基于最小窥视孔长短期记忆神经网络的电力系统短期负荷预测模型
2021-04-01蔡鑫祥撖奥洋周生奇魏振张智晟
蔡鑫祥,撖奥洋,周生奇,魏振,张智晟
(1.青岛大学 电气工程学院,山东 青岛 266071;2. 国网山东省电力公司青岛供电公司,山东 青岛 266002)
短期负荷预测主要是指对未来一个小时至几天的负荷预测,对于经济调度、最优潮流以及调度部门机组的最优组合有着重要的作用,而对于当前和未来的电力市场更是有其不可替代性。精确度高的短期负荷预测在提升经济效益和提高供电质量等方面有着非常巨大的影响[1]。
影响短期负荷预测的因素[2]主要有气象条件、日期类型等。随着近年来空调等调温设备应用越来越广泛,受温度影响较大的调温设备用电占社会总用电的比例增大,考虑气象条件能有效提高短期电力负荷的预测精度。气象条件包括:每日平均温度、每日最高温度、每日最低温度、降水概率、风速;而对于日期类型,除了节假日、工作日与周末的区分,还要考虑其周期性变化规律。
为了提高预测精度,寻找更优秀的模型与算法是必要的[3]。过去人们在短期负荷预测方面做了很多研究,有些比较成功,例如目前较为广泛使用的循环神经网络(recurrent neural networks,RNN)[4],但是Bengio等人发现在实际应用中训练RNN会出现梯度问题,即梯度消失和梯度爆炸[5-6]。长短期记忆(long short-term memory,LSTM)模型就是为解决RNN遇到的梯度问题而提出的[7]。LSTM模型能够有效解决RNN中的梯度问题,但同时也存在训练时间过长、参数过多、模型训练较难、输入数据较少时无法得到足够优秀训练模型的问题。LSTM模型提出之后学者们又提出了很多变体。有学者提出了在输入端加入上一时刻记忆细胞状态值的特殊LSTM模型,即加入窥视孔的LSTM模型。在此基础上,本文采用最小窥视孔长短期记忆(min peephole long short-term memory,MP-LSTM)模型,这种模型在保留经典LSTM模型优点的同时,又具有鲁棒性;其另一个特点是有着最少的门控单元(唯一门),将本来需要分开决定的操作,如遗忘、输入、输出进行统一决定,从而优化了结构,减少了参数,且这种模型与经典LSTM模型相比,在输入较少时依然能得到足够优秀的训练模型[8-9]。在优化算法方面,早期研究大多采用模型简单、预测速度快的反向传播(back propagation,BP)算法,但是这种学习算法存在着易于陷入局部最优、无法充分考虑输入数据的时间相关性等问题。本文采用改进粒子群优化(particle swarm optimization,PSO)算法作为优化算法,其相对于BP算法具有很好的全局寻优能力,改善了BP算法易于陷入局部最优的状态,进而提高了预测的准确率[10]。
本文首先介绍RNN模型、经典LSTM模型与MP-LSTM模型;然后简要讨论PSO算法及其改进方法,并详细说明改进PSO算法优化MP-LSTM模型流程;最后,对各个模型的仿真结果进行对比分析。
1 模型介绍
1.1 RNN模型
RNN与普通前向神经网络不同,因为RNN拥有1个可以循环信息的神经元,使得神经元细胞上一个时间步的细胞状态可以影响当前时间步的输出,从而有了记忆的可能。经典RNN模型如图1所示,其中:下标t表示当前时刻,t-1表示上一时刻,下同;St为隐藏层状态值;xt为输入;ot为输出;W为连接上一时刻隐藏层与当前隐藏层之间的权重矩阵;U为连接输入层与隐藏层之间的权重矩阵;V为连接隐藏层和输出层之间的权重矩阵。

图1 经典RNN模型Fig.1 Classic RNN model
由图1可以看出RNN可以对上一时刻隐含层状态值进行记忆,并令其影响当前时刻隐含层状态值。
RNN网络前向计算公式为:
St=tanh(WSt-1+Uxt+b),
(1)
ot=σ(VSt).
