基于多源知识图谱融合的智能导诊算法
2021-03-18刘道文张晨童邱家辉葛小玲
刘道文,阮 彤,张晨童,邱家辉,翟 洁,何 萍,葛小玲
(1. 华东理工大学 信息科学与工程学院,上海 200237;2. 上海申康医院发展中心 医联中心,上海 200120;3. 复旦大学附属儿科医院 信息中心,上海 201102)
0 引言
网上预约挂号系统由于省去了患者在医院排队挂号的时间,受到了患者的欢迎。然而,大型三甲医院通常有几十个科室,大多数患者并不了解临床科室的分工,而只能简单描述自己的症状。线下挂号时,患者通常通过医院导医台向护士叙述症状,护士推荐合适的科室。但是,目前线上缺乏这样的服务,患者只能通过网络搜索获得相关信息。但是由于症状和科室缺乏明确的对应关系,同时各医院科室设置不同,再加上医院提供信息不完整,医疗广告又充斥互联网,使得使用搜索的患者最终无所适从。因此,构建一个智能科室推荐系统,将合适的科室推荐给需要的患者,可以解决患者网上挂号遇到的实际问题,减少患者挂错号的情况。其中智能导诊服务还存在以下问题:
(1) 患者主诉中症状描述的多样性问题。需要从患者对病情的不规范文本描述中,有效识别症状信息或患者预判的疾病信息,并归一化到知识图谱的标准实体上。
(2) 病人各类特征与就诊科室之间的关系缺乏良好和可扩充的知识表示方式。首先,症状和疾病、疾病和科室是多对多的关系,部分科室不一定和症状相关,而是和部位、年龄与性别等紧密关联。再者,精准的导诊算法依赖于这些类之间的量化关系。其次,各家医院的科室设置不尽相同,意味着相同的疾病可能会到不同医院的不同科室。分析上海区域平台数据发现,“甲状腺结节”在瑞金医院的“普通外科”挂号最多,但在岳阳医院的挂号却是“内分泌科”最多。用何种知识表示模型描述上述知识,是一个难点问题。目前的导诊推荐系统大多采用向量空间计算疾病相似度的方法[1-5]。然而,这些方法没有体现医学的强知识型和可解释性。因此,采用其他方式,如知识图谱是一个可选方案。虽然目前有诸多发布的医疗知识图谱[6-7],但从本文应用角度,缺乏病人特征和科室之间关系的模式描述;从知识表示角度,未见量化关系的描述;从图谱数据角度,缺乏知识数据与真实医疗数据的融合。
(3) 图谱数据来源的选择与图谱融合方法问题。知识图谱可以通过几种方式构建,一是人工构建,二是通过医书或是来源于医书的互联网网站,三是通过区域平台电子健康档案(electronic health records,EHR)自动获取,四是结合第二种和第三种方案,对两种数据来源进行融合。第一种方案工作量太大;第二种方案在书中不存在真实科室数据;第三种方案需要多家医院电子病历数据或是区域卫生平台数据,症状数据通常又在文本中,不但采集工作量大,而且数据清洗和处理复杂度更高。为此,本文选择第四种方案,该方案的复杂度在于需要进行多源数据融合,包括不同来源实体的对齐与上下位关系的识别等。由于来自网络的症状-疾病图谱的疾病术语数据较少,而来自真实数据的疾病-科室图谱存在疾病术语描述不规范问题,因此,知识数据和真实数据的直接融合匹配率并不高,为此,本文使用基于国际疾病分类(international classification of diseases,ICD)的术语体系作为桥梁融合两个图谱。
