基于态势认知的无人机集群围捕方法
2021-03-26吴子沉胡斌
吴子沉,胡斌
(空军工程大学 航空工程学院,西安710038)
无人机集群作为一种新的应用样式,具有极大的发展前景[1]。无人机集群对目标的追捕问题是一种典型的应用场景。
针对无人机集群围捕问题,目前大多数研究均基于分布式控制[2],即通过将集群围捕问题转换为一致性问题,再设计分布式算法使得集群向目标位置收敛,实现围捕的效果。黄天云等[3]提出了一种基于松散偏好规则的自组织方法,通过分解围捕行为,利用松散偏好规则使个体机器人自发形成理想的围捕队形,并运用Lyapunov稳定性定理证明系统的稳定性。李瑞珍等[4]提出了一种基于动态围捕点的多机器人协同围捕策略,根据目标位置设置动态围捕点,并利用任务分配方法为围捕机器人分配最佳围捕点,综合考虑围捕路径损耗和包围效果,计算围捕机器人的最优航向角,实现集群对目标的围捕。张子迎等[5]提出一种多层环状伏击围捕模型,并依据能量均衡原则,对系统能量消耗进行平衡。Uehara等[6]针对有障碍的复杂环境下集群围捕问题,改进了粒子群算法,使得围捕者能够在规避障碍物的情况下实现对目标的围捕。
近年来,部分学者探索了通过强化学习来解决集群对目标的围捕问题[7-10]。Liu等[11]通过对围捕复杂任务进行分解,将学习过程分为高级学习和低级学习,并使两部分学习并行进行,完成了围捕问题分层次强化学习设计。Bilgin和Kadioglu-Urtis[12]结合Q学习(Q-learning)和资格痕迹(Eligibility Traces),对追捕者进行并行训练,并为每个追捕者维护一个独立的Q值表(Q-table),完成了集群内部存在交互的独立智能体学习。Awheda和Schwartz[13]提出了将卡尔曼滤波与强化学习结合起来的卡尔曼滤波模糊A-C算法,尝试解决在追捕者和目标训练环境不一样的情况下如何实现成功围捕的问题。Lowe等[14]于2017年提出了MADDPG(Multi-Agent Deep Deterministic Policy Gradient)算法,探索了多智能体领域的强化学习,该算法通过智能体之间信息的交互,使得每个智能体的强化学习都考虑到其他智能体的动作策略,取得了显著的效果,但该算法训练时需要知道对手智能体的逃逸策略,这与大多情景不符。
以上研究在环境属性确定的情况下能够有效解决集群围捕问题,但是在新环境下,往往围捕效果较差。基于此,本文设计了一种基于态势认知的无人机集群围捕方法,尝试解决不同环境下的围捕策略问题。首先,基于对围捕行为的分析,将围捕过程离散化;然后,利用深度Q 神经网络(Deep Q-network,DQN)方法[15-17],解决固定时间窗口长度下的围捕策略生成问题;最后,通过建立状态-策略知识库,实现面向围捕问题的认知发育[18],基于态势识别,完成围捕策略的快速选取。仿真结果表明,在确定环境情况下,所设计的基于DQN的围捕发育方法能够解决围捕问题,给出围捕策略,提出的基于态势认知的围捕方法能够实现知识库的增量发育,有效应对新环境下的围捕问题。
1 问题描述
设战场上存在N架无人机组成的集群,对一个运动的目标进行追捕,如图1所示。
用U=(u1,u2,…,uN)表示追捕无人机状态矩阵,ui表示第i架无人机的状态矢量,用T表示目标状态矢量。设追捕无人机的速度为Vp,目标的速度为Vt,Dp表示追捕无人机的探测距离,Dt表示目标的探测距离,通常设定Dp>Dt。
目标与追捕无人机均在战场上运动,追捕无人机的目的是探测到目标的位置信息,再通过协作在目标周围设立包围圈,实现对目标的围捕。当其中一架无人机获得目标的位置信息后,视为其他追捕无人机获得目标的位置信息。目标初始时刻在战场随机运动,一旦发现追捕无人机后,会按照一定的逃离策略进行逃逸。
本文假设当3架及以上的追捕无人机在目标周围设立包围圈,且包围的无人机与目标的最大距离小于目标的探测距离,即视为围捕成功,无人机亦可依据障碍物设置包围圈,如图2所示。
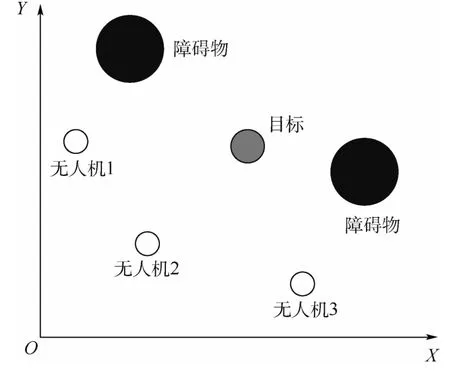
图1 围捕问题示意图Fig.1 Schematic of rounding up problem

