有一些论文将多种评价标准进行融合,以获得更好的评价效果。如Takaffoli 等[69]将Guo 等[31]的快照质量与历史质量线性组合形成新的评价标准,将其命名为动态模块度。Tabarzad 等[70]认为模块度和标准互信息措施不足以描述动态网络中社区的质量,根据两个定性标准的存在,使用调和平均数计算模块度与标准互信息得到新的衡量标准。
3.2 数据集
3.2.1 真实世界网络
真实世界网络数据集包括已知标准社区结构的网络以及未知标准社区结构的网络。前者包含有空手道网络Karate、海豚网络Dolphin、政治书籍网络Polbooks、足球网络Football和政治博客网络Polblogs等;而后者有小说《悲惨世界》中人物的共同出现网络Les Mis、查尔斯·狄更斯的小说《大卫·科波菲尔》中常见形容词和名词的邻接网络Adjnoun、表示线虫的神经网络的有向加权网络Neural、恐怖分子电话网络Call1、酵母细胞网络Yeast、Facebook 社交网络、国家电网网络Power、Arxiv 广义相对论协同网络Ca-GrQc、Arxiv 高能物理理论协同网络Ca-HepTh 和Arxiv 高能物理协同网络Ca-HepPh 等。表4 给出了以上真实世界网络数据集的相关信息。
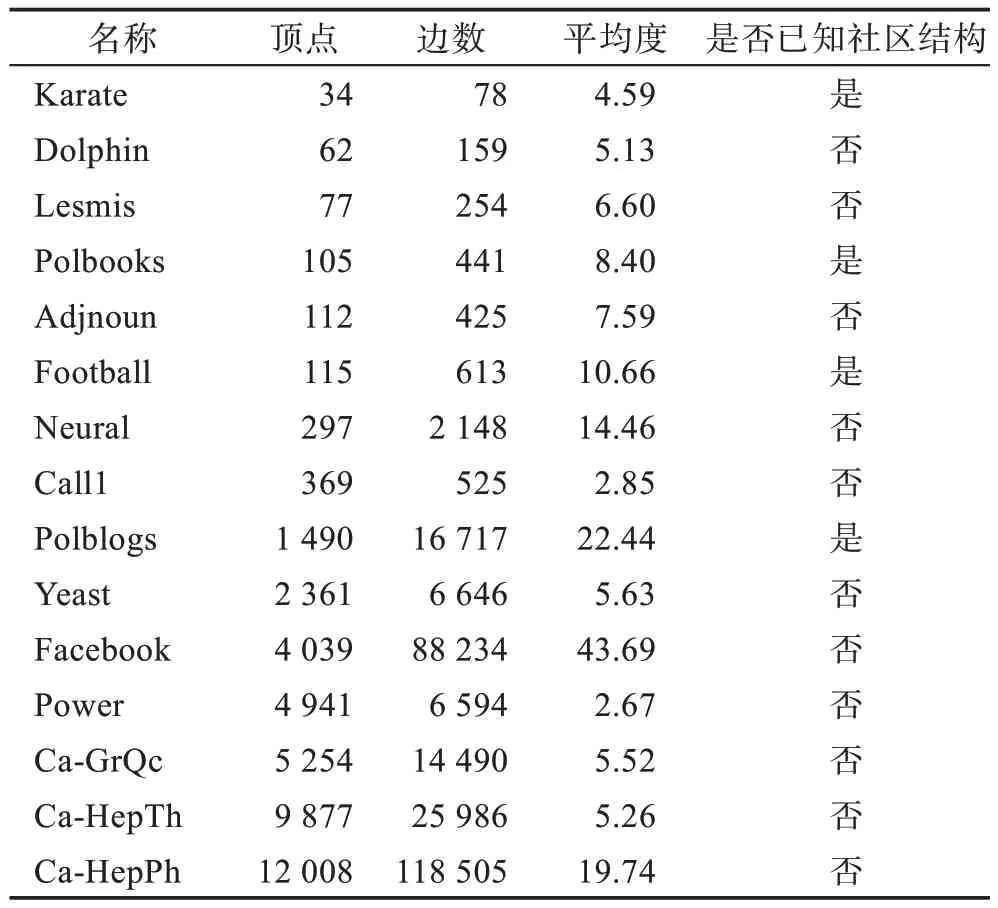
Table 4 Datasets of partial real social networks表4 部分真实社交网络数据集
在动态社区发现中真实数据集经常使用的是ENRON 和DBLP 数据集。Enron 电子邮件数据集包含了1991 年至2002 年间Enron Corporation 员工之间的交换电子邮件信息。数据集包含151 名员工的275 332 封电子邮件。DBLP 是计算机领域内以作者为核心将研究成果集成的计算机类英文文献数据库系统,按年代列出了作者的科研成果。DBLP 数据集存储了相关文献的元数据,如标题、作者、发表时间等。使用者可以根据需要提取相关的数据。
3.2.2 人工合成网络
LFR(Lancichinetti,Fortunato and Radicchi)人工网络由Lancichinetti 等[71]于2008 年提出,用来合成具有预定义社区结构的随机网络。LFR 网络的定义如式(4)所示:
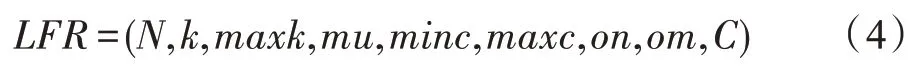
