“80后”职业人群二孩生育行为预测及影响因素分析
——基于随机森林算法
2021-04-01侯丽艳邱红燕
张 浩,侯丽艳,马 萍,邱红燕
(1.宁夏医科大学公共卫生与管理学院,银川 750004;2.大连医科大学公共卫生学院,大连 116044)
为应对老龄化问题,2016年国家实施“全面二孩”政策。2016—2019年全国出生率依次为12.95%、12.43%、10.94%、10.48%[1],并未达到政策预期。经济收入[2]、文化程度[3]及幸福感[4]等都可影响生育行为。目前,基于数据挖掘的机器学习方法已广泛应用于自然科学及社会科学领域,其对于分类数据的判断和预测具有良好的效果。相关研究表明,基于随机森林算法建立的预测模型其准确率、预测价值均优于当前所使用的其他方法[5]。因此,本文选择随机森林算法对生育行为进行建模和预测,以期为二孩政策的完善与实施提供科学依据。
1 对象与方法
1.1 研究对象
采用现况研究设计,综合考虑单位性质、员工构成及研究的可及性,于2016年11月—2017年11月在银川市、大连市和北京市分别选择5家事业单位和5家企业共10家单位作为研究现场,共发放问卷3988份,回收3665份,应答率为91.9%,其中有效问卷3454份,有效率为94.24%。排除非“80后”、未婚、调查问卷关键信息填写不全及实际生育数量超过两个者,最终共纳入1857例调查对象,均为已婚、育1~2个孩子,所有调查对象均经宁夏医科大学医学伦理委员会批准(宁医大伦理第2016-166号),并自愿签署知情同意书。
1.2 调查方法
本研究采用自行设计的调查问卷进行现场调查,内容主要包括个人及家庭基本情况、生育行为相关情况、生育意愿相关情况、生育计划相关情况、物质主义价值观、社会支持、工作压力、生活满意度以及主观幸福感经济等信息。采用现场发放、当场填写、当场回收问卷的方式(部分不能集中填写的单位,则现场发放问卷,约定时间收回)。调查问卷尽量当场审核,不足或遗漏的部分及时补充。调查结束后对问卷再次进行核查,以保证调查结果的准确性和真实性。
1.3 变量定义
1.3.1 物质价值观 采用Richins和Dawson编制的物质价值观量表(material values scale,MVS)测量,该量表共有13个条目,包括以财物定义成功、以获取财物为中心、以获得财物来追求幸福3个维度。每题分为5个等级:非常不同意、不同意、不确定、比较同意、非常同意。得分越高,表明物质主义水平越高[6]。本研究中物质价值观量表的克朗巴哈系数(Cronbach'sα)为0.764,Kaiser-Meyer-Olkin(KMO)值为0.805。
1.3.2 工作压力 采用工作内容问卷(job content questionnaire,JCQ)和付出-回报失衡问卷(effort reward imbalance questionnaire,ERIQ)。JCQ量表共22个条目,包括工作要求、工作自主和社会支持3个维度,每题4个等级,分别为非常不同意、不同意、同意和非常同意,本文在评估职业人群工作压力时,以三个模块得分的均数为临界点将它们划分成高低水平组[7]。
ERIQ量表共23个条目,包括付出、回报和超负荷3个维度,每题分为5个等级:不同意、完全不困扰、有点困扰、困扰和非常困扰。计算付出-获得不平衡指数(ERI ratio),ERI ratio=付出因子得分/(回报因子得分×C),C为付出项目个数与获得项目个数的比值,即6/11。如果研究对象的ERI ratio>1.00,则认为其存在职业紧张;若ERI ratio≤1.00,则表示其无职业紧张[8]。本研究中工作内容量表的Cronbach'sα为0.890,KMO值为0.893;付出-回报失衡量表的Cronbach'sα为0.886,KMO值为0.896。
1.3.3 社会支持 采用肖水源和杨德森(1987)编制的社会支持评定量表(SSRS)进行测量,评估个体所获得的社会支持水平。量表共10个条目,包括客观支持、主观支持和对社会支持的利用度3个维度。量表总分数越高,表示获得的社会支持度越高[9]。本研究中社会支持量表的KMO值为0.892。
1.3.4 生活满意度 采用生活满意度量表(satisfaction with life scale,SWLS)中文版,量表包括5个题目,每个项目有7个判断等级,从“非常不符合”到“非常符合”分别用数字1~7表示。被调查者在回答量表题目时按照每个题目与自己实际情况相符合的程度选择1个等级选项,计算量表题目的得分均数,高于均数为生活满意度高水平,低于均数为低水平[10]。本研究中生活满意度量表的Cronbach'sα为0.807,KMO值为0.821。
1.3.5 主观幸福感 采用Campbell幸福感指数量表(index of well-being,index of general affect)来评估个体幸福的状态。该量表共9个条目,分为总体情感指数和生活满意度两部分,前者由8个情感项目组成,后者由1个满意度项目组成,为7级计分。总体情感指数的平均得分与生活满意度得分(权重为1.1)相加即为总体幸福感指数,其范围为2.1(最不幸福)~14.7(最幸福)。得分越高,表明越幸福[11]。本研究中总量表的KMO值为0.860。
1.4 统计学方法
1.4.1 数据处理方法采用Epi Data 3.1软件对所有调查问卷进行双录入核查,采用SPSS 24.0进行异常值的删除及缺失值的填补;采用R-4.0.2进行统计分析,建立随机森林模型,以3∶1的比例将数据集分为训练集和测试集,采用训练集建立预测模型并进行变量重要性排序,采用测试集检验模型的预测效果,采用十折交叉验证筛选最优变量数;采用多因素Logistic回归分析最优变量对生育行为的影响及程度。检验水准α=0.05。
1.4.2方法说明 随机森林算法:随机森林是由很多决策树组成的,每一棵决策树之间没有关联。决策树的数量并非越多越好,应先设置一个较大的决策树进行试探,根据结果进行调试,找出多少棵树时模型最优。在得到森林之后,当对一个新的样本进行判断或预测时,让森林中的每一棵分类树分别进行判断,并看这个样本应该属于哪一类(分类算法),根据分类树的投票结果确定测试样本的分类结果;根据袋外误差评价分类的准确性;根据基尼(Gini)指数判断变量对分类树中每个节点观测值的异质性。平均Gini值下降越多,说明变量越重要[12]。
十折交叉验证:十折交叉验证将样本数据随机分为10份,每次随机选择9份作为训练集,剩下的1份作为测试集。当这一轮完成后,重新随机选择9份来训练数据。若干轮(<10次)之后,选择损失函数评估最优的模型和参数[13]。
模型评价:采用混淆矩阵和ROC曲线评价生育行为预测模型的预测价值,计算特异度、灵敏度、预测准确率、约登指数及ROC曲线下面积(AUC)。AUC值越高,表明模型预测价值越大。
2 结果
2.1 一般人口学情况
本次研究共纳入调查对象1857例,平均年龄为(32.7+3.3)岁。其中男性占27.4%;汉族占87.6%;本地人口占70.4%;文化程度以本科学历者比例最高,为47.4%;月收入以3000~5000元者最多,占56.1%;非独生子女者占55.1%;事业单位职工占52.2%;工勤技能岗职工占49.4%,见表1。

