基于多分类器DS证据理论融合的水果识别研究*
2021-03-30蔡浩郭宏亮
蔡浩,郭宏亮
(吉林农业大学信息技术学院,长春市,130118)
0 引言
我国是水果产量大国,生产的水果种类繁多,生产总量占全世界的18%左右[1]。传统的水果分类是通过人工方式进行的,这种方式不仅效率低,而且消耗大量劳动力资源[2]。随着图像处理和机器视觉技术的发展,国内外很多学者提出利用农产品的各类特征对农产品进行识别。赵玲等[3]通过提取草莓图像在HIS颜色空间模型下的H分量的均值和方差,并结合草莓红色着色面积比,使用BP神经网络识别草莓的成熟等级,识别准确率达到90%。但是使用图像的单特征并不能充分的描述图像信息,识别结果会产生一定的误差。Biswas等[4]在提取蔬菜颜色、形状、纹理等特征的基础上建立分类器实现蔬菜的自动分类,试验表明该方法取得了较高的分类精度。陶华伟等[5]提出了一种利用颜色完全局部二值模式提取的图像纹理特征并结合图像颜色特征,采用匹配得分融合算法将图像颜色和纹理特征融合,使用最近邻分类器实现果蔬农产品的分类,该方法能够实现对果蔬农产品的精确识别。Arivazhagan等[6]将HSV颜色空间中的H、S统计直方图作为颜色特征,将小波域中的自相关矩阵作为纹理特征进行果蔬识别。陈雪鑫等[7]提出了一种基于多颜色特征和纹理特征的水果识别算法,该方法对水果图像的识别率可达90%以上。但是以上方法都采用了单个分类器对水果种类进行识别,这将导致识别不均衡问题,造成识别的正确率降低。而融合多个分类器的识别结果,将多个分类器进行融合得到的最终识别结果,不仅可以提高识别准确率,同时有效的结合了各个分类器的优势,解决各分类器的识别不均衡问题。
本文提出了一种结合多种分类器,利用DS证据理论对多种分类器进行融合的水果识别方法,均衡有效地实现了对水果种类的识别。相对于单分类器的识别,在识别准确率和稳定性上有明显提高。
1 试验材料
本文选取了香蕉、苹果、桃子、草莓、梨5种水果图像为研究对象,数据来源于kaggle上的fruits360数据集,在fruits360的训练集上每类水果选取了30幅,共150幅作为训练集。在fruits360的测试集上每类水果选取了50幅,共250幅用来测试准确率。又在fruits360的测试集上选取了10组测试集图像,每组20幅,共200幅用来测试稳定性。本试验5种水果的测试集和训练集共600幅样本,部分样本集如图1所示。

(a) 桃子

(b) 香蕉

(c) 杏子

(d) 苹果

(e) 荔枝
2 图像处理与特征提取
2.1 图像预处理
图像在采集的过程中,会受环境及采集设备的影响,而产生噪声。噪声会降低信噪比,对后期图像特征的提取造成影响。中值滤波[8]是一种简单的去噪方法,能够在有效去除噪声的同时保留图像的细节,突出边缘信息。
经过多次试验后发现,图像选用在3×3中值滤波模板上处理的图像效果最好。通过预处理后的图像结果如图2所示。

