Attention-CNN 在恶意代码检测中的应用研究
2021-04-11程琪芩孙志强
马 丹,万 良+,程琪芩,孙志强
1.贵州大学计算机科学与技术学院,贵阳 550025
2.贵州大学计算机软件与理论研究所,贵阳 550025
瑞星2019 年上半年中国网络安全报告[1]指出,2019 年上半年共截获病毒样本为1.03 亿个,病毒累计感染次数4.38 亿次,病毒总体数量比2018 年同期上涨32.69%。所有恶意代码攻击中,针对Windows系统的攻击已经超过了67%。此外,病毒种类随着各种技术的进步而大幅度增长。
为了检测各种层出不穷的恶意代码,反病毒研究者需要不断获取并了解恶意代码的相关行为,主要通过人工分析揭示恶意代码的具体函数以达到解除该病毒的目的[2-3],但是这种不经过前期处理直接分析恶意代码是一个比较耗时的工程。传统方法是从恶意代码的反汇编指令中生成特征向量、控制流图并比较[4-6],但是这种比较对象仅是恶意代码的代码部分,对打包样本或重要的攻击行为隐藏在数据部分的恶意代码是无效的。
为了同时检测到恶意代码数据部分和代码部分的攻击行为,Nataraj 等人[7]将有标签的恶意代码转化为灰度图,并利用k近邻算法对未标记的恶意代码样本进行分类,这种方法即使在恶意代码是混淆的情况下也能够得到较高的准确率,但是该方法最终通过GIST(generalized search trees)算法提取图片纹理特征,而该算法复杂度高,导致提取特征的效率不高。Ahmadi 等人[8]在Nataraj 等人[7]的基础上提出多特征梯度增强算法对恶意代码进行分类,该方法有效地提高了包括压缩样本在内的恶意代码分类精度,但是用传统机器学习方法难以提取高维度的特征,导致检测效果不明显。
卷积神经网络在图像[9]、自然语言处理[10]、文本处理[11]等领域得到迅速发展,由于它能自动学习输入数据特征而无需人工参与,于是网络安全研究者们将神经网络引入到网络安全的各个领域。龙廷艳等人[12]利用自编码网络对恶意代码进行检测,这种方法能够比传统机器学习方法(随机森林、支持向量机(support vector machine,SVM))得到较好的检测效果,但是也存在无法检测混淆恶意代码的问题。Cui等人[13]采用了蝙蝠算法(bat algorithm,BA)解决了恶意代码家族样本数量不均匀导致的过拟合问题,并结合卷积神经网络对Nataraj 等人[7]提出的方案进行了改进,这种方法一定程度上检测出混淆恶意代码并得到较高的准确率。事实证明将恶意代码转化为灰度图后用深度学习的方法提取特征比使用机器学习方法得到更高的准确率[14-15]。
虽然将恶意代码转化为灰度图后,用深度学习的方法对恶意代码进行检测或分类都能得到很好的检测效果,同时还能在一定程度上检测到混淆代码,但是这样的方法也存在一定的缺陷,将恶意代码转化为灰度图已失去原有的可解释性,不能解释恶意代码存在哪些恶意行为。而注意力机制能够将网络中间层的特征赋予相应的权重并可视化[16],本文提出Attention-CNN 模型,在将恶意代码分类的同时得到注意力图,该注意力图能够对恶意代码的特殊区域进行强调,以便利用得到的注意力图进行下一步分析,找到恶意代码存在的恶意行为,保证在良好的检测效率下得到恶意代码中的行为。
本文的工作如下:
(1)将注意力机制结合卷积神经网络应用于恶意代码检测方向,构建网络模型Attention-CNN,对恶意代码进行分类并对恶意代码灰度图的重要区域进行可视化。
