电子阅读对阅读素养影响的实证研究
2021-03-30李文烨姚继军
李文烨 姚继军
(南京师范大学 教育科学学院,江苏南京 210024)
一、引 言
全国国民阅读调查报告显示,我国青少年图书阅读率增势明显。2017年,我国14-17岁青少年的图书阅读率已超过90% (中国新闻出版研究院全国国民阅读调查课题组,2018)。同时,国民阅读方式也发生了明显变化。2019年,我国国民电子阅读的接触率高达79.3%,以手机、平板、电子书等为主要阅读介质的电子阅读正成为越来越重要的阅读方式 (中国全民阅读网,2019)。阅读方式虽然发生了转变,但这种转变是否会对阅读效果产生影响,既有研究并未给出一致结论。电子阅读的支持者认为,电子介质具有轻便、容量大、呈现形式多样、不受时空限制等优势,会给阅读者带来更好的阅读体验;反对者认为,电子介质往往会带来阅读碎片化、不够深入、容易受干扰、上瘾、损伤视力等问题,不宜在中小学推广电子阅读(何明星,2005;董朝峰,2011;张冰等,2013;袁征等,2016)。然而,目前人们关于电子阅读的争论,大多基于经验而非科学证据,少量实证研究在数据的权威性、代表性及结论的稳健性方面,仍有较大改进空间。各级教育行政管理部门及学校管理者,在制定相关政策举措时也面临科学依据不足的状况。因此,分析电子阅读之于学生阅读素养的影响,便有着重要的理论和实践价值。
二、文献综述
到目前为止,“读屏”与“读书”孰优孰劣,相关实证研究尚未得到一致结论。一方面,许多研究者发现纸质文本的阅读效果更佳,阅读纸质书的读者在信息保持量上显著高于电子书阅读者(李寿欣等,2009),阅读效能感也更好(秦超等,2011)。李晓娟(2015)还发现,在阅读电子书时,读者使用阅读策略的频率会显著低于阅读纸质书。但另一方面,也有研究发现,阅读纸质文本和电子文本后,小学生、高职生和大学生的答题正确率都不存在显著差异;在简单信息处理上,两者之间也不存在差异(袁曦临等,2015;赵蓉等,2019),电子读本甚至能更好地帮助婴幼儿理解故事角色(张雪,2019)。近期的元分析结果表明,虽然电子阅读的总效应量为负,但在认知层面,电子阅读对表层理解、语义理解、推论理解都有明显的促进作用(蒋红,2017)。
很多研究者运用媒介材质理论和认知地图理论,解释电子阅读与纸质阅读效果的差异。前者的核心概念是认知负荷,即阅读一定的文本内容需要消耗认知负荷,不同的文本呈现方式使读者消耗不同的认知负荷,从而造成阅读效率等的差异(Hou et al., 2017)。认知地图理论把读者对文本的阅读类比为空间探索,读者阅读文本需要一定的背景信息,哪种媒介材质能够提供辅助阅读的背景信息越多,阅读效率就越高(Yi et al., 2013)。两种理论均认为不同阅读介质会导致不同的阅读行为及效果。但都没有充分考虑其他因素,尤其是学生个体层面的差异,也难以解释为何介质不同的情况下,结果会无显著差异。
相关研究表明,经济状况好的家庭能够从小给孩子营造更好的环境,促进其学业或认知能力的提升(姚昊等,2018);阅读时长、阅读兴趣和习惯等也影响阅读效果 (温红博等,2016)。既有研究还发现,元认知策略在语言学习过程中扮演着重要角色。正因如此,PISA等大规模国际学业评估项目已将其纳入测量指标,用以评估包括电子阅读在内的学习行为(肖武云等,2011;陆璟,2012;OECD,2016)。然而,国内有关电子阅读的研究较少考虑这些因素,相关研究结果的稳健性和全面性有待提高。
综上,学生的阅读效果或阅读能力,除了受阅读方式的影响,还受其他诸多因素影响。这意味着要精确评估电子阅读影响的大小,需要有效控制相关混淆变量,找寻更为扎实的证据。既有研究大多将学生的阅读测验成绩作为因变量,较少使用经过权威测试得到的学生阅读素养数据;部分研究虽分析了电子阅读的影响,但大多未控制样本选择偏误。在研究对象方面,多数研究以高校学生或成年人为对象,以中小学生为样本的研究较少。少部分涉及中小学生的研究,样本大多来自班级和学校内部的调查数据,代表性有限。此外,少有实证研究讨论样本的“异质性”问题,这使得只能基于研究结论给出“粗线条”的对策,难以针对不同对象的问题给出针对性建议。
基于此,本研究选择PISA2018学生数据开展研究。在PISA测试中,阅读首先被认为是渐进的认知过程,阅读素养是对文本的检索、理解、定位与评鉴能力。同时,阅读不仅包括对单一的某段文字的阅读,也涉及对多个文本的阅读,因此,阅读素养又被定义为对单一或多重文本阅读能力(OECD,2016)。使用这种数据,可有效保障研究数据的科学性和权威性。与此同时,本研究对样本的选择偏误进行控制,采用泛精确匹配等方法提高分析的精度。研究问题包括:
1)电子阅读是否会影响学生的阅读素养?
2)电子阅读产生的影响是否有一定的异质性?
3)电子阅读影响学生阅读素养的机制是什么?
