国产化平台上应用程序进程异常退出故障分析*
2021-03-20周会娜涂贵文梁鸿斌
周会娜,何 鑫,涂贵文,罗 实,梁鸿斌
(成都三零瑞通移动通信有限公司,四川 成都 610041)
0 引言
近几年,随着国内信息安全事件频繁发生,加之相关国家对关键技术的封锁,国家倡导并推动核心技术实现自主可控。在这样的背景下,国产CPU的发展和应用得到了国家的高度重视[1-2]。目前,国产CPU 正处于快速追赶的关键阶段,初步构建起了完整的产品线和上下游全产业链生态体系。在国家大力推进国产化替代工程的环境下,诸多项目开始从非国产化平台移植到国产化平台,期间不可避免出现了一些问题。本文结合某具体项目,针对一个国产CPU 弱一致性存储模型引起的进程异常退出问题进行了深入分析,并给出了解决措施。
1 故障概述
某国产服务器设备在稳定运行1 年后出现应用软件进程异常退出的故障,导致系统功能无法正常使用。
该设备为全国产化设备,基础设施平台中CPU、操作系统以及数据库等均选取国内厂家的型号产品。自主研发的应用软件在原非国产化平台运行稳定可靠,在从非国产化平台移植到国产平台时,上述设备出现故障。该设备在使用时需要做到“多任务,高并发,高可靠”,需要同在同一时间处理多任务、并发消息,具有高吞吐量和低延时,且7×24 h 无故障运行。
2 故障分析
故障发生后,远程登录设备,查看到数据库和操作系统运行正常,且在进程退出的同时生成了系统内核文件(coredump)。通过gdb 工具将进程退出时运行状态翻译为调用栈,可以看出进程退出时处理线程使用关键字delete 来释放内存,最终调用free 时发生异常导致进程退出(abort)。
通过Linux 系统编程手册[3]中free()函数的描述可以看出,释放一块未被分配的内存会导致系统工作异常。通过上文对故障现场数据的分析可以判定,故障现场的进程退出是由于释放一块未被分配的内存造成的,即定位问题的关键是找到“释放一块未被分配内存”的原因。结合代码实现,整理故障分析树如图1 所示。
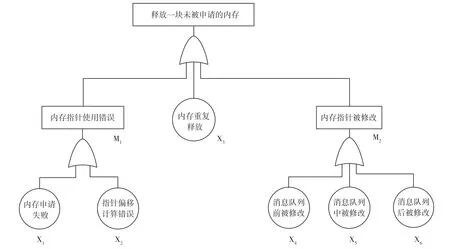
图1 故障分析树
故障出现时释放的内存是用于存放业务数据的,相关业务数据的流转轨迹如图2 所示。当发送线程接收完来源数据后,申请一块内存来构造业务数据,然后通过消息队列发送到处理线程;处理线程根据数据结构解析业务数据并进行分类处理,处理完成后释放业务数据对应的内存;当消息队列满时,发送线程需要释放业务数据的内存。
对于业务数据的流转过程和代码实现,以下几个环节构成问题分析的完整路径:业务数据对应内存的申请、释放过程;业务数据对应的内存指针的使用过程、业务数据对应的指针从内存申请成功到被释放之间是否被改动过,由此得出如图1 所示的故障分析树。针对该故障分析树具体排查如下。
2.1 内存指针使用错误(M1)
通过指针显示使用内存时,如果未能正确处理,往往会导致指针指向一块未被分配的内存,而释放这个指针会导致当前问题的出现。未能正确处理有很多表现形式,常用的且与本项目相关的几点包括内存申请失败的处理和直接使用指针时运算错误,导致使用未被分配的内存,详见X1、X2。
2.1.1 申请内存失败(X1)