针对智能导诊服务中的问题,本文提出了一种基于知识图谱的智能导诊方法。本方法的贡献点如下:
(1) 设计了面向导诊的带权重的医疗图谱模式,可以量化地定义科室与症状、疾病、性别和部位之间的关联关系与概率关系。
(2) 以国际疾病分类ICD为基础,通过融合互联网知识数据与区域大规模EHR真实数据,构建了量化的症状—疾病—科室—医院图谱。实验证明,通过ICD进行融合,比直接将互联网知识数据与区域大规模EHR真实数据进行融合,最终的科室推荐准确率提升了10%左右。
(3) 针对网络问诊文本不规范情况,提出了预滤噪的BERT实体识别模型,比经典的BERT+CRF模型提高了5%的召回率,3%的F1值。针对医学实体归一化问题,提出了部位制导的医疗实体归一化算法,对比经典的BERT+CRF模型,提升了3%的准确率,30%的召回率,17%的F1值。
(4) 提出了基于权重的联合症状预测疾病概率(weight-based disease prediction algorithm based on multiple symptoms,WBDPMS)算法,实现了多症状的疾病预测与基于患者信息的精准的科室推荐。实验证明,该算法比一般的加权求和算法的科室预测准确率提升了10%以上。
上海申康医联平台使上海市三甲医院的数据信息得以互联互通,实现了网上预约挂号服务,本文的方法在上海申康医联平台2018年1月上线以来,截止到2019年1月,一年时间共计63 795次访问,取得了良好的反馈。
1 相关工作
智能导诊的研究目前大多采用的方法是将传统数据驱动的推荐算法适配于医疗领域。马钰等[1]提出了一种面向智能导诊的个性化推荐算法,以辅助诊疗的结果为基础,和基于协同过滤的评分方式有机结合,其算法能根据患者的症状表现与地理位置等个人信息,为用户提供个性化的推荐结果。梁璐[2]基于向量空间模型对权重计算进行了改进,其核心思想在于将患者输入的症状向量化,与疾病症状集中的疾病向量进行相似度计算,进而预测患者疾病。徐奕枫等[3]在梁璐的基础上,提出了重心后移的概念,他将症状中的每个字赋予权重,后面字权重大于前面字。医学领域的特点是强知识性与解释性,病人特征和推荐的科室之间有着直接的因果关联,与传统的基于机器学习的电影推荐和书本推荐完全不同。为此,本文提出了基于知识图谱的智能导诊算法,以适应医学领域的特点与要求。
准确且完善的面向智能导诊的知识图谱是本文研究的数据基础。在国内,清华大学和上海交通大学利用网络百科知识,构建大规模的通用知识图谱,如Zhishi.me[4]和XLORE[5]。在医疗领域,国外构建了临床医疗术语集SNOMED-CT这样的通用的术语分类系统,面向药物的命名系统RxNorm,针对观测指标的编码系统LOINC,以及被广泛应用的疾病分类系统ICD等医疗术语体系。在国内,于彤等[6-7]构建了TCMKS中医药知识图谱及其服务平台。本文采用自顶向下的图谱构建方式,并在图谱模式层扩充了权重,图谱数据层采用了知识数据与业务数据相融合的方式。
