融合多种神经网络与多特征的答案排序方法
2021-03-23段利国李爱萍
王 龙,段利国,李爱萍,2
(1.太原理工大学 信息与计算机学院,山西 太原 030024;2.武汉大学 软件工程国家重点实验室,湖北 武汉 430072)
0 引 言
随着互联网技术飞快发展,数据信息急剧增多,面向大众领域的问答系统成为越来越多的人获取信息、共享知识的首选途径,以百度知道为代表的社区问答系统在人们生活中应用广泛,但其针对同一个问题往往有多个不同答案,而且答案的质量也良莠不齐。因此,旨在针对用户的提问信息,分析筛选并返回给用户所需的准确答案的答案排序算法起到重要作用。
通过分析众多问答信息数据发现,相较于长文本问答对,无法更多提取短文本文本信息,导致其排序效果差距很大,达不到较高的准确率。因此提出融合多种神经网络与多特征的答案排序模型,由多种神经网络学习文本特征,同时引入多种特征信息提高准确率。
本文的主要贡献如下:
(1)构建由卷积神经网络(CNN)、双向门控循环单元(Bi-GRUs)和多层感知器(MLP)组成的多层神经网络模型,在融合层加入词汇特征、主题特征等多种特征信息。
(2)对卷积神经网络(CNN)做出改进,采用2-Max Pooling做池化操作,同时引入Leaky Relu激活函数以解决“梯度消失”问题,加快收敛速度。
(3)该模型在WikiQA数据集上取得较好的答案排序效果。
1 相关工作
现阶段答案排序方法可以分成两类:第一类是传统的基于词汇、句法、语法等特征信息进行答案排序的机器学习方法;第二类是新兴的基于神经网络模型的深度学习方法。近年来,部分研究人员尝试将深度学习模型应用在答案排序的任务上,取得较好的效果。Nie L通过构建由一个离线学习组件和一个在线搜索组件组成的知识库的方法进行答案选择[1]。Severyn A先用二元卷积神经网络对问题和候选答案进行向量化表示,而后根据相似矩阵计算得到问题与候选答案的相似度值,并把此值与问题和候选答案的向量化表示相互拼接,再引入其它特征,最后通过softmax层对新拼接的向量进行分类[2]。Nie YP引入双向长短时记忆(LSTM)编解码器,有效地解决机器翻译任务中出现的问题和答案之间的词汇鸿沟,并使用step attention机制来允许问题集中在候选答案的某个部分[3]。Xiang等针对社区问答数据提出一个专注的深层神经网络结构,该结构采用卷积神经网络、基于注意力的长短时记忆网络和条件随机场的方法[4]。Fan等的工作则是利用多维特征组合和相似度排序对网络论坛中的社区问答排序方法进行改进,充分利用问题答案中的信息来确定问题和答案之间的相似性,并使用基于文本的特征信息来确定答案是否合理[5]。基于以上研究,为了更好地提高答案排序的性能,本文提出了一种融合多种神经网络与多特征信息的深度学习模型。
2 融合多种神经网络与多特征信息的深度学习模型
在答案排序的研究过程中,仅仅对问题和候选答案进行深度学习是不全面的,其特有的词汇特征、主题特征等多种特征信息也在一定程度上影响着答案排序效果,因此本文将多种神经网络和多特征信息进行融合,使用卷积神经网络学习问题和候选答案特征,采用双向门控循环单元对融合多种特征信息的向量进行训练,经多层感知器处理后,通过softmax分类器得出最终排序结果。图1为模型的基本结构。

