基于改进SSD的无人驾驶夜间目标检测
2021-04-01卜德飞孙韶媛王宇岚刘致驿
卜德飞,孙韶媛,黄 荣,王宇岚,刘致驿
(东华大学 a.信息科学与技术学院;b.数字化纺织服装技术教育部工程研究中心,上海201620)
目前大部分无人驾驶的环境感知相关研究集中于白天场景,而夜间场景下的研究相对较少,这使得无人驾驶在夜间的应用十分有限。夜间无人驾驶可以利用红外相机感知周边环境物体的温感成像,但形成的图像较普通,图像存在纹理信息少、噪声多、图像模糊等缺点[1],故夜间目标检测难度较大。有效的夜间目标检测能够减少交通事故的发生,应用价值较高。
目前,基于深度学习的目标检测算法已经超越传统检测方法,成为当前目标检测算法的主流,主要包括单阶式(One-stage)目标检测和两阶式(Two-stage)目标检测算法两类。Two-stage算法以Faster RCNN(faster region convolution neural network)网络[2]系列目标检测方法为主,需要进行候选区域的提取,速度相对较慢,无法满足实时性的要求。One-stage算法以SSD(single shot multibox detector)网络[3]和YOLO(you only look once)网络[4]为主,这类网络直接进行端到端的学习。SSD网络与YOLO网络的思想均是将目标检测任务由分类问题转化为回归问题,一次完成目标定位与分类。SSD网络基于Faster RCNN网络中的锚点机制,提出了相似的Prior box方法。SSD网络加入基于特征金字塔的检测方式,即在不同感受野的特征图上预测目标。
针对红外图像特征纹理低、噪声多和图像模糊等问题,本文提出改进SSD网络的算法:(1)采用特征提取能力更强的Densenet网络[5]替换SSD网络原有的特征提取网络,提升表征能力;(2)重新利用特征图,增强浅层特征的利用程度;(3)引入反卷积网络,丰富特征的语义信息;(4)采用无预训练模型的方法训练网络,使得网络参数得到最优解。本文针对改进部分做了不同的对比试验,最终验证了改进算法的有效性。
