基于融合路径监督的多波段图像语义分割
2021-04-10康萌萌谷小婧顾幸生
康萌萌, 杨 浩, 谷小婧, 顾幸生
(1. 华东理工大学化工过程先进控制和优化技术教育部重点实验室,上海 200237;2. 中国民航科学技术研究院,北京 100028)
城市场景的语义分割是实现自动驾驶的关键技术[1],通过识别图像中每个像素所属的类别,使自动驾驶车辆实现环境理解[2],进而实现可靠判断。近年来,随着深度学习技术的发展,基于深度学习的语义分割方法也日新月异。Shelhamer 等[3]提出了第1 个端到端的语义分割模型(FCN),随后,Handa 等[4]将FCN 扩展成一个对称的编码-解码结构SegNet,通过解码器逐步还原图像的空间位置信息,避免直接上采样导致分割细节不够精细的问题。文献[5]也采用类似的编码-解码网络。此外,还有一些研究致力于提高图像全局信息的利用率,如空洞卷积[6]、多尺度预测[7]、条件随机场模型[8]等。
基于深度学习的语义分割技术主要围绕可见光图像展开,但是在夜间、大雾或强曝光等特殊的光照环境下,系统性能会显著下降,导致无法正确分割物体,这也是影响自动驾驶系统走向实际应用的重要原因之一。红外热成像相机根据物体发射的热辐射强度成像[9],具有不受光照环境影响的优点。可见光-红外(RGB-IR)多波段图像由两个传感器相机同时捕获并进行配准[10],其中,可见光图像记录的是场景的反射特性,光照良好时可以提供丰富的色彩特征和细腻的纹理特征,但光照不佳时图像信息不足[11];长波红外图像记录的是场景的热辐射特性,虽然是单色图像且缺乏细腻的纹理,但可在光照环境差的情况下提供人、车等热目标的显著特征。因此,联合使用RGB-IR 多波段图像中的互补信息,可以提高自动驾驶系统的鲁棒性和准确性,使得全天候复杂交通环境下的安全行驶成为可能。
目前,基于深度学习的多波段图像语义分割方法主要采用编码-解码结构,根据特征融合方法不同可分为编码端融合[12-13]、解码端融合[14]和独立模块融合[15-16]三大类。Hazirbas 等[12]提出编码端融合的FuseNet,采用VGG16 模型构建两个并行的编码器和一个共用的解码器,在编码端将深度信息对应地相加到可见光通道中,是最直接的编码端融合结构。