基于关联规则的零售企业营销策略优化研究
2021-03-31刘志林任海帅
刘志林,任海帅
(新疆财经大学 工商管理学院,新疆 乌鲁木齐 830000)
0 引言
随着新一轮商业模式的变革,线下零售市场将成为新的零售增长点. 以大数据驱动的“新零售”在消费定位、生产制造、营销方式等方面优势明显,能够有效提升线下零售业的竞争力和经营效率[1]. 与此同时,随着多种零售业态的出现、数据化的管理、商品条形码的普及,线下零售实体也产生了大量的交易数据. 如何从海量、冗杂的数据中找出有价值的信息,关联规则分析是非常重要的工具和手段. 由于缺少对大数据的了解,以及专业背景营销人员的支持,线下零售企业对关联规则的理解只存在于概念,运用关联规则指导决策的企业屈指可数. 日本的零售企业7-Eleven通过对小店的数据赋能,店铺坪效为我国同行的十倍,我国线下实体零售有着巨大的发展潜力. 以超市为代表的实体零售企业,其利润主要来源于商品进销差价、供应链成本优化以及管理成本控制. 在国内剧烈的竞争压力下,这三者利润空间已逼近上限,仅仅靠节流已经无法提高竞争力,各大超市迫切希望借助关联规则手段深挖数据中隐藏的高价值的信息,调整自己的营销策略. 部分零售企业开始通过日常购物流水数据来研究商品之间的关联和顾客的购买习惯,但大多数超市的软硬件设备只能满足最简单的数据的录入、查询、统计等功能,无法挖掘潜在的商品关联及用户购买习惯. 营销策略方面,经典4P理论(Product, Price, Place, Promotion)认为“产品”是企业的第一战略,消费者对超市的选择本质上是商品偏好的结果. 定位消费人群和价格,提高商品组合的性价比,拥有持续的竞争力. 中国很多大型商超仍然坚持落后的经营理念,有些超市货架的摆放还未形成一套完善的系统,商品随意放置,顾客消费体验较差. 20世纪90年代美国超市已经发现了啤酒与尿布的规律,啤酒与尿布就近摆放,会使两种产品销售增加. 而我国超市最常见的关联搭配仍是避孕套和口香糖的组合,商品组合和货架布局等营销策略有待优化.
总的来说,笔者通过文献研究和实际访谈,明确了实体零售企业正在面临的困境,通过R软件对某大型超市数据进行关联规则分析,挖掘到顾客的消费习惯和商品之间的关联,将分析的结果与市场营销和消费者行为等理论相结合. 超市管理人员可以利用数据分析的结论,优化自身的营销策略,比如对货架布局进行优化、捆绑销售、互补品销售等,为顾客带来更多便利和优惠的同时,提高超市的竞争力.
1 关联规则的相关理论研究
关联规则是数据挖掘的重要内容. Agrawal等首先提出了从顾客交易数据库中发现用户购买行为模式的相关性问题,并提出了基于频繁集的Apriori算法,至今Apriori算法仍然作为关联规则挖掘的经典算法被广泛讨论[2]. 由于Apriori经典算法本身的局限以及计算效率的不足,国外学者对算法进行了不同程度的优化和研究. Agrawal本人也提出了一些改进算法,如 Apriori Tid,Apriori All等. 皮德常基于动态剪枝的关联规则发现方法,讨论了如何实施动态剪枝,给出了一个基于三元组结构的树式存储结构,并在此基础上描述了交易数据库中知识发现算法,有助于挖掘迅速更新的数据[3]. 国内的学术领域主要侧重于算法系统模型的研究. Lin Weifang等提出了关联规则的一整套系统的模型的应用研究[4]; 冯瑶基于零售业的数据挖掘技术的分析,对其中的关联分析方法进行了详细的研究[5]; 黄嘉满根据关联规则和兴趣度推出商品竞争模型、商品利润模型和商品推荐模型[6]; 于芳提出了应用关联规则中各个项目的加权利润之和的思想,评估关联规则的价值,并用 SAS 软件和 SAS语言编程实现了超市市场营销模型的演算[7].
总的来看,国内外学者多侧重于算法和模型的研究,很少有学者将关联规则应用到零售企业营销策略的优化上. 关联规则在商业实际运用中也存在很多问题,譬如在零售数据使用时,使用者对关联规则的认知通常是通过一条条规则来呈现的,这些规则经过了软件的过滤和删减. 事实上,许多耗费精力产生的规则往往不尽如人意,甚至无法给企业带来商业价值. 这主要存在三方面的原因:第一,是评估指标使用不恰当. 例如:支持度、置信度、提升度、覆盖率、确信度等指标,不同指标对于规则的筛选作用不同. 第二,缺少对关联规则的可视化分析,筛选关联规则时无法洞察多种商品之间错综复杂的关系,很容易将有效的规则排除在外. 第三,被验证过的有效规则要想解决实际商业问题,必须结合行业经验以及市场营销规律. 因此,笔者希望借助关联规则优化零售企业营销策略,填补现有研究的不足.
