基于Inception V3的高校学生课堂行为识别研究
2021-03-22柯斌杨思林曾睿代飞强振平
柯斌 杨思林 曾睿 代飞 强振平

摘要:随着人工智能和深度学习在教育领域的交叉融合,行为识别技术为学生课堂行为观察提供了一种有别于传统的新方法。以云南省X高校课堂视频为基础,经过预处理,获得六大类行为(听课、看书、书写、拍照、低头玩手机、桌面玩手机)30000張图像样本,运用Inception V3算法模型进行了研究,实验结果:六大类行为总识别率达到88.10%,但各个行为识别率有所不同,其中“拍照”和“听课”识别率较高。通过进一步的混淆矩阵分析,得到结论:模型对动作姿态单一的行为特征提取效果较好,但模型对手机、笔、课本等重要用具不够重视,不能识别书写动作和眼神角度,导致“看书”“书写”“低头玩手机”和“桌面玩手机”行为因人体动作姿态相似容易混淆。
关键词:Inception V3;深度学习;学生课堂行为;行为识别
中图分类号:TP391.41 文献标识码:A
文章编号:1009-3044(2021)06-0013-03
Abstract: With the cross-integration of AI and deep learning in the field of education, action recognition provides a new method for student classroom behavior observation, which is different from traditional method.Based on classroom video in X university of Yunnan province, this paper collects the original data by shooting students' class video.After preprocessing, the dataset of 30000 samples of six categories of behavior (watch, read, note, picture, eye-down, phone-desk) are obtained. And finally, action recognition of classroom behavior is preliminarily studied by using Inception V3 CNN model. Result: the total recognition rate of six categories of behavior is 88.10%, but the recognition rate of each behavior is different, "picture" and "watch" behavior are higher, other behavior are lower. Through further analysis of confusion matrix and error recognition samples, conclusion is drawn: The model has a higher recognition rate of simple action posture, behavior features extracted from deep learning are better. However, the model does not attach enough importance to the important props like phone, pen and book, it also can not recognize the "writing action" and "eye angle" very well, which leads to the confusion of "read", "note","eye-down", and "phone-desk" because of the similarity of action posture.
