基于文本挖掘技术的《易经》可视化初探
2021-03-21岑萧萍高日阳刘秀峰
岑萧萍,高日阳,刘秀峰
1.广州中医药大学医学信息工程学院,广东 广州 510006;2.广州中医药大学基础医学院,广东 广州 510006
中医古籍蕴含着宝贵的古代名医经验,但由于其文本具有深奥难懂的特点,价值难以得到充分发挥。大数据时代的到来为中医古籍研究开辟了新思路,如基于关联规则算法对《诊方辑要》中中药配伍的研究[1],基于文本挖掘技术对《本草集要》中语义内容特征的分析[2]。然而,已有研究对中医古籍文本信息未充分利用,难以发挥其中潜在价值[3]。
《易经》作为十三经之一,是一部蕴含中医智慧的经典古籍,对于中医的发展起到了指导作用。由于其中蕴含象数的原理,结合现代数学与计算机技术能够发掘《易经》的科学性。2017 年,唐毅[4]采用计算机技术中的蒙特卡洛方法模拟蓍草起卦过程,计算《易经》六十四卦中各爻出现概率、变爻出现概率、卦间转化概率。然而对于《易经》文本的研究,目前限于文言文的理解角度,如张瑞芳[5]、任晓彤[6]对于《易经》动词配价与虚词的研究,缺乏对《易经》所体现核心价值的直观展现。文本挖掘技术作为一门从非结构或半结构的文字中发掘出先前未知、隐含而有用的信息的计算机技术,对文本内容的潜在价值挖掘有效。但目前对于文言文尤其经典古籍的文本挖掘研究较稀缺,且鲜见《易经》文本的挖掘研究。
《易经》与中医学有着密切联系,目前国内外已有一些关于二者联系的研究[7-9],但缺乏结合现代技术进行客观反映与验证。在大数据背景下,对中医古籍进行挖掘,将使其中关键知识与规律能被更好地抽取,辅助人们理解篇目庞大、晦涩难懂的中医古籍文本。本研究运用文本挖掘技术对《易经》中六十四卦爻辞进行探索,通过对各卦的关键词提取、聚类分析等得到卦爻辞间的联系与特点,运用可视化技术进行展现,并结合中医学理论进行阐释。
1 资料与方法
1.1 数据来源
本文基于《周易正义》中六十四卦爻辞[10],构建64 行8 列的数据集,每一行代表一支卦,第一、二列依次为卦名与卦辞,其后六列分别为初爻、二爻、三爻、四爻、五爻、六爻爻辞。
1.2 分词