(a) 灰度化后的图像

(b) 中值滤波后的图像
2.2 特征提取
2.2.1 颜色特征提取
不同的水果种类的外观变化明显[9],水果图像的颜色特征能很好的反映出水果的种类,是对水果种类进行区分的重要特征之一。表达颜色特征的特征参数有很多,不同的特征参数适用于不同的领域。而特征参数的描述需要基于对应的颜色空间模型,常用的颜色空间模型包括RGB模型、HIS模型、HSB模型等。相比于RGB模型,HIS模型更符合人眼的感知习惯,对光照影响的抗干扰性强,而且HIS模型比RGB模型的维度更低,所以表明HIS模型要优于RGB模型。所以本文选用在HIS模型下对水果图像的颜色特征进行提取。
颜色矩[10]是一种常见的颜色特征表达方法,而且图像的颜色特征信息主要分布在其低阶矩,所以本文采用在HIS模型下提取的各个通道的一阶矩(均值,mean)、二阶矩(方差,variance)、三阶矩(斜度,skewness),共9个参数作为水果图像的颜色特征参数。三个颜色矩的数学公式[11]如式(1)所示。
(1)
式中:pi,j——彩色图像第j个像素的第i个颜色分量;
N——图像中的像素个数。
2.2.2 纹理特征提取
纹理特征[12]是对图像空间分布特征和图像区域内像素变化的一种描述,其中包含了大量的像素空间分布信息。灰度共生矩阵是[13]一种常见的纹理特征统计方法,是对区域内像素灰度级空间相关性的一种描述。本文选用灰度共生矩阵上的能量、熵、相关性、对比度这4个参数作为图像在纹理特征上的特征参数。其计算公式参考文献[14]。
2.2.3 形状特征提取
图像的形状特征能够很好地描述图像的轮廓信息以及区域信息[15]。本文采用轮廓信息作为图像的形状特征参数。首先将原图转换成灰度图像,再选择合适的灰度阈值将图像转化成二值图像,最后通过边缘提取算法提取图像的边缘。本试验采用的灰度阈值为210,采用的边缘提取方法为canny算子,提取之后的图像如图3所示。再根据所提取到的图像轮廓计算轮廓的圆形度S1、矩形度S2、伸长度S3、形状复杂度S4这4个参数作为图像的形状特征参数[16]。其计算公式如式(2)~式(5)所示。
S1=4πA/P2
(2)
S2=A/(H×W)
(3)
S3=P2/A
(4)
S4=H/W
(5)
式中:A——轮廓区域内面积;
P——周长;
H——与轮廓区域具有相同标准的二阶中心矩的椭圆长轴长度;
W——与轮廓区域具有相同标准的二阶中心矩的椭圆短轴长度。

(a) 二值化后的图像

(b) 边缘提取后的图像
3 基于多分类器DS融合
3.1 DS证据理论
证据理论[17]是由Dempster在1967年提出,而后由他的学生Shafer完善的一种处理不确定性问题的理论。DS证据理论是一种解决多种数据融合的方法,被广泛的应用于决策融合和信息融合上。DS证据理论主要包括识别框架,基本概率分配函数、信任函数、似然函数等。
DS证据理论中的识别框架是不确定性问题的所有可能性的集合,常用Θ来表示。识别框架内的元素之间互斥。它的幂集是2Θ,表示所有可能的问题组合,但本文的识别结果具有原子性和唯一性。所以本文中所有可能的结果只有5种,并不讨论幂集的情况。
DS证据理论针对识别框架中的每一种可能的结果都分配了概率,称为基本概率分配(BPA,Basic Probability Assignment)或者称之为基本置信分配(BBA,Basic Belief Assignment)。一般将基本概率分配函数称为mass函数,常用m来表示此函数。mass函数在识别框架的幂集2Θ满足式(6)。

(6)
式中:U——幂集上的任意一个子集;
m(U)——U的基本概率分配函数。
DS证据理论中对命题多个证据的融合规则称为DS证据理论的融合,Dempster合成法则,也称证据合成公式是DS证据理论的核心,基于这一法则,多个独立证据m1,m2,m3的合成结果为公式(7)。