(2)通过从注意力层得到的注意力图(对恶意代码灰度图的强调部分)与原始恶意代码二进制文件的映射关系,找到具有重要特征的位置,再利用反汇编工具分析该位置存在的恶意行为。
1 卷积神经网络
卷积神经网络是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一[17-18],能进行有监督学习和无监督学习,其隐含层内卷积核的参数共享使得卷积神经网络能够以较小的计算量提取特征。给定一幅图,卷积神经网络能提取其特征并通过全连接层进行输出,达到分类目的。
(1)卷积层
在卷积神经网络中,卷积层是通过卷积过滤器实现对输入图片的特征提取,如xi,j(0 ≤i<W,0 ≤j<H)表示大小为W×H的输入图片,其处理公式为:

式中,wp,q(0 ≤p,q<M)表示大小为M×M的卷积过滤器的权值。
通常情况下,在卷积处理过程中,卷积过滤器往往如图1 所示有多个通道,并且多个通道的过滤器同时进行特征提取,例如,当输入图片是xi,j,k(0 ≤i≤W,0 ≤j≤H,0 ≤k≤K),即图片大小为W×H,通道为K,其卷积处理公式为:
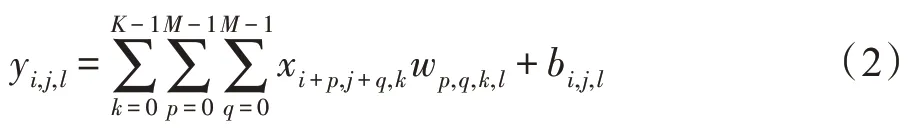
式中,bi,j,l表示神经网络的偏置,wp,q,k,l表示神经网络的权重。
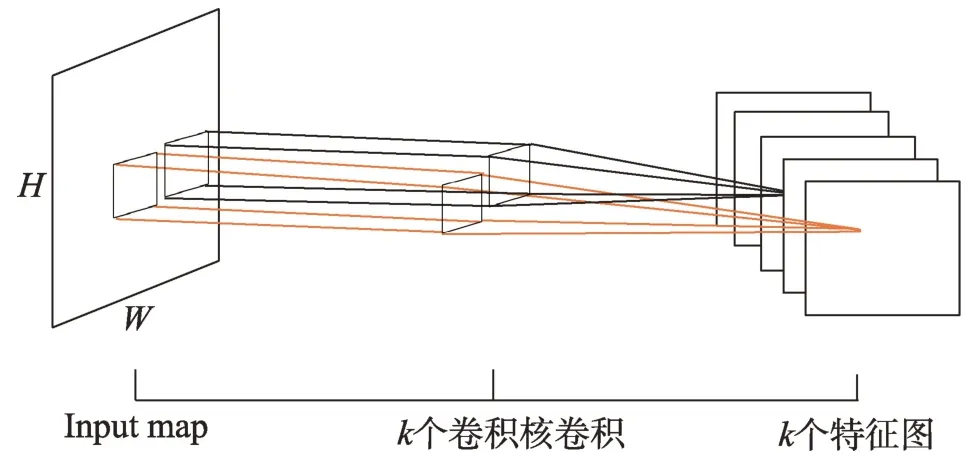
Fig.1 Multichannel convolution processing图1 多通道卷积处理
(2)全连接层
经过多个卷积层和池化层后,模型往往会连接着1 个或1 个以上的全连接层。全连接层中的每个神经元与其前一层的所有神经元进行全连接,可以整合卷积层或者池化层中具有类别区分性的局部信息。
(3)激活函数
输入图片在经过卷积处理后,会将其结果经过激活函数处理,使模型有更强大的表达能力,本文的卷积层以及全连接层的激活函数使用线性整流函数(rectified linear unit,ReLU),在x<0 时,硬饱和,x>0 时,导数为1,保持梯度不衰减,从而缓解梯度消失问题,能更快收敛,表达式为:

(4)输出层
模型最后是输出层,将全连接层的输出结果传递给一个函数,即Softmax 逻辑回归(Softmax regression),该层也可称为Softmax 层(Softmax layer),它将多个神经元的输出映射到(0,1)区间内,其输出值可作为模型检测为某类的概率,从而达到多分类的效果,其表达式为:

式中,wi为输出层的权重,b为输出层的偏置,σi(z)是Softmax 函数,作为输出层的激活函数。
2 注意力机制
注意力机制是一种常用于深度学习中对特征进行强调的技术,为了提高翻译任务的性能,首先应用于自然语言处理领域[19]。随着技术的进步,注意力机制也能应用于卷积神经网络中,对图片的重要部分进行可视化[16]。
本文所采用的注意力机制的原理如图2 所示,首先从模型的第3 个卷积层中得到zi,j(0 ≤i≤W,0 ≤j≤H),和普通卷积层一样,将得到的zi,j传输到注意力层,从而计算出图像的注意力权重,并传送到下一层。为了得到ˆ,注意力机制计算zi,j的每个区域的注意力权重即ai,j,注意力机制公式为:
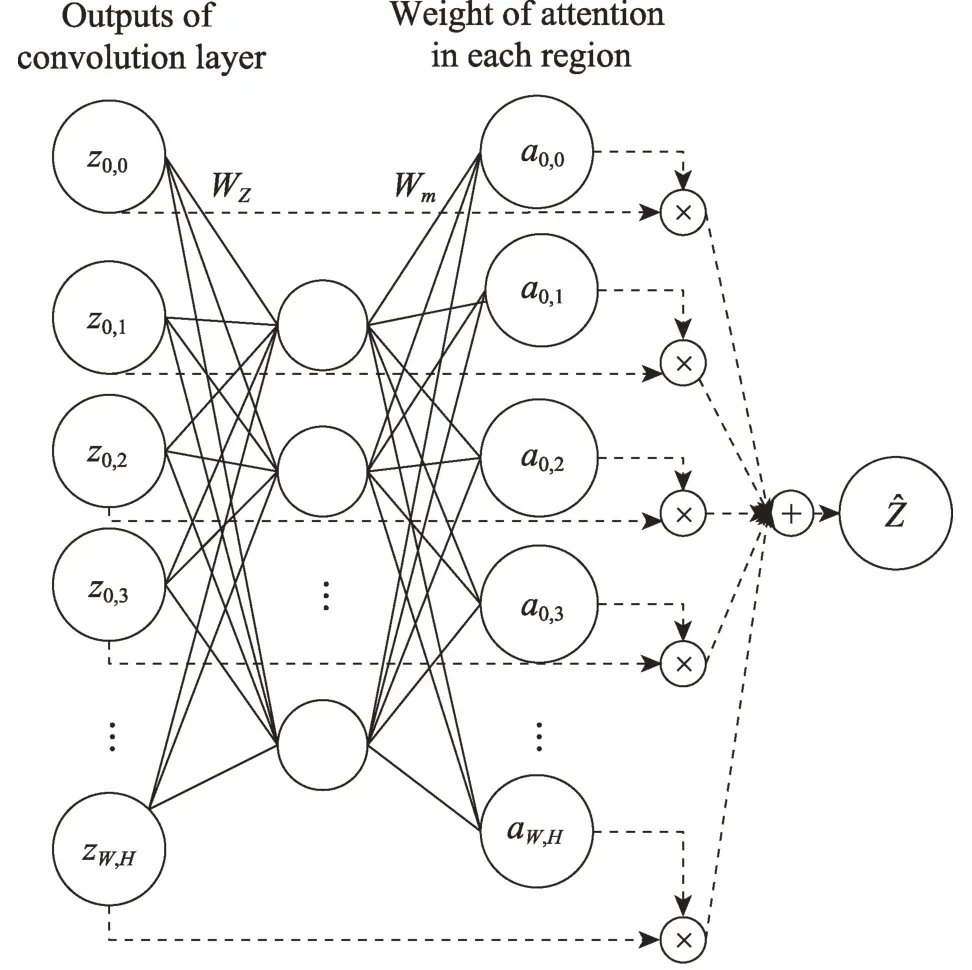