智能导诊前置工作为患者主诉处理,首先要从患者主诉中识别症状词等实体信息。Qiu等[8]利用残差神经网络获取上下文信息,然后通过条件随机场捕获相邻标签之间的依赖关系,该方法在疾病、症状等医疗实体的识别任务上取得了比RNN算法更好的结果。Wang等[9]将医学字典信息输入到Bi-LSTM+CRF模型中,能更好地处理字典中存在但数据中很少出现的实体。Gong等[10]使用谷歌提出的BERT模型进行实体识别,并且在字符嵌入中加入了汉语词根信息,可以更好地利用语义进行实体识别。然而,上述模型不能很好地处理主诉噪声多、描述不规范的问题,因此本文提出了预滤噪的BERT实体识别方法,该方法通过对主诉文本进行预处理和后处理去除部分噪声,提升医学实体输出的规范性。
为了将实体归一化到知识图谱的节点上,Wang等[11]提出的Bi-GRU-CapsNet模型,更好地解决了词汇量不足(out of vocabulary, OOV)的问题。Zhang等[12]的方法使用多种字符串相似性的结果作为输入,对比了朴素贝叶斯、随机森林、逻辑回归和Stacking等模型,对实体和节点进行归一化。谷歌提出的BERT模型[13-14]也可用在该实体归一化任务上。输入为待实体归一化的实体和知识图谱中的实体,输出为知识图谱实体中的匹配分数。然而,部位对医疗实体的归一化有着重要的影响,本文提出的部位制导的医疗实体归一化算法,提高了实体归一化的准确性。
2 整体框架
本文的整体框架如图1所示。分为两部分,左半部分是知识图谱构建过程,右半部分是基于知识图谱的智能导诊算法。
知识图谱构建中,融合了医疗百科网站、区域卫生平台EHR数据、ICD-10和ICD-11,以及搜索引擎的联合搜索概率等多源数据,具体过程如下: ①基于医疗百科网站信息,构建症状—疾病知识图谱。对于任意两个症状和疾病,利用搜索引擎中联合搜索的条目数计算症状和疾病之间的权重;②基于上海区域卫生平台提供的38家三甲医院半年来科室治疗疾病的统计数据,构建疾病—科室—医院图谱,利用就诊次数计算疾病和科室之间的权重;③利用ICD的疾病层次关系融合上述两个图谱,以补全疾病—科室对应关系。真实数据中并非所有疾病名词都存在对应的科室,但通过同义词或上下位关系可以找到含有对应科室的疾病节点。因此,带有同义词与上下位关系的疾病图谱可以弥补真实数据中疾病—科室关系的不足。由于医疗百科网站和区域卫生平台EHR数据中并没有疾病同义词及上下位关系,因此本文利用国际疾病分类ICD的11版本和10版本,形成带层次的疾病图谱,进而融合症状—疾病、疾病—科室—医院两个知识图谱。
在智能导诊过程中,患者输入中文主诉文本、性别和年龄段,首先利用本文提出的预滤噪的BERT实体识别模型对主诉文本进行实体识别,获得患者主诉中的症状实体和疾病实体。其次,再利用部位制导的医疗实体归一化算法将这些实体归一化到图谱中的相应节点。最后,通过本文提出的基于权重的联合症状预测疾病概率算法(WBDPMS)在图谱上计算患者可能患有的疾病及其权重, 进而通过权重融合算法推荐最合适的科室及医院。

图1 基于多源知识图谱融合的智能导诊方法整体框架
3 知识图谱构建
3.1 面向导诊的知识图谱模式图定义
图2展示了面向导诊的知识图谱,上半部分是模式图,下半部分是数据图。
模式图由三元组G=〈Ns,Es,Ws〉组成,Ns是知识图谱类别节点,包含了4个类节点,分别是症状、 疾病、 科室和医院,Es是节点Ns之间的关系,Ws是关系Es上的权重。
