图卷积神经网络在中文对话情感分析中的应用
2021-03-25张亚文
杨 青,朱 丽,张亚文,吴 涛
(1.华中师范大学计算机学院;2.国家语言资源监测与研究网络媒体中心,湖北武汉 430079)
0 引言
网络的快速发展推动大数据时代的到来,人们表达情绪的方式逐渐多样化,其中社交网络平台成为最重要的途径。带有情感倾向的文本信息暴增,有效挖掘海量文本的情感信息,并将其应用于实际生活中,是极其重要的研究方向,文本情感识别也成为自然语言处理领域的一个研究热点。
近年来,关于情感分析的研究工作得到许多关注,相关研究人员在文本情感分析方面不懈努力,取得了较大进步。文本情感分析也称为意见挖掘,是对带有情感倾向性的文本进行分析处理的过程。目前,大部分情感分析工作的研究目标是简单的文本,处理这些文本时没有考虑到用户信息,主要的情感分析方法有两种,即基于语义的情感词典方法和基于机器学习的情感分类方法。文献[1]基于大量微博评论文本构造大规模情感词典,用于提高情感分类效率,但分类效果极其依赖情感词典的规模和质量;文献[2]采用支持向量机(SVM)和朴素贝叶斯方法(Naïve Bayesian)在微博评论数据集上进行情感分析,指出基于机器学习的分类方法性能比基于语义的情感词典方法表现更好。
随着长短期记忆网络LSTM、卷积神经网络CNN 以及注意力机制等模型在自然语言领域,特别是在文本情感分析中的广泛应用,注意力机制和神经网络模型的结合使用成为近年来的研究热点。Bengio 等[3]提出将神经网络应用于构造语言模型;Quoc 等[4]在word2vec[5]的基础上提出doc2vec,用于获取句子的特征向量表示;文献[6]对比word2vec 和doc2vec 两种技术在情感分析句子表征中的表现,通过实验证明了doc2vec 技术在句子语序语义表达上的优势;Kim[7]使用卷积神经网络CNN 模型进行文本情感分类;文献[8]提出基于卷积神经网络CNN 结合注意力机制的模型进行文本情感分析;文献[9]使用LSTM 模型提取文本特征,结合情感极性转移模型,并将该模型用于中文文本情感分类;文献[10]使用基于注意力机制和BiLSTM的神经网络模型对中文评论进行情感分析,BiLSTM 提取文本特征,Attention 层用于突出文本分类中的重点信息;文献[11]提出使用双向长短时间记忆网络模型BiLSTM,并基于词向量对中文文本进行情感分析;文献[12]使用双向门控循环单元BiGRU 进行中文文本情感分析,一定程度上提升了分类效果;文献[13]将BiGRU 模型和注意力机制相结合,对文本情感进行极性分类,验证了BiGRU-Attention模型的有效性;文献[14]使用BiGRU 神经网络和卷积最大池化的混合模型提取文本特征信息,从而进行文本情感分类,取得了较好效果;文献[15]使用BiGRU 提取对话句子表征,指出对话中的信息主要依赖于话语中的序列上下文信息;文献[16]构建CNN 和BiGRU 混合模型用于提取文本局部特征,从而对中文文本进行情感分类。
然而,目前大多数用于文本情感分析的模型存在同样问题,大部分模型忽略了对话中的意图建模,以及话题及说话人个性等因素在对话情感中发挥的作用。从理论上分析,RNNs、LSTM、GRU 等网络模型,可以传播长期的上下文信息,然而在实际应用中,这些网络模型可能并非总是这样,从而影响到RNN 模型在其它相关任务中的有效性。
不同于传统的网络模型LSTM 和CNN,图卷积神经网络在处理广义拓扑图结构上发挥着重要作用,能够深入挖掘不规则数据的特征和规律。图卷积神经网络作为一种新兴的网络模型,在许多领域都有所应用,文献[17]提出将图卷积神经网络GCN 应用于长文本分类问题;文献[18]将关系图卷积神经网络RGCN 用于实体分类;文献[19]在英文对话数据集上将GCN 用于情感识别。社交网络中人际关系的不规则性充分反映出图结构应用的重要性和多样性,而图卷积神经网络的广泛应用则体现该模型在不同类型领域中的可利用性。
在对话情感分析中,如果充分考虑说话者之间的情绪影响,对话文本情感分析的准确率会有所提升,而采用图结构的形式刻画说话者对应话语之间的关系是一种十分方便且直观的方式。图卷积操作可以通过聚合每个节点的邻居节点特征而获得该节点的聚合特征表示,进而用于分析说话者的情感在对话文本情感分析中产生的影响。
