基于残差注意力网络的马铃薯叶部病害识别
2021-04-10李晓振吴作宏
徐 岩,李晓振,吴作宏,高 照,刘 林
(山东科技大学 电子信息工程学院,山东 青岛,266590)
马铃薯与小麦、稻谷、玉米、高粱并称为世界五大作物,其块茎含有大量淀粉,能为人体提供丰富的热量,且富含蛋白质、氨基酸、多种维生素和矿物质,其维生素含量是所有粮食作物中最全的。然而,各种病害严重制约马铃薯产量,如世界公认的马铃薯第一大病害——马铃薯晚疫病,影响我国的种植面积约为200万hm2,致使马铃薯产量在一般年份减少10%~30%,严重时可达50%[1]。我国马铃薯的种植相对分散,相关从业人员知识水平参差不齐,极大制约着马铃薯病害的防治。
近年来,随着机器学习技术的发展,研究人员试图借助机器学习技术识别作物病害,提高病害防治水平。传统识别算法通常包括预处理、特征选择、设计特征提取器和设计分类器等步骤,相对繁琐且困难。例如对图像颜色、形状、纹理等特征[2-3]的提取,需要依据先验知识和人工工程来实现。而深度学习通过一种通用学习过程,从数据中学习如何提取图像特征,克服了传统方法的缺陷。Lecun等提出的LeNet网络[4]奠定了现代卷积神经网络的基础。Krizhevsky等[5]证明了卷积神经网络在复杂模型下的有效性,展开了深度学习的研究热潮。新的卷积神经网络模型不断被提出,例如VGG、GoogleNet和ResNet等网络模型[6-8]。
人类的视觉神经系统每秒所接受的视觉信息高达千万比特,但视觉神经系统的资源是有限的,为此视觉神经系统会先对信息进行快速扫描,以滤除无用信息,进而将更多资源投入到关注目标所在区域,这便是视觉注意力机制。通过在神经网络中搭建注意力机制,使网络忽略无关信息并关注重点信息,可提升识别效率与效果[9]。Hu等[10]指出不同特征图所含的特征信息不同,具备不同的重要程度,可以将注意力作用于特征图以提升分类效果。Wang等[11]指出简单地堆叠注意力模块会造成特征值的消减,可将模型分为注意力通路和卷积通路来解决此问题。
2016年,刘鑫等[12]使用多光谱相机以及波段指数法识别马铃薯叶部是否患病,识别率达到了92.7%,但该方法依赖于多光谱相机。2017年,李艳[13]使用Fisher准则加人工神经网络对马铃薯4类病害进行识别,平均识别率为87.04%,但识别效果需进一步提升。深度学习的体系结构是简单模块的多层栈,通过组合足够多的简单非线性变换,实现对复杂变换的学习。对于卷积神经网络而言,通过卷积和激活函数实现简单非线性变换,堆叠卷积(加深网络深度)可提升识别效果,但也会产生更多的参数量和计算量,使得训练网络所需数据量和时间显著增加。本研究设计了基于注意力和残差思想的深度卷积神经网络,通过注意力模块,增强对目标信息的关注,提高识别率,而不只是简单的加深网络深度。
1 数据与方法
1.1 数据简介
实验采用的马铃薯叶部病害图像基于Plant Village Dataset[14]构建。为实现对马铃薯叶部病害程度的识别,将马铃薯叶部病害图像细分为健康、早疫病初期、早疫病晚期、晚疫病初期和晚疫病晚期,区分依据如下[15]。
1) 马铃薯早疫病初、晚期的症状:早疫病的叶部病斑有同心轮纹,湿度大时病斑上出现黑色霉层。发病初期叶面出现黑褐色水渍状病斑,晚期病斑相连,叶片枯黄;
2) 马铃薯晚疫病初、晚期的症状:晚疫病的叶部病斑无同心轮纹,湿度大时病斑上出现白色霉层。发病初期一般在叶尖或叶缘出现绿褐色水浸状病斑,晚期病斑扩展到主脉或叶柄,叶片萎蔫下垂。
马铃薯叶部病害图像如图1所示。

