基于ALS数据和哑变量技术森林蓄积量估测
2021-03-27岳彩荣李春干罗洪斌朱泊东
金 京,岳彩荣,李春干,谷 雷,罗洪斌,朱泊东
(1.西南林业大学 林学院,昆明 650224;2.广西大学 林学院,南宁 530004)
森林蓄积量是森林固碳能力的重要标志[1],被认为是监测森林生长、评估人工林和天然林木材产量、估算森林生物量的最重要的森林属性之一,对于需要准确信息的林分采伐作业相当重要[2]。传统的森林资源清查主要依靠人工实地调查,费时费力,难以进行大范围的森林结构属性获取[3-4]。遥感技术的出现为森林资源清查提供了一种新的方法,通过数学关系模型提供与感兴趣的森林属性相关的数据以协助大面积调查[5]。林业资源调查用的数据源主要是光学遥感数据,获取的主要是地表二维结构信息,光学遥感受天气的影响较大,会造成数据质量下降。近二三十年的研究发现,机载激光雷达(Airborne laser scanning,ALS)是森林调查中一种很好的辅助数据来源,机载激光雷达作为主动遥感能够获取森林的垂直结构信息,对森林地上生物量或木材体积等森林属性具有很强的预测能力[6]。
目前,利用机载激光雷达提取森林结构属性的方法主要有两种,即基于单木(individual tree detection,ITD)和基于面积(area based approach,ABA)的方法。基于单木的方法,需要识别和分离点云中的单木,直接提取单木的树高、冠幅和形状等特征,利用提取的属性预测一些未知的树木属性,例如直径,然后将这些属性相加可以得到林分水平的估计值。基于ABA的方法通过构建一系列回归模型,将样地数据(如蓄积量)与代表同一地点的激光雷达点云相关联。然后,这些模型可以应用到新的位置,从离散的栅格化网格单元中的点云度量来预测所需的森林属性[7-9]。David等[10]和Leite等[11]利用机载激光雷达数据估测森林碳储量和蓄积量时,比较了基于ITD和基于ABA模型的估测精度,研究发现基于ITD的模型精度不如基于ABA的模型精度高。由于点云密度的限制和基于ABA的模型能取得较高的预测精度,所以本文采用基于ABA的方法进行蓄积量估测。
在进行森林参数回归估测时,有不少定性或分类变量,使用哑变量可以处理这类变量。不少学者对哑变量在森林参数回归建模的应用进行了研究,王忠诚等[12]以地名和林分类型为哑变量,研究桤木林分优势平均高与平均高的相关关系;曾伟生等[13]用线性混合模型和哑变量模型方法建立了贵州省适合不同树种组和区域的通用性立木生物量方程;王金池等[14]和岳振兴等[15]构建了林分密度和龄组作为哑变量的云南松蓄积生长模型和高山松林分蓄积量模型;朱光玉等[16]构建了含林分类型或立地类型哑变量的栎类林分断面积生长模型;Chao等[17]以郁闭度为哑变量构建了基于Landsat 8数据的森林碳密度估测模型,引入哑变量参与建模,在一定程度上提高了模型的估测精度。
本文以广西高峰林场为研究区,基于机载激光雷达和96个样地数据,将树种组(阔叶林和针叶林)作为哑变量,引入到随机森林和支持向量机模型,建立含哑变量的随机森林和支持向量机蓄积量估测模型,研究哑变量对蓄积量估测精度的影响。