在实际生活中,用户之间的情感交互可能对文本的情感类别产生一定影响,对话文本的情感识别依赖于用户之间的情感状态,即参与对话人员相互间的交流会影响到对方的情绪和状态。对话情感识别是识别对话中说话人所说语句的情绪,本质上也可以归纳为文本分类问题,在预先定义好的情绪类型中,为对话中的每一句话确定其情感类别。
本文使用BiGRU 提取文本特征向量,提出将图卷积神经网络GCN 用于对话文本情感识别中,充分考虑参与对话人之间的情感交互,结合两种上下文信息获取更好的文本表征,最后用于文本情感分类。得到的实验结果证明,相较于目前分类方法,BiGRU 结合GCN 模型的方法具有更好的情感分类性能。
1 对话中的图卷积神经网络设计
本文思想是:首先,BiGRU 用于提取对话文本的序列上下文特征;然后,将对话语句按顺序构造一个有向图,GCN 通过聚合局部邻居节点信息,提取说话者级别上下文编码特征;最后,结合两个不同的特征向量,对对话文本进行情感分类。
建立说话人之间依赖关系模型的关键是说话人的信息,这使得模型能够理解说话人如何影响其他说话人的情绪状态。此外,说话人内部或自我依赖有助于理解个体说话人的情感惯性,由于这种惯性,说话人会抵抗外部因素对自身情感产生的影响。并且,目标话语和上下文话语的相对位置决定了以前说过的话如何影响未来话语。
本文中对话情感识别方法的框架大体上划分为3 部分,如图1 所示,分别是:①序列上下文编码器,其作用是提取对话文本的序列上下文信息;②说话人级别上下文编码器,用于提取对话中与说话者有关的上下文特征;③情感分类器,通过结合两种上下文特征表示,采用基于相似度的注意力机制获取最终的语句特征表示,输入全连接层进行情感分类。
对话情感识别的上下文信息主要有两种,即序列上下文和说话人级别上下文。在对话过程中,情绪学研究表明,造成情绪波动的因素主要是相互依赖性和自我依赖性,其中相互依赖性指说话人之间产生的情感波动影响,说话者在对话过程中存在感知并吸收对方情绪的倾向,参与对话人的情绪会相互影响;而自我依赖性则指说话者在对话中自身情绪对自己的情感影响,这是一种情感惰性,会导致说话者保持一种情绪。总而言之,这两种依赖性相互作用、相互干扰,共同影响参与对话人的情绪状态。因此,结合两种不同但相关的上下文信息,可以获取更好的文本上下文表示,从而提高对话情感识别效率。
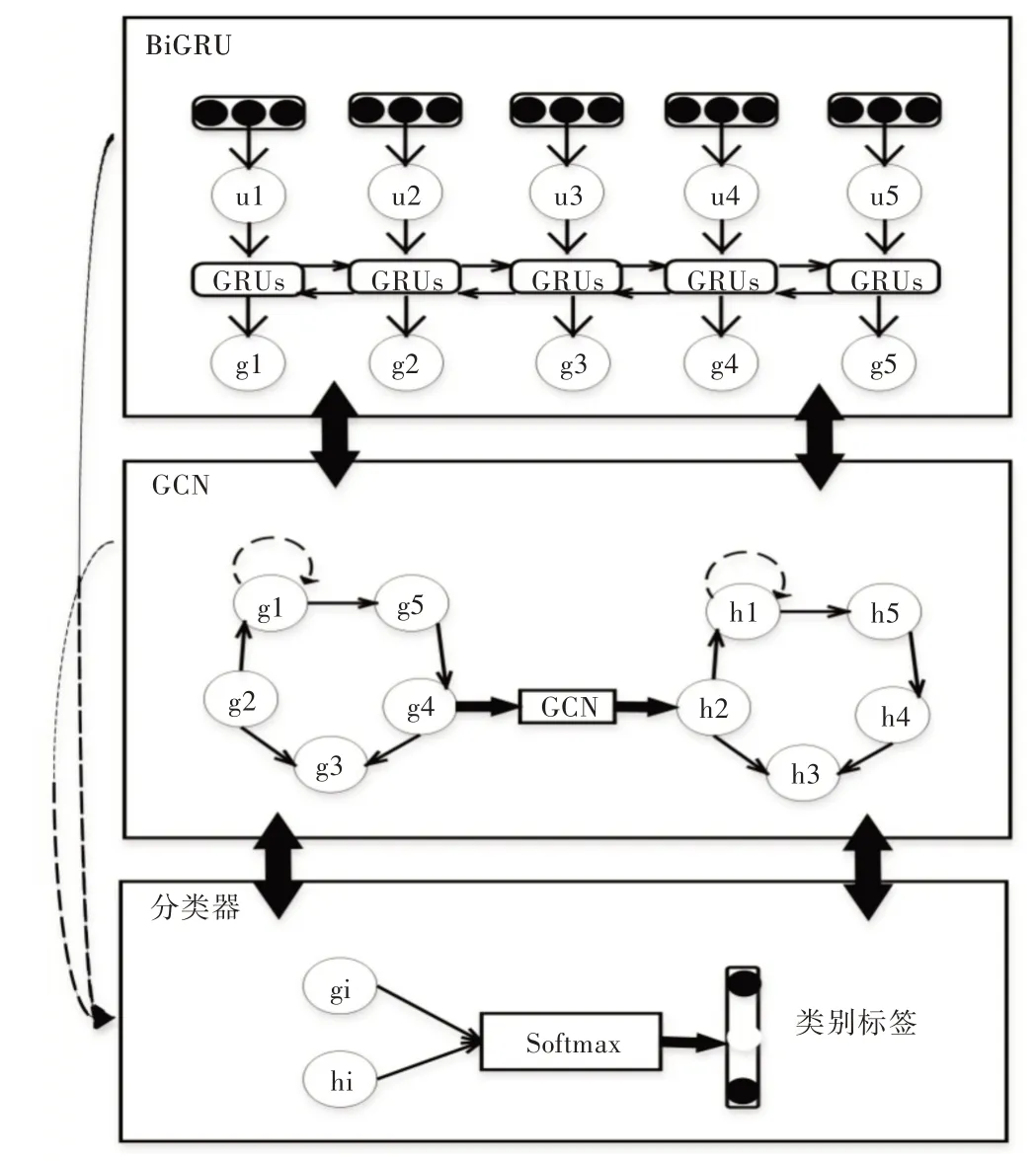
Fig.1 Model of dialogue emotional analysis network图1 对话情感分析网络模型
2 对话文本情感分析网络模型
假设构造一段对话,统计参与对话的人数为X,表示为e1,e2,…,eX,这X个人在对话中总共说了Y句话,表示为u1,u2,…,uY,ut∈RDY是每段语句的初始特征向量表示,ut对应的说话人是es(ut),s是话语与其对应的说话人索引之间的一个映射。对话文本情感分析的最终目的是预测对话中每个话语对应的情感类别。
2.1 序列上下文编码器
由于对话本质上是连续的,故对话中话语的上下文信息对于话语的情感分析具备一定的参考价值。GRU 模型[20]是LSTM 模型的一个经典变体,在效果一样的条件下GRU 模型比标准的LSTM 模型更简单。BiGRU 的基本思想则是利用两个GRU 分别处理正向和反向序列,通过将输出连接到同一个输出层,以记忆序列上文信息和下文信息,充分提取文本的所有信息。总之,BiGRU 不仅可以记忆上下文信息,而且结构相对简单。因此,本文使用BiG⁃RU 提取对话文本信息特征,以获取对话句子的序列上下文表征,过程如式(1)—式(3)所示。
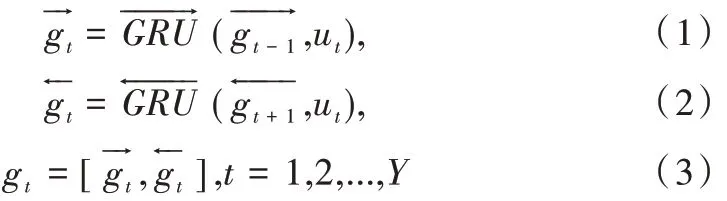
其中,ut是与上下文无关的初始话语表示,和分别是正向GRU 和负向GRU 的输出,gt是包含序列上下文信息的话语表示。
两个单向且方向相反的GRU 构成BiGRU 网络模型,输出由两个不同GRU 的状态共同决定。BiGRU 的具体结构如图2 所示。