2 关联规则挖掘的实现过程
2.1 数据准备
本文搜集到了一家大型连锁超市的原始数据集,其中包含从2019-05-14T 09:17:05至2019-05-18 T 21:50:40期间的52 283条交易记录,主要包括单号、销售时间、品名、数量和金额等信息.
(1)原始数据中包含了一些消费者信息,表中有以下属性:销售单号、销售时间、销售方式、销售金额.
(2)商品信息主要包括商品名称、规格、货号、数量.
超市原始销售数据使用xlsx格式留存,在R语言数据处理中,需要把所有相关的超市数据转换为R专用的CSV文件. 表1是超市的部分原始数据.
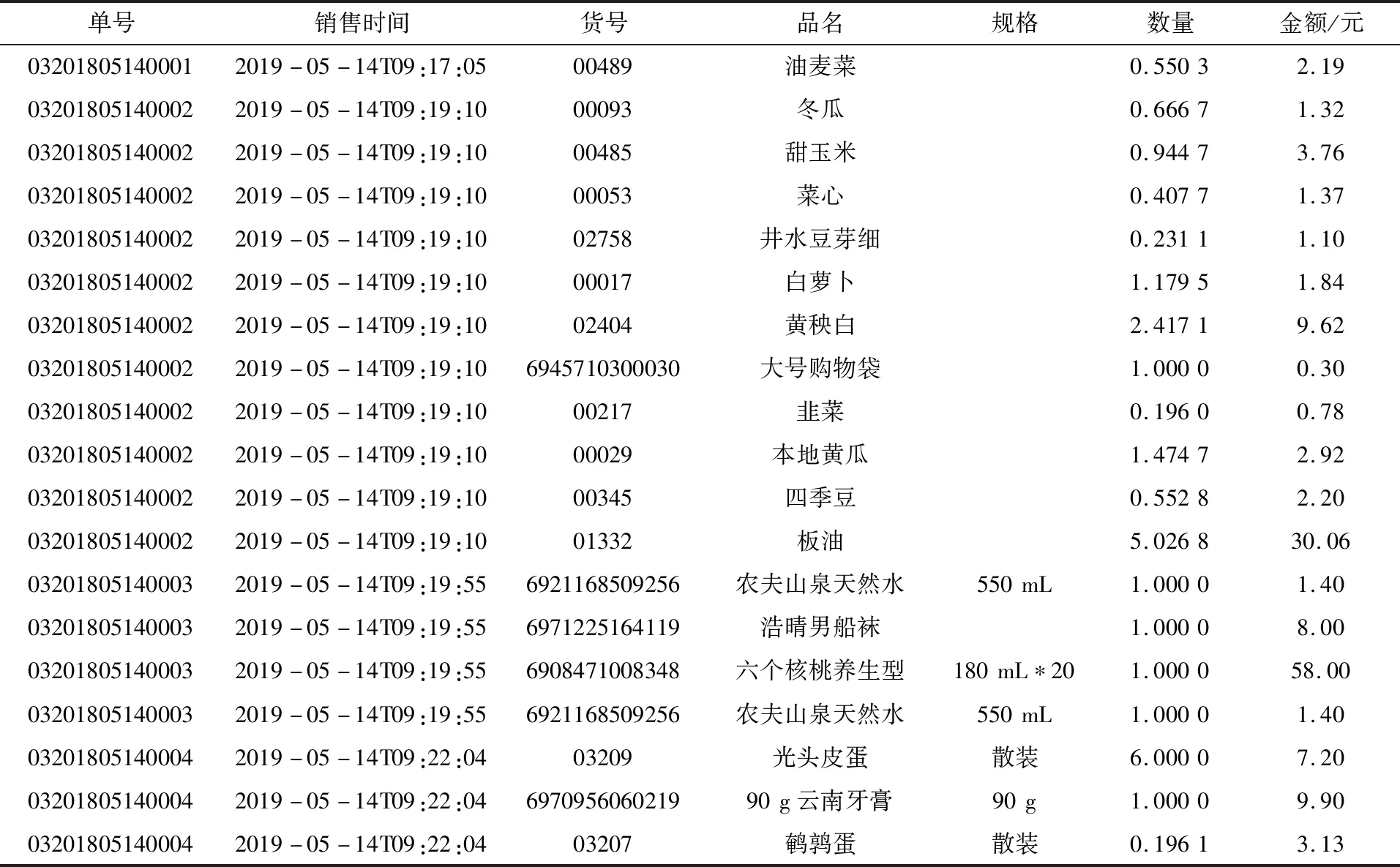
表1 销售流水表的部分原始数据
2.2 数据预处理
2.2.1 数据预处理过程
超市原始的销售数据集,存在着一些干扰性的数据,需要剔除删减后才能使用. 例如,规格等与本研究无关的变量,塑料袋类的商品销售数据,一些退换货的商品. 另外,不同的数据处理软件有着不同的数据格式. 因此,数据分析前必须对数据进行处理.
