GPU 并行计算在雷达信号处理中的应用
2021-03-25杨千禾
杨千禾
(西安电子工程研究所,陕西西安 710100)
0 引言
随着电子反侦察技术的完善,雷达面临着难以捕捉目标、工作环境复杂、多样化的工作模式和多功能一体化的发展模式。不论从研发角度还是从用户需求角度都对雷达系统提出了越来越高的要求,雷达技术必须与时俱进。
现代雷达技术发展有两个重要方向:①合理利用能量,高效获取信息;②快速适应需求,有效灵活扩展。
目前大量使用的数字阵列雷达以功能为核心,导致雷达型号众多,软件与硬件关联性强,不利于雷达升级和扩展;研制周期长、开发效率低等问题成为雷达使用性能提升瓶颈。在这种环境下,“软件化雷达”概念孕育而生。软件化雷达采用“以软件技术为中心,面向需求”的开发模式,主要思路是通过雷达系统中软件和硬件的解耦[1],使雷达系统能够基于软件化开发模式灵活实现系统功能定义、资源配置、模式扩展和性能提升,以不断满足实际需求[2]。
传统雷达信号处理机使用现场可编程门阵列(Field Programmable Gate Array,FPGA)和数字信号处理器(Digi⁃tal Signal Processing,DSP),其计算速度虽然能够满足要求,在计算上也较为精确,但与FPGA 和DSP 的软件程序复用性较低,程序调试困难。而仅使用中央处理器(Central Pro⁃cessing Unit,CPU)作为计算核心的信号处理机,受限于CPU 时钟频率和内核数目,在处理实时数据时面临着系统资源消耗过多、性能下降等问题。
为进一步提升雷达系统计算能力,同时降低后续程序调试难度,实现雷达软硬件解耦,增强雷达的可重构性,本文使用图形处理器(Graphics Processor Unit,GPU)代替DSP和FPGA 作为雷达的计算核心,组成GPU+CPU 的异构平台作为新型的雷达信号处理系统架构。GPU 内含统一计算设备体系结构(Compute Unified Device Architecture,CU⁃DA),开发人员可使用C 语言对GPU 进行编程。在CUDA下开发的软件具有很强的可移植性,可满足所有计算能力在GPU 上直接运行。
1 CPU+GPU 架构信号处理机
当前雷达信号处理机架构实现方式主要有3 种:
(1)基于专用DSP 的分布式信号处理架构。该架构由多个计算板卡组成,每个板卡内含多个DSP 处理器,板卡数量和处理器数量由实际计算资源需求决定,雷达信号处理机通过板卡之间的协同计算实现应用程序开发[3]。该架构优点是系统功耗低,能够适应不同规模的信号处理需求;缺点是软硬件解耦能力差,单节点计算能力低,需要在系统数据分发、多节点同步处理和分布式实时通信方面进行技术攻关。
(2)实现方式为基于多核CPU/PowerPC 的分布式信号处理架构[4]。此架构因为有MKL、VSPL 等计算加速开发工具包和准实时的操作系统作支撑,所以开发人员只需完成雷达信号处理应用层软件的设计[5],此方式提升了软硬件解耦能力,降低了软件移植难度,开发效率显著提高。主要难点是单节点计算能力不够强大,需要在多节点间进行数据分发、同步处理和实时通信[6]。
(3)基于CPU+GPU 的异构处理架构。主要优点是超强的单节点计算能力与较低的经济成本,高效的软件开发效率和支持智能化开发工具包。
1.1 超强计算能力和较低经济成本
相较于DSP/CPU/PowerPC 等处理器,单节点的GPU 具有更强大的浮点计算能力。单个6U VPX 结构的GPU 刀片最高可支持的单精度浮点处理能力达6.1Tflops(Tesla P6),约等于48 片TMS320C6678 的计算量,大大减少了计算节点,降低了系统复杂程度,减少了处理流水延时,如表1 所示。