Fig.2 Sequential context encoder图2 序列上下文编码器
2.2 说话人级别上下文编码器
为了有效获取对话序列语句中的说话人级别上下文信息,本文构造一个有向图刻画对话者之间的情感交互关系,并利用基于空间域的图卷积神经网络模型得到包含说话人级别上下文信息的文本表征,说话人级别上下文编码器具体结构如图3 所示。
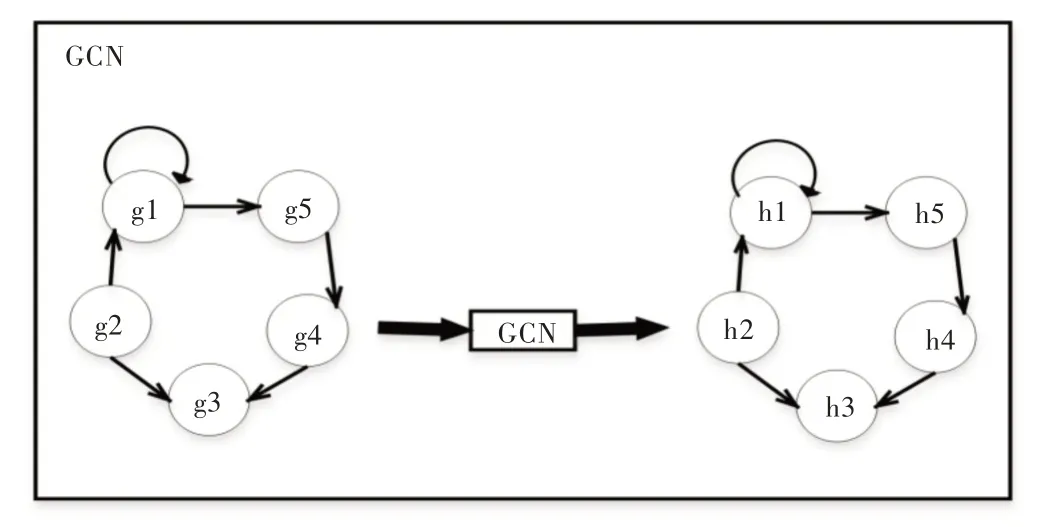
Fig.3 Speaker level context encoder图3 说话人级别上下文编码器
有向图:构造一个有向图G={V,E,R,W}用于表示对话,V 表示节点集合,E 表示边集合,每一个话语表示为一个节点vt∈V,t=1,2,…,Y,初始化特征向量表示记为gt;节点vt和节点vs之间的边记作rts∈E,r∈R 表示边的关系类型,边的关系类型取决于说话人类别和话语时间顺序两个方面,即vt和vs分别对应的说话人es(vt)和es(vs),还有节点语句vt和vs的先后顺序。
示例1 假设一段对话仅包含两个说话人e1和e2,且总共有5 句话v1、v2、v3、v4、v5,则整个对话构造出的有向图如图4 所示,且所有关系类型如表1 所示。
边权重wts∈[0,1]且wts∈W,t,s=1,2,…,Y,使用基于文本相似性的注意力模型设置边的权重,即对于每一个节点,输入边的权重全部加起来为1,考虑到每个节点语句之前的m句话vt-1,vt-2,…,vt-m和之后的n句话vt+1,vt+2,…,vt+n,节点vt和节点vs之间边的权重具体计算如式(4)所示。