从业务数据流转轨迹图(图2)可以看到,在构造业务数据前有申请内存的操作。如果申请内存失败,同时未做好失败处理,可能导致非法使用内存,从而释放未被分配的内存。此时,可以通过代码走读的方式遍历所有申请内存的位置,查看申请内存失败时是否有非法使用内存的情况。该项目未发现申请内存失败时有非法使用内存的情况。
2.1.2 指针偏移计算错误(X2)
在规划编制过程中,无论是否开展规划水资源论证,水资源都是规划无法回避的问题。为避免脱离论证对象,规划水资源论证的介入至少要在规划方案 (包括推荐方案和替代方案)形成之后才能进行。在规划方案形成阶段介入,由于不确定性因素较多,往往只能定性评价,很难作出定量估算。在规划方案形成和优化阶段介入,适合于综合规划和专项规划中的指导性规划;在规划编制草案形成之后介入,适合于专项规划,此时水资源论证的对象已经明确,可以对水资源配置、水资源利用作出定量分析和比选,通过规划水资源论证发现规划中存在的问题,提出进一步调整和完善规划的意见和建议。
从业务数据流转轨迹图(图2)可以看出,有多个地方访问内存。如果通过指针运算来直接访问内存,在运算出错时会导致非法使用内存。此时,可以通过静态代码检查工具(如Klockwork8)对程序代码进行扫描或对代码进行人工走查,着重检查指针偏移量的情况、计算的准确性、字节对齐以及数据结构定义的一致性等,查看是否存在问题。该项目未发现上述问题。所以可以排除X2。
2.2 内存重复释放(X3)
内存申请、释放过程中出现重复释放,导致再次被释放的内存是未被分配的内存。根据业务数据流转轨迹图(图2)可见,可能重复释放内存的情况是发送线程将业务数据送入队列时消息队列已满,拒绝将业务数据存入队列,发送线程将该业务数据释放,此时消息队列仍将该业务数据复制了一份到处理线程,从而引起处理线程重复释放内存。针对上述怀疑,可以编写一组测试程序来确认消息队列满时是否将已经拒绝的业务数据复制一份到处理线程。结果显示:在消息队列满的情况下,不会有复制的数据送给处理线程,故排除处理线程重复释放业务数据内存的情况。
2.3 内存指针被修改(M2)
业务数据对应内存的指针在系统运行过程中被修改,根据业务数据流转轨迹图(图2)需要分3个阶段排查,分别为进入消息队列前(X4)、在消息队列中(X5)和出消息队列后(X6)。
2.3.1 消息队列前被修改(X4)
如果业务数据的内存指针在进入消息队列前被修改,那么修改后的指针很可能指向一块未被分配的内存。为了确认是否存在该问题,在原程序中添加调试代码来跟踪业务数据内存指针的变化情况。调试代码分别添加在申请内存成功处和消息对列入口处。在测试环境中进行问题复现,当问题出现时对比两处的指针。结果显示,指针未被修改,如图3 所示,排除X4。
2.3.2 消息队列中被修改(X5)
设备软件采用自己构建的消息队列模块实现线程间通信。该模块具有高吞吐量和低延时的特点,广泛应用于通信系统的信令控制、媒体转发以及业务调度等软件中。图4 描述了该消息队列中关于内存及指针的处理过程,即业务数据的指针被发送线程传入消息队列,消息队列会把这个指针存储到指针数组。当处理线程需要获取业务数据时,消息队列会把该业务数据指针返回给处理线程。