1 研究区域及数据
1.1 研究区域
研究区域位于广西壮族自治区南宁市北部的高峰林场,是广西最大的国有林场。研究区地理位置如图1所示。该地区属亚热带湿润季风气候,日照充足,全年降水丰富,年平均气温约为21℃,年平均降水量为1 200~1 500mm,优越的自然条件有利于各种热带和亚热带物种的生长。林场地势东北高西南低,根据激光雷达数据生成的数字高程模型(DEM)数据,高程范围为88.76~462.38m,坡度为0~69.7°,大部分坡度在20~35°之间。根据2016年的森林二调数据,高峰林场主要为人工林,主要树种有杉木(CunningHamialanceolata(Lamb.)Hook.)、马尾松(PinusmassonianaLamb.)、巨尾桉(EucalyptusgrandisxuropHylla)、八角(IlliciumverumHook.f.)、火力楠(MicHeliamacclureiDandy)等。
1.2 机载激光雷达数据
机载激光雷达数据获取时间为2016年9月,以直升机为飞行平台,搭载奥地利RIEGL公司的VUX1LR的激光雷达系统,该系统是集激光测距、全球定位系统和惯性导航系统与一体,激光器的波长为1 550nm,激光发射角为0.5mrad,平均点云密度2.9个/m2。同时还搭载了3 000万像素的CCD相机获取该研究区的航空影像,空间分辨率为0.2m。
1.3 样地数据
地面样地调查时间为2016年5—12月份,根据森林二调数据中森林类型、林龄等因素,在研究区内设置96个面积为900m2(30m×30m)的方形样地,样地主要优势树种为杉木、马尾松、巨尾桉和阔叶树,按叶片形状将样地分为针叶林和阔叶林,其中针叶林样地50个,阔叶林样地46个。通过森林罗盘仪和激光测距仪设置样地,利用手持双频差分GPS接收器记录样地四个角点的地理坐标,对胸径≥5cm的树木逐个测量并记录其树种组、胸径、树高、枝下高、冠幅等,样地蓄积量根据样地胸高断面积和样地平均树高通过形高表计算获取(表1)。
2 研究方法
2.1 机载激光雷达数据的处理
机载激光雷达数据在采集过程中受一些因素的影响,会产生一些离群点,这些离群点称为噪声点,采用阈值法对噪声进行剔除。滤波处理是点云数据处理的基础和至关重要步骤[18],采用不规则三角网(TIN)方法对点云数据进行滤波,将点云数据分为地面点和非地面点,利用TIN插值法对地面点进行插值运算,生成分辨率为0.5m的DEM数据,利用生成的DEM数据对点云数据进行归一化处理。从归一化后的点云数据中提取30m×30m空间林分尺度下的37个点云特征变量(表2)。为了避免林下灌木和草本的干扰,采用高度阈值法将高度在2m以下的点云去除。机载激光雷达数据的预处理在LiDAR360软件中完成。
2.2 建模方法