(2)
式中:b为偏置矩阵;σ为sigmoid函数。激活函数公式如下:
(3)
(4)
其中对于sigmoid函数(σ)会出现输入较大得不到有效输入的情况,本文通过加入系数2对其进行了修正。
RNN的本质就是通过不停学习得到最优权重矩阵W、U、V和偏移系数b,最终用所得参数进行预测。
1.2 LSTM模型
LSTM模型通过特殊的门控单元(遗忘门、输入门、输出门)代替RNN的记忆细胞结构,利用遗忘门判断上一时刻记忆细胞信息是否对当前时刻记忆细胞有影响,并对上一时刻记忆细胞保留的信息进行删减;利用输入门判断更新信号是否传递到当前时刻记忆细胞,并通过激活函数对记忆细胞状态值进行更新;最后通过输出门输出记忆细胞的输出状态值。LSTM模型不仅可以有效解决RNN模型无法解决的梯度消失和梯度爆炸问题[11-13],还能提高模型预测精度。经典LSTM模型如图2所示,其中ft、it、ot、gt、Ct、ht分别表示遗忘门、输入门、输出门、输入细胞单元状态、细胞单元状态、输出值;“*”用于矩阵时代表矩阵对应位置元素相乘。
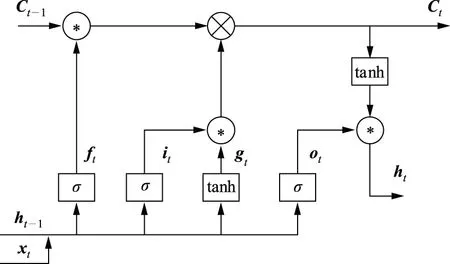
图2 经典LSTM模型Fig.2 Classic LSTM model
LSTM模型前向计算公式如下:
it=σ(Wi[ht-1,xt]+bi),
(5)
ft=σ(Wf[ht-1,xt]+bf),
(6)
ot=σ(Wo[ht-1,xt]+bo),
(7)
gt=tanh(Wg[ht-1,xt]+bg),
(8)
Ct=ft*Ct-1+it*gt,
(9)
ht=ot*tanh(Ct).
(10)
式(5)—(10)中下标“i、f、o、g”分别对应输入门、遗忘门、输出门和输入细胞单元状态。
由式(5)—(8)可知:输入门it主要作用是通过sigmoid函数判断当前时刻更新的输入数据有哪些传送至记忆细胞;遗忘门ft通过sigmoid函数判断之前记忆细胞中哪些信息需要删除;输入细胞状态gt通过tanh函数构建一个当前时刻记忆细胞的候选值,然后与输入门、遗忘门、上一时刻记忆细胞状态值通过式(9)更新当前时刻记忆细胞Ct的值;输出门ot控制记忆细胞的输出状态值;最终输出量ht由输出门和当前时刻记忆细胞状态通过式(10)决定。
1.3 MP-LSTM模型
对于LSTM模型,学界提出了很多变体,其中比较流行的变体是由Gers和Schmidhuber于2000年提出的加入窥视孔(peephole)的LSTM模型[14],这一结构让记忆细胞状态值直接参与到遗忘门、输入门、输出门的计算过程中。加入窥视孔的LSTM模型的遗忘门、输入门、输出门公式分别为:
it=σ(Wi[ht-1,Ct-1,xt]+bi),
(11)
ft=σ(Wf[ht-1,Ct-1,xt]+bf),
(12)
ot=σ(Wo[ht-1,Ct-1,xt]+bo).
(13)
本文采用的MP-LSTM模型是经典LSTM模型的一种变体。MP-LSTM模型只有2个网络层(1个sigmoid层、1个tanh层),以及1个门控单元即唯一门。MP-LSTM模型是在窥视孔连接的LSTM模型上变化而来的,因此在输入中加入了记忆细胞状态值。MP-LSTM模型将原来分开决定的对上一时刻信息的遗忘、对输入信息的更新等,变为同时决定,并用遗忘门来代替输入门和输出门[15]。该模型具体输入门、输出门替换公式分别为:
it=1-ft,
(14)
ot=ft.
