基于CPU-GPU异构体系结构的并行字符串相似性连接方法
2021-04-01徐坤浩聂铁铮申德荣
徐坤浩 聂铁铮 申德荣 寇 月 于 戈
(东北大学计算机科学与工程学院 沈阳 110169)
(xukunhao725@163.com)
随着传统互联网的发展和移动互联网的出现,数据量迅速变大,“大数据”的概念逐渐被人们熟知.但大量的数据也对传统的数据存储和处理带来了新的挑战.为了更快地处理大数据,人们采用例如MapReduce和HDFS(Hadoop distributed file system)等分布式的策略来计算和存储大数据.传统的CPU性能提升方法已经达到瓶颈,提高主频和核心数量等方法对CPU性能的提升变得越来越困难,仅由CPU负责计算的传统相似性连接算法的处理速度已经渐渐满足不了用户的需求.近年来,GPU的处理性能和并行处理单元集成度提升迅速,更多的算术逻辑单元使得GPU的综合计算性能远超CPU.GPU能够极大地解决CPU处理能力不足的问题,因此基于CPU-GPU异构体系结构的处理模式正成为未来的发展趋势.
相似性连接处理技术是对来自不同数据集的2个对象计算相似度,并以相似度是否达到指定阈值作为对象间的连接条件.目前,相似性连接技术已经被广泛地应用在搜索引擎、数据集成以及知识库构建等领域.根据计算对象间相似度的算法不同,常见的相似性连接可以分为字符串相似性连接、集合相似性连接、向量相似性连接以及图相似性连接,其中以字符串相似性连接应用最为广泛.字符串的相似性可以通过Jaccard相似度等多种相似性度量进行计算.传统的相似性连接处理技术一般使用过滤-验证框架,包含过滤和验证2个部分:在过滤阶段设计高效的过滤算法将大量不可能符合相似度要求的数据记录对过滤剔除,大幅减少候选对的数量;在验证阶段,计算每个候选对的相似度,将满足相似度条件的候选对添加至最后结果.
目前,对相似性连接算法的优化主要集中在过滤阶段的优化,通过对过滤算法的优化来提升过滤效果.现有研究工作提出了很多过滤算法,包括基于倒排索引的计数过滤算法[1]、基于位置的过滤算法[2]、基于长度的过滤算法[3]以及基于前缀的过滤算法[4].这些算法在一定程度上都提升了过滤阶段的效率,但大部分都是基于串行处理的设计思想,处理效率受到了极大的限制.因此,本文主要研究通过CPU-GPU异构体系结构并行处理相似性连接算法,提高相似性连接算法的处理效率.由于CPU与GPU在计算模型上的巨大区别,传统的相似性连接算法无法直接在GPU上直接运行.GPU强大的计算能力来源于大量的核心带来的高并行度,通过大量核心并行的执行计算提高任务处理效率,但GPU存在不适合执行复杂逻辑控制的缺点.因此基于GPU实现相似性连接的加速处理,就必须根据GPU的处理架构特点设计相应的处理策略和优化方法.
本文主要研究基于CPU-GPU异构体系结构的并行相似性连接处理方法,通过将任务进行分解并运行在不同处理器架构上,提升任务并行性,从而提高基于过滤-验证模型的相似性连接处理效率.本文的主要贡献有4个方面:
1) 提出了基于CPU-GPU异构体系结构的并行相似性连接处理策略,充分利用GPU的并行计算能力和CPU的逻辑计算能力.
2) 提出了基于GPU的倒排索引结构和构建方法,并采用SoA(struct of arrays)结构提升并行计算时倒排索引的构建速度.
3) 提出了面向长度过滤和前缀过滤算法的GPU并行过滤方法,提高记录对的过滤效率.
4) 通过对比实验证明了所提出的并行算法可以有效地提升相似性连接中并行处理的执行效率,并分析了不同条件下算法的性能表现.
1 相关工作
目前,关于相似性连接技术的研究工作可以分为基于串行技术的方法和基于并行技术的方法.
基于串行的相似性连接研究主要集中在对匹配记录对过滤算法的优化以及不同类型数据的相似性连接算法2个方面.Rong等人[4]提出了基于全局指令的多前缀过滤算法.这篇文章使用了流水线全局指令模式,并且提出适合这种模式的多前缀过滤算法,有效地减少在验证阶段需要计算的候选对数量.Cui等人[5]认为随着数据实时性要求的提升,动态数据流会成为重要的数据来源,所以对数据流的数据相似性连接展开了研究,提出基于编辑距离和滑动窗口语义验证的相似性连接算法,介绍了数据流中滑动窗口模型的构建以及特征提取等关键步骤.Wang等人[6]研究了局部相似性连接的问题,该文首先判断2个字符串是否具有一定的局部相似度,然后设计算法定位二者的最长相似子串,基于局部相似子串的长度进行字符串的相似性连接.Zhao等人[7]对数组形式的数据的相似性连接进行研究,文章首先将数组数据抽象成高维向量,然后定义了向量的相似性连接定义与度量标准;在连接的基础上进行了查询优化,提供高效的查询操作,并且将这种相似性连接与查询的算法推广至图结构的数据.Patil等人[8]研究不确定字符串的相似性连接和查询过程.以上的相关研究工作都局限在串行的相似性连接算法上,并没有突破串行算法的性能瓶颈,而且针对特定结构数据的相似性连接算法并不具备良好的普适性.
在并行的相似性连接算法方面,近些年的研究主要集中在借助已有的并行计算框架以及利用GPU实现并行化2个方面.Chen等人[9]利用MapReduce实现相似性连接,文章提出基于聚类抽样和KD树(k-dimensional tree)的数据划分方式,保证数据被平均地分配到节点上,然后提出基于顺序映射和距离的过滤方式进行数据过滤,提升算法执行效率的同时也使算法具有良好的伸缩性.邓诗卓等人[10]利用Spark框架和双前缀过滤方法实现了相似性连接算法.Matsumoto等人[11]提出了并行排序算法,同时利用并行最大最小堆结构在CPU-GPU异构体系上实现了数据相似性连接.Johnson等人[12]利用GPU实现了k-NN算法以及相似性搜索算法,利用GPU进行并行的局部数据排序,压缩数据集来减少数据传输与通信的代价.Feng等人[13]研究文档相似性连接,针对文档数据的特殊性和GPU计算的特点提出了2阶段相似性连接算法,根据TF-IDF算法进行排序后对低频词进行过滤,提出适合并行计算的倒排索引读取和相似度计算方法.
