基于注意力机制的人脸表情识别迁移学习方法
2021-03-23李思禹
亢 洁,李思禹
(陕西科技大学 电气与控制工程学院,陕西 西安 710021)
0 引 言
人脸表情[1,2]识别最核心的部分是特征提取。经典的方法都是以人工特征为基准进行提取的,如LBP[3]、HOG[4]等。但是特征选取的好坏直接决定了表情识别准确率的高低,这对于表情识别是极其不稳定的。卷积神经网络(convolution neural network,CNN)不需要手动提取特征,然而提高卷积神经网络的人脸表情识别性能最直观的方法是堆叠更多的层,因此网络基础结构也在研究中随着性能的提升而不断增大。卷积神经网络的另一个缺点是依赖于大量的数据驱动,尤其是在人脸表情识别中,很难获取大量识别场景下的标注表情数据集。此时将现有的小型已标记的数据集应用于具有大型基础结构的网络中,容易产生过拟合,网络识别性能下降。
针对以上问题,本文提出了一种基于注意力机制的人脸表情识别迁移学习方法。该方法具有以下两个特点:设计了一个基于特征分组和空间增强注意力机制(spatial group-wise enhance module,SGE)[5]的轻量型卷积神经网络来有效提取人脸表情特征;利用迁移学习在目标函数中构造了一个基于log-Euclidean距离的损失项来减小源域与目标域之间的分布距离。
1 本文方法
1.1 基于注意力机制的人脸表情识别迁移学习方法
迁移学习的主要思想是对源域的标注数据或知识结构进行迁移,以完成或提高目标领域的学习效果。领域自适应是迁移学习重要的一个分支,其目的是在不同领域内存在差异的情况下传递知识。它可以应用在当目标域的数据未标记,而源域数据已标记的情况,最终目标是最小化源域和目标域之间的相关性差异,并成功将在源域上训练的模型转移到目标域。
本文提出了一种基于注意力机制的人脸表情识别迁移学习方法。该方法由两个相同的卷积神经网络组成,其中一个卷积神经网络的输入是已标记的源域人脸表情数据,另一个网络的输入是未标记的目标域人脸表情数据。源域卷积神经网络和目标域卷积神经网络之间共享相同的权重参数。由于卷积神经网络的全连接层将分布式特征映射到样本标记空间,因此利用全连接层作为域适应适配层来实现域适应。