(1)共计15条发生退货的商品,以及包括3项合计的金额等多余信息需要进行剔除,剩下共计52 268条有效信息.
(2)删除无关的变量,只保留“单号”和“品名”两部分.
(3)将数据转化为CSV格式,以便R语言录入处理.
2.2.2 数据预处理结果
R软件提取数据集groceries,并创建稀疏矩阵,一行代表一次交易,一列是一个商品,并提取该数据集中的前10项内容. 输出的结果如图1所示.

图1 数据的基本信息
从图1可知,共计发生8 643条交易,包括6 311个商品,疏矩阵中1的百分比为0.000 9.
图2为频繁项目和支持度. 根据itemcount得到整个item基本情况; 将频繁项集按照降序排列,筛选出前10个最频繁的项目; 按照支持度(itemFrequency)排序,查看支持度最大的商品.
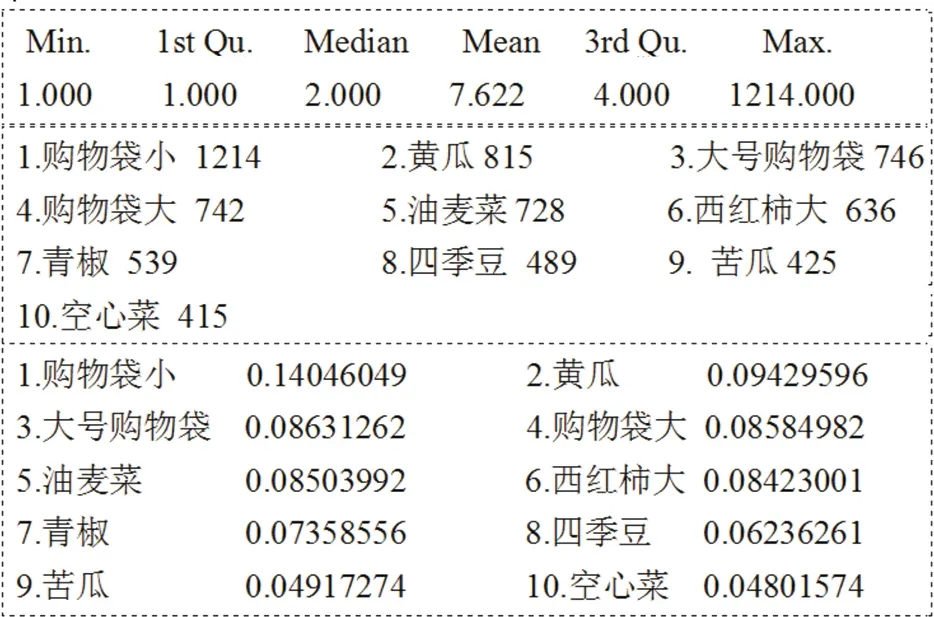
图2 频繁项目与支持度
第一分位数是1,意味着25%的项目频繁度不超过1次. 中位数是2,说明50%的项目频繁度不超过2次. 均值7.6表示所有的项目平均购买频率为7.6次,商品最大的购买频次为1 214. 最频繁出现的五项商品为(除购物袋外):黄瓜、油麦菜、西红柿、青椒、四季豆,以及它们各自出现的频次,如黄瓜815次、油麦菜728次. 在所有的交易记录中,(除购物袋之外)最大支持度为黄瓜0.094 295 96.
图3为频繁项集直方图. 可以直观地看到,这10种商品支持度都在0.04以上,西红柿与油麦菜的支持度相差很少.
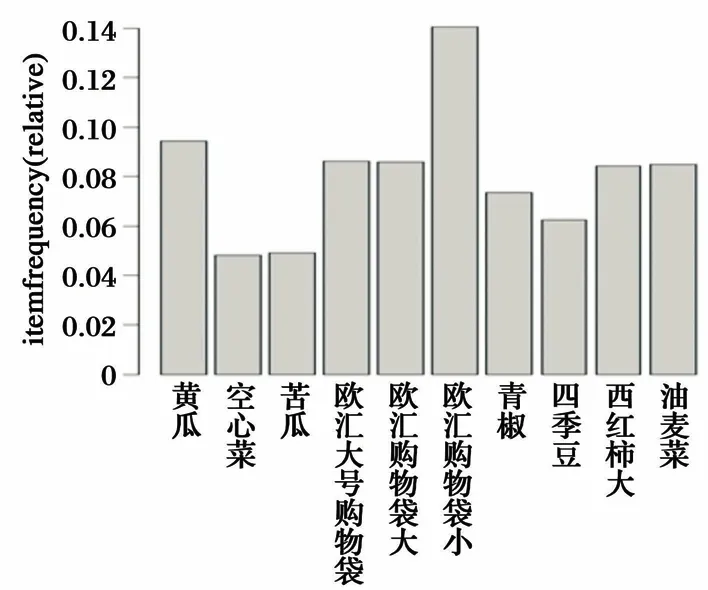
图3 频繁项集直方图
2.3 关联规则挖掘
2.3.1 支持度和置信度
确定支持度和置信度的取值是进行关联规则挖掘的前提. 实际上,算法执行过程,就是在对支持度和置信度不同数值规则的取舍. 如果支持度定得过高,很有可能会排除一些支持度低但置信度高的有效规则; 同样地,如果只考虑低支持度的规则,很可能会产生一些无效甚至是错误的规则,使得用户难以利用,甚至给经营决策带来误导. 所以,从较低的支持度和置信度的值开始,慢慢地提高阈值,根据规则数量的需要,对提升度的值进行有效性验证,筛选出有效的规则. 本文使用Aprior算法进行规则的挖掘,经过多次尝试后,确定支持度为0.004,置信度为0.208,minlen=2.