(7)
式中:m——基本概率分配函数;
K——多个独立证据m1,m2,m3的冲突程度。
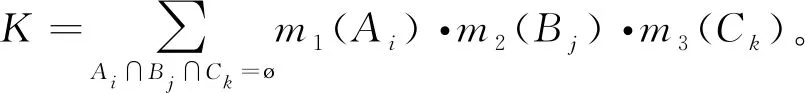
3.2 构建BPA函数
DS证据理论融合的前提是获取BPA函数,即mass函数,它表示的是证据对每种可能产生的结果的支持度[18]。本文中指的是BP神经网络模型、K均值分类模型、SVM分类模型对5种水果分类结果的支持度。
本文首先对训练集上的三种特征参数进行训练确定这三种分类模型,然后利用这三种分类模型对样本集进行测试,求得三种分类器对5种水果的识别准确率,并结合被测样本的识别结果,通过全概率公式进行融合得到各分类器对5种水果识别结果的支持度,通过归一化后可得到BPA函数。
利用构建的BPA对水果种类识别的算法流程如图4所示。
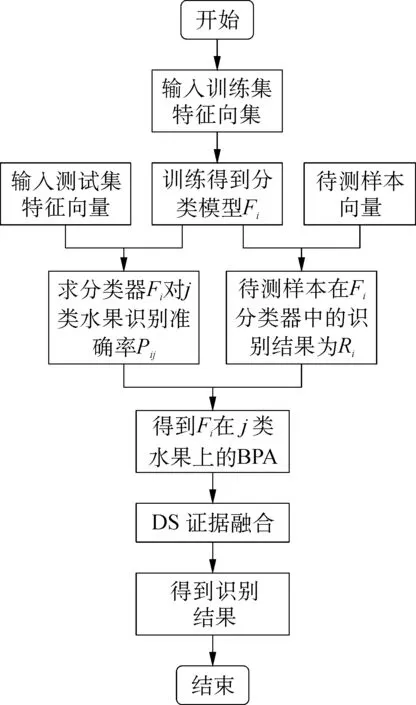
图4 算法流程图Fig. 4 Algorithm flow chart
主要有以下几个步骤。
第一,设Fi(i=1,2,3)分别表示BP神经网络分类模型、K均值分类模型、SVM分类模型。将j(j=1,2,3,4,5)类水果图像样本集特征向量分别输入到这三种分类器中,求得i类分类器对j类水果的识别准确率为Pi j。
第二,引入被测水果图像,在三种分类器上分别进行识别,得到的识别结果为Ri(Ri=1或Ri=0),当Ri=1时,表示识别结果是j类水果,Ri=0时,表示识别结果不是j类水果。然后通过全概率理论公式可以初步得到i类分类器对j类水果识别结果的支持度,具体公式如式(8)所示。
mi j=Pi j×Ri+(1-Pi j)×(1-Ri)
(8)
式中:P——识别准确率;
R——识别结果。
第三,根据BPA在识别框架幂集上的三种分类器模型的信度之和等于1的特点,可以将式(8)归一化,归一化后的公式可以表示为式(9)。
(9)
根据式(9)可以得到各种分类器对每种水果的信度值。通过DS整理理论融合规则和信度规则得到被测图像的识别结果。
3.3 DS证据合成和决策级融合
利用BP神经网络分类模型、K均值分类模型和SVM分类模型在5种水果上的BPA函数,对水果种类进行识别主要分为两个步骤。
第一,将各水果上三种分类器的BPA函数,通过DS融合规则进行融合,得到各水果分类识别结果的联合信度。
第二,根据信度规则来对水果种类实现最终的识别。
设最终识别的水果种类的联合信度为l,则l应满足以下信度规则。
1)l为5种水果联合信度值的最大值。
2)l的值必须大于阈值x。
3)l与其他4种水果的联合信度的差值总大于阈值y。
4) 若以上条件均不满足,则输出识别结果为“不确定水果类型”。
本文经过多次试验,将x和y的值确定为0.83和0.52。
4 试验与结果分析
4.1 融合多分类器水果识别试验
为了验证本文提出的模型算法对5种水果种类识别的有效性,针对上述算法在MATLAB上进行了仿真试验验证。本试验以DS融合系统为主模块,三种分类模型系统为子模块,最终实现对被测图像的识别。该试验的系统流程结构如图5所示。
试验主要分为以下几个步骤。
1) 首先,对采集到的水果图像进行预处理和特征提取。
2) 利用训练集特征集,得到BP神经网络分类模型、K均值分类模型、SVM分类模型的模型参数,构建三种分类器模型。
3) 根据这三种分类器模型,对样本集进行测试,得到各个分类器对各类水果分类的识别准确率。
4) 分别使用这三种分类模型对被测图像进行识别,根据式(7)将识别结果和各分类器的平均识别准确率进行融合,得到各分类器对不同水果的基本概率密度函数(BPA),即信任度。
5) 在DS融合系统中进行多分类器在各水果上的信度融合,得到待测图像为j类水果的联合信度。
6) 最后根据信度规则,对待测图像进行识别。
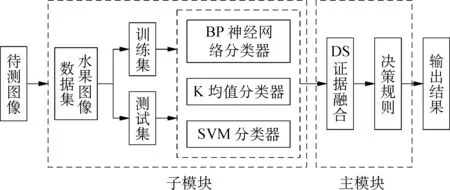
图5 系统流程结构图Fig. 5 System flow structure diagram
4.2 试验结果与分析
本文将采集到的5种水果图像集,按照图5的流程进行试验,本文使用5种水果图像的测试集进行了模型测试。
试验的测试结果如表1所示,试验对比了BP神经网络分类模型、K均值分类模型、SVM分类模型和多分类器融合模型在测试集上的识别准确率和各分类器在各水果种类识别上的总体标准偏差。
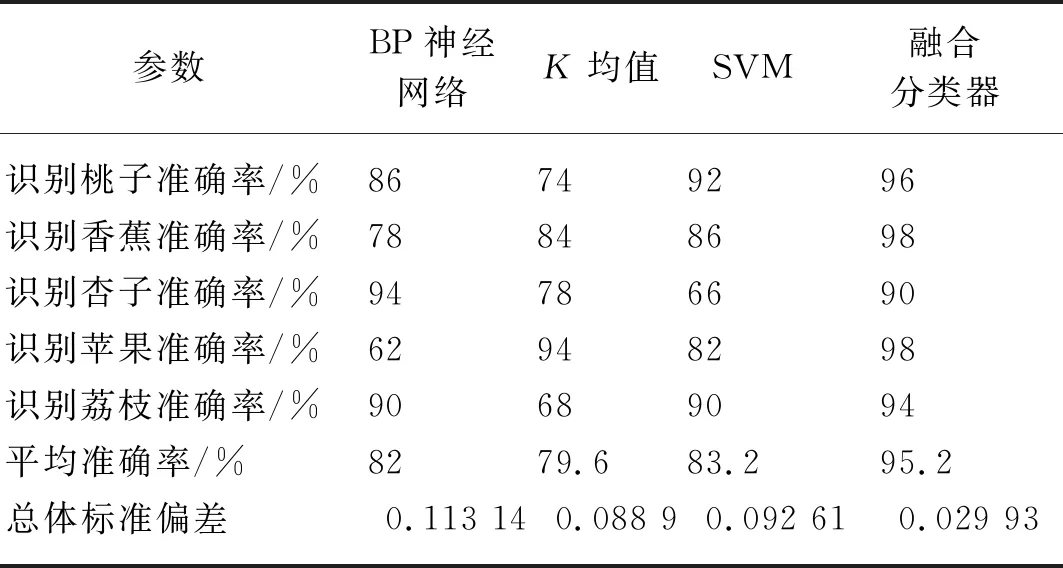
表1 测试样本集识别结果Tab. 1 Test sample set recognition results
从表1中可以看出,利用BP神经网络、K均值、SVM分类模型对5种水果识别的平均准确率为82%,79.6%,83.2%,总体标准偏差为0.113 14,0.088 9,0.092 61。融合多分类器识别模型对5种水果识别的平均准确率为95.2%,总体标准偏差为0.029 93。
结果表明,通过DS证据理论融合多分类器的识别模型对5种水果识别的平均准确率比只使用单分类器模型的平均识别准确率高。而且多分类器融合后的识别模型在对不同水果的识别上比各单分类器更均衡。
本文又在fruits360的测试集上随机的选取了10组测试集图像,每组20幅共200幅作为测试集,在各测试集上利用各单分类器和融合分类器进行测试,测试结果如表2所示。