(15)
以上公式对任意t时刻均成立。
图3为MP-LSTM结构图,其中ut为唯一门。

图3 MP-LSTM模型Fig.3 MP-LSTM model
MP-LSTM前向计算公式如下:
ut=σ(Wu[ht-1,Ct-1,xt]+bu),
(16)
gt=tanh(Wg[ht-1,xt]+bg),
(17)
Ct=ut*Ct-1+(1-ut)*gt,
(18)
ht=ut*tanh(Ct).
(19)
式(16)—(19)中Wu、bu为唯一门的权重矩阵、偏置矩阵。
与经典LSTM模型不同,MP-LSTM的唯一门ut输入端增加了上一时刻的记忆细胞状态值Ct-1。首先利用sigmoid函数更新唯一门状态值ut,通过式(18)得到t时刻记忆细胞状态值Ct;最终将得到的Ct与唯一门状态值ut通过式(19)决定输出值。
2 PSO算法优化MP-LSTM模型流程
2.1 PSO算法
PSO算法是一种在鸟群觅食行为中学习得到的具有较好全局寻优能力的算法[16-21]。
PSO算法的基本迭代公式如下:
vi,d=wvi,d+c1r1(pi,d-yi,d)+
c2r2(pg,d-yi,d),
(20)
yi,d+1=yi,d+αvi,d.
(21)
式中:yi,d为第d次迭代的第i个粒子的位置;vi,d为第d次迭代的第i个粒子的速度;pi,d为第d次迭代的第i个粒子经过的最优位置;pg,d为第d次迭代所有粒子中经历过的最优位置;w为惯性因子,是非负数;c1、c2为加速常数,是非负常数;r1、r2为[0,1]区间之内变化的均匀随机数;α为约束因子,目的是控制速度的权重。
2.2 改进PSO算法
PSO算法就是利用搜索空间内随机分布的粒子来搜索最优的算法。将第1次随机分布的粒子中效果最好的粒子保持位置不变,而其他粒子按照一定的速度向其移动,这就是第1次搜索。之后的每次迭代,都是保持最优的粒子位置不变,而其他粒子向其移动,最终就会形成类似自然界中鸟群聚集在有食物分布地区的现象,也就是说最终所有粒子位置接近;而最优的选择可以由设定最大迭代次数和最小误差大小来实现,当迭代次数达到最大值或者最小误差小于设定值,停止优化。但是如果所有粒子接近最优值和所有粒子一开始分布各处时粒子移动速度一样的话,会使得算法预测精度降低,且容易跳过最优值点。本文采用惯性权重法对PSO算法进行改进,惯性因子
(22)
式中:dmax为最大迭代次数;wmax、wmin分别为惯性因子的最大、最小设定值。这种惯性权重法的优点在于:在迭代初期粒子位置分布较散,这时惯性因子较大,全局搜索能力较强,利于全局搜索;而到了迭代后期,粒子位置相对接近,这时惯性因子减小,局部搜索能力得到加强,更利于局部搜索。惯性权重法能在迭代次数变化时改变惯性因子,使得PSO算法在全局与局部搜索之间找到平衡,从而提升搜索性能,提高预测精度。
2.3 改进PSO算法优化MP-LSTM模型流程
