基于网络爬虫的Java行业的就业分析
2021-03-28吴薛凯刘天波胡文馨
吴薛凯 刘天波 胡文馨


摘 要:随着互联网的高速发展,网络信息量呈现爆炸式增长的趋势,利用网络爬虫对大数据进行分析和处理有非常重要的意义。该文以拉勾网为例,利用Python 3.7和MySQL 5.5设计了一个关于Java相关岗位招聘信息的数据采集与存储系统。并且对采集的数据进行多方位分析,为相关行业的就业者在就业选择以及未来规划的时候提供一个有据可依的参照,起到一个就业指导的作用。
关键词:网络爬虫 招聘信息 数据分析 就业指导
Abstract: With the rapid development of the Internet, the amount of network information presents an explosive growth trend, it is important to analyze and process big data by using web crawler. This paper takes LaGou recruitment website as an example, using Python 3.7 and MySQL 5.5 to design a data acquisition and storage system about Java related job recruitment information.And through the multidimensional analysis of the collected data, the use of the analysis results can provide a reference for the employment choice and future planning of the employment and play a role of employment guidance.
Key Words: Web crawler; Recruitment information; Data analysis; Career guidance
Java作为一门成熟的语言,凭借其广泛的应用,深受高校学生以及社会人士的喜爱。该文使用Python语言开发了一套针对爬取Java行业招聘数据的专用爬虫,并对爬取的数据进行处理及分析,这里就以“拉勾网”作为实例,对如何开发爬虫獲取数据,以及对数据的处理、分析做了深入的探讨与研究,为毕业生以及社会求职人士应聘Java岗位提出了宝贵的建议。
1 爬虫设计过程
1.1 需求分析
爬虫的目的是在网站内抽取结构化的、大量的数据,并将这些数据永久保存在计算机硬盘中。该文选择MySQL数据库来保存结构化数据,并使用该数据库对数据进行清洗,再将处理过的数据导出至Excel中,最后利用pyecharts可视化库对数据进行展现和分析。
1.2 爬虫模块化设计
模块化的爬虫程序具有高延展性,因此它能适应不同的应用场景,通过对不同模块进行组合,就能构建出一个完整的网络爬虫系统,并且模块化的程序更加方便测试以及后期维护。
该文开发的爬虫程序一共分为3个模块,分别是网页抓取模块、数据提取模块、数据存储模块,这3个模块组合成为一个完整的网络爬虫系统。
1.2.1 网页抓取模块分析
爬虫程序的本质就是模拟客户端请求网页信息,并在返回网页的网页源码中爬取所需要的数据信息。但面对“拉勾网”多重的反爬机制,发现网页源码中隐藏了有关岗位的关键信息。经过研究得知网页使用了AJAX异步加载技术,AJAX可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。通过审查网页元素得知,岗位信息以JSON文件的形式存放在XHR中,XHR是AJAX功能实现所依赖的对象。