图2 围捕成功示意图Fig.2 Schematic of successful rounding up
本文考虑2D仿真环境下的集群围捕问题。将无人机及目标看作质点,不考虑无人机及目标的姿态变化,可将无人机及目标的运动模型表述为

式中:(x,y)为当前时刻位置;(vx,vy)为当前时刻速度。
2 基于DQN的围捕策略发育
根据无人机集群围捕的特点,将围捕动作分解为:右侧包抄(R)、左侧包抄(L)、逼进(F)、后退(R)、静止(S)五种,记为

考虑时间窗口长度为τ的围捕效果,将围捕策略表示为τ时刻内各无人机动作的有序集合,即

式中:

其中:at为t时刻各无人机选取的动作;Ai为从Actions集合中选取的具体动作。
假设围捕无人机数目为N,则一个时间窗口内,共有5Nτ种围捕策略可供选择。假设考虑仅3架无人机时间窗口长度为5 s的围捕效果,则围捕策略的总数也多达3×1010。因此,为解决具体环境下围捕策略的发育问题,考虑使用DQN进行策略的选择。
2.1 状 态
在无人机集群围捕过程中,可将状态看作是由战场本身存在的障碍物、各无人机及目标构成。
假设环境中第k个障碍物为以(xk,yk)为圆心、以rk为半径的圆,只考虑静止的障碍,则障碍物可以描述为

令

式中:O为环境中n个障碍物的集合。
无人机集群通过观察可获得目标的位置、速度的观测值,集群内部通过相互通信,可以获得各自的位置、速度信息,将t时刻目标状态描述为
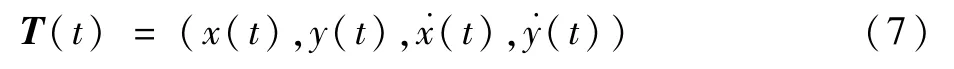
将t时刻集群的状态描述为
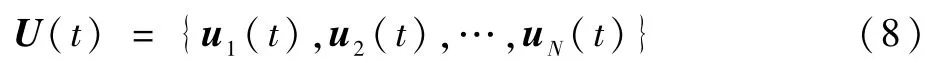
式中:
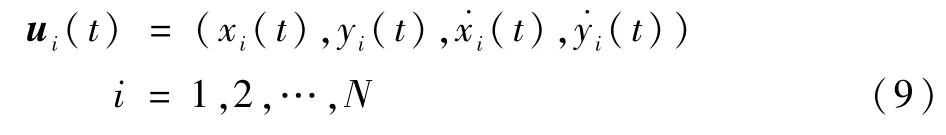
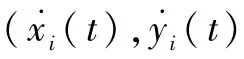
将状态统一描述为