从返回的结果看,总共有50条规则生成,其中长度为2的规则有38条,长度为3的规则有12条. 表3列出了其中的20条规则,并且按照提升度由高到低排列,表3中第2、7、14个规则无效,故剔除.
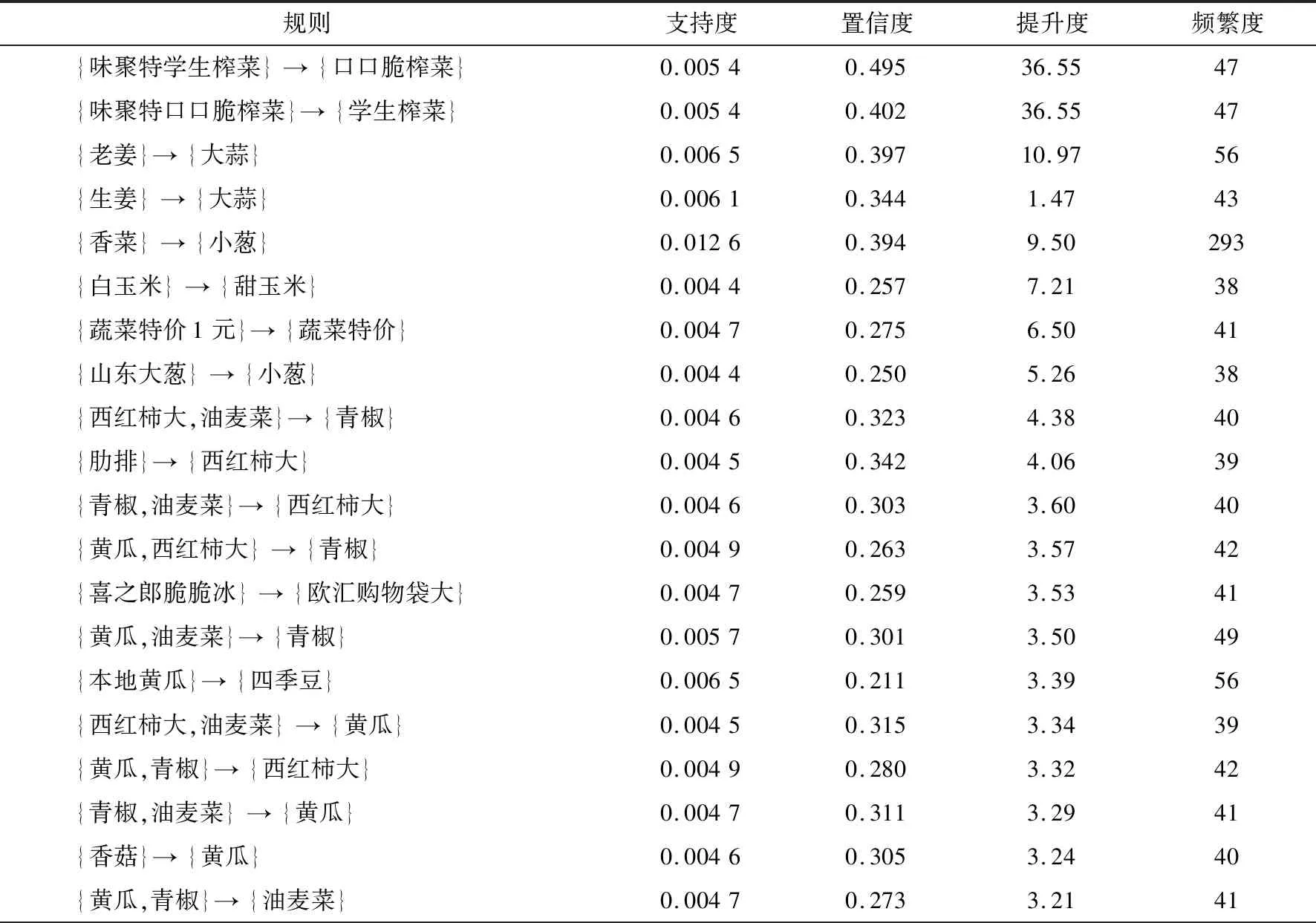
表3 关联规则
图4是21条规则的散点图,横轴表示支持度,纵轴表示置信度,颜色的深浅代表着提升度. 根据散点图来看,这20条规则的提升度均大于1,说明规则有效.
