一种联合检测命名数据网络中攻击的方法
2021-04-01吴志军张入丹
吴志军 张入丹 岳 猛
(中国民航大学电子信息与自动化学院 天津 300300)
(zjwu@cauc.edu.cn)
命名数据网络(named data networking, NDN)是信息中心网络的实例与未来Internet体系结构研究的热点[1-2].与TCPIP的细腰结构不同,NDN将网络实体从主机转换为命名的内容.在NDN中,消费者请求驱动了2种类型的传输包(兴趣包和数据包)的交换.消费者将所请求数据内容的名称放入兴趣包并将它发送到整个网络,当有生产者或者中间路由器可以满足所请求的兴趣包时,返回一个相应的数据包给消费者[3].每个NDN节点都包含3个数据表:内容缓存(content store, CS)、待定兴趣表(pending interest table, PIT)和转发信息表(for-warding information base, FIB)[1].用户请求数据的转发过程如图1所示[1].
NDN网络中,消费者通过发送特定名称的兴趣包来请求数据包,生产者再根据兴趣包的传播路径返回一个数据包.这种去IP地址的传播方式直接消除了IP源地址欺骗等攻击,并且解决了IP地址数资源不足的问题.但也引发了一系列问题,如兴趣泛洪攻击(interest flooding attack, IFA)和合谋兴趣泛洪攻击(conspiracy interest flooding attack, CIFA).IFA是一种路由相关攻击,它类似于分布式拒绝服务攻击(distributed denial of service attack, DDoS)中的资源耗尽型攻击[4].发生IFA时,攻击者通过发送大量恶意兴趣包请求不存在的内容攻击网络,消耗中间路由节点的PIT资源,阻塞网络链路.由于每个节点可以接收的兴趣包请求有限,所以合法用户请求的兴趣包会被丢弃或优先级会降低[5].CIFA的攻击目的与IFA相同,但是攻击形式不同.CIFA是一种周期性的脉冲攻击,它的平均速率很低甚至低于正常网络流量的速率所以不易被检测到,它类似于低速率拒绝服务攻击[6](low-rate denial-of-service attack, LDoS).与IFA中攻击者单方面大规模发起攻击不同,为了更长时间占用PIT,CIFA中的合谋者会在一段时间后回复攻击者请求的非法内容.这种合谋的攻击方式不但占用了路由资源,而且避免了非法兴趣包条目因为超过PIT生存时间而被检测.隐蔽性较高的CIFA会使网络长时间受到更大危害.

Fig. 1 Forwarding process of NDN node图1 NDN节点转发过程
本文的创新点有2个:
1) 提出使用关联规则联合多个特征,分析异常特征指标之间关联性的方法.常用的检测特征有兴趣包满意度、PIT占用率和丢包率.现有检测方法仅使用其中1个特征检测攻击,且这些特征异常时并不能完全证明存在攻击,尤其是检测CIFA这种隐藏性较高的攻击(在第3节分析具体原因).针对检测特征单一的问题,本文通过提取发生攻击时PIT和CS中的数据信息,挖掘新的检测特征“CS异常偏离率”.关联规则常被用于数据挖掘,它的作用是发现事物之间的关联性.为了提高检测攻击的准确性,本文使用关联规则关联新特征与已知特征,增加了检测依据.若特征之间关联性较强则有很大的概率说明发生了攻击.
2) 提出基于关联规则Apriori算法和决策树算法的联合检测NDN中攻击的方法.针对现有方法检测率不高且不能判断是IFA还是CIFA的问题,本文提出一种更细粒度的检测方法.在利用关联规则挖掘多个检测特征之间的关联性基础上,采用决策树ID3算法对Apriori算法产生的规则进行分类,得到训练集建立检测攻击的模型;使用关联规则算法不仅可以联合多个特征增加检测依据,且将它输出的多条规则作为决策树的输入可以增加决策树的分类属性.通过决策树算法的分类结果判断是何种攻击,以减小误判对合法兴趣包的有效传输造成的影响.通过实验对比我们发现,本文所提出的算法会更有效地检测攻击并判断攻击类型.且具有复杂度较低、实时性高的优点.
1 相关工作
目前检测NDN攻击的研究已经取得一些成果.文献[7]提出Interest Traceback方法,当PIT大小超过设定的阈值或警告率时使用回溯法追踪攻击者.文献[8]中Compagno的团队提出一种减轻兴趣泛洪攻击的方法,即Poseidon方案.此方法根据兴趣包满意度和PIT占用率来判断不同接口是否存在兴趣泛洪攻击.当检测到攻击时,限制兴趣包的转发速率.文献[7-8]利用NDN网络本身具有的流平衡特性实现对网络流量的控制,但是在监测网络流量时仅关注了PIT中的特性且检测时的阈值设定不确定.防御措施虽然达到了阻止IFA的目的,但是大大影响了正常用户的请求.
为避免合法兴趣包被误判,文献[9]中用累积熵和相对熵检测攻击.通过计算网络中兴趣包中一些特定属性(兴趣包名称前缀等)的分布随机性来发现异常流量,使用相对熵理论识别恶意前缀,再对有非法前缀的兴趣包采取回溯措施找到攻击源.该方案在面对恶意攻击者发送的较为复杂的恶意前缀时,其基于相对熵的恶意前缀识别能力将会产生很大的限制,尤其是面对CIFA这种隐藏性较高的攻击时,该方案检测率较低.
在文献[10-12]中,Salah等人提出使用中央控制器的潜在机制从全局的角度监控网络检测一种更复杂的IFA攻击.该方案通过中央控制器从全局视图时刻关注网络的变化趋势,并且与网络中的每个节点交换信息并做出决策.但在这种全局监控的模式下,单个路由器很难依靠自身检测攻击.文献[13]中用一种基于隐马尔可夫(HMM)模型的计费奖励机制来对抗兴趣泛洪攻击.该方法通过建立兴趣包的满意度和消费者状态之间的模型,通过HMM来定期预测消费者的状态.以上检测方案在面对CIFA时,恶意消费者发送的兴趣包也会收到数据包的回复,导致机制在最初的预测阶段发生误判,所以均无法区分IFA和CIFA.
崔建等人[14]研究关联规则算法与决策树的结合,利用不同时期的数据集建立了新的决策树算法,在使用决策树算法处理分类问题的同时又使用关联规则并行处理进行剪枝,使决策树具备良好的伸缩性及可调整性.在实际情况中,可能会有多个特征的变化表明路由器已经受到攻击,仅根据单一指标的异常变化可能会造成误判,所部署的策略反而使合法用户受到不公平的限制.本文针对现有检测和防御方法的不足之处,通过大量实验对比挖掘新的特征,提出使用关联规则和决策树联合多个特征检测攻击的新方法,更加准确地检测NDN中的攻击区分IFA和CIFA,提高了检测效率.
2 检测攻击的特征
目前的检测方法存在一些待解决的问题.通过总结,现有检测方案主要分为3类:1)检测时只关注PIT中的数据信息和兴趣包满意度[15];2)识别兴趣包的名称空间,找到恶意前缀名称或者跟踪其传播接口来追踪攻击者[16-17];3)在下游节点部署防御措施限制转发速率以减轻兴趣泛洪攻击[18].这3类方法的缺陷在于检测特征单一,不能分辨是何种攻击且存在误判.针对上述问题,本文通过分析发生攻击时CS和PIT中的数据信息,挖掘新特征增加判断依据,更加细粒度地检测攻攻击.
本文所需提取PIT和CS中的数据信息以及相关特征的计算关系和表示方法如表1所示.首先,在真实的大型网络拓扑中模拟攻击场景,通过大量实验从路由节点中提取PIT和CS中的数据包和兴趣包的信息.其次计算兴趣包满意度、PIT占用率和丢包率.最后,通过分析CS中数据包的信息挖掘出新特征“CS异常偏离率”,提高了检测攻击准确性.
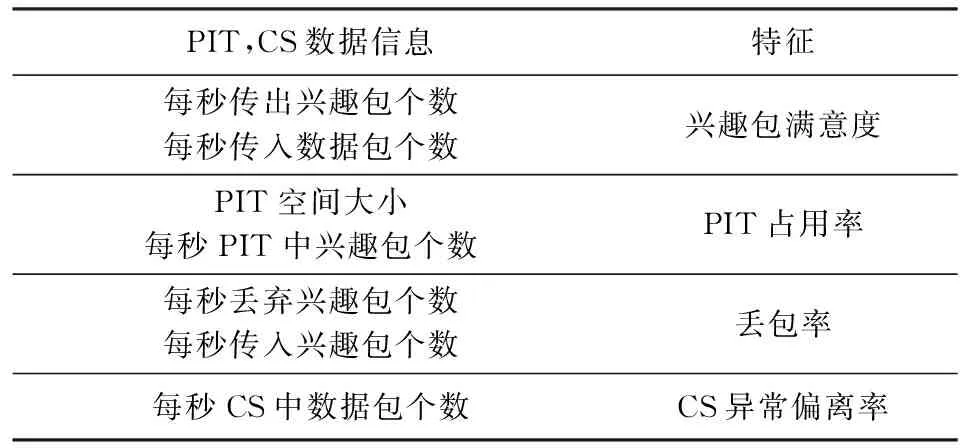
Table 1 Data Information Extraction and Eigenvalue Calculation
2.1 兴趣包满意度
兴趣包满意度即NDN路由节点所发出的兴趣包被满足的程度.满意度过低有3种情况:1)IFA攻击导致PIT中存在大量非法兴趣条目,只有合法兴趣包被所请求的数据包回复;2)在较小时间段内合法用户请求的数据量过大,兴趣包可能因为请求超时被丢弃而得不到回复;3)发生了CIFA攻击.本文从PIT中提取相关数据信息,计算NDN路由器每个接口的满意度,计算公式为

(1)
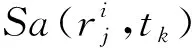
2.2 PIT占用率
PIT占用率描述的是PIT被占用的程度.当PIT占用率过高时有2种情况:1)发生IFA攻击时PIT被合法和非法兴趣包名称共同占用;2)短时间内发送大量合法兴趣包请求使PIT占用率高,但只有很小一段时间此指标的值会过高.本文中NDN路由节点rj的PIT占用率公式为

(2)
其中,Op(rj,tk)为第k秒时路由器rj的PIT占用率.分子为第k秒路由器rj中兴趣包的个数,分母为PIT容量.网络流量正常情况下PIT占用率的值几乎为0,PIT被占满时值几乎为1.
2.3 丢包率
PIT中的兴趣条目过了生存时间时会被丢弃.导致丢包率过高可能有3种情况:1)攻击者发送大量非法兴趣包,超过PIT的生存时间时这些非法兴趣包会被丢弃;2)链路拥塞.合法请求因不能及时收到生产者回复的数据包而被丢弃;3)合法兴趣请求过多导致链路拥塞或生存时间超时.NDN路由节点的丢包率计算公式为

(3)
Dr(rj,tk)是路由节点rj在第k秒的丢包率,分子是节点rj在第k秒丢弃兴趣包的数量,分母是节点rj在第k秒传入兴趣包的数量.