2.2 奖励函数设定
DQN根据奖励值来调整网络权重,实现对网络的更新。奖励函数的设定极大地影响到训练的效果。
集群对目标的围捕成功与否是以无人机到目标的距离及相对角度判断的,因此,设置奖励函数时,需充分考虑这2个因素。
将无人机i到目标j的距离用dij表示,当∀dij>Dp时,无人机集群尚未发现目标;当Dt<dij≤Dp时,表示无人机i发现了目标j,且自身未暴露;当Dt≥dij时,表示目标j已经发现了无人机i,此时如果尚未形成包围圈,目标j会主动逃逸。
通过距离建立奖励函数:
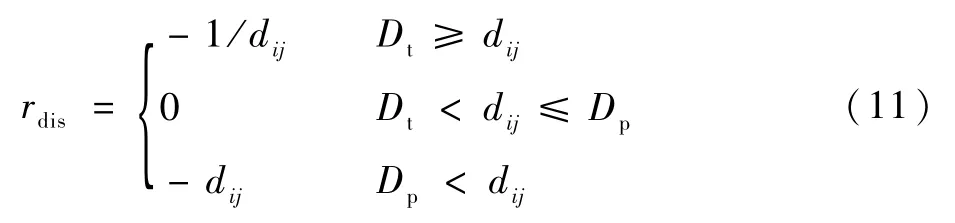
理想的围捕队形通常是多无人机均匀分布在以目标为圆心、以围捕半径为圆的圆上[4],以3架无人机组成的集群为例,如图3所示。
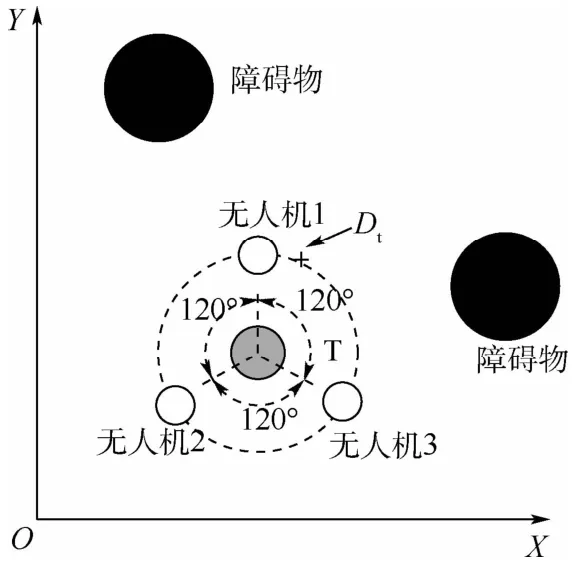
图3 围捕队形示意Fig.3 Schematic of rounding up formation
设无人机i与周围2架无人机分别以目标为顶点的角度为ψ和φ,则ψ*=φ*=2π/N为最优的角度,可以通过角度建立奖励函数:
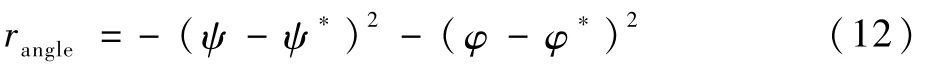
此外,需在奖励函数中加入避障项,以使得无人机能够主动规避环境中的障碍物:

式中:rOb为奖励函数的避障相;dmin为无人机距离最近障碍物的距离。
综上,将奖励函数设置为
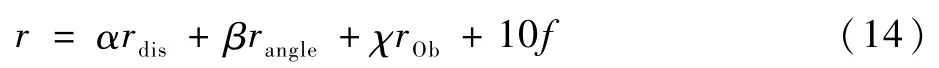
式中:α、β和χ分别为距离项、队形项和避障项的权重,权重的确定通常需要实际训练来调整;f定义为当围捕成功,无人机会获得+10的奖励。

