一种基于MySQL的数据同步中间件研究
2021-03-24刘丽胡晓勤
刘丽,胡晓勤
(四川大学网络空间安全学院,成都610065)
MySQL是最流行的关系型数据库管理系统之一,在国内互联网中应用十分广泛,原生的MySQL主从复制缺乏的灵活性,无法满足源端、目标端库表结构不一致的同步场景,也不能同步到异构数据存储中。基于MySQL Replication协议,设计并实现一种基于MySQL的数据同步中间件,支持增量数据的自定义规则处理,提供数据同步定制能力,目标数据存储支持MySQL、Kafka,以及其他异构数据存储。
MySQL;数据同步;异构;中间件
0 引言
在互联网高速发展的今天,针对MySQL的数据同步需求越来越繁杂,原生的MySQL主从复制仅支持MySQL实例之间的全量复制,且主从数据库之间库、表结构一致,这在一些数据迁移场景需求下无法满足。如将源MySQL实例的A库迁移到目标MySQL实例的B库、在同步过程中根据某些数据字段的变化情况进行复制等,针对这些业务定制很强的场景,MySQL原生主从并不能解决。此外,在OLAP[1]场景下,往往需要将关注的MySQL增量数据采集到Kafka、ElasticSearch等异构数据存储中,因此,也需要解决MySQL同步至异构数据存储的问题。
针对上述问题,本文提出了一种基于MySQL的数据同步中间件,支持MySQL实例之间的单向数据同步,并提供了自定义增量数据同步规则的定制入口,能满足所有的映射同步、过滤同步等复杂的同步场景。此外,还支持将MySQL增量数据同步至Kafka等异构数据存储中,应用也可自行实现自己的数据存储同步适配器,具备极高的可拓展性。
1 数据同步中间件架构
本文提出的数据同步中间件系统架构如图1所示,整体分为逻辑层、协调层。本数据同步中间件的逻辑层包含Replicator组件和Consumer组件,Replicator组件负责从存储层的源MySQL实例中采集增量的Binlog Event数据,经过解析、过滤后,使用自定义的数据结构封装并保留在存储模块中,Consumer组件负责从Replicator组件中消费增量数据,并还原至目标MySQL实例中;协调层负责为逻辑层组件提供分布式协调服务,基于Zookeeper[2]为Replicator组件和Con⁃sumer组件提供状态同步、集群管理、服务发现的分布式服务能力。
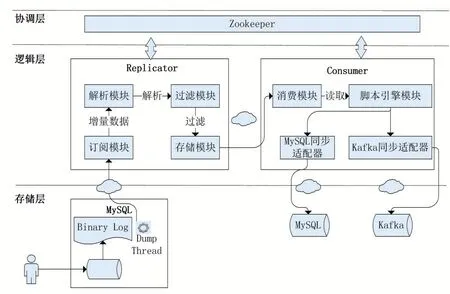
图1 数据同步中间件系统架构
2 Replicator组件
2.1 订阅模块