Sun等[13]提出的RTFNet 网络也采取编码端融合结构,通过ResNet 残差网络进行特征提取,并提出一种新的解码器来恢复特征图分辨率。Ha 等[14]构建的MFNet轻量级网络采用解码端融合方法,将编码端捕获的多波段信息直接连接到解码端构成解码端融合架构,以减少对特征提取的干扰。以上模型都采用特征直接相加或级联的方式,而Lee 等[15]提出的RDFNet网络结构通过构建MMF 融合模块对多模态特征和多级特征进行筛选融合,属于独立模块融合结构。类似的工作还有Valada 等[16]提出的AdaptNet 网络,通过多尺度特征融合块MS 构建独立模块融合结构。
多波段图像语义分割方法缺乏对融合特征的有效性判别,可能导致互补信息丢失或信息过度冗余。为了提高融合特征的鉴别性,本文对特征融合过程施加监督信号,提出了一种基于融合路径监督的多波段图像语义分割方法(SFNet)。通过将特征融合模块串联形成特征融合支路,在融合支路末端施加监督信号,使融合特征更具有鉴别性。此外,构建了Dice 损失和交叉熵损失的混合监督训练模式,改善对于小目标的分割效果。
1 基于融合路径监督的多波段图像语义分割
1.1 多波段图像语义分割整体框架
基于融合路径监督的多波段图像语义分割网络结构如图1 所示。基础模型采用基于SegNet[4]的编码器-解码器架构,该架构可以灵活地将多波段图像的多级特征进行融合,提高信息利用率。首先利用SegNet 模型构建两个并行的编码器,分别对可见光图像和红外图像进行特征提取,在编码末端得到两个512×10×10 的高层语义特征图,代表编码输出的10×10 特征图共有512 个;然后将提取到的多波段高层语义特征直接级联,通过一个共用的解码器进行解码。
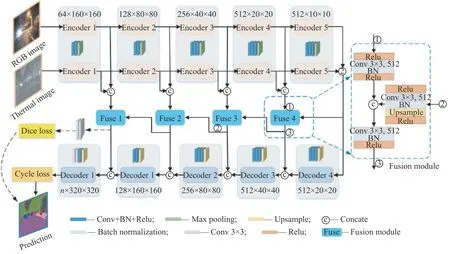
图1基于融合路径监督的多波段图像语义分割网络结构Fig.1Multi-spectral image semantic segmentation network with supervised feature fusion
