基于多视图深度学习的推荐系统跨域用户建模算法
2021-04-07刘凯
刘 凯
(宁夏医科大学 网络信息中心,宁夏 银川 750001)
推荐系统和内容个性化在目前的在线Web服务中扮演着越来越重要的角色。其中,有一个常见难题就是很多Web服务致力于找到用户需要的最相关内容,来为用户减少查询时间。当前的研究中,对于此问题常常使用协同过滤方法,如将用户先前在Web站点中的交互历史保存,之后通过一定的预测模型来推荐相关内容[1-5];另一种常见的方法是使用基于内容的推荐算法[6-7],将用户与内容之间的特征进行相似性匹配,之后通过相似度来推荐新的条目。随着用户对于个性化和推荐质量的要求的提高,这种固化的算法有明显的局限性,两种传统的方法难以提供高质量的推荐内容。为了构建用户特征,本研究从用户浏览和搜索的所有历史中,提取具有聚类特点的特征来描述用户的搜索趋向。这种方法潜在的假设是,用户在线活动历史反映了大量用户特有的背景和偏好,具有个性化特点。
因此,为了解决以上两种传统方法的局限性,提出了一种使用多视角深度学习方法,利用用户和项目的特征来构建推荐系统。本设计创新性地构建了一种深层的结构语义模型(DSSM)[8],将用户和特征项映射到语义空间,利用非线性变化的方法使用户数据和特征数据之间的相似性最大化。不仅如此,通过对原始的DSSM模型进行分析和实验,将来自单个域的特征拓展,共同学习为不同域的特征,将其命名为“多视图深度神经网络”(MV-DNN)。实验结果表明,这种多视图扩展思想,可以同时提高所有域的推荐质量,使得本模型可以在潜在的空间中找到用户的精确特征表示,更容易存储并学习不同视图间的共享信息。
综上,本研究的贡献如下:第一,提出了一种基于内容的深度学习方法,并且使用非线性映射方法构建了丰富的用户和项目特征;第二,介绍了一种新颖的多视图深度学习模型,并对其进行拓展,提出了MV-DNN模型来学习语义特征;第三,通过实验,证明了此方法的有效性,给类似问题提供了新的解决办法。
1 多视图深度学习(DNN)
本文介绍的多视图深度学习,即DNN,是一种深层结构化的语义模型,具体为DSSM模型,最早出现在文献[9]中,这种模型是为了促进Web快速搜索上下文中的匹配词语而出现的。
DNN的典型架构DSSM模型如图1所示,DNN的输入为原始文本特征,是一个高维的向量,比如在查询过程中的原始计数或者是还没有归一化处理的文本。之后DSSM通过两个神经网络进行传递计算,将这些原始高维向量映射到共享的语义空间当中,最后对Web给出的推荐词语进行排序[10]。值得注意的是,DSSM会计算查询词语和文档之间的相关性,将其作为对应的语义向量的余弦相似性,也就是最后排序的依据。

图1 DSSM模型
具体原理如下,设x表示输入向量,y表示输出向量,i为中间的隐藏层,则1≤i≤n。ωi代表第i层的权重,bi代表第i层的偏置,则DSSM的更新迭代过程如下:
l1=W1x
li=f(Wili-1+bi),i=2,…,n-1
y=f(Wnln-1+bn)
(1)
针对深层结构语义模型(DSSM),一般使用TANH函数作为输出层和隐藏层的激活函数,其中i=1,2,…,n。
(2)
传统方法中,每个单词W由一个高维向量表示,向量的维数是每个词汇的大小。但是,在实际的Web搜索任务中,词汇量非常大,并且一个矢量词汇的维数越高,神经网络处理起来就会越复杂。因此,DSSM使用单词的哈希、通过字母的三角向量来表示单词[11]。例如,给出一个单词“Web”,在添加单词边界符号之后,将这个字母分成序列,如W-E-B,之后将这三个字母进行计数,这样得出的向量特征的维数远小于直接处理单词。在训练过程中,假设查询的结果与所点击过的文章参数有关系,则通过softmax函数从一个查询中的语义相关性估计给定文档的后验概率如下(其中γ是softmax函数中的平滑因子,通常在特定的数据集上进行特定的设置):