Es分为两种,一种是类节点之间的关系,另一种是属性关系。前者称为对象属性,后者称为数据属性。对象属性有五个,分别存在于疾病和疾病、症状和疾病、疾病和科室、科室和医院之间。疾病和疾病节点之间存在上下位和同义词关系。数据属性有两个,存在于疾病节点和科室节点上,分别为性别和年龄。由于部分疾病和科室与性别和年龄有关,比如“月经不调”是女性疾病,而“老年高血压”是老人特有的疾病,而“妇科”和“儿科”分别面向女性和儿童两个群体。因此,图谱在疾病和科室上增加了“性别”和“年龄”两个属性,用于进一度提升导诊算法的精度。
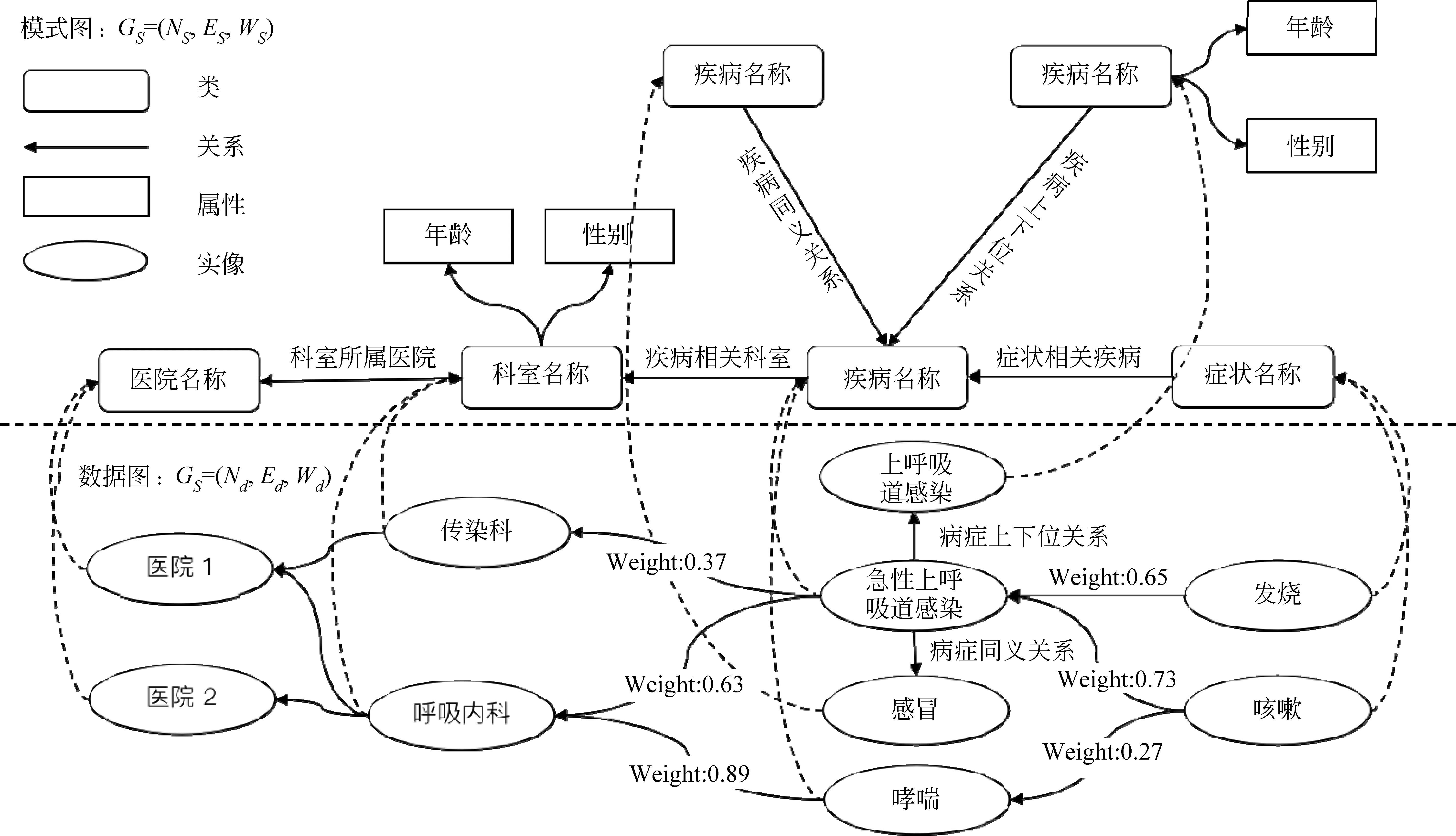
图2 面向导诊的知识图谱模式图及数据图
Ws是附属在Es上的属性,Ws存在于症状和疾病、疾病和科室上,前者代表症状和疾病关联的概率,后者代表疾病和挂号科室关联的概率。由于不同症状在不同疾病上的贡献度不同,可能引起的疾病也不同,如果症状和疾病之间没有权重关系的话,会导致如“发烧”这个症状预测出来的“感冒”和“小儿腹泻”的权重相同。此外,由于区域卫生平台EHR数据的真实性,疾病在不同医院的不同科室之间的权威性都不同,通过“疾病—科室”关系之间的权重能让患者更好地选择有权威性的科室及医院。本文在实验过程中,针对权重设置对推荐结果的准确性进行了对比。
数据图是模式图的实例,以图2面向导诊的知识图谱模式图及数据图的数据为例,描述的是症状“发烧”,链接的疾病为“急性上呼吸道感染”,其概率为0.65。症状“咳嗽”链接的疾病为“急性上呼吸道感染”和“哮喘”,概率分别为0.73和0.27,说明“咳嗽”更有可能是由“急性上呼吸道感染”导致的。同时,“急性上呼吸道感染”存在上位词“上呼吸道感染”和同义词“感冒”。“急性上呼吸道感染”有0.37的概率会去传染科治疗,0.63的概率去呼吸内科治疗,“哮喘”有0.89的概率去呼吸内科治疗。医院1有传染科和呼吸内科,医院2有呼吸内科。
3.2 面向导诊的知识图谱构建过程
首先,选取39健康网为知识抽取源站,从疾病列表页获取所有疾病列表,通过疾病名称进入详情页,抽取疾病别名、发病部位和典型症状信息,构建“疾病—症状”信息。由此得到的症状以及症状-疾病关系可能不全,进一步根据症状列表补全症状,并由症状页链向疾病的关系,对“疾病—症状”信息进行补充。
其次,补充单个症状与疾病之间的概率关系。本文以搜索引擎中症状—疾病对出现的频次计算相关程度。在搜索引擎上对〈症状—疾病〉对pair〈s-d〉进行联合搜索,获取pair〈s-d〉在互联网上的出现次数作为分子,记为count(pair〈s-d〉),Sd={s1,s2,…,si}为疾病d所链接的所有症状,因此症状和疾病的权重计算如式(1)所示。
(1)
再者,构造疾病—科室—医院图谱。基于区域卫生平台EHR数据,抽取其中的疾病及其挂号的科室信息,包括在该科室挂号的次数和科室所在的医院,用以构建疾病—科室—医院图谱。较百科知识型数据而言,使用区域卫生平台数据真实数据构建疾病—科室—医院关系的优点如下:
(1) 体现医院的科室设置不同,例如,“呼吸内科”在不同医院的名称不同,有“呼吸科门诊”“呼吸科”“门诊呼吸科”等,而看起来相似的科室,具体面向的疾病也有不同。因此,本文的知识图谱是从疾病链接到不同医院的不同科室,并没有对科室做归一化处理。
(2) 疾病挂号次数体现了某疾病在该科室下的治疗经验,可以作为“疾病—科室”关系的权重,能为推荐带来更高的精准度。
(3) 医院特定疾病的挂号次数体现了医院治疗该疾病的经验。
本文获取的区域卫生平台EHR数据共计1 780 449条,通过对数据中的异常值记录进行清洗后,得到有效数据281 488条。形成了“疾病—科室”关系281 488条、“科室—医院”关系6 110条。
最后,将两个图谱进行融合。EHR数据中虽然疾病名称众多,但是疾病名称并不规范和全面,因此疾病—科室关系不完整,会导致有些疾病没有科室可挂的情况。此时可以通过疾病的同义关系或上下位关系找到挂号科室。因此,需要具有同义词与上下位关系的疾病图谱,弥补真实数据中疾病—科室关系的不足。
为此,本文利用ICD国际疾病分类,将ICD分别和症状—疾病图谱以及疾病—科室—医院图谱融合,构建完整的症状—疾病—科室—医院图谱。本文采用Wang等[11]的方法进行上下位及同义词识别,进行图谱的融合。ICD-10中共有18 050个疾病节点,ICD—11中共有3 542个疾病节点。通过EHR构建的图谱共有20 756个疾病节点,通过同义词和上下位识别,与ICD树关联上9 408个疾病节点。其中上下位关系57 423条、同义词关系2 927条。
最终生成的知识图谱包含症状节点6 220个,疾病节点30 164个,科室节点6 110个,医院节点38个,症状—疾病关系60 736条,疾病上下位关系57 423条,疾病同义词关系2 927条,疾病—科室关系281 488条,科室—医院关系6 110条。
4 智能导诊算法
4.1 算法流程与实现
如图3所示, 智 能导诊 算法分为四部分: 首先识别患者主诉中的实体词(包括症状、疾病和部位),然后对实体词向知识图谱进行归一化。接着通过WBDPMS算法,基于图谱中的关系和权重,计算患者可能患有的疾病和概率。最后通过融合权重算法,结合“疾病—科室”关系上的权重,给出最合适的医院和科室。
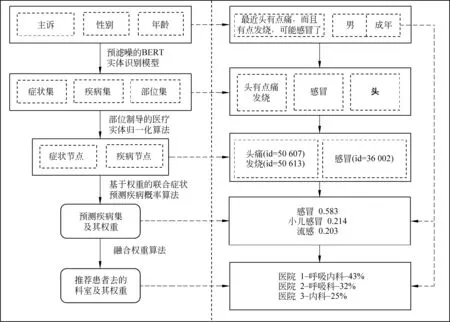
图3 智能导诊算法流程
4.2 患者主诉实体识别与实体归一化
由于患者主诉不规范,存在大量的与诊疗无关的语句和字词。无关语句主要表现在存在很多与病情描述无关的语句上,例如,“医生您好”“请问是什么原因”等。同时,由于本文对症状时间不做处理,因此,病人描述的时间语句在该系统中视为无关语句,例如,“怀孕已经28周了”“每次一到冬天的时候”“反反复复发作”等。此外,由于患者对症状描述存在形容词或副词,例如,“头有点痛”“膝盖下面隐隐作痛”等。在对1 640条训练数据进行子句分割,一共得到10 517条子句,平均每个患者主诉包含6个子句,但是其中只有3 099个子句包含本文需要的症状信息,占比为29.5%。因此,通过对主诉的后处理,精炼出更加有效的主诉,能有效提高准确率。
