基于时域映射的多无人机系统给定时间分布式最优集结
2021-03-26丁超魏瑞轩周凯
丁超,魏瑞轩,周凯
(1.空军工程大学 研究生院,西安710051; 2.空军工程大学 航空工程学院,西安710038)
通信受限条件和复杂战场环境下,多无人机系统自组织协同作战是应对广域战场空间中动态任务的有效作战方式[1]。而系统状态的一致性是自组织协同作战的基础,是发挥多机系统集群优势、实现智能汇聚的关键。
近年来,众多文献针对多自主体系统一致性进行了深入研究,分别提出了若干动态和静态一致性算法[2-6]。但是上述文献的研究重点在于系统内部控制结构,难以针对复杂多变的外部环境,形成较为开放自主的任务完成能力。
为解决上述问题,一些学者将研究点进一步拓展,开始逐步研究分布式优化问题,即如何在局部通信条件下,不仅实现全局一致性,还能针对单个系统不能完全感知的外部环境作出协调反应,实现某些指标的全局最优。关于分布式优化问题,文献[7-10]将梯度下降算法与一致性协议结合,在离散框架下解决了相应问题。然而文献[7-10]所考虑的多自主体系统不包含动力学模型,这与实际应用场景不符。因此,文献[11]针对连续的动力学系统,提出事件驱动机制解决了对应的优化问题,但是决策协议中部分参数的选择依赖于外部环境全局信息。为解决此问题,文献[12]利用自适应技术,分别构造性地设计了基于边和节点的分布式自适应优化协议,但无论是一致性还是最优化都只能实现渐近收敛,一定程度上限制了其应用范围。基于此,文献[13-14]运用符号函数技术,保证了系统一致性与最优化在有限时间内完成,但所有局部目标函数必须满足类二次型(Quadratic-Like)假设。为消除该限制性条件,文献[15]进一步采用切换策略,将有限时间收敛结果推广到更一般的凸目标函数。然而,应该指出的是,文献[15]中的收敛时间与初始条件有关且优化时间无法显式计算。