订阅模块负责与订阅的源MySQL实例进行网络通信交互,完成增量数据的持续采集,如DML(Data Manipulation Language)和DDL(Data Definition Lan⁃guage)操作产生的Binlog Event数据。订阅模块与MySQL进行网络交互的协议包括TCP三次握手协议、MySQL HandShake协议、MySQL Replication协议[3],交互时序如图2所示,该交互过程中涉及到的MySQL协议均遵循原生协议规范。
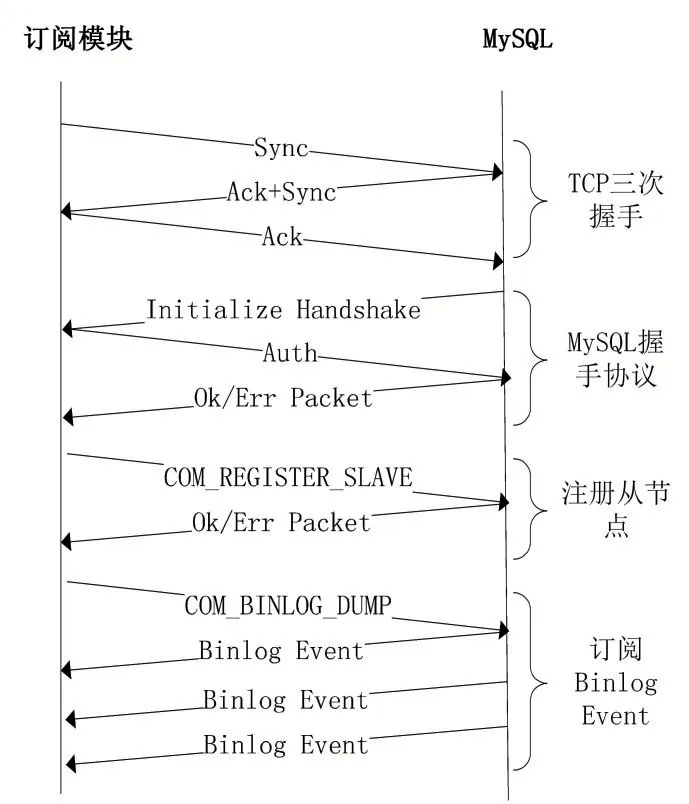
图2 订阅模块与MySQL协议交互流程
(1)订阅模块与MySQL进行TCP三次握手,建立TCP连接;
(2)完成TCP连接建立后,MySQL会主动给订阅模块发送一个MySQL初始化握手数据包,订阅模块对该握手数据包解析后,将自身登录使用的账号、密码等信息反馈给MySQL服务端;
(3)当订阅模块与MySQL服务端成功握手后,订阅模块通过MySQL Replication协议,给MySQL服务端发送COM_REGISTER_SLAVE命令,将本模块注册为MySQL服务端的从节点;
(4)当订阅模块成功注册成为MySQL服务端的从节点后,订阅模块通过MySQL Replication协议,给MySQL服务端发送COM_BINLOG_DUMP命令,使MySQL服务端持续推送增量的Binlog Event数据给订阅模块;
完成上述的MySQL Replication协议交互后,本模块将使用Netty框架监听订阅MySQL推送Binlog Event数据流的写入事件,并将其缓存在字节缓冲区中,用于解决粘包/拆包问题,截取完整Binlog Event数据包流程如图3所示。
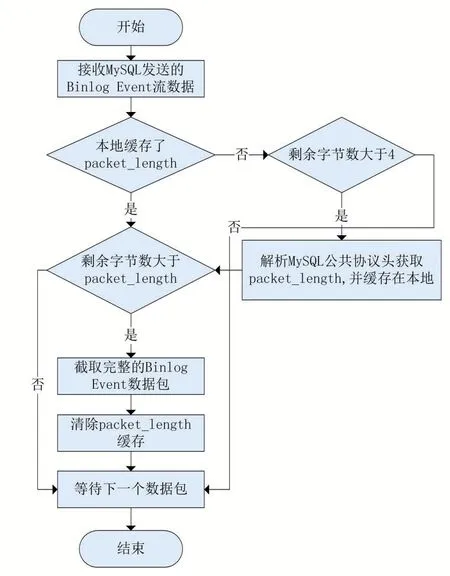
图3 Binlog Event粘包/拆包解析流程
(1)订阅模块接收到MySQL服务端推送的数据包后,尝试解析前四个字节,并获取完整数据包的字节大小packet_length;
(2)如果本数据包剩余字节大小大于pack⁃et_length,说明出现了粘包现象,缓冲区中包含了完整的Binlog Event数据,则根据packet_length进行截取,获得完整的Binlog Event数据包;如果本数据包剩余字节大小小于packet_length,说明出现了拆包现象,需要等待下一个数据包到达;
通过上述方法进行完整Binlog Event数据包的截取后,将其交给解析模块进行深度解析。
2.2 解析模块
