融合MobileNet 与GhostVLAD 的欺骗语音检测
2021-03-25闫佳,冯爽
闫 佳,冯 爽
(1.中国传媒大学计算机与网络空间安全学院;2.智能融媒体教育部重点实验室;3.媒体融合与传播国家重点实验室,北京 100024)
0 引言
自动说话人验证技术[1]越来越多地应用在安全领域,但是结果[2]显示它的鲁棒性不是很好,很容易受到各种各样的欺骗。这些欺骗方法主要包括语音转换、语音合成和重放等。为此,ASV spoof[3-5]发起相关竞赛,在自动说话人验证(Automatic Speaker Venification,ASV)方面进行反欺骗研究。ASVspoof 2013 指出这一严重的问题,但没有具体解决方案;ASVspoof 2015 专注于寻找语音合成和语音转换(Logical Access,LA)对策,ASVspoof 2017 专注于区分真实音频和重放音频(Physical Access,PA)方法;ASVspoof 2019则涵盖了LA 和PA,但分为两个子任务,等误差率(Equal Error Rate,EER)是其共同的度量标准。
传统的检测欺骗语音方法是使用常数Q 倒谱系数(Constant Q Cepstrum Coefficients,CQCC)[6]或线性频率倒谱系数(LFCC 特征)和高斯混合模型(Gausssian Mixture Model,GMM)分类器。随着深度学习的发展,卷积神经网络(Convolutional Neural Networks,CNN)表现比直接使用GMM 要好得多。CNN 可以接收低级的手工制作特征输入,随着层数的加深可得到更为高级的特征表示,然后通过某种聚合方式将帧级特征聚合成话语级别特征。端到端的CNN 可通过优化某种损失函数直接得到最终的得分。通过选定一个阈值来确定某段语音是真实语音(得分高于阈值)或是虚假的欺骗语音(得分低于阈值)。但是常用的一些CNN 变体(如Resnet[7]、VGG 等)都有网络层数多、计算量大等问题,存储空间以及能耗方面开销巨大。为此,模型轻量化是目前的研究方向。MobileNet 在对象检测、细粒度分类、人脸识别和大规模地理定位等方面证实它在模型参数和速度方面的有效性。
在说话人识别领域和ASVspoof 领域,常用的聚合方法有平均池化[8-9]、全局平均池化[10]、统计池化[11]、可学习的字典编码池化[12]、注意力池化[13]、注意统计池化[14]等。文献[15]提出一种基于GhostVLAD 的聚合方法,在说话人识别领域能够很好区分不同的说话人。本文是第一个使用GhostVLAD 聚合方法来区分真实语音和欺骗语音的。
之前ASVspoof 2017 和ASVspoof 2019 的参赛者构建了几种不同的检测欺骗语音方案。文献[16]使用TDNN 网络从MFCC 中生成x-vector 嵌入,这些嵌入联合建立27 种环境和9 种欺骗类型模型;文献[17]针对不同特征使用两个VGG Net 的融合网络;文献[18]提出一个有助于多任务学习的蝴蝶单元来传播二进制决策任务和其他辅助任务之间的共享表示;文献[19]从数据增强、特征表示、分类和融合4 个方面优化欺骗检测系统的管道;文献[20]对真实语音与欺骗语音的全局概率累积函数进行实验研究;文献[21]使用高分辨率的频谱图探索既包含幅度信息又包含相位信息和功率谱密度信息的互补信息;文献[22]提出在真实的回放对基础上建立回放设备特征提取器方法。