文献[16]进一步将具有固定时间收敛特性的双幂次趋近律运用到分布式优化问题当中,消除了一致性收敛时间上界对系统初始状态的依赖。但该上界仍然取决于某些全局信息及协议参数,并且系统最优性无法在有限时间内实现。如何在给定时间内进行协调决策,更快地实现信息和智能的汇聚成为分布式优化领域亟需解决的难点。
为解决给定时间内多无人机系统的分布式最优集结问题,本文提出了一种具有时变增益的分布式优化协议。通过建立时域映射,并基于原有限时域给定时间稳定性与转换后无限时域渐近稳定性的等价关系,在转换时域证明了分布式协议的有效性。与目前常规的基于幂次趋近律的有限和固定时间方法相比,本文收敛时间能够被任意规定,有效增强了面向任务的能力。此外,时变增益的使用还消除了传统方法增益设计的限制性条件,避免了常数增益和自适应增益设计方法中需要一定全局先验知识以及复杂度增加的问题。仿真结果验证了本文给定时间分布式优化协议的正确性和有效性。
1 问题描述
1.1 通信拓扑
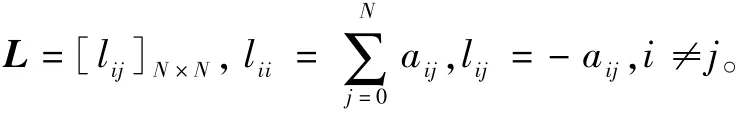
在假设1条件下,每架无人机仅能获取自身及其邻居的局部信息,但同时也保证了多无人机系统中不存在完全孤立的个体,这使得群体中每名成员的信息可通过间接方式实现融合。对于无向连通图,有如下引理:
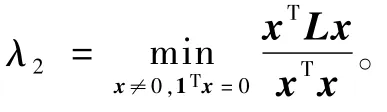
1.2 任务建模
假定在某次任务中,N架无人机在分布式通信条件下分别由不同初始位置起飞,从不同方向集结到任务区域。在整个集结过程中,需要综合考虑我方支援补给、敌方探测雷达、防空导弹威胁等约束条件,实时动态地规划每架无人机的飞行航迹,并要求无人机群集结完毕时所在位置全局最优。本文约定每架无人机能够依据自身设备与知识得到态势判断函数fi(xi):Rn→R,并进一步计算出当前梯度信息Δfi(xi):Rn→Rn,xi为无人机i的位置,fi(xi)越小越好。此外,战场环境瞬息万变,战机稍纵即逝,为了不打乱既定作战计划,保证整个任务链顺利进行,要求无人机群必须在给定时间T内完成集结。任务可用数学语言描述为