2.4 CS异常偏离率
CS异常偏离率描述的是发生攻击时CS中数据包的增长量对比正常网络流量下CS中数据包的增长量的偏离程度.通过模拟正常网络场景和攻击场景后,发现CS中数据包的数量呈现异常增长原因有:1)兴趣泛洪攻击时,PIT中有大量非法兴趣包,所以生产者发送回来的合法数据包非常少;2)当发生CIFA时,为了占用网络资源,合谋的生产者会发回大量数据包回复攻击者发出的合谋兴趣包.NDN路由节点rj的CS缓存异常偏离率的表达式为
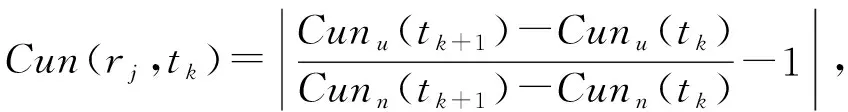
(4)
Cun(rj,tk)为路由节点rj在第k秒的缓存异常偏离率.在分式中,分子为发生攻击时每秒CS中数据包的增长个数,分母为正常发包情况下CS中数据包增长个数,其比值表示CS数据包增长率,通常值为1.减去1取绝对值即为异常偏离率.通过实验对比发现,发生IFA攻击时CS异常偏离率<1,发生CIFA时的值会>1.综上所述,CS缓存异常偏离率这个特征不仅可以作为是否发生IFA和CIFA的依据,而且还可以辨别发生的哪种攻击.
本文模拟了正常网络流量和IFA攻击流量下的CS缓存异常偏离率,如图2所示.选取网关节点和骨干节点并对比CS中数据包的数量增长情况.由图2对比发现,正常发送兴趣包时(持续100 s)CS中数据包的数量均匀增长.当发起攻击时(20~80 s结束),由于没有数据包回复,所以CS中包的数量增长减缓,而在前没有攻击时,2条线拟合.
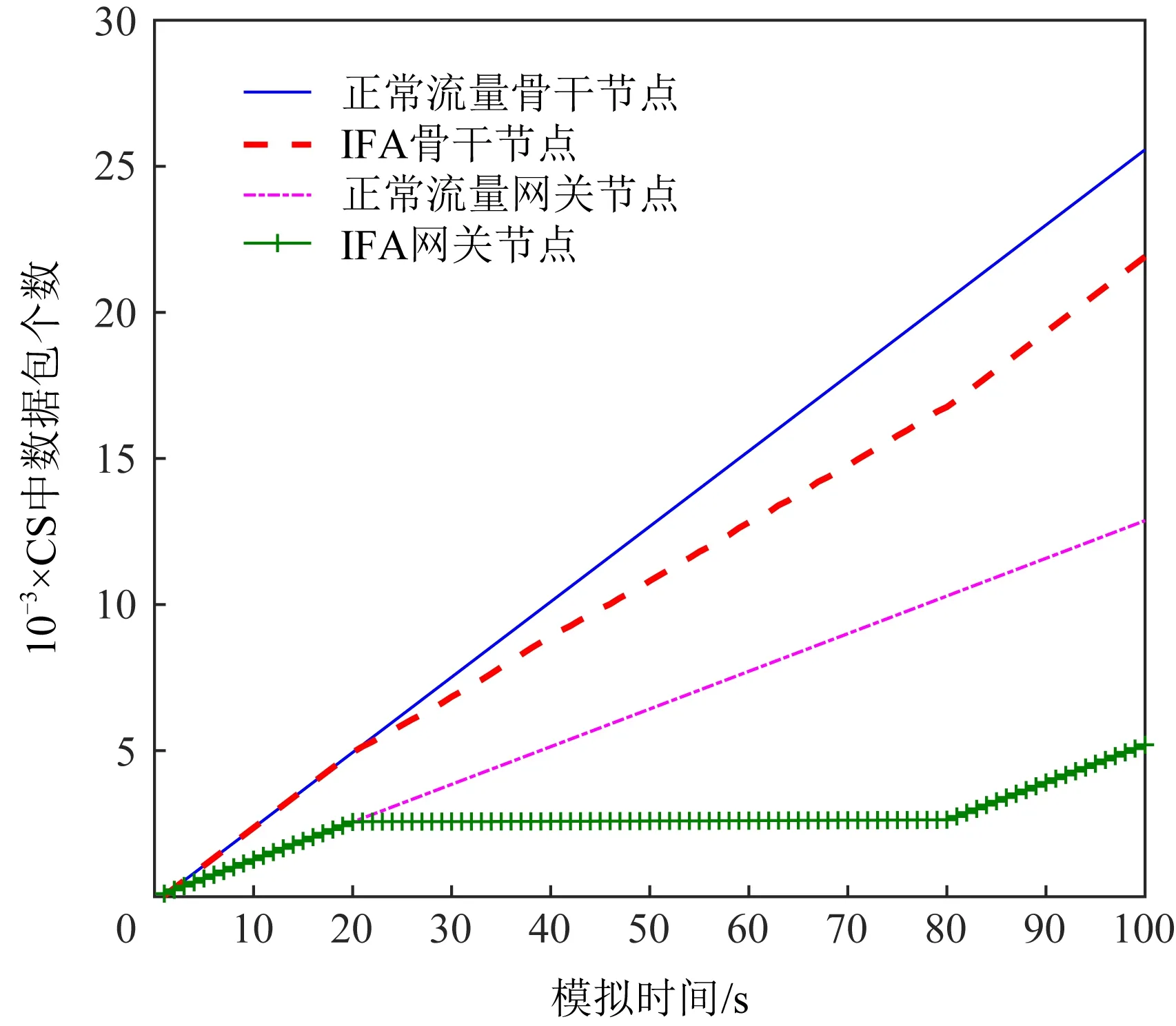
Fig. 2 Number of packets in CS(IFA)图2 CS中数据包个数(IFA)
发起不同程度的CIFA,观察CS中数据包的增长趋势,如图3所示.合谋攻击者脉冲式发起攻击,随着攻击速率变大,合法数据包和合谋生产者回复的数据包都会缓存在CS中,所以CS中数据包呈阶梯式增长.图3中Good表示合法用户的发包速率,Bad表示合谋攻击者的发包速率.
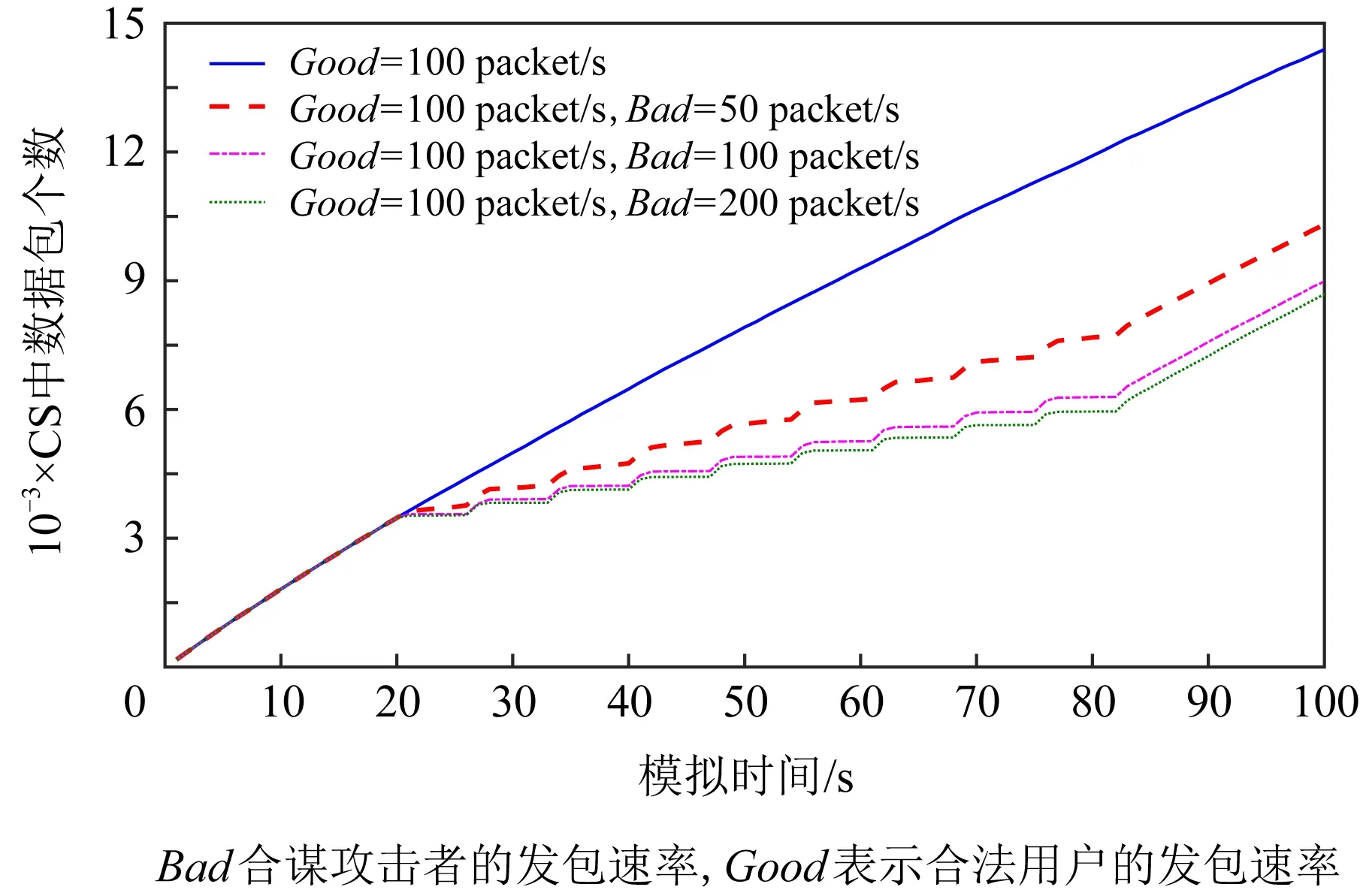
Fig. 3 Number of packets in CS(CIFA)图3 CS中数据包个数(CIFA)
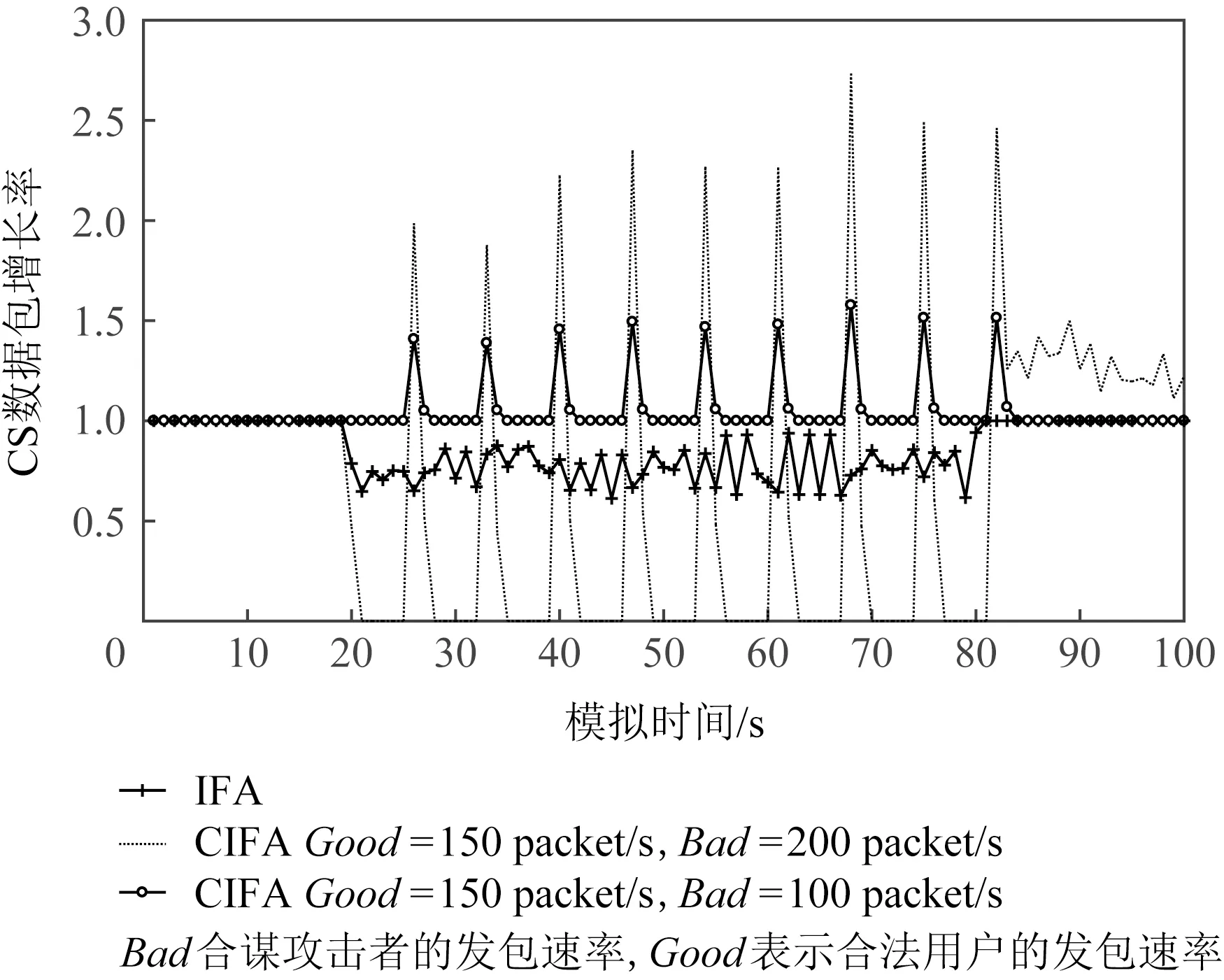
Fig. 4 CS packet growth rate comparison图4 CS数据包增长率对比
本文分别发起IFA和CIFA,观察CS数据包增长率,如图4所示.选取拓扑中的同一个点,可以观察到当发起IFA(20~80 s)时CS中数据包的增长速率明显降低(<1).但是当发起不同程度的CIFA攻击时,数据包增长速率也呈脉冲式变化且随着攻击强度变大这种现象越明显,这是因为CIFA中攻击者以脉冲方式发起攻击,所以合谋者回复的数据包也会突然在某段时间内占据CS.以上实验证明此特征作为检测攻击的依据十分有效.
3 关联规则与决策树联合检测NDN攻击