在找到网页的数据接口后,经过对此接口Headers请求头的观察,可以看到请求是以POST的方式传递的,同时传递了参数,经过研究发现,“pn”代表爬取的页码,“kd”代表关键字,通过改变这两个参数就可以改变爬取的内容。
针对拉勾网的高度反爬,还需要在模块中引入适当的破解反爬策略,来确保成功爬取网页数据。如使用IP代理池的技术去访问服务器、修改请求头信息、设置访问时间间隔等。部分设计代码如下。
1.2.2 数据提取模块分析
在获取存有岗位信息的JSON文本后,需要将关键数据从中提取出来。由于在当前时间段,拉勾网有关Java的岗位信息共有200页,所以在爬取数据的时候,设置pn为200,kd为Java即可。
1.2.3 数据存储模块分析
抓取拉勾招聘网站上所有Java岗位获得的信息相对来说是一个比较大的数据,所以在这里选择MySQL Service5.5数据库对这些数据进行存储,并通过MySQLdb对数据库进行操作,在程序开始,利用API建立数据库的连接。接下来,将基于需要保存的信息,建立数据表。随后在数据提取模块提取信息后,将这些数据导入到所创建的数据库中的表内。这样就实现了用Python语言对数据库进行操作,将爬取的数据永久性地存储到数据库中,为下文的就业数据分析奠定了基础。该文利用MySQL可视化图形界面SQLyog展示的部分数据,具体见图1。
2 数据可视化分析
上文通过设计好的爬虫程序将需要的数据导入到数据库中,通过使用SQL语句对数据库进行查询得到,在当前时间段,拉勾网总共发布了2 991条Java岗位信息,下文将通过Pandas库和pyecharts库对数据进行可视化分析,来初步指导广大的Java行业的就业人员。
数据分析结果如下。
随着应届毕业生数量的显著增长,和各行业社会人员向IT行业转职意愿的增强,整个社会的就业压力也随之增大,在这种就业形势如此激烈的社会中,如何做出正确的选择,成了广大学者研究的热点和焦点。
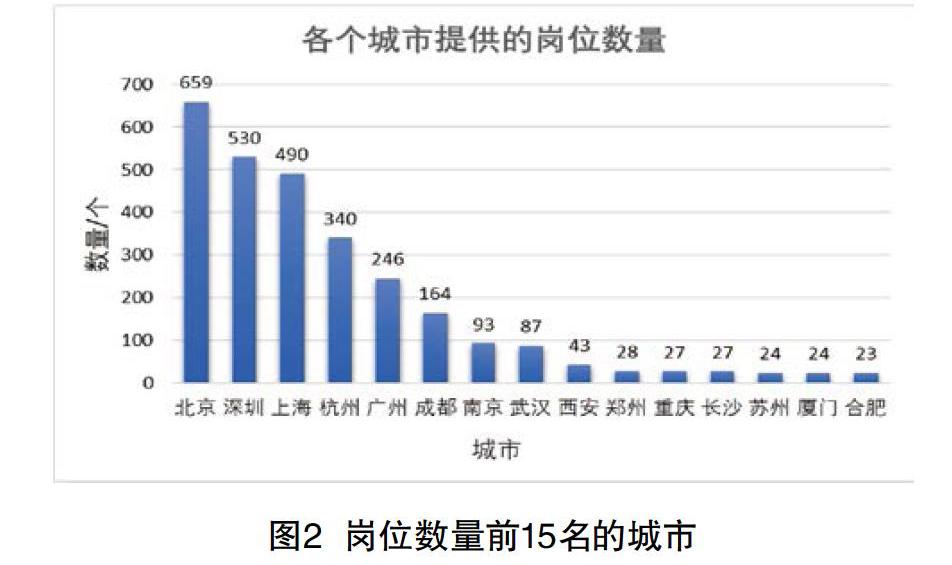
经研究可得,全国各地提供的Java岗位数量的前15名的城市具体见图2。
从图2可以看出,国内各地区提供的岗位数量还是有很大差别的,其中北京、深圳、上海和杭州提供的岗位最多,分别为659、530、490、340。且从图中可以看出排名在武汉之后的城市提供的岗位数量较少,大多数岗位都集中在一线城市以及部分发展较好的新一线城市。
再对所有城市提供的岗位数量进行分析,得知Java岗位在全国各地的分布主要存在以北京、上海、杭州和深圳为中心并向周边城市辐射的现象。这意味着IT行业越发达的地区,提供的岗位数量也越多,并且以这4个城市为中心的周边城市所提供的岗位数量也比较可观。由此可见,IT产业发达的城市可以带动周边城市IT产业的发展,并且IT产业发达城市的就业机会比较多,更适合作为毕业生以及社会人士求职的地方。
Java就业市场对应聘人员的学历层次要求也各有不同。全国Java招聘单位对学历的要求见图3。从图3的结果可以看出在全国范围内岗位招聘当前的需求主要还是本科学历以上,对于部分应届生,也可以选择考研或者考博来提升自己在就业市场上的竞争力。
在薪资水平方面,总体上还是相当可观的。主要集中在月薪10~15 K、15~20 K以及20~30 K这3个层次,并且这3个层次的岗位数量共占整体的78.61%,整体的收入保持在一个较高的水平。