三、研究方法
本研究以学生阅读素养得分为被解释变量,以学生是否进行电子阅读为核心解释变量,以学生个体层面的背景变量以及可能影响学生电子阅读的因素为控制变量,构建回归模型,并采用STATA13.0软件分析PISA2018学生数据。具体分析过程包括:先采用最小二乘法回归计算电子阅读的影响,随后采用泛精确匹配(Coarsened Exact Matching)控制样本选择偏误带来的影响以提高分析精度,并使用分位数回归检验样本的异质性,最后构建中介模型分析变量间的影响机制和路径。
(一) 数据来源与样本说明
PISA是经济合作与发展组织每三年开展一次的大规模学生评估项目,该项目采用分层抽样方法,先选择被试学校,然后按照等比例从被试学校随机选择参测学生。2018年我国共有来自北京市、上海市、江苏省、浙江省的12508名学生填写了PISA问卷并参与了素养测评,其中男生占52.2%,女生占47.8%。与其他评估不同,PISA侧重于测评学生素养,阅读素养测评题目最大程度地考虑“情境”的真实性,让学生基于特定情境完成更高层次的阅读任务(王晓诚,2019)。在最新的PISA2018中,我国参测学生阅读素养平均得分位列第一(李刚等,2020)。
(二) 变量选取与说明
为了探究电子阅读对学生阅读素养的影响,本研究参考既有文献,将阅读时间、能力、兴趣作为控制变量纳入分析模型。考虑到既往研究还发现家庭经济文化状况与学生发展高度相关,本研究选择父母职业、受教育年限、家庭经济文化指数以及纸质书和电子阅读设备数量作为家庭背景变量。2018年PISA测评内容的重大改变在于阅读策略体系的构建(兰丹等,2017),元认知策略被首次纳入指标体系。因此,本研究将元认知策略变量也纳入分析,以更精准地计算电子阅读带来的影响(见表一)。
1.被解释变量
回归模型中,被解释变量为学生的阅读素养得分,PISA根据学生阅读题目得分,基于项目反应理论(Item Response Theory, IRT)生成10个拟真值(Plausible Value, PV)供研究者使用。除了阅读总素养得分,PISA将阅读素养根据认知过程细分为信息检索、信息理解以及信息评鉴与反思,根据文本结构细分为单一文本和多重文本,并得出五个子维度的得分。本研究在选取阅读素养总得分的同时,将其五个子维度的得分也纳入分析。需要说明的是,PISA技术手册建议不能简单取10个拟真值的均值作为学生的总素养,因此,本研究将PV1作为因变量。有研究发现,PV1的信息载荷较大,用其进行回归与用10个拟真值进行回归得到的结果,不存在明显差异(Jerrim et al., 2017)。考虑到分析的简洁性以及匹配的方便性,本研究仅将各维度的PV1纳入模型分析。
2.核心解释变量