本文提出了预滤噪的BERT实体识别模型(A bert entity recognition model for pre-filtered noise)。算法结构如图4所示,首先将主诉输入基于词典特征的Bi-LSTM+CRF模型[2],其中部位词典采用《人体解剖学名词(第二版)》中的部位词(共3 063);症状词典采用文献[2]的症状词典(共762)和本文知识图谱症状节点名称(共6 220)进行融合,得到最终的症状词典(共6 829个)。我们将患者主诉的每个字进行向量化,组成模型的输入ei,并且采用位置相关实体特征(position-dependent entity type feature, PDET type)构建输入di。ei和di分别经过Bi-LSTM+CRF层,将输出进行合并,再通过CRF层输出主诉中的症状词和部位词。将CRF层输出的结果里同一子句中的部位词和症状词中间的无关词语删除,并且将没有出现过任何实体的子句作为无关语句删除, 获得滤噪后的主诉。以{[CLS]滤噪后的主诉[SEP]}作为BERT的输入,模型输出主诉中的症状实体。
本文将实体识别出来的症状实体集Scomplain={s1,s2,…,si,…}归一化到知识图谱的症状节点集Ns={n1,n2,…,nj,…},其中Ns∈Nd。利用部位词典对Scomplain中的部位进行抽取,得到部位词B。当si和nj部位词不一致时,则判断si不能归一化到nj上。若si没有包含部位词,而nj包含部位词, 例如,“胀痛”和“肌肉胀痛”, 则将部位词B和si进行拼接,进而判断是否能归一化到nj上。同理,用相同的方法从患者主诉中获取疾病实体集Dcomplain={d1,d2,…,di,…},称之为患者主诉中预判疾病集。

图4 预滤噪的BERT实体识别模型
为了判断si是否能归一化到nj上,本文采用了多个维度的字符串相似性算法,包括最长公共子串的长度占比、编辑距离、Jaccard距离、余弦相似度、Hamming距离和Levenshtein距离,以此作为模型输入。通过对比朴素贝叶斯(Naive Bayes)、最近邻(KNN)、AdaBoost(弱分类器为CART决策树)、bagging(分类器为决策树)、梯度下降树(GBDT)、随机森林(random forest)、支持向量机(support vector machine)、逻辑回归(logistics regression)、多层感知器(multilayer perceptron)的方法,并且将这些算法通过排列组合进行融合,选择其中的一组算法组合以达到最好的效果。
4.3 智能导诊算法的实现
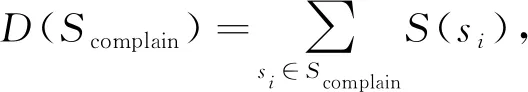
(2)
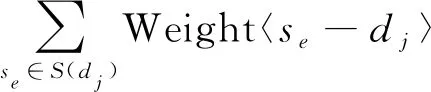
通过式(2)得出了基于患者主诉中的症状预测的疾病集以及其对应的概率W(dj),W(dj)的值越大,表示症状集Scomplain与疾病dj的关联度越大。
其次,我们通过Dcomplain对D(si)中的疾病权重进行更新,将疾病集和患者预判的疾病进行疾病权重融合,方法如下:
(1) 若Dcomplain中疾病的di在D(si)中,则增加查询项中该疾病的权重。计算方法如下:
设W(di)为患者预判疾病在疾病集中对应的权重值,ni为患者预判疾病在疾病集中按权重排序得到的名次。患者预判的疾病权重如式(3)所示。