Fig.2 Attention mechanism图2 注意力机制

式中,Z=(zi,j) 表示从卷积层中得到的特征图,A=(ai,j)表示对每个输入特征强调的总和。

式中,zi,j表示从上一个卷积层中得到的特征图的某个区域,ai,j表示特征图中某个区域的注意力权值。
总的来说,本文所使用的注意力机制算法如算法1 所示,输入是从第3 个卷积层得到的特征图,输出是特征图的注意力权重。
算法1注意力机制算法
输入:第3 个卷积层输出的特征图zi,j。
输出:注意力权重。

3 Attention-CNN 检测模型
Attention-CNN 恶意代码检测模型框架如图3 所示,本章将从恶意代码可视化、模型构建、模型训练几个方面介绍该检测框架的具体过程。首先是处理数据,即将恶意代码转化为灰度图,具体过程将在3.1节介绍,其次是构建带有注意力机制的网络模型并结合灰度图对网络模型进行训练。接着用待检测样本对网络模型进行检测,最后是结果分析,结果分析将在第5 章进行详细阐述。
3.1 恶意代码可视化
恶意代码的恶意行为不仅仅存在于代码部分,还可能隐藏在恶意代码的数据部分。为了更有效地检测恶意代码,本文将恶意代码二进制文件转化为灰度图,这样可以以统一的方式处理样本的代码部分和数据部分。具体方法如图4,首先将给定的恶意代码二进制文件的每8 位组合,其次遍历整个二进制文件,将组合后的8 位二进制排列为无符向量。而8位二进制转化为十进制数后,其范围是0 到255,刚好是灰度图像素值(0:黑色,255:白色),最后将向量转换为一个二维数组,即灰度图。图像的宽度是固定的,高度可以根据文件大小而变化。
转化后的灰度图中,同一个家族的灰度图其纹理是相似的,而不同家族的图像纹理又有一定的区别。图5(a)、图5(b)分别是Hoax.Win32.Renos 家族以及Trojan.Win32.BHO 家族的灰度图,可以观察到同一个家族内的恶意代码纹理是相似的,而两个不同的家族其纹理又是有一定的区别。
3.2 模型构建
Attention-CNN 由多个卷积层堆叠而成,本文的检测模型由3 个卷积层、1 个注意力层以及2 个全连接层组成。
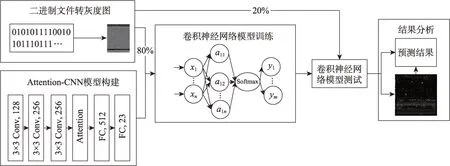
Fig.3 Workflow of this paper图3 本文的工作流程

Fig.4 Binary to grayscale图4 二进制转灰度图

Fig.5 Texture of malware family图5 恶意代码家族图片纹理
卷积操作存在两个问题:
(1)随着网络层数的加深,输出的特征图越来越小;
(2)图像边界信息丢失,即有些图像角落和边界的信息发挥作用较少。
因此需要在卷积层加入padding 填充,常用的padding 填充有“valid”和“same”,当输入图片大小为W×H,卷积核大小为M×M,strides=[1,1,1,1],padding=valid,则卷积层输出的图片大小为(W-(M-1))×(H-(M-1)),即相应图片的长和宽都减少了M-1 个单位。若要图片大小保持不变,则需要在卷积处理前对图片的边缘用0 填充,即“same”填充,在与valid 填充有相同的输入图片大小、卷积核大小以及strides下,经过卷积后得到的特征图的大小为((W+2P)-(M-1))×((H+2P)-(M-1)),其中P=(M-1)/2。