PISA询问了学生日常阅读方式,对于“下列哪一项陈述最能描述你阅读书籍的情况”这一问题,学生可以选择“几乎不阅读”“以纸质书为主”“以电子阅读为主”或“两者差不多”。选择“以纸质书为主”和“以电子阅读为主”的学生分别占35.7%和34.7%。本研究的电子阅读指在手机、平板、电脑、电子书等电子产品上开展阅读。
3.控制变量
除去人口学变量,PISA基于学生报告的家庭拥有物数量、父母受教育年限、父母职业声望①等计算得出家庭经济文化指数,并通过主成分法将其合称为家庭经济社会文化指数(ESCS)。该指数越高,说明家庭经济文化状况越好。最新的PISA报告显示,我国的家庭经济文化指数平均得分为-0.67,低于经济合作与发展组织的均值(教育部基础教育质量检测中心,2019)。
参考既往研究,我们还在模型中纳入与学生阅读素养有较高关联的学生阅读状况,包括学生阅读能力、阅读兴趣和阅读时间三个变量(宋凤宁,2000;张文静等,2012;张生等2014;温红博等,2016)。相关数据来源于PISA学生问卷。其中,阅读时间为学生报告的每周阅读时间;阅读能力和阅读兴趣的得分根据学生填写的选项生成。以学生的阅读能力为例,PISA通过调查问卷要求学生报告对自身阅读能力的感知,题项包括 “能否流畅阅读” “能否了解文章深奥的内容”“是否有阅读困难”等六道题,然后以经济合作与发展组织的均值为0,标准差为1,计算各选项的标准分,再采用主成分法生成该维度得分。
学生的阅读元认知策略也是本研究的控制变量。PISA共设置了16道题测量学生的阅读元认知策略,涉及理解与记忆策略、信息概述策略、信息评鉴策略三类指标。以理解文章信息这一任务为例,PISA设置了“集中看文中易于理解的内容”“快速阅读全文两遍”“阅读后,与其他人讨论内容”“在文中的重要内容处画线标记”“用自己的语言总结文中内容”“向他人大声朗读”六类阅读策略,学生给这些策略赋分(1-6分),分值越高说明学生认为该方法越重要。
(三) 数据处理
为了选择对照组和处理组,本研究以对问题ST168(下列哪一项陈述最能描述你阅读书籍的情况?)的回答为分类依据,将以纸质阅读为主的学生划分为对照组,以电子阅读为主的学生划分为处理组,选择其他选项或存在缺失的样本不纳入分析,最终样本量为7952。其中,纸质阅读组样本量为3885,电子阅读组样本量为4067(见表二)。样本的总阅读素养得分为558.01分,得分最高的子维度为阅读信息评鉴与反思,最低的是单一文本阅读,这与既往研究结论(陈纯槿,2020)类似,说明抽取的观测样本的阅读素养特征表现和原样本基本保持一致。此外,在阅读元认知策略方面,我国学生的阅读理解与记忆、阅读信息评鉴均高于经济合作与发展组织均值,但阅读信息概述得分较低,说明我国学生基本掌握了阅读理解、记忆以及信息评鉴的技巧,但在信息概述上还存在不足。
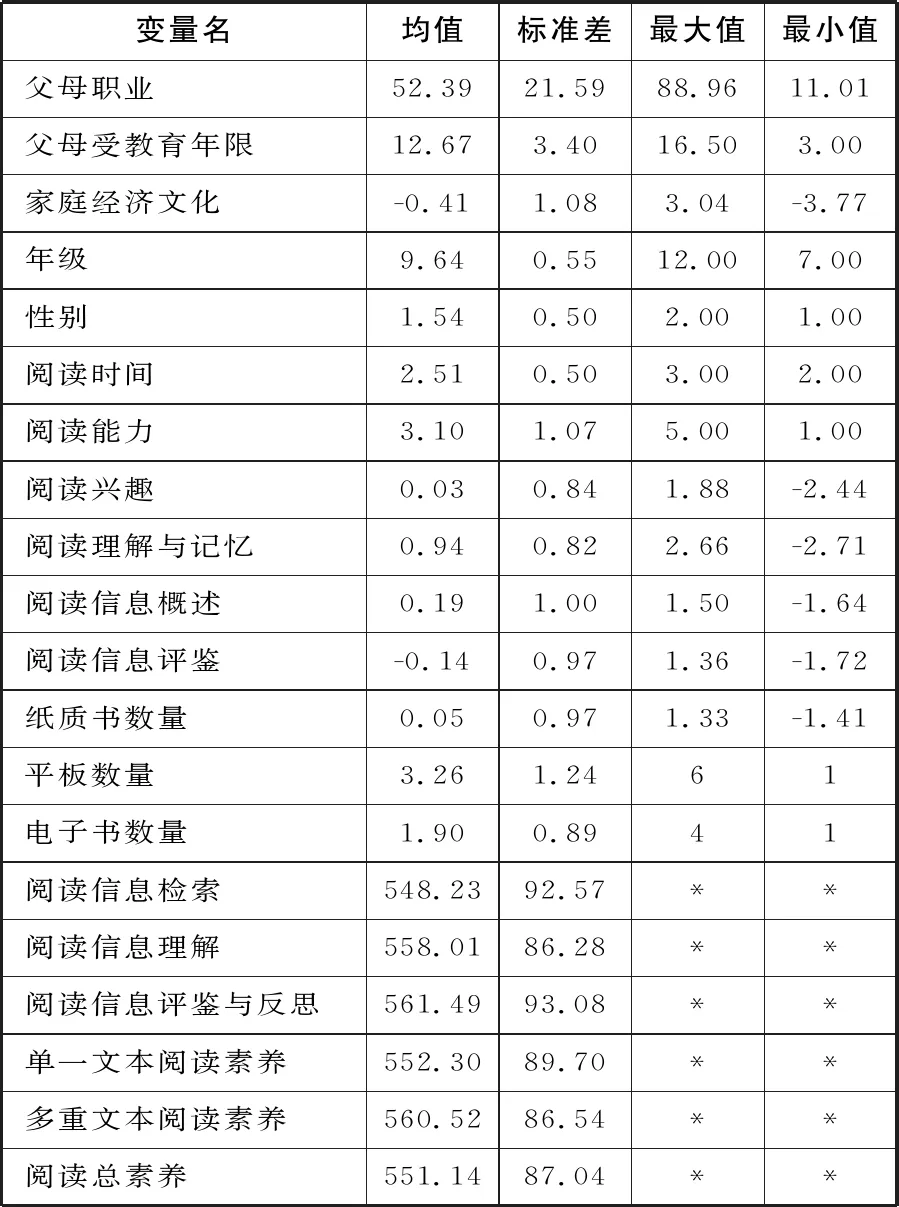
表二 变量描述统计②
(四) 模型选择