图1 网络模型结构
2.1 输入层
输入层对数据集中的问题和候选答案均使用词向量进行表示,该词向量集来自于Google news,共收录约300万个英文词,每个词的维度均为300维,使用词匹配的方式将问题和候选答案中的每个单词与词向量集中相对应单词比对替换,查找不到的单词使用300维的0向量进行表示。
此外,为确保模型具有健壮性,通过对WikiQA英文数据集中数据的分析得知,问题句子的最大长度为22,候选答案句子的最大长度为98,因此,实验过程中全部采用最大长度120,对于长度不足的句子均用0进行补齐。
2.2 卷积神经网络
近年来,卷积神经网络[6]作为深度学习的典型算法得到了进一步发展,并被广泛地应用在计算机视觉以及自然语言处理等多个领域。与普通的神经网络相比,其主要区别在于,卷积神经网络含有一个由卷积层和池化层构成的特征抽取器。且卷积和池化可以大大简化模型的复杂度,减少模型的参数。图2为卷积神经网络在自然语言处理中的应用示例。
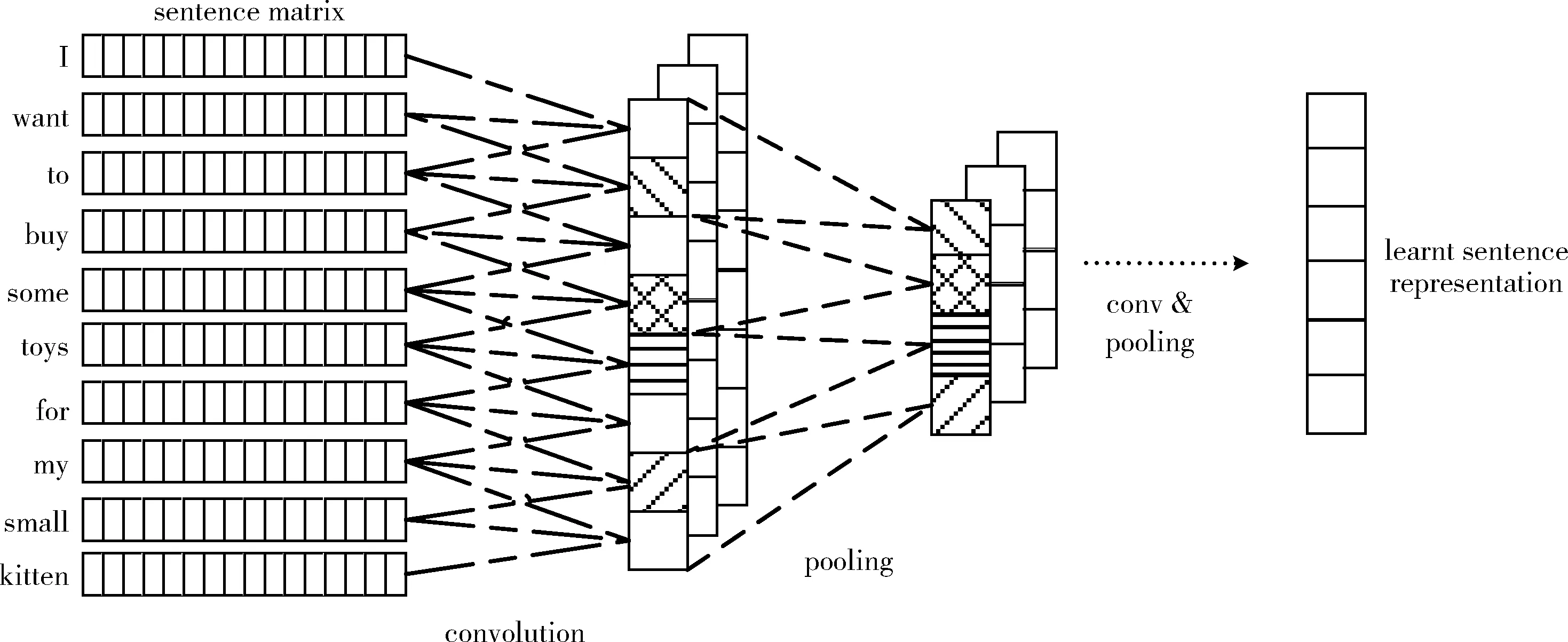
图2 卷积神经网络在自然语言处理中的应用示例
本实验中,卷积层对输入层中得到的120*300阶的矩阵进行处理,其中120表示句子的长度,300代表词向量的维数。当卷积作用在滑动窗口步长为2的句子上时,将得到119个输出结果。其操作如式(1)所示
ci=f(W*vi,i+k-1+b)
(1)
W是卷积层权重矩阵,vi,i+k-1表示滑动窗口作用时第i个单词到第i+k-1个单词的词向量组成的矩阵,b代表偏置项,f为激活函数。本文中选用基于Relu函数的变体Leaky-Relu。其相较于sigmoid和tanh等饱和激活函数,Relu及其变体作为非饱和激活函数能解决“梯度消失”问题并加快收敛速度。而Leaky-Relu函数能够处理Relu函数在z小于0时,斜率为0的情况。其函数公式如式(2)所示
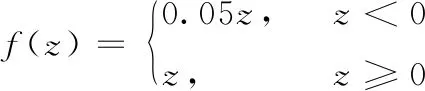
(2)
式中:0.05为斜率,函数图像如图3所示。
池化层对卷积核作用后的结果向量c=[c1,c2,…,c119] 做池化操作,实验中使用最大池化的变体2-Max Pooling,与Max Pooling相比,其能够提取所有特征值中得分最高的2个值,并且可以保留这些特征值原始的先后顺序。通过进行池化操作后,便得到每一个卷积层所抽取的特征集中相对于较为重要的部分,即问题和候选答案的重要语义部分。图4为2-Max Pooling的示例。
图3 k=0.05时的Leaky-Relu函数