分词是文本挖掘的关键步骤,其效果对挖掘结果可产生直接影响。目前已有的分词方法主要有盘古分词、jieba 分词等。有研究表明,在中医文献分词中,jieba 分词有较高的准确率,且结合自定义词库能够提升分词准确性[11]。本研究运用python 中的jieba 分词模块对数据进行分词,得到分词结果。依据文言文分词规律及《易经》注释文本,发现部分词划分不够准确。如“利见大人”应分为“利”“见大人”,但jieba将其分为“利见”“大人”。因此,导入自定义词库,添加“见大人”等词,提升了分词准确性。
1.3 去停用词
文言文中一些虚词大多无实际意义,需去除。常见的停用词表主要针对现代文,因此需自定义停用词表。18 个文言虚词包括:而、何、乎、乃、其、且、若、所、为、焉、也、以、因、于、与、则、者、之,将常见的18 个文言虚词以及所有文中出现的标点符号载入,在分词基础上剔除上述停用词。
1.4 Word2Vec 词向量表示
Word2Vec 是基于神经网络将文档中的词汇映射为词向量的一种词向量表示模型,由Mikolov 等[12-13]提出,可用来快速有效地训练词向量。Word2Vec 分为2 种模型,CBow 模型通过上下文来预测当前词,Skip-gram 模型则通过当前词来预测其上下文。由于本研究的数据量较小,选择运用Skip-gram 模型进行词向量训练[14]。
1.5 词频-逆文档频率文档表示法
词频-逆文档频率(TF-IDF)是用以评估一个词语对于一个文档集中某一文档的重要程度的统计方法。字词的重要性与其在文档中出现次数成正比并同时与其在文档集中出现频率成反比,即一个词语在一个文档中出现次数越多,同时在所有文档中出现次数越少,就越能够代表该文档。运用TF-IDF 文档表示法可将分词、去停用词后文本数据映射为文档-词频矩阵,将文本数据转化为结构化、易于计算的数据。
1.6 层次聚类
聚类分析指将物理或抽象对象的集合分组成为由类似的对象组成的多个类别的分析过程。层次聚类是聚类分析算法之一,其基本思想是通过某种相似性度量计算节点间的相似性,并按相似度由高到低排序,逐步重新连接各节点。为更好地挖掘六十四卦间的联系,本研究采用层次聚类方法基于TF-IDF 文档-词频矩阵对六十四卦进行聚类。