本文最后会通过得到的注意力图回溯到原来的灰度图以及原始恶意代码,以分析该重要位置存在的恶意行为,为了使注意力图与输入图片能有位置上的对应关系,本文在卷积层“same”填充,同时省去池化层,以保持图片大小不变,详细参数如表1 所示。
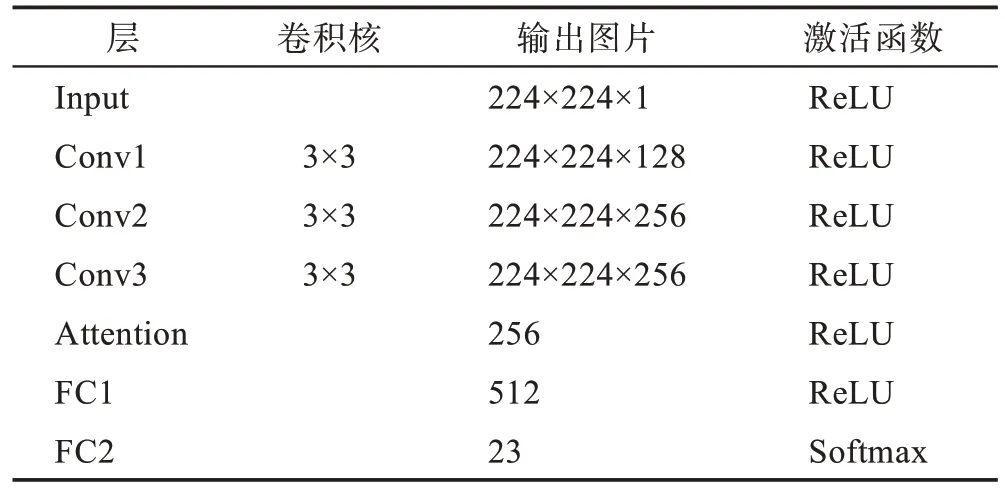
Table 1 Model parameters of convolutional neural network表1 卷积神经网络模型参数
3.3 模型训练
卷积神经网络的训练过程分为两个阶段:第一个阶段是数据由低层次向高层次传播的阶段,即前向传播阶段;另外一个阶段是当前向传播得出的结果与预期不相符时,将误差从高层向低层进行传播训练的阶段,即反向传播阶段,训练过程如图6 所示。训练过程为:
(1)网络模型权值的初始化。
(2)输入数据经过卷积层、全连接层的向前传播得到输出值。
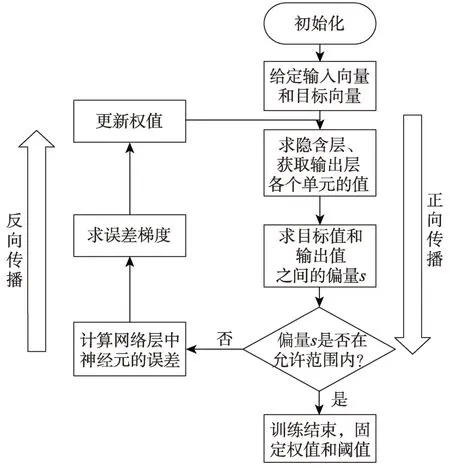
Fig.6 Model training process图6 模型训练流程
(3)求出网络的输出值与目标值之间的误差。
(4)当误差大于期望值时,将误差传回网络中,依次求得全连接层、卷积层的误差,通过梯度更新权重和偏置;当误差等于或小于期望值时,结束训练。
本文的恶意代码检测模型训练与检测过程如算法2所示,具体分为两步:首先是构建带有注意力机制的卷积神经网络模型;其次用3.1 节中可视化的恶意代码灰度图输入到检测模型中训练并检测。
算法2Attention-CNN 检测模型训练与检测过程
输入:G={Mi},i={1,2,…,n},i表示输入的序号,Mi表示经恶意代码转化的灰度图,G表示灰度图集合。
输出:R={ri}和A={ai},R表示检测结果集合,ri表示第i个恶意代码的检测结果。A表示注意力图,ai表示第i个恶意代码对应的注意力图。
1.构建Attention-CNN 检测模型
1.1 增加一个包含128 个神经元、卷积核大小为3×3 的卷积层,填充为Same;
1.2 增加一个包含256 个神经元、卷积核大小为3×3 的卷积层,填充为Same;
1.3 增加一个包含256 个神经元、卷积核大小为3×3 的卷积层,填充为Same;
1.4 增加注意力层
1.5 注意力层得到的权重与上一个卷积层得到的特征相乘;
1.6 增加包含512 个神经单元的全连接层,激活函数为ReLU;
1.7 增加包含23 个神经单元的全连接层,激活函数为Softmax;
2.Attention-CNN 模型训练与测试
2.1 参数初始化;
2.2 while 不满足提前终止训练条件do:
2.3 while 训练集剩余数据不为空do:
2.4 模型训练输入一组小批量数据样本;
2.5 使用Softmax 函数进行数据样本分类;
2.6 使用Adam 梯度下降优化算法更新权重值;
2.7 end while
2.8 使用测试集数据验证模型;
2.9 end while
4 实验过程与结果分析
4.1 数据集
(1)Data1:本文的模型最终目的是得到分类结果以及注意力图,实现用注意力图与输入图片以及原始恶意代码进行对比分析,因此所需的数据集是原始恶意代码并非现成的灰度图。考虑到这个因素,采用VX Heaven[20]上公开的数据集作为本实验的数据集。该数据集曾用于2017 年Vyas 等人[21]、2018 年Dam 和Touili[22]以及2019 年Dovom 等人[23]的论文中,包含了48.88 GB 的恶意代码原始恶意代码,本文选用其中的9 644 个样本进行处理。样本类别以及数量如图7 所示,为了便于显示,图中将恶意代码家族的名称每节用两个字符显示,如“Backdoor.Win32.Cecknogtihuan”改为“Ba.Wi.Ce”。