除此以外,GPU也被广泛地应用到其他方面.Alam等人[14]设计适合GPU并行计算的cuPPA算法解决无标度网络中遇到的问题,算法基于优先附着模型,并且可以通过Hash的方式支持多GPU同时计算.Doraiswamy等人[15]使用GPU构建索引来解决时空数据的查询问题,索引覆盖多个维度,采用块存储的形式加快数据查询速度,并且同时支持基于异构体系结构的查询请求.
与已有的工作相比,本文的工作将研究基于并行计算方式的相似性连接处理策略,突破传统串行算法的性能瓶颈,设计面向GPU的数据匹配索引结构,以及利用GPU处理架构并行计算模型,提升单处理机上的并行处理能力,降低分布式环境的数据划分和网络通信代价.
2 基于CPU-GPU的相似性连接处理框架
2.1 相似性连接方法
本文的研究内容主要面向以文本为属性内容的记录集合间的相似性连接方法,其中记录集合间的相似性度量主要采用基于字符串的相似性匹配方法.字符串相似性匹配方法可以分为2类:基于特征的相似性匹配和基于字符的相似性匹配,其中常用的相似性度量算法有Jaccard相似度、余弦相似度、遗传相似度和编辑相似度等.本文将针对基于特征的相似性匹配方法相似性连接进行优化处理,为此首先给出相似性连接相关定义:
定义1.相似性连接.给定2个记录集合R和S,r和s分别是来自R和S的记录,Sim表示相似度计算函数;对于给定相似性阈值τ,相似性连接是指找出所有相似度大于τ的记录对r,s,即集合:
{r,s∈R×S|Sim(r,s)≥τ}.
目前相似性连接最常用的处理框架是过滤-验证框架.过滤-验证框架分为记录对过滤和相似度验证2个步骤.过滤步骤主要的目的是过滤不相似的候选记录对,减少候选记录匹配集的大小.过滤算法的设计需要同时平衡过滤效果与过滤成本2个因素:想追求更好的过滤效果势必会增加过滤成本;而简单的过滤算法又会导致过滤效果不明显,难以降低验证阶段的处理代价.
在过滤策略中可以使用索引结构提高过滤效率:例如对每个特征建立倒排索引,利用倒排索引的包含项生成候选对.目前,相似性连接在过滤阶段最常用的算法是前缀过滤算法.前缀过滤算法的基本思想是利用前缀子串来衡量整体的相似性[16].其中,首先对所有的特征进行排序,然后对每一个字符串进行比较,如果其前缀部分的重叠程度小于设定的阈值,就将候选对删除.前缀过滤常常与长度过滤和位置过滤等方法共同使用来达到更好的过滤效果.
验证阶段主要任务是精确计算所有候选对的相似度,如果记录间的相似度大于给定阈值,那么该记录对即可以作为连接结果输出.
相似性连接算法不仅可以处理2个数据集合间的记录相似性匹配,也可以用于在同一个数据集合执行自连接操作,从而发现集合中冗余记录.
2.2 基于GPU的数据处理原理
随着GPU处理器计算能力的提高,通用型GPU(general-purpose GPU, GPGPU)被广泛地应用于高性能计算等领域.相关研究表明GPU在处理连接、排序、索引构建等过程时具有更优异的表现.常用的通用GPU计算框架包括NVIDIA的CUDA(compute unified device architecture)和非盈利性组织Khronos Group掌管的OpenCL.目前,多数的研究使用的是CUDA框架处理并行计算问题,该框架使GPU利用SIMT(single instruction multiple threads)体系结构解决复杂的计算问题.本文将基于CUDA框架在索引处理上的性能特性设计相似性连接的算法处理流程.
GPU的优势在于众多内核带来的高并发度,然而并不是所有的计算任务都适合使用GPU计算.CPU适合处理控制密集型任务,GPU适合处理包含数据并行的计算密集型任务.因此GPU的并行处理并不是处理完整的计算流程,而是按照计算任务的特性进行划分,GPU处理由计算任务主导的且带有简单控制流的计算任务.2种处理器在功能上互补,使CPU-GPU异构并行计算体系结构获得最佳性能.
2.3 基于异构体系的相似性连接处理框架
传统串行相似性连接方法可以分为数据读取、倒排索引构建、原始数据过滤和相似度验证4个主要步骤,其处理过程都是基于CPU处理计算,数据在主存中存储.
基于CPU-GPU异构体系结构的处理方法将传统方法的4个步骤分开处理,其中适合并行计算的部分由GPU负责,数据存储在GPU显存中;涉及复杂逻辑控制的部分由CPU负责,数据存储在主存中;处理器之间通过PCIe(peripheral component interconnect express)通道进行数据传输.这种方式能充分利用CPU-GPU异构体系结构中2种处理器不同的数据处理特点,提高整体的执行效率.本文对传统相似性连接方法的主要步骤进行分析和重新设计,如图1所示.①使用CPU读取数据,利用GPU并行构建倒排索引;②使用CPU依据倒排索引生成候选对;③使用GPU对候选对进行双重长度过滤;④使用CPU验证相似度得到最终结果集R. 2种处理器协同工作完成相似性连接整体任务.