其中,N为节点数量;k表示节点的平均度;maxk表示节点的最大度;mu是混合参数,用来调节生成网络的社区结构,mu值越大,越难划分社区结构;minc表示社区的最少能包含的节点数量;maxc表示社区最大能包含的节点数量;on表示重叠节点的数量;om表示重叠节点中有成员关系的数量;C表示平均聚类系数。
3.3 性能分析
本节在11 种数据集上验证了8 种典型的社区发现算法,采用运行时间、模块度和标准化互信息来分析算法的相关性能,并详细介绍了6 种用于网络社区可视化的相关软件。
本节采用的8 种算法分别是Fluidc 算法[72]、GN 算法[2]、Louvain 算法[64]、LPA(label propagation algorithm)算法[11]、Spectral Clustering 算法[73]、Greedy modularity算法[74]、Kernighan 算法[5]以及Block model 算法[75],对3 种类型共11 种数据集进行研究,分别是已知社区结构的真实网络数据集Karate、Football、Polbooks;未知社区结构的真实网络数据集Dolphin、Lesmis、Power;人工数据集Lfr200、Lfr500、Lfr1000、Lfr2000 和Lfr5000。
3.3.1 运行时间
表5 中给出了8 种算法在11 种数据集中的运行时间,其中GN 算法对Lfr2000 和Lfr5000 数据集的社区发现没有成功,主要原因在于GN 算法对大型数据集的处理效率过低,耗费时间过长;而Spectral Clustering 算法在对Power 数据集的处理上由于采用算法的某些原因不能对其进行社区划分。实验表明,GN 算法在运行速度上与其余算法相比最慢,耗费时间最长。LPA 相对于其他算法而言,运行时间最短,速度最快,主要原因是其时间复杂度呈线性,较其他算法要快得多。各算法的时间复杂度和输入参数对比详见表6,其中μ表示深度。对于小型数据集大部分算法都可以在较短的时间内计算出来。GN、Spectral Clustering 以及Kernighan 算法在大型数据集上则需要较多的时间。
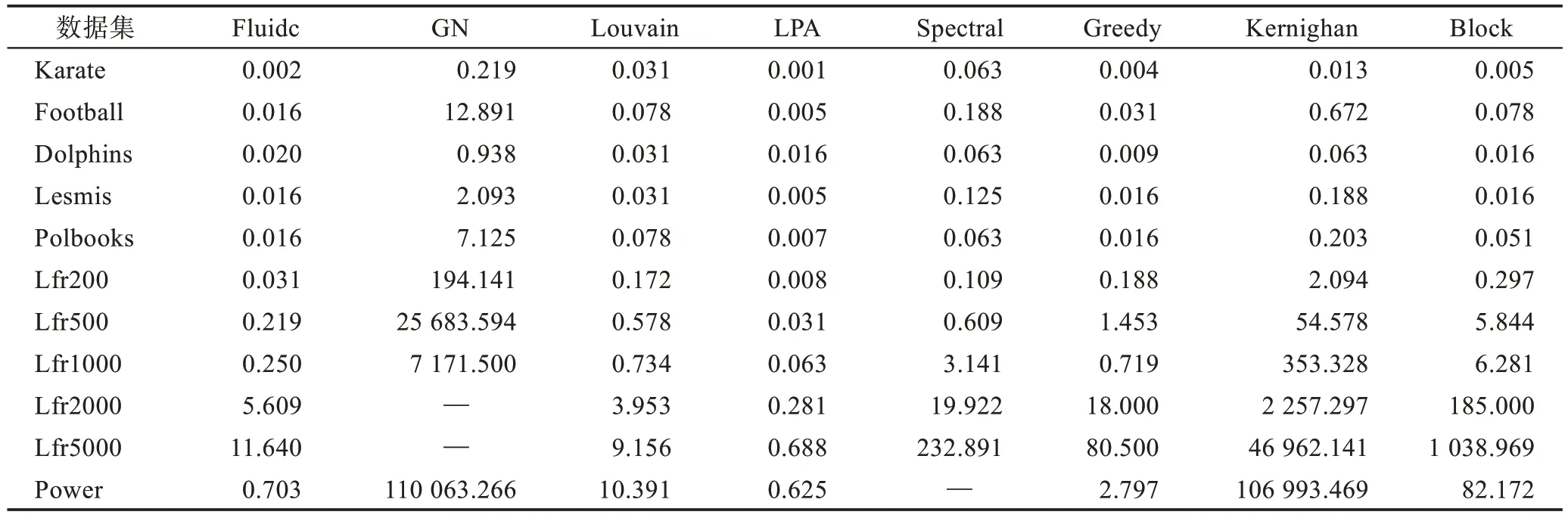
Table 5 Running time of 8 methods on datasets表5 8 种算法在数据集中的运行时间 s