2 结果
2.1 词频统计
为探索《易经》中出现频次较多的词语,去停用词后进行词频统计,并通过python 的wordcloud 模块制作词云图进行可视化,见图1。在词云图中,词频越高的词对应的字体越大,越突出显示。由词云图可以看出,“无咎”是《易经》文本中出现频率最高的词,其次为“有孚”“贞吉”“君子”“有攸往”“不利”“悔亡”“元吉”“利贞”等。

图1 《易经》卦爻辞词云图(100词)
2.2 共现词挖掘
为进一步探索图1 中得到的关键词间出现频率的相关性,选择词频较高的5个重要词语,利用Word2Vec模型计算得到其最相似的6个词,见表1。Word2Vec模型构建参数如下:上下文窗口设置为5,词向量维度设置为500维,使用夹角余弦计算词语相似度,设置迭代次数为10。结果显示,《易经》中常见的词语无咎、吉、凶、君子、有孚等有着很强的相关性。
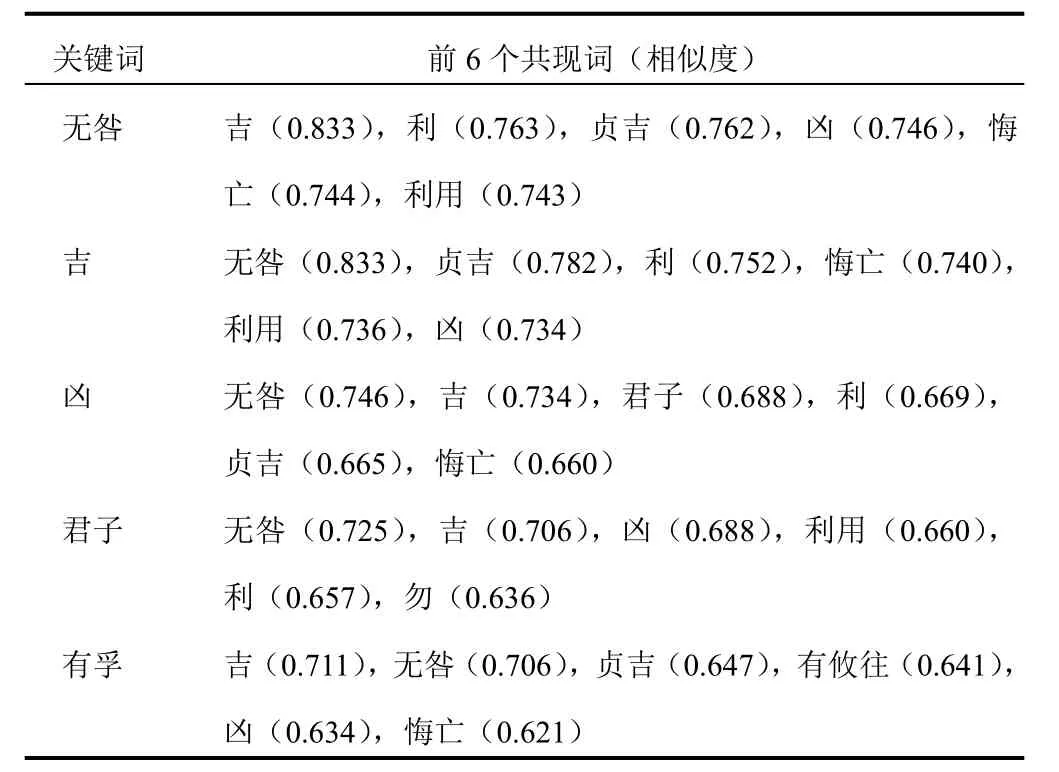
表1 5个重要关键词的主要共现词及其相似度
2.3 六十四卦联系探索
《易经》六十四卦相互联系而各有特点。通过对各卦进行词频统计发现,《易经》全文中出现较多的词语如“无咎”“贞吉”“凶”等也在各?卦的卦爻辞中频繁出现,词频统计难以显示各卦特点。因此,本研究采用TF-IDF词频计算方法将六十四卦分别映射为向量,进而通过聚类分析、相似性网络分析探索六十四卦的联系。
2.3.1 层次聚类
将每支卦对应的所有卦爻辞分别作为一个文档,通过TF-IDF计算映射为向量,基于参数设置降低矩阵稀疏度,得到64*122维的文档-词频矩阵。对所得文档-词频矩阵进行层次聚类,详见图2、表2,其中六十四卦编号为0~63。六十四卦首先被聚成2个大类,一类包含2个模块,另一类包含3个模块。其中能够反映出《易经》各卦的一些性质与联系,如既济和未济卦爻排列颠倒,字面含义相反,且互为综卦,被聚到不同模块(2、4),且分属于2个不同大类。大过和小过字面含义相近,仅表意程度不同,被聚到相同大类的2个不同模块(3、5)。但也出现了一些特殊情况,如大有和大过、损和益虽然字面含义相反,却被聚在同一个模块(3、5),且属于同一最小簇,具有很强联系。否和泰互为综卦,被聚到2个模块(1、2),但无法被明显区分为2个大类。