图4 2-Max Pooling示例
此外,为防止过拟合现象的产生,引入了Dropout机制[7],其原理是当数据在前向传播的时候,让若干神经元的激活值以一定的概率p停止工作,反向传播时再次激活。
2.3 融合层
融合层将经卷积神经网络学习后得到的向量与主题特征、词汇特征。词汇特征和主题特征均采用one-hot编码。其中主题特征由数据集中的Title项提供。词汇特征由斯坦福大学提供的Standford CoreNLP工具包[8]进行处理获得,其中主要包括词性和命名实体识别两项,英文词性标注集合共有36种。表1给出了一个英文例句在经过Standford CoreNLP工具包处理后的示例结果。

表1 英文例句处理结果示例
表中第三行对应例句中每个单词的词性标注结果,其中NNP代表专有名词单数形式,VBD代表动词过去式,DT代表限定词,NN代表名词单数形式,TO代表单词to。表中第四行对应例句中每个单词的命名实体关系特征,其中人名Kosgi Santosh被识别为PERSON,校名Stanford University被识别为ORGANIZATION,而其它非命名实体均用O来表示。
2.4 双向门控循环单元
随着深度学习的兴起,长短时记忆网络模型因为其学习过程更容易收敛且规避了循环神经网络的梯度爆炸和梯度消失问题,正在自然语言处理研究中发挥着越来越重要的作用,本课题所使用的门控循环单元是基于长短时记忆网络模型而提出来的一种变体方式[9],相较于由遗忘门单元、输入门单元、输出门单元和记忆细胞单元组成传统记忆块,门控循环单元只有一个更新门单元和一个重置门单元,且取消进行线性自更新的记忆细胞单元,而是在隐藏单元中利用门控直接进行线性自更新。其记忆块的结构如图5所示。
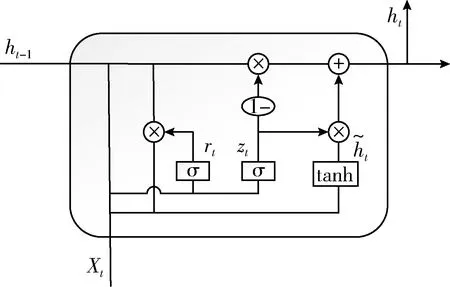
图5 门控循环单元记忆块结构
更新门单元主要用于控制前一时刻的状态信息有多少被带入到当前状态中。将前一时刻的状态信息和当前时刻的状态信息分别进行线性变换,再将相加后得到的数据送入到更新门单元,更新门单元的值zt越大说明前一时刻的状态信息被带入的越多。如式(3)所示
zt=σ(Wz·[ht-1,xt])
(3)

rt=σ(Wr·[ht-1,xt])
(4)
门控循环单元不再使用单独的记忆细胞单元存储记忆信息,而是直接利用隐藏单元记录历史状态。利用重置门单元rt控制当前信息和记忆信息的数据量,并生成新的记忆信息继续向前传递,由于重置门单元的输出在区间 [0,1] 内,因此利用重置门单元控制记忆信息能够继续向前传递的数据量,当重置门单元的输出值为0时表示记忆信息全部消除,反之当重置门单元的输出值为1时,表示记忆信息全部通过。如式(5)所示
(5)
(6)
单向门控循环单元主要是根据之前时刻的时序信息对下一时刻的输出做预测,但是在有的一些问题里,当前时刻的输出不单与之前的状态信息有关,与未来的状态信息也可能有关系,因此双向门控循环单元[10]便应运而生,即在正向门控循序单元的基础上添加反向门控循环单元,使其能够同时对两个方向的序列进行操作,每个节点会生成正向与反向两个独立的门控循环单元输出向量,然后将这两个独立的输出向量进行拼接作为当前节点的输出结果,由此得到当前节点的向量信息。简单来说可以将双向门控循环单元看成是一个两层的神经网络,第一层是从左侧作为序列的输入端,在文本处理上即是从句子的开头开始输入,而第二层则是从右侧作为序列的输入端,即是从句子的最后一个词语作为输入,反方向做与第一层同样的操作。最后对得到的两个结果进行拼接处理。图6为双向门控循环单元。