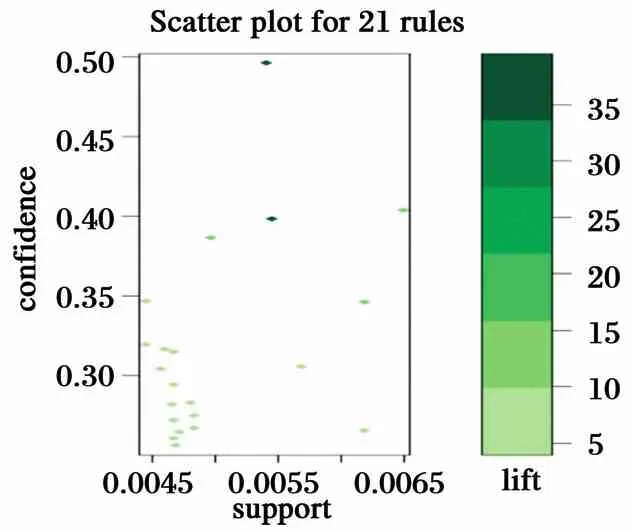
图4 21条规则散点图
2.3.2 关联规则其他评估方法
表4为关联规则的评估指标,分为以下四种:
(1)费雪尔正确性检定(Fisher’s Exact Test):检定两组独立样本所来自的两个母群体,在某一特性上分别所占的比例是否相等.p值大部分都是很小的(p<0.05),这就说明这些规则反映出了真实的用户的行为模式.
(2)规则的覆盖率(Coverage):LHS的支持度,相当于覆盖到了多少范围的用户.
(3)卡方统计量(ChiSquared):可以检验规则的LHS和RHS之间的独立性. 卡方值统计量的值越高,规则越可信.
(4)确信度(Conviction):类似于卡方统计量,也是衡量独立性的指标. 这个值越大,关联度越高.
2.3.3 关联规则可视化