图1 马铃薯叶部图像示例
为扩增数据集,按照上述依据筛选、分类图像后,采用旋转、镜像、调整对比度和随机调整纵横比(3/4~4/3)等方法扩增图像数量,最后各类样本图像的比例约为5∶4∶5∶4∶4,共10 032张。
1.2 网络模型设计
使用Python下的开源机器学习框架PyTorch完成网络模型的构建,PyTorch追求最少的封装,让用户尽可能专注于实现自己的想法,是一个简洁且高效快速的框架,已被广泛应用在机器学习和其他数学密集型应用中。
模型在读取图像数据后,首先对图像进行随机裁剪,并调整为224×224像素大小,然后进行直方图均衡化处理,将原始图像的灰度值从集中分布在某个灰度区间变成在全部灰度范围内均匀分布,减轻光照条件对图像识别造成的干扰。最后经标准化处理后输入到卷积层进行特征提取。
通过堆叠卷积加深网络深度,会导致模型的识别精度先升后降(退化问题)。残差结构通过将输入x传到输出作为初始结果,使得输出结果为H(x)=F(x)+x,因此卷积的学习目标变为F(x)[8]。根据反向传播的链式法则可以得到:
(1)
本研究基于注意力思想及残差思想提出了残差注意力网络RANet(residual attention network),对马铃薯叶部病害进行识别。通过构建注意力模块实现注意力机制,该注意力模块包含两部分,一是并行池化的通道注意力模块(图2),二是并行池化的空间注意力模块(图3)。
通道注意力模块首先对输入特征图进行全局池化操作(h×w×c⟹1×1×c),其中平均池化操作得到的特征值主要描述图像的背景信息,最大池化操作得到的特征值主要描述图像的纹理信息,同时采用两种池化操作,可更有效地描述特征通道所含信息。在通道维度拼接两组池化输出后,使用MLP映射为表达各个通道重要度的权值,然后借助Sigmod函数将权值范围约束到(0,1)区间,最后对输入特征图进行加权,以增强病害区域的表达,抑制无用信息的表达,提高病害特征在决策中的贡献,提升识别效果。
空间注意力模块首先对输入特征图在通道维度上进行池化操作(h×w×c⟹h×w×1),以减少增加的参数量。然后使用卷积提取信息,得到描述特征图中特征空间位置信息的Mask map,经Sigmod函数对该Mask map进行约束后,将Mask map作用于特征图,得到根据特征空间位置信息进行约束增强后的新特征图,以增强病害区域的信息表达,抑制其余区域的信息表达。
结合注意力模块、捷径连接和卷积块构建残差注意力卷积(residual attention convolutional,RAC)层,如图4。注意力模块位于卷积之前,为先通过注意力模块“扫描”输入的特征图,以增强目标(病害)区域的表达能力,再通过3个连续的卷积提取图像特征,更符合视觉注意力机制,而且可减少注意力模块增加的参数量。通过构建捷径连接①②③④(图4),可保证梯度的反向传播,避免网络退化问题,并使注意力模块、卷积块及整个残差注意力卷积块均可被构造为恒等映射,以保证注意力机制的引入不会降低网络的精度。而且网络可通过构造恒等映射,实现注意力模块和卷积部分的自适应组合。此外注意力模块会对特征值进行(0,1)范围内的加权,造成特征值的消减,而捷径连接①②将注意力模块的输入值作为初始输出值,可避免此问题。

图3 并行池化的空间注意力模块
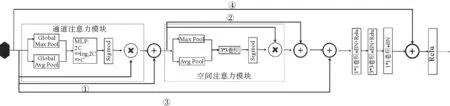
图4 残差注意力卷积层
依据ResNet50的网络结构构建残差注意力网络RANet结构如图5所示,其中Down RAC表示RAC模块中3×3卷积的步长为2(RAC中卷积的步长默认为1),对特征图进行下采样以保障RAC提取的特征转变为更高层次、更抽象的特征。