解析模块负责解析Binlog Event数据包,将其封装成自描述的数据结构。解析模块从订阅模块中获取的Binlog Event数据包遵循原生MySQL中Binlog Event数据包协议,通过对其解析后,获取完整的行数据变更描述。DDL(Data Definition Language,数据定义语言)语句产生的Binlog Event数据,解析后获得其执行时的SQL语句;DML(Data Manipulation Language,数据操纵语言)语句产生的Binlog Event数据,解析后获得行数据变更前后的数据描述,包括列名、列值、列类型等信息;
本文描述的数据同步中间件基于MySQL Server的行复制(Row-Based Replication,RBR)模式,在这种模式下Binlog Event会详细描述行数据变更前后的状态,可以最大限度的保证主从复制的一致性,需要MySQL服务端开启binlog_format=ROW。基于MySQL服务端的行复制模式,当客户端在MySQL服务端提交事务时,二进制日志中会产生QUERY_EVENT、TA⁃BLE_MAP_EVENT、ROWS_EVENT(WRITE/UPDATE/DELETE)、XID_EVENT四种类型的事件,如图4所示。
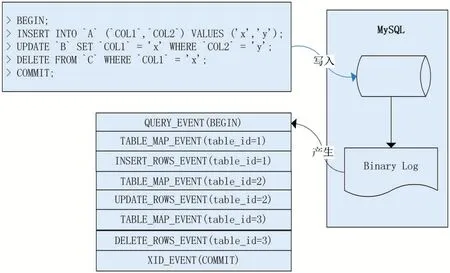
图4 Rows-Replication事件结构图
(1)QUERY_EVENT。当客户端执行DML导致行数据变更时,该事件记录了事务开始的发生,该类型的Binlog Event数据包中可以记录诸如BEGIN、END、XA START、XA END、XA COMMIT、ROLLBACK等语义;当客户端执行DDL语句时,该事件记录了DDL语句操作的库名称以及客户端执行的SQL语句;
(2)TABLE_MAP_EVENT。当客户端执行DML导致行数据变更时会产生该类型的事件,该类型的Bin⁃log Event数据包中记录了行数据变更的库、表、字段信息。解析模块在完成本类型Binlog Event数据包解析后,将在本地内存中缓存该表信息的内容,供下文解析ROWS_EVENT使用;
(3)ROWS_EVENT(WRITE/UPDATE/DELETE)。该事件类型的Binlog Event数据详细描述了DML语句修改数据的前后状态,ROWS_EVENT类型的Binlog Event数据包中记录了变更行数据的表序号(table_id),结合TABLE_MAP_EVENT中解析的表信息,可以从ROWS_EVENT数据包中获取行数据变更前后的列值信息;