通过域适配层得到表征源域和目标域数据的分布特征后,构造了一个基于log-Euclidean距离[6]的损失函数,以此来计算提取到的源域和目标域特征之间的分布距离,并将其视为两个域之间的相关性差异。接着在卷积神经网络进行参数更新的过程中,结合了分类损失和log-Euclidean损失一起进行联合训练,最大程度减小了源域和目标域之间的相关性差异,在训练结束时两种损失达到平衡状态,最终可以使目标域得到有效的表情分类。本文方法在训练过程中,有标签的源域数据用来计算多分类损失,而对于新构造的基于log-Euclidean距离的损失项,所提网络结构中所有输入均参与。该方法中还设计了新的网络结构,引入了残差恒等块和注意力模块SGE,丰富了特征连接,增强了人脸表情的特征学习。本文网络整体结构如图1所示。
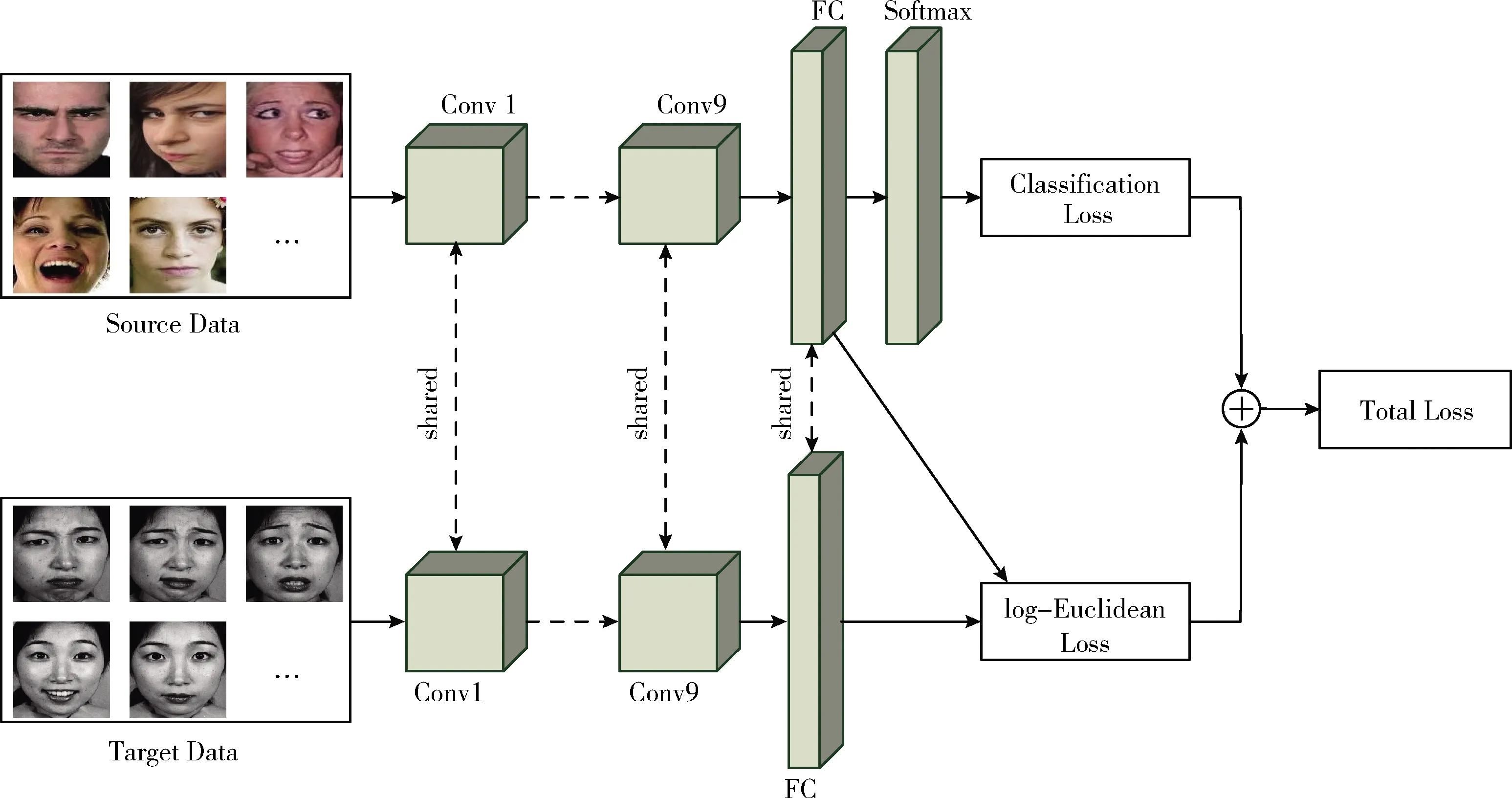
图1 基于注意力机制的人脸表情识别迁移学习方法结构
本文提出的基础网络主要由9个卷积层、6个最大池化层和两个全连接层组成。该网络中9个卷积层的卷积核大小均为5*5,步长均为1,通道数依次为64、64、64、128、128、128、64、64、64,并且每个卷积层后都分别加有批量归一化(batch normalization,BN)[7],激活函数ELU(exponential linear unit)[8]和注意力机制SGE模块。该网络在卷积连接中存在3个残差恒等块,网络中的残差恒等块结构如图2所示,其中包含了两个卷积层和两个SGE模块,它可以将输入直接与后面SGE模块的处理结果之和输出给下面的网络层。池化层在第1、3、4、6、7、9个SGE模块之后,所有池化窗口大小为3,步长为2。全连接层在以上所有网络层之后,分别是一个64维的域适应适配层和一个用来输出7类表情预测的Softmax分类器。整体网络结构如图3所示。
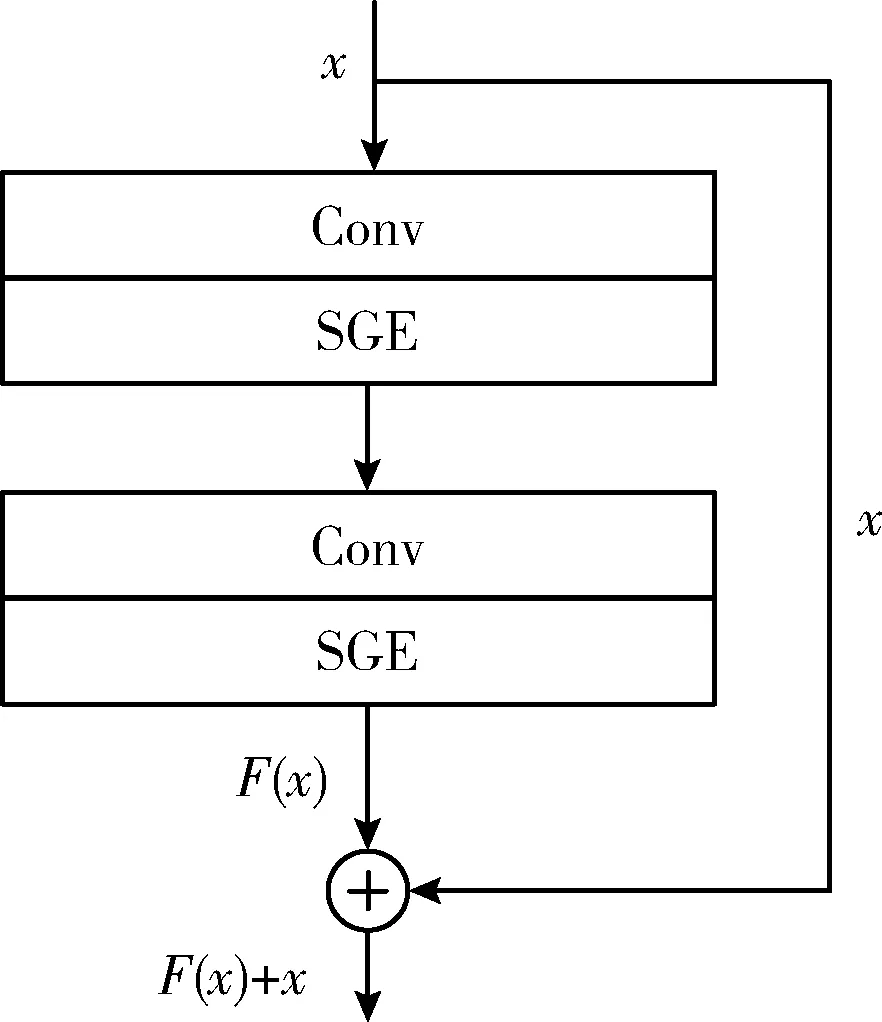
图2 残差恒等块结构
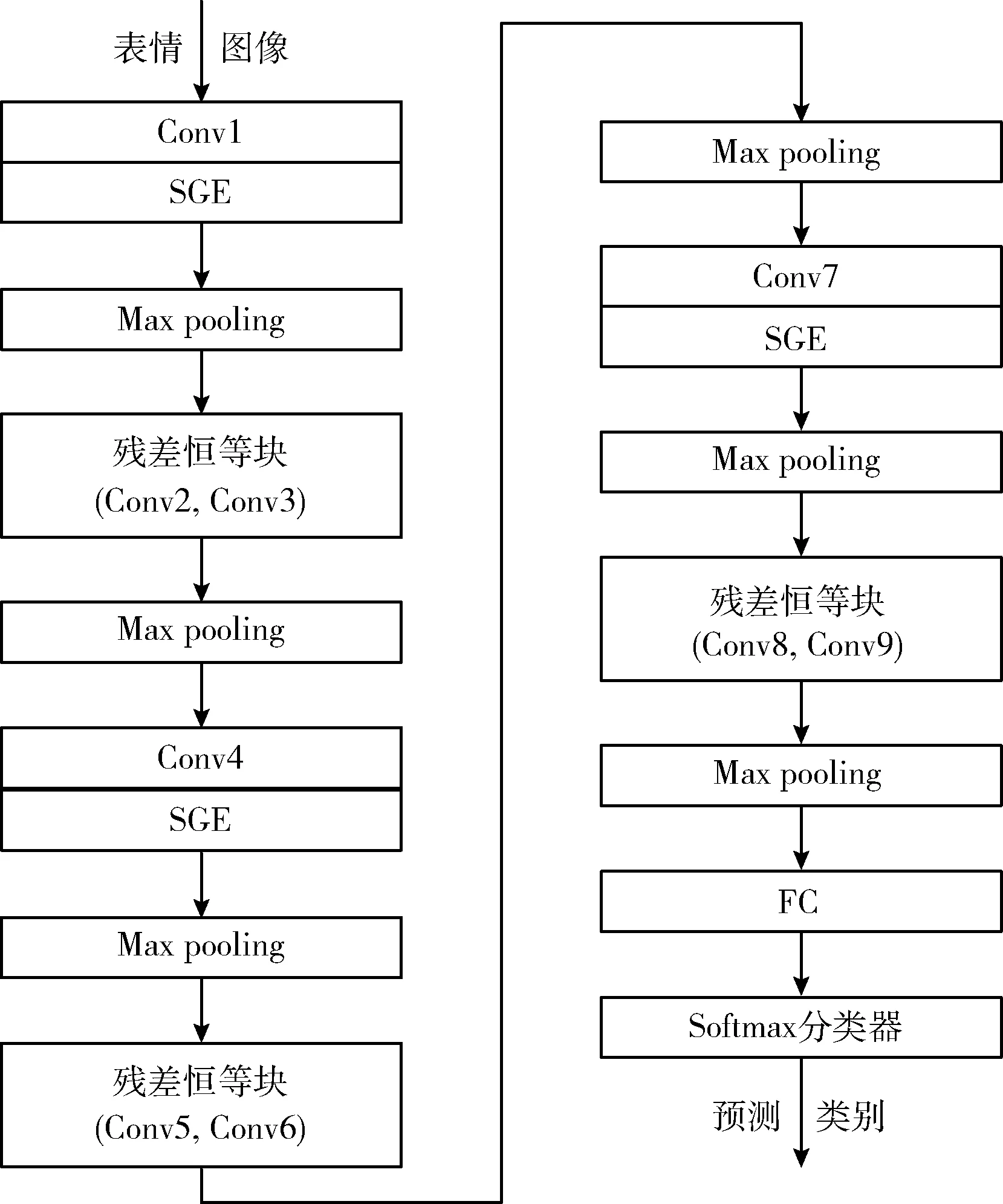
图3 卷积神经网络结构
1.2 基于注意力机制的人脸表情特征提取