图5 网络结构
采用SGD(stochastic gradient descent )优化器训练网络参数,并引入Momentum项抑制SGD的震荡。普通的SGD中,参数的迭代更新公式为:
W=W-αdW,
(2)
b=b-αdb。
(3)
引入Momentum后,迭代更新公式为:
vdw=βvdW+(1-β)dW,
(4)
vdb=βvdb+(1-β)db,
(5)
W=W-αvdW,b=b-αv。
(6)
其中,W为权值,b为偏置值,α(学习率)和β为自行设置的超参数,β的值决定上次的更新值对本次更新影响。
引入Momentum后,网络参数的每次更新都会考虑上次的更新值,加强梯度方向与上一次梯度方向相同参数的更新,削减梯度方向与上一次梯度方向不同的参数的更新[17],以增加稳定性和提升学习速度,使网络能在一定程度上摆脱局部最优解。模型相关超参数设置如下:学习率为0.01,采用指数衰减调整学习率大小,Momentum的参数值为0.9,权重衰减的参数值为1×10-4,每个批次使用32张图像进行训练。
2 结果与分析
首先将图像数据按照7∶2∶1的比例随机划分为训练集、验证集以及测试集。然后使用训练集和验证集训练和验证网络模型。最后使用测试集测试得到的网络模型,得到测试结果。各类识别率的计算方式为:该类样本预测正确的数目/该类样本的总数目。
在通道注意力模块中,MLP将表达特征通道所含信息的特征向量变换为表达特征通道重要度的权值向量,在其神经元数目影响着注意力模块的参数量和其对准确率的提升效果。通常会按照一定比例缩放输入特征向量的长度,以确定MLP的神经元数目,该方案下随着缩放比例的降低,参数量增加,准确率提升[10]。文献[4]指出,深度学习采用了分布式特征表示,通过学习分布式特征表示,泛化适应新学习到的特征值的组合(例如,N元特征有2N种可能的组合)。因此取输入特征向量长度的对数值作为MLP的神经元数目,进而在保证对输入进行有效变换的同时减少MLP的参数量。

表1 不同MLP下的识别率和参数量

表2 不同组合方式下的识别率和参数量
对不同MLP参数下的识别率和参数量进行对比实验,实验结果如表1所示,其中N为MLP的神经元数目,L为输入特征向量的长度,参数量使用Python中的Thop库计算得出。
可以看出,在参数量相近时,采用对数方法取值的识别效果更好;而识别效果相近时,采用对数方法可以有效控制参数量的增加。
进一步进行实验,对比不同组合方式下的识别率和参数量,首先验证通道注意力模块,然后验证空间注意力模块,最后验证卷积的组合方式与其它组合顺序的性能差异,其中CA表示通道注意力模块,SA表示空间注意力模块。实验结果如表2所示。
由表2知,相比于卷积+SA+CA方案,CA+SA+卷积方案的参数量更少,为25.95 M;识别率更高,提升了1.52%,达到了93.86%。这是因为卷积+SA+CA方案先提取特征再区分特征的重要性,而CA+SA+卷积方案先区分输入信息的重要性,再提取特征,可以将更多的注意力(网络资源)作用于病害特征上,可以更细致地提取病害特征,提高识别效果。相对于SA+CA+卷积,CA+SA+卷积的识别率由93.38%提升到了93.86%,提升了0.48%,这是由于在空间注意力模块中用以对输入特征图进行约束增强的Mask map是基于所有特征图构建的,而CA+SA+卷积可先依据特征图所含信息对输入进行调整,因此输入到空间注意力模块的特征图是在通道层面上根据特征图所含信息进行了约束增强。所以在构建Mask map时,含有病害信息的特征图对Mask map的贡献更大,使得Mask map能更好的对病害特征的空间位置进行描述,进而将更多的网络资源作用于病害区域,提升卷积部分提取病害特征的能力。即,如果通道注意力模块没有被构建为恒等映射,那么其会提升后面的空间注意力模块的性能,进而提升模型整体的识别效果。
由表3知,RANet模型对各类病害识别效果最好,平均识别率高出其它模型2.46%~16.13%。在单个类别上,识别率高出其它模型1.42%~26.7%。相对于VGG16、ShuffleNet和MobileNet模型,RANet和ResNet50模型构筑深层网络,取得了明显高于其它模型的识别效果。而VGG16、ShuffleNet和MobileNet为相对浅层的网络,特征提取能力较弱,所以对叶部健康的识别率较高,但对病害的识别率相对较低。相对于ResNet模型,RANet模型利用注意力机制将平均识别率提高了2.46%,达到了93.86%,对早疫病初期、早疫病晚期、晚疫病初期和晚疫病晚期的识别率提升了1.42%~4.86%。