表2 在10组测试样本集上的识别结果Tab. 2 Recognition results on 10 test sample sets
结果表明,在10组测试集上各单分类器识别结果的平均准确率为76%,70%,71.5%,总体标准偏差为0.106 77,0.116 19,0.089 58,融合分类器识别结果的平均准确率和总体标准偏差为93.5%和0.055。融合分类器对水果识别的准确率和稳定性更好。
5 结论
1) 水果识别是现代农业研究领域的热点和难点,构建合适的识别方法是进行水果识别的关键步骤。传统的水果识别算法主要是基于单分类器的,不同分类器对不同水果的识别效果不同,会造成识别结果不均衡。本文基于BP神经网络、K均值、SVM分类模型,利用DS证据理论对三种分类器进行融合,构建各分类器对不同水果的BPA函数,最后根据DS融合规则得到联合信度,最后根据信度规则得到识别结果。结果表明,融合分类器对每种水果的识别准确率分别为96%,98%,90%,98%,94%,5种水果准确率的总体标准偏差为0.029 93,低于各单分类器的总体标准偏差,且平均识别准确率为95.2%,高于各单分类器的平均识别准确率,融合多分类器识别模型能够在提高识别准确率的同时有效的解决各个单分类器对不同水果的识别不均衡问题。
2) 本试验又采集了10组水果种类均衡的测试集,通过DS证据理论融合多分类器得到的模型,对10组测试集进行测试,结果表明,融合多分类器在10组测试集上的平均识别准确率和总体标准偏差为93.5%和0.055,而各个单分类器在10组测试集上识别准确率的识别准确率和总体标准偏差分别为76%、70%、71.5%和0.106 77、0.116 19、0.089 58,进一步验证了融合多分类器在提高对水果种类识别准确率的同时,也提高了识别准确率的整体稳定性。