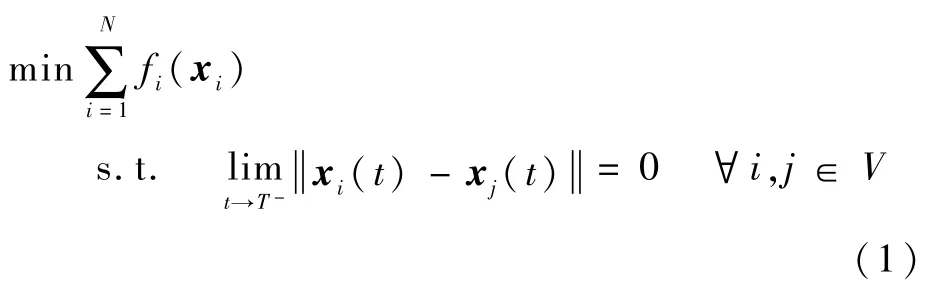
为了保证目标函数最优解存在,给出如下凸优化假设:
假设2对于任意i=1,2,…,N,fi(xi)二阶可微且Δ2fi(xi)为正定矩阵。


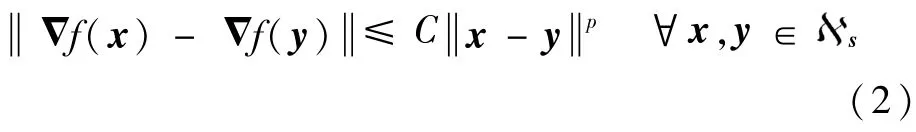

对于可微凸函数f(s)而言,假设3是一个相当宽泛的条件,它比一般的Lipschitz连续性条件更弱。假设4则保证了全局梯度的变化率有限,符合实际情况。为便于分析,介绍如下引理:

1.3 决策模型
若将无人机看做质点,其三维运动学模型可表示为[19]

式中:[x,y,h]T为无人机的位置向量;v为无人机速度大小;ψ和θ分别为无人机的航向角和俯仰角。
可以看出,若忽略飞控系统的动态响应过程,无人机的三轴速度都可以通过v、ψ和θ合适的指令进行相应配置。由于本文旨在研究如何通过实时在线分布式决策实现智能汇聚,仅涉及到空间内三轴速度指令决策,故决策系统的一般表达式即为
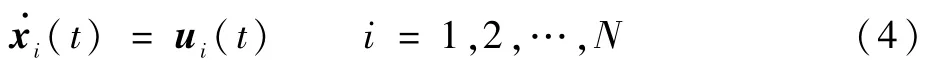
式中:xi(t)∈Rn为无人机的状态,若仅考虑三轴位置,则n=3,为体现本文方法的可扩展性,仍记为未定整数n;ui(t)∈Rn为决策指令输入,ui(t)只能使用自身和从邻居处获取的信息。
实际的决策系统多采用离散化的方式逐步确定下一时刻位置指令。注意到当采样时间Δt较小时,可将微分方程(4)转化为如下差分方程进行离散化决策:
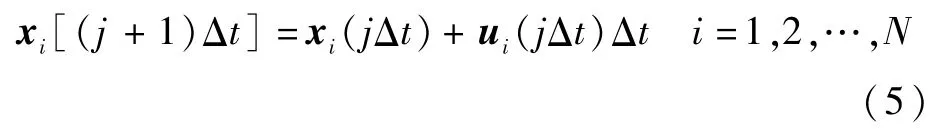
式中:j∈N为采样次数;N为自然数集合。
2 主要结果
2.1 时域映射
借鉴文献[20]提出的时域映射方法,本节将系统(4)的给定时间分布式优化问题转化为时变系统(9)的渐近优化问题,相比于通常的固定时间幂次趋近律方法,简化了分析与设计流程。