1 网络结构
本文以SSD网络为基础,将特征提取网络由VGG-16(visual geometry group network)[6]网络替换为Densenet网络,利用稠密连接的方式将网络中多尺度的特征图进行重利用,并添加反卷积层[7],最终将卷积层和反卷积层中相同分辨率的特征图进行融合后送入预测层。
1.1 SSD网络
SSD网络检测速度快且精确率较高。借鉴YOLO网络将目标检测任务由分类问题转化为回归问题的思想,无需区域候选框的提取过程,大大缩短了检测时间。同时借鉴Faster RCNN网络的锚点机制,即在特征图的每个像素上产生一定个数(4或6)且纵横比确定的默认框。SSD网络的主要贡献是在不同尺度的特征图做预测,提高对物体的检测准确性。
SSD网络的网络结构如图1所示,输入表示为一张图像(300像素×300像素),首先根据其输入特征提取网络,原始的SSD网络结构采用VGG -16网络,将VGG -16网络的fc6和fc7层转化为卷积层,去掉所有的Dropout层和fc8层,添加额外的卷积层Conv9、Conv10、Conv11。与YOLO网络、Faster RCNN网络等不同,SSD网络对不同分辨率的特征图(Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2)进行多尺度预测,并利用两个卷积层(卷积核尺寸为3×3)分别进行位置回归和类别置信度预测。最后经过非极大值抑制删除一部分重叠或者不正确的边界框,生成最终的边界框集合。
位置回归采用smoothL1损失,置信度损失采用softmax损失,总的损失为两者之和,如式(1)所示。Lconf(x,c)表示置信度损失,Lloc(x,l,g)表示位置回归损失,这两个损失所占的比重通过系数α调节。