2.3 基于DQN的策略发育
DQN[19]通过构建深度神经网络,完成对Q函数的拟合,解决了传统Q-learning方法中状态量太多导致的维度灾难问题。本文采用文献[19]中提出的DQN方法,实现多维度状态到低维度动作的映射。
为获取围捕策略,在每组训练过程中,将最终获得奖励值最大的一次训练的每一步以(St,at,rt)的形式储存,在所有训练结束后,针对储存的动作从t=0时刻进行一次长度为τ的采样,并进行m次长度为τ的随机采样。设采样的时刻为:0,t1,t2,…,tm,对应的采样点状态为:S0,St1,St2,…,Stm,可 获 得m+1次 策 略:π0,π1,…,πm。
3 基于态势认知的围捕决策
得益于人脑强大的认知能力,飞行员在面对复杂多变的动态环境时,能够迅速地做出有利于战局的决策。仿照生物认知机制去构建具有学习和经验的增量式发育算法是解决一类复杂问题的有效途径,文献[18]受此启发,提出了包括认知决策、制导规划和执行控制3个层级的无人机认知控制系统结构,并在复杂动态环境下的多威胁无人机防碰撞问题中验证了有效性。本文在此基础上提出了一种基于场景认知的围捕决策。
如图4所示,在基本的围捕算法之上,构建包含状态-策略的知识库。当无人机集群每完成一次围捕训练,判断围捕方法是否有效,并设立一定的门槛,将有效训练的围捕策略存储到知识库中,构建围捕策略知识库。通过大量仿真训练,获得大量的状态-策略数据,在遇到相似状态的情况,可以直接调用策略进行围捕,而不需要重复训练。
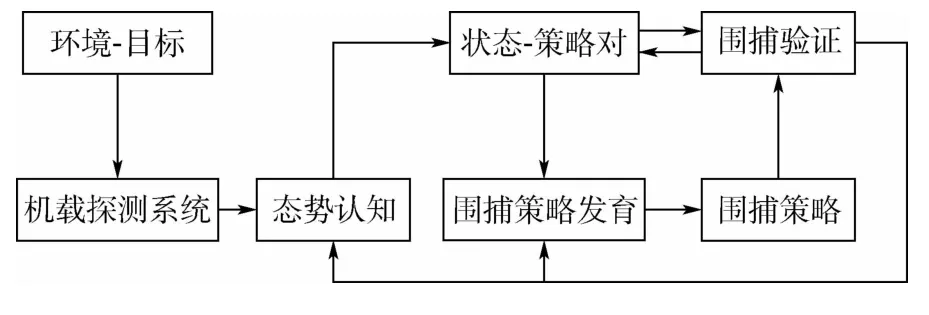
图4 无人机集群发育结构示意图Fig.4 Schematic diagram of UAV swarm development structure
3.1 基于认知发育的围捕
基于认知发育的围捕流程如图5所示。
围捕开始后,无人机集群获得当前时刻信息,通过态势认知将当前状态与知识库内的状态信息进行匹配,选择符合标准的策略进行围捕,若状态信息无法匹配,即遇到了新的状态,则调用第2节中的围捕发育算法进行围捕策略发育,以获得合适的围捕策略,此次围捕结束后,将获得的状态与相应的围捕策略加入到状态-策略知识库中,实现知识库的增量发展。

图5 基于认知发育的围捕方法Fig.5 A rounding up algorithm based on cognitive development
3.2 态势认知与策略匹配
围捕状态的描述已经在3.1节中给出,下面简要介绍如何通过对态势的认知,判断该状态是否为已知状态,并完成对状态的匹配。
为方便表述,将式(10)中状态的属性统一用G表示,共3n+4N+4项,即
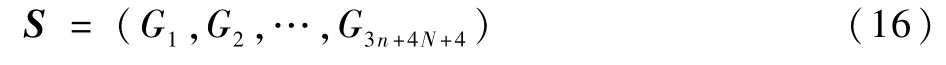
为了实现对不同环境-目标模式的区分,以实现后续的分类及匹配工作,以绝对值指数法定义相似度函数:

式中:wi为属性Gi的权重。
设定C为相似度阈值,当

就认为S与S′为同一模式,否则为不同模式。并取增量判别函数:
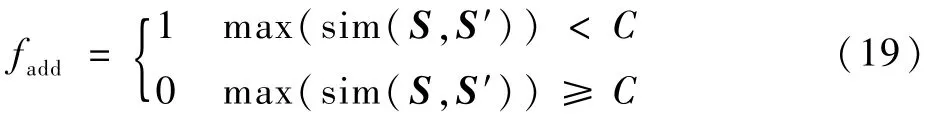
作为判断是否需要将新状态S′加入状态-策略知识库的依据,当S′与已有知识库中的模式进行匹配时,如果相似度最大值大于阈值,则认为S′为已存在模式,直接调用相应的策略进行围捕。反之,将S′认为是全新的模式,调用围捕策略发育算法生成策略,并扩充到知识库中。
为简化状态匹配流程,将相似度阈值分解为