本文主要贡献有3 点:①设计并实现了一个基于Mo⁃bileNet 的变体模型来执行语音的欺骗检测;②比较两种不同的特征在MobileNet 下的性能;③探索了GhostVLAD 聚合方法在语音欺骗检测中的性能。
1 模型设计
1.1 数据增广
在神经网络训练中,数据增广(Data Augmentation,DA)能够很好地提高模型的鲁棒性。语音数据增广方法主要有两种:①利用外部数据集进行数据扩充,如VoxCeleb、AISHELL[23-24]、CN-CELB[25]等;②利用数据本身,比如添加各种噪音(如背景音乐、嘈杂人声、不同环境音)和混响,进行速度扰动等数据增广。具体为随机使用0.9、1.0 和1.1 系数对ASVspoof2019 数据集中的语音进行速度扰动,随机使用Simulated Room Impulse Response Database 中不同房间的混响设置来添加混响。是否进行速度扰动、是否添加混响、是否保持原样的概率都是1/3,这样数据集就被扩充了1 倍,即整体数据量是原来的2 倍。
1.2 特征提取
CQCC:该方法使用ASVspoof 2019 官方提供的Matlab程序来提取音频的CQCC 特征。CQCC 特征通过常数Q 变换与传统倒谱分析相结合得到。它对一般形式的欺骗语音非常敏感,并在各种特性中产生优异性能。CQCC 的更多详细信息见文献[6]、[26]。
振幅频谱图(Amplitude spectrum diagram,spec):深度神经网络模型的优点是它们能够从原始输入数据中自动学习高级特征表示,这种能力使得深度神经网络模型处理原始输入的性能优于处理人类手工制作的特征性能,故该方法选择比梅尔频率倒谱系数(Mel-Frequency Cepstral Co⁃efficients,MFCC)或CQCC 都要更原始一些的振幅频谱作为输入,希望依靠神经网络将原始输入转换成网络隐藏层中的更高层次表示。该方法使用长度为50ms、偏移量为20ms的汉明窗和2 048 个频率间隔(FFT bin)提取频谱图,使用高分辨率的特征表示,即使用2 048 个频率间隔而不是常用的512 个频率间隔。
该方法没有选择MFCC 或i-vector 作为输入特征,因为他们最初以最大程度区分不同的说话人而设计。另外,有文献指出传统的MFCC 特征可能会丢失一些鉴别真实语音与欺骗语音的信息;文献[27]的实验显示i-vector 效果不好。
1.3 模型结构
传统卷积神经网络如VGG 或Resnet 的内存需求大、运算量大,导致无法在移动设备以及嵌入式设备上运行。MobileNet 是由Google 团队在2017 年提出的,专注于移动端或者嵌入式设备中的轻量级CNN 网络[28]。相比传统卷积神经网络,在准确率小幅降低的前提下大大减少了模型参数与运算量。据文献[28]中的图8 显示,MobileNet V1 相比VGG-16 在数据集ImageNet 上准确率减少了0.9%,但模型参数只有VGG-16 的1/32。MobileNetV2 相比MobileNetV1准确率更高、模型更小[29]。MobileNetV3 则集合了Mobile⁃NetV1 的深度可分离卷积、MobileNetV2 的线性瓶颈逆残差结构和MnasNet 的基于挤压激励结构的轻量级注意力模型等3 种结构优点[30-31]。该方法使用了MobileNetV2(α=1.0,β=224)和MobileNetV3-large 网络来探索其在检测虚假语音方面的效果。MobileNetV2 的基础结构与文献[29]中一致,MobileNetV3-large 的基础结构与文献[30]中一致。