为了尽可能地控制样本选择偏误以得到更为精确的回归系数,本研究在最小二乘法回归的基础上,采取泛精确匹配技术对样本进行匹配,并运用分位数回归计算不同分位数上的学生受到电子阅读的影响,最后构建结构方程探讨影响机制。
1.泛精确匹配技术
泛精确匹配(Coarsen Exact Matching,CEM),又叫广义精确匹配,主要用于处理样本选择偏误问题。以本研究为例,影响学生电子阅读的特征变量同样也可能影响学生的阅读素养。为更精确地评估电子阅读对阅读素养的影响,“匹配”方法可排除混淆变量的干扰。与常见的倾向值匹配方法(Propensity Score Matching, PSM)相比,泛精确匹配能够平衡组间样本的分布,且有更高的数据匹配率和更少的样本信息损失(Iacus et al., 2011)。该技术会对数据进行预处理,将协变量划分为不同层次,根据算法精确匹配每层的处理组样本和对照组样本,一方面使组与组之间满足了共同支持要求,另一方面也使总样本的不平衡性大大降低(陈纯槿等,2019)。研究者可以根据预先设计的变量区间,不断降低组别间的不平衡性,保留尽可能多的样本,并提高分析精度。近年来,不少实证研究采用泛精确匹配技术对样本进行匹配处理,对干预措施的效应进行精确计算(杨振宇等,2016;郑琦等,2018;张扬等,2020)。
本研究通过泛精确匹配技术输出权重(Cem_weights),并将其带入回归模型进行加权回归,从而控制选择偏误,降低组间特征变量的不平衡性。用于泛精确匹配的特征变量为父母最高职业声望、父母最高受教育年限、家庭经济文化水平、年级、性别、家庭藏书量、家庭电子阅读器数量以及家庭拥有的平板数量,具体模型见式(1),其中,Readingi为第i个学生阅读素养的得分,β0为模型的截距,EBOOKi为第i个学生电子阅读和纸质阅读的情况,Xi为学生在控制变量上的得分。β1和β2为各变量的回归系数,εi为残差。
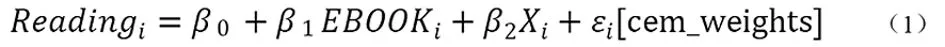
2.分位数回归
常见的回归方法虽然可以探明解释变量与被解释变量之间的关系,但回归样本通常并非均匀对称分布,得到的相关系数仅限定于刻画样本的集中趋势,且容易受到极端值的影响(陈强,2010)。鉴于此,本研究利用分位数回归模型计算电子阅读对不同阅读素养分位的学生的影响。分位数回归模型由康克和巴西特最先提出(Koenker & Bassett,1978)。该方法将因变量按照不同分位进行回归,可以帮助研究者直观了解自变量在不同因变量层次造成的影响,从而发现可能存在的异质性。本研究调查了不同阅读素养水平学生选择电子阅读受到的影响是否会有差异及呈现何种变化,构建的模型见式(2),其中,P为分位数点。本研究按照逆序的方式,分别计算不同分位因变量的系数大小,因变量分为后10%(阅读素养极低)、后25%(阅读素养较低)、后50%(阅读素养一般)、后75%(阅读素养较高)、后90%(阅读素养极高)的学生。