本文模型包括4 个相似的特征融合模块,将其互相串联形成特征融合支路。特征融合模块作为特征运输的桥梁,将融合后的高层语义特征(即上一个特征融合模块的输出)和当前编码端引出的中间特征再次进行融合,并分别连接到对应的解码端,以帮助解码器更好地恢复对象细节。在融合支路上设置Dice 损失函数对融合过程进行监督,联合解码支路的交叉熵损失函数,利用二者之和作为网络的最终损失进行反向传播,构成混合监督训练模式。
1.2 融合模块及融合支路
首先构建特征融合模块,具体结构如图1 中Fusion module 所示。融合模块有两个输入,一是从编码端引出的多波段特征,将其级联后送入融合模块①端,通过3×3 卷积进行融合预处理并将通道降为原来的1/2;二是来自高层的融合信息,利用模块②端的3×3 卷积将其通道降为原来的1/2。将经过预处理的两组特征图级联,通过3×3 卷积进行后处理,并将通道降为原来的1/2 输出到③端;输出的融合信息连接到解码端,促进解码分割,同时将其作为下一个融合模块的输入。通过以上从高层到低层特征的传递,将特征融合模块串联成融合支路,利用高层融合信息指导低层信息融合。本文构建的特征融合模块避免了互补信息丢失和信息过度冗余等问题,使融合信息在捷径连接的过程中保持对齐,减少冲突。另外,为了防止过拟合,在特征融合模块输入端①、②添加Relu 激活函数来减少网络的稀疏性。
1.3 融合路径监督
为了使融合特征更具有鉴别性,在独立的融合支路末端直接添加损失函数构成融合监督信号,利用监督信号促进特征融合过程。类似的工作有Lee 等[17]提出的深度监督网络,该工作指出利用监督学习可以让中间隐藏层的学习过程更加直接和透明,减少分类的错误,从而使学习到的特征更加鲁棒和易区分。本文方法与深度监督网络工作的不同之处在于,深度监督复用了同一条网络支路,而本文基于融合模块构建了一条独立的新支路,并对其施加不同的监督信号。
首先,使用图像分割中常用的交叉熵损失函数对融合支路进行监督,其具有求导方便、易于训练的优点,交叉熵损失函数( Lcross)如式(1)所示。交叉熵损失函数对每个类别具有相同的关注度,易受类别不平衡因素的影响,因此为了提升对小目标的分割精度,使用Dice 损失函数 (LDice)[18]对融合支路进行监督。