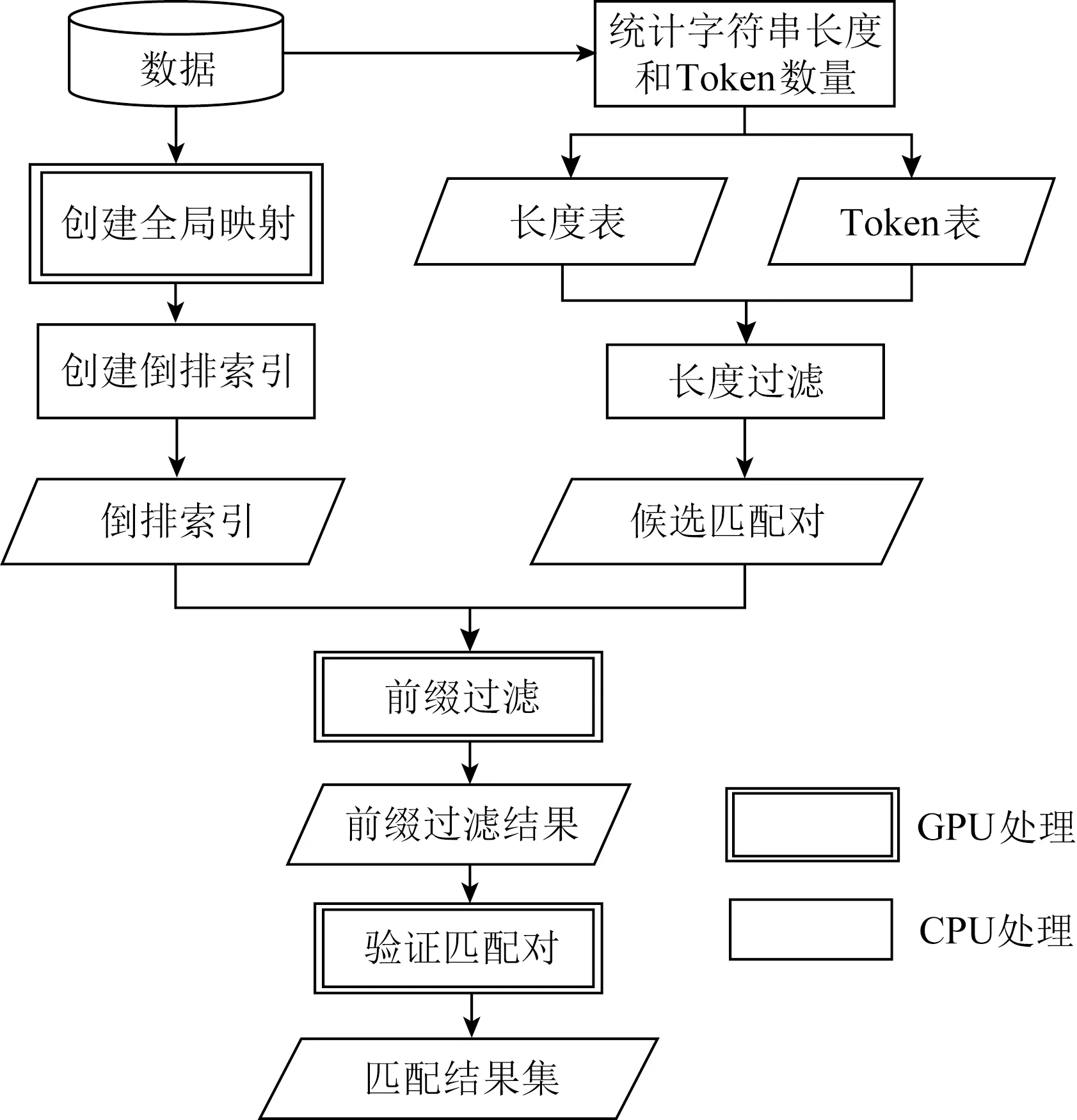
Fig. 1 Similarity join algorithms based on theCPU-GPU heterogeneous architecture图1 基于CPU-GPU异构体系的相似性连接算法
3 基于GPU的倒排索引构建方法
在相似性连接算法中,利用倒排索引可以快速找到可能相似的候选项,从而达到过滤不相似项的效果.倒排索引是大部分过滤算法的基础,为此本文首先提出使用GPU构建倒排索引的方法.
相比于内存空间,GPU的存储空间是很有限的,GPU全局内存(global memory, GM)一般只有几GB的空间,而访问速度更快的共享内存只有KB级别的空间,所以使用GPU生成倒排索引时必须考虑减小倒排索引的体积.同时,GPU与主机内存之间的消息通信必须通过PCIe通道,目前CPU从内存读写数据的速度是PCIe通道的4~8倍,所以需要尽可能对原始数据以及倒排索引进行压缩,利用GPU存储空间来存储数据.出于以上的考虑本文采用了全局内存映射表来减小数据和索引的体积.
全局内存映射表的功能类似于数据字典,可以将体积较大的字符串类型的特征项转换为数值类型的唯一序号.通过这种结构,倒排索引中每个键值对所占用的空间大幅减少,原始数据的体积也大幅减少,这样就可以使用GPU全局内存存储更多的原始数据以及索引信息.
基于这个问题,本文首先对传统的倒排索引结构进行改进,采用基于SoA结构的倒排索引,充分利用GPU多线程并发访问的特性,提升索引访问和构建速度.SoA也被称为并行结构体或者并行数组,这种数据结构的出现主要是为了解决在并行访问的场景下传统结构体数组访问和写入效率低的问题.图2所示为SoA与AoS这2种数据结构的定义以及在内存中布局方式的对比,SoA为结构体中定义的每个属性创建一个数组,相同的属性值在内存中连续存放,不同的数据之间没有任何耦合.所以这种数据结构非常适合多线程同时并发访问,并且全部由基本数据类型组成的数组在访问时也不需要进行数据补全.