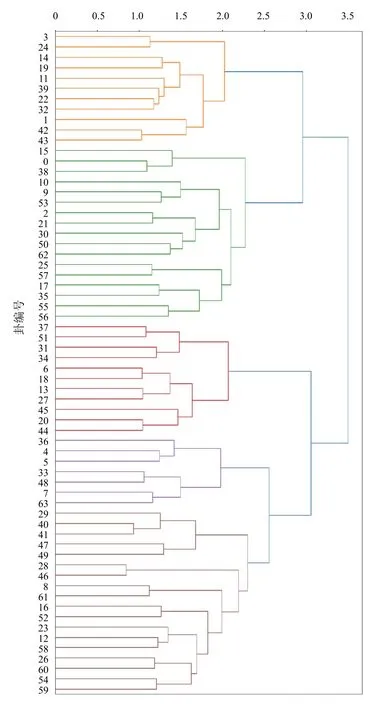
图2 《易经》六十四卦层次聚类树状图

表2 六十四卦聚为5类对应卦名
2.3.2 相似性网络图
为深入探索六十四卦的联系,计算各卦爻辞向量间余弦相似度,可视化成为网络图(见图3)。图中显示六十四卦相似网络图较复杂,每一卦都有与其相似的卦。为深入探索相似度较高的卦爻对,选择0.45作为相似度阈值,筛选出大于阈值的卦爻对,见表3。
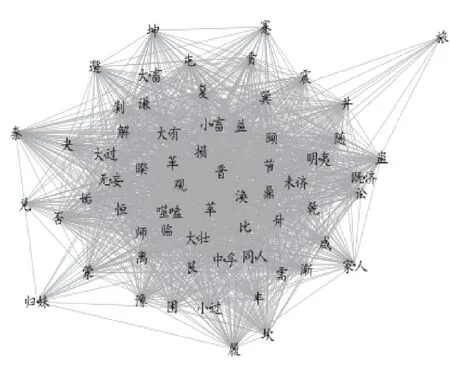
图3 六十四卦相似网络图
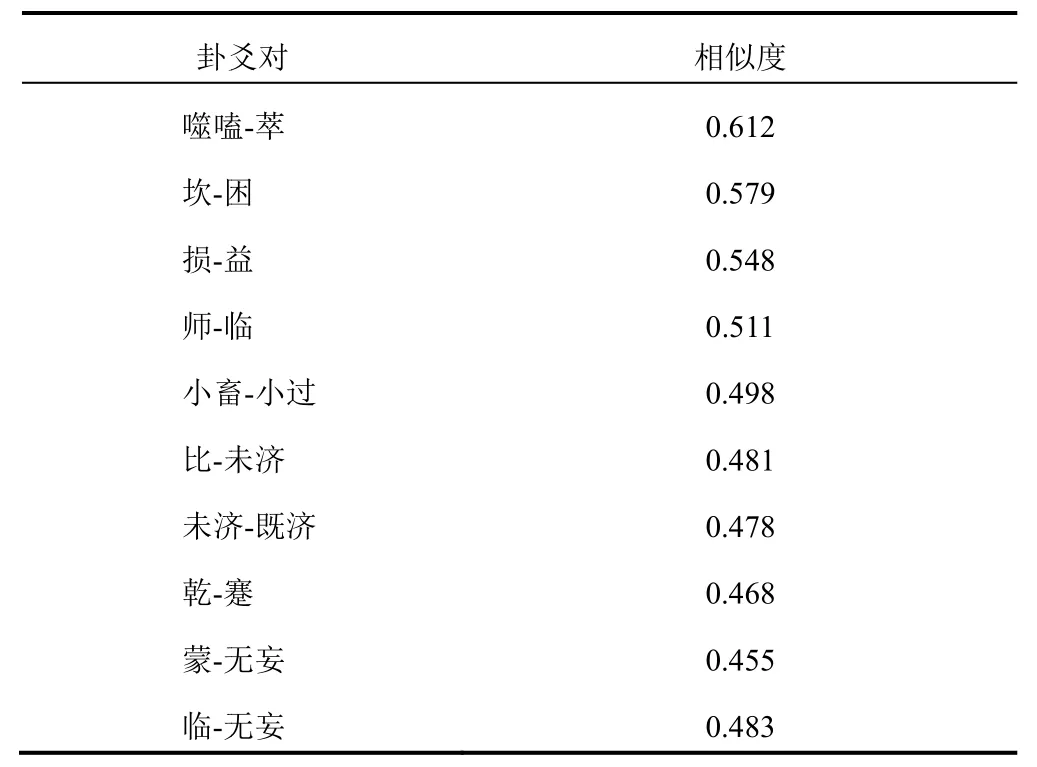
表3 六十四卦高相似度卦爻对(>0.45)
小畜和小过、师和临、损和益、坎和困、噬嗑和萃、比和未济、未济和既济、乾和蹇、蒙和无妄、临和无妄等有较强文本相似性。为探索其文本相似性,依据TF-IDF文档-词频矩阵提取上述10对相似卦的关键词,其中强相似的4对卦的TF-IDF词频最高的前4个关键词(坎卦仅有3个关键词),4对相似卦的关键词均有重复,详见表4。这些关键词来源于某一句或多句卦爻辞。其中2对卦包含相同的单卦,如坎(下坎上坎)和困(下坎上兑)均包含坎卦单卦,师卦(下坎上坤)和临卦(下兑上坤)均包含坤卦单卦。
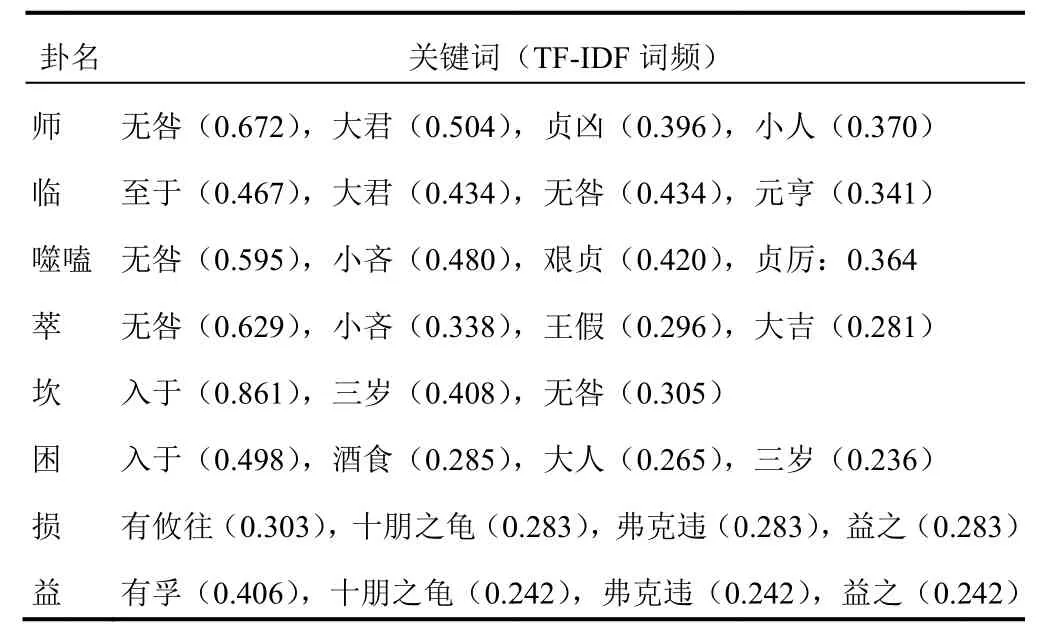
表4 强相似卦爻对的重要关键词
3 讨论
3.1 《易经》的无咎思想与中医的中庸之道
《易经》被普遍认为用于预测吉凶,由图1可见,与吉凶相关的词语出现频次较多,而《易经》中出现频次最高的词语不是吉凶,而是“无咎”。由表1中Word2Vec词语相似性度量结果可知,“无咎”与“吉”有0.833的相似度,高于其与“凶”的相似度(0.746)。由于Word2Vec词语相似度主要与文档中词语间以一定距离内间隔的频率相关,该结果说明“无咎”和“吉”在文档中相近出现的频率高于其与“凶”同时出现的频率,反映“无咎”更趋于吉。