Dice损失函数最初用于医学图像分割,它以交并比最大为优化目标,可以从较大的背景区域中将前景目标分离出来,防止预测结果偏向于背景,具有较强的检测小目标区域的能力,Dice 损失函数如式(2)所示。本文在解码支路使用交叉熵作为损失函数,在融合支路使用Dice 损失函数作为监督信号。最后,使用Dice 损失函数和交叉熵损失函数之和作为网络的最终损失函数进行反向传播,构建混合监督训练模式,最终的损失函数( Ltotal)见式(3)。
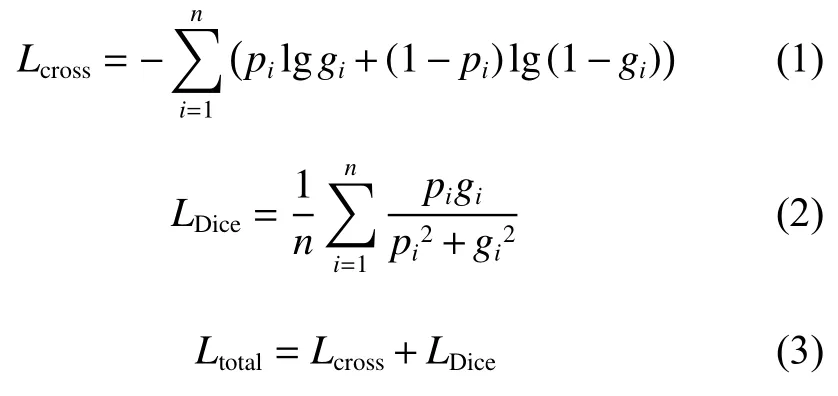
其中:n 为数据集中分割类别的个数; pi和 gi分别为预测分割值和标签值。
2 实验与分析
2.1 实验环境与参数设置
计算机硬件配置为Intel Core i7-7700k CPU,GeForce GTX 2080Ti GPU,操作系统为Ubuntu 16.04 LTS,计算框架为Python 3.6.6,Cuda 9.0,Cudnn 7.2 以及Torch 0.4.1。网络训练过程中将图片分辨率统一设置为320×320,参数学习采用带动量的小批量随机梯度下降方法,为解决训练期间出现的轻微过拟合问题,在卷积层之后添加L2正则化。训练批次大小为4,最大迭代次数Tmax=400,初始学习率η0=0.01。训练过程中学习率 ηT随迭代次数T 使用poly 策略衰减至0,其表达式为
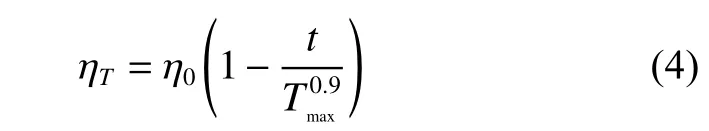
2.2 数据集及评价指标
2.2.1 数据集 对比实验在两个多波段语义分割数据集上展开。数据集1 是课题组自行构建的夜间道路场景图像语义分割数据集,共有541 组配准的RGB-IR 图像及语义标签图,图片分辨率为400×300。语义标签设定为:汽车、自行车、行人、天空、树木、交通灯、道路、人行道、建筑、栏杆、路标、杆子、巴士共计13 类物体,外加空类,代表13 种物体之外的场景,本文模型的训练与评估过程不包括空类。数据集2 是Ha 等[14]针对自动驾驶问题构建的城市场景RGB-IR 图像语义分割数据集,共包含1569张分割图像(其中820 张图片来自白天,另外749 张图片来自夜晚),图片分辨率为480×640。语义标注中提供了在交通环境中常见的8 种障碍物及背景标签,本文在数据集2 上的实验不计算背景标签。