在特征关联过程中,本文采用关联规则的Apriori算法将兴趣包满意度、PIT占用率、丢包率和CS异常偏离率等4个特征进行联合,并找出它们之间的关联特性;根据输出特征之间的关联规则初步判断是否发生攻击.使用关联规则算法的优点是整合大量特征数据,联合多个特征找到特征之间的关联性,是检测攻击的基础.特征之间的关联性越高,发生攻击的可能性越大.但是仅凭多条关联规则算法输出的规则并不能判断是否发生攻击,也不能分辨是何种攻击,所以需要使用决策树分类.首先将输出的多条规则和CS数据包增长率作为决策树的特征,生成训练集.其次确定每个叶子节点的属性,构造决策树模型并检测攻击.这种先使用关联规则进行预处理再用决策树检测攻击的方法弥补了关联规则的不足,关联规则算法输出的多条规则增加了决策树的检测特征.这2种算法的结合可以对攻击进行分类,避免了误判并提高了检测率.本文的算法流程图如图5所示:
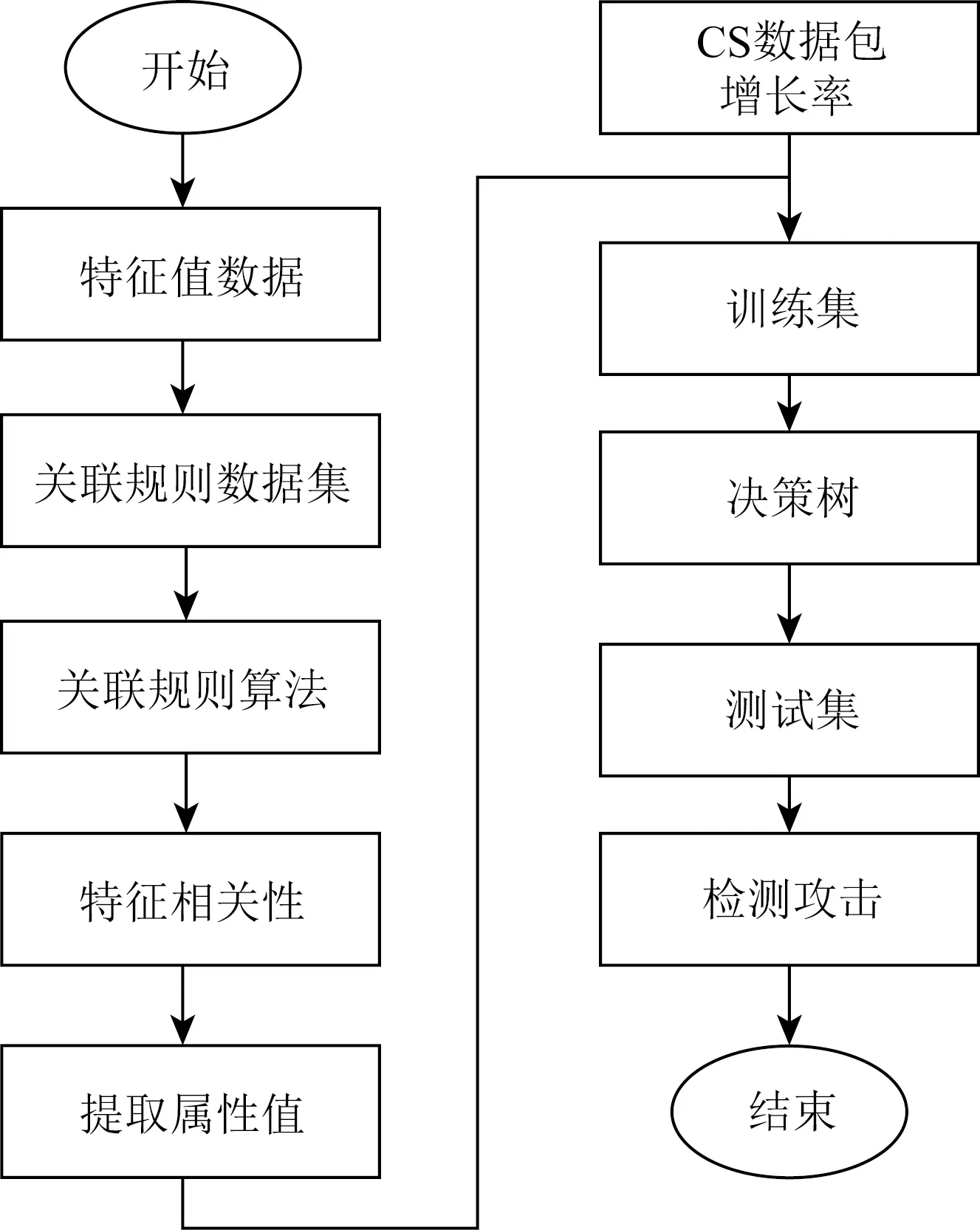
Fig. 5 Algorithm flow chart图5 算法流程图
3.1 关联规则Apriori算法
Apriori算法常被用于数据挖掘,它是关联规则算法中一种挖掘布尔关联规则的频繁项集算法,是一个基本算法[19].关联规则的作用找出数据集中的频繁项集,分析特征之间的关联性.处理PIT和CS中获取到的数据信息计算4个特征,划分4组特征,再构造布尔型数据集以便作为关联规则Apriori算法输入.在关联规则算法中,首先找到符合支持度标准的频繁项集,其次找到最大个数的频繁项集[20].如何划分数据集是保证用关联规则联合4个特征检测攻击的关键.使用关联规则的具体步骤为:
1) 提取PIT和CS中的数据信息,计算特征值,找出时间T内4个特征的最大值和最小值,并求最大值、最小值之差,将差值分为N份,每个特征的划分如表2所示.
2) 划分特征后,构造Apriori算法所需要的布尔型数据集.布尔数据集的构造如表3所示.TID表示条目,是划分的区间个数1~N.(10)表示是否落在划分的间隔内.当计算的各个特征落在所划分的间隔内时则为“1”,否则为“0”.当满意度的值越小即对应TID编号越大,则表明攻击可能越严重.对于其余3个特征,其值越大即对应TID编号越小,则表明攻击越严重.
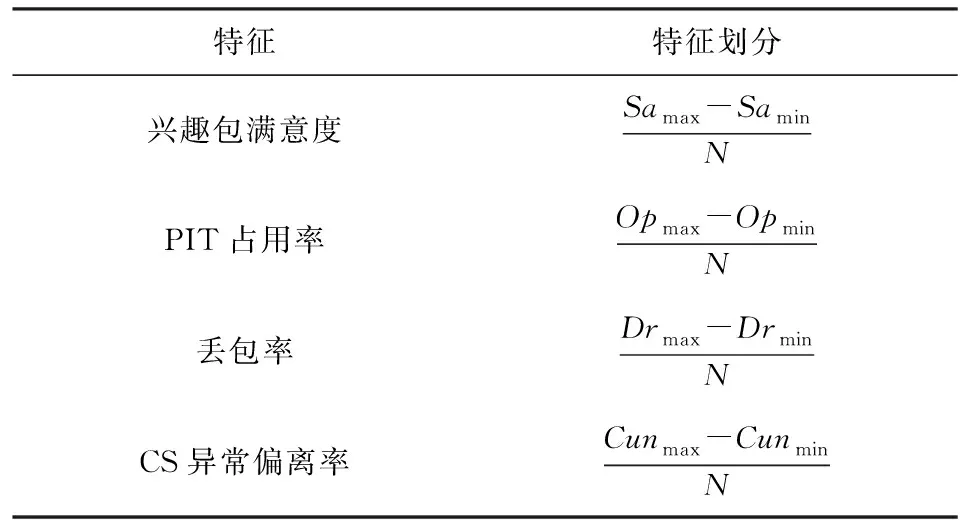
Table 2 Feature Division表2 特征划分

Table 3 Boolean Data Set D表3 布尔型数据集D
3) 在关联规则中,若项集的支持度大于最小支持度,那么此项集就是频繁项集.在Apriori算法中,首先找出所有的由最小支持度决定的频繁项集.支持度即几个数据关联出现的概率.4个特征的支持度计算为
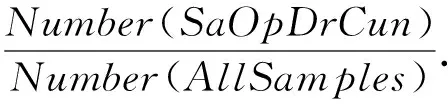
(5)
根据置信度和频繁项集找出强关联规则.置信度体现了一个数据出现后另一个数据出现的概率,即数据的条件概率.如4个特征Sa,Op,Dr,Cun中Sa对于Op,Dr,Cun的置信度为
Co(Sa⟸OpDrCun)=P(Sa|OpDrCun)=
P(SaOpDrCun)P(OpDrCun).
