基于改进PSO-LSSVM模型的变压器绕组热点温度预测
2021-04-10卢银均刘红云王梁伟
刘 闯,卢银均,刘红云,向 晓,王梁伟
(国网湖北省电力有限公司荆门供电公司,湖北 荆门 448000)
0 引言
变压器是电力系统的核心设备之一,其安全稳定性是电网稳定运行的必要条件[1]。变压器的使用寿命与其内部温度及热量散失密切相关。绕组热点温度是限制变压器运行负载的主要因素,绕组温度过高,会对变压器的绝缘造成不可逆损害,严重影响变压器的使用寿命[2]。因此,及时掌握变压器绕组温度变化情况,做好绕组热点温度预测工作,对保障电力系统稳定运行具有重要意义。
目前,国内外专家已对变压器绕组热点温度进行了大量研究。国际上推荐的绕组热点温度计算公式来源于IEEEC57.91 和IEC354 导则[3],但这些导则没有考虑环境温度的影响。随着智能算法的兴起,大量智能算法被应用到变压器绕组热点温度预测领域。文献[4]通过监测装置获取变压器端部温度、顶层、中层和底层油温,建立了基于灰色神经网络的变压器绕组热点温度预测模型,取得了较好的预测效果,但预测模型的输入量具有一定的局限性。文献[5]采用Levenberg-Marquardt 算法对BP 神经网络进行改进,建立了变压器绕组热点温度预测模型,并采用实测数据对预测模型进行检验,结果表明,三层BP神经网络的预测效果最好,但BP神经网络易陷入局部最优解。文献[6]根据实验室模拟变压器的实测数据,提取变压器绕组热点温度预测模型的输入量,采用遗传算法(Genetic Algorithm,GA)优化支持向量机(Support Vector Machines,SVM)参数,建立了基于GA-SVM 的变压器绕组热点温度预测模型,预测效果优于BP和Elman神经网络,但预测精度有待提高。
针对上述变压器绕组热点温度预测方法中存在的不足,本文在粒子群算法(Particle Swarm Opti⁃mization,PSO)基础上,采用收缩因子对粒子速度更新方式进行改进,加强粒子在寻优过程中的搜索能力,提出了采用PSO 对最小二乘支持向量机(Least Squares Support Vector Machines,LSSVM)参数寻优的方法,建立变压器绕组热点温度预测模型,并对该方法的预测效果进行验证。
1 算法介绍
1.1 LSSVM算法