人脸表情识别的重点在于特征提取。本文网络引入注意力机制SGE模块帮助网络更加精确地提取人脸表情特征。SGE模块采用了特征分组的思想,沿通道将卷积特征分组为多个子特征。由于缺乏对人脸表情特定区域或细节的监督,同时表情图像中可能会存在噪声,表情特征的空间分布会出现不稳定的情况,从而会削弱局部表情特征的表达能力。为了使每一组特征在空间上具有鲁棒性和良好分布性,SGE在每一个特征组内建立了一个空间增强机制,使用注意遮罩在所有位置上缩放特征向量,注意遮罩的生成源为全局统计特征和局部特征之间的相似性。这种设计能有效抑制噪声,并能突出语义特征重点区域。其目的在于提高各组不同语义子特征的学习,并自我增强组内空间分布。SGE模块的结构如图4所示。
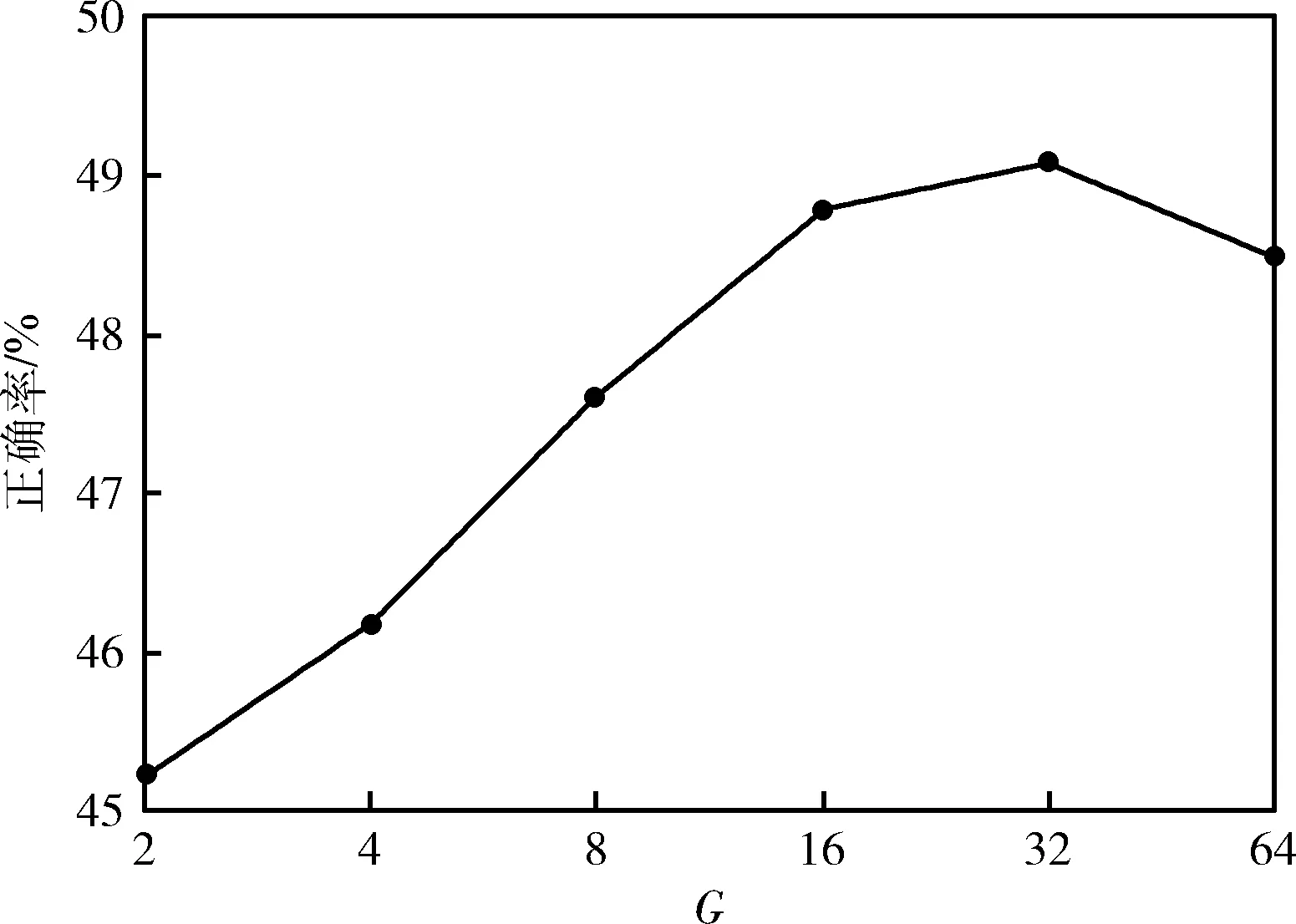
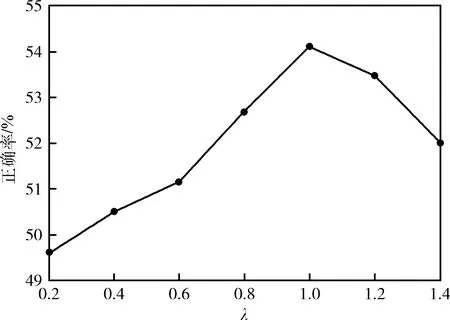
该注意力机制SGE模块首先将一个C通道,H×W的卷积特征沿通道数划分为G组。SGE并行处理所有的子特征组,同时在每个子特征组内进行单独的注意操作。其中一个特征组在空间内的每个位置上都存在一个特征向量,在这里将此原始特征向量表示为xi,xi∈RC/G,1 (1) 接下来,利用组内的全局特征和原始特征的点积结果,来获得每个特征对应的注意系数,将此注意系数记为ci,则有 ci=g·xi (2) (3) (4) (5) (6) 图4 SGE模块结构 (7) 人脸表情识别最终要解决的问题的本质是利用卷积神经网络提取一组图像的特征向量并将其类别划分为K类。网络在预测过程中用分类器来为给定的这组图像提供一个属于K类中每个类的概率。在本文所提的实际问题中,即将一组人脸表情数据分为7类(6类基本表情和正常表情)。在迁移学习中,定义了源域表情数据为XS,源域表情标签为y,无标签的目标域表情数据为XT。 将源域XS和标签y输入源域卷积通道,将目标域XT输入目标域卷积通道,在提取源域和目标域的人脸表情特征之后,利用log-Euclidean距离来计算两个域之间的表情特征相关性差异,然后使其和多分类损失一起作为优化目标来实现源域和目标域之间的相关对齐。 首先,用CS和CT来分别表示源域和目标域的特征协方差矩阵,则有 (8) (9) 其中,nS和nT分别表示源域和目标域数据的个数,1表示一个列向量,所有元素都为1。