Table 6 Time complexity and input parameters of 8 methods表6 8 种经典算法的时间复杂度以及输入参数
3.3.2 模块度
图4 给出了8 种算法在11 种数据集中的模块度。结果表明,Louvain 算法在所有数据集中形成社区的模块度都是最大的,即相对于其他算法性能最优,主要是因为Louvain 算法是基于模块度优化的算法,其对模块度的计算有着天然的优势。同时Spectral Clustering 算法对于5 种人工数据集的模块度与Louvain 算法的结果一致,表明谱聚类算法对人工数据集的社区划分的性能优于其对真实网络数据的划分。Block model 算法的模块度在8 种算法中是最低的,即其所划分的社区结构的质量较差。
3.3.3 标准化互信息
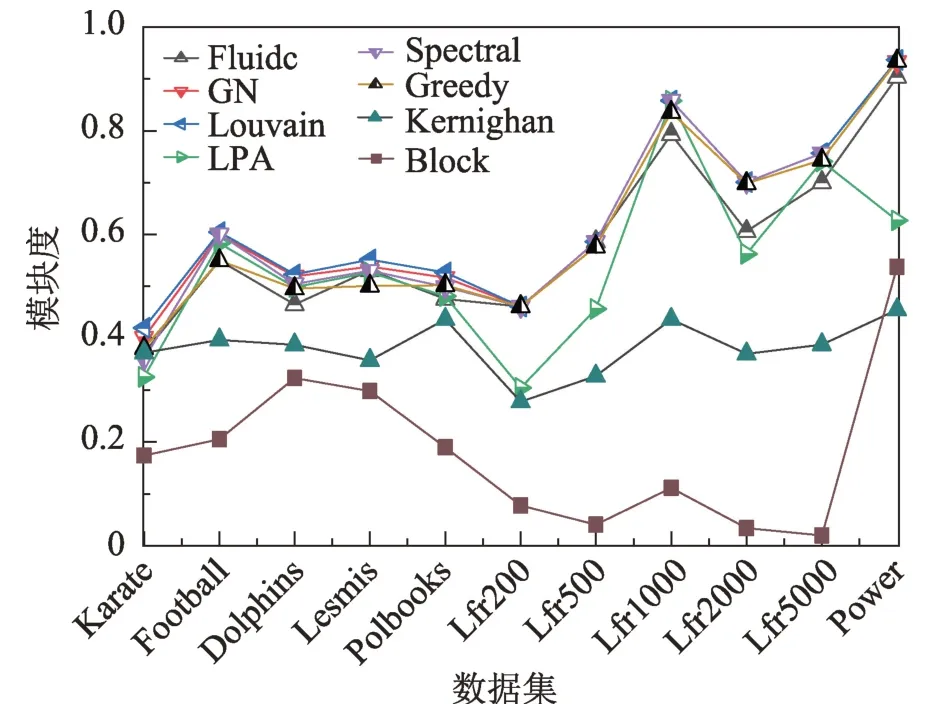
Fig.4 Modularity of 8 methods on datasets图4 8 种算法在数据集中的模块度
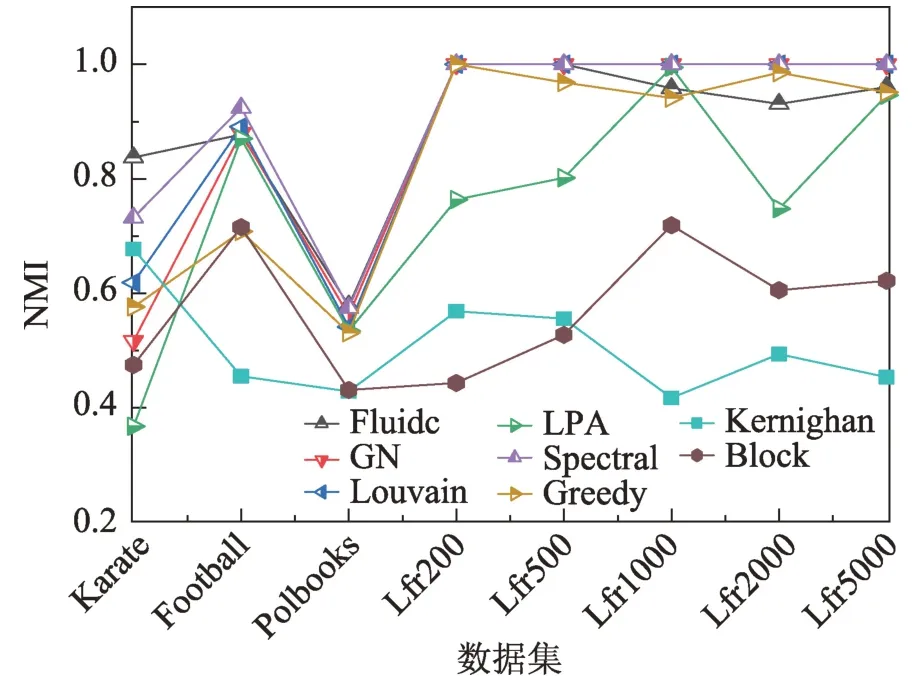
Fig.5 NMI of 8 methods on datasets图5 8 种算法在数据集中的标准化互信息
图5 给出了8 种算法在8 种已知社区结构的数据集中的标准化互信息。结果表明,Louvain 算法、谱聚类算法、GN 算法对于5 种人工数据集的标准化互信息均为1,即这3 种算法对人工数据集的社区划分的所得结果与真实社区结果一致,性能最优。但结合表5,Spectral Clustering 算法的缺点在于需要社区数量作为输入。而Kernighan 算法和Block model 算法在图中处于较低水平,表明这两种算法对于相关数据集的划分结果与实际社区结构有较为明显的差距。
3.3.4 可视化
目前,复杂网络可视化分析软件有50 多种,表7中选择6 种主流常用软件信息进行对比:UCINET、NodeXL、Pajek 和Gephi 属于独立软件,NetworkX 和igraph 属于工具类库。

Table 7 Complex network analysis tools表7 复杂网络分析工具
图6 是NetworkX 应用Karate 数据集绘制的标准社区结构,以及应用8 种算法进行社区发现的结果。从图中可以发现每个算法对数据集的划分都与标准的社区结构有着一定的差距。结合图3、图4 研究发现,模块度大并不代表所划分的结果与实际社区结构相似,如Louvain 算法在Karate 数据集上的模块度高于其他算法,但在NMI 上的结果比Kernighan 算法要低。