(6)
最后计算提升度,提升度表示含有Y的条件下,同时含有X的概率,与X总体发生的概率之比,它体现了各个特征之间的关联关系.所以根据提升度可以从强关联规则中筛选出有效的强关联规则.为了生成所有频集,使用迭代方法以此类推,直到无法再找到频繁项集为止.此时对应的频繁项集的集合即为Apriori算法的输出结果.算法1是关联规则的伪代码,首先输入构造的数据集D,再根据最小支持度找到频繁项集,将产生的候选项集进行筛选剪枝最后得到特征之间的关联性.
算法1.关联规则Apriori算法.
输入:布尔型数据集D、最小支持度min_support及相关参数;
输出:特征之间的最大频繁n项集Gn.
① 扫描数据集D产生1-频繁项集G1;
② for (n=2;Gn-1≠null;n++) do
③ 产生候选并剪枝,即Cn=Gn-1;
④ for扫描D进行候选计数do
⑤ 返回候选项集中不小于最小支持度的项集;
⑥ end for
⑦ end for
⑧ 返回Gn;
⑨ 得到特征之间的关联规则.
3.2 决策树ID3算法检测攻击
使用决策树进行分类检测,不仅可以更准确地检测攻击还可以判断攻击类别.本文采用目前常用的ID3决策树算法,它的优点是理论清晰且学习能力较强.ID3算法的核心是:为了在每个非叶子节点进行测试时可以获得有关被测试记录最大的类别信息,所以用信息增益(information gain)作为决策树各级节点上选择属性的标准[20].具体算法的步骤为:
1) 将Apriori算法输出的各个特征之间的关联规则和CS中数据包增长率作为训练集样本的特征,计算特征集合中信息增益最大的属性作为决策树的节点.决策树中计算信息增益首先要知道信息熵.事件的不确定性越大,它的熵就越大.训练样本集X的信息熵定义为
(7)
pk表示样本集合中发生事件k的概率,即样本k所占比例,n表示样本个数.条件熵为
(8)
Xi表示根据节点的属性A划分X后的第i个子集,其中|Xi|(i=1,2,…,m)为样本子集Xi中包含的样本数,|X|为样本集X包含的样本数.信息增益为
Gain(X,A)=E(X)-EA(X),
(9)
在选择节点时选择信息增益最大(信息不确定性减少的程度最大)的样本.
2) 由该属性的不同取值建立分支,再对各个分支采用步骤1建立决策树节点的分支.
3) 递归调用步骤1,2直到所有子集仅包含同一个类别为止,最终得到决策树模型.
通过训练集得到决策树模型后即可输入测试集检测是否有攻击,并对攻击进行分类.实验流程如图6所示:
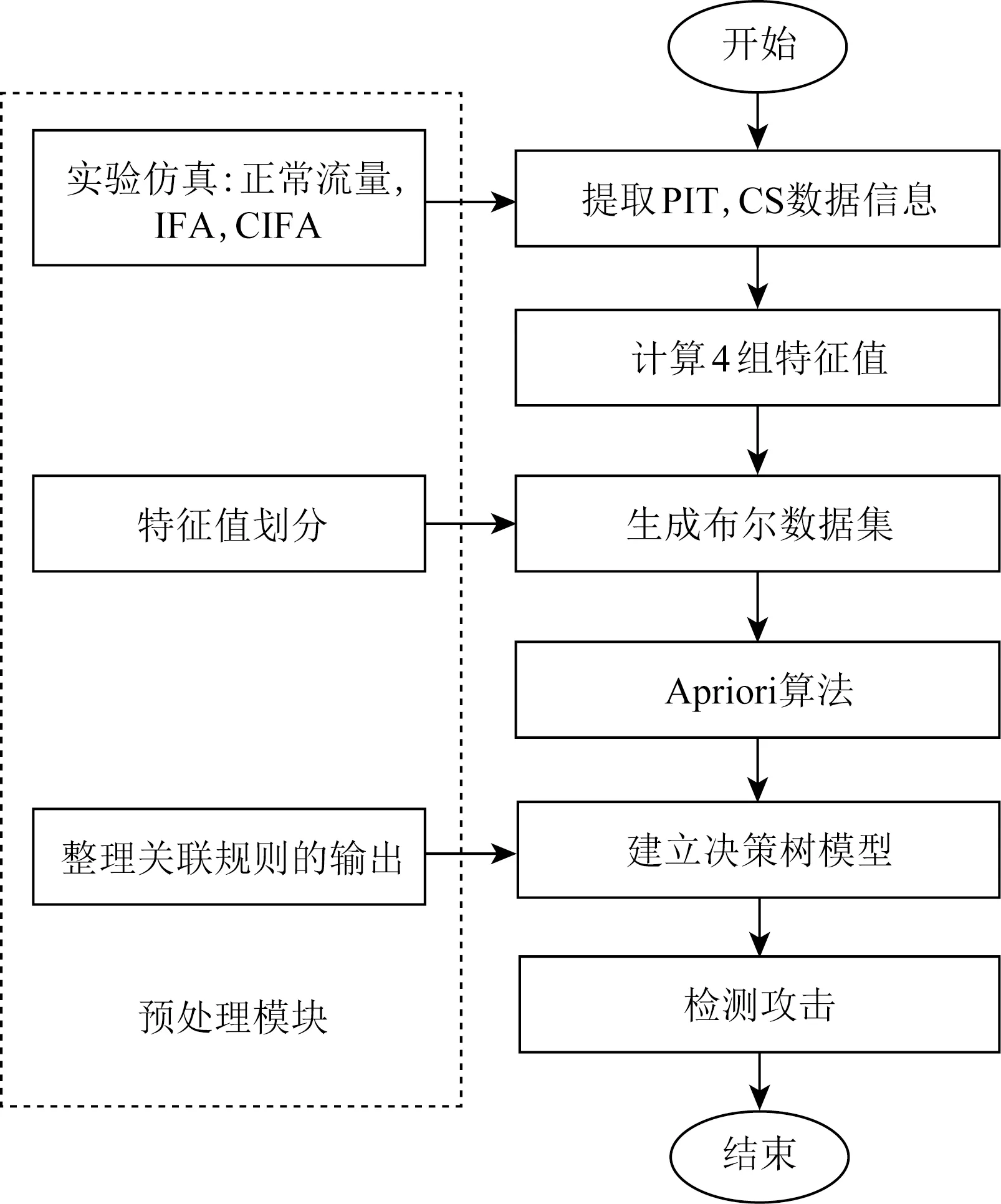
Fig. 6 Flow chart of experiment图6 实验流程图
4 实验仿真及结果与分析
本文实验在开源的ndnSIM平台上进行.ndnSIM是基于NS-3的网络模拟器,它可以实现NDN架构并运行各种大型和小型网络拓扑、模拟实验场景.在ndnSIM平台上实现关联规则Apriori算法和决策树的ID3算法.本实验在大规模和小规模拓扑中模拟不同强度的IFA攻击和CIFA.最终证明本文所提方法提高了检测率,还可以检测到是IFA还是CIFA.通过对比分析发现本文的检测方法有很好的检测效果.
4.1 实验环境
本文使用的实验平台为基于NS-3的开源模拟器ndnSIM1.0.本文所使用的小型二叉树拓扑(binary)如图7所示,使用的大型拓扑(ISP)如图8所示.
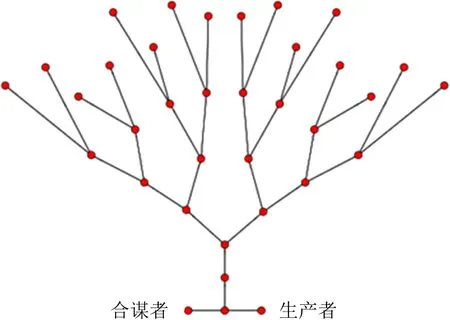
Fig. 7 Small binary tree topology图7 小型二叉树拓扑
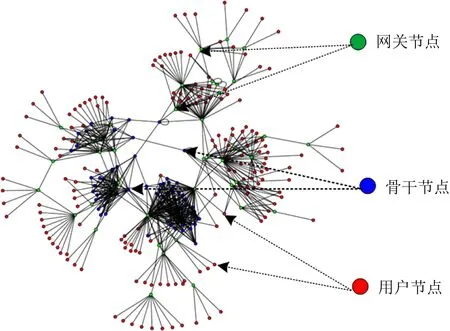
Fig. 8 ISP large topology图8 ISP大型拓扑
图8所示的大型ISP拓扑是基于Rocketfuel中Telstra拓扑结构的修改版本[21].拓扑节点由用户节点、与用户直节点接相连的网关节点和骨干节点组成.由IFA的攻击原理可知,IFA中不存在合谋者,所以当模拟IFA时不使用图7拓扑中的合谋攻击者节点,只存在生产者节点回复合法兴趣请求.根据隐蔽性高的CIFA的攻击原理可知,CIFA的合谋者会回复攻击者发送的非法兴趣包,因此,在模拟CIFA时图7中的合谋者和生产者分别回复非法和合法的兴趣请求.