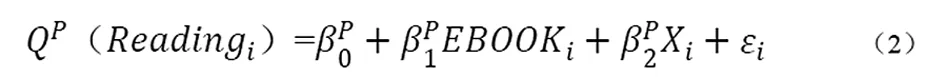
3.中介效应模型
本研究通过构建中介效应模型探究电子阅读对阅读素养的影响机制。既往研究发现,阅读元认知策略或可解释电子阅读与纸质阅读之间的差异(陈纯槿,2020)。基于此,本研究以电子阅读为自变量,以理解与记忆策略、信息概述策略、信息评鉴策略等三类阅读元认知策略为中介变量,并将学生阅读素养设置为因变量,利用AMOS23.0软件计算自变量、中介变量、因变量之间的路径系数和显著性。
四、研究结果
(一) 电子阅读造成的影响效应评估
本研究首先采用最小二乘法回归计算电子阅读产生的影响,各个变量间均不存在共线性问题,且没有严重的异方差(见表三)。阅读总素养的回归系数为-15.90,且在0.01水平显著,说明在控制其他条件的情况下,选择电子阅读的学生比选择纸质阅读的学生得分低15.90分。具体到阅读素养各子维度,信息检索、信息理解、信息评鉴三个维度的得分均能被电子阅读显著负向预测,信息评鉴素养受影响最大,回归系数为-21.80。单一文本阅读和多重文本阅读维度的得分均会被电子阅读负向预测,多重文本阅读所受影响较小,系数为-12.09。
(二) 控制选择偏误后的计算结果
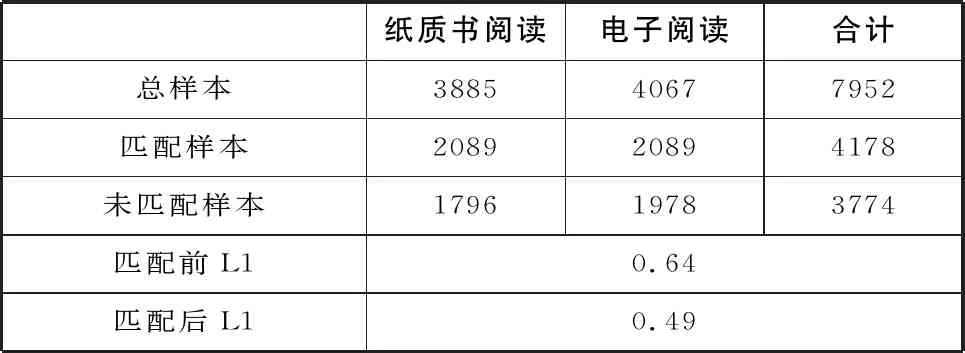
最小二乘法的回归结果可以说明电子阅读给学生的阅读素养带来了负面影响,但这一结果可能受样本选择偏误的干扰,造成有偏估计。因此,本研究利用泛精确匹配技术以避免样本选择偏误。泛精确匹配输出的L1值(Multivariate Imbalance Measure)表明了数据的不平衡程度,L1值介于0~1之间,数值越大说明数据的不平衡性越高。研究者可以根据L1值的变化判断匹配效果,L1下降越多,说明匹配效果越好(Iacus et al., 2012)。
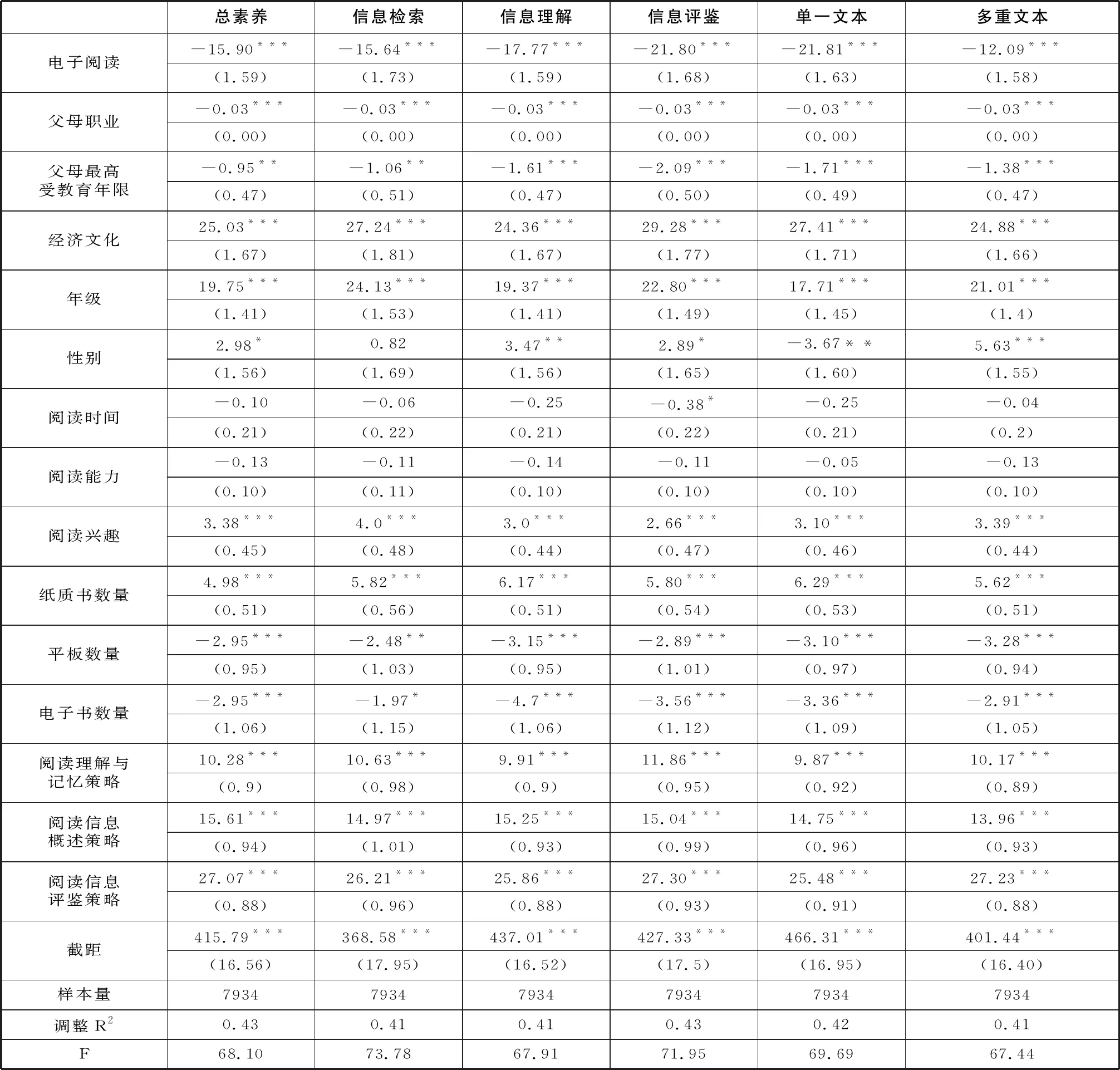
表三 最小二乘法回归结果
表四表明,泛精确匹配后保留了4178个有效样本,占原有样本的53%,L1值从0.64下降为0.49,说明本研究在获得较好匹配效果的同时,也保留了较多的样本。本研究进一步将得到的权重(Cem_weights)带入回归模型进行计算,回归结果见表五。
表四 泛精确匹配结果
表五 匹配回归结果(泛精确匹配加权)③
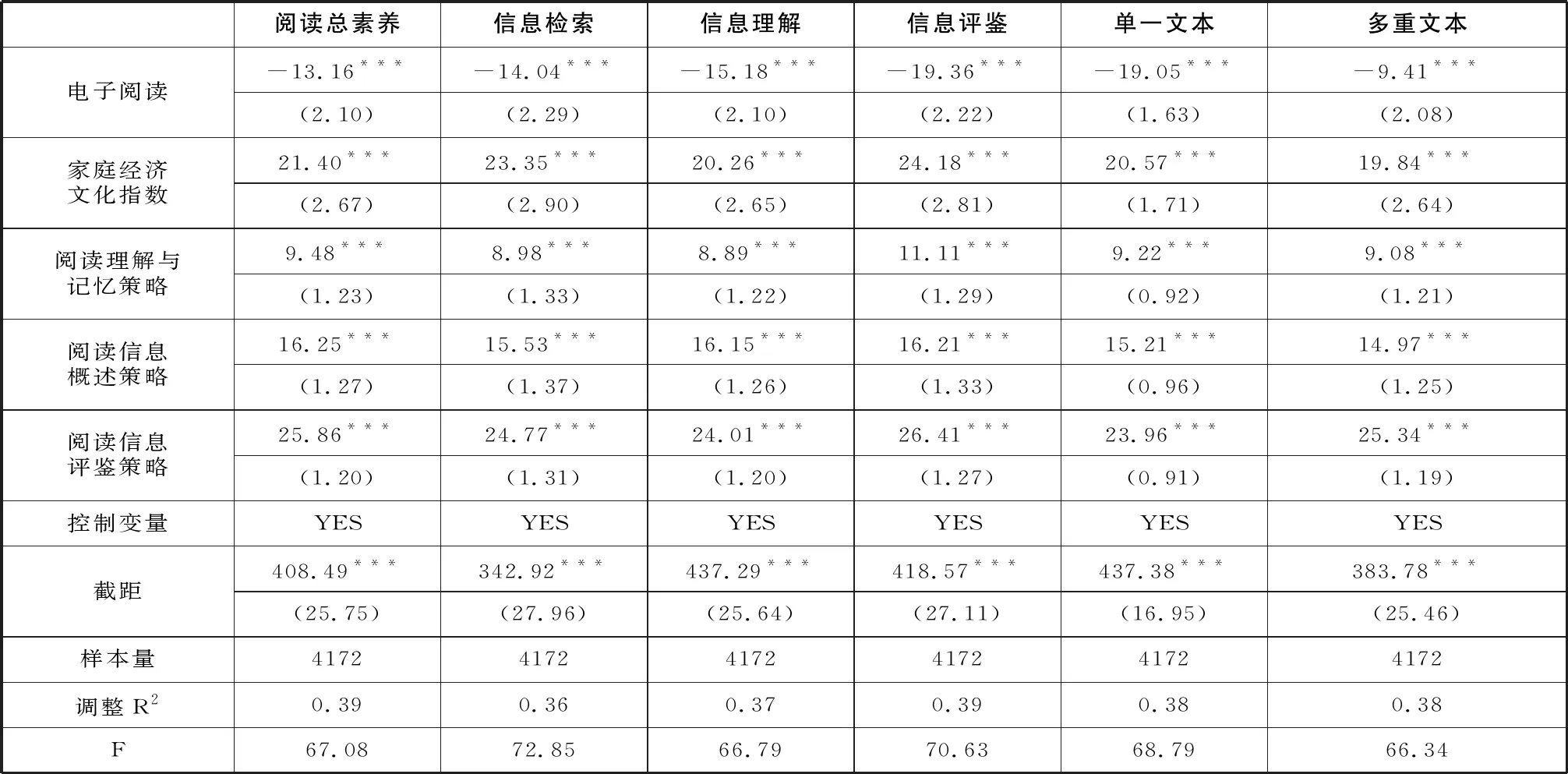
在控制了选择偏误后,电子阅读仍会负向预测学生的阅读素养。具体而言,在阅读素养总得分及各子维度上,学生选择电子阅读造成的差异均下降了2-3分,说明泛精确匹配技术很好地纠正了最小二乘法的估计误差。其中,多重文本阅读受电子阅读的影响仍最小,回归系数从原来的-12.09变为-9.41。信息检索、信息理解、信息评鉴、单一文本阅读四个维度受电子阅读的影响分别为-13.16、-14.04、-15.18、-19.36、-19.05。