4 经典应用场景
社区发现的应用场景非常广泛,Karataş等[76]综述了社区发现算法在犯罪学、公共卫生、政治学、智能广告、定向市场营销、推荐系统、社交网络分析、网络归纳、隐私领域、链接预测和社区演化预测等领域的研究进展。本章探索研究动态社区发现在公共安全、公共卫生、市场营销、推荐系统、网络分析、链接预测和舆论监测等领域的研究进展。

Fig.6 Comparison of results of 8 methods and normalized structure in Karate dataset图6 空手道数据集中8 种算法和标准结构的结果对比
(1)在公共安全领域,社区发现能够识别犯罪用户群体。能够将支持或散布犯罪观念或类似恐怖主义的活动的真人账号或机器人账号建立为社区,从而发现其中有价值的信息。Ferrara 等[77]通过手机通话记录,建立一个基于网络科学、法医学和统计分析原理的计算框架,使用GN 和Newman 快速算法进行社区发现来研究犯罪网络的社区结构和演化,设计出专家系统用以帮助警察分析电话日志记录。Calderoni 等[78]通过研究针对意大利南部地区卡拉布里亚的黑手党组织的大型执法行动的案例来分析社区结构。Sarvari 等[79]使用PageRank 分析网络中犯罪分子的重要程度,通过CFinder 对网络上的犯罪分子的电子邮件地址网络进行社区发现来构建大规模的社交图,并使用人工分析的方法来发现犯罪分子的社交信息,从而能够破坏犯罪社区并找到关键成员。
(2)在公共卫生领域,网络社区中健康相关话题已经引起相关研究人员的关注。Lu 等[80]对医学健康论坛中的话题进行文本聚类,用于构建医学主题模型,从而分析论坛用户对疾病的关注重点。社区发现通常用于发现易患流行病的某些群体的发展动态[81],检测癌症等疾病[82-83],或者用于器官检测[84-85]。
(3)在市场宣传营销方面,社区发现直接用于划分公司的客户类型、智能广告和定向营销[76]。如果公司能够了解其客户类型,就可以提供更好的服务方案。Mosadegh 等[86]根据发现到的客户类型进行定向广告和营销宣传的研究。