令多无人机系统集结时间的上界为T,当t∈[0,T)时,考虑利用如下的时域坐标映射将有限时域t扩张到无限时域τ。

其逆变换记为

显然有ω(τ):[0,+∞)→[0,T)。式(7)左右两边对τ求导可得
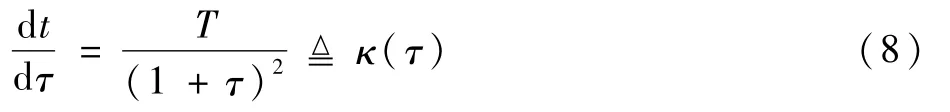
式中:κ(τ)为时变系数。
当t∈[0,T)时,式(4)两边同时乘以式(8)可得

式中:τ∈[0,+∞)。系统(9)即为原系统(4)在时域τ内的动力学表达式。
注1时域映射(6)及其逆变换(7)建立了有限域t和无限域τ之间的双射,这意味着想要解决原系统(4)的给定时间控制问题,只需要在无限域τ上实现转换系统(9)的渐近控制即可。对于转换后的时变系统(9),κ(τ)可视为系统的时变控制系数。因此,为了对系统(9)进行渐近控制,决策指令必须包含增益项1/κ(τ)来补偿时变控制因子κ(τ)的效能损失,而指令的有界性通过乘以更快趋于0的状态量来保证。
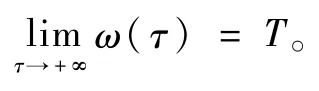
2.2 决策协议
为解决式(1)和式(4)所述给定时间分布式优化问题,直接给出时域t内的分布式协议如下:
由此可见,当代泰国虽然政权更迭频繁,但对文化的产业化培育和国际推广却给以持续的重视。数十年来,泰国形成了文化部、观光与体育部、工业部、外交部、政府公共关系部等多部门共同参与,王室、政府、企业相配合的文化推广体系;文化产业已成为泰国创造经济收益和塑造“微笑国度”形象的重要名片。目前泰国已成功主办了四次亚运会,在亚洲各国中居首位。2017年,泰国接待的国际游客创下了3538万人次的新纪录;[28]其中仅曼谷就可吸引2327万人次的国际游客,在世界城市中名列第二。[29]而截至2018年,泰国已连续四年被彭博社评为“全球最幸福的国家”。