图6 双向门控循环单元

(7)
2.5 多层感知器
感知器网络是一种典型的前馈人工神经网络模型,采用单向多层的结构,每层均包含若干个神经元,同层的神经元相互之间无连接,每层之间信息的传送只沿一个方向进行,即从输入层开始接收信息,处理后输出到下一层,直至输出层获得最后结果[11]。第一层称为输入层,最后一层为输出层,中间为隐藏层。隐藏层可以是任意层。图7为含有一个隐藏层的多层感知器。
图7 含有一个隐藏层的多层感知器
在本文方法中,将双向门控循环单元层得到的ht送入多层感知器计算当前候选答案at的预测得分scoret,具体如式(8)所示[12]
scoret=σ(Wyht+by)
(8)
式中:Wy、by分别表示权重矩阵及偏置。
2.6 输出层
输出层使用softmax分类器对每个候选答案对应的分数进行处理,选取概率最大的值作为最后结果。其计算公式如式(9)所示
Softmaxi=escorei/∑jescorej
(9)
3 实验与分析
3.1 数据预处理
本文研究中使用微软公司在2015年公开的WikiQA英文数据集,其是一个应用于开放领域问答的数据集,共含有3047个问题和对应的29 258个答案,其问题是筛选自微软公司推出的必应(Bing)搜索服务平台下的查询日志中的真实用户提问信息。用户搜索的问题均连接一个与所查询问题的主题有关的维基百科页面,并将此页面中摘要部分的每一句话选为该问题的候选答案集合,通过使用人工的方法对所有问答对进行正确与否的标注[13]。表2给出了WikiQA数据集中的详细信息。

表2 WikiQA数据集信息
3.2 超参数设置
根据文献中的经验值,卷积神经网络层中卷积核长度设置为3、4、5,卷积核个数分别设置为50,dropout的比率设置为0.5,Adam学习率设为0.01,batch_size设为64,神经元的激活函数使用Relu。双向门控循环单元层中单层隐含层状态设置为150维,学习率、dropout比率和卷积神经网络层设置一致。多层感知器层中采用RMSprop优化器,dropout比率和卷积神经网络层设置一致。卷积核个数不同时的结果如图8所示。
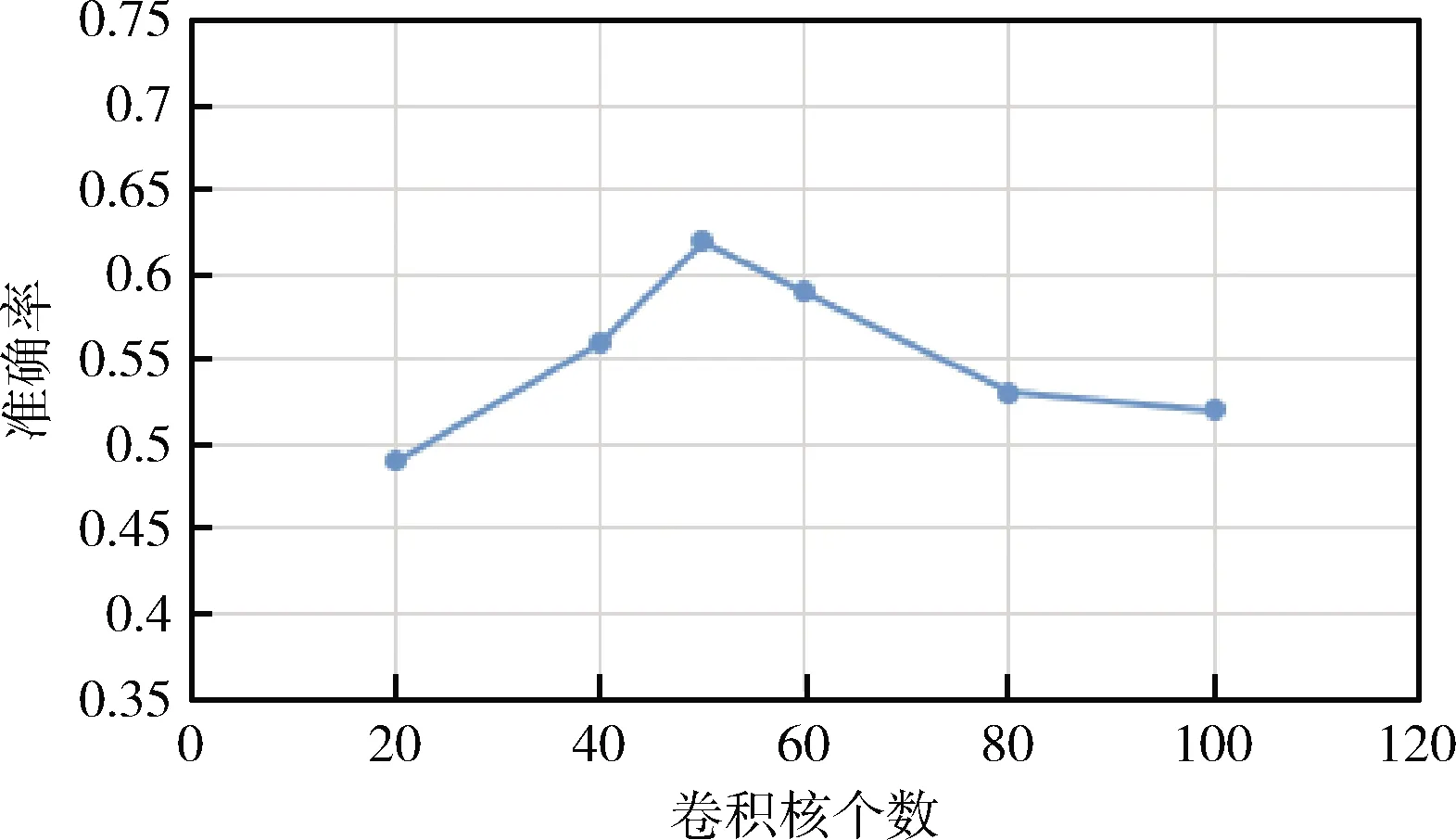
图8 卷积核个数不同时的结果
3.3 实验分析
使用自对比实验的方式分析本文所提方法的答案排序性能。CNN方法是通过对问题和候选答案的分布式表示进行卷积池化操作后,将结果送入softmax进行分类。CNN+WORD是对问题和候选答案的分布式表示加入词汇特征后再送入卷积神经网络。LSTM是利用长短时记忆网络提取问题和候选答案的特征。Bi-LSTM是在单向LSTM的基础上又添加反向的LSTM,由此得到两个相互独立的LSTM输出向量,然后将这两个独立的LSTM输出向量拼接作为当前节点的输出。Bi-GRU是基于门控循环单元(GRU)作为LSTM的一种变体情况下演变而来的。Bi-GRU+WORD+TOPIC是在Bi-GRU的基础上将词语的向量表示与词汇特征和主题特征相融合作为输入送入网络。CNN+Bi-GRU是将卷积神经网络和双向门控循环单元做结合,CNN的输出结果作为Bi-GRU的输入内容。CNN+Bi-GRU+MLP+WORD+TOPIC则是本文所提出的新方法。具体实验结果对比见表3。