合法用户以恒定速率发送兴趣包,发包时间间隔随机,为用户提供近似于真实网络流量的模拟场景.每个合法用户请求的内容分布都满足Zipf-Mandelbort分布,每个攻击者分布遵循均匀分布[22].实验环境参数设置如表4所示:
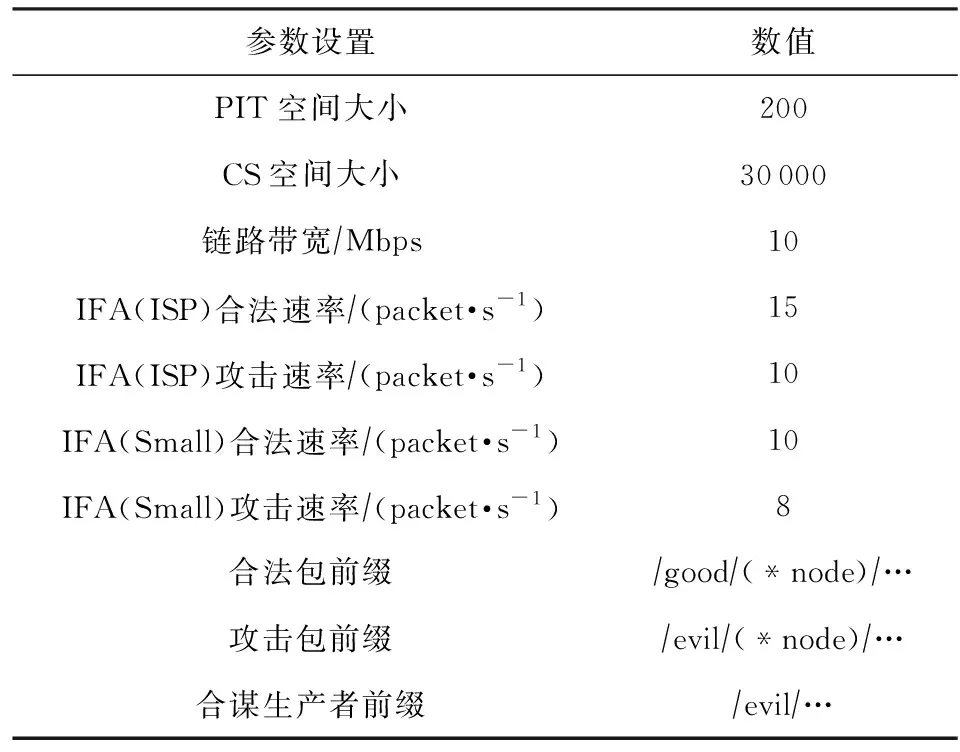
Table 4 Experimental Parameters表4 实验参数
大拓扑中,IFA恶意节点所占所有用户节点的百分比约为40%,模拟CIFA时逐渐增加攻击者的攻击强度,每次实验随机选择攻击节点.小拓扑中模拟CIFA和IFA时从16个叶子节点中随机选取4个节点作为攻击者,其余为合法用户.CIFA一个周期的攻击示意图如图9所示:
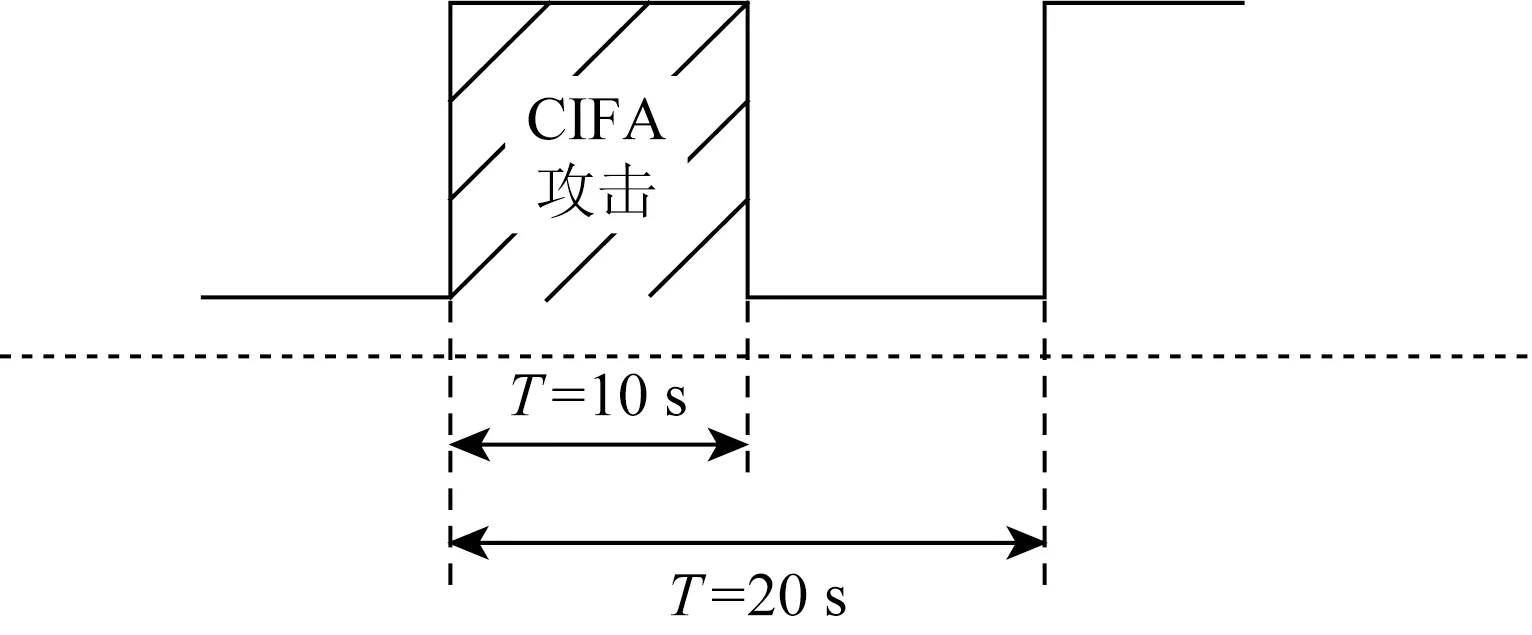
Fig. 9 Schematic diagram of CIFA attack cycle图9 CIFA攻击周期示意图
4.2 特征值提取及分析
为了证明4个特征可以有效检测攻击,在大型ISP拓扑和小型二叉树中进行实验,每次实验持续100 s.模拟2种攻击,IFA和CIFA的模拟时间均为100 s,在20~80 s发起攻击,前20 s和后20 s正常发包.每种攻击模拟10次,模拟结束后提取表1所列出的PIT和CS中的数据信息,计算每次实验的4个特征的值(每秒计算1次),将10次实验的计算结果求和取平均值.
4.2.1 ISP大型拓扑中模拟IFA

Fig. 10 IFA interest satisfaction(ISP)图10 IFA兴趣包满意度(ISP)
为了分析大拓扑下IFA攻击对整个网络不同节点的危害程度以及发生攻击时各个特征的变化特点,从下游节点(用户节点、网关节点)和上游节点(骨干节点)中分别随机选取1个节点进行观察.在大型ISP拓扑中模拟10次IFA,模拟结束后提取PIT和CS中的数据信息,按照式(1)~(4)分别计算兴趣包满意度、PIT占用率、丢包率、CS缓存异常偏离率.求和取平均后的实验结果分别如图10~13所示:
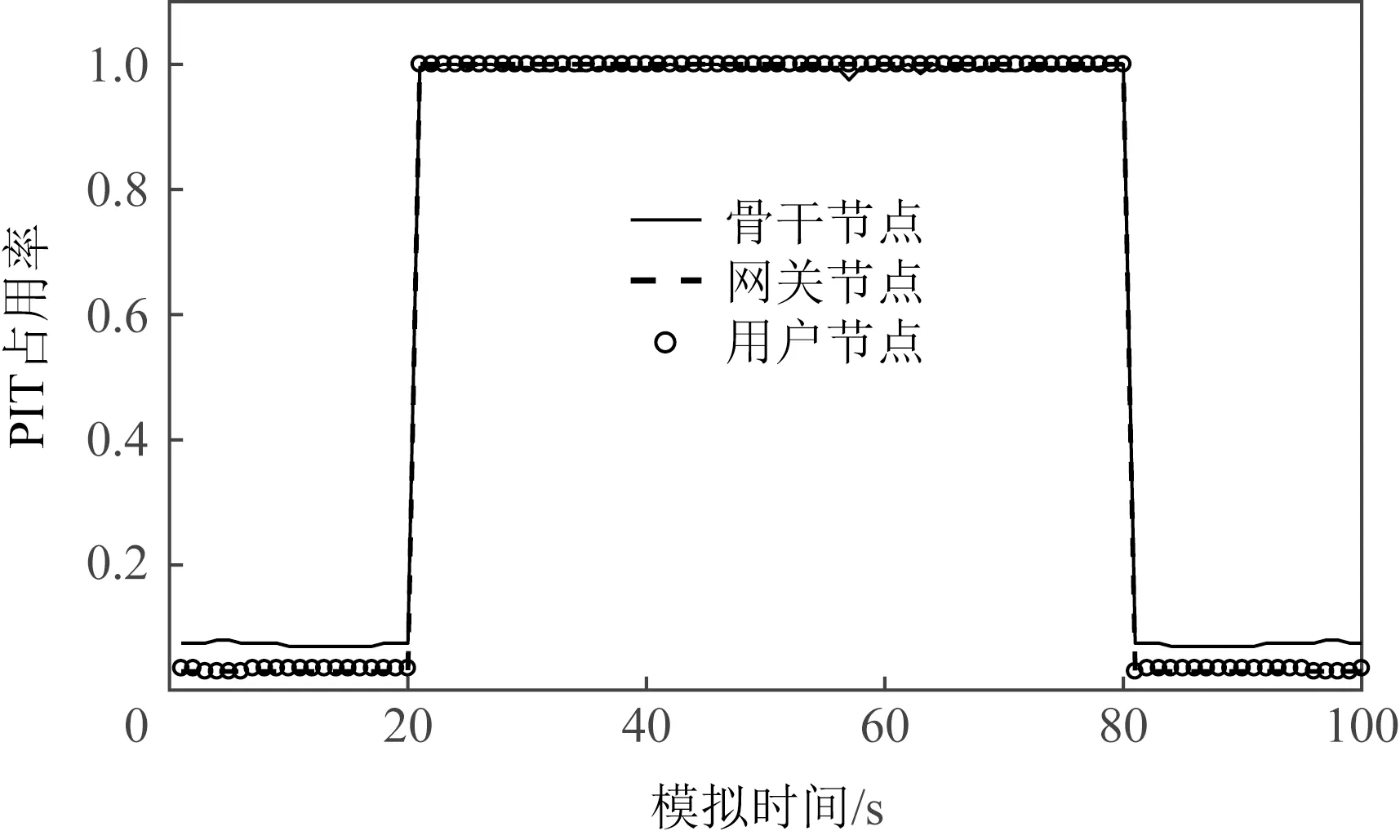
Fig.11 IFA PIT occupancy(ISP)图11 IFA PIT占用率(ISP)

Fig. 12 IFA drop rate(ISP)图12 IFA丢包率(ISP)

Fig. 13 IFA CS abnormal deviation rate(ISP)图13 IFA CS异常偏离率(ISP)
从4个特征的直观图中可观察到,在发起攻击期间(20~80 s),PIT满意度、PIT占用率、丢包率、CS异常偏离率均会发生异常变化.如图10所示,未发生攻击时各个节点的满意度几乎为1.从第20 s发起攻击时,骨干节点的满意度下降了一半,而用户节点和网关节点的满意度几乎为0.如图12~13所示,攻击产生时骨干节点的丢包率和CS缓存偏离率变化幅度小.图10~13中不同节点的特征变化曲线均说明相比于骨干节点,网关节点和用户节点受到IFA攻击时各个特征值的变化更明显,攻击对上游节点的危害更小.这是由于骨干节点上汇聚了来自多个下游节点的流量(合法流量和非法流量都有),而靠近下游的节点汇聚的流量少,所以特征值变化幅度小.综上,本文所选取的4个特征均可以作为检测攻击的依据,并且选取下游节点的特征会使更准确地检测攻击.