式中:ci对应项Gi的相似度。
比较状态S和S′的第i项,如果
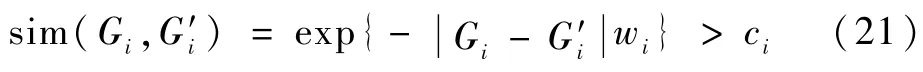
则认为状态S和S′的第i项相似。进行状态匹配时,从G1项开始,从知识库中依次筛选符合条件的状态-策略对,最终获得匹配结果。
4 仿真与分析
为验证本文方法的有效性,采用文献[20]中的平台进行发育训练。通过随机生成围捕环境,建立训练集,验证基于态势认知的发育算法在围捕问题上的效果。
4.1 训练集参数设定
取无人机数目N=3,无人机和目标均为直径是2 m 的圆,设定围捕环境横纵坐标范围为[-25,25]m,无人机和目标的坐标每次均随机生成,具体参数如表1所示。
记录围捕所消耗的时间,并设定围捕时间步大于100时为围捕失败。
训练集大小为1 000,通过对障碍物属性的随机生成,获得不同的围捕环境。设定障碍物的生成参数如表2所示。

表1 无人机与目标参数设定Table 1 Parameter setting of UAV and target

表2 障碍物生成参数Table 2 Obstacle generation parameters
4.2 仿真结果
1)仿真实验1。选取一个随机生成的环境对所设计的DQN方法进行验证。
图6为一次具体的围捕场景实例。此次围捕分为3个阶段:①无人机与目标距离较远,互相不知道对方的位置,无人机集群在搜索目标,目标在以随机的初始航向游走。②目标仍然随机运动。无人机2发现目标位置,其始终将自身与目标的距离控制在5~10 m之间,无人机1和无人机3则绕过障碍物,向目标前进,以构成围捕队形。③无人机3最先进入目标的探测范围,目标向反方向逃逸。无人机集群已在目标周围构成三角形,一同向目标趋近完成围捕。
从图7中可看出,初始时刻,无人机集群无法有效完成对目标的围捕。随着训练次数增加,无人机集群最终能够在45步以内完成对目标的围捕。由此可见,DQN方法对无人机集群围捕问题是有效的。
2)仿真实验2。对基于态势认知的围捕方法进行训练,获得初步的知识库,再按照训练集的生成方法,生成一组长度同样为1 000的新环境,对知识库的有效性进行了验证,结果如图8所示。
图8表示了随着对不同围捕环境的训练,状态-策略知识库中的状态-策略对也相应地增加,最终由于增量判别函数中阈值的存在,策略数目会稳定在一定的范围。
从图9中可看出,大多数场景下,集群都能在45步以内完成围捕,这表明面对新生成的不同环境,无人机集群能够迅速完成围捕任务。
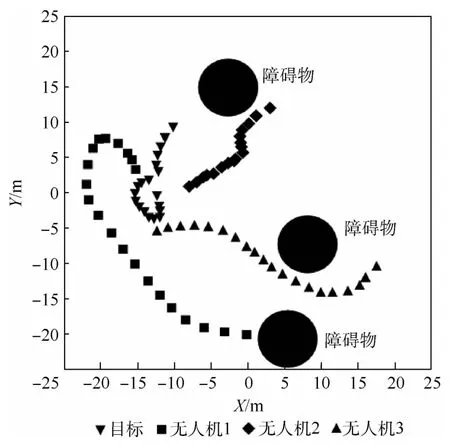
图6 围捕实例Fig.6 An example of rounding up

图9 测试环境下的围捕结果Fig.9 Rounding up results in test environment
5 结 论
1)设计的基于DQN的围捕策略发育方法能够有效解决固定环境下的围捕问题,给出围捕策略。
2)提出的基于态势认知的围捕方法能够实现知识库的增量发育,有效应对新环境下的围捕问题。
为使本文方法能够应对更复杂的环境,仍需要优化策略存储机制及策略的提取机制,满足实时性要求。