2.2.2 评价指标 在算法评估中,采用每个类别的分割准确率(Acc)、联合交叉概率(IoU)、Acc 和IoU 在所有类别上的平均分割准确率(mAcc)及平均联合交叉概率(mIoU)指标对语义分割性能进行定量分析,公式如下:
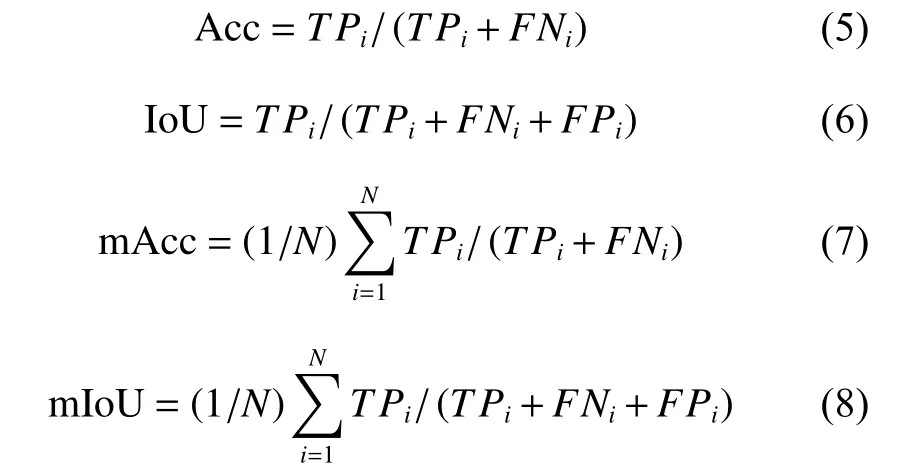
2.3 实验结果与分析
2.3.1 消融实验 消融实验主要分为三部分。首先,为了验证融合支路可以让高层融合指导低层融合,使信息的利用率更高,从而改善分割效果,本文设计了基于独立模块融合方法与融合支路方法的对比实验。独立模块融合方法是指在图1 中多波段图像语义分割架构的基础上,利用两个3×3 卷积代替图1 中的Fusion module,通过它对级联后的多波段特征进行融合,并将其连接到解码端,结构如图2(a)所示。融合支路方法是指在本文模型基础上去掉融合支路末端的监督信号,结构如图2(b)所示。两种方法分别在两个数据集上进行实验,对比结果如表1 所示。从表1 可以看出,利用特征融合支路可以将分割结果mIoU 值提升1.0~2.0,说明融合支路与独立融合模块相比可以利用更多的融合信息,提高语义分割效果。
在融合支路末端直接施加监督信号,构成基于融合路径监督的分割模型,根据监督信号的不同,分别将交叉熵损失监督和Dice 损失监督的模型称为SFNet*和SFNet,简化结构如图2(c)所示。在融合支路末端添加与分割支路相同的交叉熵损失监督信号时,实验结果见表1 中的SFNet*。对比表1 的实验结果可知,在融合支路末端添加交叉熵损失时,在两个数据集上的mIoU 值和mAcc 值与融合支路方法相比都有所提高,说明对融合路径设置交叉熵信号监督能提高融合特征的鉴别性,进而改善分割效果。
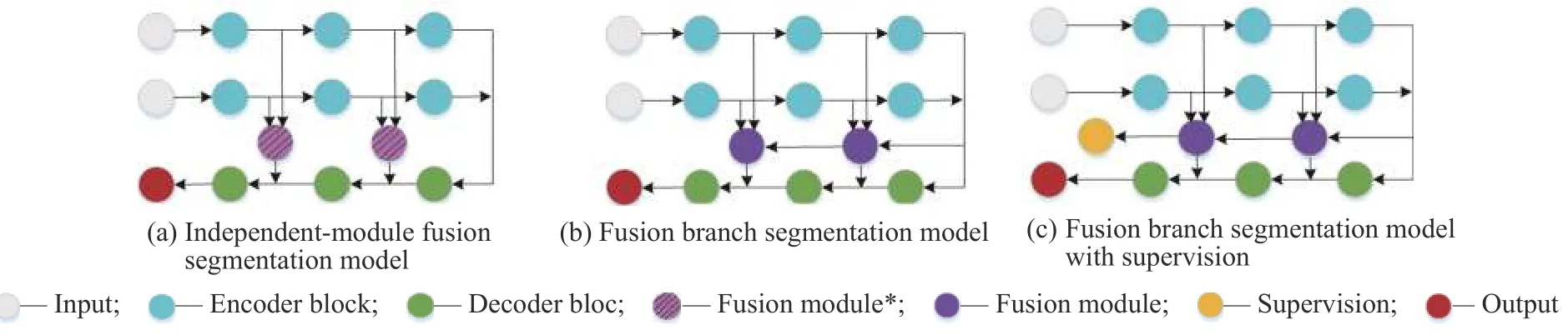
图2消融实验模型Fig.2Ablation experimental model