由上述对神经网络的描述可知,MP-LSTM模型需要训练的权值包括更新门权值Wu、输入细胞权值Wg、偏移系数bu和bg。本文采用改进PSO算法进行优化,将MP-LSTM模型各权值看作空间中搜索粒子的属性,以最终输出预测值与实际值的误差作为目标函数,通过迭代得到目标函数最小值时得到最优权值。
改进PSO算法优化MP-LSTM模型流程为:首先对历史数据进行归一化处理,并对各粒子的速度、位置进行初始化处理;接着利用PSO算法计算各个粒子的初始适应度,通过迭代更新粒子的个体最优以及全局最优位置;当误差小于设定值0.01或者到达最大迭代次数之后结束训练,并将此时所得到的粒子位置赋予MP-LSTM模型神经网络的更新门权值Wu、输入细胞权值Wg、偏移系数bu和bg;然后将训练得到的权值作为预测模型的权值,并利用MP-LSTM模型进行预测;最后,将预测出的所有数据进行反归一化处理,即可得到最终预测结果。
3 算例仿真
3.1 数据处理
负荷数据取自某地区电网,每日采集96个负荷数据,采样间隔为15 min。为提高预测精度,需综合考虑负荷的多种影响因素。本文考虑的天气数据包括:日最低温度、日最高温度、日平均温度、日气象因素、日降水概率、日期类型(工作日为1,非工作日为0)。
在将电负荷数据与天气数据一同作为MP-LSTM模型输入之前,因各种数据单位不统一,需要先对数据进行归一化处理。归一化公式为
(23)
式中:z为输入的真实负荷数据;zmax和zmin分别代表同类型输入数据(负荷数据、天气数据共7类)的最大值、最小值;Z为归一化之后的负荷数据。
将预测日t时刻前3天对应的t-1时刻、t时刻、t+1时刻的9维负荷数据,以及预测日当天的天气数据共15维数据作为MP-LSTM模型的输入,预测日t时刻1维数据作为模型的输出。在对预测日前13天的负荷数据构成的训练样本进行训练后,对预测日进行预测。
3.2 仿真结果分析
为了验证MP-LSTM模型的预测性能,将本文所提出的模型与其他模型进行对比研究。建立4种模型:模型1为使用改进PSO算法优化的RNN模型;模型2为使用改进PSO算法优化的经典LSTM模型;模型3为使用改进PSO算法优化的MP-LSTM模型;模型4为使用常规PSO算法优化的MP-LSTM模型。4种模型全部采用1层LSTM结构,每层10个神经元。激活函数一般有sigmoid、tanh、ReLU等,但是实验表明在神经网络层数较少时tanh函数的效果明显更好,故本文采用tanh作为激活函数。PSO算法优化参数设置为:粒子数50,最大迭代次数1 000,学习因子c1、c2取1.496 2,粒子移动速度最大值vmax、最小值vmin分别取0.4、-0.4,惯性权重的最大值wmax、最小值wmin分别设为0.95、0.4。为测试新模型的预测性能,本文采用了平均误差、最大误差、均方根误差来表征预测误差。
工作日的预测结果如图4所示,预测误差见表1。
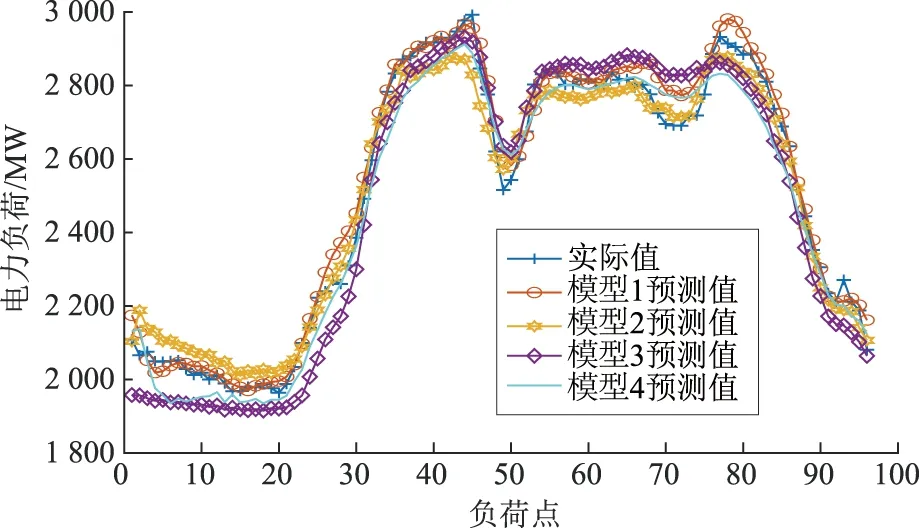