4.2.2 ISP大型拓扑中模拟CIFA
为了观察不同攻击强度下各个特征的变化特点,合法用户的发包速率不变(每秒发100个兴趣包),调整攻击者的发包速率,发起不同程度的CIFA(不同程度的攻击分别模拟10次).在大型ISP拓扑中模拟CIFA,提取PIT和CS中的数据信息,根据式(1)~(4)计算4个特征值.求和取平均值后画出直观图观察4组特征.如图14~17所示.图中Bad表示攻击者发包速率,Good表示合法用户的发包速率.CIFA中攻击者发起周期性脉冲攻击,从4个特征的直观图中可以看到在攻击期间4组特征值均呈现脉冲式变化,且攻击者发包速率越高,特征值的异常变化越明显.
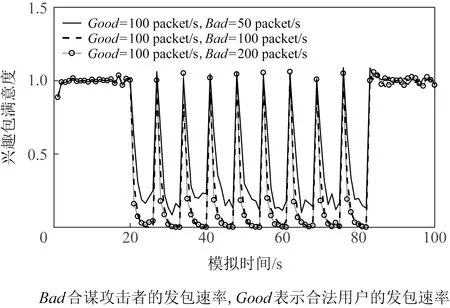
Fig. 14 CIFA interest satisfaction(ISP)图14 CIFA兴趣包满意度(ISP)

Fig. 15 CIFA PIT occupancy(ISP)图15 CIFA PIT占用率(ISP)
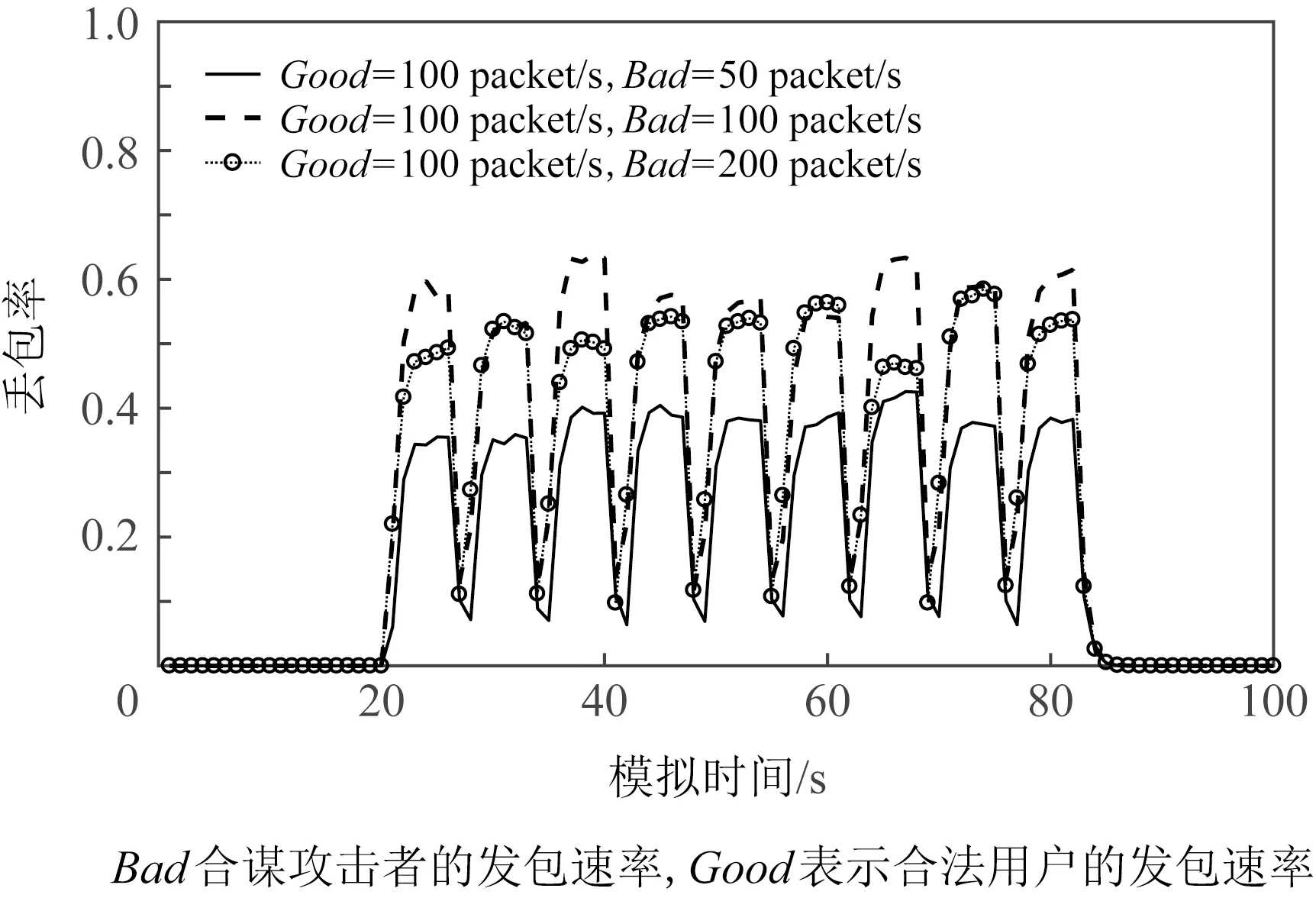
Fig. 16 CIFA drop rate(ISP)图16 CIFA丢包率(ISP)
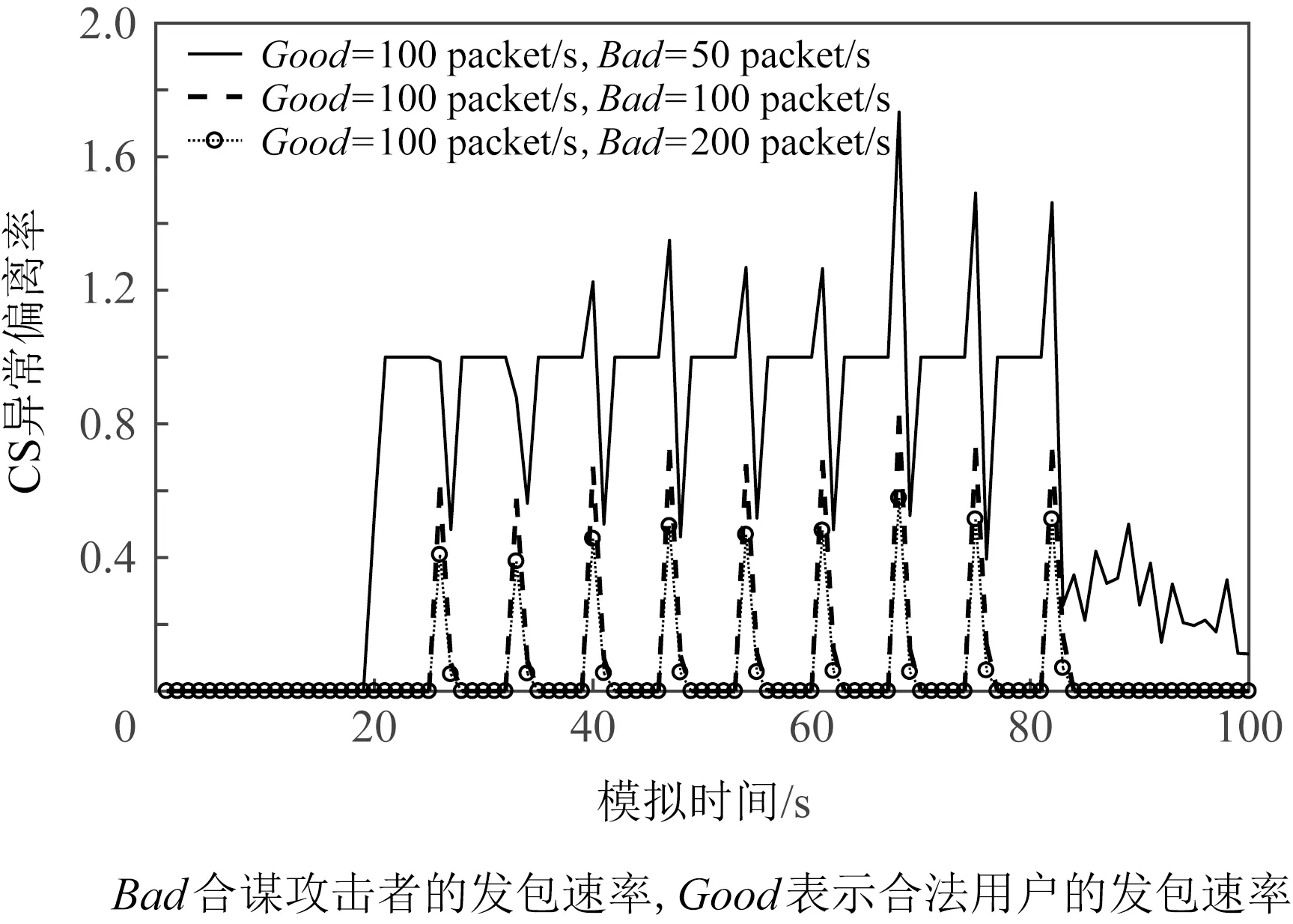
Fig. 17 CIFA CS abnormal deviation rate(ISP)图17 CIFA CS异常偏离率(ISP)
4.2.3 二叉树小型拓扑中模拟IFA
为了观察IFA攻击对小型网络拓扑中不同节点的危害程度.在二叉树中模拟10次IFA,随机选取1个骨干节点和1个网关节点,提取这2个节点PIT和CS中的数据信息.按照式(1)~(4)分别计算PIT满意度、PIT占用率、丢包率、CS异常偏离率.