表1 调查对象一般人口学特征描述
2.2 赋值
对人口学特征、生育行为及相关变量进行赋值,见表2。
2.3 变量重要性排序
利用训练集建立基于随机森林模型的生育行为风险预测模型,利用随机森林分类器获得变量重要性排名,由高到低分别为:生育计划、一孩经历对生活的影响、一孩经历是否符合预期、主观幸福感、年龄、社会支持、照顾孩子时间、文化程度、意愿子女数、性别偏好、孩子三岁前由谁照顾、一孩年抚养支出、理想子女性别构成、工作单位、独生子女、工作岗位、月收入、户籍、工作要求、性别、生活满意度、以获取财物为中心、工作支持、以财物定义成功、工作自主、ERI ratio、民族、通过获取财物追求幸福,见图1。
2.4 模型评价
2.4.1 混淆矩阵 利用混淆矩阵评价模型效果。结果显示,预测为“一个孩子”错误的概率为0.03,预测为“两个孩子”错误的概率为0.17,见表3。根据混淆矩阵结果计算,模型整体判断准确率为95.4%,预测准确率为97.3%,灵敏度为97.4%,特异度为82.2%。

表2 变量赋值情况表

图1 变量重要性排序

表3 混淆矩阵情况
2.4.2 ROC曲线 采用随机森林算法在训练集建立二孩生育行为预测模型对测试集进行预测,AUC值为0.913,特异度为0.981,灵敏度为0.845,预测一致率为0.949,约登指数为0.826,见图2。