W′(di)=W(di)×log2(ni+1)
(3)
(2) 若Dcomplain中疾病的di不在D(si)中,本文考虑了该疾病对导诊结果的影响,将患者预判疾病加入疾病集,并取所有疾病权重的平均值作为该预判疾病的权重,如式(4)所示。
(4)
最后,我们通过D(si)={d1,d2,…,dj,…}和其权重W(dj)计算患者应该去的科室及其权重。由于ICD疾病丰富,区域卫生平台数据中的疾病不能完全覆盖所有ICD疾病,因此会导致预测出的疾病不能够直接连接到科室。本文通过以下规则获取疾病dj所连接的科室节点: ①若dj可以直接通过“疾病-科室”获取科室及其权重,则直接返回该疾病的科室节点nj∈Nd及其权重Weightj∈Wd;②若dj找不到连接的科室,则先寻找其子孙节点,获取所有子孙节点的科室关系,并取其平均值作为权重Weightj进行返回;③若dj所有子孙节点均没有“疾病相关科室”关系相连,则回溯其祖先节点,直到找到一个祖先节点nj∈Nd有“疾病—科室”关系进行返回,并返回其权重Weightj∈Wd。则患者应该去的科室权重计算如式(5)所示。
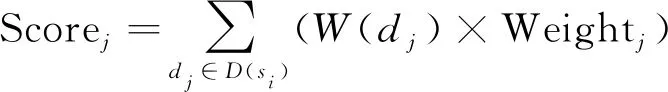
(5)
综上,本文得出了一组带有权重的科室列表Departments={Department1:Score1,…,Departmentn:Scoren}。对科室列表中与患者性别、年龄段无关的科室去除。最后,对Scoren进行排序,从大到小输出推荐科室结果,对概率较低的科室不予推荐。
5 实验结果与分析
5.1 实验数据
为了训练实体识别算法,本文从医疗问询网站抽取了1 640条问诊主诉数据进行训练。该数据集中,男性患者804例,女性患者836例;普通成人1 181例,儿童376例,老年83例。人工标注其中的症状和疾病实体作为实体识别算法的训练和测试,并且将标注出的实体手工归一化到知识图谱的节点上,共标注了2 435条实体归一化数据,以构建实体归一化模型的训练集和测试集。
此外,为了实现真实科室情况下的算法评估,本文随机采样了医疗网站中患者问询的200条数据作为导诊算法的测试集。其中,普通成人、儿童、老人的数据比例为171∶15∶14;通用疾病、男性疾病、女性疾病比为135∶14∶51。对于这批数据推荐科室的标注,由两位临床医生进行科室标注,每条数据标注三个以内最适合的科室。
5.2 实体识别及实体归一化联合算法结果
为了进行患者主诉的症状词和疾病词的抽取,本文基于词典特征的Bi-LSTM+CRF、残差膨胀神经网络、XLNET+CRF和BERT+CRF进行患者主诉处理,实体识别结果如表1所示。
由表1结果可得,基于词典特征的Bi-LSTM+CRF取得了0.74的F1值。BERT+CRF模型F1值取得了0.83的好成绩。本文的方法将F1值提升到了0.86,取得了最好的结果。实验表明,针对图4的例子“我今年29岁了,最近一段时间总是感觉身体有点不正常,腹部总是隐隐作痛,所以想在这咨询一下医生,小腹有些疼痛小便有尿血怎么回事?吃点什么药可以缓解疼痛?”,用后处理的主诉作为输入,BERT输出症状词为“腹部痛”“尿血”。如果直接使用BERT进行实体识别操作,该例子将会输出“不正常”“疼痛”和“尿血”。其中“不正常”“疼痛”不能体现具体的症状信息。因此将本文提出的实体识别算法作为后续实体归一化和导诊算法的前置工作。