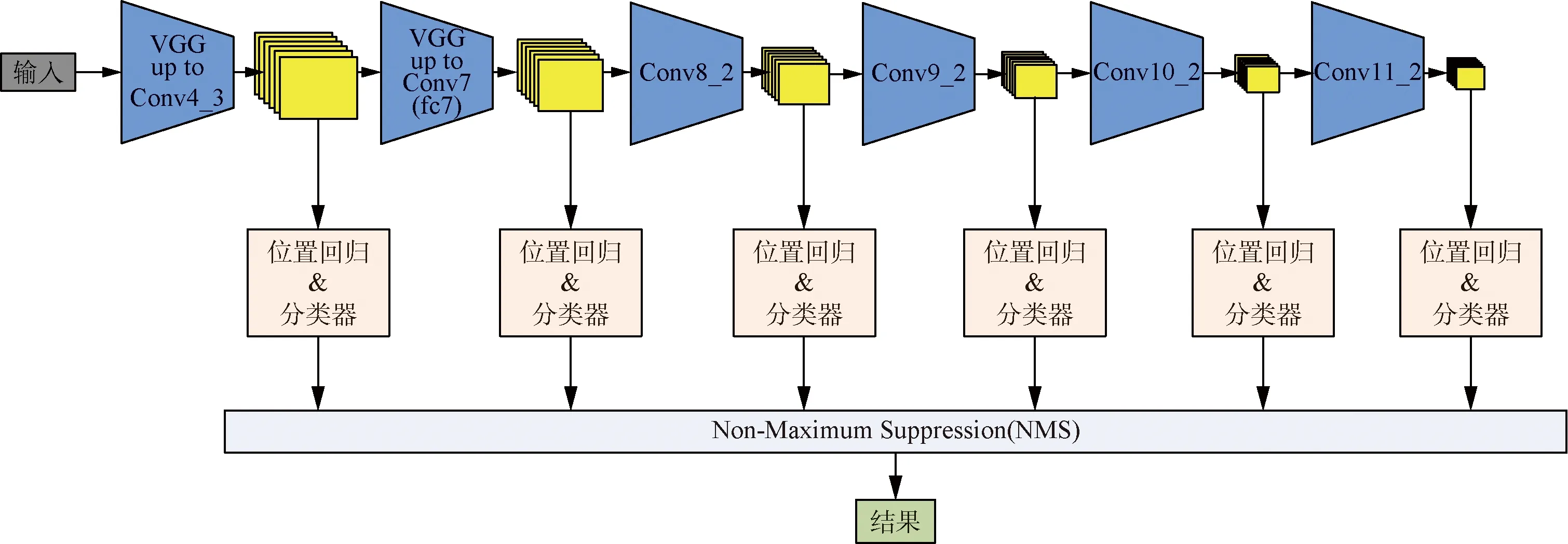
图1 SSD网络结构Fig.1 Network structure of SSD
(1)
位置回归损失的回归默认框d的中心偏移量(cx,cy)以及宽w、高h,如式(2)所示。
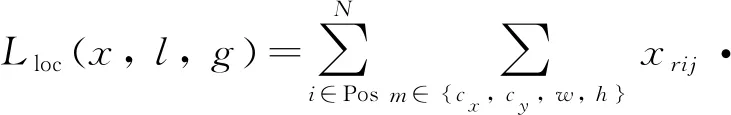
(2)
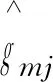
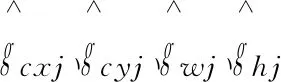
(3)
(4)
(5)
(6)
置信度损失是多个类别的softmax损失之和,如式(7)所示。
(7)
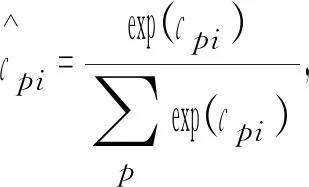
1.2 改进的SSD网络
本文对SSD网络进行了改进,其网络框架如图2所示,在卷积层之后加入反卷积层,对卷积层的特征图与反卷积层的特征图进行融合,将融合后的特征图送入预测器,损失函数和原SSD网络一样。
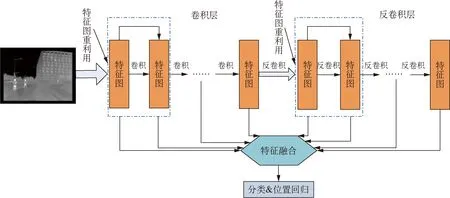
图2 改进的SSD网络框架Fig.2 Improved SSD network framework
改进的SSD网络结构如图3所示,在原网络中引入稠密连接,并在最后一层卷积层后加入反卷积层,将其特征图尺寸通过反卷积操作一直扩大到与原SSD网络卷积层Conv4_3特征图的尺寸相同。然后通过对降采样之后的特征图做反卷积操作,将特征图尺寸扩大,并获取比卷积层输出相同尺寸的特征图更加丰富的语义信息。预测阶段将卷积操作生成的特征图与反卷积操作生成的特征图进行拼接,再将拼接后的结果送入检测器和分类器中进行处理。
1.2.1 特征提取网络的替换