表3 实验结果对比
在此自对比实验的基础上,又进行了进一步的对比实验。Word Cnt是计算问题和候选答案中相同词的个数作为评价标准。PV-Cnt是先对问题和候选答案进行向量化表示,同时计算问答对的语义相似度,再与词共现特征做拼接组合。CNN-Cnt是采用卷积神经网络与词共现特征结合的结果。CNNlexical[14]在得到问题和候选答案的分布式表示后,通过对两者中的词语分解引入词汇特征,然后对候选答案打分。Bi-LSTM+Lexical+Topic+Cnt通过在 Bi-LSTM 模型中加入词汇特征、主题特征、词共现特征后对候选答案进行判断。对比中使用新的评价指标平均AP值mAP(mean average precision),AP就是对一个问题,计算其命中时的平均精准度,而mAP则是在所有问题上求平均,mAP的计算方法如式(10)所示,其中AP表示平均精准度,q表示在单个类别的总样本个数,QR表示问题类别数量。具体模型结果对比见表4
(10)

表4 模型结果对比
通过对比上述发放可知,本文所提出的融合多种神经网络与多特征的答案排序模型的准确率均高于现有模型。
4 结束语
本文提出了一种融合多种神经网络与词汇特征、主题特征等多种特征信息的答案排序模型。用Word2vec分别对问题和候选答案进行词向量表示,并送入到卷积神经网络,将卷积池化后的结果与词汇特征、主题特征拼接后作为双向的门控循环单元的输入,输出结果经多层感知器进行处理后,使用softmax进行多分类处理。该模型在WikiQA英文数据集上取得不错的效果。此外,通过研究发现,融合特征信息后的效果要明显优于简单的深度学习模型,说明特征信息在一定程度上起到了作用。
考虑到引入部分特征能够对准确率起到作用,且对于长文本问答对中,过多的冗余信息也会对准确率造成一定影响。因此,结合当下神经网络研究的热点之一注意力机制[15],下一步的工作将选择性地加入更多特征信息,尝试把注意力机制与模型相结合,以期进一步提高答案排序效果。