Table 1 Comparison of floating point processing capacity of main devices表1 主要器件浮点处理能力对比
对于大型数字阵列雷达,需要同时形成多个不同指向的数字接收波束,完成对指定发射空域的覆盖[7]。因此,需要配备计算能力强大的信号处理机。由于功耗和面积限制,1 块6U 板卡最多支持8 片TMS320C6678 的多核DSP 处理器;或者是1 片E5-2648LV4 的CPU 处理器,单板浮点处理能力为896Gflops;亦或是最多支持4 片T4240 处理器,单板浮点处理能力为768Gflops。虽然1 块6U 板卡只能搭载1个MXM 接口的Tesla P6 GPU,但这个板卡的计算处理能力可达6.1Tflops。
1.2 软件开发高效率
相较于DPS/FPGA 动辄十几分钟甚至一个小时的烧写时间,GPU 软件编译仅需几秒,程序调试几乎支持所有的C/C++集成开发环境,摆脱了仿真器束缚,大大增加了灵活性。与CPU/PowerPC 的处理平台相比,单节点处理能力更强,板卡数量大大减少,减少了节点之间的数据传输,使系统复杂程度降低。目前市场上的计算级GPU 以英伟达公司的板卡为主,CUDA 驱动的向下兼容和向上兼容都较稳定,使CUDA 程序具有较好的可移植性,避免再次开发相似功能,节省了人力资源,降低了开发难度,提高了开发效率。在面对更大计算需求时可以灵活扩展或升级GPU 卡。
1.3 支持智能化开发工具包
近年机器学习的兴起对高性能计算需求越来越大。GPU 作为目前机器学习的核心载体在市场需求推动下快速升级,不断推出更强大的计算能力和更优良架构的GPU。
最新的GPU 不仅支持神经网络算法,还支持Caffe、TensorFlow 等深度学习框架,这些机器学习算法在雷达目标识别技术中的应用是当前和未来研究的重点。GPU 能够快速完成机器学习算法从训练到部署的全过程,非常适合未来雷达向智能化方向发展。
2 GPU 并行优化关键技术
GPU 高效计算的关键在于软件的优化加速。对于计算密集型、可并行性较高的程序,使用CUDA C 对已有的串行代码在GPU 上进行并行复现能获得很好的加速效果。对串行程序并行化的方法有两种:①对一个完整的项目程序进行并行加速,将所有计算步骤放在GPU 完成;②将项目程序中包含大量的计算密集型算法提取出来,单独导入GPU 进行计算。一般情况下采取后一种方式对程序进行加速,这样可在最短的时间内获得好的加速性能。但是要充分发挥GPU 强大的计算能力还需要对程序性能进行调优[8]。CUDA 程序实现只是完成了CUDA 加速工作的一小部分,要达到CUDA 加速的最终目的必须优化CUDA 程序[9]。
2.1 CUDA 程序优化准则
针对CUDA 程序进行优化需要采取一定的策略。绝大多数的GPU 应用程序优化方法具有较高的优先级别,但那些针对特定环境下的优化手段要在较高优先级别优化完成之后再做调整[10]。图1 列出3 个优先级中常见的几个优化项。
相对于GPU 动辄达到Tflops 级别的单精度计算能力,GPU 存储带宽大多是GB/s 级别。以英伟达的Tesla P6 显卡为例,其单精度浮点计算能力为6.1Tflops,存储带宽为192GB/s。要想在Tesla P6 上获得峰值的计算性能,程序的计算访存比需要达到22.25。所以,访存优化成为GPU 性能优化的研究重点。