Fig.4 Constructed directed graph for example 1图4 示例1 构造的有向图

式(4)中,softmax 函数确保了节点vt与节点vt-m,…,vt,…,vt+n之间输入边的总权重之和为1。

Table 1 Relation types of sample graphs表1 示例图的全部关系类型
图卷积神经网络模型GCN 通过聚合每个节点的局部邻居节点特征信息,使用两步图卷积操作将与说话人无关的节点特征向量gt转换为与说话人信息有关的新的特征向量表示ht,计算方法如式(5)和式(6)所示。

其中,σ是一个激活函数,可以设置为ReLU 函数,为变换参数,wts、wtt∈W,表示关系r∈R中节点vt的邻接指数。式(5)、式(6)有效地聚合图中各语句节点的局部邻域说话人信息,并且自连接的边也确保了自相关特征转换。
2.3 情感分类器
情感分类器结构如图5 所示,先将包含序列上下文信息的特征向量gt和与说话人信息相关的特征向量ht连接起来,再通过基于相似度的注意力机制获取新的对话文本特征表示,最后使用全连接层对话语进行情感分类,得到文本对应的情感类别标签xt。
如式(7)所示,将两种上下文特征向量表示gt和ht连接起来。如式(8)、式(9)所示,将连接的文本向量表示采用基于相似度的注意力机制转换为最终对话文本特征表示。