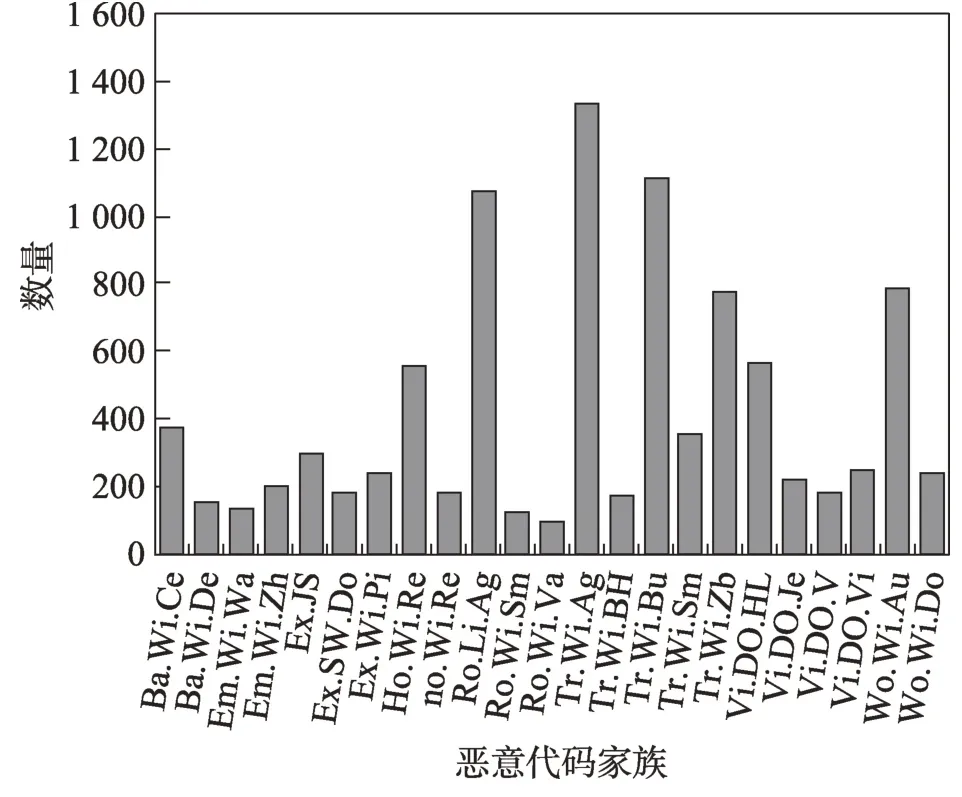
Fig.7 VX Heaven dataset图7 VX Heaven 数据集
(2)Data2:目前用灰度图对恶意代码进行分类的方法中,有一部分研究者使用的数据集是Nataraj 等人公开的Malimg 数据集[7],该数据集有25 类共9 339个样本。为了和现存的恶意代码分类模型对比,本文在Malimg 数据集上与其他方法进行训练并对比实验结果。样本类别及数量如图8 所示。
4.2 优化模型
4.2.1 优化函数对模型的影响
VX Heaven 数据集中的二进制恶意代码转化成灰度图后,将得到的灰度图按照2∶2∶6 的比例分别得到验证集、测试集和训练集,并输入到本文的Attention-CNN 深度学习模型中训练。在训练阶段,不同的优化函数会得到不同的训练效果,为了得到更好的训练效果,本文对比了多个优化函数对函数收敛的影响。图9 显示Adam、Momentum、Adadelta、SGD 几个优化函数在模型中的收敛情况,其中Adam和Momentum 都能快速收敛,但Adam 收敛效果较好,而Adadelta 和SGD 效果比较差,故本文使用的优化函数是Adam。其他参数设置如表2 所示。
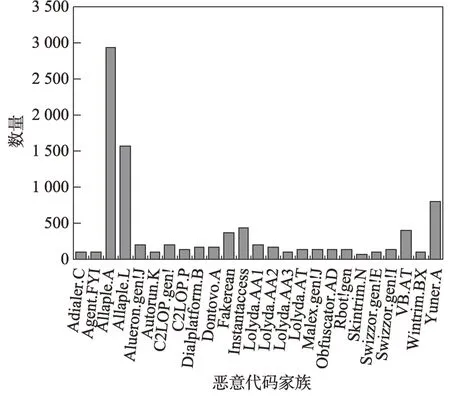
Fig.8 Malimg dataset图8 Malimg 数据集
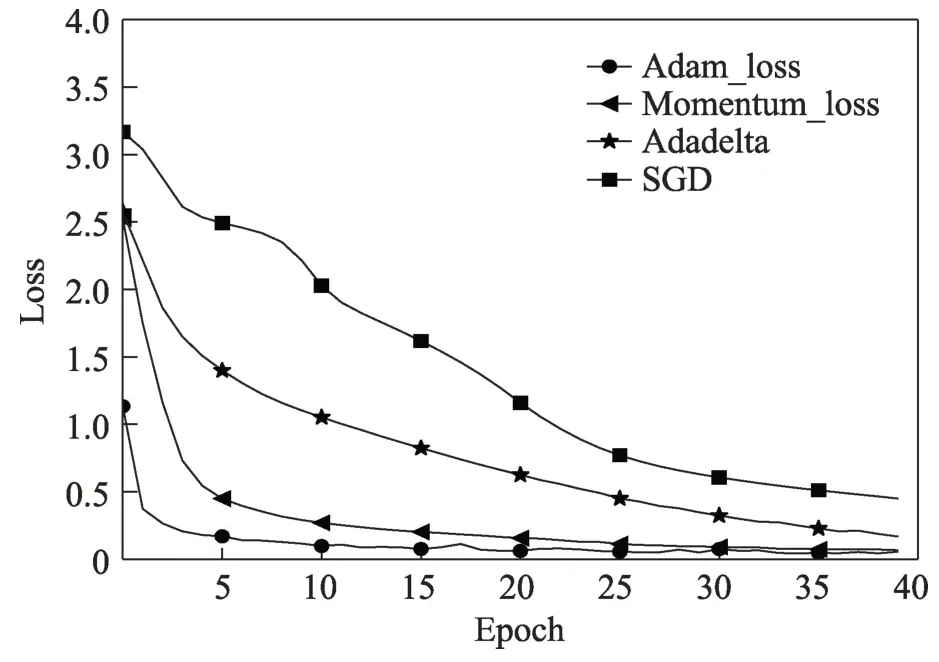
Fig.9 Influence of optimization function on loss function图9 优化函数对损失函数的影响

Table 2 Model parameter setting表2 模型参数设置
4.2.2 不同大小的输入图片对模型的影响
CNN 模型输入图片的尺寸是固定的,但是不同的输入图片大小会使CNN 得到不一样的效果,为了得到更适合的输入图片的尺寸,本文以64×64、96×96、192×192、224×224 的输入尺寸来训练模型。表3记录了各个尺寸的图片的相应评价指标,可以看出,图片尺寸越大,其相应的准确率(Accuracy)、精度(Precision)、召回率(Recall)以及F1-score越高。
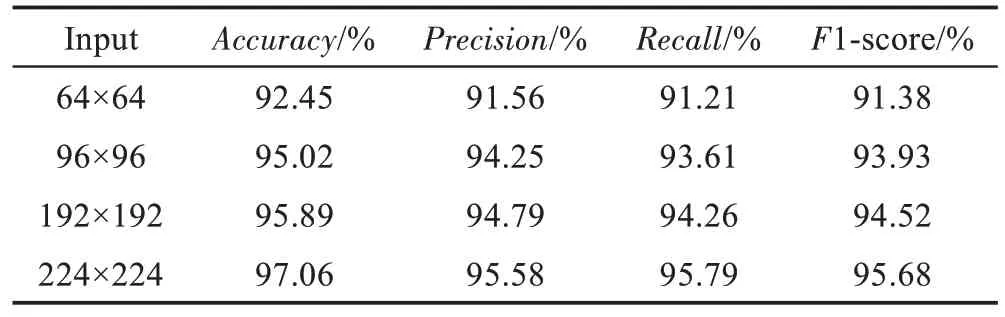
Table 3 Comparison of input pictures of different sizes on each indicator表3 不同大小的输入图片在各个指标上的对比
此外,图10 是用不同大小的图片作为模型输入而得到的混淆矩阵。该图显示,输入尺寸越大,其混淆矩阵得到预测标签和真正标签更匹配(大部分值都对应在正角平分线处)。为了得到更好的分类效果,本文设定模型的输入图片大小为224×224,尽可能保留恶意代码中的有用信息。
4.3 评价指标
训练及测试的过程中,将使用不同的评价指标评估本文模型,本文的评价指标主要有4 个,分别为Accuracy、Precision、Recall以及F1-score。