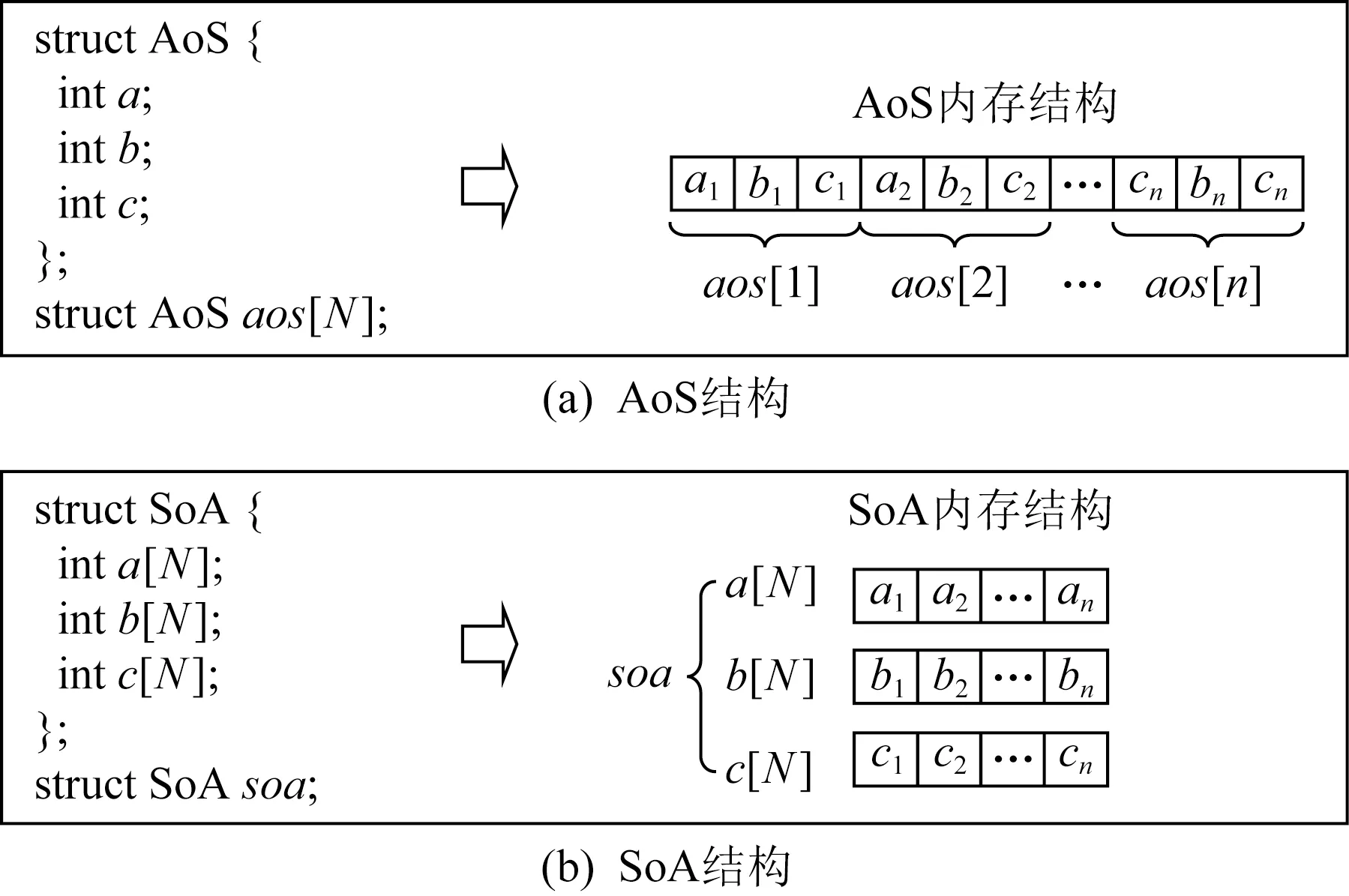
Fig. 2 Comparison of SoA and AoS structure图2 SoA与AoS结构对比
GPU最大的优势在于多线程并行计算的能力.为了充分地提高并行度,每个线程块block将负责一部分原始数据的解析工作,block中的每个线程每次会读取一个单词,根据全局映射表解析数据生成tid,sid,然后查找全局倒排索引,使用函数atomicAdd将sid和tid分别写入对应的位置,等到所有线程完成各自的任务后,SoA型倒排索引的构建工作也就完成了.如果想要进一步提高索引的读写速度,可将得到的全局倒排索引按照共享内存的大小顺序划分,划分后的部分索引传入共享内存中等待后续使用.将构建完成的索引回传至主存,然后对tid相同的匹配对进行合并就得到了通用性更好的传统倒排索引.算法1表述了基于GPU的倒排索引的构建过程.
算法1.基于GPU的倒排索引构建算法.
输入:字符串集S;
输出:倒排索引ISoA.
① 初始化:
② 基于字符串集S构建全局映射表Map;
③ 为字符串集S中每个token创建特征编号tid,为每个字符串创建编号sid;
④ 记录数据集中token的数量N;
⑤ 将S和Map加载到全局内存;
⑥ 初始化SoA结构的倒排索引ISoA;
⑦ for eachS中的字符串si并行执行操作:
⑧ 创建字符串si的token集合Tsi;
⑨ for eachTsi中的token并行执行操作:
⑩ 基于Map解析数据生成tid,sid;
算法1中行①~④是在CPU和主存上做的准备工作,主要包括数据读取、构建全局内存映射表Map等.行⑤~⑥将数据和映射表通过PCIe通道传输至GPU全局内存并且初始化大小SoA型倒排索引结构.行⑦~为具体的并行倒排索引构建过程,图3对这一过程进行了简要的描述.对于每条数据使用一定数量的线程并行解析,根据全局内存映射表Map解析tid,sid,使用atomicAdd函数并行补全SoA倒排索引.行将处理得到的SoA倒排索引回传至主存,因为并行计算得到的倒排索引是SoA类型,行~在CPU上对倒排索引进行合并,得到传统的AoS类型的倒排索引.合并后的倒排索引具有更高的普适性和更广泛的应用场景,可应用到搜索引擎、数据清洗等方面.

Fig. 3 Construction process of inverted index图3 倒排索引构建过程
4 基于CPU-GPU的并行相似性连接方法
长度过滤的基本思想是:如果字符串s与r相似,则其长度一定不会相差太多.以Jaccard相似度为例,给出长度过滤算法中字符串长度与相似度阈值的关系.长度过滤因计算简单,且条件仅仅需要统计每条数据项的长度等特点被广泛地应用到过滤-验证框架中,同时这种逻辑简单的计算密集型过滤算法特别适合GPU并行计算.因此本文考虑使用基于GPU的长度过滤算法对原始数据集进行过滤:
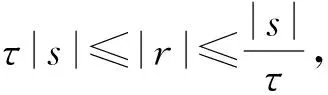
(1)
其中,τ为已定义的相似度阀值.如果数据集中的字符串是由许多特征组成的,那么除了使用字符串的长度进行长度过滤之外,还可以使用每个字符串的特征数量进行过滤.因为数据集中普遍存在长度相近,但是所含单词数量相差很多的字符串,仅使用数据长度无法过滤掉这些不相似的字符串.而使用长度和特征数双重过滤的方式可以过滤掉这一类型的字符串,进一步提升过滤效果减少候选项的数量.长度过滤算法的主要过程是统计每个字符串的长度,以及判断字符串的长度是否在相似度阈值规定的区间内.这2个步骤是2个完全独立的工作,并且这2部分工作都是简单的读写任务,不涉及复杂的逻辑处理,因此十分适合使用GPU对这部分工作进行并行化处理.