图2随机森林模型ROC曲线
2.5 筛选最佳变量个数
采用十折交叉验证筛选最佳变量个数。结果显示,变量个数为4~9时交叉验证错误率最低。根据变量重要性排序,选择前9个变量作为最佳变量,依次为生育计划、一孩经历对生活的影响、一孩经历是否符合预期、主观幸福感、年龄、社会支持、照顾孩子时间、文化程度和意愿子女数,见图3。
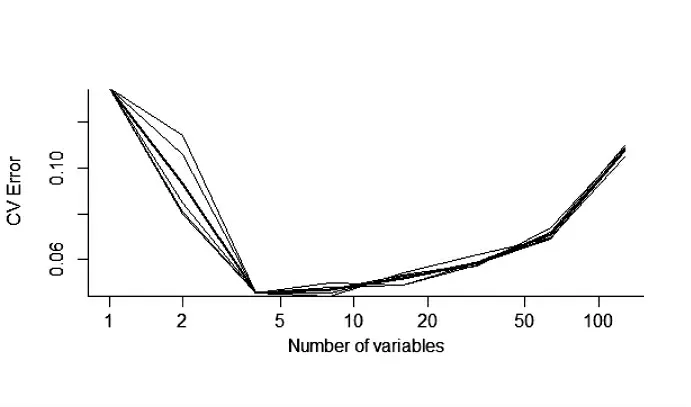
图3 十折交叉验证
2.6 逻辑回归
由于生育计划、一孩经历对生活的影响和一孩经历是否符合预期这3个变量分布的差异过大,导致进入Logistic回归后OR值过大,因此不考虑纳入。进一步根据随机森林变量重要性排序顺次选择主观幸福感、社会支持、年龄、照顾孩子时间、文化程度、意愿子女数作为自变量,生育行为作为因变量进行多因素Logistic回归(赋值:一个孩子=0,两个孩子=1)。结果显示,社会支持、文化程度、意愿子女数对生育行为的影响均有统计学意义(P均<0.05),社会支持得分越高,生育二孩的可能性越大,OR值为1.03(95%CI=1.01~1.05);大专、本科、研究生及以上学历者生育二孩的可能性分别是高中及以下学历者的0.56倍(95%CI=0.37~0.85)、0.45倍(95%CI=0.33~0.62)和0.25倍(95%CI=0.12~0.52);意愿子女数为两个孩子以上者生育二孩的可能性是不要孩子者的7.89倍(95%CI=2.29~27.15),见表4。
3 讨论
生育行为直接反映了二孩政策的实施效果,提高育龄人群的生育行为是解决我国老龄化问题的最根本途径。关于生育行为影响因素的研究,目前应用最广泛的方法是多因素Logistic回归分析。由于影响因素很多,某些不显著因素的综合作用可能对生育行为产生较大影响,但只有显著变量才可以引入Logistic回归模型中,因此Logistic回归方法不一定能够准确地对生育行为进行判别和预测。本研究运用随机森林算法建立模型对生育行为进行预测,找出影响生育行为的最主要因素,为政策的制定和完善提供更为准确的方向和依据,从而促进人口出生率的提高。

表4 生育行为影响因素的多因素Logistic回归分析
随机森林算法作为一种以决策树为基学习器的集成学习算法,简单、易于实现,本身精度明显优于大多数单一算法,优于其“两个随机性”,能够很好地避免过拟合问题,解决了描述性统计分析难以避免的变量间的相互作用。本次研究对随机森林模型的评价采用混淆矩阵和ROC曲线两种方法。混淆矩阵结果显示,模型预测一个孩子和两个孩子的分类错误均较低,模型整体判断准确率、预测准确率、灵敏度及特异度均较高。ROC曲线结果显示,模型的灵敏度、预测一致率、约登指数均达到满意程度,AUC值为0.913。两种评价方法评价结果差别不大,均显示模型预测精度较高。李冬领等[14]比较了随机森林模型与Logistic回归模型对二孩生育意愿的预测效果,发现随机森林模型的正确率、查准率、查全率、AUC值均高于Logistic回归模型。另外,随机森林算法无法解释变量的作用方向及其影响程度,因此,结合多因素Logistic回归模型进行分析,可以得到更加准确和完善的结果。
本次研究结果显示,社会支持、文化程度和意愿子女数是二孩生育行为的主要影响因素。首先,获得的社会支持越高,二孩生育率越高。一项探讨有妊娠经历育龄青年女性二孩生育意愿的研究显示,主观社会支持对有妊娠经历的年经女性的二孩生育意愿具有正向影响,该人群的心理弹性对生育意愿的影响则受社会支持利用度的调节[15]。另一项研究[16]表明,女性选择生育二孩的原因可以分为主要选择和被动选择两种。无论是主动还是被动,女性选择生育二孩都受到良好的夫妻感情、较好家庭的经济情况、长辈的帮助及亲朋好友支持的影响,生育二孩的女性绝大多数都获得了较高的社会支持,与本文研究结论一致。其次,文化程度越高,二孩生育率越低。一项针对广西省不同职业妇女生育水平的研究[17]显示,随着女性文化程度的提升,初婚、初育年龄产生了明显的后移,这可能是导致高文化程度伴随低生育水平的主要原因。另外一项研究[18]认为,文化程度较高的女性拥有较高的职业追求和精神生活追求,主观上并不希望多生、多育,此外职业追求势必造成晚婚及晚育,推迟了初育年龄,错过了生育旺盛期,降低了生育二孩的机会。因此,文化程度通过不同方面的作用对生育行为产生间接影响。最后,意愿子女数高的人群更有可能生育二孩。意愿子女数是个人对生育子女数量的理想态度,反映人群的生育意愿。研究[19]表明,二孩政策实施后,生育意愿与生育行为产生了明显的悖理现象,较高的生育意愿与较低的生育行为,表明了我国正在面临低生育率陷阱的高度风险[20]。主观的生育意愿对生育行为的影响不可忽视。本文研究中,已生育二孩的人群,其意愿子女数为两个以上者所占的比例最高。
随机森林算法对大样本量的数据具有更好的预测效果。本次研究存在一定局限性,即样本量相对较少,导致某些变量的分布存在一定的偏差,下一步增加样本量可有效提高模型的准确率和精确度。