将融合支路末端的交叉熵损失替换成Dice 损失,与解码分割支路上的交叉熵损失构成混合监督训练模式,实验结果见表1 中的SFNet。对比SFNet*与SFNet 的分割结果可以看到,Dice 损失监督模型的mAcc 没有明显提高,而mIoU 值提升1 左右,这恰好体现了Dice 损失函数的特点,以交并比最大化为目标进行参数更新,提升小目标的分割效果。图3示出了在特征融合支路上分别添加Dice 损失和交叉熵损失的分割结果对比,从图3中红色圆圈标注的地方可以看出,在特征融合支路上添加Dice 损失监督信号时,模型对路标、杆子等细小物体的分割效果将更优。
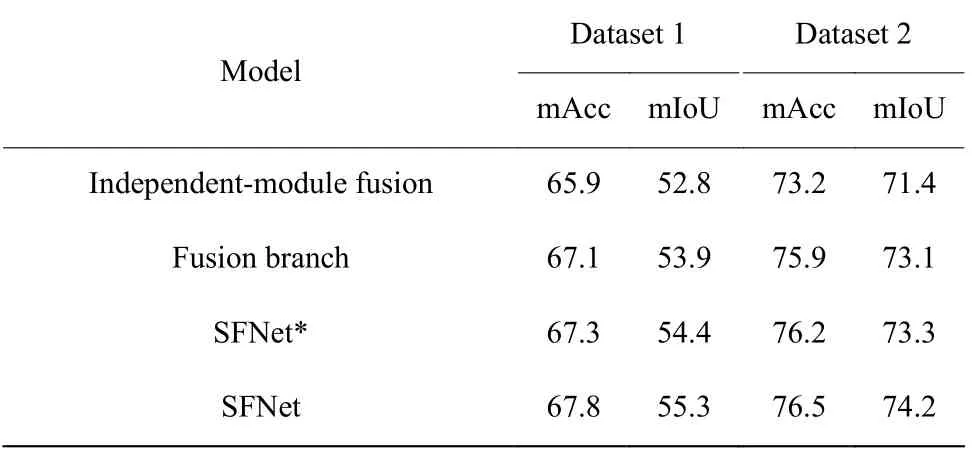
表1在数据集1 和数据集2 上的消融实验结果Table1Ablation experimental results on dataset1and dataset 2
图4 分别示出了表1 中4 组对比模型在数据集1 的训练过程中,验证集的损失函数变化和mIoU 变化情况。观察图4(a)中损失函数变化曲线发现,在融合支路上加入损失函数进行融合监督之后,SFNet*和SFNet 损失曲线下降较快,说明设置融合监督信号后加快了收敛速度,减少了训练时间。图4(b)中mIoU值的变化曲线显示,加入Dice 损失的混合监督信号方法与其他方法相比具有较好的分割效果。综上,基于融合路径监督的方法加快了模型收敛速度,同时能提升融合特征鉴别性,进而改善分割结果。
2.3.2 算法对比及分析 本文选取了目前较为成功的几种分割网络作为对比算法,其中包括FCN[3]、SegNet[4]和UNet[13]等经典的单模态图像语义分割方法,以及FuseNet[12]、MFNet[14]、RTFNet[13]和RDFNet[15]等多波段图像语义分割方法,分别在数据集1、2 上进行实验。表2 和表3 分别示出了对比算法在数据集1 和数据集2 上的分割结果,表中黑体字表示分割最优值。结果验证了本文提出的基于融合路径监督的多波段图像语义分割模型具有较好的分割效果。
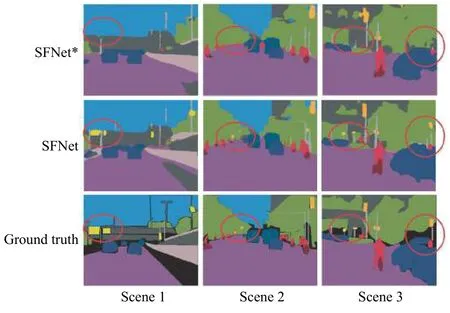
图3不同监督信号对比结果Fig.3Comparison results of different supervision signals