Key words:Inception V3;Deep Learning; Student Classroom Behavior; Action Recognition
课堂观察最早是由Flanders提出的对课堂教学进行观察和研究的基础方法,通过它可以评价教师的教育理念和教学效果,同时结合学生的课堂学习表现情况进行有针对性的反馈和改进[1],因此课堂观察不仅可以提高教师的教学能力,也可以提高学生的学习效果。而传统的学生课堂行为是通过教师对学生进行人工课堂观察来实现,由于种种原因,效果并不理想,在实际中并没有发挥它应有的作用。随着人工智能和深度学习的快速发展,行为识别技术为学生课堂行为观察提供了一种新的可能性。深度学习通过大量的样本训练,学习并提取学生课堂行为的视觉特征,最终形成特征模型,后期通过软件平台实现学生课堂行为这一教学过程数据的挖掘利用[2-3]:教学过程监测;教学策略调整;学生成绩预测[4-6],问题学生诊断及预警干涉[7];教师教学评估等等。可见学生课堂行为在智慧教育、个性化教育等方面都具有重要的现实意义。研究以云南省X高校的学生上课视频为原始数据,运用Inception V3卷积神经网络模型对学生课堂行为识别进行了研究,并根据实验结果结论提出了几个后继研究方向。
1数据采集、预处理和标注
1.1视频采集
学生课堂行为数据来源于高校学生上课视频,在阶梯教室共拍摄26课时,统一使用SONY NEX-FS700CK高清摄像机1920×1080分辨率拍摄。拍摄时,采用三脚架高角度固定构图拍摄以便采集到更好的方便预处理的视频。
1.2 数据预处理
数据预处理包括视频编辑、图像序列抽帧、样本抠图三个步骤:(1)视频编辑,对原始视频进行后期剪辑,剪去课前课后和课中休息的与正常教学无关的废镜头,最终导出25帧/秒的MPEG视频文件;(2)图像序列抽帧,实验使用2秒1帧的频率对视频进行采样抽帧;(3)样本摳图,实验使用PHOTOSHOP对图像序列进行自动批处理裁剪得到单个学生样本,抠图基本原则是学生个体不能有前景遮挡且背景尽量不要出现其他学生的脸部。
1.3学生课堂行为分类与标注
在进行样本训练前,应把所有样本进行初步分类,找出典型的值得研究的学生课堂行为。与中小学生不同,大学生的课堂行为较随意也更加多样化,在分类过程中,发现当代大学生喜欢用手机拍课件,这种课堂行为虽然发生次数不多且持续时间不长但是很普遍,严格来讲它属于学习行为,是记笔记的一种形式,和往常“手机在课堂中起负面作用”的印象是相反的,可见手机作为一种出现在课堂中的“道具”具有两面性,研究也把这个典型的课堂行为纳入其中。然后对非典型的课堂行为(如喝水、打哈欠等)和样本数量较少的课堂行为(如睡觉、举手等)进行二次清理,最终根据学生课堂行为姿态特征分为6大类(听课、看书、书写、拍照、低头玩手机、桌面玩手机),具体行为姿态画面特征如表1所示。
分类完成后经过人工标注,最终得到六大类学生课堂行为样本总共30000张,其中“听课”10870张,“看书”2480张,“书写”8310张,“拍照”580张,“低头玩手机”4220张,“桌面玩手机”3540张,各种行为比列基本符合高校课堂实际情况,其中学生A的课堂行为样本如图1所示。
2算法模型与实验结果
2.1 Inception V3算法模型
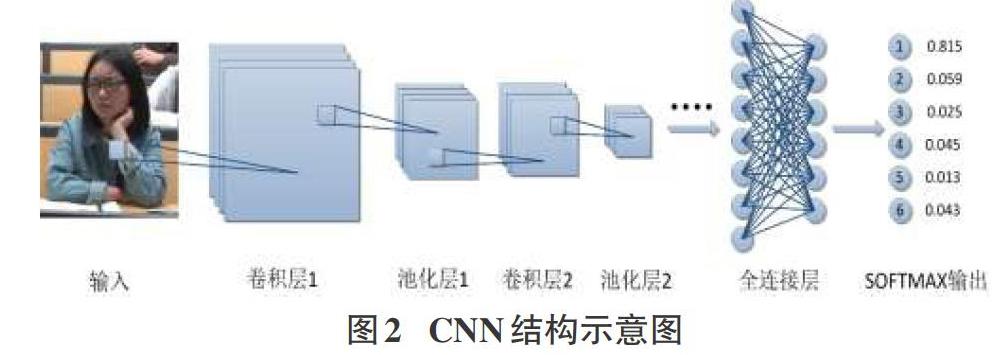
深度学习Deep Learning,源于人工神经网络,通过模仿人类大脑的思维方式以及神经网络的接收反馈方式进行计算机模拟学习,是人工智能领域最具有发展前景的一个分支。卷积神经网络Convolutional Neural Networks,简称CNN,是深度学习领域的代表算法和引领者,CNN模型由输入层、核心部分、输出层组成,而核心部分由卷积层、池化层和全连接层组成。如图2所示,在样本训练时,CNN一般通过3x3卷积核对224x224x3图像进行卷积操作生成特征图,通常在比较浅的卷积层中,卷积操作可以提取到比较细节的特征,在比较深的卷积层中,卷积操作把之前提取到的细节特征进行组合和二次提取,得到更高级、抽象的特征,最终在多神经元组成的全连接层中得到特征矩阵;在样本测试时,经过卷积操作和特征矩阵计算最终在SOFTMAX多分类器中输出结果,数值最大的即是识别结果。实验使用GoogLeNet的Inception V3模型,其网络结构共有22层,模型对图像进行1x3和3x1非对称多尺度并行卷积处理,将多个不同尺度的卷积核,池化层进行整合,形成一个Inception module模块,这种机制带来的一个好处是大幅度减少了参数数量,并且使得网络深度进一步提升的同时还增加了非线性表达能力。