LSSVM是基于SVM的一种改进方法,它遵循结构风险最小化原则,其核函数的选择与SVM 相同。二者的不同点在于,LSSVM采用平方项作为优化指标,并以等式约束代替SVM 的不等式约束[7]。LSS⁃VM 结构简单,对小样本非线性问题处理效果较好,在回归、预测领域应用广泛,LSSVM 回归的原理及步骤可参考文献[8]。
1.2 PSO算法
PSO 是一种基于群体搜索的智能算法,起源于飞鸟搜索食物,也就是利用个体间保持竞争又相互合作,在复杂的空间中找到最优解。因其具有简单、容易实现且需要调节的参数少等优点,常被用于回归算法的参数寻优[9]。
假设D 维空间存在种群X=( x1,x2,…,xn),该种群包含n 个粒子。将其中的第i 个粒子看做是D 维空间中的一个向量Xi=[ xi1,xi2,…,xil]T,即在D 维空间中第i 个粒子的位置。根据目标函数计算D 维空间中各粒子位置Xi的适应度值。第i个粒子速度的向量为Vi=[vi1,vi2,…,vil]T,个体极值的向量为Pi=[ pi1,pi2,…,pil]T,群 体 极 值 的 向 量 为 Pg=[ pg1,pg2,…,pgl]T。两个极值通过迭代更新粒子的速度和位置,即:
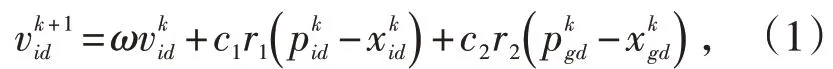
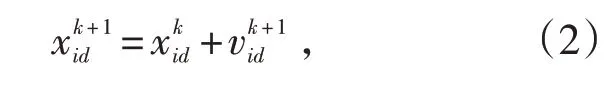
式中,d=1,2,…,D;i=1,2,…,n;k为当前迭代次数;vid为当前速度;c1、c2为加速因子,且c1、c2均大于0;ω为惯性权重;r1和r2为随机函数,取值区间为[0,1];和为D 维上第i 个粒子在k+1 次迭代的位置和速度。
PSO 算法在搜索过程中过度依赖Pbest和gbest,搜索能力有限。本文提出在PSO 算法中引入收缩因子,收缩因子的变化既能保证PSO算法的收敛性,又不受速度边界的影响,加快种群全局搜索的同时又能增强粒子的局部搜索能力[10-11]。速度更新公式为:

式中:z为收缩因子;φ为总加速因子;kmax为总迭代次数。K 为收缩系数,用来控制PSO 的全局和局部搜索能力;当其趋近1 时,会造成大量的全局搜索行为,导致PSO 算法收敛慢;当其趋近0 时,大量的局部搜索导致收敛过快。
仿真分析证明,在对多维函数进行优化时,引入收缩因子的PSO算法在初始阶段具有良好的全局搜索能力,而后期局部寻优能力增强,收敛性能良好,因此被广泛应用。
2 改进PSO-LSSVM预测模型