(4)XID_EVENT。当客户端在MySQL服务端提交事务时会产生该类型事件,标识了一个事务的结尾;
通过对上述类型的Binlog Event数据进行解析,解析模块将需要的解析结果用一个定义好的对象结构RowData存储,完整的对象结构描述如表1,RowData数据结构中存储了本事件的语义类型(如DML、DDL、事务开始/结束等类型)、Binlog位点(Binlog文件名、偏移量)、DML语句执行后行数据变化前后的列信息,该列信息数据结构如表2所示,其中,字段名称在Binlog Event中并未提供,需要解析模块自行查询源MySQL获取。
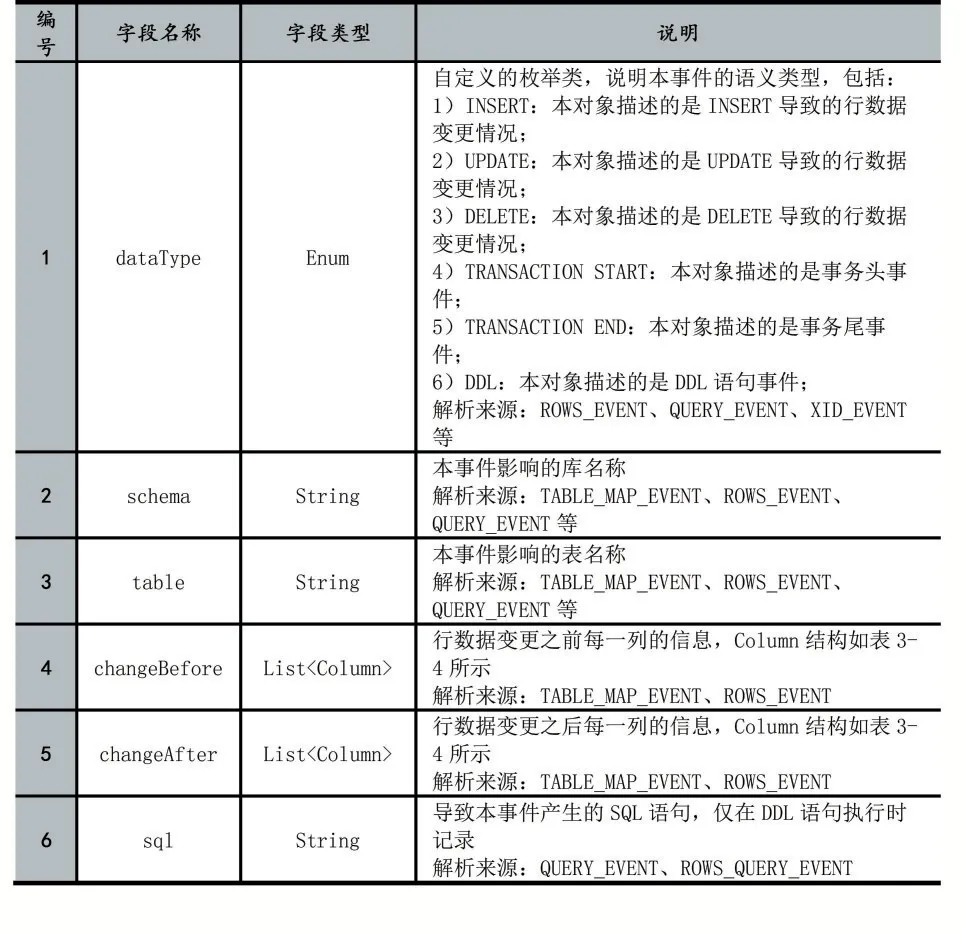
表1 Row Data对象结构

表2 Column对象结构
2.3 过滤模块
过滤模块负责过滤不关注的库、表数据。本模块使用Aviator引擎框架完成正则表达式的高性能求值,实现了Binlog Event黑白名单功能,过滤类型包括以下:
(1)Binlog Event类型过滤。本文中只保留了其中的事务开始事件、事务结束事件、DML产生的行数据变更事件和DDL产生的变更事件;
(2)Binlog Event库表过滤。除了对事件类型进行过滤外,过滤模块还将根据用户指定的库、表黑白名单对Binlog Event数据进行过滤,只保留本数据同步中间件关注的库表Binlog Event数据,减轻下游数据处理压力。
2.4 存储模块
存储模块负责需要同步的Binlog Event数据的管理与分发,本模块使用分段数据文件的形式存储被解析的Binlog Event数据,在经过前置过滤模块的筛选后,数据文件中只保存了下游需要消费的事件数据。
数据文件使用二进制形式存储数据,通过Proto⁃buf[4]序列化算法将Binlog Event数据的位点信息和事件内容信息转换成一连串的字节描述,并使用紧凑的变长变量存储以提高磁盘利用率。具体的,每一条事件数据的存储结构如表3。其中,位点信息和事件内容信息为变长数据,分别使用8字节固定长度的空间存储变长数据的字节数,并通过CRC32(循环冗余校验)算法计算出前(8+positon_length+8+rowdata_length)字节内容的的校验码,用于数据访问时做简单的数据检查,避免数据损失导致数据读取异常。位点信息的数据结构如表4,包含了Binlog文件名、Binlog偏移量以及该Binlog Event的时间戳。
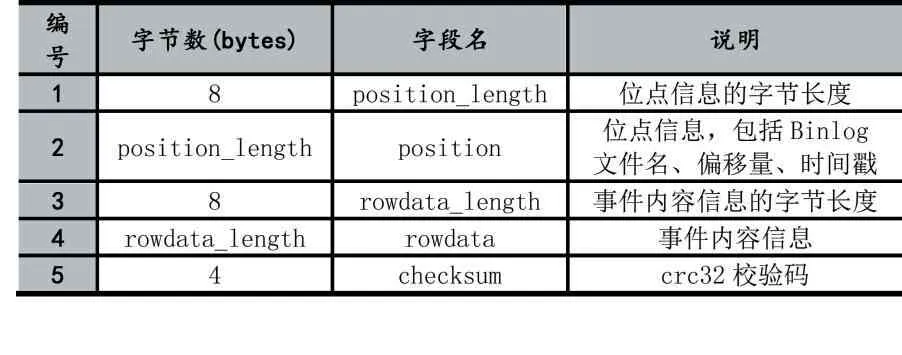
表3 数据文件Binlog Event数据存储结构
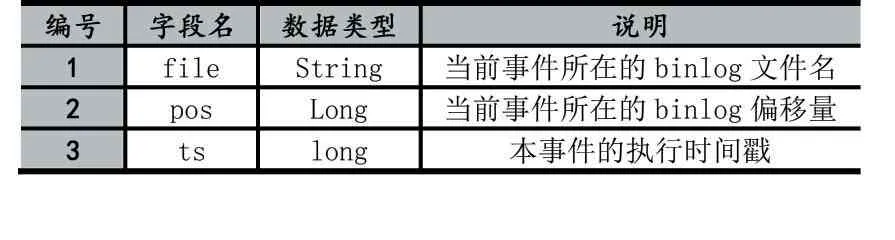