控制变量中,家庭经济文化状况在各个维度均可以显著正向预测学生的阅读素养。随着年级的增长,学生的阅读素养也会提高。女生在信息检索、信息理解、信息评鉴、多重文本四个维度的得分均高于男生,但男生的单一文本阅读表现更好。在非认知层面,学生的阅读兴趣越高,各维度阅读素养得分也越高。除了单一文本阅读,阅读时间在各个维度均会负向预测学生的阅读素养。值得一提的是,阅读元认知策略对阅读素养的预测效应十分明显,三类策略的得分越高,阅读素养也越高,其中,信息评鉴策略的促进作用最明显,信息评鉴策略得分每上升一个单位,阅读素养得分将提升25.86分。
(三) 不同分位数下电子阅读的影响
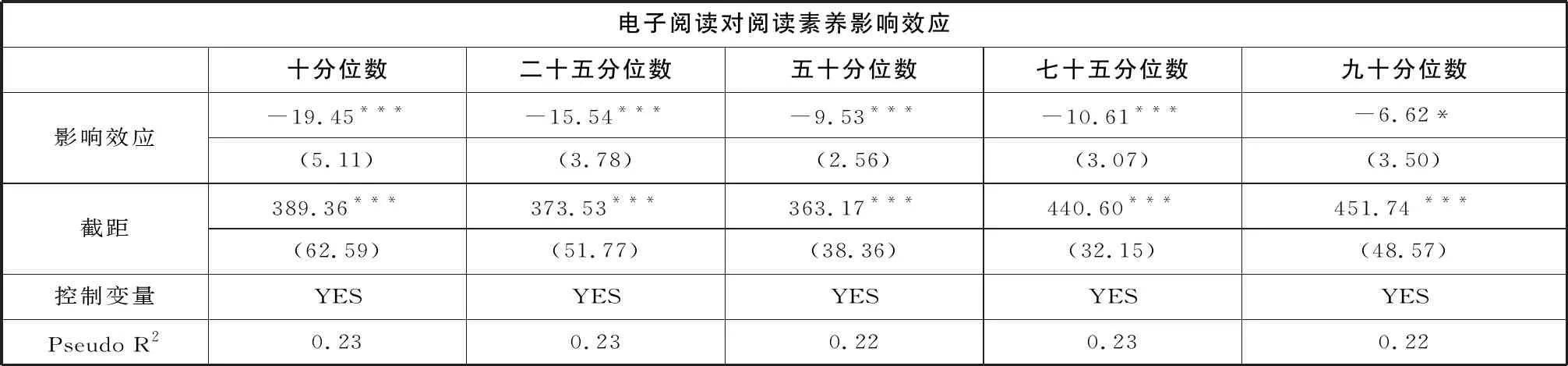
为确保回归结果具备足够的稳健性,本研究采用分位数回归模型检验样本可能存在的异质性。分析结果显示,电子阅读对学生阅读素养的边际影响在不同分位数上呈“逐渐降低”的特征,即随着阅读素养的提高,电子阅读的干扰越来越小。学生样本中存在较高的异质性,高阅读素养的学生似乎没有受到阅读介质的过多干扰,尤其是位于九十分位的学生,显著性仅通过0.1水平的检验(见表六)。
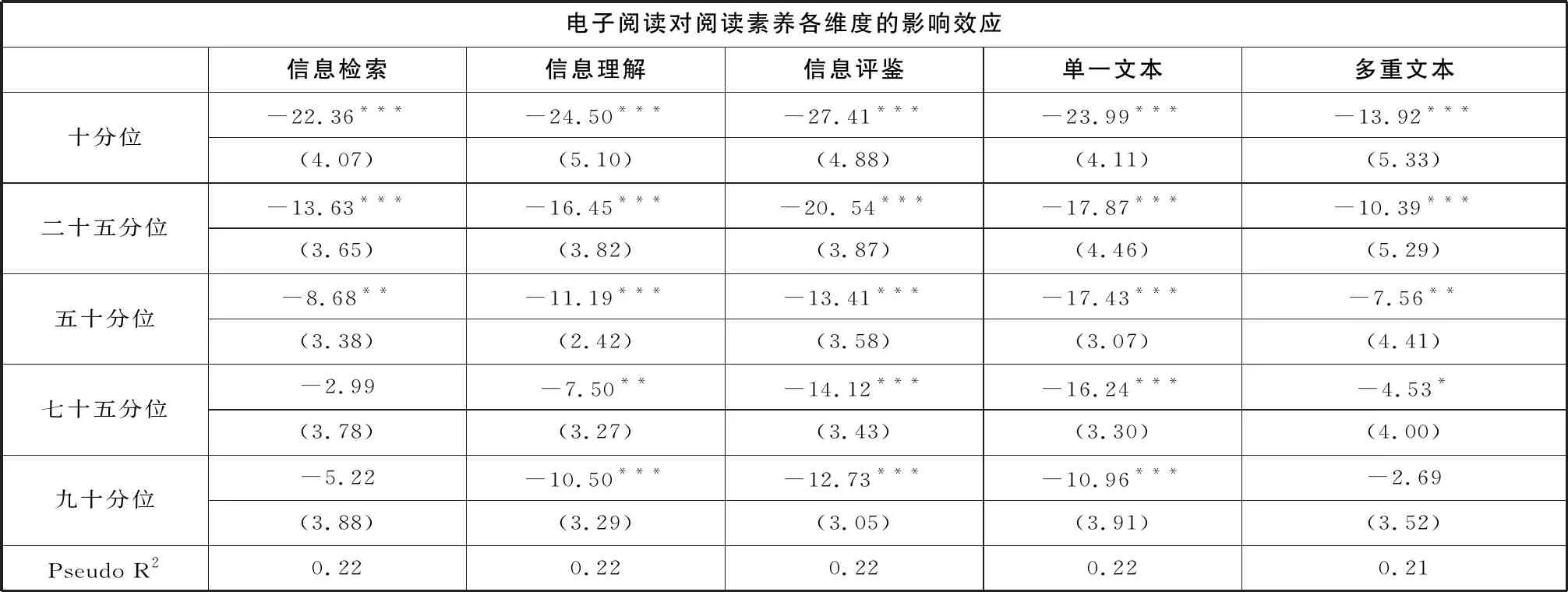
具体到阅读素养的各子维度,这种变化趋势依旧明显。后50%的学生在五个维度受到电子阅读的影响明显高于较高分位的学生,即阅读素养越高的学生,受到电子阅读的影响越低。尤其在信息检索方面,高阅读素养的学生已不再受电子阅读的影响。此外,在多重文本阅读方面,高阅读素养的学生受到的影响也极其微弱(见表七)。
(四) 电子阅读影响机制
如前所述,既往研究发现阅读元认知策略会对学生的阅读素养产生显著影响,但其在电子阅读的影响机制中扮演什么角色,还需探讨。本研究以三类元认知策略指标为中介变量,以阅读总素养为因变量构建中介效应模型(见图1)。结果显示,无论哪类阅读元认知策略,都存在部分中介效应。电子阅读均可通过三类阅读元认知策略,对阅读素养产生间接影响,间接效应值分别为-0.0099、-0.0189、-0.0288,直接效应为-0.09,中介效应分别占6.7%、12.8%、19.5%。以上发现不仅说明选择电子阅读的学生没能熟练掌握阅读元认知策略,也说明阅读元认知策略在电子阅读的影响机制中扮演了重要角色,即学生掌握的元认知策略越熟练,电子阅读造成的影响就越小。
表六 分位数回归结果
表七 各维度分位数回归结果
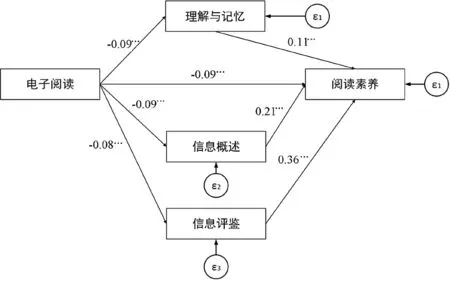
图1 电子阅读影响机制
五、结论与讨论
(一) “屏幕劣势”虽存在,但其影响具有明显的 “异质性”
