学贯中西:让机器学习华夏智慧
2021-03-22高焕堂
高焕堂
0 前言
机器学习(ML)除了能够学习大数据(big data)中的规律和法则之外,也能够学习人类的智慧。华夏文化渊源长久、博大精深,处处充满智慧。因此,我们可以让机器来学习华夏的文化底蕴和智能,还能更上层楼而学贯中西。
1 复习:什么是特征(feature)
机器学习之路,首先从观察特征出发。回忆一下,人们对于周围的问题或事件常从不同的角度来观察或看出不同的特征。所谓特征(feature),就是一件事物或一群事物,其具有与众不同的特色或表征。例如,人们在辨别其他人的长相时,常常会观察对方的脸形、眼神、嘴巴、发型等特征来区分和判断,只要记住对方独特的长相特征就可以,而不必记忆其他细节。这是人们天赋的观察和提取特征的能力。再如,当您一大早从家里出门时,常常会先观察天气的特征:温度23℃、“阳光普照”等。
在前面各期曾经说明了ML(机器学习)的目的并不一定是拿数据来运算,而是在于〈观察〉在此X空间里数据的大小、分布及重复出现频率(次数)等。每一条数据成为空间里的一个点(point),而每一项特征则成为空间的一个维度(dimension)。于是,各条数据的特征值成为该点的坐标值。
2 特征的种类
在ML(机器学习)领域,特征常分为两种:数值型(Numerical)特征与分类型(Categorical)特征。“数值型特征”是大家很熟悉的,可以用整数或浮点数表示,是能拿来进行加减乘除等数学计算的特征(值)。例如刚才提到的气温是23℃。这就是一个数值特征。再如,人的身高、猫尾巴长度等也都是数值特征。至于分类型特征,又可细分为两种:次序型(ordinal)特征和名目型(nominal)特征。
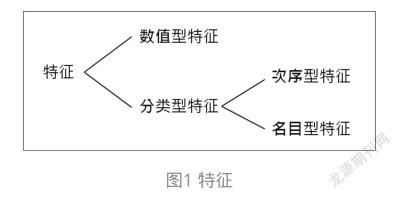
其中,“次序型特征”是具有顺序、可分等级的特征。例如,衣服的大小常常分为:小(S)、中(M)、大(L)、特大(XL)4个等级。再如,牛排的熟度可分为:Blue、Rare、Medium Rare、Medium、Medium Well和Well Done 6个级别。
再如,《孙子兵法》有言:“不战而屈人之兵,善之善者也。故上兵伐谋,其次伐交,其次伐兵,其下攻城。”其中分为4个等级:伐谋、伐交、伐兵和攻城。《孙子兵法》又言:“知彼知己,百战不殆。不知彼而知己,一胜一负。不知彼不知己,每战必殆。”其中分为三个等级:知彼知己、不知彼而知己和不知彼不知己。
“名目型(nominal)特征”只是对事物分门别类之后各类别的名称或标签而已。例如,性别:男、女。两仪:阴、阳。五行:金、木、水、火、土。它们之间没有级别之分。
3 如何对“分类型特征”进行编码
在ML领域,必须将分类型特征转换成数字,又称为对这些特征进行编码(encoding)。对于次序型与名目型特征,各有不同的方法将它们转换成数字。
例如,对于次序型(ordinal)特征常使用卷标编码(label-encoding)方式进行转换。例如,衣服的小(S)、中(M)、大(L)、特大(XL)4个等级对应1、2、3、4,这样特征(值)之间的大小顺序也就呈现出。再如,牛排熟度的Blue、Rare、Medium Rare、Medium、Medium Well和Well Done 6个等级对应1、2、3、4、5、6,这样就可以了。
另外,对于名目型(nominal)特征则常使用唯1编码(one-hot-encoding)方式进行转换,在中文里又称为“独热编码”。例如上述的两仪。
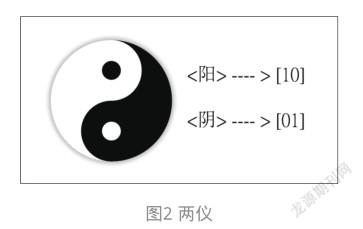
由于它们之间不具有顺序性,所以也可把“阳”对应成[01],而“阴”对应成[10]。

由于每一个编码中都含有一个1,其他都为0,所以称为One-Hot-Encoding编码;简称OHE编码。
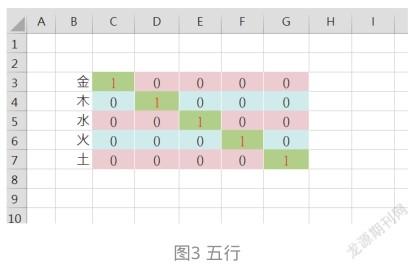
4 “分类型特征”的范例
刚才已经提到了华夏文化中的五行观念,就是金、木、水、火、土。使用OHE编码如下:
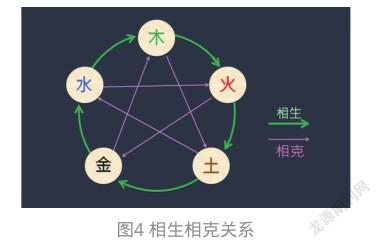
大家知道,五行之间有“相生”关系,也有“相克”关系。
现在,来建立一个两层神经网络(NN)模型,如图5所示。