一般情况下,两个域之间的相关性差异利用协方差定义,假设此处将相关性差异用基于Euclidean距离的方法表示,则有 (10) (11) 式中:U和V分别表示CS和CT的对角化矩阵,σi和μi(i=1,…,d) 为相应的特征值。此时考虑到,若只最小化分类损失,可能会导致对源域过度拟合,从而降低目标域上的性能,另外,若单靠最小化log-Euclidean距离可能会导致表情特征一定程度上的退化。最终,使用多分类损失函数与此距离一起来定义为迁移学习的总损失,则有 l=lclass+λllog(CS,CT) (12) 式中:l表示迁移学习的总损失,将会作为最终的优化目标来更新网络参数,lclass表示源域的多分类损失,llog(CS,CT) 表示源域和目标域之间的分布距离,λ表示权衡分布距离在网络中作用的权值。多分类损失函数的定义为 (13) 式中:yp表示网络预测的表情类别,y表示真实的表情类别,i表示已定义的表情类别数目。在训练结束时,多分类损失和基于log-Euclidean距离的损失项会达到一定平衡,最终能够在源域数据上保持良好分类精度的同时,也在目标域数据上获得更好的人脸表情分类性能。 本文实验用到了3个人脸表情数据库,分别为RAF-DB[10]、JAFFE[11]、CK+[12]。 RAF-DB[10]数据库的人脸图像均来自互联网,共有29 672张。该数据库提供了7类基本表情的子集和11类复合表情的子集。本文实验借助其7类基本表情(生气、厌恶、害怕、高兴、悲伤、惊讶、正常)的子集进行训练,共包含15 339张图片。本文在实验之前,对该数据集进行了相关预处理。主要原因在于该数据集的各类表情数量相差很大,差距最大的两类表情为害怕(355张)和高兴(5957张)。因此,本文将该数据集进行均衡化处理,主要表现在对数量多的表情进行过采样处理(包括对图像的水平翻转和随机旋转操作),对数量少的表情进行欠采样处理。处理后的数据集包含14 640张图片,各类表情数量相对平衡。 JAFFE[11]数据库是一个来自实验室的图像数据库,包含来自10个日本女性的213个表情图像,其中每个人均有7类基本表情,每种图像表情有3张或4张。