“屏幕劣势”这一概念指的是相较于传统的纸本阅读,通过手机、电脑、阅读器等电子产品进行阅读会影响阅读效果(Rakefet & Morris,2011;颜敏,2018)。本研究发现,控制了选择偏误后,纸质阅读组的阅读素养总得分比电子阅读组高13.16分,五个子维度的结果也类似,说明“屏幕劣势”的确存在。有研究者认为,在使用电子书等数字化媒介过程中常有超链接、广告、屏幕操作等非认知活动打断阅读进程,使得学生需投入更多的认知负荷,降低了阅读效率(周钰等,2015;Porion et al., 2016;袁征等,2016)。此外,电子书也缺乏必要的辅助性信息帮助学生阅读。李寿欣等(2009)的实验研究表明,在有文章标记的前提下,场依存认知方式的被试阅读效果会得到提升。学生可以直接在书本上做笔记,方便阅读理解,从而发挥文章标记效应。但电子书目前无法实现这一功能,一些电子书的笔记功能繁琐,会消耗读者部分认知负荷。
本研究同时发现,“屏幕劣势”对不同群体的影响存在差异。学生受到电子阅读的影响在不同分位呈明显的递减趋势,处于阅读素养极低分位的学生和阅读素养极高分位的学生,受电子阅读的影响差异明显。这一现象在陈纯槿(2020)的研究中也有提及。不过,由于前期研究没有控制样本的选择偏误和其他因素的影响,“夸大”了电子阅读与纸质阅读之间的差异。本研究较好地纠正了这一估计误差,发现九十分位学生的边际效应值为-19.45,十分位学生为-6.62,即在电子阅读时,阅读素养低的学生比“学霸们”多损失12.83分。这表明,有必要关注电子阅读过程中的“马太效应”,即随着电子阅读不断普及,学生阅读行为和阅读结果的差异可能越来越明显。较高阅读素养水平的学生,受电子阅读的影响不大,电子阅读不会成为学习阻力。但阅读素养较低的学生很容易被电子阅读分散注意力,造成阅读素养明显下降,久而久之,处于不利地位的学生受到的影响更大。因此,家长和教师应当理性看待电子阅读这一新兴阅读方式,既要能看到电子阅读的“方便快捷”,也要意识到可能存在的“屏幕劣势”。如果孩子的阅读素养不高,不妨先以纸质阅读为主,无需盲目追求电子阅读。
(二) 元认知策略发挥重要的促进和中介作用
阅读元认知策略,对阅读的促进作用已经在不少研究中得到证实(杜晓新,1997;许余龙,2003;潘黎萍,2006)。本研究进一步验证了这一结论,即阅读元认知策略可以有效促进阅读素养的提升。在影响机制方面,李晓娟(2015)发现,阅读策略的使用频率受电子阅读影响,但元认知策略的使用频率并没有被电子阅读影响;陈纯槿(2020)发现,高低阅读素养的学生在元认知策略得分上存在明显差异。这些发现均说明,学生的元认知策略在电子阅读和阅读效果之间发挥着相对独立和重要的作用,学生阅读素养的差异或更多来自于元认知策略的差别,分析电子阅读的效果应充分考虑元认知策略的影响。据此,本研究通过分析揭示了阅读元认知策略对电子阅读的中介效应,良好的阅读元认知策略可以帮助学生有效消弭电子阅读的负面影响。
