基于深度学习的地空通信文本命名实体识别研究
2021-03-24张兴明
张兴明
(四川大学视觉合成图形图像技术国防重点学科实验室,成都610065)
根据实际的空中交通管制指令解析任务需求,进行地空通信文本命名实体识别研究,用以辅助指令解析任务。该模型构建方法采用双向的长短时记忆网络结合注意力机制与条件随机场模型。双向长短时记忆网络进行文本的上下文特征信息提取;注意力机制能够更多地关注到与当前输出有关的信息;条件随机场模型能够学习标签之间的约束关系。在少量的地空通信文本标注数据上进行多组对比试验,实验结果证明该方法的有效性,取得较好的识别结果,F1值达到96.61%,可以为指令解析任务提供辅助信息。
命名实体识别;地空通信;深度学习;注意力机制
0 引言
在空中交通管制(Air Traffic Control,ATC)中,地空通信(Air-Ground Communication)是管制员对飞行器进行指挥与调度的唯一途径,其重要程度不言而喻。对通信内容进行实时监控,及时发现错误指令,能够有效避免险情事故发生。近年来,随着深度学习技术不断发展,国内外都已经有研究机构将语音识别技术应用于空中交通管制语音识别中[1]。在空中交通管制语音识别文本基础上做进一步的语义分析与指令提取,可为空中交通管制提供预警信息,如指令复诵一致性检查、相似航班号检测、跑道入侵检测等。
命名实体识别(Named Entity Recognition,NER)[2]是自然语言处理中一项基础性关键任务,可为后续的关系抽取、事件抽取,语义解析提供关键信息。命名实体一般指的是文本中具有特定意义或者指代性强的实体,在地空通信文本中可以将命名实体类型分为三大类,分别是实体类、数字类、指令类。通过自动识别文本中的相关实体,可以为后续的语义分析和指令提取提供辅助信息。
近年来,基于神经网络的深度学习方法在命名实体识别任务中逐渐成为主流方法,相比于另外两种传统的识别方法,它不需要人工制定规则或人工选取文本特征,可以自动学习到文本的特征信息。命名实体识别可以看做序列标注问题,Hochreiter等人[3]在1997年提出长短时记忆网络(Long Short-Term Memory,LSTM)在由Alex Graves等人[4]改良后成为一种有效解决序列相关问题的循环神经网络模型,被研究人员广泛应用在解决各类序列相关的问题中。同样,LSTM网络也被学者们广泛运用在命名实体识别的任务中,在不同领域的命名实体识别中都取得了较好的识别效果。Huang等人[5]将双向的长短时记忆网络和条件随机场模型进行结合,组成BI-LSTM-CRF模型,并与LSTM模型、BI-LSTM模型、LSTM-CRF模型在不同数据集上对比实验,均取得了最优的F1分值;Guillaume Lample等人[6]使用基于LSTM-CRF的识别模型,结合词向量的表示方式,在英语、荷兰语、德语以及西班牙语上都取得了较好的识别结果;单义栋等人[7]采用字符向量和词向量相结合作为输入层,隐藏层使用双向的长短时记忆网络,以此构建了军事文本的命名实体识别模型。