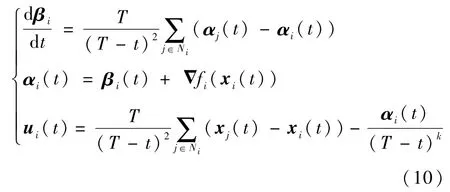
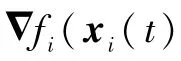

从而当αi(t)达成一致性时,式(11)表明其可实现对梯度平均值的无偏估计。这种引入辅助变量的设计思想类似于文献[15,21]。但本文使用了时域映射方法,与上述文献相比,既避免了使用不连续的符号函数技术,又不需要进行控制增益的选择。
对于给定时间分布式协议(10),有如下定理成立。为使内容结构清晰、便于理解,其证明过程分为一致性与最优性分析放在2.3节和2.4节。
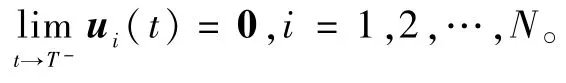
2.3 一致性分析
利用式(6)~式(8)建立的时域t和无限域τ之间的映射关系,不难得到分布式协议(10)在无限域τ内的等价表达式:
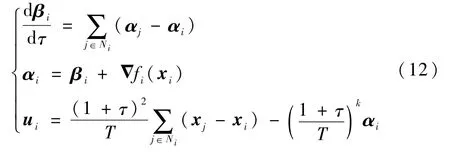
本节研究αi和βi的给定时间一致性,联立式(9)和式(12)可得
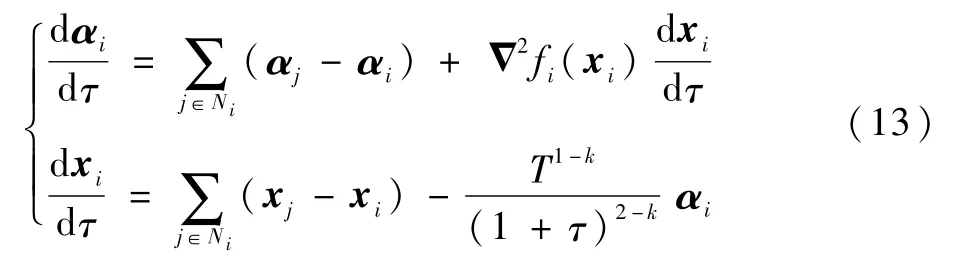
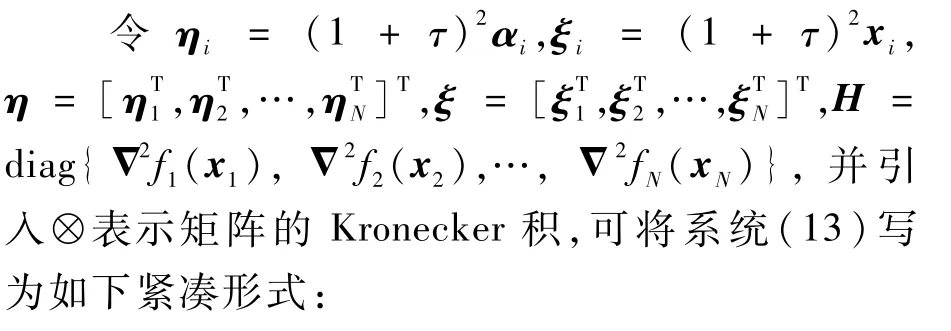
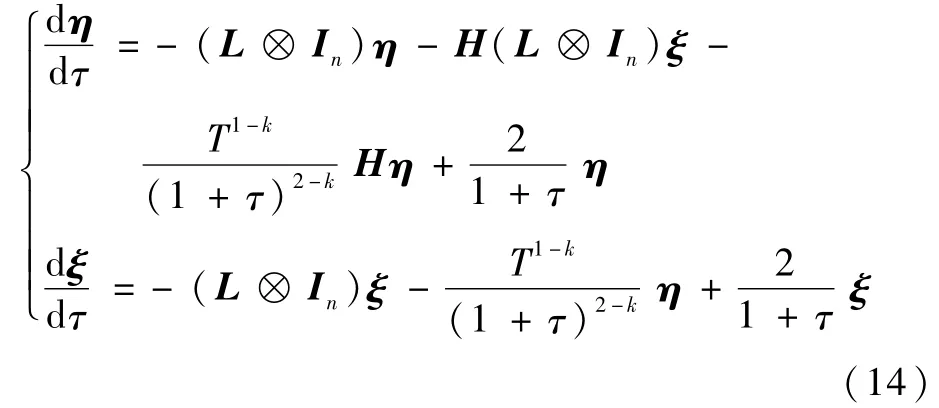
进而考虑如下Lyapunov函数:
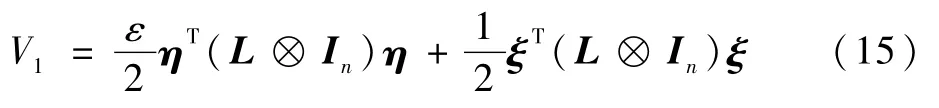
式中:常数ε>0。对式(15)沿式(14)对τ求导,并注意到L⊗In和H都是对称矩阵,有
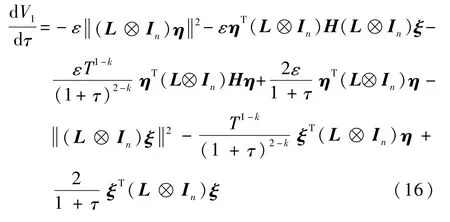
考虑到假设2以及引理1,对称矩阵H和L⊗In分别为正定和半正定的。可证明(L⊗In)H 为半正定矩阵,则
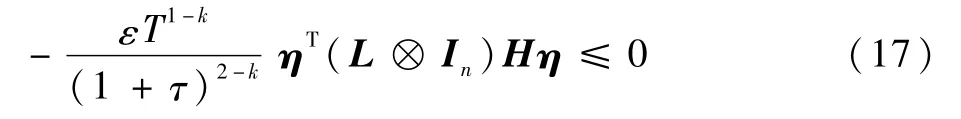