最后,如式(10)、式(11)所示,将新的语句特征表示输入到全连接层,softmax 层对文本语句的情感进行多分类,根据式(12),得到最大概率的情感标签xt。

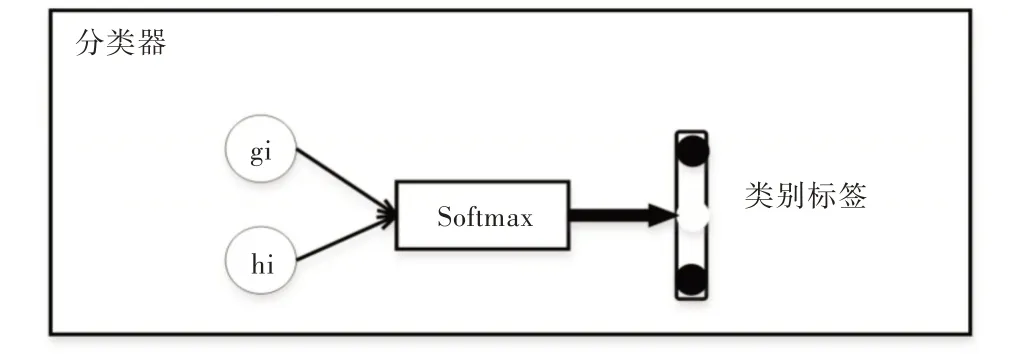
Fig.5 Emotion classifier图5 情感分类器
3 实验
本文算法实验环境是基于Windows 10 操作系统,硬件为英特尔i5 6200U CPU,采用深度学习框架PyTorch,版本号为1.0,在Python 3 运算环境下进行算法实验。
3.1 实验数据集
本文实验选取的实验数据集是一个通过爬取大量学习网站的对话练习内容而收集到的英文语料库dailydialog(http://yanran.li/dailydialog),原始数据包含大约11 318 个对话,选取其中部分语料集翻译为中文,用于中文对话情感分析研究,节选的中文语料库包含大约600 个对话,对话平均有10 轮,语句规模大约为6 000 句,语句标注的情感类别有7 种,分别是中立、愤怒、厌恶、恐惧、幸福、悲伤及惊喜。
本文选取的dailydialog 语料库主要由日常聊天场景中两个人的多轮对话构成,其中日常对话涉及生活中的多个主题,话题比较丰富,这些对话语句包含极其丰富的情感信息,且基本符合人类的对话方式,适合用于对话文本情感分析研究,dailydialog 语料库具体示例如图6 所示。

Fig.6 Examples of dailydialog dataset图6 dailydialog 数据集示例
3.2 数据预处理
对文本数据进行预处理,一般而言,符号对算法没有很大意义,为了减少噪声干扰,首先使用正则表达式过滤掉文本中的无用标点符号,然后采用Python 中的结巴分词库对实验数据集中文文本进行分词处理,最后基于预训练的词向量,使用Doc2vec 工具[21]将文本向量化,获取文本语句的特征向量表示,得到的输入句子向量将用于本文模型训练。
3.3 句子向量维度选择
为了更好地进行算法实验,本文对输入样本的长度进行分析,假设选取数据集样本长度的最大值为maxL,那么当样本长度小于maxL时,样本需进行填充零向量操作,使样本长度达到最大值,而当样本长度大于maxL时,则需舍弃样本多余部分,截断过长的样本。
样本长度最大值maxL的选取关系到实验结果的好坏。当maxL设置较大时,样本数据零向量填充过多,而maxL设置较小时,样本数据舍弃的信息过多,因此,maxL大小的设置可能对模型性能产生一定影响。本文通过设置不同的maxL,观察对比maxL的大小对模型性能造成的影响,F1 值随样本长度变化情况如图7 所示,且实验结果差异如表2 所示。
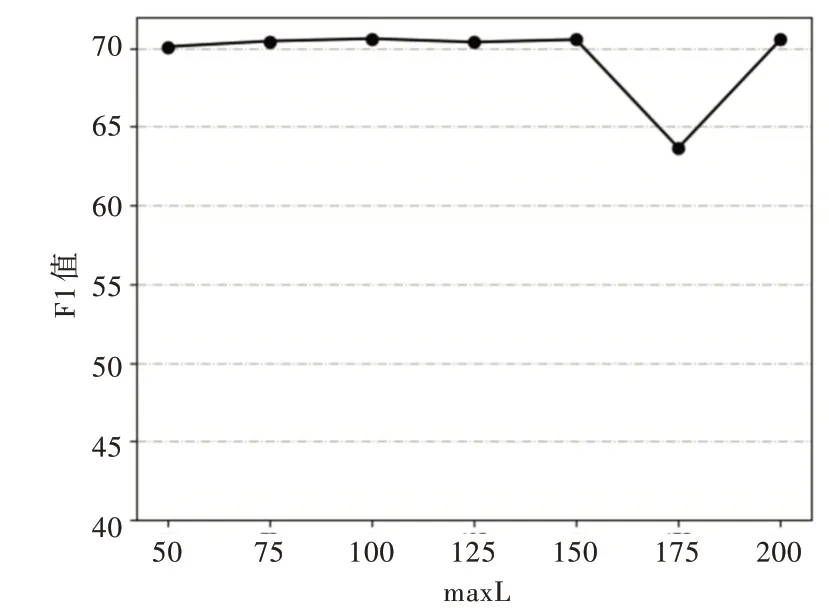
Fig.7 Effect of maxL on F1图7 maxL 值大小对F1 值的影响
观察图7 和表2,可以发现当maxL设置小于100 时,F1 值相对较低,这是由于样本数据舍弃的信息过多,当maxL取100 时,F1 值达到最高点,为79.54%,当maxL大于100 时,F1 值均有所降低,模型性能下降,且F1 值在maxL为175 时取得最低值,只有63.66%,因为maxL设置过大时,样本数据填充的零向量过多,对数据特征造成干扰。