1 命名实体识别模型构建
本文构建的地空通信命名实体识别模型如图1所示。该模型主要包括:字符级输入层、双向长短时记忆网络隐藏层、注意力机制层、条件随机场层。首先将输入语句按照字符拆分进行输入,在字符级词向量输入层通过查询预训练的字符级词向量将其转换为模型的输入,再通过隐藏层和注意力机制层进行特征信息提取,最后通过条件随机场进行输出结果校正得到模型最终的输出结果。
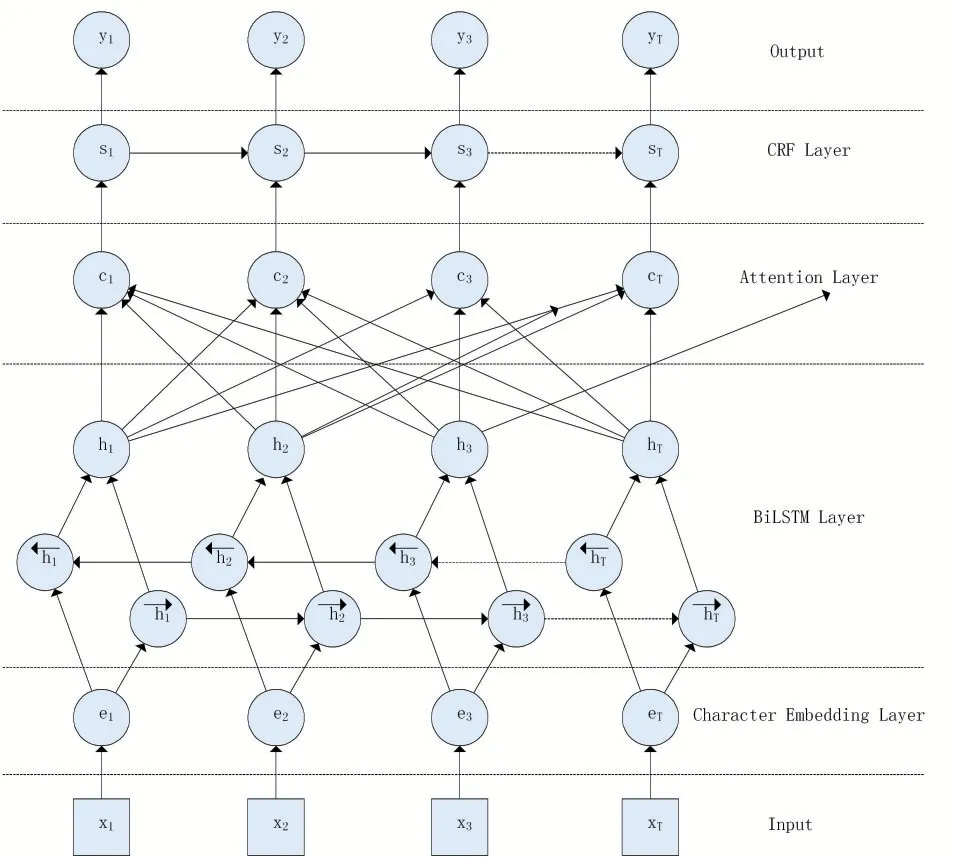
图1 地空通信命名实体识别模型
1.1 字符级输入层
文献[8]中提出的Word2Vec工具,让自然语言处理向前迈了一大步。本文使用的是基于字符的词向量编码方式来表示输入的语句,即将单个汉字字符或单个英文单词用词向量的方式来表示,以此做为命名实体识别模型的输入。
这样做主要是基于地空通信文本的特点考虑:
(1)地空通信文本中存在大量的汉字数字字符,而这些连续数字字符的组合可能表示实体,若是将数字组合在一起作为一个单独的词来进行词向量表示,则会在识别阶段出现大量的未登录词组,影响模型的识别性能;
(2)由于地空通信受通信规则的约束,在地空通信中所用到汉字字符与英文词汇的总数量相对有限,而词组数量确是非常庞大的,以字符向量作为输入能大幅降低对计算性能的需求,同时也能较好地解决未登录词组的问题。
具体处理过程如下,将一个含有n个字符的语句记做X=(x1,x2,x3,…,xn),其中xi为单个字符。在大量未标注的数据集上训练出字符向量Em×d=[e1,e2,e3,…,em],其中m为字典大小,d为字符向量的维度。在输入句子X=(x1,x2,x3,…,xn)时通过查询xi在Em×d=[e1,e2,e3,…,em]中对应的字符向量ei作为该字符的输入,对于那些未出现在字符向量Em×d中的字符,采用随机初始化生成。
1.2 Bi-LSTM隐藏层
在地空通信文本命名实体识别中,需要识别的实体类型较多,且前后字符之间有较强的相关性。在预测当前输入字符的标记类型时,正向的LSTM网络模型只能捕获到当前输入字符的前文信息,而无法获取到后文信息,这些信息对预测当前字符的标记类型是不充分的。文献[9]提出双向的LSTM网络模型(Bidi⁃rectional LSTMnetworks,Bi-LSTM),该网络模型能够同时捕获前后文信息,它相比于正向的LSTM网络模型获取的信息更加充分,理论上Bi-LSTM网络模型对地空通信文本命名实体识别是有正向作用的。Bi-LSTM模型结构如图2所示。
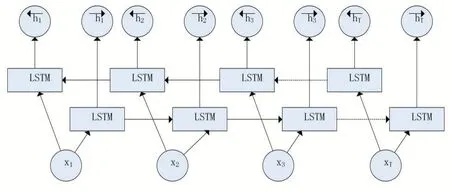
图2 Bi-LSTM模型结构
1.3 注意力机制层