Accuracy表示分类的准确率,即对给定的数据,分类正确的样本数占总样本数的比例,其计算公式为:
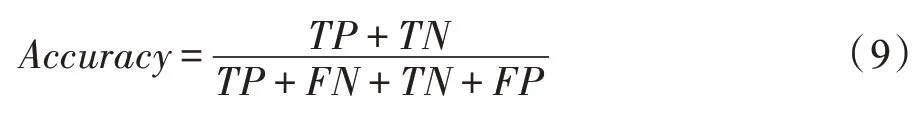
Precision是指在预测为正确样本中真正正确样本所占的比例,其计算公式为:

Recall指的是预测正确的某类样本占该类总样本的比例,其计算公式为:

F1-score 是精确率和召回率的调和平均。因为精确和召回率两个指标是相互矛盾的,当检测结果的精确率高时,其召回率往往会相应降低,反之亦然。为了调和这样的矛盾,本文引入了F1-score,其计算公式为:
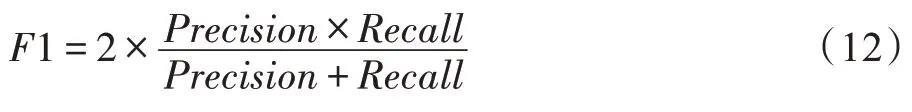
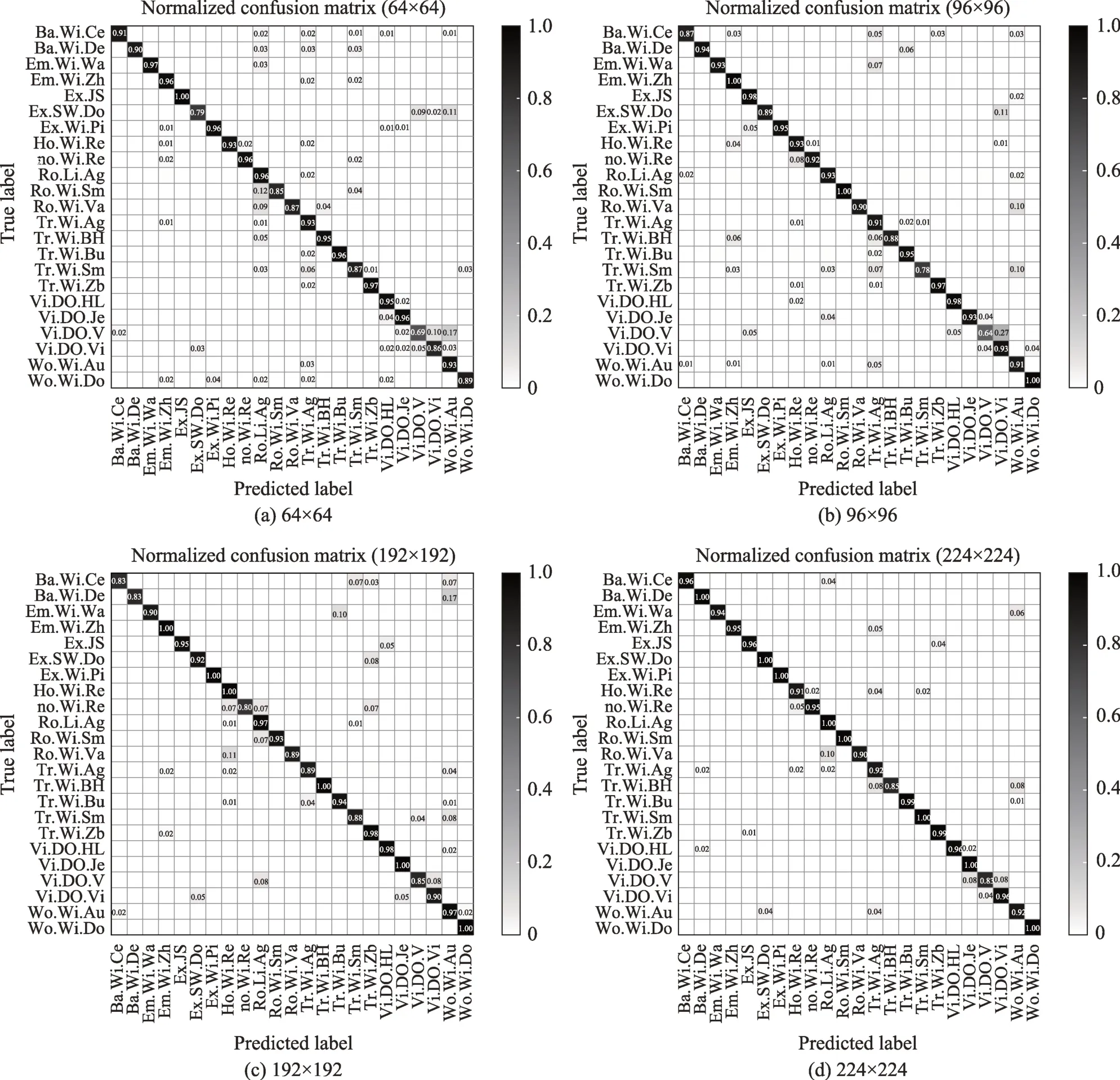
Fig.10 Confusion matrix obtained from different input images in training models图10 不同输入图片训练模型得到的混淆矩阵
其中,TP表示样本预测为某个家族,实际上也是该家族;FP表示样本预测为某个家族,实际上不是该家族;TN表示样本预测不是某家族,实际上是该家族;FN表示样本预测不是某家族,实际上也不是该家族。
4.4 对比分析
4.4.1 在数据集VX Heaven 下的对比实验
为了证明本文方法的检测效果,将传统的机器学习方法和没有注意力机制的CNN 与本文方法进行对比实验,并统计检测结果的Accuracy、Precision、Recall以及F1-score 4 个指标。
其中机器学习方法的参数设置如下:
(1)用网格搜索算法对RF(random forest)寻优,最优的参数如表4 所示,表中n是树的棵数,m是最大特征数,d是最大树的深度,k是最小样本数。

Table 4 Random forest parameter setting表4 随机森林参数设置
(2)SVM 分类的影响因素主要是C(错分惩罚因子)、g(RBF 核函数的控制因子值),网格寻优(Gridsearch)确定最优值为C=128,g=0.12。
(3)J48.trees参数设置主要有C=0.25,M=2。
表5 记录了传统机器学习方法、不带注意力机制的CNN(参数与表2 相同)以及本文的Attention-CNN的各个指标的情况。RF、SVM、J48.trees 都是机器学习方法中常用的分类算法,但是相比本文方法其准确率、精确度、召回率以及F1 值都不高。同样不带注意力机制的CNN其相应的评价指标略低于本文方法。
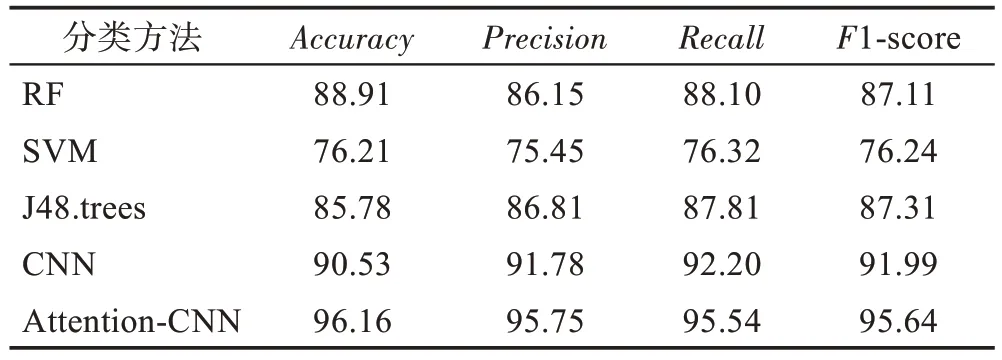
Table 5 Comparison of Attention-CNN with other methods表5 Attention-CNN 与其他方法的对比结果 %
4.4.2 在Malimg 数据集下的对比实验