2.2实验结果
实验使用Anaconda运行环境平台,Tensorflow深度学习框架,系统运行环境如下:WIN7 64位操作系统;CPU Intel(R) Core(TM) i7-6800K,3.40GHz;DDR4内存16G;250G固态硬盘;2T机械硬盘;显卡AMD Radeon(TM) RX 460 Graphics,4G显存。
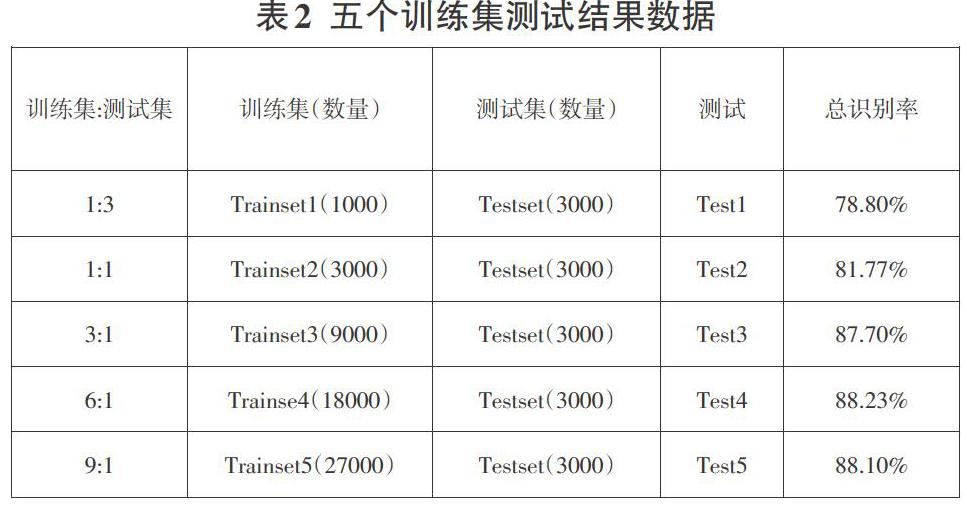
实验把标注好的数据集按照9:1比例划分,90%样本数据作为训练数据(27000张),10%样本数据作为测试集(3000张)。另外,为了分析训练集样本数量对各种行为测试识别率的影响规律,实验测试集Testset(3000张)始终不变,把27000张训练样本再划分为5个训练集依次进行训练和测试,如表2所示,是数据集划分和最终训练测试数据,结果表明:训练集的样本数量对测试结果是有影响的,在Trainset1和Trainset3区间,随着训练样本数量的增加,总识别率得到大幅提升,由78.80%上升到87.70%,说明此区间深度学习效果较好;在Trainset3和Trainset5区间,虽然训练样本数量的成比例增加,但是总识别率只有微幅提升和波动,最终达到88.10%,说明此区间训练样本数量对深度学习效果影响不大,接近于收敛状态。
如图3所示,是各类行为识别率趋势图,六类行为总结分析如下:(1)watch,识别率整体高于92%,比较稳定,随着训练样本数量的增加,识别率小幅提升后微幅波动,最终达到95.73%,说明深度学习特征提取比较理想;(2)read,识别率整体较低,随着训练样本数量的增加,识别率大幅提升,由18.24%最终上升到75.88%,说明深度学习特征提取还不够好;(3)note,识别率整体较低,比较稳定,随着训练样本数量的增加,识别率在波动中小幅提升,最终达到71.29%,说明深度学习特征提取不够好;(4)picture,识别率整体高于96%,也比较稳定,随着训练样本数量的增加,识别率微幅波动后最终达到97.37%,说明深度学习特征提取比较理想;(5)eye-down,识别率整体不稳定,随着训练样本数量的增加,识别率在波动中提升后反而大幅下降,最终达到76.36%,说明深度学习特征提取不稳定,可能是因为eye-down与其他行为的人体动作姿态相似容易造成混淆;(6)phone-desk,识别率整体一般,随着训练样本数量的增加,识别率在大幅提升后小幅下降,最终达到80.93%,说明深度学习特征提取不够理想。
3实验评估与分析
如表3所示,是Test5测试结果数据的混淆矩阵,针对6类行为对Trainset5训练模型评估如下:(1)模型对watch的识别率高达95.73%,效果较好,容易误判为read占比2.99%;(2)模型对read的识别率75.88%较低,容易误判为phone-desk占比11.76%,read和phone-desk行为人体姿态的确有很大相似之处容易造成混淆,都是小角度低头看桌面,仅仅从人体姿态来识别确实困难,两者不同的地方在于,read是看书,而phone-desk是看桌面上的手机,说明模型并没有完全提取到read和phone-desk的关键物品特征;(3)模型对note的识别率71.29%也较低,容易误判为watch占比13.23%和phone-desk占比11.61%,note和phone-desk行为人体姿态也有很大相似之处,都是小角度低头看桌面,两者不同的地方在于手势,note是拿笔进行书写动作,而phone-desk是操作桌面上的手机;(4)模型对picture的识别率高达97.37%,其余全部误判为watch;(5)模型对eye-down的识别率76.36%较低,容易误判为read占比23.18%,eye-down和read行为人体姿态有相似之处,都是低头看下面,关键区别在于低头角度,eye-down更低一些,几乎垂直地面大角度低头看桌面下的手机,而read是小角度低头看桌面上的书本,说明模型没有提取到两者的关键细微特征,行为识别不够细腻;(6)模型对phone-desk的识别率80.93%,容易误判为note占比15.37%,phone-desk和note的关键区别在于操作手机和书写动作,而且两者的手势有相似之处,并且phone-desk画面中手机具有一定的隐蔽性,增加了识别难度。