长度过滤算法也有缺点,例如对相似度阈值敏感、对方差较小的短文本数据集过滤效果很差等.为了弥补长度过滤算法的缺点,本文使用前缀过滤与长度过滤相结合的方式进行数据过滤.
前缀过滤算法是目前比较领先的过滤算法之一,并且常常与长度过滤等方法一起使用来获得更好的过滤效果.前缀过滤的基本思想是:对于已按照某种规则排序后的数据项,如果2个数据项的前p项特征中有相同项,那么这2个数据项就可能相似.前缀长度p与字符串长度|s|以及相似度阈值τ的关系:

(2)
使用前缀过滤算法对经过长度过滤之后生成的中间结果集进行2次过滤:对于中间结果集中的每个候选项,根据相似度计算公式计算出前缀p,然后判断候选项是否出现在前缀项对应的倒排索引中.经过前缀过滤之后的中间结果集被进一步减小,从而也少了后续相似度验证阶段的任务量.
基于以上考虑,本文首先使用算法1,利用GPU构建倒排索引;然后使用GPU对原始数据集进行双重长度过滤生成中间结果集;随后根据倒排索引,使用前缀过滤算法对中间结果集进行2次过滤,剔除不满足前缀过滤要求的候选项;最后对通过2次过滤的候选项逐个进行相似度验证,将通过验证的候选项添加至最终结果.以Jaccard相似度为例,算法2描述了使用倒排索引基于前缀过滤和长度过滤思想的并行相似性连接算法.
算法2.并行相似性连接算法.
输入:字符串集S、相似度阈值τ、相似性度量函数Sim;
输出:相似字符串匹配集RM.
① 使用算法1创建SoA结构倒排索引ISoA;
② 设置RM=∅,创建全局字符串token映射表TS和长度表LS,初始化候选匹配对集合Candi;
③ for eachS中的字符串si并行执行
④ 使用atomicAdd函数对si中的每个token执行操作以在TS和LS中记录si的token数量和特征长度:
⑤ end for
⑥ for eachS中排序后的字符串si并行执行操作:
⑦low=τ|si|,high=|si|τ,min=τTS[si],max=TS[si]τ;
⑧ 对于S中其他的字符串sj,如果满足|sj|∈[low,high]且TS[sj]∈[min,max],则添加候选匹配对(sj,si)至Candi;
⑨ end for
⑩ for each候选对(sj,si)∈Candi执行
算法2中行①依据算法1使用GPU并行构建倒排索引,行②进行相关结构的初始化.行③~⑤解析数据统计每个字符串的长度以及所含特征的数量.行⑥~⑨使用GPU对原始数据集进行双重长度过滤,根据给定的相似度阈值τ计算出长度和特征数范围,将同时满足长度和特征数量要求的记录对添加至中间结果集.行⑩~对中间结果集进行前缀过滤,将同时满足2种过滤条件的候选项添加至候选结果集中.行在CPU上对候选结果集中所有候选项进行相似度验证,将相似度超过阈值τ的候选项添加至匹配结果集.
5 实验结果与分析
5.1 实验设置与数据集
本次实验采用多种不同类型的数据集,表1给出了本次实验所用数据集的基本信息.
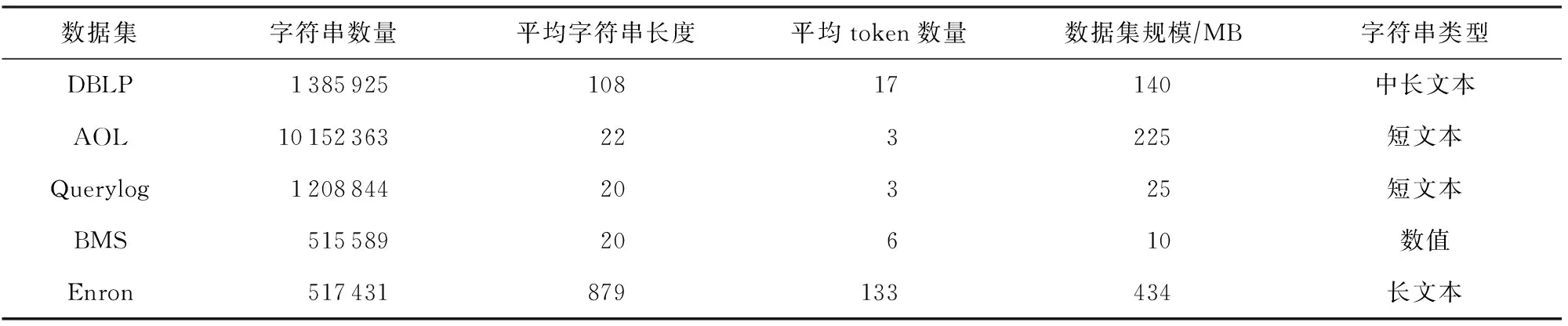
Table 1 Datasets for Experiments表1 实验所用数据集
1) DBLP.从DBLP(database systems and logic programming)原始数据集中抽取作者名和论文名进行拼接,然后随机删除、更改后形成的数据集.
2) AOL.AOL(american online)搜索引擎的查询日志,该数据集中的每一行代表一组查询关键词.
3) Querylog.某搜索引擎的查询语句集合.
4) BMS.商业管理系统(business management systems, BMS)的某商店使用POS机记录的销售数据.
5) Enron.真实的电子邮件数据集,一个字符串代表一个真实的电子邮件的信息,平均长度很长.
本文实验主要测试算法的执行时间、加速比、算法各部分占比以及数据集大小、相似度阈值等条件对算法的影响.实验环境:本文实验所用GPU:NVIDIA GTX 1060 6 GB;CPU:Intel Core i7-8700 3.20 GHz;内存:8 GB;操作系统:Windows 10.算法使用CUDA 9.0和C++实现.
5.2 实验结果与分析
本文将通过实验分别检测GPU加速在倒排索引构建阶段和相似性连接整体执行上的加速效果.
1) 基于GPU的倒排索引构建方法的作用
表2记录了分别使用GPU和CPU在不同数据集上构建倒排索引时程序的执行时间.可以明显地看出使用GPU构建倒排索引可以大幅提升倒排索引的构建速度.在不同的数据集上,本文提出的基于GPU的SoA型倒排索引的构建方法的加速比(并行算法与串行算法执行时间的比值)分别达到了51.87,8.53,81.40,23.83,80.58,加速效果明显.