表4 位点信息数据结构
3 Consumer组件
3.1 消费模块
消费模块负责通过自定义RPC协议,从Replicator组件中批量获取关注的Binlog Event数据。该消费通信遵循2PC(Two-Phase Commit protocol,两阶段提交协议)协议,第一阶段中,消费模块从Replicator组件中获取批量数据,第二阶段,消费模块确认第一阶段数据处理完成或进行消费回滚,时序流程如图5所示。
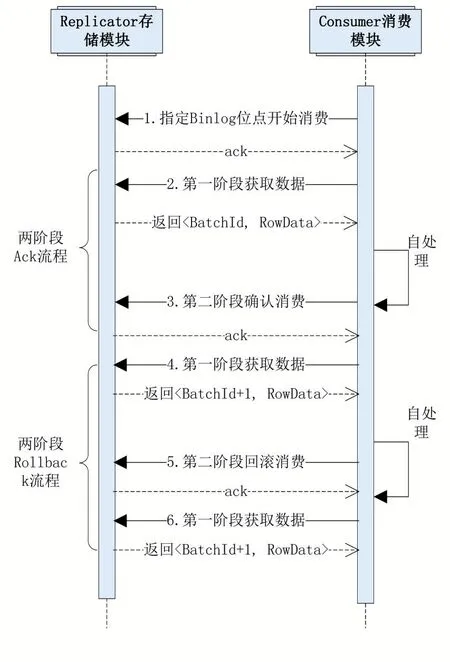
图5 两阶段流程
(1)两阶段Ack流程。消费模块首先进行第一阶段,从存储模块中批量获取RowData数据,存储模块将为该批次数据分配一个序号batchId,消费模块完成该批次RowData的处理后,第二阶段对该批次batchId进行确认,表示该部分数据已经消费完成,至此两端Ack流程完成;
(2)两阶段Rollback流程。区别于Ack流程,当消费模块没有正确处理完该批RwoData数据,认为需要重试时,第二阶段将向存储模块发起回滚请求,消费模块下次获取数据时仍从本批次开始。
3.2 脚本引擎模块
脚本引擎模块负责对用户自定义规则脚本生命周期的维护,包括加载、编译、编排、执行。基于规则脚本,用户可以对RowData数据自定义加工处理,实现字段级数据过滤、字段加工、映射同步等功能,为业务提供灵活的增量数据加工处理入口。
在脚本引擎模块中将解析两种类型的文件,一种是脚本编排文件,一种是脚本规则文件,其中脚本规则文件中存储的是用户编写的数据处理逻辑,本文中包括Java文件和Groovy文件,脚本编排编排文件中存储了规则文件的编排方式信息,以Yaml格式进行存储,每一个脚本信息的描述数据结构如表5所示,本模块通过指定每个脚本的执行顺序进行执行拓扑的编排。
基于上述的脚本编排文件格式,如图7所示,在文件系统中存在编排文件engine.yaml以及多个规则脚本文件,脚本引擎模块将根据编排文件中描述的脚本信息进行脚本的编译、编排,如图6所示。
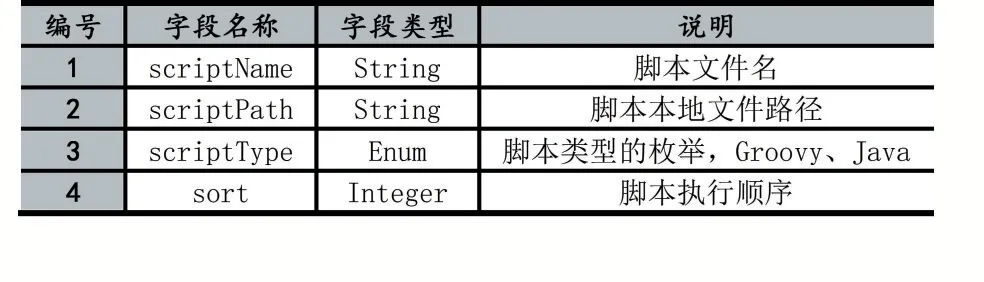
表5 脚本编排信息数据结构
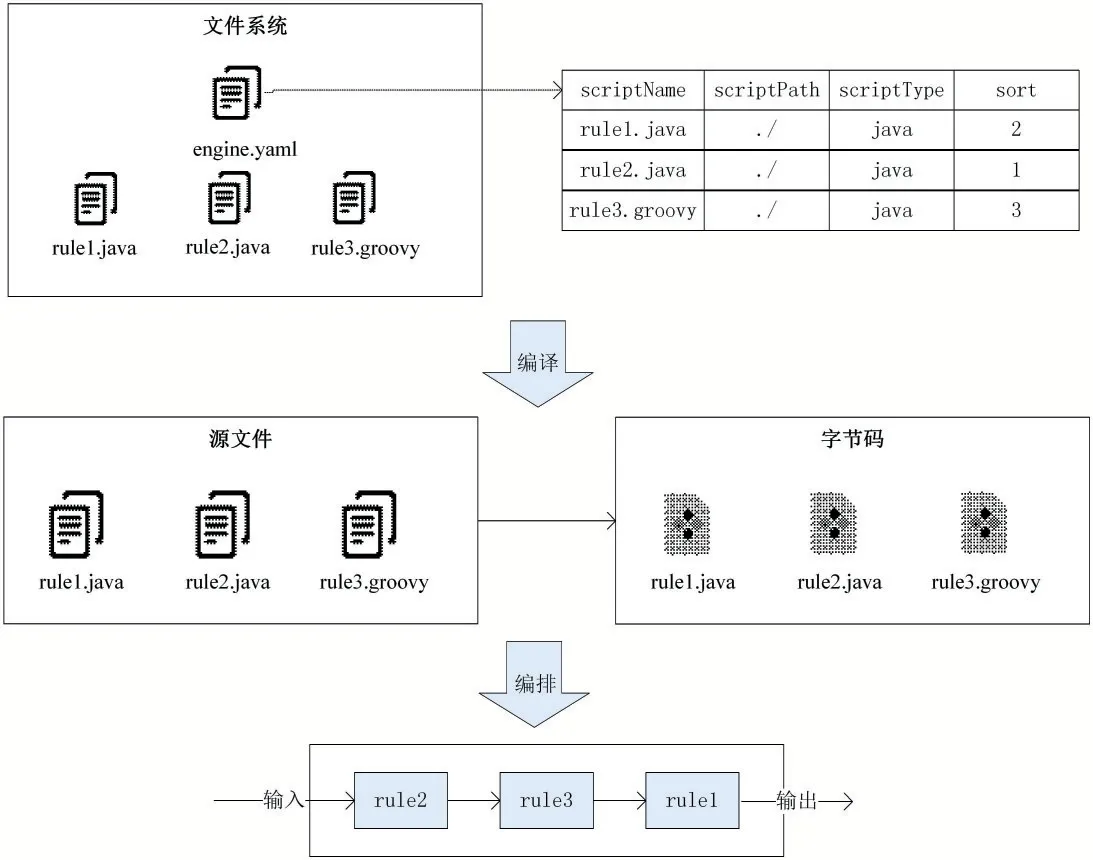
图6 脚本引擎工作流程图
(1)脚本引擎初始化时读取指定目录下的编排文件engine.yaml文件并进行解析,获得编排文件中存储的脚本编排信息,包括脚本文件的脚本名称、脚本路径、脚本类型以及执行序号;