研究表明,LSSVM 算法适合小样本回归,具有较高的预测精度,但预测效果受惩罚因子C 和核函数参数σ的影响,当C 和σ取值不当时,容易出现欠学习或过学习现象,均不利于样本回归。因此有必要采用寻优能力更强的改进粒子群算法及LSSVM的最佳参数组合。本文基于改进PSO-LSSVM 预测模型进行建模,流程如图1所示。具体步骤如下。
(1)对变压器绕组热点温度样本进行预处理,样本数据由不同类别的数据组成,且单位均不相同,若直接建模,通过特征向量内积计算的特征值过大,本文采用公式(15)对样本数据进行归一化:

式中:Ti、Tmax、Tmin分别为变压器绕组热点温度样本数据的原始值、最大值和最小值;Ti′为变压器绕组热点温度归一化后的输入值。
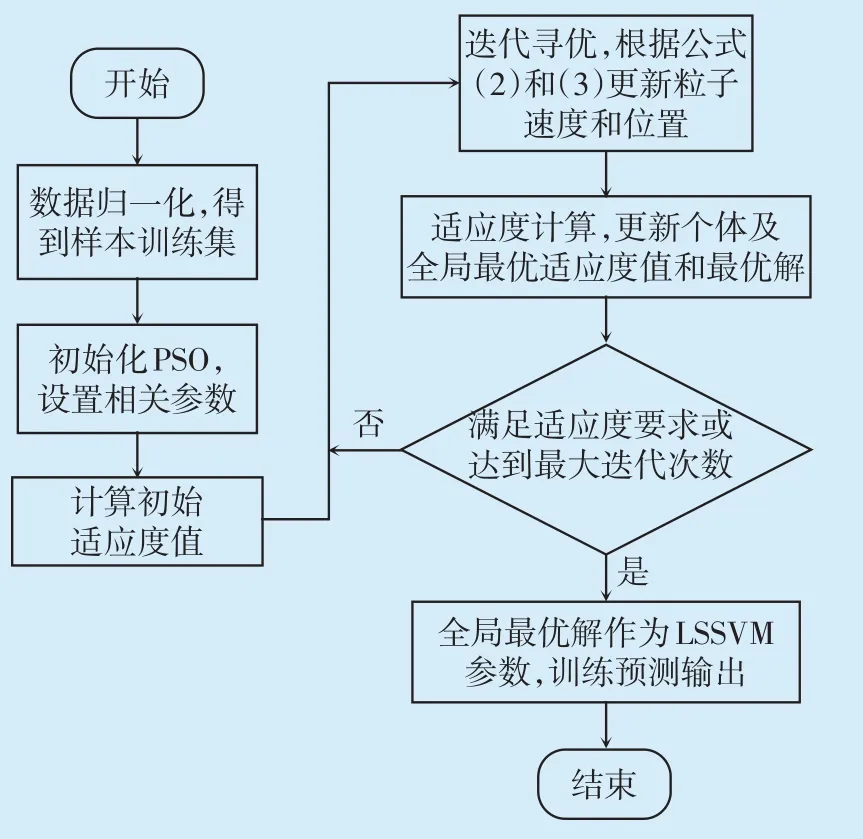
图1 改进PSO-LSSVM预测模型建模流程
(2)初始化设置LSSVM的核函数参数,令惩罚因子C=100,核函数宽度σ2=2.5。经预测模型运算后输出结果,然后根据式(16)计算适应度值I:

式中:n为样本容量;Ti*为变压器绕组热点温度预测值。
(3)设置改进PSO 参数,种群规模d=30,加速因子c1=c2=2.05,总迭代次数kmax=300,采用线性递减的方法将惯性权重ω从0.9递减到0.4。
(4)将惩罚参数C 和核函数参数σ作为粒子,初始值分别为C=100、σ2=2.5,将其记作当前个体最优解,并计算初始适应度值,搜索适应度值的最优解作为当前全局最优适应度值,与其对应的粒子即为全局最优解。
(5)迭代过程开始,根据公式(2)和(3)计算粒子新的速度及位置。
(6)将新的速度和位置作为核函数和惩罚因子重新带入LSSVM模型进行训练输出,计算新适应度值。
(7)比较步骤(6)中的新适应度值和当前适应度值,如果新适应度值优于当前适应度值,则更新适应度值,并将新适应度值对应的粒子值更新为个体最优值。
(8)如果新适应度值比全局适应度值更优,则将其更新为全局适应度值,并将与新适应度值相对应的速度和位置更新为全局最优解。
(9)判断迭代后的结果能否满足寻优及迭代次数的要求,若是则结束计算,输出全局最优解;不满足则返回步骤(5)。
(10)将寻优后的C和σ带入LSSVM模型,即可进行变压器绕组热点温度预测。
2 算例分析
本文采用文献[11]中的100 组实验数据组成样本进行算例分析。在连续时间序列上取100组实验数据,时间间隔为30 min,数据包括变压器负载电流、顶层油温、底层油温、油箱上死角、油箱下死角温度及环境温度,将100组数据依次编号为1—100,部分实验数据如表1所示。