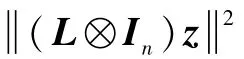

式中:μij∈R。则有
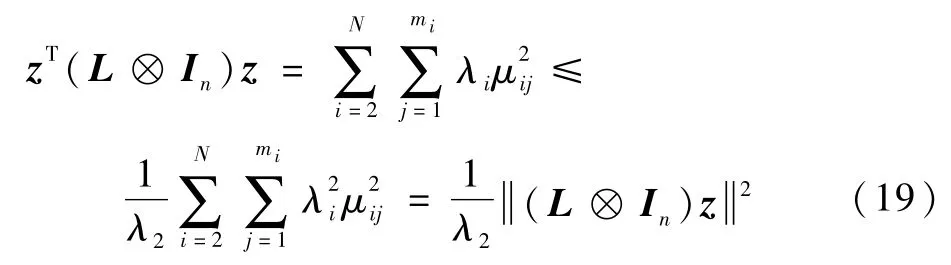
注意到
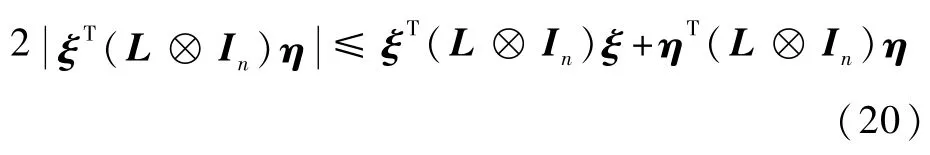
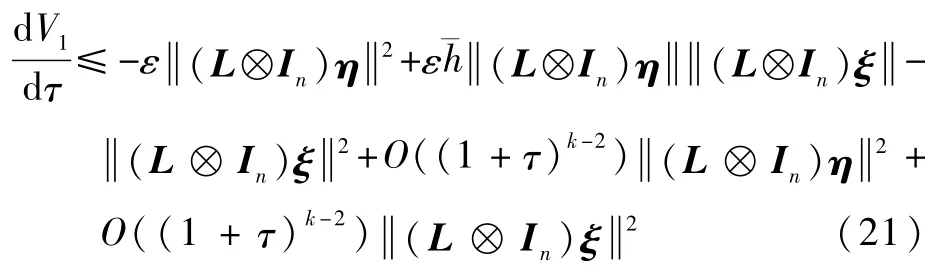
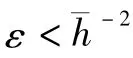
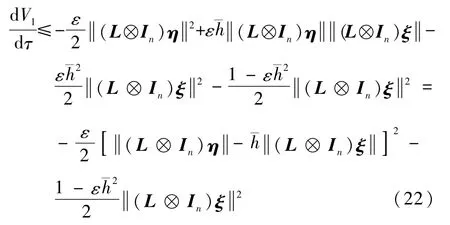

2.4 最优性分析
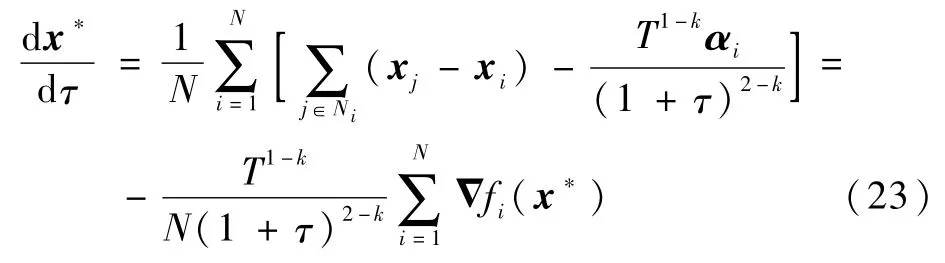
考虑如下Lyapunov函数:
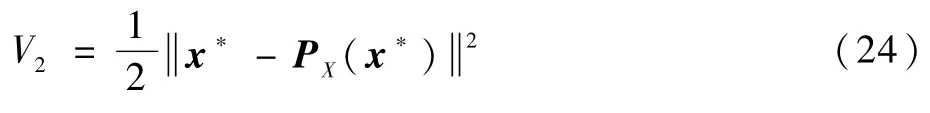
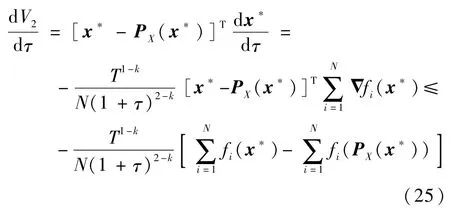


对式(26)两边积分可得
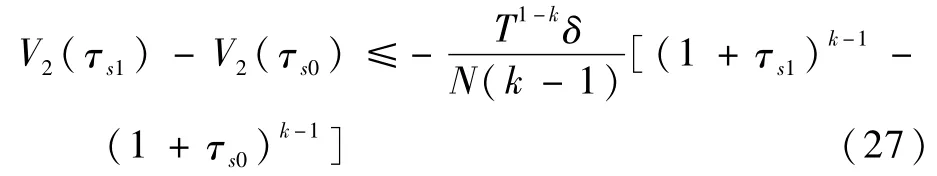
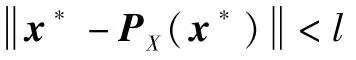
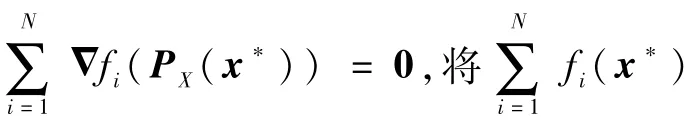
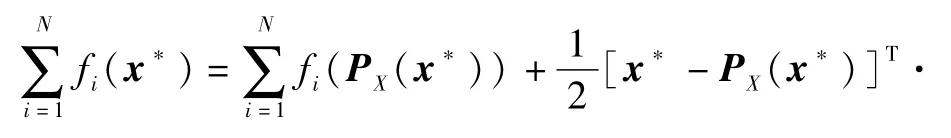
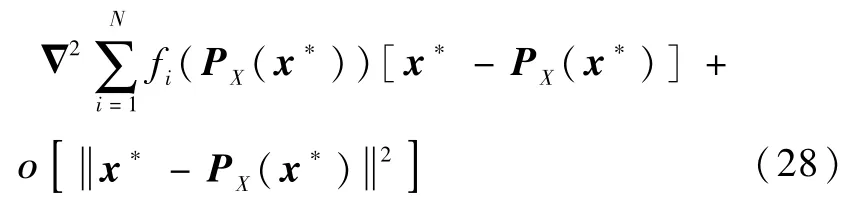
式中:ο(·)表示高阶无穷小。考虑当τ→+∞时的情形,此时x*→PX(x*),根据式(28)和假设2,存在常数C′>0使得
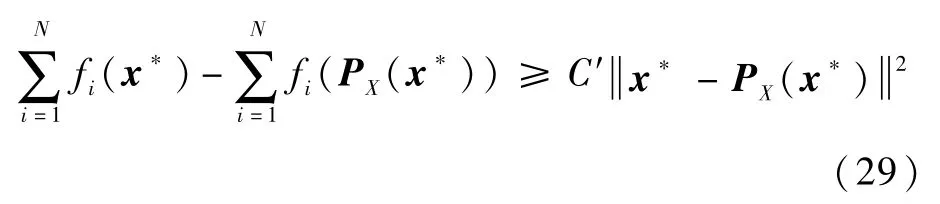
将式(29)代入式(25)可得
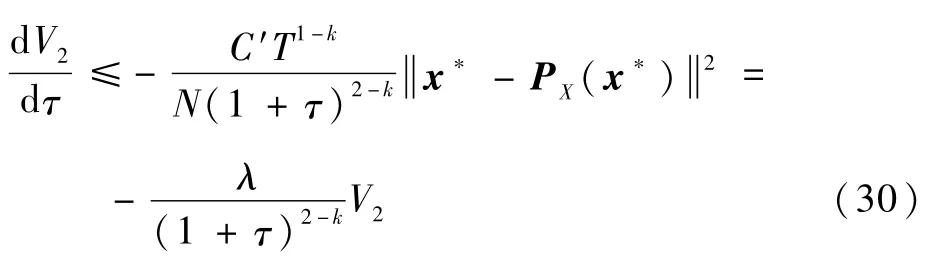
式中:λ≜2N-1C′T1-k。对式(30)两边在(τs0,τ)上积分并整理可得