Table 2 Experimental results of different maxL表2 样本长度对实验结果的影响
因此,本文模型选取maxL的值为100 最为合适。
3.4 模型训练
本文实验使用L2 正则化度量训练过程中的损失,并采用基于随机梯度下降的Adam 优化器[22]对模型进行优化。为避免网络模型训练过程中出现过拟合现象,采用Dropout 策略,将丢弃率的大小设置为0.5,并结合10 折交叉验证进行实验。
3.5 实验结果与分析
在构造上下文语句的有向图时,语句节点与其之前和之后的若干个语句节点之间存在构造的边关系,本文实验通过改变上下文窗口的大小,发现在dailydialog 数据集上,F1 值的大小随着上下文窗口的大小而变化,如图8 所示,窗口设置小于2 时,模型性能表现较差,当窗口设置值大于2 时,性能表现稳步上升,出于对实验数据集中对话轮数以及计算上的考虑,本文实验设置窗口大小为5 即可。

Fig.8 Effect of different window sizes on F1图8 窗口大小对F1 的影响
本文将BiGRU+GCN 与CNN、BiLSTM、BiGRU 等模型进行对比分析,在dailydialog 中文语料库上的情感分析实验结果如表3 所示。

Table 3 Experimental results of different models表3 不同模型的实验结果
观察各模型实验结果,可以看出在dailydialog 数据集上,与BiLSTM 模型相比F1 值提高了15.69%,与BiGRU模型相比F1 值提高了14.87%。相比于CNN、BiLSTM 等模型,BiGRU 结合GCN 的混合模型在对话文本情感识别方面的准确率明显有所提高,且F1 值高达70.61%,整体分类效果表现更佳。
根据表3 可知,与其它模型相比,BiGRU+GCN 模型不仅可以提取文本序列上下文特征,还能够充分考虑文本对应说话人的情感信息交互,获取更好的对话文本情感特征,从而在分类效果上表现更佳。在没有上下文语境的情况下,比如“是的”“好的”等一些简短语句的情感类别被认为是中性词,但在实际语境中其情感类别可能不是中性的,而BiGRU+GCN 模型可以避免这种错误分类情况,提高对话文本情感分类准确率。
4 结语
本文充分考虑说话人之间的情感交互,利用图卷积神经网络GCN 提取与说话者相关的文本特征,再结合BiG⁃RU 模型提取文本序列特征,将两者连接起来,以提高对话语句情感分析中的上下文理解能力,有效识别对话文本中的情感类别。实验结果证明了该模型的有效性,与其它方法相比,该模型在对话情感分析中表现出良好的分类效果。本文将图卷积神经网络用于对话文本情感分类,因此只关注实验数据集中的文本信息,多模态情感识别则有待进一步研究。