(3)
2 MV-DNN在推荐系统中的跨域算法
2.1 MV-DNN的算法描述
DSSM可以看作是一个多学习框架,将数据的两个不同的视图映射到一个共享视图,因此,在设置中可以查看两个不同视图之间的共享映射[12]。基于此,在此创新性地提出MV-DNN模型,如图2所示。它使用DNN来映射高维稀疏特征,如将用户、新闻、应用程序的原始特征转化为联合语义空间的低维稠密特征。

图2 MV-DNN模型
MV-DNN模型的目标函数更新为:
(4)
将目标函数改进为这一形式,是为了找到一个用户特征的单一映射,即它可以将用户特征转化成用户在不同域中所有项目匹配的空间,这种共享参数的方法会增强算法的鲁棒性,因为其允许没有足够信心的域,通过具有更多数据的其他域来学习良好的映射[13]。采用SGD(随机梯度下降)的方法对MV-DNN进行训练。在实验中,每个训练过程包含一对输入和输出,一个用于用户视图的输入,一个输出目标数据视图。
2.2 MV-DNN的优势
虽然MV-DNN是从DSSM扩展而来的框架,但它具有以下几个独特的特征,相比DSSM更适合大数据规模的问题。
(1)原始的DSSM模型用于查询视图和文档、查看相同尺寸的特征[14],并且使用相同的表示(如字母排序)进行预处理,但由于推荐系统的异构性,用户视图和项目视图很可能出现不同设置的输入特征。因此,许多类型的特征不能使用DSSM的预处理方式最佳地表示。例如,URL地域特征通常包含前缀和后缀,如www、com等。因此,通过去除DSSM的通用预处理约束,新的MV-DNN模型可以结合分类特征,如电影类型和应用类别、地理空间特征或用户输入的原始文本特征来进行数据预处理[15]。
(2)MV-DNN具有扩展到跨域的能力。通过每个项目以及对应视图的成对训练,MV-DNN可以轻松采用新的视图进行训练,并且因为视图在训练过程中每个阶段都保持独立的用户和项目集,且在每次训练的迭代过程中对所有项目最优嵌入,所以,改进后的模型,更好地适应了跨域这一功能。
3 实验过程及结果
3.1 实验数据集描述
本实验中的4个数据集是从微软产品的用户日志中收集的,主要包括:(1)来自Bing Wed中的搜索日志;(2)来自Bing Web新闻的文章浏览历史;(3)来自Windows App Store的下载日志;(4)来自Xbox的电影/电视剧浏览日志。所有的日志收集时间为2013年到2014年,主要集中在美国、加拿大和英国,如表1所示。

表1 数据集描述
表1中的用户特征部分是从Bing收集了用户的搜索查询和点击过的URL(统一资源定位符)形成的用户特征。需要首先对查询历史进行归一化处理,之后将其拆分成UNIG和RAM特征,并且将URL缩短为域级。之后,使用IF指数只保留最流行的特征。最后,从数据中选择了300万个单域特征和500K的跨域特征。
而新闻部分,是Bing网络的新闻站点手机的新闻点击历史数据。每个新闻项目由三部分特征来表示,第一部分是新闻标题的特征编码,第二部分是每个新闻的顶级类别(如娱乐、体育等),第三部分为每个文章中的命名实体。使用内部专有的NLP解析器生成,最后生成大小为100K的特征向量。
3.2 实验过程及结果
对于每一个数据集,实验的目标是评估已经在该域存在的用户(旧用户)和先前没有与系统进行过交互的用户(新用户)的推荐性能[16]。其中,针对新用户,有一些搜索和浏览历史,可以被编码成用户视图。为了评估系统性能,数据集被分为训练集和测试集,如表2所示。使用以下标准对数据集进行分类:首先,每个用户被随机分配一个标签,训练和测试的概率比为0.9∶0.1[17];其次,对于每个具有测试标签的用户,将其进一步标记为新用户或者旧用户,概率比为0.8∶0.2[18]。对于标记为旧用户的数据,因为其结果标记准确,因此有50%用于项目训练,其余的用于测试;对于新用户,因为项目无法保证结果,所以只能用于测试。