(4)在推荐系统领域,社区发现有着十分广泛的应用,通过社区发现将特定目标用户进行分类,可以将同一社区的用户的相关喜好进行相互推荐,能提高推荐成功的概率。Rezaeimehr 等[87]提出了基于时间的推荐算法,该算法主要采用重叠社区发现用于研究。而Gurini 等[88]基于社区的用户推荐算法利用兴趣和情感进行社区发现,从而给用户最终的推荐。Lalwani 等[89]采用社区检测算法通过分析用户-用户社交图来提取用户之间的友谊关系,并采用基于用户项目的协作过滤来进行评分预测,进行推荐。
(5)在网络分析领域,社区发现仍然是一个非常重要的研究领域。社区发展预测是指根据社区过去和现在状态对社区未来形式的预测,这也是社区分析领域的热门话题之一[76]。为了实现社区演变的预测,需要检测动态社区来查看分析社区的演变规律。Bringmann 等[90]利用图演化规则开发了图演化规则挖掘器,并运用到社区演化预测中。İlhan 等[91]提出基于事件预测的特征识别框架来检查网络的各种结构特征,并发现社区特征的最突出子集。该框架通过提取网络结构,确定社区特征的子集,从而能够实现准确的社区事件预测。
(6)在链接预测中,可评估网络成员之间将来链接的可能性,并用于确定虚假链接、丢失的链接和将来的链接。通过社区检测算法找到网络的社区结构,然后计算两个成员之间存在链接的可能性。Valverde等[92]提出了一种基于社区检测的链接预测方法,使用社区发现算法对每个节点进行划分,然后在链接预测中明确使用获得的社区结构信息。Soundarajan 等[93]通过使用Louvain、Infomap 和Link Communities 进行社区划分,使用获得的社区信息来提高链接预测的准确性。
(7)在舆论监测领域,随着智能手机的普遍使用,社交媒体应用越来越频繁,微信、QQ、微博、Facebook、Twitter 等社交应用成为信息传播的主要平台。舆论传播的方式也越来越多,与此同时也带来了许多虚假信息的发布与传播。因此,舆论监测显得尤为重要。Xia 等[94]则是从评论内容中提取语义信息从而构建语义网络,然后通过社区发现方法对网络进行划分,从而进行网络数据分析。
5 挑战
随着大规模在线复杂社交网络的出现,传统的动态社区发现技术面临着一些新的挑战。
(1)网络异质。现实社交网络一般拥有多种多样的异质信息,例如在线社交网络除了包含用户与用户之间的相互关系,还包含用户发布或转发的文本、图片、视频等信息。目前对网络的表示,仅仅是将角色转换为节点,将角色之间的联系转换为边,而忽略了角色之间存在多种类型的联系。