本文构建的模型能够在得到注意力图的同时对样本进行分类,为了验证本文提出的模型的分类效果,用相同Malimg 数据集与文献[13]模型进行训练并与本文方法进行对比。为了便于说明,将文献[13]中使用的模型称为vsNet,将本文使用的模型称作Attention-CNN,对比结果如图11。在Malimg 数据集下的实验证明,vsNet 模型检测的准确率是94.50%,而本文的Attention-CNN 模型能够达到98.80%的准确率,相比于vsNet的方法提高了4.3个百分点。同时从图11 中可以看出,Attention-CNN 在25 个epoch 附近,函数已经收敛,损失函数基本达到稳定,精确度基本达到最大值。而vsNet 模型在100 个epoch 的时候还未达到稳定,精度缓慢增加,经过后续的训练,最终在200 个epoch 的时候达到稳定。因此本文提出的分类模型能够得到较好的分类效果,训练时间相对较短。
5 利用注意力图对样本进行额外分析
5.1 通过注意力图获取恶意代码行为信息
本文的Attention-CNN 模型,最终会输出分类结果以及注意力图。本节对得到的注意力图进行分析。
图12 展示本文的恶意代码分析流程,完成模型训练阶段后,模型对样本进行检测,最终会得到相应的分类结果和注意力图。接下来将模型输出的注意力图用于人工分析。当重要区域在代码部分,则用IDApro 将二进制文件反汇编,将注意力图的重要区域位置对应到二进制文件的相应位置,并提取该位置的函数从而得到恶意代码的行为信息,当重要区域落在数据部分则提取相应的资源文件。
得到的注意力图如图13 所示,注意力图中标注了该样本特有的特征位置,图中标有颜色的点就是含有该样本的重要字节序列位置,当灰度图中的位置是确定的时候,则可将该位置对应到二进制文件的相应部分,后续可通过IDApro 找到该部分对应的函数,以分析该恶意代码的行为。
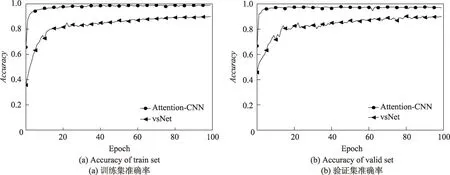
Fig.11 Accuracy of Attention-CNN and vsNet图11 Attention-CNN 和vsNet的准确率
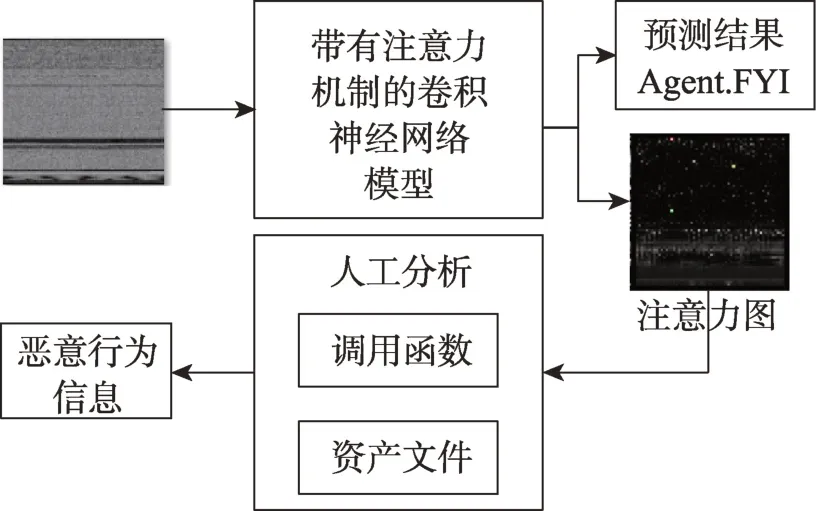
Fig.12 Workflow of manual analysis图12 人工分析工作流程
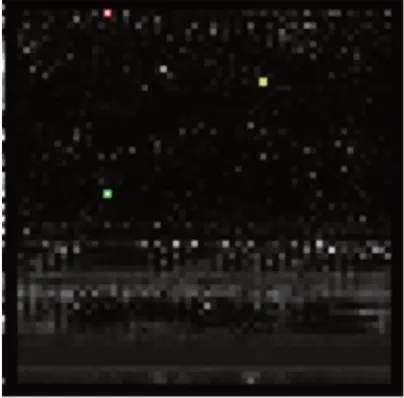
Fig.13 Attention map图13 注意力图
Nataraj 等人[7]指出,通过二进制转换而来的灰度图,其各个部分都对应着二进制文件的相应部分,如图14 是Trojan.Donto.vo.A 变种的相应部分在灰度图中的显示情况,其中.text 表示二进制文件的代码部分,.rdata 和.data 都表示二进制文件的数据部分,最后一部分是.rsrc 部分,它包含模块的所有资源以及应用程序所使用的图标。因此当注意力图的重要位置在代码部分,则提取恶意代码的函数,当注意力图的重要位置在数据部分以及资源部分时,则提取恶意代码的资源文件。

Fig.14 Section division of grayscale image图14 灰度图的节划分
5.2 对Backdoor.Win32.Agobot.lt的分析
图15左图是Backdoor.Win32.Agobot.lt灰度图,属于Worm:Win32/Gaobot 家族,它能够通过IRC(Internet relay chat)执行来自远程服务器的命令。除此之外,该家族能够通过拦截HTTP/FTP 通信来窃取登录信息[24]。图15 右图是本文模型得到的Backdoor.Win32.Agobot.lt的注意力图,本文将该恶意样本的二进制文件用IDApro 来反汇编,通过注意力图中的标有重要信息的位置找到原文件中的相应位置。图15右中标有红色的点对应到源文件的sub_401356函数,通过分析得到,该位置是一个能够连接到IRC 服务器并进入聊天室接收来自远程服务器的指令。标有绿色点对应到源文件的sub_410F80 函数,这是一个用于接收截获的HTTP 通信的内容的函数,并检查内容是否包含字符串,例如“PAYPAL”或“paypal.com”。