在地空通信文本命名实体识别中,虽然通过双向的长短时记忆网络已经能获取到前后文信息,但是不是所有的信息都有作用,如“国航四幺八九成都联系地面幺幺九点两五”,其中“联系”一词的信息对频率值“幺幺九点两五”的识别更为重要,而“国航”、“成都”等信息对频率值“幺幺九点两五”的识别就不是特别的重要,因此引入注意力机制到别模型中,理论上有助于提高模型识别效果。
借鉴文献[10]中所提出的注意力机制并针对命名实体识别任务做相应的改变,具体结构如图3所示。
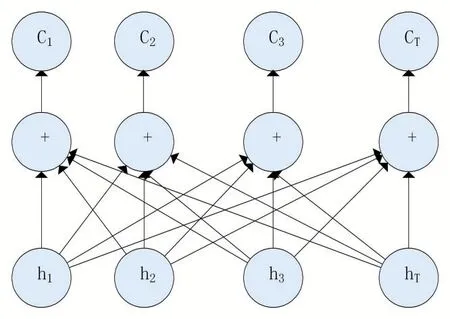
图3 注意力机制层结构
注意力机制层在各时刻计算出一个对应的特征向量Ci,用于表示与当前时刻相关的记忆信息,其中包含更多与当前时刻有关联的信息,其计算公式如下:
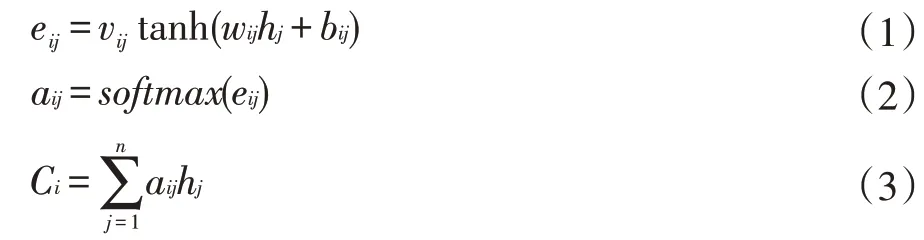
其中,vij、wij为权重参数,bij为偏置参数,各时刻的特征向量Ci由隐藏层输出结果[h=[h1,h2,h3,…,hT]和对应时刻的注意力权值分布矩阵ai=[ai1,ai2,ai3,…,aiT]进行加权求和所得。最终,在注意力机制层输出的结果为C=[C1,C2,C3,…,CT]。
1.4 CRF解码层
通过隐藏层和注意力机制层的计算得到了特征张量C=[C1,C2,C3,…,CT],若直接使用特征张量C来计算各标签的概率分布,是可以计算出各时刻概率最高的的一个标签,从而得到一个标签序列,然而这样的标签序列并不一定是全局最优的序列。在命名实体识别中各标签之间存在一定的约束关系,如标签“B-ACID”之后不可能跟的是标签“I-LOC”,同理,标签“B-CODE”之后不可能跟的是标签“I-FREQ”,而条件随机场模型(Conditional Random Field,CRF)是可以通过训练学习到这种约束信息,即标签之间的转移概率分布。
为了让地空通信文本命名实体识别模型表现的更好,将条件随机场模型作为整个识别模型最终的解码输出层。条件随机场算法对注意力机制层输出的特征张量C进行建模,学习标签之间的转移概率得分矩阵An×n,其中n为标签类型个数。CRF解码层的具体结构如图4所示。

图4 CRF解码层结构
由CRF解码层结构可知,预测结果的概率得分可以量化定义如公式(4)所示:
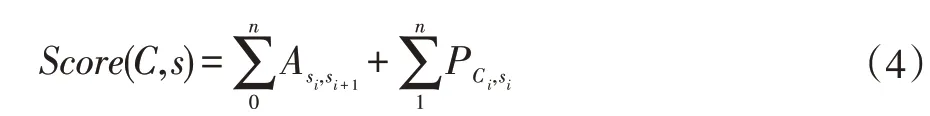
该量化公式由两部分组成,其中,A表示标签之间的转移概率得分,P表示由特征向量Ci得出标签si的概率得分。记所有的标记序列为S,则标注序列为s的概率可以采用Softmax函数进行计算相应的概率值,具体计算公式如公式(5)所示:

训练时,利用训练数据集通过对数极大似然估计得到条件概率模型P(S|C),其损失函数如公式(6)所示:
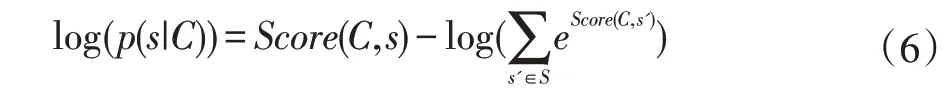