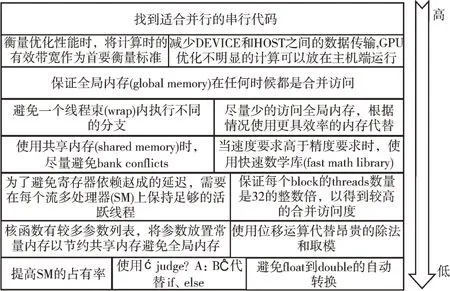
Fig.1 Priority of CUDA program optimization strategy图1 CUDA 程序优化策略优先级
2.2 全局内存的对齐与合并
全局内存(global memory)是GPU 中存储空间最大、使用频率最多的内存[11]。当线程束向内存加载数据或从内存中读取数据时,传输带宽效率一般只与跨线程的内存地址分布和每个事物内存地址的对齐方式这两点有关[12]。一般来说,数据传输过程中内存请求越多,未被使用的字节被传回的可能性就越高,会导致数据吞吐量降低。
所有的全局内存访问都会通过二级缓存(32Byte 内存事务),有些内存访问会使用速度更快的一级缓存(128Byte内存事务)。当设备的内存事务首地址是32Byte(仅使用二级缓存)或者128Byte(使用了一级缓存)的偶数倍时,就可实现对齐内存访问[13]。在一个线程束中所有32 个线程访问一个地址连续的内存块时就能实现合并访问[14]。
因此可将全局内存中的数据大小尽量整合成32Byte的整数倍以增加数据对齐的灵活性。对于无法整合的数据如结构体,其尺寸和对齐要求可使用对齐修饰符__align__(8)或__align__(16)被编译器保证。如果受实际情况限制无法实现数据对齐或者间隔访问,就要充分利用共享存储器来避免程序性能下降。
2.3 共享内存访问冲突与避免
共享内存是位于GPU 流处理器(Stream Processor,SM)中的低延迟内存池,该内存池被线程块中的所有线程所共享[15]。在物理层面共享内存接近SM,因此相较于全局内存而言延迟要低大约20~30 倍,而带宽高大约10 倍[16]。
在调用共享内存时,线程会通过32 个存储体(bank)进行访问。当线程束中的多个线程在同一Bank 中访问不同地址数据时会发生存储体冲突(bank conflict)[17],导致线程对共享内存重复请求,所以多路存储体冲突会造成访存阻塞,降低计算性能并影响带宽利用率[18]。解决这种存储体冲突的方法是在每N 个元素之后添加一个字,这里的N 是存储体数量。由于对内存数据进行了填充,之前属于同一个bank 的存储单元现在被传播到了不同的存储体中,改变了从字到存储体的映射,如图2 所示。
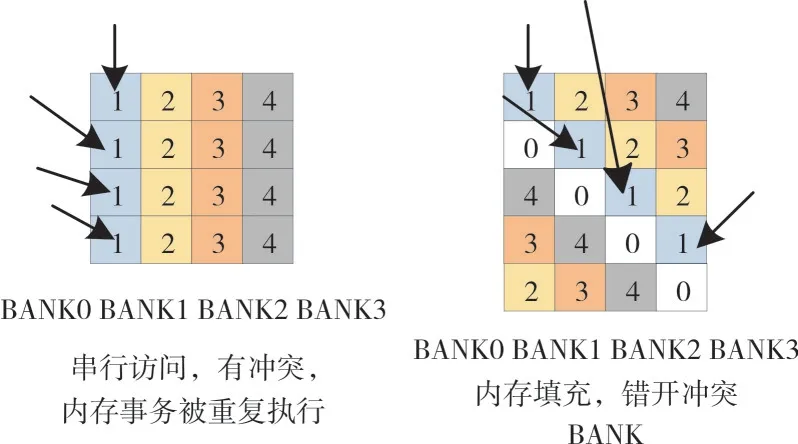
Fig.2 Memory padding to avoid memory conflicts图2 内存填充避免存储体冲突
3 GPU 在信号处理机中的实现
计算刀片以Intel 公司的至强E5-2648L V4 14 核CPU为主处理器,用于处理流程的控制和资源的调度;GPU 刀片以Nvidia 公司的Tesla P6 GPU 为核心,用于系统的高性能并行计算,计算刀片与GPU 刀片之间通过PCIe3.0 x16 的数据总线进行数据传输。
3.1 脉冲压缩的GPU 实现
使用GPU 对某认知雷达搜索模式下的“和差差”3 个波束、1 024 个脉冲压缩距离单元、940 个有效距离单元、128 积累点数的信号进行处理。数据格式为实部虚部交替存储。
在频域上实现匹配滤波,使用CUDA 内部的CUFFT 库来实现快速傅里叶正逆变换。使用CUFFT 实现FFT 需要调用FFT 句柄完成对数据排布和输出格式的初始化,之后设定傅里叶变换方向。初始化方式和执行傅里叶变换方式如下:

初始化输入了数据维度、排列方式,输出数据的排列方式和输入输出的数据类型。执行函数规定输入输出的首地址指针和FFT 方向(CUFFT_FORWARDCUFFT_FOR⁃WARD 是FFT 运算,CUFFT_INVERSECUFFT_INVERSE 是IFFT 运算)。