图5是对提升度前21规则的可视化呈现. 可以很明显地看到,箭头总是从其中一个项集指向另外的一个项集,例如,西红柿、油麦菜和青椒的箭头表示规则{西红柿大,油麦菜} → {青椒}. 该图例中图形颜色的深浅代表着提升度的高低,取值范围为1.942~36.547; 置信度的范围为0.259~0.459; 提升度最好的规则是{味聚特学生榨菜63g} → {味聚特口口脆榨菜63g}.
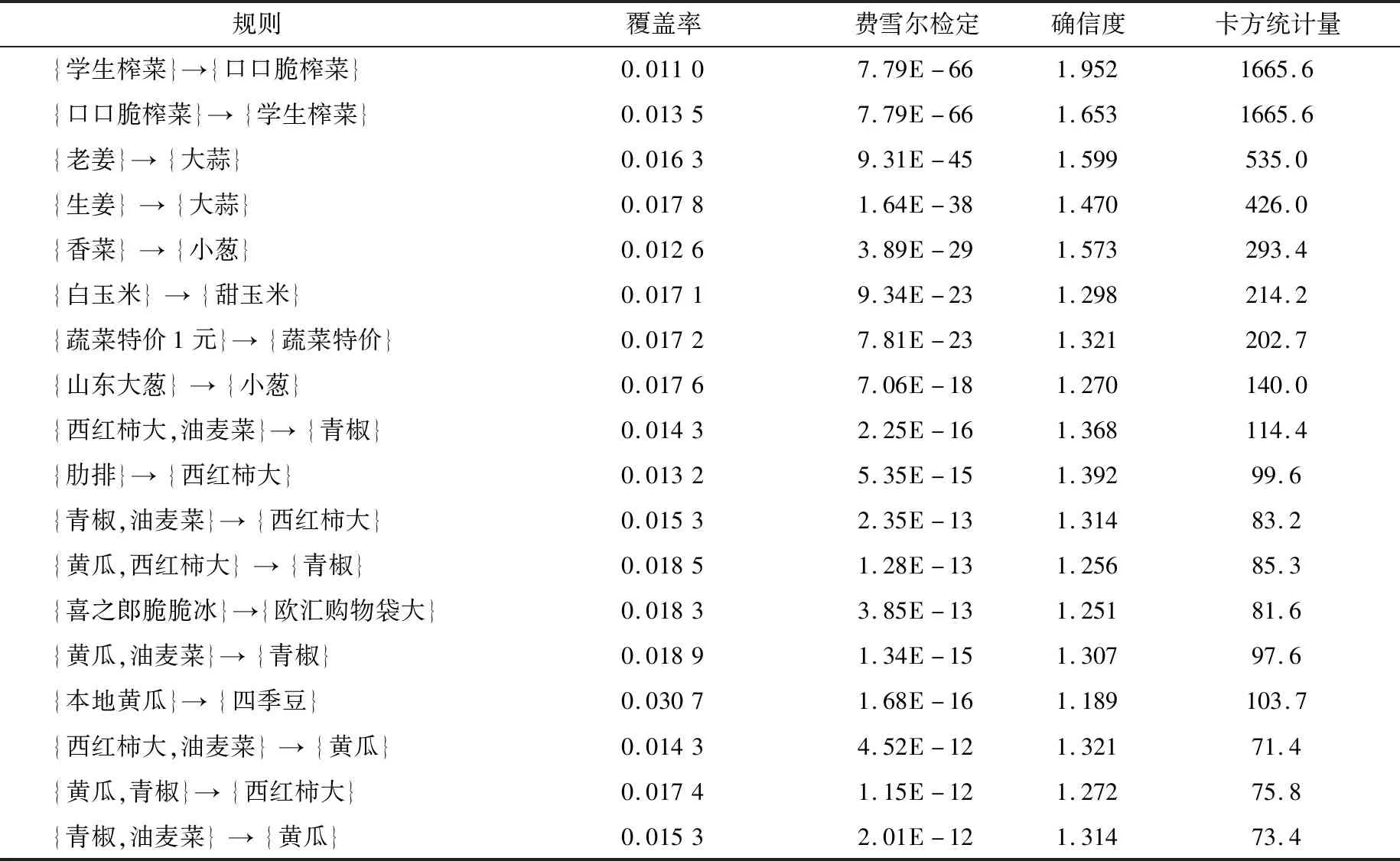
表4 4种评估指标
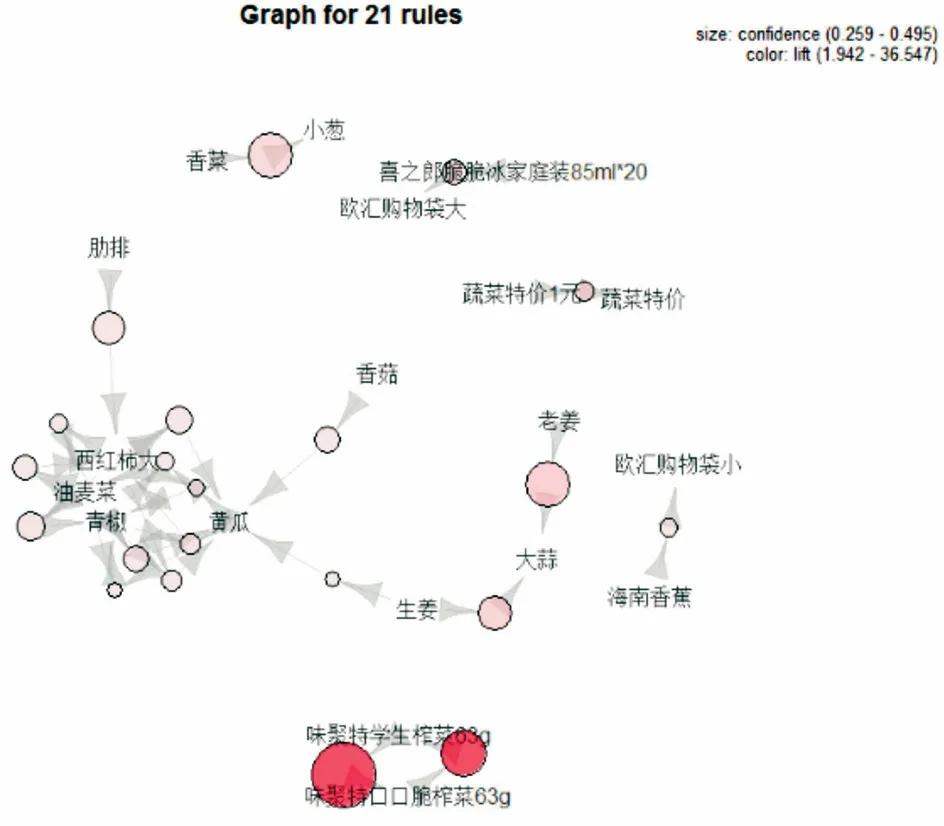
图5 21条规则可视化
由于上述只是支持度较高商品的关联情况,可能会忽略其他更为有效的关联规则. 因此,通过降低支持度,提高置信度得到了150个关联规则. 然后,根据提升度排序,选出20个有效的规则(见图6). 提升度的取值区间为41.979~370.414,置信度的区间为0.4~0.9,提升度最好的规则是{桂皮} →{八角}.