相比VGG-16网络,Densenet网络含有更少的参数量,可促进特征重利用,并具有隐含监督等优势。本文借鉴深度监督目标检测器DSOD[8]的替换规则,将卷积过程中的特征提取网络VGG-16换成了Densenet网络,以降采样后特征图尺寸相同为标准,用Densenet网络中的模块代替VGG-16网络,以确保最终送入检测器的特征图尺寸与原网络的特征图尺寸保持一致。
1.2.2 特征图的重利用
SSD网络按照逐层卷积的方式,将特征图依次传播下去,每个卷积层生成的特征图仅使用1次。本文对特征图进行稠密连接,融合后重利用。特征图的拼接需要保证尺寸一致,故将上一卷积层产生的特征图进行尺寸减半操作,如图4所示,其中h和w是图像的高和宽,P1和P2是图像的通道数。由图4可知,将上一卷积层的特征图利用1个1×1卷积层和1个2×2最大池化层进行尺寸的减半,接着与当前卷积层得到的特征图进行拼接操作。为了避免特征图的稠密连接导致通道数过度增加的问题,本文在每次拼接操作之后利用1×1卷积进行降维。
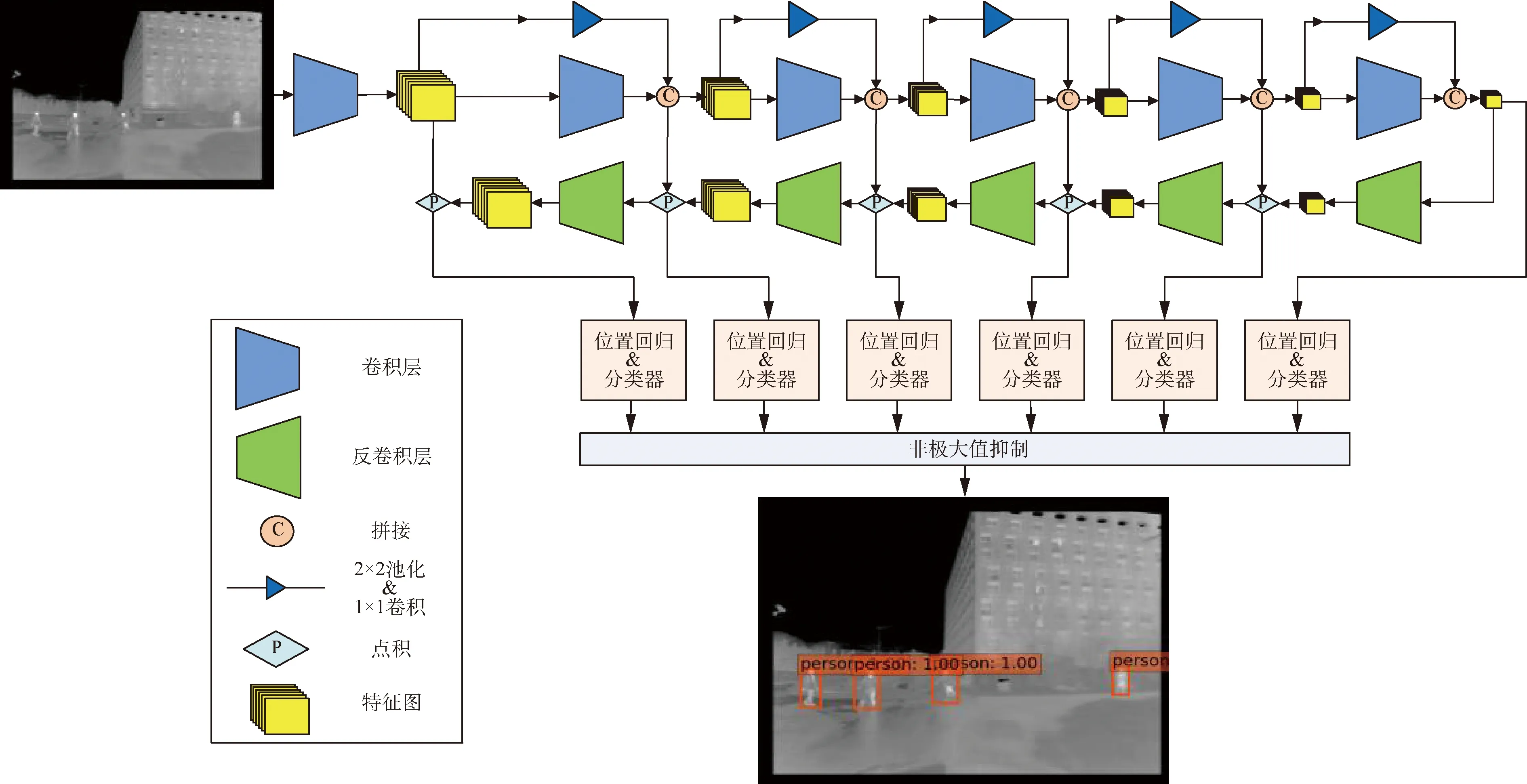
图3 改进的SSD网络结构Fig.3 Network structure of improved SSD
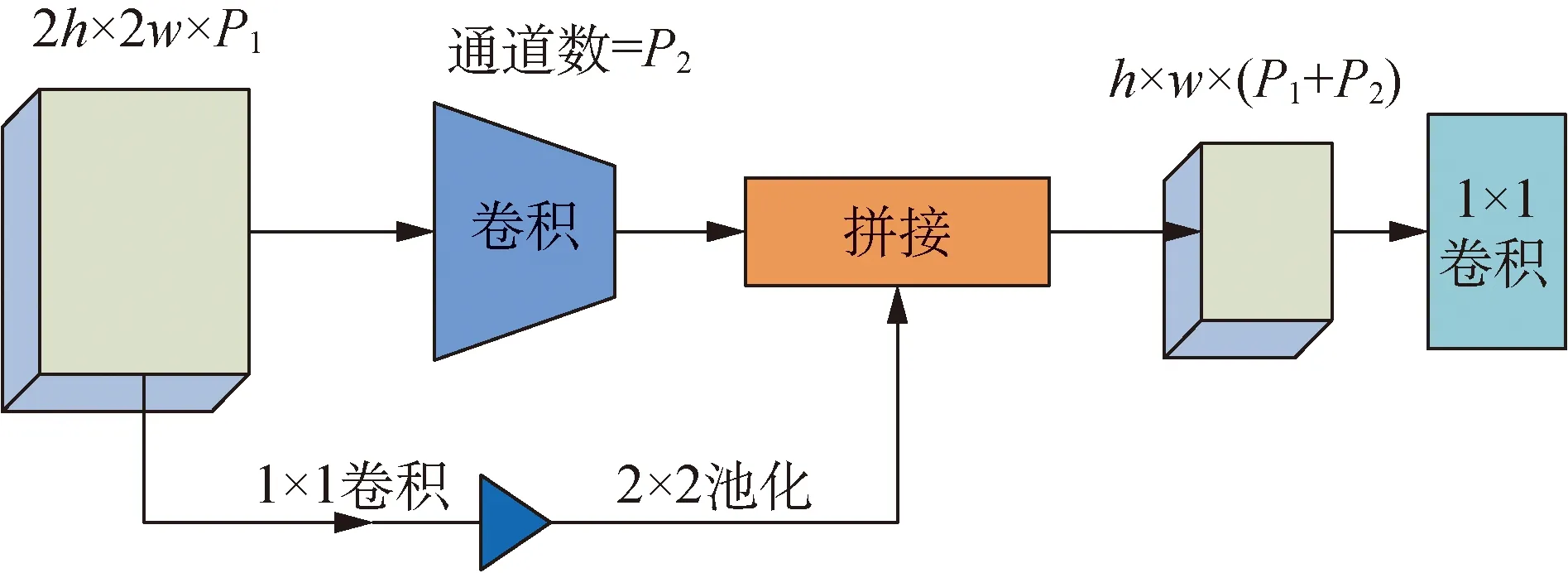
图4 特征图重利用Fig.4 Reusing feature map
1.2.3 反卷积的引入
卷积过程中尺寸大的特征图往往具有较小的感受野,而具有大感受野的特征图的尺寸较小,对小物体不敏感,这导致SSD网络对中小目标的检测不够准确。本文引入反卷积操作,不仅能够对尺寸小但感受野大的特征图进行尺寸放大,而且在操作过程中使用稠密连接能够增加特征的重利用,具体操作如图5所示。先对小尺寸的特征图进行反卷积操作,然后对扩大了尺寸的特征图进行3×3卷积和批处理正则化[9],通过点积的方式将反卷积处理后的特征图与卷积过程得到的特征图进行融合。