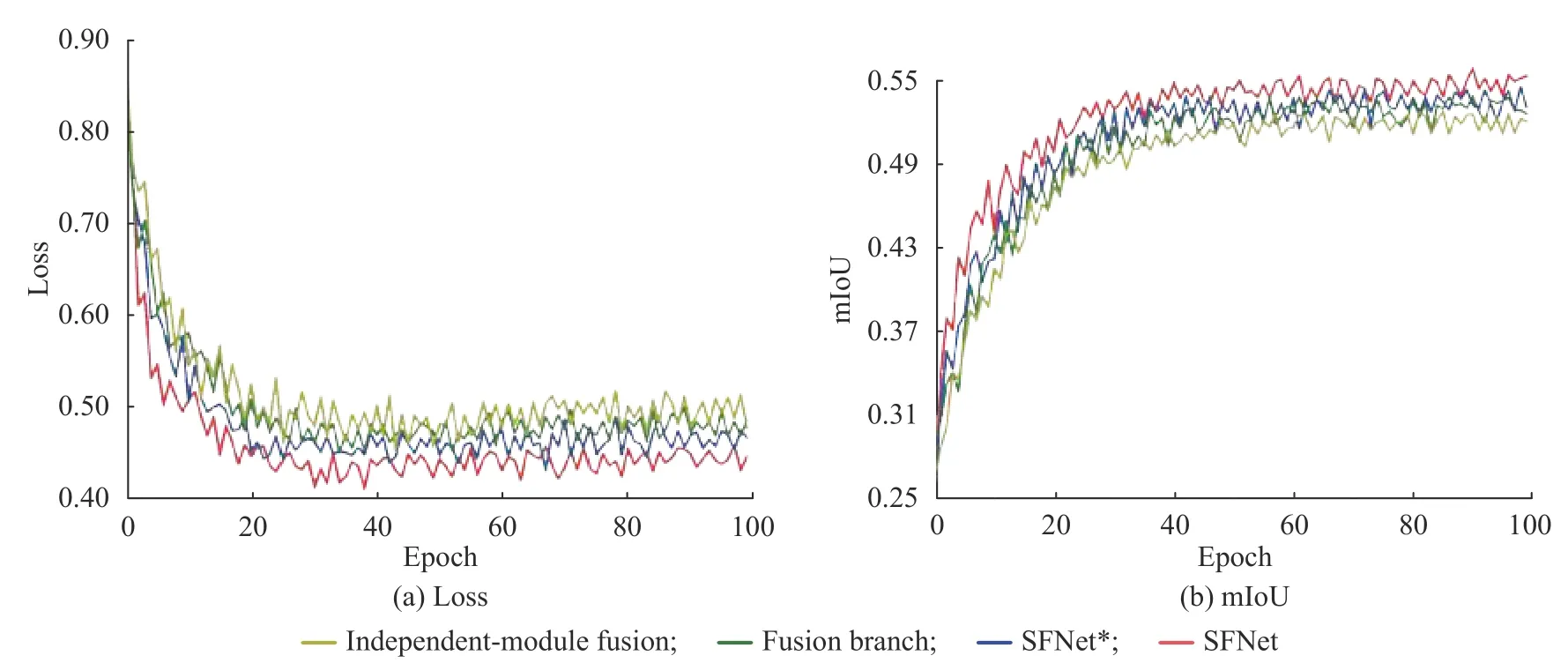
图4验证集上的损失函数和mIoU 变化曲线Fig.4Loss and mIoU curves on the validation set
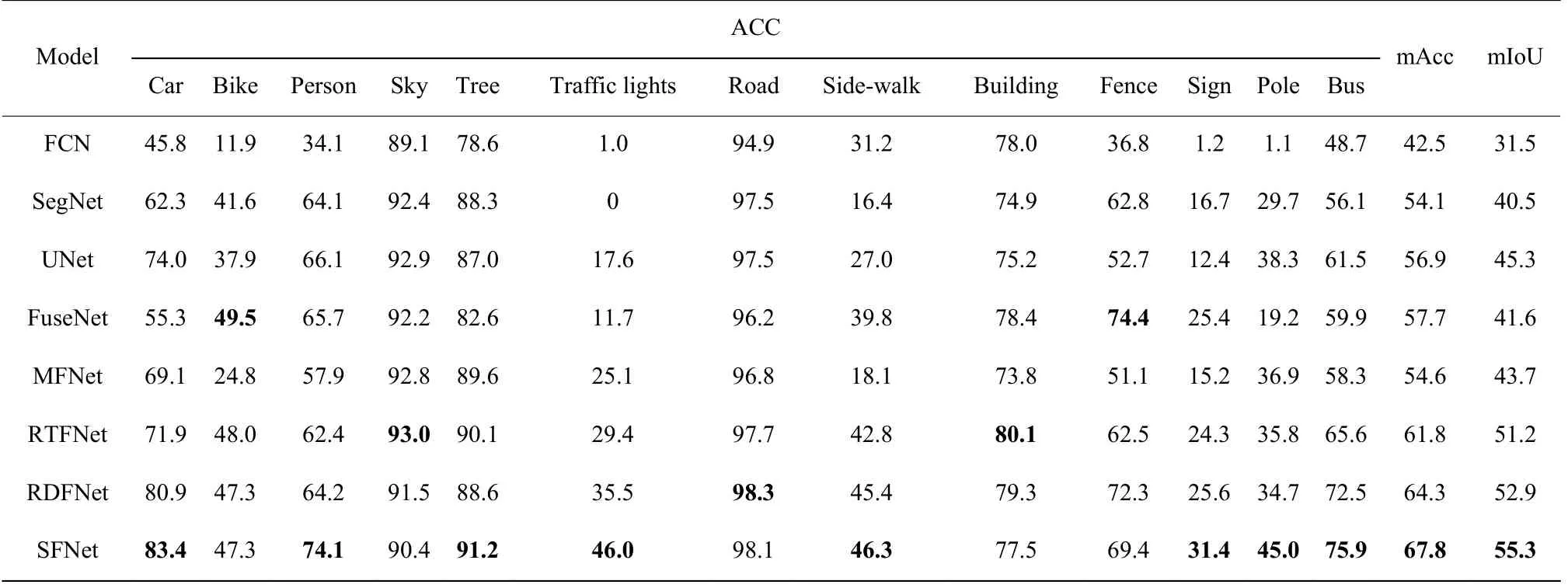
表2不同分割方法在数据集1 上的分割结果Table2Segmentation results of different segmentation methods on dataset 1
表2 中只显示了每个类别(不含空类)的Acc、mAcc 和mIoU。从比较结果来看,在当前主流算法中,以独立模块融合方法为代表的RDFNet 模型表现较好,分割结果mIoU 值为52.9,本文的SFNet 方法与RDFNet 相比,mIoU 提高了2.4。从整体对比结果来看,本文方法不论在mAcc 还是mIoU 评价指标上都优于其他算法,在大多数类别的像素准确率上与其他方法相比也有较好的分割效果,特别是对交通灯、标志牌、杆子等小目标的分割像素准确率有较明显的提高,验证了在融合支路末端添加Dice 损失监督信号对小目标分割的有效性。

表3不同分割方法在数据集2 上的分割结果Table3Segmentation results of different segmentation methods on dataset 2
表3 数据集中含有大量的背景类像素,这对小目标对象的分割造成了很大的挑战,因此,为了消除背景类像素对整体分割效果的影响,在数据集2 上的实验过程中不计算背景类像素。尽管如此,在数据集2 上进行语义分割实验时,依然出现某些分割方法对护栏类别分割结果为0 的情况,这是由于该类别在数据集2 中所占比重较小(约占0.1%),因此没有被检测到。从表3 的分割结果来看,采用本文方法得到的mIoU 与mAcc 值明显高于其他模型。
从表2 和表3 的分割结果可以看出,本文的SFNet模型在两个数据集上的mAcc 和mIoU 值均达到最高,体现了本文方法在不同的语义分割数据集上都具有良好的表现,鲁棒性较好。图5 示出了不同方法在两个数据集上的语义分割结果。