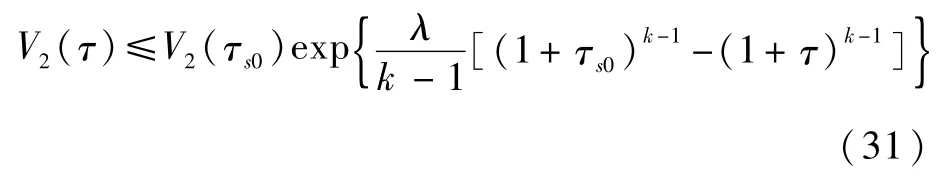
考虑到假设3成立,记
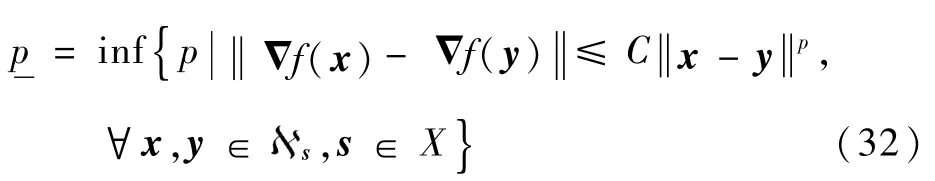
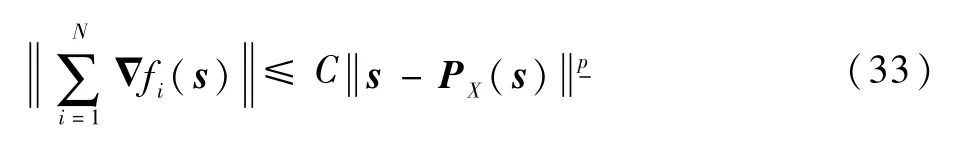
根据式(24)和式(33)可知,当τ→+∞时必满足:
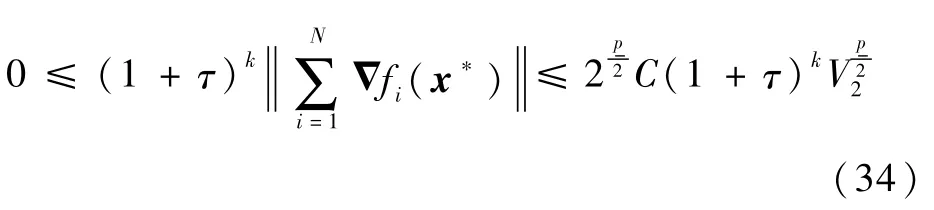
将式(31)代入式(34),并运用夹逼定理可得
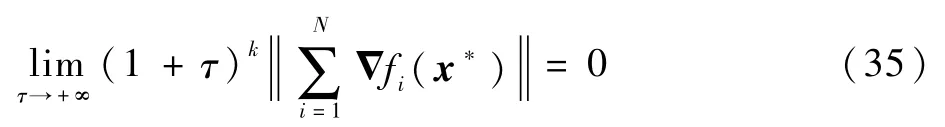
综合式(35)和2.3节中的结果可知
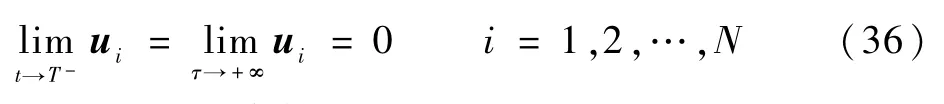
这表明决策协议(10)是非奇异的。
3 仿真验证
为验证本文的主要结论,考虑由5架无人机组成的无人机群,仿真中涉及到的时间、位置和速度单位分别为m in、km和km/min。它们之间的通信拓扑构成无向连通图,对应的Laplacian矩阵为

为使仿真效果直观,考虑多无人机系统在二维平面内的分布式优化问题,从而n=2。给定集结时间为T=5m in,为方便我方5个基地支援补给,假设每架无人机的态势判断函数fi(xi):R2→R分别为
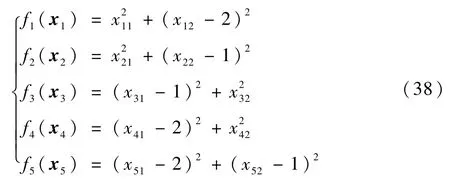
显然,式(37)和式(38)所述问题满足假设1~假设4。每架无人机的初始位置依次取为(-2,4)km,(-2,0)km,(0,-2)km,(4,2)km,(2,4)km。仿真结果如图1~图5所示。
从图1和图2可以看出,所有无人机均在给定时间T=5m in内集结完毕,最终集结地点坐标约为(1,0.74)km,通过对优化函数分析计算可验证上述坐标确为全局最小值点,这表明多无人机系统在给定时间内完成了分布式最优集结。从图3和图4可知,所有无人机决策指令输入保持全局有界,且终值趋于零,表明了本文方法的可用性。图5绘制了整个集结过程中无人机群的航迹示意图以及全局优化函数等高线,航迹曲线光滑平稳。集结过程当中,随着信息的分布式流通,各无人机不断调整修正自身航迹,直至在最优点集结完毕。