在Enron,DBLP,BMS这3个数据集上获得了较高的加速比,而在Querylog数据集上的加速比相对较低.这是因为Querylog是小数据集,数据集较小时并行计算带来的计算速度的提升效果不明显,同时GPU的引入会提升数据传输的代价,所以加速比相对较低.而同样是小数据集的BMS是纯数字数据集,数字类型占据空间相对较小,所以体量更小的BMS数据集的数据规模其实比Querylog数据集更大,因此使用GPU构建倒排索引的加速效果也比较明显.在使用CPU构建倒排索引时需要使用Enron等较大数据集是因为并行计算大幅减少数据处理时间,所以加速效果十分明显.

Table 2 Comparison of Inverted Index Construct Time表2 倒排索引构建时间对比

Fig. 4 Impact of dataset size on execution time图4 数据集大小对执行时间的影响
图4(a)记录了使用GPU构建倒排索引时方法的执行时间随数据集大小的变化情况,图4(b)记录了并行方法加速比随数据集大小的变化情况.随着数据集的增大,基于GPU的并行索引构建方法的执行时间呈近似线性增长.这是因为SoA结构保证不同线程间的读写没有耦合,数据集的增大仅仅会增加单个线程完成计算任务需要的次数.加速比随着数据集的增大逐渐提升,说明传统的索引构建方法不能在数据集增大的同时保证运行时间的线性增长.因此本文提出的倒排索引构建方法可以在数据集规模较大的时候依然保证良好的执行效率,并且数据集越大构建方法的加速效果越明显.
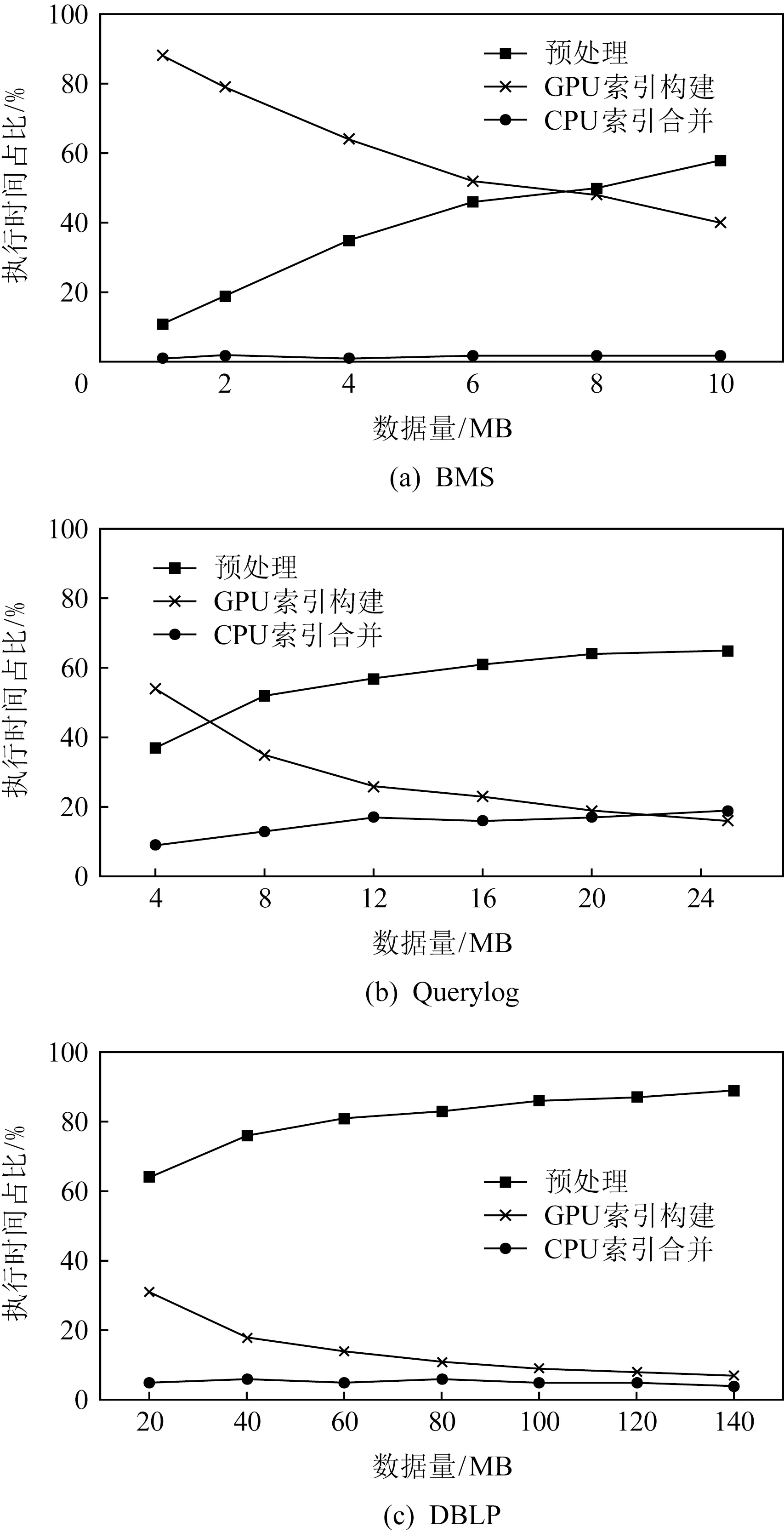
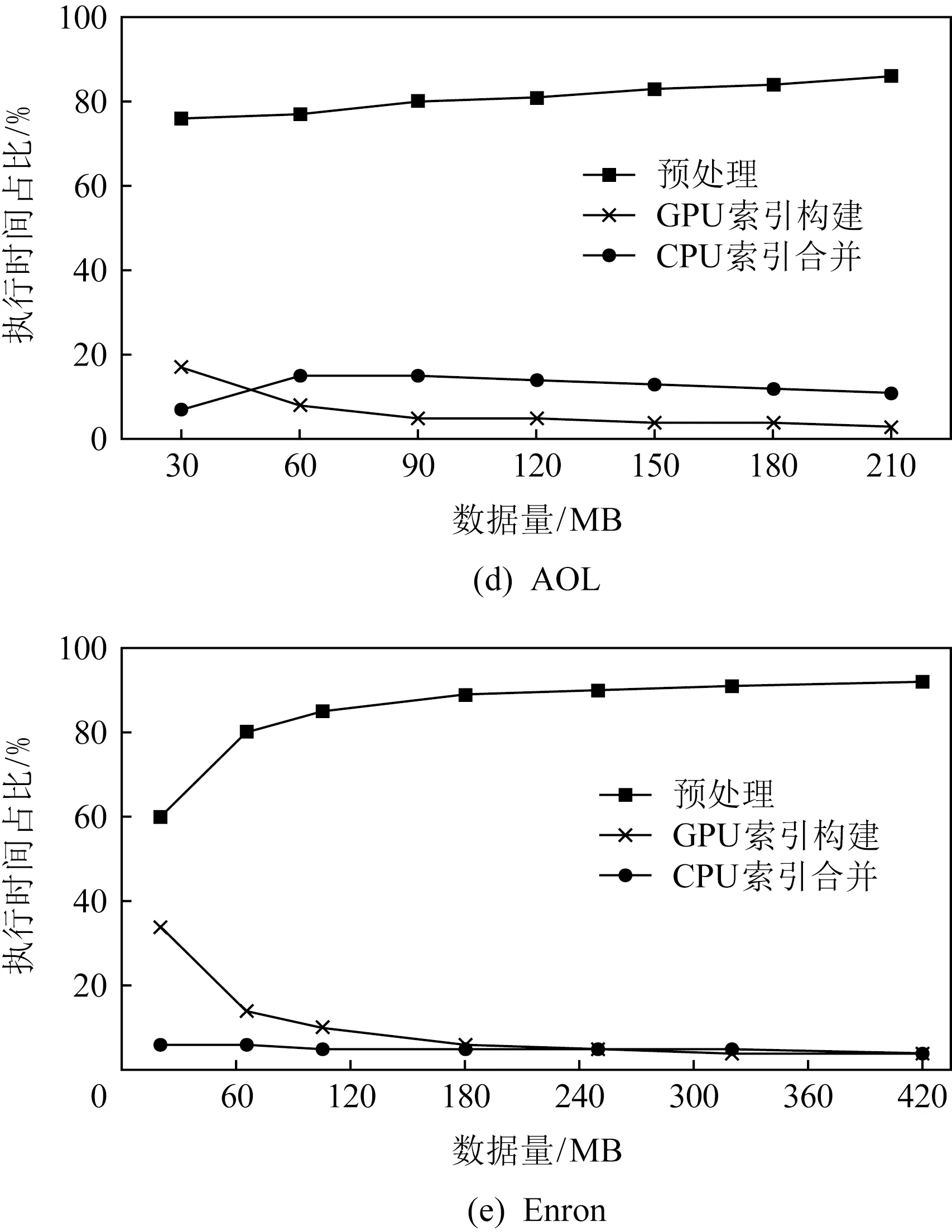
Fig. 5 Time proportion of each part of inverted index construction algorithm图5 倒排序索引构建算法各部分时间占比
图5比较了使用GPU构建倒排索引的过程中方法各部分的时间占比.其中预处理部分包括原始数据读取与全局映射表构建2个步骤;GPU构建索引部分同时也包括主存与全局内存之间数据传输过程;CPU索引合并部分是指将SoA型倒排索引合并成通用的倒排索引结构的过程.在不同数据集上的实验表明:数据预处理部分的时间占比最高,并且随着数据集体积的增大,这部分的时间占比会进一步提高;而并行计算以及索引合并2个阶段的时间占比很低.所以在CPU-GPU异构体系结构的倒排索引构建方法中,方法的性能瓶颈主要在CPU端的数据预处理部分.