图4 工作日电力负荷预测结果Fig.4 Power load forecast results in working days

表1 工作日电力负荷预测误差Tab.1 Power load forecast errors in working days
由图4和表1可以看出,在工作日:模型3的平均误差、最大误差相对于模型1分别降低了1.80%、2.48%,相对于模型2分别降低了0.53%、0.97%,相对于模型4分别降低了0.47%、2.41%;模型3的均方根误差相对于模型1、模型2、模型4分别降低了46.67%、16.37%、21.36%;模型3的预测值在负荷的波峰和波谷处都能较好地拟合实际负荷值,得到较为理想的预测结果。
非工作日的预测结果如图5所示,预测误差见表2。
由图5和表2可以看出,在非工作日:模型3的平均误差、最大误差相对于模型1分别降低了2.52%、5.50%,相对于模型2分别降低了0.57%、1.47%,相对于模型4分别降低了0.88%、1.28%;模型3的均方根误差相对于模型1、模型2、模型4分别降低了60.45%、35.02%、28.45%。但由于本文训练时间为预测日之前3天的负荷数据,而非工作日之前3天一般都为工作日,所以非工作日的模型精度相对工作日有一定的下降,在高峰期也有一定的偏差;但MP-LSTM模型的最大误差相对于经典LSTM模型和RNN模型有较大降低,体现了MP-LSTM模型的鲁棒性,同时也证明了在输入数据较少时MP-LSTM模型能够比经典LSTM模型得到更优秀的训练模型。

图5 非工作日电力负荷预测结果Fig.5 Power load forecast results in non-work days
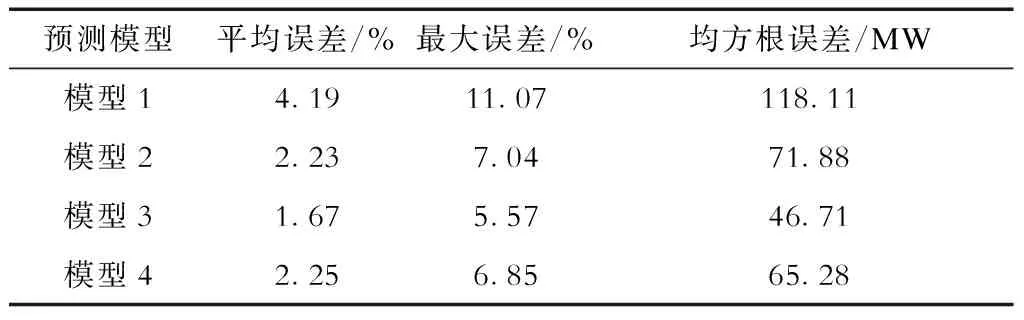
表2 非工作日电力负荷预测误差Tab.2 Power load forecast errors in non-working days
表3为MP-LSTM模型与经典LSTM模型的训练时间及相关参数个数的比较。

表3 模型训练时间及参数个数对比Tab.3 Comparisons of model training time and parameter numbers
由表3可以看出,模型3相较于模型2训练时间减少了33.65%,训练参数减少了40%。MP-LSTM模型相对经典LSTM模型不仅能小幅提升预测精度,还能大幅优化预测模型的训练过程,减少参数。
4 结束语
本文针对经典LSTM模型存在的训练参数多、训练困难等问题,采取了一种全新的MP-LSTM模型。这种模型不仅保留了经典LSTM模型可以避免梯度消失和梯度爆炸的优点,极大减少了训练参数,同时还拥有较少的门控单元(唯一门),模型具有鲁棒性。仿真实验结果表明,MP-LSTM模型在一定程度上相比经典LSTM模型能小幅度提升预测精度,同时能极大减少训练时间与训练参数。