3 结论与展望
3.1 研究结论
根据对超市销售数据进行分析,我们可以得到以下结果:
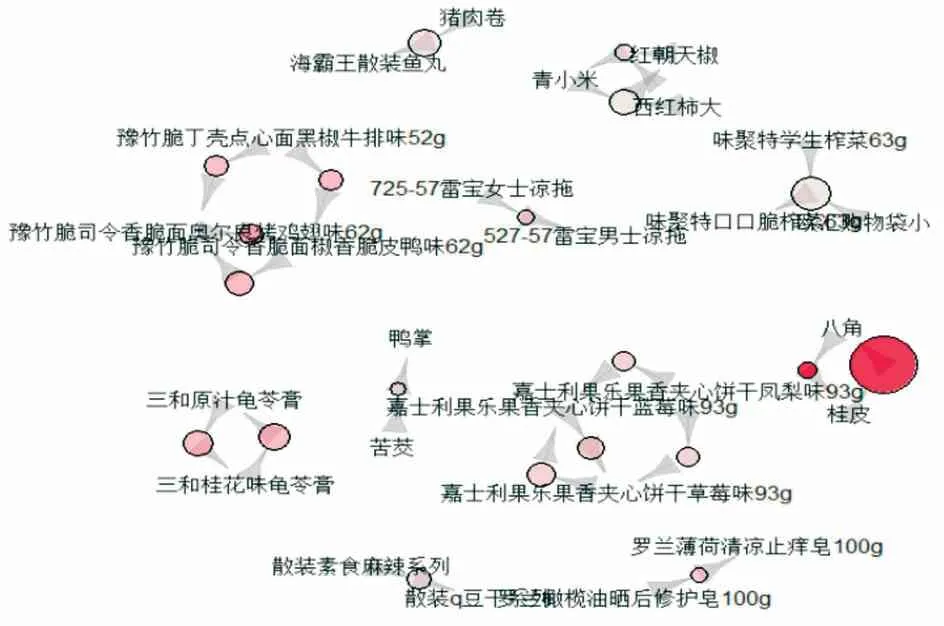
图6 20条规则可视化
1. 购买频率最高的商品是果蔬类商品,黄瓜、油麦菜、西红柿、青椒、四季豆这几种商品购买量较多; 共计15个商品发生退货,退款金额最多的商品为折价水果和蒙牛特仑苏低脂牛奶; 购买金额最高商品为5条玉溪软条香烟,共计1 040元.
2. 果蔬类商品. 顾客更倾向于小葱和香菜、生姜和大蒜搭配购买; 西红柿、青椒、油麦菜、黄瓜这四种蔬菜,顾客在购买其中任意两种蔬菜后往往会继续挑选另外一种蔬菜进行购买; 黄瓜和香菇的提升度较好,香菇和黄瓜搭配购买可能性大; 青小米、红朝天椒和西红柿往往被一起购买; 桂皮和八角提升度非常高,顾客倾向于两种商品搭配购买; 两种榨菜的提升度最高,购买了味聚特学生榨菜的顾客还会买味聚特口口脆榨菜.
3. 零食类商品. 豫竹脆司令香脆面(奥尔良烤鸡翅味62 g)、豫竹脆司令香脆面(椒香脆皮鸭味62 g)、豫竹脆丁壳点心面(黑椒牛排味52 g)这三种干脆面顾客通常一起购买; 购买了散装素食麻辣系列的顾客还会去购买散装q豆干系列; 嘉士利果乐果香夹心饼干凤梨味、蓝莓味、草莓味这三种口味的商品被一起购买可能性大.
4. 肉食类商品. 苦茭和鸭掌这两种商品被一起购买的可能性较大; 购买了猪肉卷的顾客会顺便购买霸王散装鱼丸.
5. 生活用品. 三和原汁龟苓膏和三和桂花味龟苓膏、雷宝女士凉鞋和雷宝男士凉鞋、罗兰薄荷清凉止痒皂和罗兰橄榄油晒后修复皂,这几种商品搭配效果好.
3.2 营销建议
1.做好商品布局优化工作. 消费者行为理论认为,消费者的购买行为会受到外界环境的影响,具有情境性. 关联规则匹配较好的商品很大程度上是因为商品所属货架摆放相对靠近,消费者在既定的常规路线上行走时实现了商品的关联购买. 因此,商超货架布局应尽可能提高货架展示水平,不断引导顾客浏览更多商品,产生新的购买行为. 新的产品所带来的关联效应又会刺激消费者的下一次购买决策,循环往复,最大程度激发顾客的消费潜力. 从实证结果来看,肋排与西红柿关联度较好,可以将肉食类商品的货架与零食类的货架交换,使蔬菜类货架与肉食类货架远离. 而且由于肉菜类商品属于生活必需品,想要购买两种商品的顾客必然会穿过零食类商品货架去购买,刺激消费者购买需求. 超市也可以交换鸭掌和苦茭的位置,使肉类和配料相对分开一些,那么需要制作美味的苦茭鸭掌汤的顾客就必须穿过肉类区和食品区,这样就可能引起消费者潜在的购物欲望.
