基于粗糙集理论的人力资源需求预测指标约简
2021-03-19郝营辽宁工程职业学院
郝营 辽宁工程职业学院
在进行人力资源需求预测时,由于数据获取的准确性和完整性难以满足,过多的指标也会增加需求预测的复杂程度和工作量,同时,指标设置过多,可能会产生相关指标相关性过高而影响预测的精度和效率,如何选择需求预测的核心指标以提升预测的精度和准确性是人力资源需求预测的前提。选择核心指标,进行数据降维的能够有助于减少计算用时,提高算法的可用性,删除冗余变量,解决多重共线的问题,有助于数据可视化。
一、人力资源需求预测影响因素
企业人力资源需求预测受多种因素的影响,主要与业务量密切相关[1],因此,选取能够反映企业业务量的指标作为人力资源需求预测的经济指标(EI),所选取的变量有:经济规模(GDP)、年生产量(YP)、下一年计划生产量(NYP)、年销售量(AS)、年利润(AP)、利率(IR)、税率(TR)、出口贸易额(EV)、进口贸易额(IV)。企业人力资源需求预测是一项多目标决策问题,其中人力资源成本最小化是很多研究人员考虑的一项目标[2],因此,本文把企业员工的人工成本(LC)纳入企业人员需求预测的指标当中;将企业员工的工资支出(SS)、培训支出(TS)、企业工资与地区行业工资比值(RSR)、劳动生产率(LP)等内容作为企业人力资源需求的人力指标(LI)。企业人力资源需求预测还受到现有人力资源流动的影响,本文在做企业人力资源预测时把离职率(TR)、出勤率(AR)、晋升比率(PR)、绩效评价结果(PER)、员工满意度(ES)作为内生变量指标。企业员工的结构是人力资源需求预测的核心体系之一[3]。因此,企业员工结构应是人力资源需求的指标,即包括管理人员比重(PM),科技人员比重(PT),普通人员比重(PO)。蒋蓉华等在预测企业人力资源需求时,将本科以上的员工作为高学历人员[4],随着人口素质的不断提升,在本文将研究生以上学历作为高学历人员,将高学历(研究生以上)人员比重(PAS)作为预测的人力指标(LI)之一(见表1)。
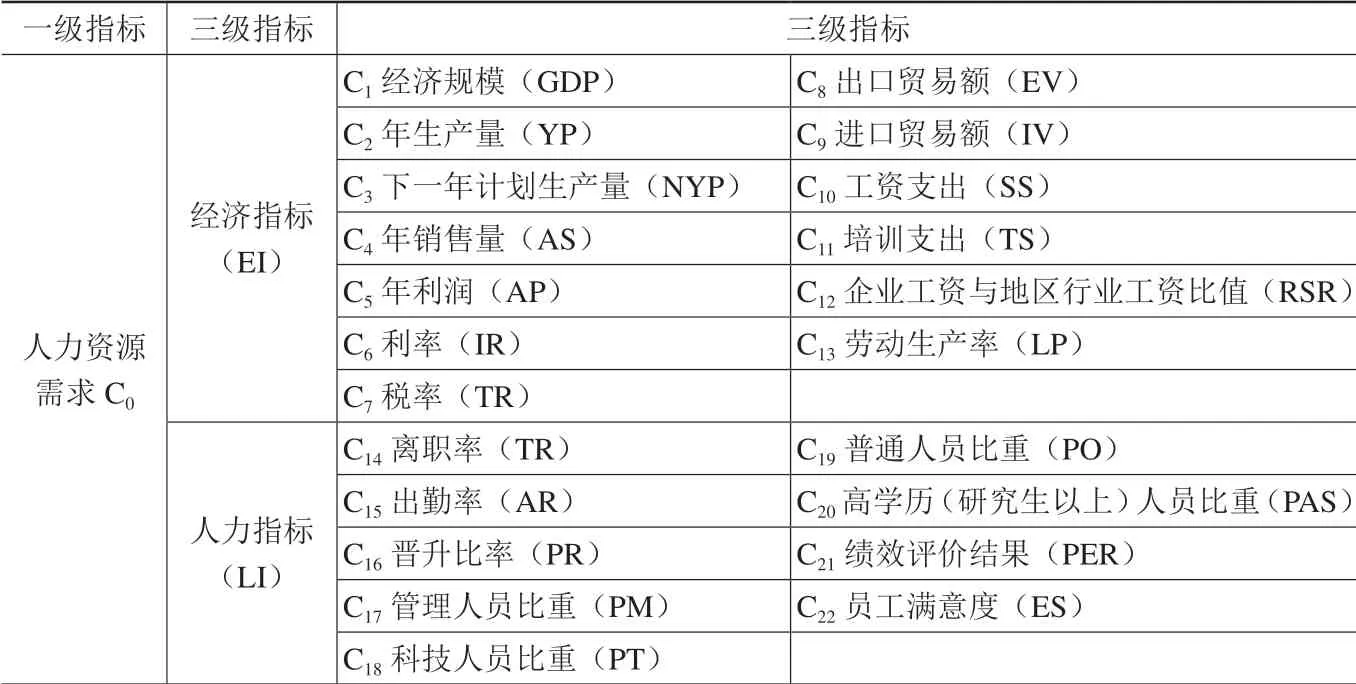
表1 企业人力资源需求预测指标
二、人力资源需求预测指标的属性约简
可将人力资源需求预测看作一个信息系统S={U,A,V,f},U为对象的有限集,A为属性的有限集;A=C∪D,C是条件属性子集,D是决策属性子集;V=∪P∈AVp,Vp是属性P的域;f:U*A→V是总函数,使得对 每个xi∈U,q∈A,有f(xi,q)∈Vq。在决策系统S=<U,C∪D,V,f>中,若POSC(D)=POSC-p(D),那么属性p是C中D可省略,否则就是不可省略的。
条件属性集C的D约简是C的一个非空子集P。若满足:∀a∈P,a都是D不可省略的,POSP(D)=POSC(D),那么P是C的一个约简。C中所有约简的集合记为REDD(C),C中所有不可省略属性的集合为C的核,记为CORED(C)。
性质1:若M⊆N⊆C则POSM(D)⊆ POSN(D)
性质2:M⊆N⊆C,X⊆U,则对任意x∈U,若x∈POSM(D),则x∈POSN(D)
论域U是每一年人力资源相关数据的非空有限集合,即U={x1,x2,…,xn};把所总结的22个人力资源需求预测的指标作为条件属性C,即C={C1,C2,…,C22},每一年的人力资源数量变动率作为结果属性D,即D={Y(t)},A=C∪D是属性的非空有限集合,从而建立一个系统决策表K=(U,C∪D)。在此基础上,对人力资源需求预测决策系统K进行条件属性约简,得到最小条件属性约简。
三、结论
决策表中的属性并不是同等重要的,有些属性甚至是冗余的,这就增加了计算的复杂性、降低信息处理的效率。因此要在条件属性和决策属性之间的依赖关系不发生变化的前提下,删除其中不重要的属性。企业在进行未来一段时期的人员规划时,有必要对企业人力资源的需求量进行精确预测,避免人力资源不足或过多而造成的资源浪费。