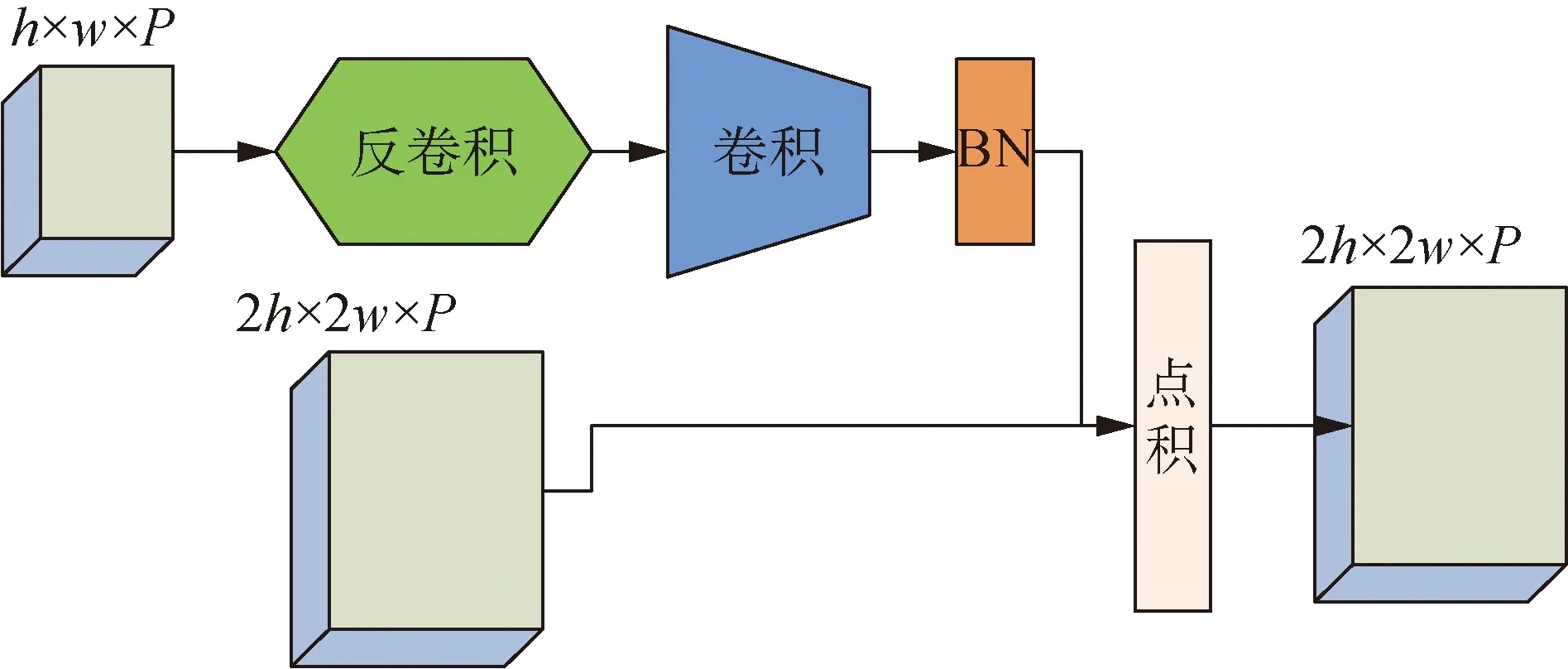
图5 反卷积模块Fig.5 Deconvolutional module
2 红外数据集与训练方法的选择
本试验数据由载有红外摄像头的无人车在夜晚拍摄所得,将被检测的物体分为行人和车辆。完整数据集包括4 500张红外图像(共标记27 891位行人、15 548辆车),其中,训练集为3 500张,验证集为500张,测试集为500张。
本文对红外数据集进行分析,发现该数据集适合使用无预训练方法进行训练,原因如下:
(1) 数据特征不同。红外图像与公开数据集(如ImageNet[10]、Pascal_VOC[11])中的图像格式不一致,主要表现为红外图像是单通道的灰度图像,而公开数据集则是三通道的RGB图像。灰度图像具有纹理低、图像清晰度低、噪声多等不良特性。直接从RGB图像数据集进行迁移学习可能会使模型达到局部最优解,但无法拟合全局最优解。
(2) 样本数量不均衡。相比经预训练模型训练的公开数据集,本地数据集样本较少,且公开的预训练模型多在公开数据集上迭代10万次以上才得以生成,这将导致模型拟合的特性更加偏向于样本数量多的公开数据集。
(3) 网络结构受限。采用预训练模型的训练方式时,需要在预训练模型上进行参数微调,并要求网络必须采用与预训练模型相匹配,这将增大网络结构调整难度。
(4) Densenet网络的“深度监督”与正则化效应。Densenet网络的稠密连接优化了网络中的信息流和梯度,每个隐层都可以直接从损失函数和原始输入信号中获得梯度,从而产生隐含的深度监督,这有助于模型的训练。稠密连接也具有正则化效应,缓解了因训练集样本数量少而导致的过拟合现象[6]。因此,借助Densenet网络的优点能够使训练网络快速拟合。
3 试验过程及试验结果分析
3.1 试验设备
本文算法使用Caffe框架[12],试验的软硬件配置如表1所示。