(2)根据编排文件中的脚本信息,对涉及的规则脚本进行编译,如果是Java类型的规则文件,则使用JDK6开始提供的JavaCompiler工具进行动态编译;如果是Groovy类型的规则文件,则使用GroovyClassLoader加载器进行编译,并缓存在脚本引擎模块中;
(3)根据编排文件中描述的执行顺序,对规则脚本的执行进行编排,当有数据输入时,根据该规则拓扑进行数据加工处理。
3.3 同步适配器模块
3.3.1 MySQL同步适配器
本中间件描述的方案基于InnoDB存储引擎,且同步表含有主键。对于DDL语句,直接在目标MySQL执行RowData中记录的SQL即可。对于DML,本中间件通过RowData合并、SQL还原以及并行复制的方式完成目标MySQL的写入。工作流程如图7所示。
(1)Merger对本批次RowData进行合并,在保证数据一致性的前提下,将本批次中相同主键的行数据变更记录进行合并,如一条行记录先后经历INSERT、多次UPDATE,最终被DELETE,该行数据在结果上不需要同步到目标数据库,即以最终结果为准,减少了目标MySQL回放的数据量;
(2)Partitioner对合并后的数据进行分区。根据行数据的库、表、主键三元组进行哈希分组,将其切分成N个小批次数据,并提交到线程池;
(3)线程池调度执行,每个线程处理一个小批次的数据,通过SQL还原的方法将RowData描述的数据变化转换成DML语句,针对每个事件类型进行如下处理:
①本事件属于INSERT类型。使用INSERT IN⁃TO...ON DUPLICATE KEY UPDATE语义,该语义在目标MySQL存在该行数据时进行更新操作,不存在该行数据时进行插入操作。根据RowData的schema、table、afterChange构造SQL语句如下:
INSERT INTO`schema`.`table`(`filed_1`,...,`field_n`)VALUES(value_1,…,value_n)ONDUPLICATEKEY UP⁃DATE field_1=VALUES(field_1),…,field_n=VALUES(field_n);
②本事件属于UPDATE类型。使用REPLACE INTO语 义,根 据RowData的schema、table、before⁃Change、afterChange构造SQL语句如下:
REPLACE INTO `schema`.`table`(`filed_1`,…,`field_n`)VALUES(value_1,…,value_n);