2) 基于GPU的相似性连接方法的作用
表3记录在不同数据集上进行实验的结果,对比的串行算法为目前效率较高且适用范围较广的PPJoin算法[17].为了节省算法的执行时间,本节实验分别从Enron,DBLP,AOL这3个数据集中抽取了24 000,60 000,140 000条数据进行实验.实验结果表明本文提出的基于CPU-GPU异构体系结构的算法相较于原有算法有一定的提升,在AOL数据集上获得了最高45.6%加速效果,整体加速效果与倒排索引构建方法相比很不明显.
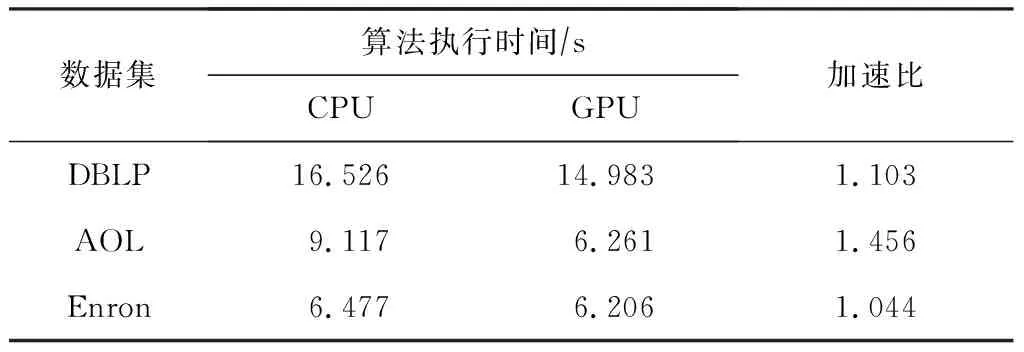
Table 3 Comparison of Algorithm Execution Time表3 算法执行时间对比

Fig. 6 Execution time of the algorithm with differentdata scales图6 算法在不同数据规模下的执行时间

Fig. 7 Time proportion of each part of similarity join algorithm图7 相似性连接算法各部分时间占比
为了探究相似性连接方法加速效果及相关影响因素,本文记录了通过实验对比算法各个部分的时间占比随数据集大小的变化情况,实验结果如图6和图7所示.图6展示了Enron,DBLP,AOL这3个数据集在不同数据记录数量规模下的执行时间变化情况,从实验结果可见,随着数据规模的增大,算法的执行时间呈近似线性增长.图7展示了Enron,DBLP,AOL这3个数据集在不同数据记录数量规模下的算法各部分执行时间占比,从实验结果图可以看出使用GPU执行的创建索引(create index)和过滤记录对(filter pairs)这2个阶段的时间占比较低,随数据集的变大逐渐减少或保持平稳;而相似度验证记录对(verify pairs)阶段时间占比最高,超过了其余步骤的总和,并且随着数据集的增大不断增大.因此,最后在CPU端执行的相似度验证阶段是本文提出的相似性连接方法加速效果不明显的主要原因,要进一步提升算法的加速效果,必须重新设计适合GPU并行计算的相似度计算方法.