rank 表示FFT 运算的信号维度;n 是一个数组,表示进行FFT 的每个信号行数,列数和页数与上一个参数rank 相互呼应;inembed 表示输入数据的三维点数,[页数,列数,行数]、[列数,行数]或[行数],若数据是一维数据该参数会被忽略;istride 表示每个相邻输入信号的直接距离;idist为两个连续输入信号起始元素之间的间隔;onembed 为输出数据情况,同inembed;osteide 和odist 与此同理,batch 为进行FFT 运算的信号个数。
传输到设备端的数据按照列优先的存储规则排布,可通过改变参数istride 与idist 或osteide 与odist 来改变FFT 的输入输出数据格式。在工程实践中有时会在矩阵数据计算前进行转置操作以追求数据排布的一致性,可通过句柄初始化设定数据的输出格式,直接省略转置步骤。超大数据的矩阵转置会耗费大量时间,该方法可以有效优化运算时间。
频域的匹配滤波实现就是使用频域的匹配滤波系数(脉冲压缩系数)与经过FFT 处理后的信号进行向量点乘。在CUDA 中暂时没有专门针对向量点乘的函数,需要编写核函数实现系数相乘。可将匹配滤波系数放入常量内存或者共享内存中以提高数据的读取效率,或者在全局内存中采取数据对齐合并访问实现优化。
经过CUFFT 库实现的快速傅里叶变换(Fast Fourier transform,FFT)使运算结果增大2N倍,在使用MatLab 对GPU 计算结果进行误差分析时需要考虑。使用MatLab 对输入信号进行同样计算,得到的运算误差分析如图3 所示。
由分析结果可知,GPU 计算结果的实部与虚部和Mat⁃Lab 的误差都在10-4左右。考虑到GPU 上计算的数据类型为单精度FLOAT 型,而在MatLab 上计算的数据类型都自动转换成双精度DOUBEL 型,因此0.01%的误差属于可接受范围。在距离单元上对数据进行裁剪,使距离单元变成有效距离单元940,即可对数据进行动目标检测处理。
3.2 动目标检测GPU 实现
动目标检测(Moving Target Detection,MTD)滤波器组实现方法一般分为两类:①设计多阶数的有限脉冲响应(Finite Impulse Response,FIR)滤波器组对脉冲压缩之后的数据进行滤波[19],该方法能针对回波信号自适应降低信号副瓣,但计算量过大,对于硬件的计算能力要求过高;②采用快速傅里叶变换。这种方式计算效率较高,在计算资源有限的情况下能较好完成MTD 任务,但会导致滤波后信号副瓣较高,降低MTD 检测性能。一般在FFT 运算之前会针对不同的杂波类型对数据加上合适的窗函数以降低副瓣干扰,不过加窗操作会导致主瓣的展宽,降低主瓣的增益。
将与积累点数相同阶数的二维FIR 系数矩阵和待处理的数据矩阵相乘,实现有限脉冲响应滤波器算法,可使用CUDA内含的CUBLAS库专门针对矩阵运算进行加速。
CUBALS 库复数矩阵相乘,C=alpha*A*B+beta*C,函数为:

transa和transb表示矩阵A、B 是否需要在计算前进行转置;m,n,k是计算矩阵的维度信息;lda,ldb,ldc是对应矩阵的主维度。GPU 上的矩阵存储方式默认列优先,有别于C/C++的行优先。对矩阵相乘的结果进行求模,导出求模结果,MTD 输出结果和误差分析如图4 所示。GPU 和MatLab计算的结果误差在0.05%以内,属可接受范围。