在消息队列入口、写指针数组以及消息队列出口3 处增加调试代码,记录业务数据指针.问题出现时对比3 处记录,以判断指针是否被修改。
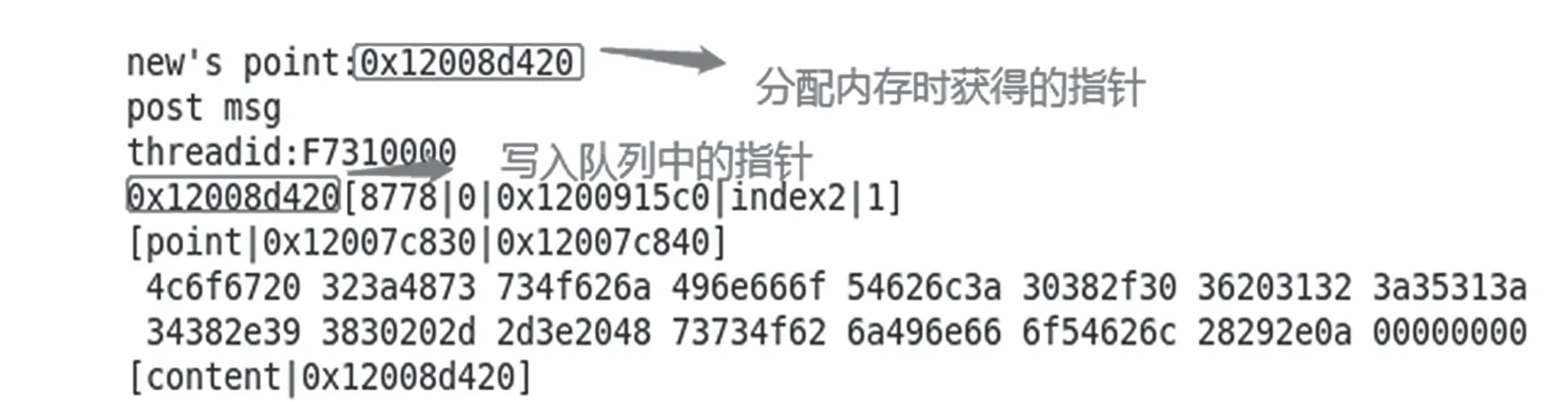
图3 申请内存与放入队列前对比
实验发现:消息队列入口处与写指针数组处的指针相同;消息队列出口处的指针与消息队列入口处不同。根据实验结果,问题定位需要聚焦在消息队列出口处读到的业务数据指针与写指针数组时不同的原因。为了分析指针在队列的传输中被改变的原因,在原代码中增加调试代码,当问题出现时观测到的情况如图5 所示。

图4 消息队列内存及指针处理过程

图5 消息队列调试处理过程
②为了确认Data1 数据是否写入指针Index62处,写线程在数据写入完成后,读取指针Index62处的数据(标记为Data2),发现Data2=Data1,确认Data1 数据已经写入指针Index62 处。此时的时间点标记为T2。
③读线程再次从消息队列中读取指针Index62处数据(标记为Data4),发现Data4=Data1。此时的时间点标记为T3。
综上所述,读到的错误指针是队列中的“旧”值。再次读取该地址可以读到正确指针,证明指针读取错误是由内存刷新延迟造成的。
经过与CPU 厂家技术人员共同分析,本项目中的内存刷新延迟可能与国产CPU 架构弱一致性存储模型[4]有关,同时给出了验证方案,即增加内存屏障[5],对比使用前后内存刷新延迟的情况。内存屏障用于保证操作有序,屏障之前的操作一定会先于内存屏障之后的操作。
根据原程序的架构拟制了验证程序,功能包括:3 个写线程向队列中写入指针,写入时打印指针地址;1 个线程从队列中读取指针,读取到指针后打印指针地址。在该程序代码中加入了内存屏障,通过对比打开和关闭内存屏障的结果,进行问题原因验证。
①开启内存屏障,未出现内存刷新延迟,程序运行正常;
②关闭内存屏障,出现内存刷新延迟。
据此证明内存刷新延迟是由弱一致性存储模型造成的。
2.3.3 消息队列后被修改(X6)
如果业务数据的内存指针在出消息队列后被修改,修改后的指针很可能指向一块未被分配的内存。为了确认指针是否被修改,可以在原程序中添加调试代码来跟踪业务数据内存指针的变化情况。在消息对列出口处和释放内存前记录内存指针,对比观测结果,两处指针相同,指针在出队列后未被修改,排除X6。
2.4 故障定位结果
通过以上故障树分析和实验结果得知,故障的根本原因是该国产CPU 采用的是弱一致性存储模型,在与其适配过程中应用软件未做内存屏障,引起应用软件读到错误指针,致使一块未被分配的内存被释放而应用软件进程退出故障。
3 机理分析
消息队列模块广泛应用于通信系统的信令控制、媒体转发以及业务调度等软件中,在x86、ARM 和PowerPC 等架构处理器上稳定运行多年,最大特点是高吞吐量和低延时。为了实现上述特点,在数据结构、指针数组管理和并发处理上做了很多优化,如消息队列的读写同步通过指针数组的计数变量来实现,可以极大地减少系统开销。但是,这个优化在多核系统中对缓存的一致性有很大挑战[6]。