由于该数据集中的图像包含无关表情区域,因此本文在实验之前对其做了裁剪,只保留了人脸表情区域,实验中使用的数据全部为裁剪后的人脸表情图像。 CK+[12]同样是实验室数据库,包含123名受试者的593个视频序列,其中有标记的只有309段表情序列,标记规则为6种基本面部表情。本文实验从此309段表情序列中提取最后1帧到3帧和每个序列的第一帧,以此作为正常表情,然后将其与上述提到的已标记的6种表情组合起来,作为本文实验的7类表情数据集,共包含1236张图片。 本文实验主要分为两组,一组是从RAF-DB数据集到JAFFE数据集的人脸表情迁移实验,另一组是从RAF-DB数据集到CK+数据集的人脸表情迁移实验。即源域数据为有标签的RAF-DB人脸表情数据集,目标域数据为无标签的JAFFE人脸表情数据集和无标签的CK+人脸表情数据集。 本文所有实验均将3个数据集中的人脸表情图片缩放到56×56像素大小之后再输入至网络中,训练数据批量大小为128,并采用学习率为0.009,动量为0.9,权值衰减系数为0.0001的动量梯度下降法进行训练,输出为不同类别表情的概率。 本文实验是基于Tensorflow的深度学习框架构建的,编程语言及版本为Python3.6.5,使用的CPU为内存16 G Intel(R) Core(TM)i7-8700,GPU为11 GB的NVIDIA GeForce GTX 1080 Ti。 本文实验的评价准则之一为人脸表情识别正确率,其定义为 (14) 式中:Ni表示为第i类识别正确的表情数量,nT表示为目标域数据的表情数量。 2.3.1 通道分组数对比实验 本文实验将基于特征分组的注意力机制模块SGE嵌入到卷积神经网络中,并研究其通道分组数G对网络性能的影响。SGE模块中的通道分组数G取值不同,则相关语义子特征的数目不同。因此,一定存在一个合适的分组数G,可以相对平衡表示每个语义,从而优化网络性能。本文在未使用迁移学习的条件下,对G=2,4,8,16,32,64这6种情况进行对比实验,实验结果如图5和图6所示。 图5 JAFFE表情识别正确率 图6 CK+表情识别正确率 结果显示,在G=2时,网络在两个数据集上的人脸表情识别正确率最差,数据集JAFFE上的正确率为45.23%,数据集CK+上的正确率为58.81%。