Interdonato等[95]尝试使用局部社区发现的方法对多层网络进行划分,而Meng 等[96]则在悉尼科技大学出版物数据集上使用多语义路径聚类方法进行分析研究。该数据集是包含期刊、会议论文、会议记录、章节和书籍等多种信息的异构数据集。SHINE[97]是一种用于情感链接预测的带符号的异构信息网络嵌入框架,可以对情感网络、社交网络和个人资料网络进行网络嵌入,然后将三种特征进行融合并进行优化。
(2)计算效率。随着大规模实时复杂社交网络的出现,对于动态社区发现算法的计算效率要求也越来越高。现有的动态社区发现方法或牺牲准确度提高计算效率,或牺牲计算效率提高准确度,很难同时满足时间复杂性低、发现准确度高和无监督等要求。现实应用场景里,许多方法很难适应复杂的大型实时网络,计算和存储方面的效率也都较为低下。
(3)评价标准。虽然目前多数算法的实验结果都从模块度、NMI 或时间复杂度来与现有算法进行比较,但研究表明,模块度函数有时不能准确地衡量划分出的社区结构的优劣程度[67]。有些模块度较高的社区直观上还不如模块度较低的结果。Takaffoli等[69]尝试将当前网络的模块度与历史网络的模块度线性组合形成新的评价标准,将其命名为动态模块度。Tabarzad 等[70]则将模块度和标准互信息的调和平均数作为新的衡量标准。因此,统一的动态社区发现结果评价标准可能成为动态社区发现未来重点研究方向之一。
6 结束语
本文首先从网络和节点层面对社区发现方法进行了分析,然后根据采用算法的不同将动态社区发现分为四种类型,分别是基于聚类方法的社区发现方法、基于动力学的社区发现方法、基于统计模型的社区发现方法和基于启发式算法的社区发现方法。接着介绍了社区发现方法中模块度、标准化互信息、持久性等常用的评价标准以及在进行仿真实验中常用的真实世界网络和人工合成网络数据集。然后对八种经典静态社区发现算法进行对比实验,使用运行时间、模块度和NMI 评价这些方法在真实网络和人工网络中的性能。随后介绍了动态社区发现方法在公共安全、公共卫生、市场宣传营销、推荐系统、网络分析、链接预测和舆论监测等领域的应用研究。最后从网络异质、计算效率和评价标准三方面提出了动态社区发现目前面临的挑战。
目前对复杂网络的社区发现的研究虽已日渐深入,但仍存在需要深入研究的方向。随着大数据时代的来临,社交媒体的广泛应用,对真实社交网络的动态社区发现的研究仍具有重要意义。在未来的工作中,将进一步研究动态社区发现方法的对比实验,着力于解决网络异质、计算效率和评价标准的挑战,以期在后续研究上有更大突破。