而“吉”和“凶”有较大的相似性(0.734),如讼卦“有孚窒惕,中吉,终凶”,屯卦“屯其膏,小,贞吉;大,贞凶”,体现吉转化为凶、吉中有凶的现象,可见《易经》强调居安思危、防患于未然。“吉中有凶”在中医体现为疾病治愈后可能有未病或复发,即“瘥后防复”。因此,无吉无凶即无咎,是《易经》中所提倡的处事道理。从儒家角度,无咎可理解为中庸之道。中庸之道认为“中”即平衡是事物的最佳状态,《黄帝内经》也十分注重通过调节取得平衡,主要体现在治病行调和阴阳以取得平衡[15]。
本研究通过文本分词、词频统计与词语相似度分析得到《易经》中出现频次较多的关键词语以及词语之间的联系,从统计角度解读《易经》文本的核心,该方法可用于文本内容更丰富的其他中医古籍如《灵枢》《伤寒论》等研究中,通过抽取其关键词语,帮助人们把握中医古籍的主题。
3.2 《易经》的物极必反、损中有益与中医的阴阳制化、损益配伍
本研究通过对《易经》六十四卦的层次聚类挖掘出卦爻语义间的联系。既济和未济互为综卦,两者字面含义相反,在聚类时分属于2 个模块,但两者的相似度(0.478)却不低,观察发现两者卦爻辞内容相近,多处出现重复词语,而聚类能够区分两者,说明该聚类方法的有效性。泰和否互为综卦,且字面上含义相反,分属于2 个不同模块。本研究发现多对综卦能够聚在不同模块,意味着综卦具有互补或相反的性质。但泰和否在聚类时没有明显地区分成为两大类,两者共同关键词为“拔茅茹”,分别对应于泰卦的初九爻“拔茅茹,以其汇,征吉”与否卦的初六爻“拔茅茹,以其汇;贞吉,亨”,二者初始相同,但其后的爻辞不同,一定程度上说明泰转化为否的道理。大有和大过字面上看含义相反,却被聚在同一模块,两者共同关键词为“不利”,分别体现在大有卦的上九爻与大过卦的九二爻,反映出物极必反、大有至极为大过的道理。这种物极必反的思想在《易经》中多次体现。中医强调阴阳对立制约、相互转化,阴阳的相互转化发生在事物发展变化的“物极”阶段,即“物极必反”。《素问》“重阴必阳,重阳必阴”“寒极生热,热极生寒”体现了物极必反的道理。