总体来说,训练模型可以较好地识别picture和watch两种人体姿态画面特征简单明显的行为,而对于姿态画面特征较相似较复杂的read、note、eye-down、phone-desk行为,存在普遍的混淆现象,模型的识别能力不够理想。
4 总结和展望
由于实验条件和样本数量有限,六大类学生课堂行为最终识别率只达到88.10%,仍然需要提升才能进入最终的应用软件研发阶段,而后继研究工作可以在以下几个方面进行突破和深入:(1)目标检测,从实验结果结论可以看出,“手机”“笔”和“课本”等重要课堂用具对学生课堂行为的识别具有重要的作用,甚至可以说这些课堂用具是某些行为的关键特征,是区别于其他行为的重要标志,picture和phone-desk必须有“手机”,note必须有“笔”,read必须有“课本”,因此关键物体的目标检测[8]具有很好的辅助作用;(2)运动检测,帧差法[9]通过计算代表“手”和“笔”这部分像素在图像序列或前后图像帧中是否有位移变化来识别是否有“书写动作”,适合于运动检测,可以通过它识别出“手”和“笔”是否真的在进行“书写动作”,只有存在“书写动作”才能判断是note行为,否则有可能是学生手上拿着笔(没有书写动作)却在“看黑板”或“看书”甚至“桌面上玩手机”;(3)眼神识别,眼神通常代表了学生的心理活动和注意力,是判断课堂行为的重要依据,眼神识别或头部姿态识别是六类行为的重要区分之一,read和eye-down行为姿态特征几乎相同,两者非常容易混淆,一个目视桌面书本,一个目视桌子下面,唯一的区别就在于眼神角度不同;(4)手势识别,手势在一定程度上也代表学生的注意力,note和phone-desk的重要区别就在于手势动作,因此手势识别的辅助可以提升模型区分note和phone-desk的能力。
总之,学生课堂行为识别不同于一般的图像识别,传统的图像识别只需要识别出某种物体即可,只要求学习到这个物体的关键共性特征,而行为识别要提取到人物或物体的行为姿态特征,难度大大提高。如果在关键物体目标检测、运动检测、眼神识别、手势识别等技术上实现突破,肯定会更容易识别学生课堂行为的关键动作姿态特征,最终提升整体识别率,加强算法模型的泛化能力,最终进入应用阶段。
参考文献:
[1] 方海光,高辰柱,陈佳.改进型弗兰德斯互动分析系统及其应用[J].中国电化教育,2012(10):109-113.
[2] 陈德鑫,占袁圆,杨兵.深度学习技术在教育大数据挖掘领域的应用分析[J].电化教育研究,2019,40(2):68-76.
[3] 柯斌,蘆俊佳.智慧教育背景下高校学生课堂行为数据挖掘与利用[J].电脑知识与技术,2020,16(26):148-150.
[4] 王亮.学习分析技术 建立学习预测模型[J].实验室研究与探索,2015,34(1):215-218,246.
[5] 牟智佳,武法提.教育大数据背景下学习结果预测研究的内容解析与设计取向[J].中国电化教育,2017(7):26-32.
[6] 丁梦美,吴敏华,尤佳鑫,等.基于学业成绩预测的教学干预研究[J].中国远程教育,2017(4):50-56.
[7] 范逸洲,汪琼.学业成就与学业风险的预测——基于学习分析领域中预测指标的文献综述[J].中国远程教育,2018(1):5-15,44,79.
[8] 尹宏鹏,陈波,柴毅,等.基于视觉的目标检测与跟踪综述[J].自动化学报,2016,42(10):1466-1489.
[9] 高凯亮,覃团发,王逸之,等.一种基于帧差法与背景减法的运动目标检测新方法[J].电讯技术,2011,51(10):86-91.
【通联编辑:王力】