表1 试验的软硬件配置
3.2 试验过程
试验流程如图6所示。由图6可知,利用红外相机进行数据采集(数据集有行人和车辆两类),并通过标记工具LabelImg对采集到的图像进行标注,将标注后的数据图像生成为适合Caffe输入的lmdb文件。使用训练集对改进的SSD网络进行迭代训练,设置基本学习率为0.1,动量为0.9,每迭代10 000 次对学习率除以10,迭代次数为50 000次,训练耗时约213 h(8.9 d)。不断的迭代学习使网络模型收敛,然后将网络模型参数存储下来,最后用测试集进行测试和验证。

图6 试验流程图Fig.6 Flow chart of the experiment
3.3 网络参数设置
反卷积参数如表2所示,反卷积的输入为卷积最后一层的输出特征图,根据式(8)来确定使用的卷积核参数,以保证得到需要的特征图尺寸。
Fout=s×(Fin-1)+a-2p1
(8)
式中:Fout表示输出特征图尺寸;Fin表示输入特征图尺寸;s表示步长;a表示卷积核大小;p1表示填充。
3.4 试验结果分析
不同检测网络的损失值随训练迭代次数的变化如图7所示,所有网络均采用相同的损失函数。图8为最后10 000次迭代的结果。SSD_YES是使用了预训练模型的SSD网络;SSD_NO是未使用预训练模型的SSD网络;Ours(k=12),Ours(k=48)为本文提出的改进SSD网络,区别是Densenet网络中生长率k的取值不同。
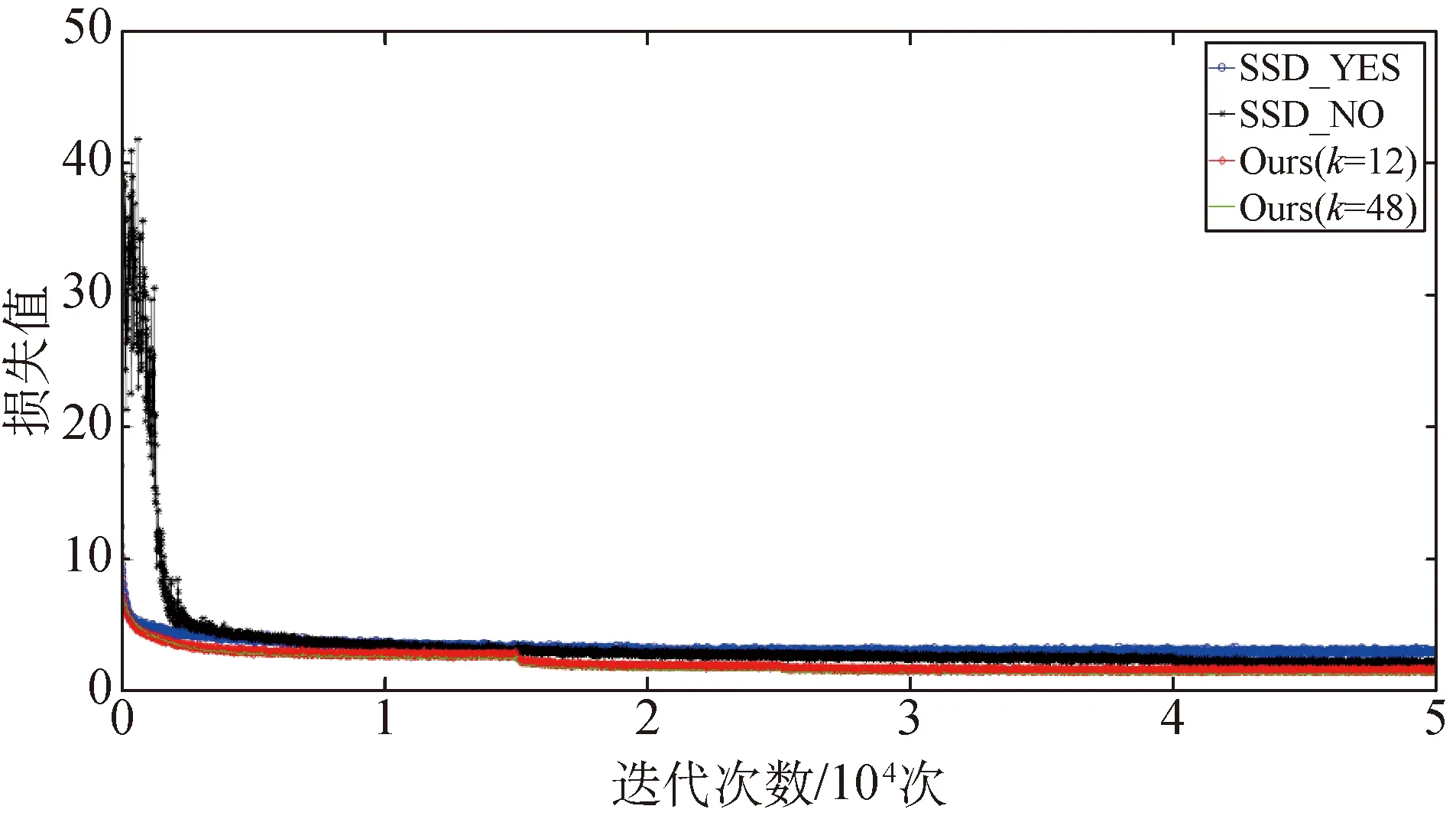
图7 训练损失随训练迭代次数的变化Fig.7 Training loss varying with the number of iterations