由图2、表3 可见,损和益虽互为综卦,但其不仅在聚类时聚在同一模块,文本相似度也较高(0.548),说明损卦和益卦具有紧密联系。分析损卦和益卦的共同关键词,发现“十朋之龟”“弗克违”“益之”分别来自损卦的六五爻“或益之,十朋之龟。弗克违,元吉”和益卦的六二爻“或益之,十朋之龟。弗克违,永贞吉。王用享于帝,吉”,两句爻辞内容基本相似,且在损卦中2 次出现“弗损益之”的语句。可见,损中有益,损和益配合需要根据实际情况进行,符合中医“损有余而补不足”的治疗理念。中医治疗总则为以平为期,平即均也,均者,合道也。中医按损益原则组方遣药,既有大承气汤的“泻其有余”,也有四君子汤的“补其不足”,更多的是按虚实比例不同的补中有泻、泻中有补,如六味地黄汤的三补三泻、白虎加人参汤的泻中有补,都体现了以损益为立论础的配伍原则。
通过层次聚类、相关性分析可发现《易经》文本中一些隐藏规律,该方法可用于分析挖掘其他中医古籍的潜在规律,如药物之间的相关性、古籍文本之间的相关性等。
3.3 中医古籍挖掘及可视化的价值与意义
中医古籍内容丰富,蕴含大量中医理论与古代名医积累的宝贵知识经验,是学习中医和运用中医的优秀知识来源。中医古籍内容深涩难懂,对于学习、研究和应用中医造成很大阻碍。随着人工智能的发展,大数据挖掘对于中医古籍核心内容的抽取与中医古籍的潜在规律的探索具有重要意义,而可视化技术可对中医古籍中潜在规律进行直观展现,帮助人们更好地理解中医。本研究的文本挖掘流程可扩展用于中医古籍内容的初步挖掘与可视化,结合一些新兴人工智能技术将有助于深入挖掘中医古籍中的潜在规律价值,以期为中医的理论与实践提供指导。
4 结语
本研究运用文本挖掘对《易经》中六十四卦卦爻辞进行探索,基于TF-IDF 关键词抽取、聚类分析、相似性网络分析等挖掘方法,得到的结果验证了已有研究《易经》与中医在损益理论方面的联系[16]、《易经》中的“物极必反”思想[17],且通过词频统计、词语相似度计算体现了《易经》的“无咎”思想,采用了可视化技术对所挖掘结果进行展现,直观量化地反映了《易经》的核心价值。本文体现了文本挖掘技术在中医古籍研究中的潜在价值,后续将进一步结合深度学习、知识图谱、文档推理等技术扩展用于其他中医古籍的挖掘与可视化研究。