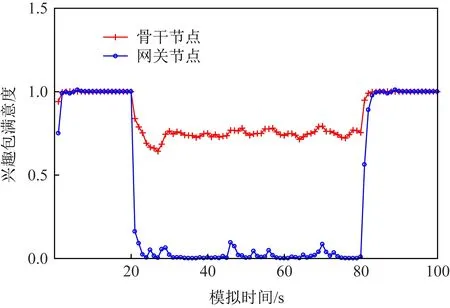
Fig. 18 IFA interest satisfaction(binary tree)图18 IFA兴趣包满意度(二叉树)
各个特征值的直观图如图18~21所示:
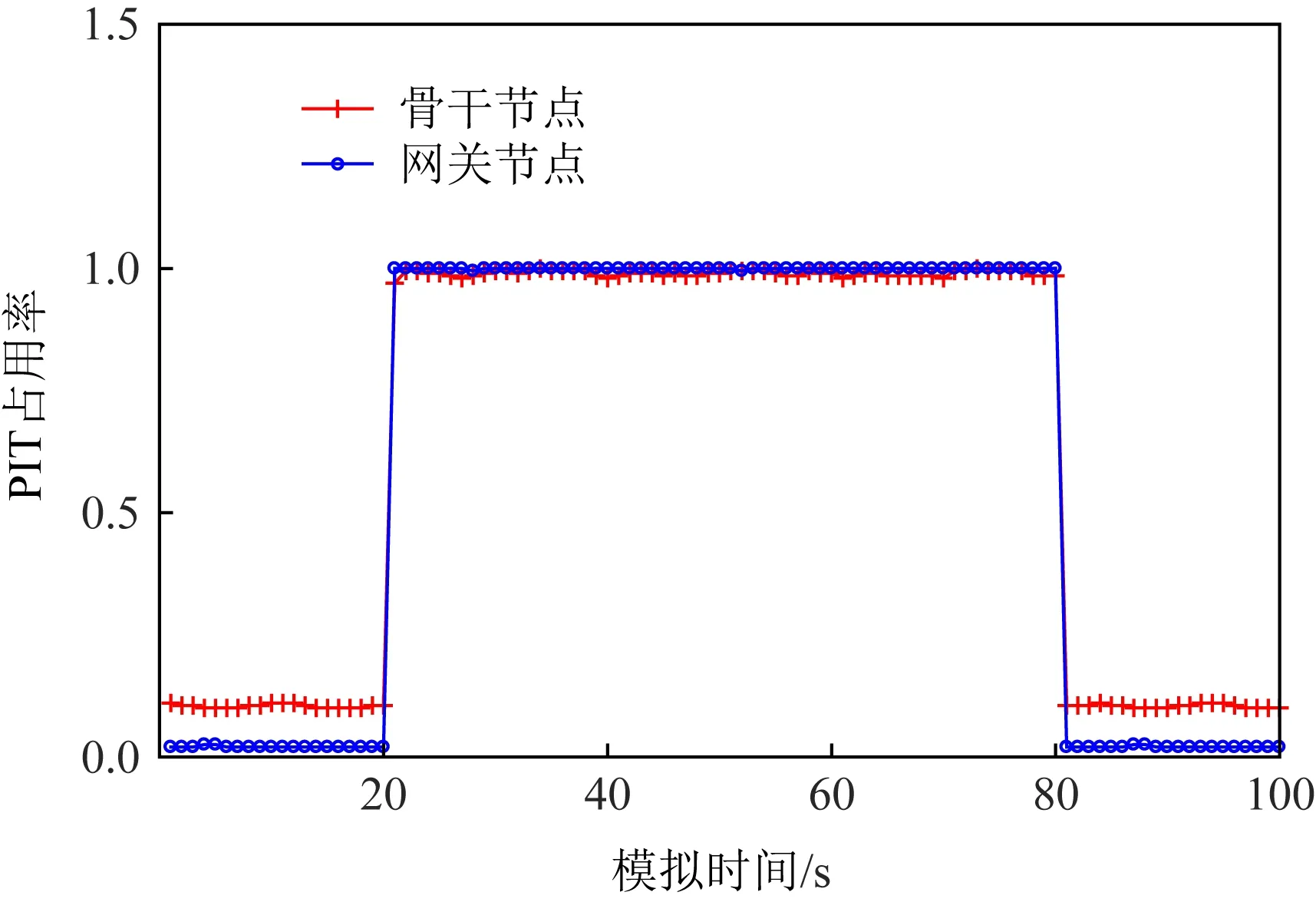
Fig. 19 IFA PIT occupancy(binary tree)图19 IFA PIT占用率(二叉树)
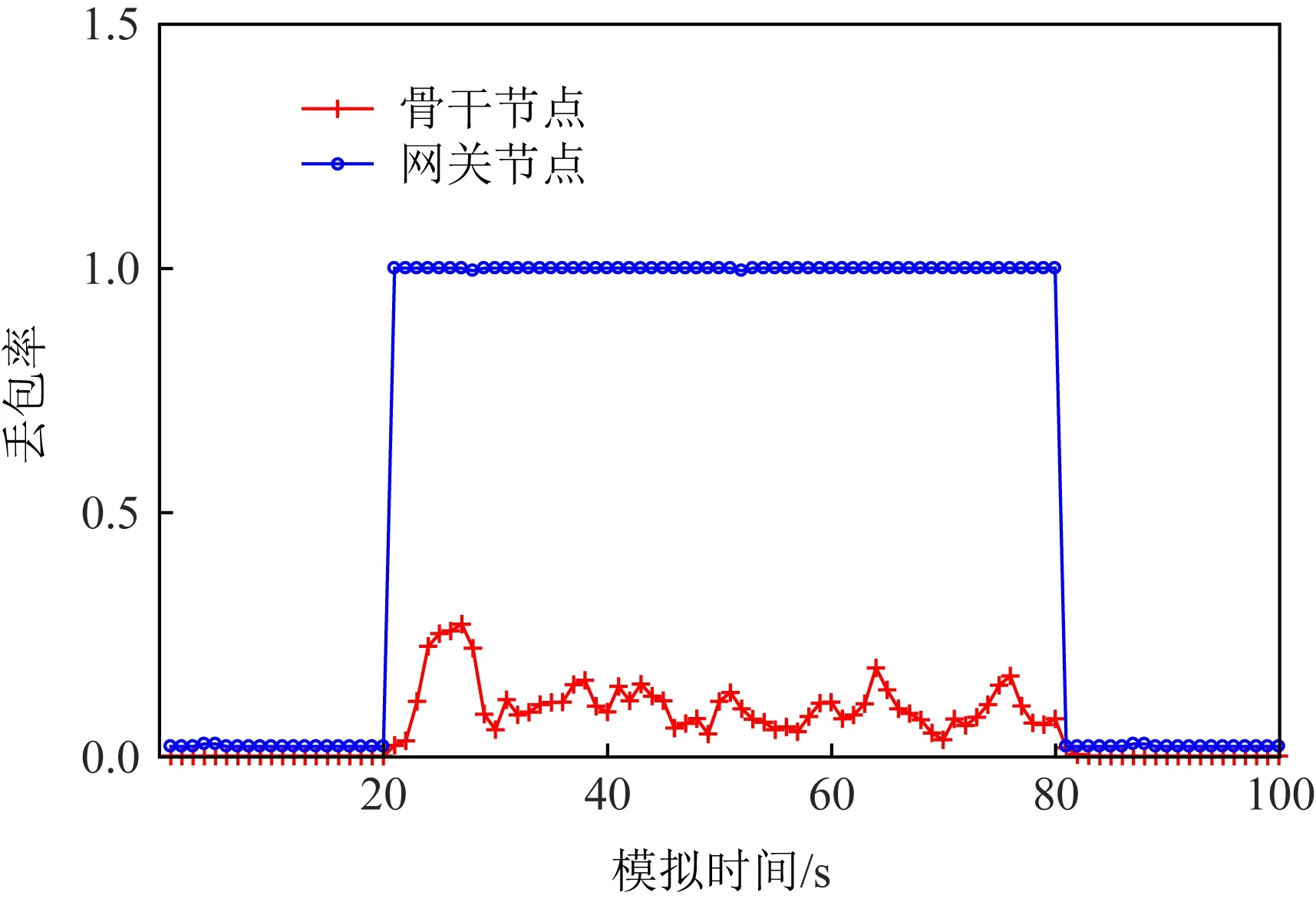
Fig. 20 IFA drop rate(binary tree)图20 IFA丢包率(二叉树)
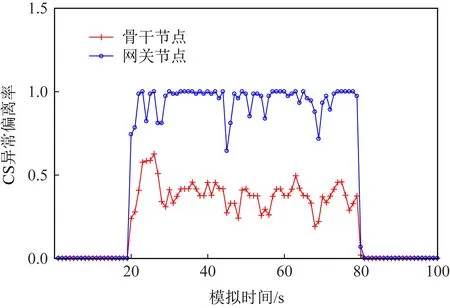
Fig. 21 IFA CS abnormal deviation rate(binary tree)图21 IFA CS异常偏离率(二叉树)
由图18~21可观察到,未发生攻击时各个特征值均处于正常状态,但是在发起IFA攻击时,图18~21中的特征曲线均会发生异常变化.如图18所示,网关节点的兴趣满意度几乎从1降到0,骨干节点的兴趣满意度下降了0.3左右.如图19~21所示,与正常网络流量情况相比,发生攻击后网关节点的PIT占用率、丢包率和CS异常偏离率的值都发生了明显变化,且骨干节点比网关节点的特征值变化幅度更大.实验表明,与大拓扑相同,二叉树小拓扑中攻击对网关节点(即下游节点)的危害更大.
4.2.4 二叉树小型拓扑中模拟CIFA
在小型二叉树拓扑中模拟CIFA,为了发起不同程度的CIFA(分别模拟10次).提取网关节点(cgw-8)PIT和CS中的数据信息,根据式(1)~(4)计算4个特征值.求和取平均值后画出直观图观察4组特征.如图22~25所示:

Fig. 22 CIFA interest satisfaction(binary tree)图22 CIFA兴趣包满意度(二叉树)

Fig. 24 CIFA drop rate(binary tree)图24 CIFA丢包率(二叉树)
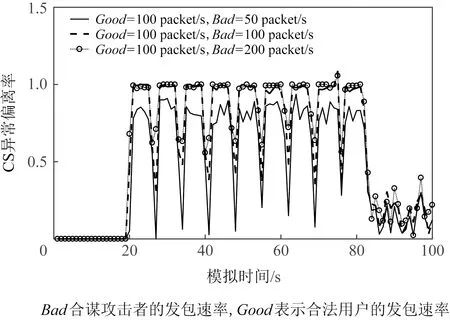
Fig. 25 CIFA CS abnormal deviation rate(binary tree)图25 CIFA CS异常偏离率(二叉树)
与大拓扑模拟CIFA的特征图14~17对比发现,二叉树小拓扑下CIFA的特征值脉冲式变换更加明显,这是因为小拓扑中攻击流量在各个节点更加聚集.对比各个特征在不同攻击强度下特征值的变化可知,随着攻击强度变高,特征值变化幅度变大.
本节通过对比大型拓扑和小型拓扑下IFA和CIFA攻击时4个特征变化,观察到无论发生何种攻击,各个特征均会发生变化.实验结果证明将这4个特征作为检测攻击的指标十分有效.
4.3 关联规则和决策树联合检测结果及性能评估
本节将评估本文算法的性能.首先,为了生成输入关联规则的布尔数据集D需要计算相关特征值.其次,将布尔数据集输入关联规则,得到各个特征之间的关联性.最后对输出的关联规则进行预处理生成训练集,建立决策树模型,检测NDN中的攻击.
4.3.1 关联规则
在大型和小型网络拓扑中分别模拟10次IFA,CIFA和正常网络流量,每次模拟持续时间为100 s.CIFA和IFA在20~80 s之间有攻击.提取PIT,CS中数据信息,每2 s计算1次兴趣包满意度、PIT占用率、丢包率、CS异常偏离率、CS数据包增长率.首先按照表2划分特征值,其次按照表3构造布尔型数据集,最后使用Apriori算法计算特征之间的关联规则.通过统计,输出关联规则有50种类型,如图26所示.
