基于Hadoop 分布式集群搭建方法研究
2021-03-23罗利
罗利
(湖南信息职业技术学院,湖南 长沙410299)
Hadoop 是开源的大数据平台,其分布式文件系统HDFS 进行数据存储,计算框架MapReduce 做数据计算。用户不需了解底层实现细节就可以实现海量数据存储计算。实际生产过程中Hadoop 平台搭建需要多个物理服务器,但是学生学习过程中并没有真实的服务器供学习。
1 环境准备
Hadoop 完全分布式集群搭建环境需要至少3 台服务器,本实验选择在VMware WorkStation 15 中创建3 台虚拟机,各系统环境要求集群节点规划信息如表1 所示。
1.1 安装JDK
CentOS7 预装了OpenJDK,先删除OpenJDK。下载匹配环境的JDK jar 包,解压,将JDK 路径添加到/etc/profile 末尾:
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile 使文件生效。java -version 检查JDK 是否安装成功,如果成功,会出现java 版本号等信息。
1.2 安装Hadoop 2.7.2
本文采用的Hadoop 版本为Apache Hadoop2.7.2。下载匹配环境的Hadoop jar 包,解压,修改/etc/profile 文件:
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
source /etc/profile 使文件生效,hadoop version 检查Hadoop是否安装成功。
1.3 克隆3 台虚拟机
将上述已经安装好JDK 和Hadoop 的节点克隆2 个节点,对新节点的MAC 地址重新生成,保证唯一性。
1.4 修改主机名
编辑/etc/hostname 文件,修改3 个节点主机名分别为master、slave1、slave2,用hostname 查看是否修改成功。
修改文件vi /etc/hosts,建立IP 地址和主机名映射关系:
192.168.200.100 master
192.168.200.101 slave1
192.168.200.102 slave2
再 关 闭 防 火 墙 , 在 /etc/selinux/confi 中 设 置“SELINUX=disabled”,systemctl disable firewalld 永久关闭防火墙。

表1 集群环境规划信息
1.5 SSH 免密登录
配置SSH 免密登录,实现多个节点之间不输入密码即可登录成功。
SSH 安全外壳协议,以master 节点免密登录slave1 为例,配置如下:
1.5.1 生成公钥和私钥。在master 节点的.ssh 目录(在用户家目录)下,执行ssh-keygen -t rsa,执行三个回车,生成公钥id_rsa.pub 和私钥id_rsa。
1.5.2 拷贝公钥到需要免密登录的目标节点。执行ssh-copy-id slave1 ,将公钥拷贝到slave1 节点上。
至此,在master 节点可以ssh slave1 直接免密登录。同理,在slave1 上需要配置免密登录maser、slave2,slave2 上需要配置免密登录maser、slave1。
2 配置集群[3]
在master 节点配置以下6 个配置文件。
2.1 hadoop-env.sh、yarn-env.sh、mapred-env.sh。这3 个文件中分别修改JAVA_HOME 环境变量,修改jdk 安装路径:
export JAVA_HOME=/opt/module/jdk1.8.0_144
2.2 core-site.xml。指定HDFS 中NameNode 的地址和Hadoop运行时产生文件的存储目录。

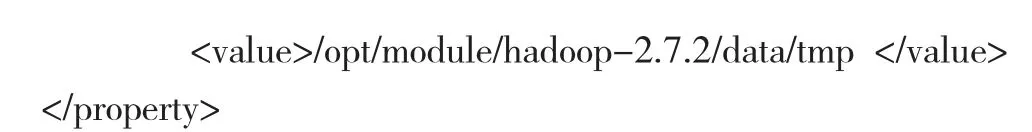
2.3 hdfs-site.xml。指定HDFS 副本数为3 和辅助名称节点配置。

2.4 yarn-site.xml。指定Reducer 获取数据的方式为mapreduce_shuffle 和YARN 的ResourceManager 的地址。

2.5 mapred-site.xml
执行cp mapred-site.xml.template mapred-site.xml 复制重命名文件,再修改指定MapReducer 运行在yarn 框架:

2.6 所有配置文件分发到slave1 和slave2 节点。
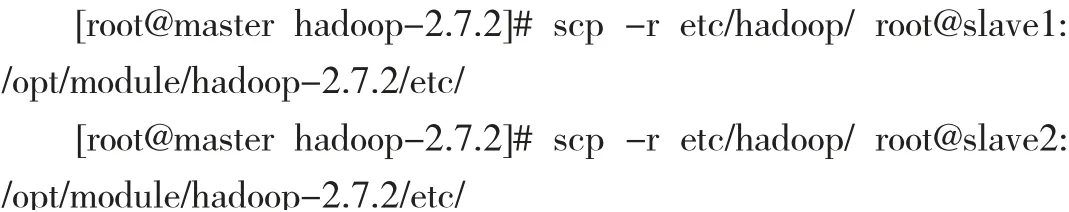
3 启动集群并查看状态
第一次启动集群,先格式化NamaNode,再启动集群。master节点执行hadoop namenode -format 格式化NamaNode,
配置slaves 文件,群起集群:
master
slave1
slave2
在master 节点直接用start-all.sh 命令启动所有进程,jps 查看进程:master 节点运行了NamaNode、DataNode、NodeManager进程,slave1 节点运行ResourceManager、DataNode、NodeManager进 程 ,slave2 节 点 运 行 DataNode、NodeManager、SecondaryNameNode 进程。
以上节点各项服务正常启动后,WEB 页面可查看Hadoop集群的运行状态,浏览器中输入http://NameNode IP:50070 打开HDFS 的管理界面。
4 运行应用程序
集群搭建成功后在集群上运行官方WordCount 案例,统计每个单词出现的次数。
4.1 在Linux 本地/opt/module/hadoop2.7.2 下新建目录winput,并创建测试文件word.txt,写入内容:

4.2 HDFS 根目录下创建目录testinput:
[root@master hadoop-2.7.2]# hadoop fs -mkdir /testinput
4.3 本地文件系统的word.txt 上传到HDFS 的/testinput 目录下:

4.4 运行wordcount 案例,将输出结果输出到/testoutput 下:

4.5 查看运行结果。

5 结论
本文利用虚拟机搭建了基于Hadoop 的大数据实验平台,以1 个master 节点和2 个slave 节点为例,介绍了Hadoop 集群分布式搭建的方法,最后使用该平台进行单词统计实验,经过测试实践,该搭建方法是正确的。说明利用普通PC 机集群环境简单方便、成本低廉,对课程教学提供易于实现的解决方案,为后续学习打下坚实的基础。