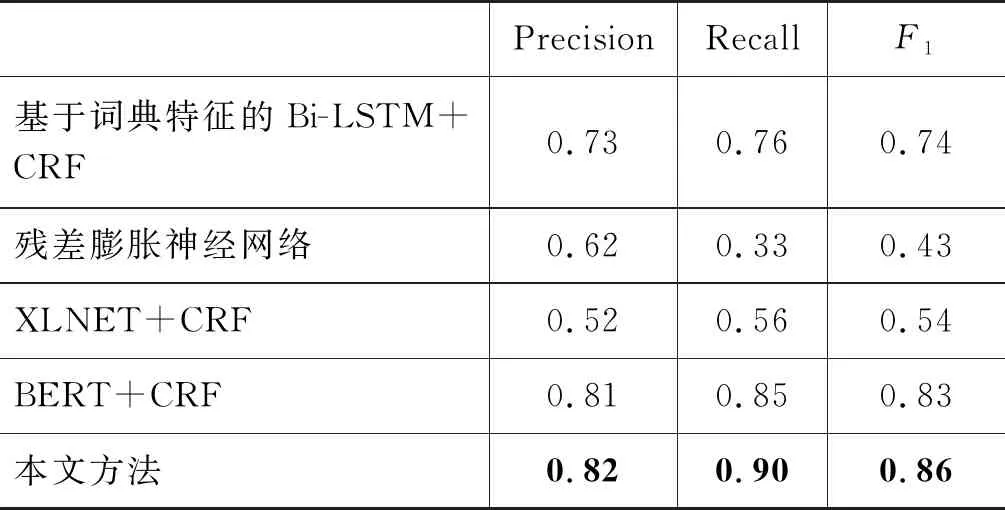
表1 实体识别结果
实体识别后需要将实体与知识图谱中的节点进行归一化,本文采用了部位制导的医疗实体归一化算法进行实体与节点的归一化,同时对比BERT、多元字符串相似度算法(Cos-similarity)和上下位及同义词识别算法进行实体归一化,实体归一化结果如表2所示。
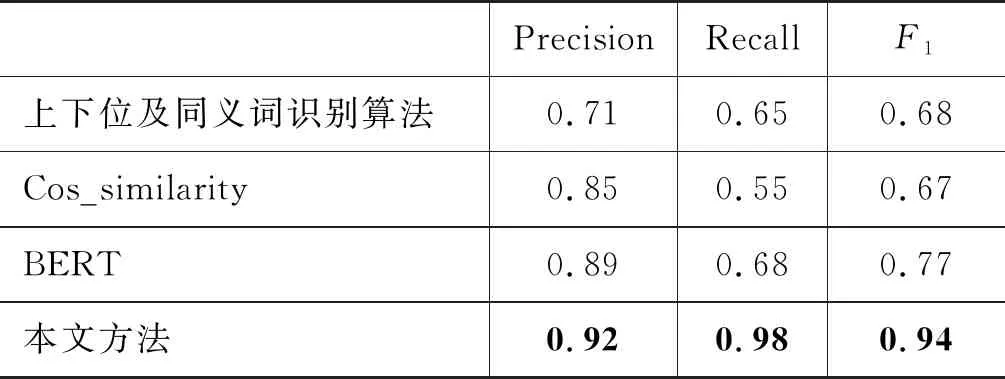
表2 实体归一化结果
由表2结果可知,本文提出的部位制导的医疗实体归一化算法取得了最优的成绩。通过对数据的分析,53.6%的数据si和nj都不包含部位词,39.6%的数据si和nj都包含部位词,其他的6.8%的数据中si包含部位词而nj不包含部位词。在53.6%的数据上,BERT算法取得了最好的效果,但本文方法在39.6%和6.8%的数据上针对本文做了处理,取得了比其他算法更好的结果。结合上述两个方面的算法,本文将实体识别最优的前三个算法和实体归一化最优的前两个算法进行排列组合,分别通过本文WBDPMS算法+ICD融合树进行最终科室结果的正确性对比,找到最适合的实体识别+实体归一化算法,以此选择最终的实体识别和实体归一化算法,结果如表3所示。
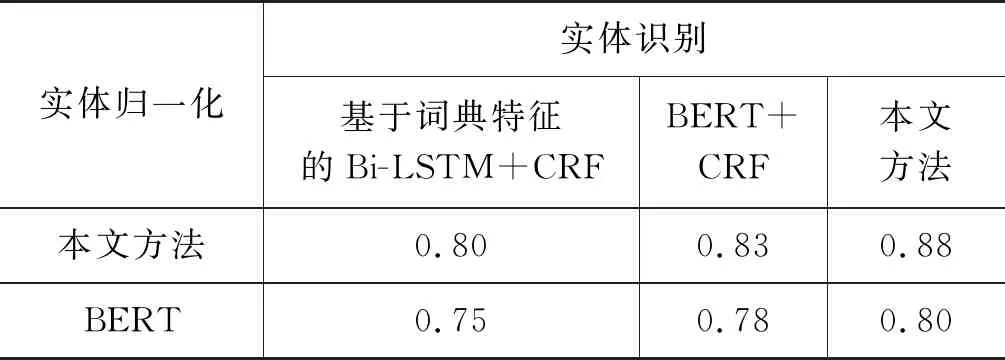
表3 实体识别+实体归一化结果
5.3 科室推荐算法对比
在上一节中,本文使用预滤噪的BERT实体识别和部位制导的医疗实体归一化算法进行最终导诊算法的前置工作。本节通过对比简单的加权求和算法和本文的WBDPMS算法,并且考虑权重对推荐结果的影响。“症状—疾病”关系和“疾病—科室”关系上不含权重表示为各条关系的权重相同。通过对比“症状—疾病”和“疾病—科室”都不含权重、分别只有一个关系上有权重和都包含权重,对算法结果进行对比。同时,为了判断ICD疾病层次对结果的影响,本文在数据中是否利用ICD层次结构进行算法优化进行对比。实验结果如表 4所示。
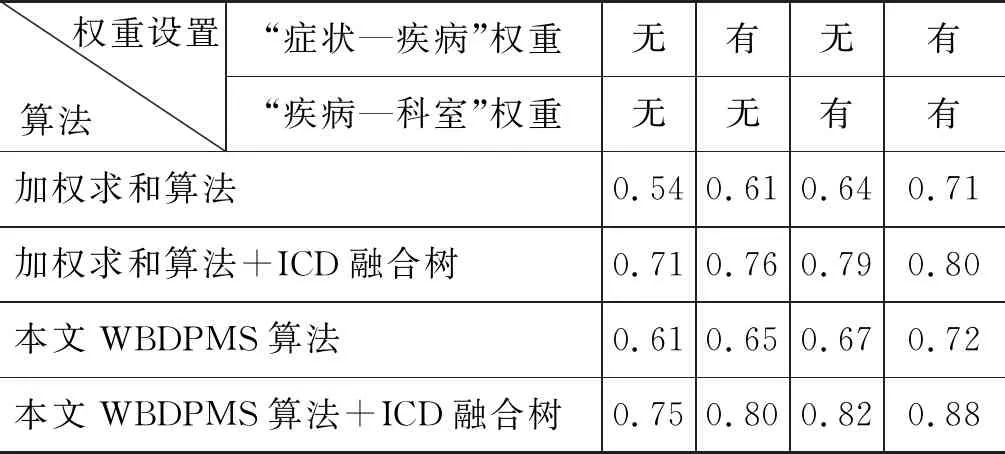
表4 导诊算法结果
结果显示,两种关系权重都能带来一定的精确率提升,“症状—疾病”权重可以通过症状在不同疾病上的特征性不同以提高预测疾病的准确性,“疾病—科室”权重通过不同科室对相同疾病治疗的权威性进行优化。WBDPMS算法在各种权重设置情况下均比加权求和算法精确率更高,且包含的权重越多提升越显著。同时,由于ICD疾病层次可以使未链接到科室的疾病节点找到适合的科室,预测效果比没用ICD疾病层次的效果更优。
6 结论与未来工作
本文实现了一个基于症状—疾病—科室—医院知识图谱的智能导诊平台,解决了主诉识别,图谱知识表示与多源图谱融合等难点问题,推荐正确率达到了0.88,并在区域卫生平台成功上线。在未来的工作中,我们将通过引入对话系统,增强患者与系统之间的交互。在一次问询之后,系统将主动询问患者可能患有的其他症状,做进一步的鉴别诊断,以提高推荐的精度。