对比图7中SSD_YES与SSD_NO的曲线,可以看出,有预训练模型的SSD_YES能够很快收敛,而SSD_NO则在训练开始会有剧烈的波动。这是因为无预训练模型的方法是对参数进行随机初始化,这将使得刚开始的梯度较大。在图8中继续对比这两条曲线,SSD_NO能够达到更小的损失值,说明其能够达到更优的局部最优解或全局最优解。这一结果表明采用无预模型训练方法能够得到更优的模型参数。
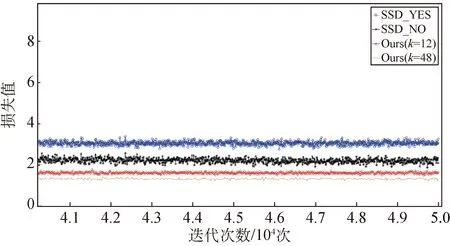
图8 最后104次迭代的损失变化Fig.8 Loss varying with the last 104 iterations
由图8可知,使用生长率为k=48的本文网络相比使用生长率为k=12的损失值更低。这表明滤波器通道数的增加能够提取更多的特征,更好地学习数据的特性。
表3为不同算法的性能对比:SE-MSSD网络为刘学等[13]针对红外图像行人检测而改进的SSD网络,其中使用Mobilenet网络作为特征提取网络,加入SENet模块进行特征提取,并使用深度可分离卷积加快运行速度;SE-MSSD_NO为SE-MSSD网络通过无预训练模型方式训练得到的结果;SE-MSSD_YES为SE-MSSD网络加载了预训练模型得到的结果。文献[13]中提到在数据集上SE-MSSD网络要比SSD网络的准确率更高,而在本文的数据集上,效果却很差。分析原因是本文所使用的数据集图像质量更差,目标更小,且目标重叠密集,而SENet模块在做特征权重分配时更加注重主要特征而忽略次要信息,因此对小目标和密集目标的检测效果较差。
与SSD_YES相比,SSD_NO有着更高的平均准确率,两者网络结构完全一样,表明无训练模型方法可更好地拟合数据集特性。De_SSD_NO是加入反卷积后的SSD网络不加载预训练模型得到的训练结果[15],De_SSD_NO相比SSD_NO准确率提高,这证明了引入反卷积确实是有益的。