另外,顾客能否准确定位到商品的位置取决于超市商品的陈列摆放. 销售量的多少不能决定超市的实际效益,而是由每一单位货架上商品所获得的利润所决定的,即单位货架利润. 由于高支持度的商品一般利润都比较低,尽可能把置信度较高的商品摆放在人眼能及的地方来方便顾客购买,同时也能带动邻近商品的销售量增加. 根据关联规则分析的结果来看,顾客习惯将榨菜与干脆面搭配购买,因此可以将方便面类和榨菜类日常的商品放在临近的位置,方便顾客同时购买. 国外大型商超如“Costco”也经常利用关联规则进行货架布局. Costco的奶制品、卫生巾、尿不湿、纸巾、宠物用品是放在一个区间里的,在熟食区的旁边. 妈妈们采购完熟食后,顺便可以囤些尿不湿、纸巾、卫生巾,或者给宠物购置商品. 另外,超市应该将日常需求较大的商品放在货架两侧,给顾客带来便利的同时,能够节省时间让顾客有余力浏览货架上的其他商品,实现更多的购买.
如何对有销量差异的商品进行布局,以及精准预估顾客的耐心至关重要. 远距离货架的设计在一定程度上增加了顾客的负担,使顾客不能很快速地获取所需的商品. 但是通过动线设计吸引顾客在店内来回走动,提高回游性,使顾客在超市走动的时间延长,帮助超市赢得更多的利润. 另外,最大置信度和最小支持度相差越小,生成的竞争商品组数越多. 如果两种商品的置信度都比较低,说明这两种商品被同时购买的可能性不大,那么可以分开摆放. 支持度、置信度较小的商品通过有意识地改变货架陈列布局,在经常性消费的产品之中嵌入消费者忽略的新产品,打破消费者的购买习惯,使消费者发现没有注意到的商品,吸引消费者购买.
2.采取捆绑销售策略. 捆绑销售(bundling)被定义为将两种或两种以上不同产品或者服务进行组合,并以一个特定价格进行销售的销售策略[8]. 捆绑销售作为一种重要的销售策略,是学者们研究的热点. 大数据研究发现,关联产品捆绑是消费者接受度最高的,对商品及品牌的信任度和满意度影响显著. 相对于同产品和同类产品捆绑,相关产品捆绑更加能满足消费者需求,关联规则是研究捆绑销售策略的有效手段[9].
基于消费者的关联购买意愿进行捆绑销售分析,从超市果蔬销售情况来看,果蔬类生活必需品销售量很大,不同季节下顾客对商品的组合购买是不同的. 夏季,顾客倾向于同时购买西红柿、青椒、油麦菜、黄瓜这四种蔬菜. 而一些蔬菜属于百搭品种,如小葱和香菜、生姜和大蒜,商家可以进行捆绑销售,为顾客提供便利的同时,实现组合销售获得的利润最大化. 鸭掌和苦茭这两种商品的关联度较高,夏季顾客对于苦茭鸭掌汤的需求旺盛,可以提供制成品来满足顾客需求,提高顾客满意度. 如果捆绑销售的产品互补性低,商超要相应地提高产品的价格折扣,提高顾客忠诚度.
3.搞好竞争商品的关联促销活动. 对于大型商超来说,在数以万计的商品中找到竞争性的商品,单纯依靠经验分析是不够的,必须依靠数据的支持. 通过关联规则分析,可以找到有潜在竞争关系的商品,辅助商超的管理人员制定相应的营销策略. 例如,罗兰薄荷清凉止痒皂与橄榄油晒后修护皂为竞争商品,其中一个商品与毛巾购买后便不会购买另一种商品. 如果罗兰薄荷清凉止痒皂厂商想通过促销活动来吸引购买橄榄油晒后修护皂的消费者, 经营者可以对每个橄榄油晒后修护皂的顾客进行推广. 但是另外一种更高明的手段是只做一个类型群体的推广,这个购买人群的购买行为和购买橄榄油晒后修护皂的顾客相近, 卖家可以优先向同时购买毛巾和罗兰薄荷清凉止痒皂的顾客进行针对性推广,让消费者接受新的商品. 同样地, 当罗兰薄荷清凉止痒皂供不应求时, 商超可以利用橄榄油晒后修护皂来代替原来的商品, 充分满足顾客的需求.
3.3 不足与展望
尽管通过本次的实证分析得出一些结论,但是在本次研究中仍然存在不足的地方. 首先,为了保证所研究数据的准确性,努力寻找本地超市的一些销售数据. 但受限于隐私等客观条件,数据量较少,无法进行季节性比较分析和商品利润的分析,对数据准备存在不足之处. 其次,由于现有的关联规则挖掘算法倾向于找出关联度高的频繁项目集,所以经常忽视支持度较低的项目集. 本文对低支持度的项目集进行了规则挖掘,希望未来可以进一步深入挖掘频繁项集与非频繁项集之间的关联. 虽然尽可能全面地进行数据提取,但论文只针对购物篮商品进行分析,没有对销量、金额、时间等进行分析,无法准确地掌握商品畅销程度,以及在不同时间、不同地域的销售区别.
未来的研究可以从以下几个方面着手:首先,提高数据量,增加不同的时间段和地域的数据,提高数据分析结果的有效性和可行性; 其次,引入利润率作为重要的评价关联规则好坏的指标,量化关联规则可以给商超带来的经济效益; 再次, 未来研究可以引入顾客会员身份信息,针对不同类型的顾客提供多样化的服务,进一步提高关联规则的利用率.