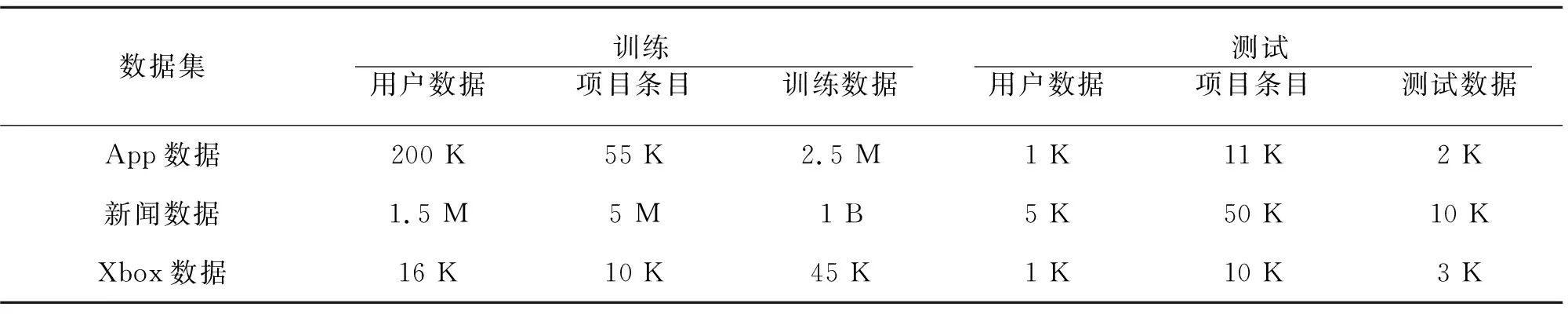
表2 训练集与测试集描述
本研究中的性能评估标准,使用两个评价标准:(1)MRR(平均倒数秩),即计算正确项目的秩与其他项目的倒数,并在整个测试数据中求平均结果;(2)P(精度)计算,即计算系统将项目正确的排序与数据库中的正确项目的百分比。实验的运行结果如表3和表4所示。

表4 实验结果2(第二组)
表3中所有的方法都是经典方法,有些结果采用文献[19]、[20]中的结果,有些是本文自己搭建模型后测试的结果。而表4中的模型,均为本文的实验结果。其中,在DNN模型中,需要使用降维方法来处理数据。MV-DNN方法中,前两个结合应用程序和新闻数据,使用了Topk和KMess的用户特征,第三组实验则利用应用程序、电影电视建立了联合模型,即实现了跨域学习。在MV-DNN训练过程中,训练的损失结果如图3所示。
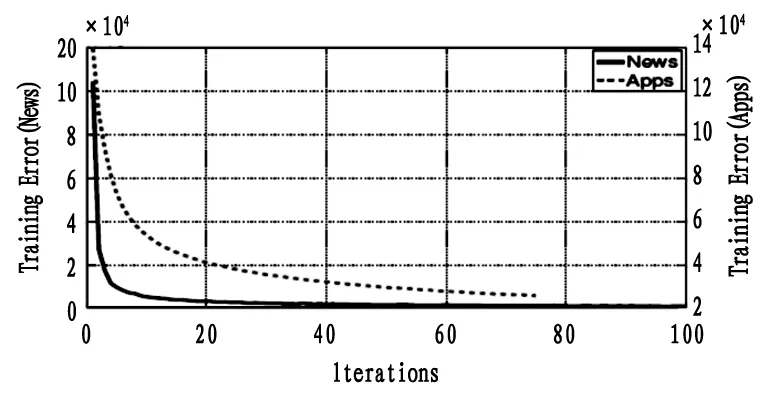
图3 MV-DNN的训练过程中的损失结果
4 分析与讨论
本文将算法分成三类进行对比,表3显示的是基础算法,表4显示的是单视图模型以及多视图的深度学习模型。其中,由表3可知,基础算法运行的算法结果很差,证实了在开头提到的对于新用户,传统算法的表现较差;结果表明,即使在具有协同过滤的矩阵中,标准CRA算法在矩阵分解这项任务中表现得也不够好。同时,CCA算法也并没有比随机推荐算法效果更好,这表明即使使用了DSSM中的非线性映射,也并没有改善用户特征和项目特征的对应相似性。根据表3可以清楚地发现,CRT模型[21]对于已有用户结果较好,但对于新用户来说表现较差。
由表4可知,对于单视图DNN来说,使用降维方法在某种程度上起到了一定作用,即用户可以用相对较小的信息特征集来建立模型。同时也表明,K均值和LSH不太能有效地捕获用户行为的正确语义。将表4的方法与表3的方法进行对比可知,单视图模型中的SV模型优于基准线模型CTR。由此可以证明本文算法中的映射方法的有效性。此外,对于MV-DNN模型来说,无论对比传统方法还是单视图方法,最后一行的结果明显优于其他方法。尤其在与单视图最优模型相比时,所有用户的MRR得分从0.497提升为0.517,当加入MV改进之后,可以提升为最高0.527。这种大幅度的提升,可以证明本文算法的有效性。
由此,通过以上实验,可以得出以下分析,作为经典方法的协同推荐和基于内容的推荐,包括近邻建模[22]、矩阵分解[23]、限制玻尔兹曼机[24]、贝叶斯矩阵分解等方法[25]等,这些方法本质上都是通过对用户数据进行协同过滤,之后直接计算用户与项目间的相似性,使用相似性来计算新的条目与用户之间的关联程度。这些经典的方法在老用户上表现还不错,但是在面对稀疏数据的时候,推荐质量大幅度下降。而深度神经网络模型,通过对用户数据进行完整学习且兼顾了跨域学习,表现已经有大幅度的提升,尤其是进行非线性映射,提高了用户在不同域中的相似性筛选,已经基本解决了面对新用户的推荐质量问题。且当使用本文的多视觉神经网络(MV-DNN)时,最大程度找到了在跨域问题上的用户特征,使得最后的结果明显好于传统方法,由此证明了本文算法的实用性。
5 结论
本研究提出了一种使用多视图的深度学习方法,以丰富的用户与项目特征形成了推荐算法。同时,为了提高鲁棒性和可扩展性,还展示了如何扩展这个框架,来给类似的问题提供解决思路。最后,在实验中表明,本文提出的方法大大优于其他系统。在将来的工作中,目标系统将更多的用户特征融入到用户视图中,希望本文的深度学习模型具有更强的灵活性,从而能够将用户特征集用于无限维数的数据集训练中。同时,笔者希望将传统的协同过滤方法与本文方法相结合,来解决传统方法的不足,进一步提高本算法的性能。