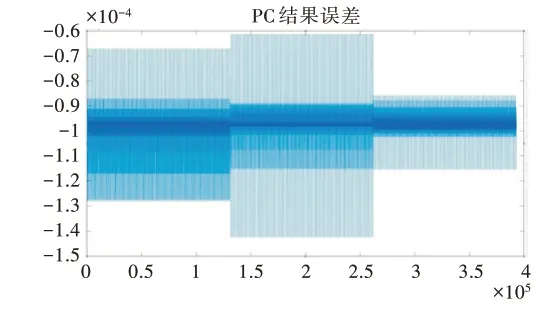
Fig.3 Error analysis of pulse compression results图3 脉冲压缩结果误差分析
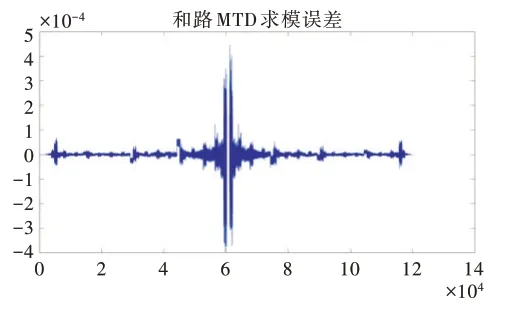
Fig.4 MTD result error图4 MTD 结果误差
3.3 恒虚警检测的GPU 实现
在某认知雷达中使用恒虚警检测(Constant False Alarm Rate,CFAR)算法为最大选择(Greatest Of)算法,在GO-CFAR 检测器中取两个局部估计的较大值作为总的杂波功率水平估计,在每次被测目标单元更新时,滑动窗口内的参考单位都会再次调用。若还是将数据存储在全局内存中,即便将数据对齐合并读取也会因为全局内存距离线程较远而花销大量时间,所以需要将被检测数据放在线程读取速度更快的共享内存中。同时因为共享内存只能被同一个线程块中的线程所共享,所以要分配一个线程块来计算一个多普勒道内的数据,线程块内的每个线程处理一个距离单元,实现细粒度并行优化。
将GPU 处理结果与MATLAB 的处理结果进行对比,得到各自的CFAR 结果如图5 所示。图中结果1 表示通过恒虚警检测门限,0 则表示未通过检测门限,表示位置没有检测到目标。脉冲压缩后的雷达回波信号存在距离副瓣,强的距离副瓣会产生虚假目标[20],所以恒虚警检测后会出现过门限目标,若要检测出目标确切位置还需要进行点迹凝聚算法。
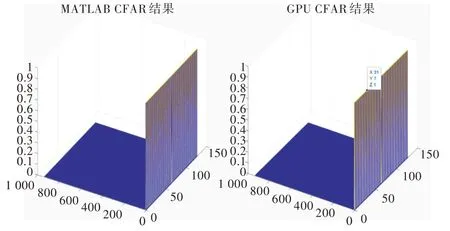
Fig.5 Comparison of CFAR results(no condensation)图5 CFAR 结果对比(未凝聚)
4 GPU 实现效果与优化结果
将GPU 处理结果与MatLab 处理结果进行对比。脉冲压缩、动目标检测和杂波图误差在10-4级别,恒虚警输出结果完全一致。对于“和差差”3 个波束,1 024 个脉冲压缩距离单元,128 积累点数的脉冲压缩处理,“和路”波束940 个有效距离单元,128 积累点数的动目标检测和恒虚警检测,在GPU 和CPU 下的处理时间对比如表2 所示。

Table 2 Comparison of radar signal processing time in GPU and CPU表2 雷达信号处理在GPU 与CPU 中的耗时对比
可以看出,在包含大量FFT 和点乘运算的脉冲压缩和动目标检测部分GPU 加速效果明显。对于CPU 不擅长的矩阵相乘运算,GPU 表现出惊人的加速效果,在极短时间内实现了基于时域有限脉冲响应滤波器的MTD。在充分利用计算资源的同时避免了加窗造成的主瓣展宽。在存在大量逻辑运算的CFAR 部分,经过GPU 的内存优化之后性能也得到了较大提升,但与脉冲压缩和动目标检测相比,加速的幅度较小,仍需要找到更好的优化方法。
5 结语
本文使用CPU+GPU 异构计算平台实现了雷达信号处理中的脉冲压缩、动目标检测和恒虚警检测。由于GPU 强大的并行计算能力,雷达信号处理算法在经过CUDA C 优化后较好地提升了计算性能。通过对GPU 的内部存储特性分析和挖掘CUDA 高速计算库,对已实现的CUDA 程序进一步优化,二次提升了计算性能。特别是使用FIR 技术实现MTD 时,在获得相较于CPU 实现1 000 倍加速之外,还避免了加窗操作对雷达回波信号主瓣的展宽,降低了主瓣的能量损失。但是,该方法对于内含大量逻辑判断的恒虚警检测获得的加速效果有限,后续需要找到更优的加速方案以实现程序的全面优化。