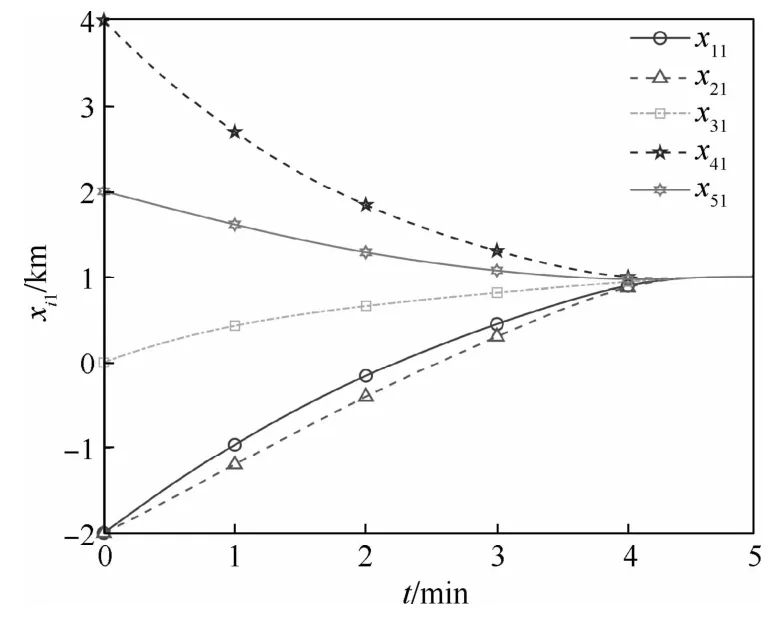
图1 无人机状态响应xi1Fig.1 State response xi1 of UAVs
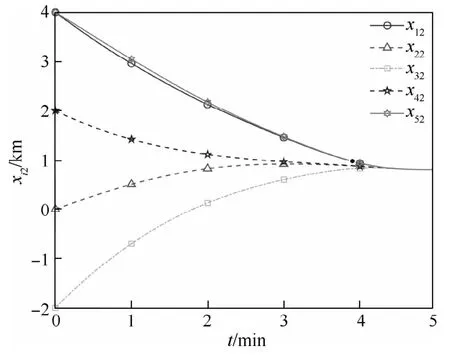
图2 无人机状态响应xi2Fig.2 State response xi2 of UAVs
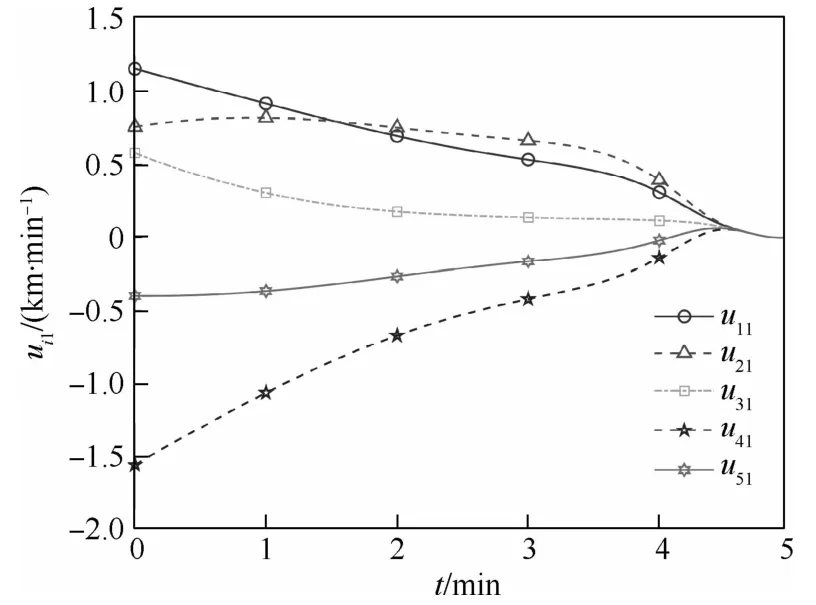
图3 无人机决策指令ui1Fig.3 Decision command ui1 of UAVs
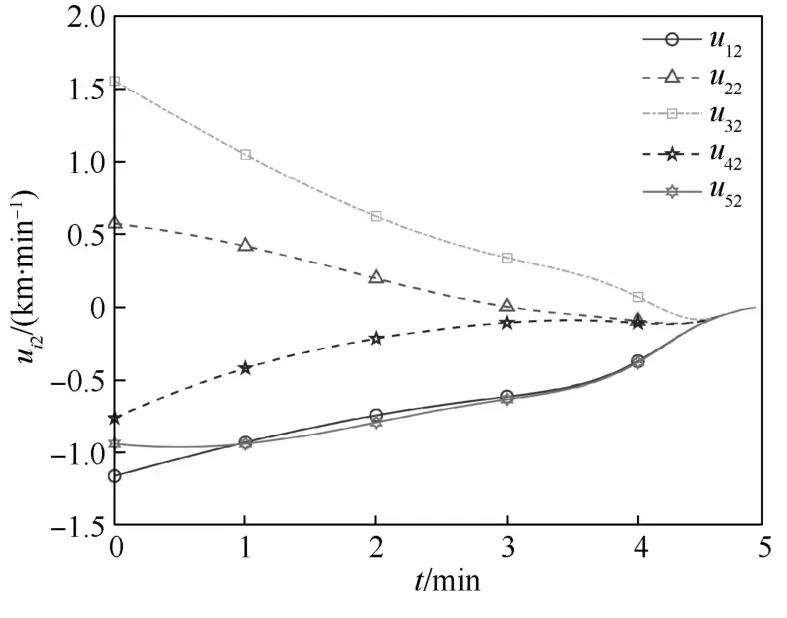
图4 无人机决策指令ui2Fig.4 Decision command ui2 of UAVs
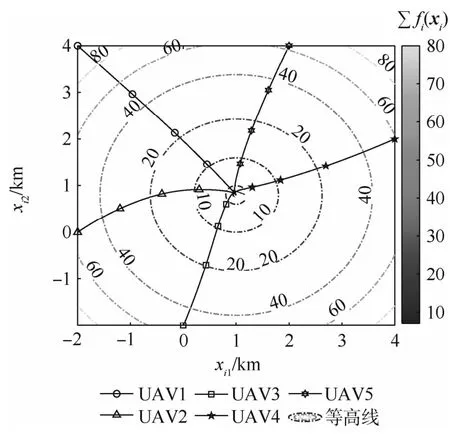
图5 无人机群航迹与全局优化函数等高线Fig.5 Flight path of UAV swarm and contour of global optimization function
4 结束语
本文研究了基于时域映射技术的多无人机系统给定时间分布式最优集结问题。所设计的带时变增益的给定时间分布式优化协议包括2个部分,第1个部分即辅助变量αi(t)和βi(t)的分布式动力学,可针对全局目标函数梯度进行实时估计;第2个部分即分布式决策指令ui(t),它又包括一致性输入以及梯度修正2个部分,通过系数k∈(1,2)使其相互协调。
注意到,本文结果只分析了决策指令的有界性,而对其上界没有定量估计,下一步可研究输入受限条件下的给定时间分布式优化问题。