1.4 聚合方法
GhostVLAD[32]是在NetVLAD[33]的基础上提出的,用于人脸识别聚类时自动削减模糊图像的权重。面部图像可能在姿势、表情、光照等各方面质量有所不同。有些人脸非常模糊,对聚类不利,GhostVLAD 会对输入的人脸质量自动计算权重。一般把一些噪声数据自动分配给一个“Ghost”类的想法具有普遍适用性,这种做法可以去除噪声较大或损坏严重的数据。在聚合层也就是GhostVLAD 层中包含了Ghost 类。Ghost 类不利于聚类的样本,高质量的样本信息对聚类贡献很大。Ghost 类增强了网络处理低质量样本能力,提取的嵌入可以软分配到Ghost 类中,但不包括在聚合中。有关GhostVLAD 的公式等详细信息可以参考文献[32]。文献[15]中的实验证实了GhostVLAD 方法在说话人识别中表现良好,探索了其在检测虚假重放语音方面的应用。
2 实验设置
使用PyTorch 实现网络模型,使用带有NVIDIA GPU 的台式机训练模型。数据增强过程使用Kaldi 中的方法,CQCC 特征提取使用Matlab,振幅频谱图则使用Python 中的Scipy.signal.spectrogram。
2.1 数据集
该方法使用ASVspoof 2019 组织者提供的PA 和LA 数据集,它们是从20 名说话者(8 名男性、12 名女性)中以16 kHz 采样率和16 位记录的话语。各个数据集中真实语音和欺骗语音数量见表1,有很大的类别不平衡问题。其中,PA 中的欺骗语音是在27 种不同的录制声学环境和9 种不同质量的重放配置下生成的。LA 中的欺骗语音是根据两个语音转换算法和4 个语音合成算法生成的。LA 测试集包含没有在训练集和开发集中出现的欺骗语音生成算法。
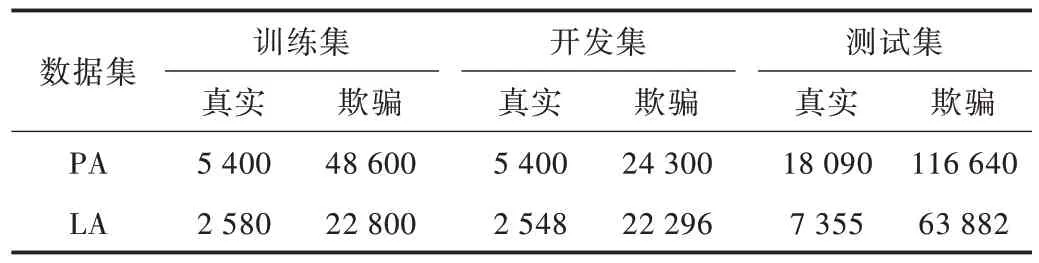
Table 1 Number comparison of real speech and spoofed speech in PA and LA表1 各数据集中真实语音和欺骗语音数量对比
2.2 基线方法
使用ASVspoof 2019 组织者提供的CQCC-GMM 和LF⁃CC-GMM 作为基线系统,更多详细信息可以参考官方主页。官方基线系统是基于20 维LFCC 和30 维CQCC 的,两种方法都提取了静态系数、增量系数和双增量系数,后端是一个二分类的GMM,有512 个分量。
2.3 评估指标
使用等错误率(Equal Error Rate,EER)作为本次实验的评估指标。在选定某个阈值之后,对作为CNN 输出结果的得分可计算出两种错误率,即错误拒绝率和错误接受率。通过调整阈值可以得到这两种错误率相等或最接近的一个操作点,即EER。
2.4 实验过程
由于本次数据中欺骗语音数量远大于真实语音数量,因此在每个batch 的数据采样中会随机选择和真实语音同等数量的欺骗语音进行网络训练,以通过提高epoch 的数量来使用所有数据。
为了适应MobileNet 的网络输入尺寸,使用裁剪长话语或复制短话语的方法得到一个固定大小为224×224 的频谱图,裁剪剩余数据作为一个新的数据加入到原有数据中,在最开始使用1×1 的卷积得到一个3 通道的输入。GhostV⁃LAD 实验则是把网络的最后一个池化层替换成GhostVLAD层,使用文献[14]中效果最好的参数设置,即vlad clusters设为8,ghost clusters 设为2。使用卷积核(即过滤器)的数量来控制vladclusters 和ghostclusters 的数目。