以NN模型表示如图6所示。

在Z空间中设定了5个目标值,如图7所示。
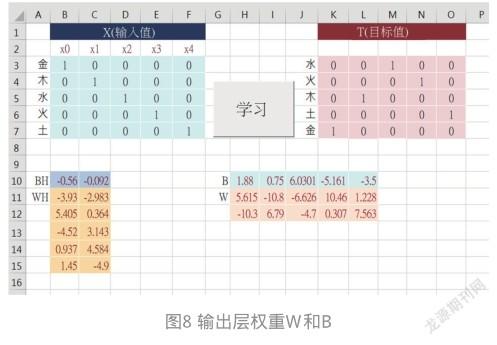
只要按下“学习”按钮,ML就会寻找出隐藏层的权重WH和BH,同时寻找出输出层的权重W和B。如图8所示。
有了隐藏层的权重WH和BH,以及输出层的权重W和B之后,就可以随时输入层X空间,对应隐藏层H空间,再对应输出层的Z空间,就得到预测值了。例如,把刚才训练好的权重拿过来,就可以随时输入X值,然后通过两层权重的计算得到Z预测值。这个过程,就是所谓的:预测(Predict)。如图9所示。
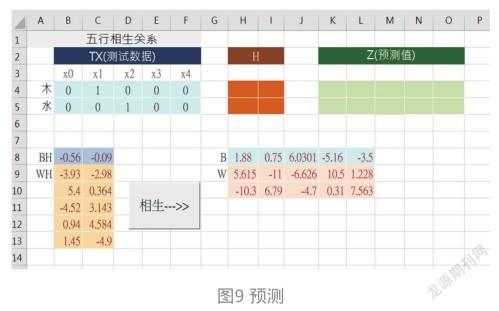
请按下“相生”,输入木和水的OHE编码,然后通过两层权重的计算得到Z预测值。如图10所示。
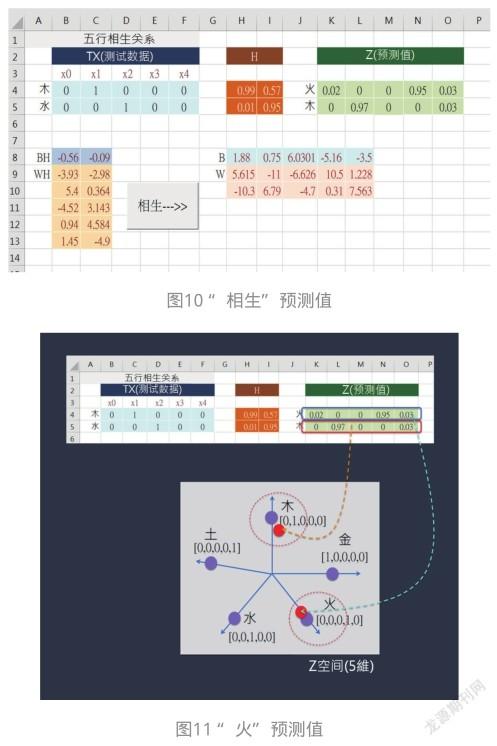
例如,输入测试数据:木=[0,1,0,0,0],通过NN模型的两层权重计算得到预测值。此时,ML计算出预测值:Z=[0.02、0、0、0.95、0.03]。那么,ML如何得知这个预测值就是“火”呢?非常简单,只要看看Z空间中这个预测值代表的点靠近哪一个目标值(点)就知道了。例如,预测值Z=[0.02、0、0、0.95、0.03],非常靠近[0、0、0、1、0],所以归于“火”类。如图 11所示。
同样,另一测试资料:水=[0、0、1、0、0],通过NN模型的两层权重计算得到预测值:Z=[0、0.97、0、0、0.03]。那么,ML如何得知这个预测值就是“木”呢?非常简单,只要看看Z空间中这个预测值代表的点靠近哪一个目标值(点)就知道了。例如,这预测值Z=[0、0.97、0、0、0.03],非常靠近[0、1、0、0、0],所以归于“木”类。
5 结语
善于使用OHE编码将非常方便表达华夏文化中的概念(Concept)和术语。然而,您可能会问:如果数千或数万个术语,其OHE编码将变得很冗长,实际上可行嗎?答案是没问题的。因为ML有很好的机制可以进行“降维”,能有效化解上述问题。下一期,将会继续说明。
3175501908239