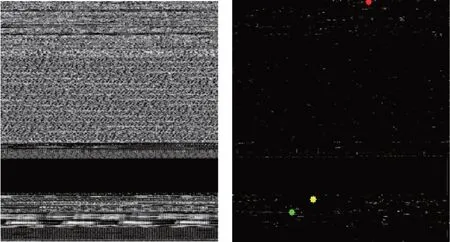
Fig.15 Grayscale and attention map of Backdoor.Win32.Agobot.lt图15 Backdoor.Win32.Agobot.lt灰度图和注意力图
5.3 对Trojan-Banker.Win32.Banbra.r的分析
图16 左图展示的是Trojan-Banker.Win32.Banbra.r灰度图,这是一种TrojanSpy:Win32/Banker 家族的恶意样本,其设计目的是通过输入键盘和鼠标来窃取银行账户信息[25],图16 右图是其通过本文方法得到的注意力图,其中红色的地方表示权重最高的位置,通过该位置找到了源文件中的sub_480A84,这是一个通过电子邮件发送操作系统版本、键盘记录、截图等信息的函数。此外黄色地方表示权重第二大的位置,该位置映射到源文件的“√”和“×”,这是存在于可执行文件中,并由以Delphi为按钮图标生成的资源文件,位图数据被认为具有很高的重要性,因为Delphi经常被用于TrojanSpy:Win32/Banker,具有标识作用。

Fig.16 Grayscale and attention map of Trojan-Banker.Win32.Banbra.r图16 Trojan-Banker.Win32.Banbra.r灰度图和注意力图
分析结果表明,所提出的方法所得到的注意力图中的区域所对应的字节序列在人工分析恶意代码样本行为时提供了有用的信息。此外,即使每个样本的位置发生变化,该方法也可以有效提取相应的特征。
6 结束语
针对目前网络中存在大量的恶意代码的攻击问题,本文提出了基于注意力机制的卷积神经网络模型,对恶意样本进行检测和分析,模型最终输出待检测恶意代码样本属于哪个家族,同时得到相应的注意力图。通过与传统的机器学习以及不带注意力机制的CNN 进行比较,本文方法在准确率、召回率、以及F1 值都有较高的值。在Malimg 数据集下与文献[13]的方法进行比较,其准确率提高了4.3 个百分点,取得较好的检测效果。通过模型输出的注意力图,本文获取到恶意代码的重要特征区域并通过与恶意代码二进制文件的映射关系进行人工分析,实验证明,本文方法能够获取恶意代码存在的行为,弥补传统灰度图形式的恶意代码检测方法中的恶意代码不可解释性。
本文提出的检测方法可能面临以下挑战:
(1)本文通过将VX Heaven 数据集中的恶意代码转换为灰度图,其相应家族之间的图片纹理区别不大,导致分类的准确度并没有使用Malimg 数据集高,但Malimg 数据集中只有现成的图片,没有原始恶意代码,导致无法做进一步分析。
(2)本文在VX Heaven 数据集以及Malimg 数据集上都得到较好的检测效果。但是现如今的恶意代码与VX Heaven 或Malimg 数据集存在一定的差异,因此下一步工作将收集比较新的恶意代码样本,使模型在现代恶意代码中有更好的泛化能力。