从LiDAR数据中提取37个特征变量结合样地数据采用随机森林、支持向量机建立蓄积量估测模型。首先,将96块样地数据按7∶3的比例随机划分为67个建模样本数据、29个测试样本数据,以67个建模样本作为建模基础。利用随机森林进行特征选优,利用优选的特征进行支持向量机建模,利用随机参数寻优法和十折交叉验证法对随机森林和支持向量机模型参数进行寻优。将树种组和龄组分别作为哑变量,引入到随机森林和支持向量机模型。最后,运用测试样本对基础模型和哑变量模型精度进行评价。随机森林和支持向量机均使用Python语言实现。
2.2.1随机森林回归模型
随机森林算法是Breiman等[19]提出的,利用bootstrap方法生成m个建模集,然后对于每个建模集,构造一棵决策树,在节点找特征进行分裂的时候,并不是对所有特征找到能使得指标(如信息增益)最大的,而是在特征中随机抽取一部分特征,在抽到的特征中间找到最优解,应用于节点,进行分裂。随机森林实际上相当于对样本和特征都进行了采样,在一定程度上可以避免过拟合。
2.2.2支持向量机回归模型
支持向量机最早用于分类,随后推广到了回归拟合。当样本在原始空间线性不可分时,引入了核函数,可将样本从原始空间映射到一个更高维的特征空间,是样本在这个特征空间线性可分。支持向量机的核函数主要有线性核函数(linear)、多项式核函数(poly)、高斯核函数(RBF)和Sigmoid核函数。支持向量机中有两个重要参数惩罚系数(C)和gamma,当C过大或过小时,模型的泛化能力变差;gamma影响建模与预测的速度。
2.2.3哑变量的引入
哑变量又称虚拟变量,通常取值为0,1或-1。哑变量处理是对定性因子或分类变量进行处理的一种常用方法。哑变量的定义为:对于等级性(定性)数据x,用变量δ(x,i)表示,当x取值为第i等级时,δ(x,i)=1,否则为0[14,20]。本文将树种组和龄组分别作为哑变量参与建模,将属性变量用定性代码0或1表示,第i种林分类型表示为zi,定性数据zi转化为(0,1)形式:
当哑变量为树种组时,式中:i=1,2;z1,z2分别表示阔叶林和针叶林的定性代码。
当哑变量为龄组时,式中:i=1,2,3,4;z1,z2,z3,z4分别表示幼龄林、中龄林、近熟林、成熟林和过熟林的定性代码。z1=1,z2=0,z3=0,z4=0(幼龄林);z1=0,z2=1,z3=0,z4=0(中龄林);z1=0,z2=0,z3=1,z4=0(近熟林);z1=0,z2=0,z3=0,z4=1(成熟林);z1=0,z2=0,z3=0,z4=0(过熟林)。
2.3 模型预测精度评价
采用决定系数(R2)、均方根误差(RMSE)和相对均方根误差(rRMSE)来评估模型的估测精度。
(1)
(2)
(3)
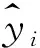
3 结果
3.1 特征选择及模型建立
基于样地数据和机载LiDAR数据提取的37个特征变量建立随机森林和支持向量机蓄积量回归模型。利用随机搜索算法和十折交叉验证法对随机森林和支持向量机进行参数寻优。1)随机森林参数的寻优结果为:构造决策树的数量为100,树节点分裂的最小特征数为2,最小叶子节点为1。2)参考相关文献[21-23],支持向量机使用的核函数为RBF,参数寻优结果为:惩罚参数(C)为10,gamma参数为0.01。3)利用随机森林回归模型得到了LiDAR特征变量的重要性,如图2所示。本文选择大于80%的累计贡献的特征变量参与支持向量机回归建模。选择参与支持向量机回归建模的特征变量如表3所示。