电子产品可能需要读者消耗更多的认知负荷,以及掌握更多的阅读元认知策略。阅读素养较高的学生可以凭借较好的阅读元认知策略,高效地进行电子阅读,反之,素养不足的学生由于没有熟练的阅读元认知策略为其电子阅读“保驾护航”,阅读效果会大打折扣。因此,教师应尽力帮助学生熟练掌握阅读元认知策略,使其在电子产品上依旧可以进行深度阅读。教育者需清醒认识到,电子产品只是辅助阅读的工具而非决定阅读效果的关键因素,对阅读策略的训练,应是提升学生阅读素养的重中之重。
(三) 家庭背景等先赋要素对电子阅读的效果存在显著影响
本研究发现,家庭经济文化地位可以显著正向预测学生的阅读素养。既往的大规模国际调查和小规模区域调查均发现,家庭经济文化背景会影响学生学业表现、认知能力、教育机会的获得(范静波,2016; 张沁,2017; 赵红霞等,2020)。有研究者认为,处于高经济阶层家庭的学生获取新信息的能力更强,可以更快积攒信息优势,巩固原有的阶层优势,这可能导致或加剧阶层之间的“知识鸿沟”(杨钋等,2020)。在这一过程中,家庭背景越好的学生,越有可能获得更多、性能更先进的数字资源,掌握电子设备的速度也越快,越有可能更好地适应电子阅读。这就使得数字资源匮乏者与富有者之间出现“数字鸿沟”,进而影响教育公平(杨钋等,2017;刘骥,2020)。这意味着,在电子阅读普及的过程中,消除学生家庭背景等先赋条件的影响,是教育管理者们须高度重视和着力解决的重要问题。
本研究也存在一些不足。人们对电子阅读介质的关注,大多聚焦于电子书、平板这类电子产品,但本研究涉及的电子产品还包括手机、电脑等。手机和电脑虽然也可以作为阅读工具,但相较于更加专业的电子书,在操作使用和防止学生“他用”等方面都存在欠缺(黄晓芸,2014),这或许可以解释为何在控制了样本选择偏差影响的情况下,本研究中电子阅读和纸质阅读还会有如此大的差异。另外,本研究并未分析电子阅读强度的影响及其对不同学科学习的影响,这都有赖于在未来研究中进一步深化。
[注释]
①PISA对职业声望的计算如下:首先允许学生在问卷中开放回答父母的职业,再按照国际职业标准(ISCO)编为四位数的代码,并参考国际职业社会经济指数(ISEI)进行赋值,取父母最高值得到HISEI指数。
②此处的描述统计没有呈现阅读素养的最大值和最小值,这是因为阅读素养总得分以及五个子维度的得分均无法通过简单计算10个PV值的均值就可得到。按照PISA官方发布的技术手册,PV值指学生素养可能存在的得分区间,不存在最大值和最小值。此外,均值的计算需要按照PISA给予的权重重复计算至少80次。本文的均值以及标准差通过PISA官方提供的IEA软件计算得出(具体操作步骤请参考PISA官网:https://www.oecd.org/pisa/data/httpoecdorgpisadatabase-instructions.htm)。
③泛精确匹配主要控制的是样本的选择偏误带来的影响,主要影响的是核心自变量的回归系数,其他控制变量变化并不明显。受篇幅限制,本文仅汇报后期讨论用到的变量的回归系数与显著性。