在前文对全国的收入水平进行直观判断的基础上,进而得到国内提供岗位数量前10名地区的招聘收入情况,具体见图4。应聘人员的工作年限与薪资水平的关系具体见图5。从图4可以看出,薪资水平处于前5位的地区分别是北京、上海、杭州、深圳以及南京,其中一线城市的工资要明显高于其余城市,这也跟当地的经济发展和消费水平有关。这样应届毕业生以及社会人员在就业的时候可以根据地区消费的不同,以及对未来的规划选择合适的工作区域。
与此同时,应聘人员以往拥有不同的工作年限,则企业给出的薪资的整体水平也各有不同,由图5分析可知,目前在整个Java领域工作机会最多的是有3~5年工作經验的人才,针对这个批次的人才,企业给出的平均薪资水平约为20.2 K,并且月薪在30 K以上的岗位数量明显增多。拥有5~10年工作经验的程序员的工资将会达到一个相对较高的水平,主要集中在20~30 K或以上,但是招聘需求量也会递减。此外,工作经验在1~3年的就业人员也拥有不错的就业机会和薪资待遇,平均月薪约为14.4 K,这个阶段的人才有很大的职业发展空间。反观那些没有任何相关工作经验的人员以及应届毕业生,企业提供的岗位较少,薪资水平的分布也比较均匀,各个层次的岗位数量相差不多。通过更进一步研究发现,对于这两类人,影响薪资的主要因素便是技术能力和学历水平。所以拥有优秀的技术和较高的学历,更容易找到高薪岗位。
综上所述,以往的工作经验跟薪资水平存在正相关的关系,且在一定的范围内,工作年限越长,就业机会也越多。针对没有经验的人员以及毕业生,就业机会相对偏少,并且薪资水平和技术能力以及学历层次呈正相关的关系,针对这两类人员,提升学历和技术水平更容易找到满意的工作。对于部分应届毕业生,则可选择考研考博,凭此来提升在未来市场上的竞争实力。
3 结语
该文通过Python语言以及MySQL Service5.5数据库,创建了一个基于拉勾网的网络爬虫系统。该爬虫系统可以模拟用户登录拉勾网,获取网页数据接口,并采用一系列技术手段绕过网站的反爬虫系统,爬取数据接口中的信息,同时对数据进行筛选。最后,将筛选后的数据存储至数据库,并在此基础上,对这些数据进行了深度的挖掘,也就是运用一系列的数据分析手段,获取关于全国各个城市对于Java开发工程师的需求程度、不同城市提供的薪资待遇、求职者的学历及以往工作年限对于工作机会以及可能获得的薪资待遇之间的关系等一系列重要信息,为广大的就业人员提供有益的借鉴与参考。
参考文献
[1] 项博良,唐淳淳,钱前,等.基于网络爬虫的就业数据分析[J].智能计算机与应用,2020,10(1):223-226.
[2] 王碧瑶.基于Python的网络爬虫技术研究[J].数字技术与应用,2017(5):76-77.
[3] 李培.基于Python的网络爬虫与反爬虫技术研究[J].计算机与数字工程,2019,47(6):1415-1420.
[4] 王斌.基于聚焦爬虫的舆情管理系统设计与实现[D].上海交通大学,2016.
[5] Ou Gengxin.Development of GUI Applications for Groundwater Modeling Using Python[J].Groundwater,2020,58(4):91-94.
[6] 林捷.主题网络爬虫的研究和实现[D].武汉理工大学,2011.
[7] 薛炜,袁媛,董思勤,等.基于可视化技术的城市餐饮数据分析[J].科技资讯,2020,18(18):17-18.
[8] 陆树芬.基于Python对网络爬虫系统的设计与实现[J].电脑编程技巧与维护,2019(2):67-68.