表3 参与SVR建模的特征变量
3.2 精度评价
使用67个建模样本数据和29个测试样本数据分别利用基础模型、树种组哑变量模型和龄组哑变量模型进行蓄积量估测。图3和图4分别是随机森林和支持向量机模型建模样本和测试样本预测值和实测值关系图。
模型的精度评价如表4所示。从表中可以看出,加入哑变量后,模型的检验精度相较于基础模型有了一定程度的提升,龄组哑变量对模型精度提升效果优于树种组哑变量,但两者估测精度差距不明显。对比6个模型的建模样本和检验样本的R2,RMSE和rRMSE,加入龄组哑变量的随机森林模型建模精度和检验精度是最优的。表中差值一项反映了建模精度和检验精度之间的差距,差值越小,模型泛化能力越强[21]。总体上,支持向量机回归模型建模精度和检验精度之差小于随机森林回归模型,说明支持向量机回归模型的泛化能力优于随机森林回归模型。

图2 特征变量重要性
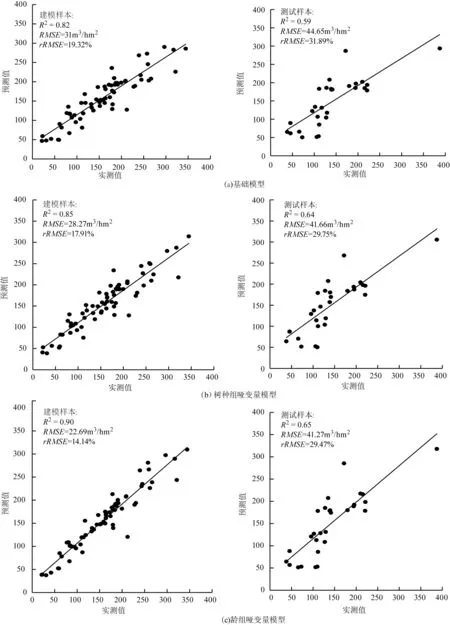
图3 随机森林模型蓄积量预测值和实测值对比图

图4 支持向量机模型蓄积量预测值和实测值对比图
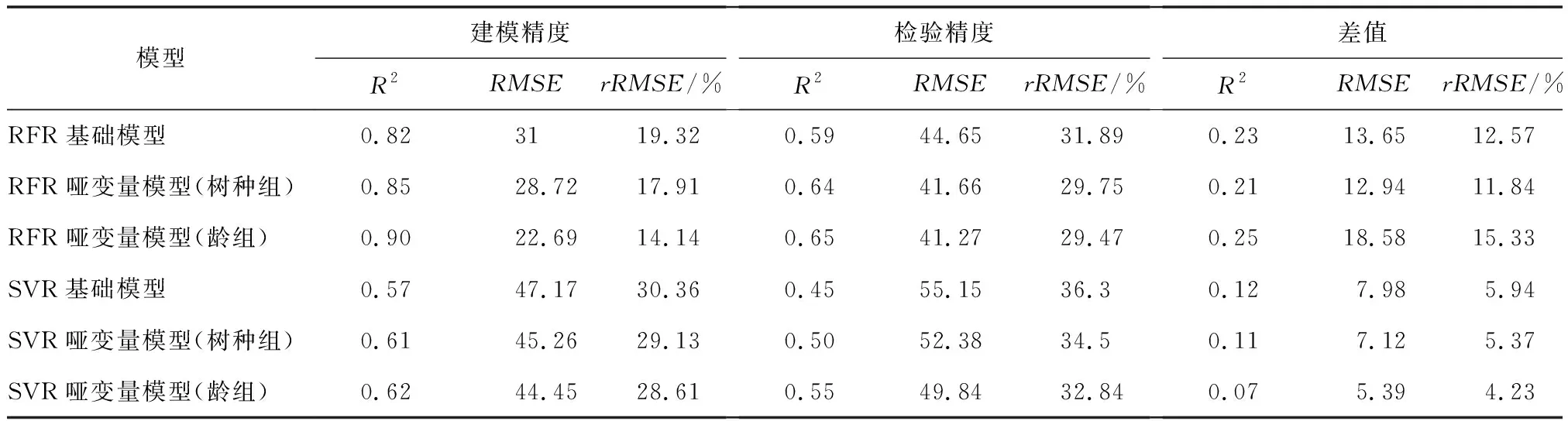
表4 模型精度评价指标
4 讨论与结论
4.1 讨论
1)总体上看,含哑变量的蓄积量估测模型的决定系数、均方根误差和相对均方根误差都优于基础模型,表明引入树种组构造的哑变量模型对于蓄积量估测精度有了一定程度的提升。建立哑变量模型,不需构造多个分段模型,减少了建模的繁琐过程。
2)使用机器学习算法进行蓄积量估计时,估测精度高度依赖于相关算法中参数的优化和样本的代表性。本文使用随机参数寻优算法和交叉验证法选取最优参数组合,避免在蓄积量建模中盲目调参,造成预测结果过拟合或欠拟合。
3)龄组哑变量对模型精度提升的效果优于树种组哑变量。由于样地数量较少,树种仅分为针叶林和阔叶林树种组,但阔叶林中桉树和其他阔叶树差异较大,桉树为人工林,树种单一且林相整齐,结构简单,其他阔叶树树种组成和结构都较复杂。如果样本数量允许,可将阔叶树种组按树种差异作进一步划分,以提高树种组哑变量对蓄积量的估测精度。
4.2 结论
基于机载激光雷达数据和96块样地数据进行森林蓄积量遥感模型研建,采用随机森林和支持向量机回归为建模方法,以LiDAR点云特征变量为基础,将树种组和龄组作为哑变量引入模型,通过对比引入哑变量前后模型精度的变化,评价了哑变量技术对蓄积量预测精度的影响。研究结果表明,引入哑变量在一定程度上提高了模型的拟合精度,其中引入龄组哑变量的随机森林模型的建模精度和测试精度最优;但支持向量机模型相对于随机森林模型具有更好的泛化能力。引入哑变量对基于机载激光雷达数据估测蓄积量模型的精度提升是有效的。
致谢:
感谢广西林业勘测设计院为本次实验提供了机载 LiDAR数据及样地数据!