当G的逐渐增大时,网络的表情识别正确率逐渐升高。在G=32时,网络在两个数据集上均达到正确率的最高值,数据集JAFFE上的人脸表情识别正确率为49.09%,数据集CK+上的人脸表情识别正确率为60.34%。当G增大到64时,网络在两个数据集上的识别正确率开始下降,分别为48.50%和60.09%。可以看出,随着G的增加,网络的性能呈现出先升后降的趋势。因为通道数是固定的,分组过多会减少组内语义子特征的维数,导致每个语义响应的特征表示较弱,反之,分组过少会限制语义特征表达的多样性。显然,当G=32时在本文网络框架中能得到最好的特征平衡,因此,本文将选择G=32来进行后续所有的实验。 2.3.2 惩罚系数对比实验 惩罚系数λ是一个权值,在源域上用分类精度来权衡域适应的效果。因此,一定有一个相对合适的λ值来权衡迁移的程度。本文实验选取λ=0.2,0.4,0.8,1.0,1.2,1.4来进行对比人脸表情识别的分类效果,实验结果如图7和图8所示。 图7 JAFFE表情识别正确率 图8 CK+表情识别正确率 结果显示,随着λ的增加,网络的人脸表情识别性能先增大后减小。在λ=0.2时,数据集JAFFE上的人脸表情识别正确率为49.61%,比未使用迁移学习时高0.52%,数据集CK+上的人脸表情识别正确率为60.97%,比未使用迁移学习时高0.63%,说明加入迁移之后对网络的识别性能有一定帮助。当λ逐渐增大时,网络的表情识别正确率逐渐升高。显然,当λ=1.0时,表情识别正确率最高,在数据集JAFFE上达到54.12%,在数据集CK+上达到65.03%,在两个数据集上分别比未迁移时高出5.03%和4.69%。当λ增大到1.2时,网络的表情识别率在两个数据集上的表情识别率开始下降,分别为53.49%和64.39%,当λ继续增大时,正确率更低。说明惩罚系数并不是越大越好,如果让λ继续增大,网络的识别正确率可能会出现低于未使用迁移时的正确率。因此选择合适的惩罚系数能更好地权衡域适应的效果,对网络的识别性能相当重要。 