③本事件属于DELETE类型。根据RowData的schema、table、beforeChange进行SQL还原,根据主键删除目标MySQL数据,构造DELETE语句如下:
DELETE FROM`schema`.`table`WHERE`pri_key_1`=pri_value_1…AND`pri_key_2`=pri_value_2;
(4)多线程并行写入目标MySQL,完成数据同步。
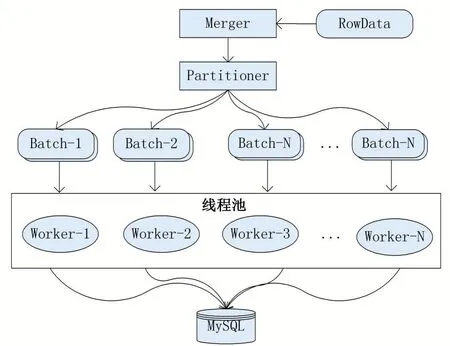
图7 MySQL同步适配器并行复制过程
3.3.2异构同步适配器
在本数据同步中间件中,每一个异构数据存储类型对应了一种同步适配器,适配器负责获取MySQL增量行数据,在进行数据处理后,通过异构数据存储的SDK完成写入。结合本中间件提供的脚本引擎模块,可以完成更多目标数据存储的支持,有很高的可拓展性。当目标为Kafka等队列存储时,同步适配器需要着重考虑Binlog Event分发的顺序性,此时提供两种写入策略。
(1)对于需要保证行数据级别Binlog Event顺序的场景,在适配器处理数据时,根据库、表、主键计算哈希值,并对写入队列的数量取余,将相同主键的行数据事件分发到同一个队列中,只要下游应用对每个队列启用一个线程进行消费,则可以保证行数据级别的Bin⁃log Event的顺序性;
(2)对于需要保证全局Binlog Event顺序的场景,该适配器写入队列的数量只能为1,并且使用单线程写入队列,下游应用也只能启用一个线程消费该队列,吞吐量将十分有限。
4 基于Zookeeper的分布式增强
4.1 组件高可用
Replicator组件和Consumer组件的集群化,实现组件的主备切换,提供高可用服务能力。以Replicator组件为例,当多个组件启动初始化时,分别向Zookeeper相同路径下中注册临时节点,路径为/data/sync/{task_id}/replicator/node,其中task_id为本同步任务的唯一标识,注册时使用的值为各自组件的IP地址和服务端口。由于Zookeeper临时节点的特性,只有一个节点会注册成功,注册成功的节点将作为主节点,进行正常的工作,其余节点将注册该临时节点的监听事件,当该临时节点发生删除事件时,将会重新进行新一轮的选主过程,以此保证组件的高可用特性。对于Consum⁃er组件同样采用上述逻辑实现高可用。
4.2 服务发现