预测时,给定输入序列X=(x1,x2,x3,…,xn),首先通过隐藏层和注意力机制层计算得到其特征张量C=[C1,C2,C3,…,CT],然后将其输入到 条 件 概率模型P(S|C)中使用维特比算法(Viterbi Algorithm)[11]求出概率最大的输出序列s*=[s1,s2,s3,…,sT],即为最终的标注序列。
2 实验及结果分析
为验证本文所构建的地空通信命名实体识别模型的识别效果,首先采用人工标注与核验的方式构建实验数据集,确保数据集的准确性;接着搭建对比模型与地空通信命名实体识别模型进行对比试验;最后对实验结果进行分析。
2.1 实验数据
本文所用实验数据来源于真实的中文地空通信语音标注文本。本文所采用的标注格式为:BIO格式。经过预处理、人工标注、人工核验后得到实验所用的数据集。为准确有效验证模型的识别效果,将数据集按照7:3的比例随机划分为训练集和测试集。训练集和测试集的实体个数统计如表1所示。
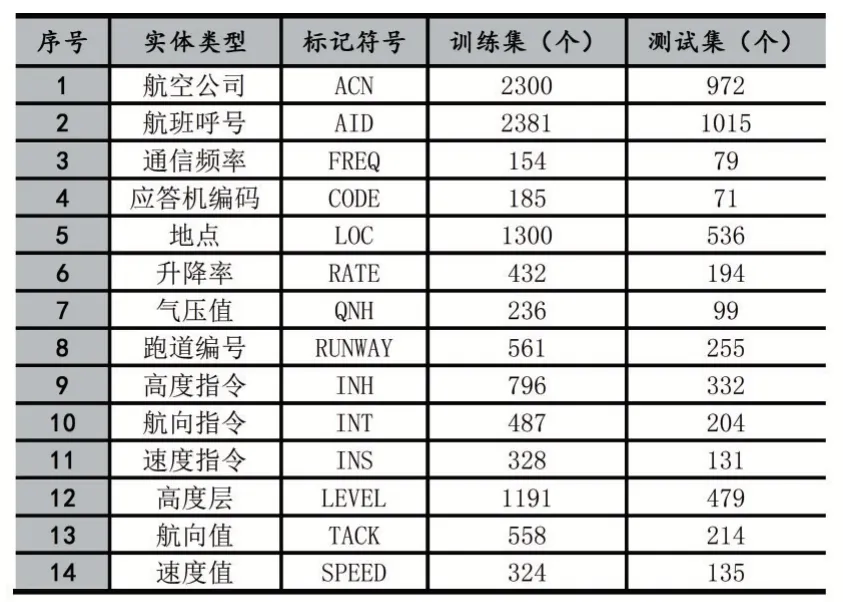
表1 数据集中实体个数统计结果
2.2 实验评价标准
实验采用精准率(P)、召回率(R)和F1值对识别结果进行评价,3种评价指标的具体计算公式如下:

其中,m为模型识别结果与标注一致的实体个数,即识别正确的实体个数,n为模型识别为实体的总个数,s为数据集中标注为实体的总个数。
由于数据集中不同类型实体的数量分布不均,若是直接采用上述计算方式得出精准率(P)和召回率(R),则结果会受到某类较多实体个数识别结果的影响。为了真实准确地评价模型识别结果,本文采用对每类实体赋予相同权重的方式,用于计算模型的精准率(P)、召回率(R)。首先采用公式(7)、(8)计算出各类型实体识别的精准率(Pi)与召回率(Ri),再进行相加求和得到最终结果。其中n为实体类型个数,具体计算公式如下:

2.3 实验设置
实验采用TensorFlow深度学习框架搭建识别模型,总共搭建了4个模型进行实验。第一组模型以双向的长短时记忆网络构建而成,作为基准模型,记为:BiLSTM;第二组模型以双向的长短时记忆网络结合注意力机制构建而成,记为:BiLSTM_ATT;第三组模型以双向的长短时记忆网络结合条件随机场模型构建而成,记为:BiLSTM_CRF;最后一组是本文所构建的识别模型,记为:BiLSTM_ATT_CRF。
在训练参数设置上,为了真实准确地对比四个模型的识别效果,公共的训练参数配置采用相同的参数大小进行试验。具体配置如表2所示。
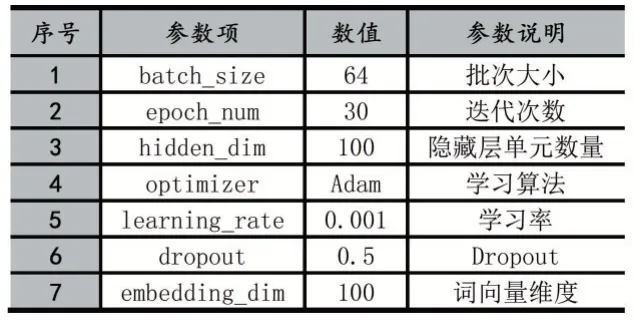
表2 实验参数配置
2.4 实验结果及分析
模型训练完成之后,分别在测试集上进行测试,采用2.2中所提到的公式计算模型识别的精准率(P)、召回率(R)和F1值,各模型整体识别结果如表3所示。