表1 部分实验数据
在Matlab软件中进行仿真,将负载电流、顶层油温、底层油温、油箱上死角温度、油箱下死角温度及环境温度作为变压器绕组热点温度预测模型的支持向量,100组样本数据分为两部分,前90组数据为训练集,后10 组为测试集,分别采用改进PSO 算法和PSO 算法训练测试集数据,对LSSVM 参数寻优。改进PSO算法获得的最优参数为C=58.36、σ2=3.25,PSO 算法获得的最优参数为C=65.84、σ2=3.76,两种算法的适应度曲线如图2所示。
从图2中可知,PSO-LSSVM模型大约迭代计算180次才能找到全局最优解,而改进PSO-LSSVM模型只需约80次即可完成迭代。由此可见,改进PSO算法能够明显加快收敛速度。
将最优参数分别赋与LSSVM 变压器绕组热点温度预测模型,对后10 组测试集数据进行预测,预测结果如图3 所示。由图3 可知,改进PSO-LSSVM模型预测效果更好。
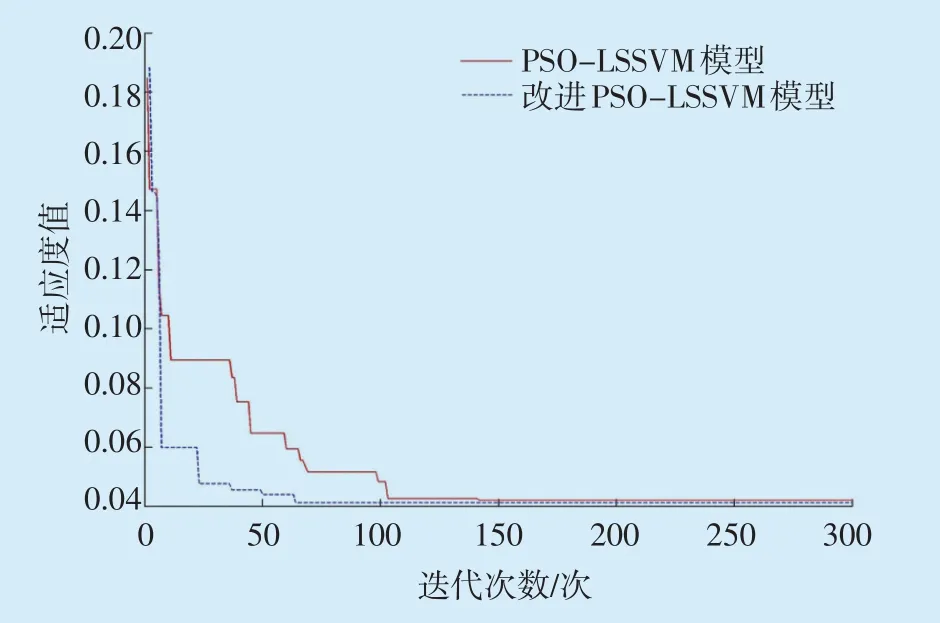
图2 两种模型的适应度曲线
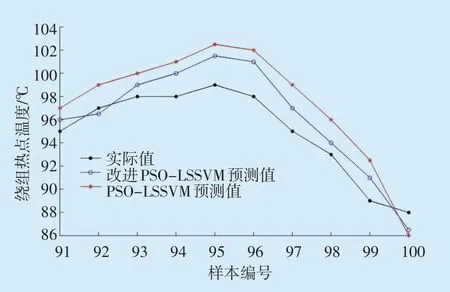
图3 测试集数据预测结果
为检验预测模型的精度,采用平均相对误差对本文提出的变压器绕组热点温度预测方法进行评价,平均相对误差计算公式如下:
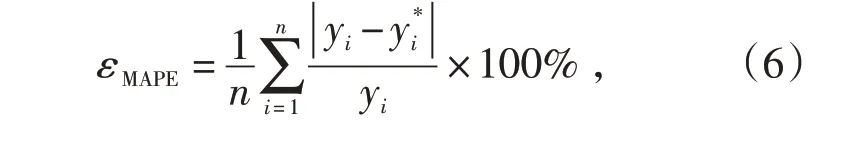
式中:n 为测试样本的数量,yi为第i 个实际值,为第i个预测值。
为进一步验证本方法的正确性,采用100 组样本数据另外建立GA-SVM 预测模型和GA-BP 预测模型,通过测试集数据检验各种预测模型的精度,4种预测模型的平均相对误差如表2所示。由表2可知,改进PSO-LSSVM 模型的平均相对误差最小,收敛时间最短。可见基于改进PSO-LSSVM 的变压器绕组热点温度预测方法明显优于其他方法。

表2 4种模型预测误差
3 结束语
本文针对粒子群算法存在收敛速度慢、寻优能力差等不足,采用收缩因子对粒子群算法进行改进,建立了基于改进PSO-LSSVM 的变压器绕组热点温度预测模型,取得了理想的预测效果,验证了该方法的正确性。变压器绕组热点温度变化过程较复杂,本文收集的样本数据有限,未来将开展相关实验,获取更多样本数据,进一步完善预测模型。