当Replicator集群发生主备切换时,Consumer组件需要及时切换到新的Replicator组件节点进行订阅消费。当Consumer组件启动后,会在Zookeeper中查询/data/sync/{task_id}/replicator/node是否有注册成功的Replicator组件,如果有成功注册的节点,则获取节点中存储的IP地址和服务端口,随后通过RPC协议与Replicator组件进行2PC交互,如果没有发现成功注册的Replicator节点,则Consumer组件处于挂起监听状态,直到有Replicator组件在该同步任务下创建临时节点,以此实现Replicator组件的服务发现。
4.3 消费位点管理
对于Replicator组件进行消费位点的管理流程如图8所示,当Replicator接收到二阶段Ack请求后,根据批次号获取该批数据的位点信息,在更新内存消费位点后,完成本次请求后直接反馈成功,之后,Replica⁃tor组件由内部异步任务定时向Zookeeper中更新位点信息,位点信息在Zookeeper中的路径为/data/sync/rep⁃licator/{consumer_cluster_id}/process,其 中 consum⁃er_cluster_id为Consumer集群的唯一标识,存入的值为本批次最后一条Binlog Event的位点。
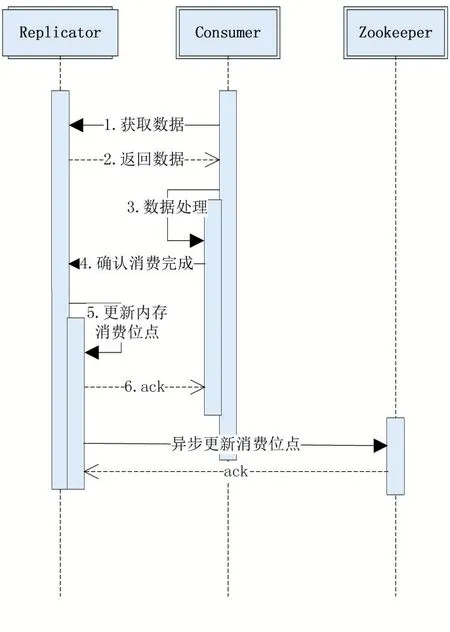
图8 Replicator位点记录时序图
5 测试
测试所用的机房有两套,分别为北京机房和广州机房,两个机房之间的网络延迟约为30ms左右,环境配置如表6。
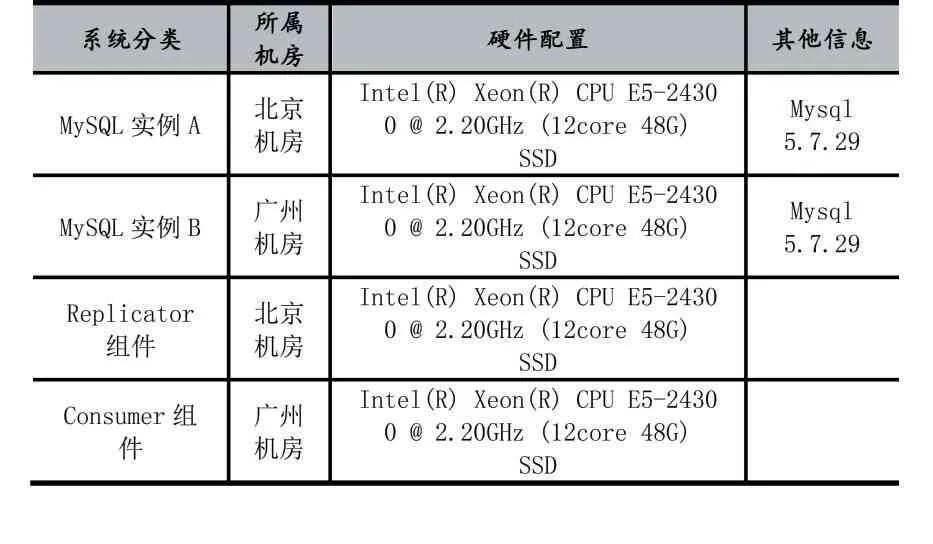
表6 测试环境配置表
本次实验的拓扑结构如图9所示,两个MySQL实例间都已经打开二进制日志并设置为ROW模式。
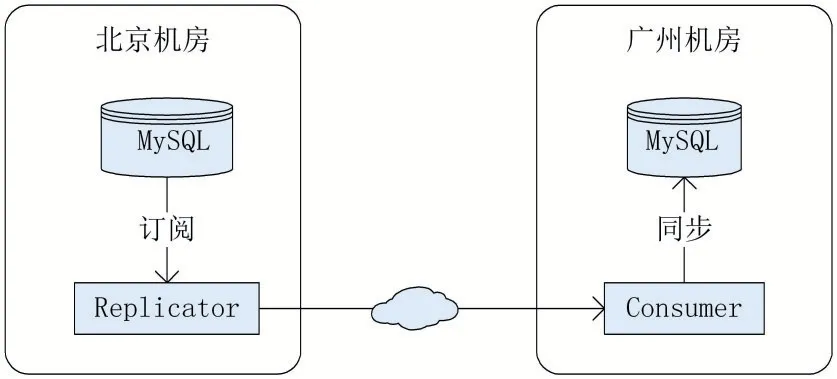
图9 单向同步实验拓扑图
下面将从INSERT、UPDATE以及INSERT/UP⁃DATE混合三种场景下,对比单向同步复制中不同并行度下的性能表现,具体数据如表7所示。
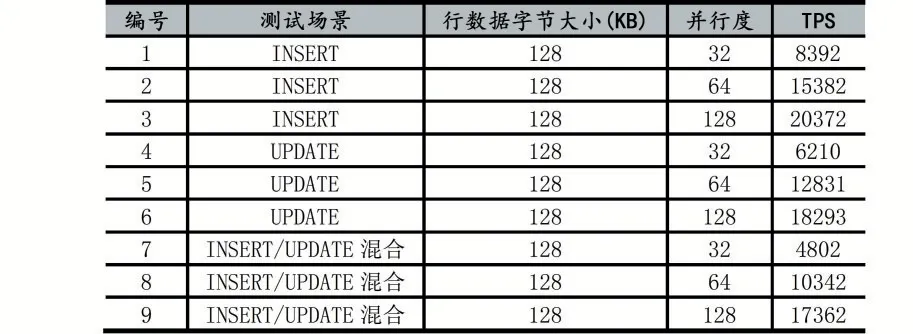
表7 单向同步并行复制性能测试报告
由上述实验情况可知,本数据同步中间件在MySQL单向同步的INSERT场景下表现良好,主要是经过数据合并后对同表的INSERT语句使用了预编译方式,将INSERT语句批量提交到目标MySQL中,避免了目标MySQL多次解析、优化相同的SQL语句。
6 结语
本文基于MySQL设计并实现了一个数据同步中间件,用于将MySQL中的增量数据同步至目标MySQL或其他异构数据存储中,并支持业务自定义增量数据处理的规则脚本,几乎满足了各类业务的同步需求。