SSD_densenet(k=48)是更换特征提取网络为Densenet(k=48)的SSD网络,SSD_densetnet(k=48)相比SSD_NO能够得到更高的平均准确率,这表明Densenet网络取代VGG网络是有效的。对比Ours(k=48)与SSD_densenet(k=48)和De_SSD_NO,结果证明同时使用这两个操作比单独使用一个有着更高的准确率。
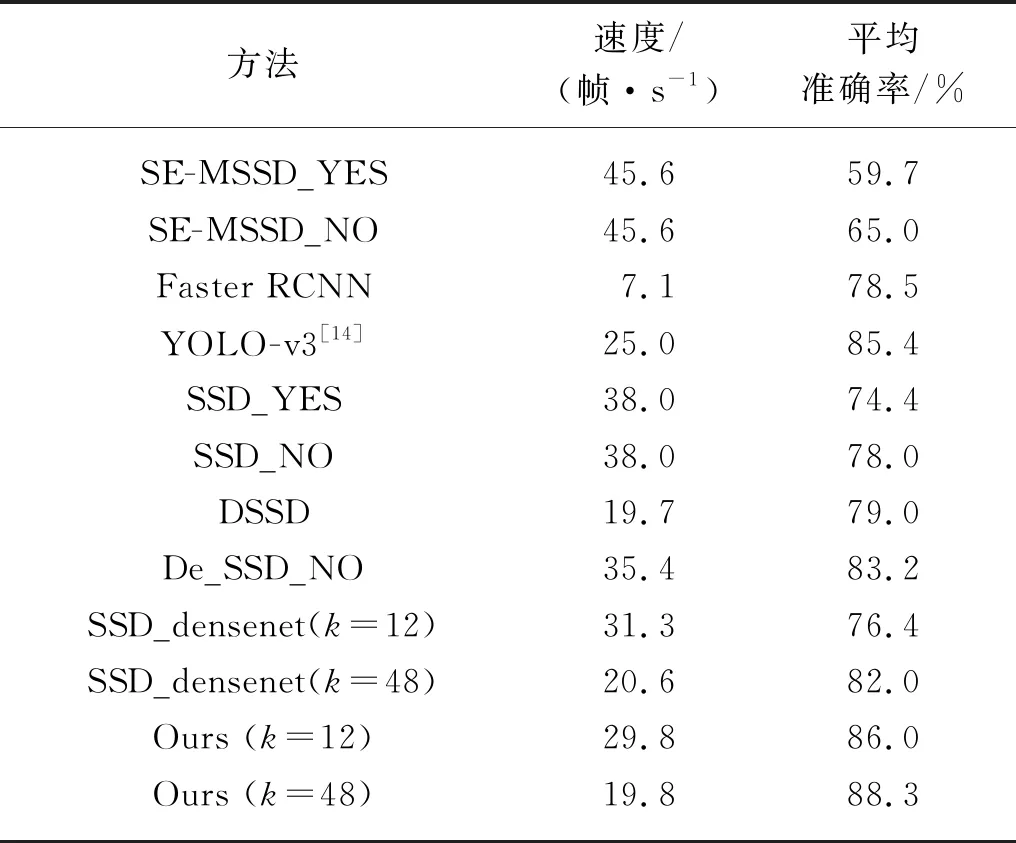
表3 不同算法的性能对比
特征提取网络VGG-16的参数量为22 935 232个,Densenet网络的参数量为12 184 324个,但由表3可知,本文的Ours(k=48)的检测速度低于SSD网络,其原因在于Densenet网络进行特征提取时相比VGG-16网络使用了更大的特征图,增加了计算复杂度。
本文的Ours(k=12)与YOLO-v3网络的平均准确率相同,但检测速度却更高。改进的Ours(k=48)在保证更高的检测准确率的同时,依然有很快的速度,满足了无人车夜间检测的需求。
图9分别展示了测试图像、人工标记图像、SSD网络的检测结果和本文算法的检测结果,人工标记图像中的深红色框为实际目标检测框,而SSD算法结果图与本文算法结果图中的矩形框为模型预测得到的目标位置框,其上方显示了这个目标框内目标的类别与概率得分。
4 结 语
本文对无人驾驶的夜间目标检测方法进行分析,鉴于红外图像成像质量差,并且现阶段目标检测算法对中小目标检测效果较差,尝试使用Densenet网络进行特征提取,并对包含中小目标信息的特征图进行重利用,以增强特征提取能力,并在原有网络的基础上加入反卷积层,将卷积层的特征图与反卷积层相同尺寸的特征图融合,结果证明这对于特征图的信息提取是有益的。
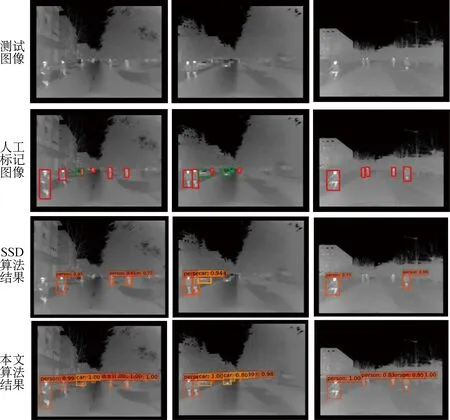
图9 红外图像目标检测Fig.9 Infrared image target detection