2.3.3 不同方法对比实验 为了验证所提方法的有效性,本文通过人脸表情识别正确率,卷积神经网络参数量和卷积神经网络计算复杂度(floating point operations,FLOPs)这3个指标将本文提出的卷积神经网络(Our CNN)、使用迁移学习方法后的卷积神经网络(Our CNN & log-Euclidean)与常用的人脸表情识别网络AlexNet[13]、VGG16[14]和迁移学习方法Deep CORAL[15]进行了对比,实验结果见表1。 表1 不同网络对比实验 表1数据结果显示,在不使用迁移学习的情况下,本文方法在数据集JAFFE上的人脸表情识别正确率为49.09%,在数据集CK+上的人脸表情正确率为60.34%,比AlexNet网络在两个数据集中的正确率分别高出3.13%和3.45%,比VGG16网络在两个数据集中的正确率分别高出1.74%和2.27%,说明了本文网络在识别任务上有一定的成效。在加上迁移学习方法后,两个数据集的表情识别正确率分别可以达到54.12%和65.03%,这个结果比未加上迁移方法的识别正确率分别高出了5.03%和4.69%,比AlexNet网络分别高出8.16%和8.14%,比VGG16网络分别高出6.77%和6.96%,验证了本文所提的迁移学习方法能有效地减小源域和目标域之间的分布距离。此外,本文迁移方法的识别正确率在两个数据集上的识别正确率比迁移方法Deep CORAL分别高出4.35%和4.17%,足以验证了本文方法在优化源域和目标域之间的相关对齐问题上的优越性,更适用于人脸表情识别任务。 另外由表1还可以可以看到,本文网络的参数量大约为1.7 M,AlexNet网络和VGG16网络的参数量大约为62 M 和138 M,本文网络的参数量在一众对比方法中最少,大约为AlexNet网络参数量的1/37,VGG16网络参数量的1/83。另外本文所提网络的计算复杂度为0.261 G,而AlexNet网络和VGG16网络的计算复杂度为0.727 G和16 G,大约为本文网络的3倍和61倍,表明本文所提网络运行效率较高,因此本文网络实现了轻量化的同时还取得了较高的表情识别正确率。综合两个数据集上实验结果,验证了本文所提方法在人脸表情识别任务上的有效性,并且有一定的应用价值。 图9和图10给出了相同实验环境下数据集JAFFE和CK+上实验结果的混淆矩阵,可以更加明了地观察到本文所提方法的人脸表情识别效果。