最后的分类层中只有两个节点,表示为真实语音和欺骗语音。在交叉熵损失监督下以端到端的方式优化整个检测系统,最终的话语水平得分可以直接从最后一层输出中获取。
3 实验结果与分析
表2 展示了几个配置不同的模型和基线算法在开发集和测试集上的EER 情况。该方法暂时没有对得分进行融合,只是进行了几个单系统的性能比较。表2 第1-6 行展示在PA 数据集上的实验结果,由最后一列数字可以看出,4 种单系统性能均超过了两种基线系统。性能最好的单系统在第5 行,EER 是6.84,相比基线最好的结果11.04 降低了38%。然而GhostVLAD 方法并没有表现出期望的结果,原因需要进一步探究。
图1 展示了不同配置条件下CQCC 和spec 两种特征在PA 测试集上的性能曲线。横轴为9 种不同的配置,纵轴为EER。模型结构使用的是MobileNetV3-large,聚合方法为Average。每个配置用两个字母命名,第一个字母代表录音设备与真实说话人之间的距离,“A”表示10-50cm,“B”表示50-100cm,“C”表示>100cm;第二个字母表示重放设备的质量,其中A 表示质量非常高,B 表示高,C 表示低。结果表明,随着距离的减小和重放设备质量的提高,反欺骗任务变得越来越困难,在设置“AA”时会获得最差的结果。
表2 中第7-12 行展示了在LA 数据集上的实验结果。由最后两列数字比较可知,开发集的结果与测试集结果相差较大,这可能是由于测试集中包含了更多的未知欺骗类型。在LA 条件下,GhostVLAD 方法要比PA 情况下效果好很多。第12 行含有GhostVLAD 方法的模型在测试集上得到了最佳的EER 7.04,相比基线最好的结果8.09 降低了13%。由于不同的语音转换或语音合成方法可能对不同特征造成不同程度的损失,故需要进一步区分具体情况研究不同的欺骗方法。
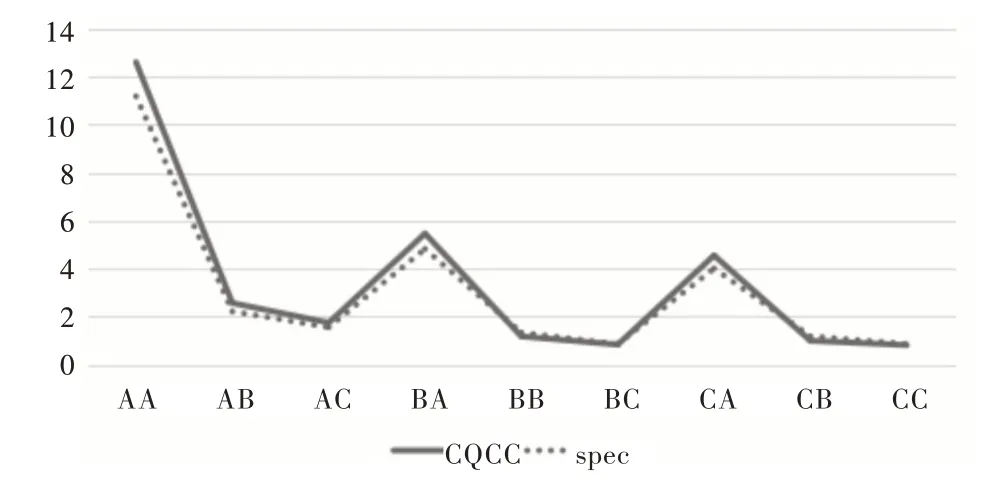
Fig.1 Model performance curves under different playback configurations图1 不同重放配置条件下模型性能曲线
总的来说,经过数据增广后,本文模型在PA 条件下比LA 条件下表现得更好,这可能是由于在PA 中特征来自于录制环境或重放设备,更易于学习和泛化。而在LA 中,特征的不同部分被不同的算法修改,再加上测试数据集中的大多数欺骗类型是未知的,在训练集中没有出现过,因而更增加了模型的挑战性。

Table 2 Score comparison of different model configurations表2 不同配置的得分对比
4 结语
本文将MobileNet 和GhostVLAD 方法应用于欺骗音频检测,可同时适用于PA 情况和LA 情况。结合两种不同的特征对模型性能进行比较。根据ASVspoof 2019 测试集上的结果可知,该模型对重放语言欺骗(PA)将EER 指标降低了38%,针对语音合成或语音转换欺骗(LA)将EER 指标降低了13%。对于GhostVLAD 的超参数选择还需进行更多实验。后续研究方向是如何更好地提高模型对未知欺骗类型的泛化能力。可能的方法有:①使用特征融合技术,把互补的特征拼接起来再输入网络;②对不同的网络进行集成,这样可以训练网络相互协作,获得更好的融合效果。