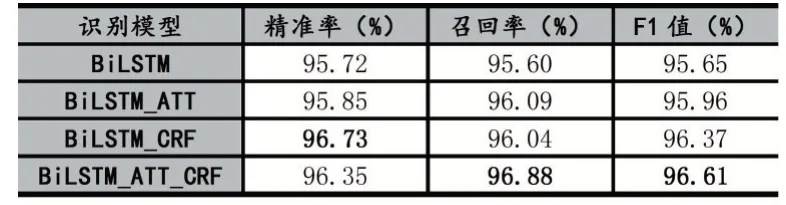
表3 模型对比试验结果
本文使用BiLSTM模型的测试结果作为基准。BiLSTM_ATT模型与BiLSTM模型相比,在精准率上提高了0.13%,在召回率上提高了0.49%,相应的在综合性能F1值上有0.31%的提升,说明注意力机制在识别过程中是关注了更多与当前输入有关的记忆信息,可以将其运用到地空通信文本命名实体识别模型中,有助于提升模型的识别效果。
BiLSTM_CRF模型与BiLSTM模型相比,在精准率上提高了1.01%,在召回率上提高了0.44%,相应的在综合性能F1值上有0.72%的提升,说明条件随机场模型是学习到了标签之间的一定的约束信息,在解码输出过程中使用条件随机场模型是有助于进一步提升模型的识别效果。同时,也可以观察到BiLSTM_CRF在精准率、F1值两项指标上的提升高于BiLSTM_ATT在这两项指标上的提升,而两者在召回率上相差不大,说明条件随机场模型对提升模型识别效果所发挥的作用是大于注意力机制所发挥的作用。
本文所构建的BiLSTM_ATT_CRF模型与BiLSTM模型相比,在精准率上提高了0.63%,在召回率上提高了1.28%,相应的在综合性能F1值上有0.96%的提升。BiLSTM_ATT_CRF在精准率、召回率、F1值三项指标上均高于BiLSTM_ATT模型;BiLSTM_ATT_CRF在精准率上略低于BiLSTM_CRF模型,但在召回率、F1值上均优于BiLSTM_CRF模型。F1值是一项综合反映模型识别效果的评价指标,故可以表明BiL⁃STM_ATT_CRF模型的识别效果是优于BiLSTM_ATT模型和BiLSTM_CRF模型。
从以上的分析,可以得出如下结论:①将注意力机制引与件随机场模型引入到模型中能够提升模型的识别效果;②将条件随机场与注意力机制进行结合构建的模型识别效果是最优的。从而,说明本文构建的地空通信命名实体识别模型的效果最优,它能够提升识别效果。
3 结语
本文以双向长短时记忆网络模型为基础结合注意力机制与条件随机场模型所构建的地空通信文本命名实体识别模型,考虑了不同位置的字符对实体识别的影响以及前后标签之间的约束关系,使得模型识别效果较优。在少量的标注数据就取得了较好的识别效果。通过实验证明了该模型能够有效解决地空通信文本中命名实体识别任务,可以将其运用到关键指令信息提取中,辅助指令解析任务。但目前仍存在以下不足:
(1)根据实验结果显示,目前在某些实体类型的识别上效果并不理想,例如地点(LOC)、速度指令(INS)和航迹指令(INT)等实体上F1值均低于95%。
(2)在地空通话领域中,某些实体类型出现频率较高,某些实体类型出现频率较低,导致数据集中各类实体分布不均,训练出的模型也可能受到一定影响。
后续将针对以上问题,扩充数据集数量,并对数据集进行优化处理,进一步改进模型结构,以到达实际应用水平。