结果显示,在JAFFE和CK+两个数据集中,本文方法对惊讶表情的识别正确率最高,分别为90%和93%;其次是高兴表情,正确率分别为77%和72%。通过观察表情图片发现,表情惊讶和高兴的表现特征较其它表情更为明显,表情惊讶大多都会表现出眼睛大睁、眉毛抬起、双唇分开等,表情高兴大多都会表现出下眼睑上扬、嘴巴变长、脸颊上升等。因此惊讶和高兴表情的识别正确率较高。从图中还可以看出,本文方法在两个数据集上对生气表情的识别正确率最低,分别为13%和4%。另外可以很明显地发现,本文方法很容易将生气表情识别为厌恶表情,这种情况在两个数据集中分别高达50%和61%,并且在厌恶表情的识别中,仍旧有不可忽视的一部分误识别为生气表情。通过观察发现,两个数据集中生气和厌恶表情的样例特征较为相似,都出现了相似程度的皱眉、皱鼻和嘴巴鼓起,给识别工作带来了一定的难度,因此混淆矩阵给出的结果相对合理。 图9 JAFFE混淆矩阵 图10 CK+混淆矩阵 本文提出了一种基于注意力机制的人脸表情识别迁移学习方法。该方法主体为两个相同且参数共享的卷积神经网络,其使用已标记的源域数据辅助训练未标记的目标域数据,且利用SGE模块将特征分组并使每个单独的特征组自主增强其学习表达,提高了网络的特征提取能力。最后在目标函数中构造了一个基于log-Euclidean距离的损失项,并将其与多分类损失一起作为优化目标来实现源域和目标域之间的相关对齐,提高了表情分类能力。实验结果表明,本文方法能够在自主增强人脸表情特征学习的同时,还能成功将源域知识迁移到目标域上,最终使目标域表情数据正确分类。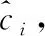
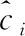
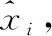

1.3 基于迁移学习的人脸表情识别

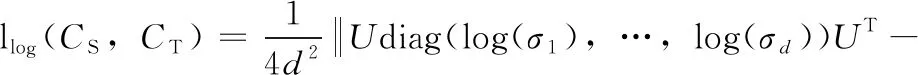
2 实验结果与分析
2.1 实验数据集及预处理
2.2 实现细节及实验环境
2.3 实验对比与分析





3 结束语