图8和图9分别比较了相似度阈值τ对算法执行时间和过滤效果的影响.随着相似度阈值的增加,候选项的数量以及算法的整体执行时间成近似线性减少,算法的过滤效果良好.其中DBLP数据集对阈值变化最敏感,因为此数据集中字符串长度方差最大,所以使用前缀过滤和长度过滤时提升相似度阈值可以大幅减少候选项的数量,迅速减少算法执行时间.
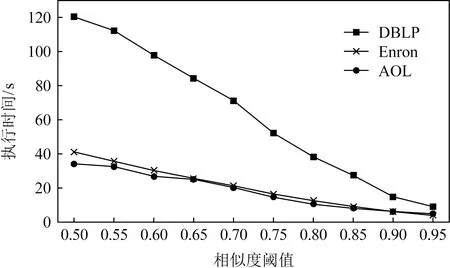
Fig. 8 Effect of similarity threshold on execution time图8 相似度阈值对算法执行时间的影响
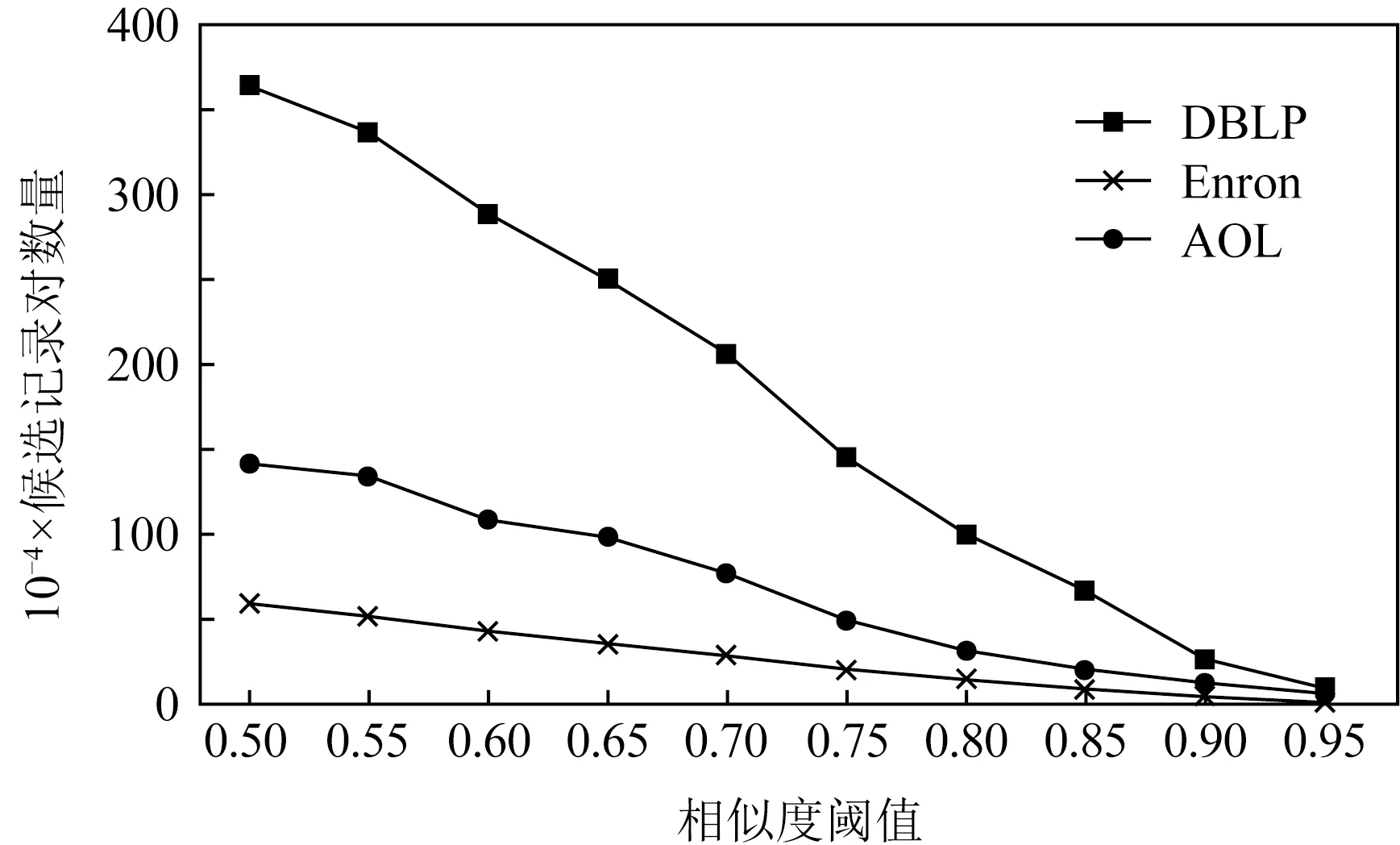
Fig. 9 Influence of similarity threshold on candidatefiltration图9 相似度阈值对算法过滤效果的影响
通过本节实验可以得出2个结论:
1) 使用GPU构建倒排索引可以明显加快索引的构建速度,并且数据集数据量越大,算法的加速效果越明显;
2) 基于CPU-GPU异构体系结构的并行相似性连接方法过滤效果良好,与传统方法相比具有一定的加速效果.
6 总结与展望
本文提出了基于CPU-GPU异构体系结构的倒排索引构建方法以及相似性连接方法.采用SoA型的倒排索引结构加快并行条件下索引的读写速度,在获得较高加速比的同时保证索引具有良好的通用性.基于前缀和长度过滤的并行相似性连接方法在一定程度上进一步提升了传统方法的执行速度,并且为相似性连接算法的研究提供了一个新的思路.但是本文提出的方法依然存在局限性,实验结果表明数据读取和相似度验证的2个阶段时间占比较高,如果可以使用例如直接寻址等技术读取数据并且构建适合GPU并行计算的相似性度量,就可以进一步提升方法的执行速度.下一步,我们将试图在本文的基础上解决这一问题.