图5语义分割结果Fig.5Results of semantic segmentation
此外,对于自动驾驶技术来说,图像分割的实时性也是决定其能否走向实际应用的一个重要因素。因此,为了评价模型的实时分割效果,利用NVIDIA GeForce GTX2080Ti 显卡对上述语义分割网络的推理速度进行测量。在数据集1 上输入图片分辨率为320×320 的情况下,对比不同融合方法对同一张图片进行分割所需的平均时间成本t 和速度(FPS),其中FPS 表示每秒可以分割多少张图像,分割性能和效果对比如表4 所示。
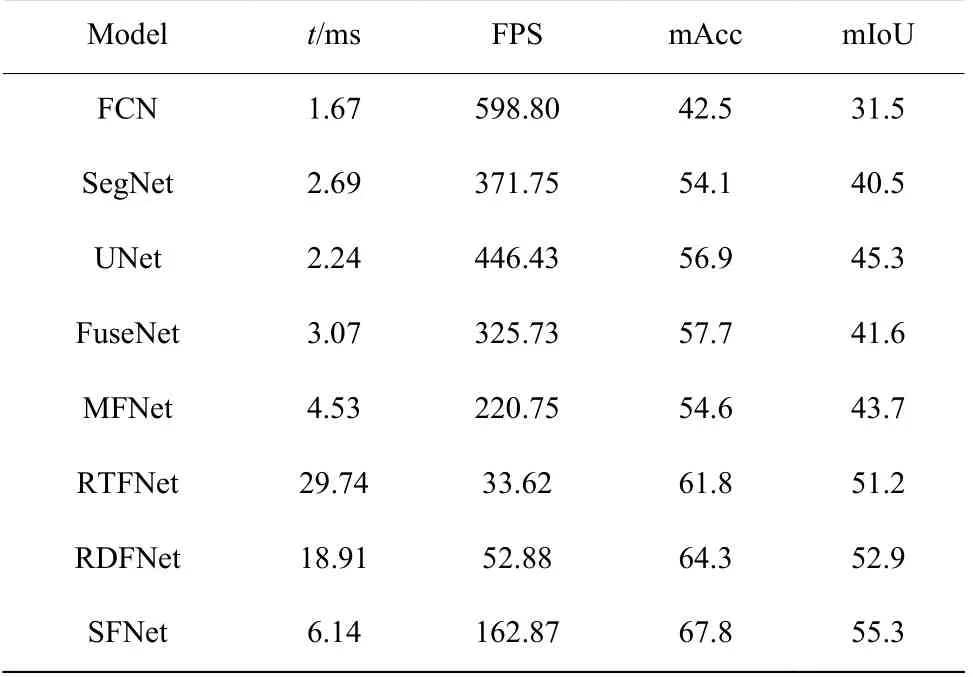
表4不同模型推理速度和性能对比Table4Comparison of inference speed and performance for different models
RTFNet 与RDFNet 都由卷积层数更深的ResNet基础网络构成,从表4 中可以看到,与其他基于VGG网络的方法相比,RTFNet 和RDFNet 可以提取更多的图像特征,因此其分割效果优于其他主流算法,但是使用更深的模型在一定程度上增加了网络运算量和模型参数,因此其分割速度均较差。本文模型使用VGG16 基础网络搭建,模型参数较少,训练速度快;同时,本文模型构建融合路径监督策略,使融合特征更具有鉴别性,从而提升分割结果。从对比结果来看,采用本文方法得到的mIoU 值比RDFNet 方法高2.4,分割速度约为RDFNet 方法的3 倍。综上,本文提出的基于融合路径监督的多波段图像语义分割方法不仅具有优良的分割结果,同时具有可靠的推理速度。
3 结束语
为了增强多波段图像融合特征的鉴别性,提高语义分割效果,本文提出一种基于融合路径监督的多波段图像语义分割方法。首先,利用独立融合模块将高层特征与低层特征串联形成融合支路,提高信息利用率;其次,对独立融合支路施加监督信号,不仅使融合特征更具有鉴别性,而且加快模型收敛速度,提高训练效率;最后,对融合支路施加Dice 损失监督信号,与分割主支路的交叉熵损失构成混合监督训练模式,改善对于小目标的分割结果。在不同数据集上的实验结果显示,本文方法与同类算法相比,具有更好的分割效果和分割性能。