本项目使用的国产CPU 芯片有4 个核,每个核包含独有的指令缓存(I-Cache)、一级缓存(D-Cache)和二级缓存(V-Cache),4 个核之间通过交叉互联网络与三级缓存(S-Cache)相连,进而再通过另一个交叉互联网络与内存相连。该国产CPU 采用GS464E 处理器核,实现的是弱一致性存储模型。
该国产CPU 对弱一致性存储模型的描述为“弱一致性存储模型,即多条不相关的加载指令或存储指令的返回结果的到达的先后次序跟处理器内部数据通路的畅通性有关系,不一定按照发出的次序依次返回,这不影响访存操作的正确性。如果程序具有显式的因果关系,弱序一致性一定会尊重这种序关系,否则乱序有可能会打破原有的程序逻辑,就需要使用屏障来抑制乱序,以维持程序所期望的逻辑”。由此可知,弱一致性的影响与处理器内部数据通路的畅通性有关。在CPU 内部数据通路繁忙时,会概率性地出现无显式因果关系的代码被乱序执行。
根据业务数据流转轨迹图(图2),结合原程序中的相关代码,在故障发生时,弱一致性存储模型在多核系统中的读写行为如图6 左侧所示。
应用程序软件写线程利用Fifo[NextIn]=A 将业务数据指针(A)存入消息队列,然后利用NextIn=(NextIn+1)通知读线程取出业务数据指针。在CPU内部数据通路繁忙时,弱一致性会概率性导致如下情况:读线程先读到已经NextIn=(NextIn+1)的数据,再通过Fifo[NextOut]读取业务数据指针(A)的数据,此时数据A 还未完成存储,当前Fifo[NextOut]中的值还是上一轮存储的“旧数据”。这个旧数据指向的是一块未被分配的内存,如果被处理线程释放会引起“释放一块未被分配的内存”错误。
内存屏障用于保证操作有序,屏障之前的操作一定会先于内存屏障之后的操作。大多数现代计算机为了提高性能而采取乱序执行,使得内存屏障成为必须。工程实现上,它经常应用于对存储时序有严格要求的场景。图6 右侧结合原程序中的相关代码描述了加入内存屏障后弱一致性存储模型在多核系统中的读写行为。
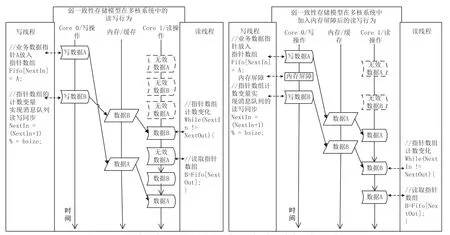
图6 弱一致性存储模型在多核系统中的读写行为和加入内存屏障后的读写行为
内存屏障会保证写线程将业务数据指针存入消息队列指令(Fifo[NextIn]=A)先于通知读线程指令(NextIn=(NextIn+1))执行,从而保证读线程能获取到正确的业务数据指针进行处理。
4 解决措施
在原应用程序中增加内存屏障,针对整改后的应用软件版本,采用故障复现时同样的测试环境、测试数据和测试方法进行验证。验证包括“验证测试”和“极限测试”两部分。其中,“验证测试”的目的是验证在设计指标下程序是否稳定运行;“极限测试”的目的是验证在超过软件处理能力的条件下程序是否稳定运行。
通过实测验证,修改措施有效,设备满足设计指标要求,在超过软件处理能力时设备可以正常运行,丢弃了处理不过来的数据。
5 结语
本文对某项目在国产化替代移植过程中遇到的典型故障“进程异常退出”,采用故障树分析法进行问题分析,最终定位故障的根本原因是国产CPU采用的是弱一致性存储模型,在与其适配过程中应用软件未做内存屏障,引起应用软件读到错误指针,致使一块未被分配的内存被释放,导致应用软件进程退出。文章给出了添加内存屏障的解决方法,经实测验证,解决措施有效,可以为解决同类问题提供参考。