表3 不同模型的识别率
对比使用混淆矩阵可视化识别效果前三的RANet、ResNet50和VGG16在测试集上的表现,进一步分析RANet的表现。混淆矩阵是机器学习中总结分类模型预测结果的情形分析表,行表示样本的真实类别,列表示样本的预测类别,表中每个值为将行类别预测为列类别的概率,对角线的值为预测正确的概率。

图6 混淆矩阵
由图6可以看出,相对于VGG模型的12种错误识别,RANet和ResNet50模型只有6种错误识别,错误率比VGG模型低1%~12.98%,其错误识别主要发生在对病害时期的区分上。RANet模型的各个识别错误率均低于ResNet50模型,这得益于注意力机制减少了对无用区域(不利于区分病害的区域)的学习,将更多的资源作用于病害区域,可更细致地提取病害特征,提高病害区域对决策的贡献,提升识别效果。RANet模型对病害的错误识别主要发生在对初期和晚期的识别上,这是因为病害初期到病害晚期的发展是一个连续过程,两者的界限相对模糊。另一方面,病害的一些特征会存在于不同时期,因此需要更细致地区分特征或使用更少的特征实现识别,增大了识别难度。

图7 参数量与识别速度
将识别效果前三的VGG、ResNet50和RANet模型的参数量及识别速度绘制为百分比堆积柱状图(图7)。可以看出,VGG16的参数量占三者参数量之和的72.87%,达到了138.56 M,而ResNet50和RANet分别仅为25.56和25.95 M,这主要得益于1×1卷积的使用。先使用1×1卷积降低特征图的通道数,再使用3×3卷积提取特征,最后再由1×1卷积增加特征图通道数,既可以加深网络的深度,又能够减少网络的参数量。从识别速度上看,VGG16的平均识别速度为114 ms/Image,而RANet和Resnet50的平均识别速度分别为73 ms/Image和70 ms/Image。相比Resnet50,RANet的参数量增加了0.39 M,识别速度相差3 ms/Image,而平均识别率提高了2.46%,达到93.86%,这得益于对池化操作和对数取值方法的使用。在借助注意力模块提升识别效果的同时,有效控制了注意力模块的参数量。综合考虑识别率、速度和参数量,RANet的表现更好。
根据混淆矩阵计算RANet的精确率,精确率表示预测为正类的样本中有多少真正为正类,其计算方式为:正类预测为正类/(正类预测为正类+负类预测为正类)。

表4 各个类别的RANet 识别精确率

表5 与其他方法的对比
由表4可知,从识别结果角度而言,当RANet给出的识别结果为早疫病初期和晚疫病晚期时,精确率为92.90%和93.77%;识别结果为晚疫病初期时,精确率最低,为87.87%;识别结果为早疫病晚期时,精确率最高,为96.43%。
最后,将本研究与前人研究的识别率进行对比(表5)。由表5可知,本研究的识别效果最好,且克服了传统方法依赖于人工提取特征的困难。
3 结论
马铃薯叶部病害识别是机器视觉技术在农业领域的重要应用方向之一。本研究基于注意力和残差思想构建了RANet模型,实现了马铃薯叶部病害的识别。
RANet的平均识别率为93.86%,比Resnet50、VGG16、ShuffleNet和MobileNet模型提升了1.42%~26.7%。单个类别的识别率同样高于其它模型的识别率且均不低于89.66%。在单张图片的识别速度上,RANet模型比VGG模型快41 ms,通过对注意力模块参数量的有效控制,使得RANet的识别速度仅与ResNet50相差3 ms。
但目前模型所能识别的病害较少,需进一步扩充。且如果同一叶片患有多种病害,模型将无法有效识别,需进一步研究。