Fig. 26 Statistical diagram of association rules classification图26 关联规则分类统计图
4.3.2 决策树检测攻击
由图26关联规则分类统计图可知,输出的关联规则有50种类型,加上CS数据包增长率,共构成51个特征.
预处理51个特征数据,构造输入决策树的训练集.生成决策树模型后,再输入测试数据集进行测试.数据集包括大型和小型拓扑各420组,共840组数据,其中,大拓扑和小拓扑下的正常流量,IFA与CIFA分别有140组数据.
输入决策树的数据集用特征向量V=(V1,V2,…,V51)表示,其中V1表示CS数据包的增长率,V2至V51表示关联规则输出的50种关联规则.从大拓扑的420组测试数据集中随机抽取12个分类结果如表5所示:
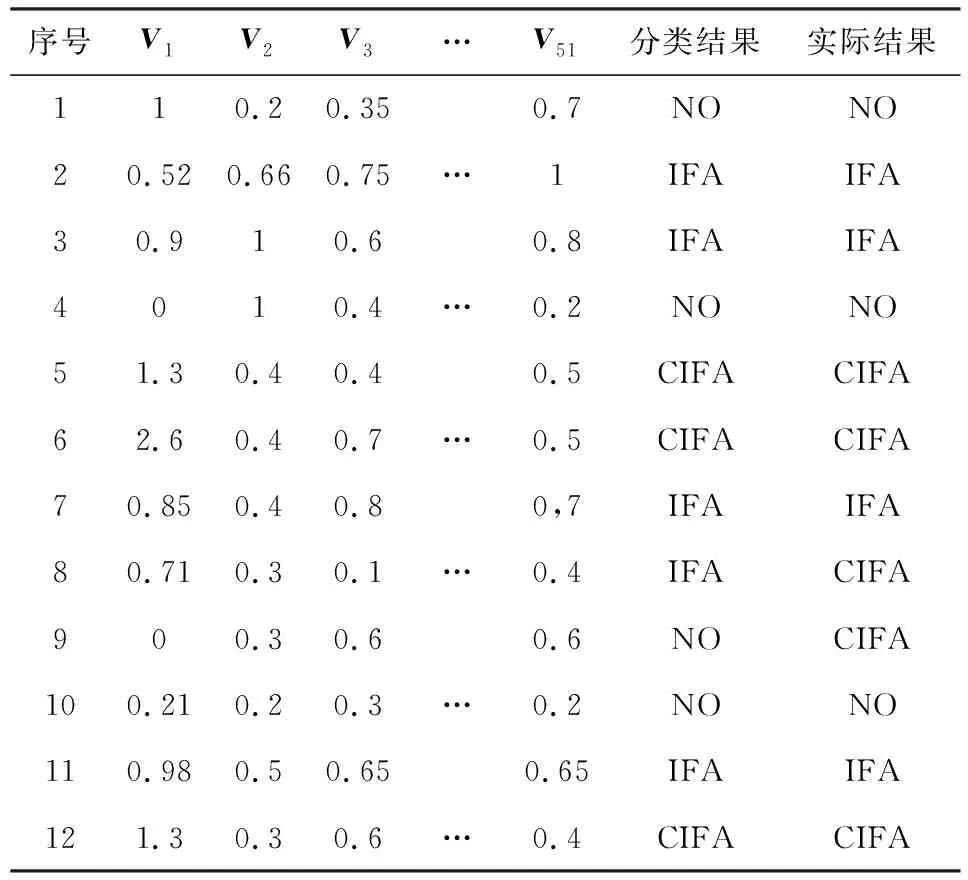
Table 5 Decision Tree ID3 Algorithm Classification andExtraction(ISP)
对决策树ID3算法输出的840组分类结果进行统计,分类统计结果如表6所示.表6中ISP表示大拓扑,Small表示小型二叉树拓扑.测试结果为不同拓扑下不同攻击相对应的结果,将测试结果和正确分类结果求差即为误报数(false positives).
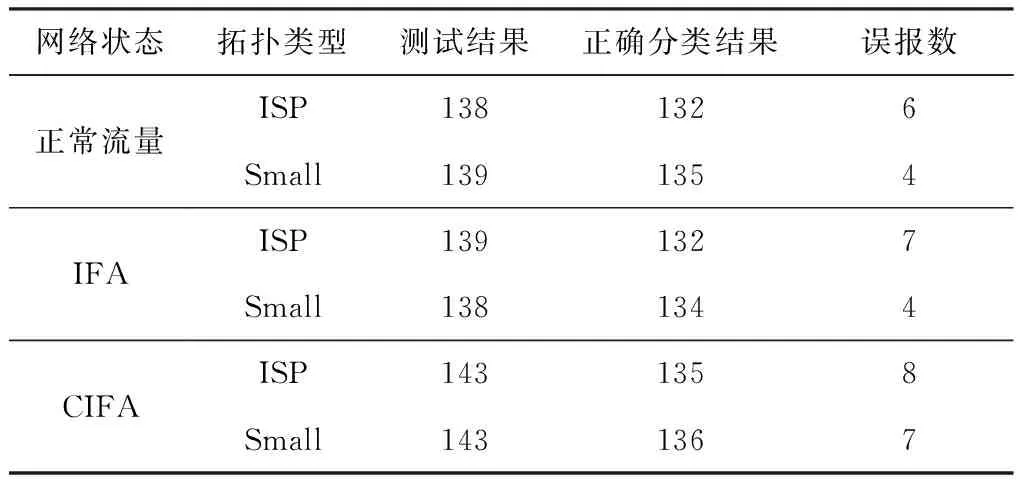
Table 6 Decision Tree Classification Results for Different Topologies
为了更直观地分析决策树ID3算法检测攻击的效果,统计量化2种拓扑下的分类结果,并与基于小波分析检测法、基于满意度回推方法进行比较.比较的指标有检测率和误警率,3种方法的性能对比结果如表7所示:
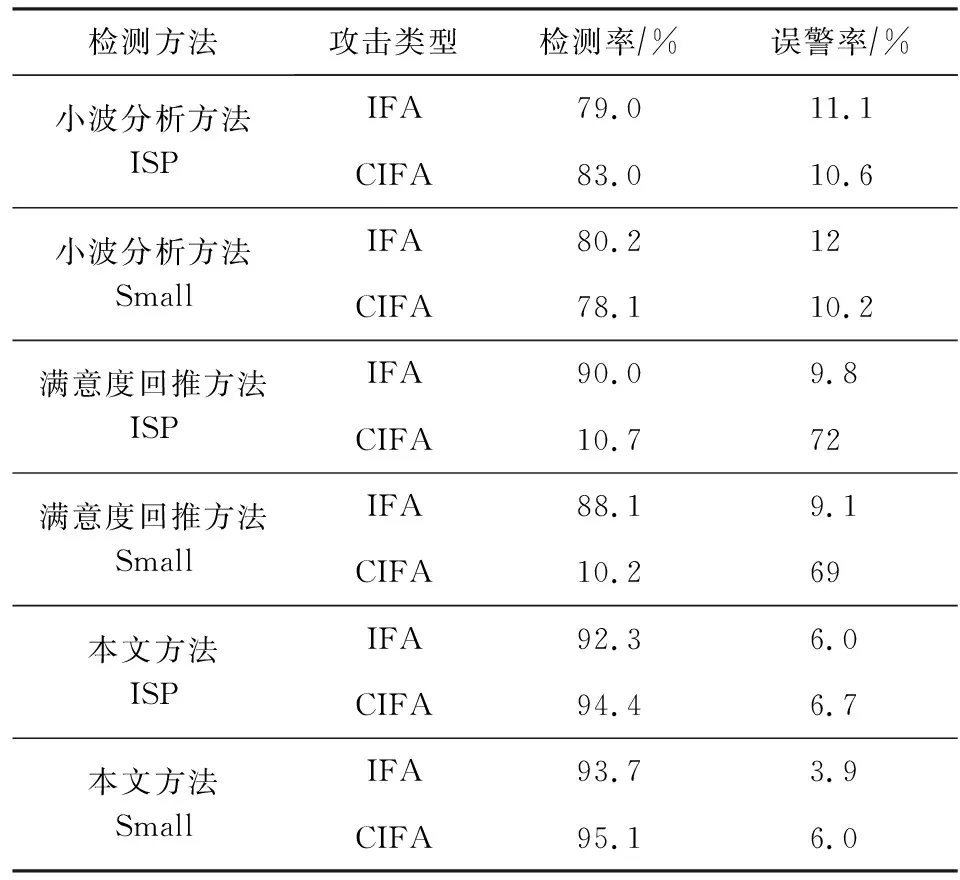
Table 7 Comparison of Detection Performance ofDifferent Methods
通过对比检测率和误警率可得到的结论是:1)基于小波分析法检测CIFA的检测率高于检测IFA检测率,说明前者的效果更好,同时检测IFA的误警率较高.2)基于满意度回推算法检测CIFA的检测率在大拓扑和小拓扑下都较低,但误警率高,且它更易检测IFA,这是因为CIFA隐蔽性好所以极难被检测到.3)本文通过实验分析CS中数据包的增长趋势,发现CS缓存增长率可以明显辨别IFA和CIFA.使用关联规则和决策树联合检测攻击的算法,使小拓扑下CIFA的检测率达到了95.1%,IFA的检测率达到了93.7%;大拓扑下CIFA的检测率达到了94.4%,IFA的检测率达到92.3%.本文的方法检测这2种攻击的误警率都较低,小拓扑下IFA和CIFA的误警率分别是3.9%和6.0%,大拓扑下的误警率分别是6.0%和6.7%.本文算法检测CIFA的检测率更高,但大拓扑和小拓扑下CIFA误警率稍高于IFA的误警率.分析对比大拓扑和小拓扑下攻击的检测率可知,相比于其他2种检测方法本文算法的检测率明显提升,误警率也有所降低.综上所述,本文所提的检测攻击方法提高了攻击的检测率,并且可以辨别攻击种类.
5 结论及展望
本文通过实验分析CS中的数据包信息,挖掘了判断攻击的新特征.针对NDN中的攻击,提出一种基于关联规则和决策树的联合检测方法.通过实验对比以及性能分析可知该方法提高了检测率并且区分是何种攻击.将方法部署在网关节点中,通过Apriori算法找到网络中的流量特征信息的关联性,进行预处理后构造输入决策树的训练集构建决策树模型增加了决策树算法的分类属性,最终通过决策树判断是否有攻击以及产生攻击的原因.通过大量实验和性能对比发现本文具有较好的检测效果.但是本文所提方法计算量较大,检测攻击有一定延时.针对本文方法的不足之处,在未来的工作中我们旨在研究如何降低算法的时间复杂度,更快、更准确检测攻击,并找到对于不同攻击的防御措施,更加有效地防御IFA和CIFA.
