基于LSTM的层次化篇章依存分析方法
2021-03-18贾延延程学旗
贾延延,程学旗,冯 键
(1. 中国再保险(集团)股份有限公司 博士后科研工作站,北京 100033;2. 中国科学院 计算技术研究所,北京 100190;3. 中国再保险(集团)股份有限公司 信息技术中心,北京 100033)
0 引言
篇章是由词、短语、句子和段落构成的自然语言单位,是一个有组织和层级的整体,可以表达完整的思想和意图。篇章具有连贯性(Coherence)、衔接性(Cohesion)、信息性(Informativity)、意图性(Intentionality)、情景性(Situationality)、可接受性(Acceptability)和跨篇章性(Intertextuality)等7种特性[1]。
基于修辞结构理论(Rhetorical Structure Theory, RST)[2]的篇章结构分析是篇章连贯性分析中的一个重要分支。在RST理论中,基本篇章分析单元(Element Discourse Unit, EDU)之间存在修辞关系。篇章成分分析通过这种修饰关系自底向上地合并分析单元,形成中间节点,直到建立包括整篇文章中所有EDU的篇章成分分析树。目前,绝大多数篇章分析工作都采用成分分析模式。几乎所有针对英语的篇章成分分析工作都基于经典的修辞结构理论篇章树库(RST DT)[3]。例如,Hernault等[4]提出了基于支持向量机的篇章成分分析器HILDA,他们采用二分类器进行结构分析,用多分类器预测修辞关系和核心附属属性,借助位置、长度、距离、句法分析结果、支配集等特征自底向上地建立成分分析树;Feng等[5]为提升HILDA的分析效果,引入丰富的语言学特征。例如,规则、依存结构、语义相似度、支配节点、上下文信息等特征,构造了多达21 410个特征模板,通过互信息评价特征的贡献将其排序;Li等[6]借助斯坦福自然语言处理工具获得句法树结构,利用递归神经网络获得EDU和中间分析单元的向量表示,再基于神经网络的分类器分别判断篇章分析树结构和修饰关系。但是,上述无论传统分析方法或是基于深度学习的篇章分析方法都无法避免人工特征提取。
虽然篇章成分分析较篇章依存分析[7]更受关注,但篇章依存分析的优势不容忽视。篇章成分分析通过引入中间节点的方式,缓解“长距离依赖”这一性能瓶颈问题。然而,篇章依存分析无需增加中间节点,就可以直接分析EDU之间的关系,水平建立分析树。因此篇章依存分析便于直接判断篇章中任意两个分析单元之间是否存在依存关系,其分析结果更为直观和便捷。典型的依存分析工作如Li等[7],选择基于图模型的Eisner算法和最大生成树算法进行篇章依存分析。首先,将RST篇章树库中的成分分析树转换为依存分析树。然后,结合词汇、词性、长度、位置、句法分析结果、语义信息等六类特征集进行实验,所生成的依存分析树不包含额外引入的中间节点。然而,虽然基于图模型的分析方法便于全局优化,且实验效果通常优于基于转移的篇章分析器。但是,用图模型进行分析的算法时间复杂度较高。更重要的是,基于图模型的分析方法依然无法克服篇章依存分析的两大难点与挑战问题: (1)在篇章依存分析中,长距离依赖场景的分析效果差;(2)为提高分析效果,引入大量人工特征来辅助判断。
在实际应用场景,只有减少和规避特征提取才能提高篇章分析器的易用性和鲁棒性,以避免人力浪费。若要缓解长距离依赖场景分析效果差这一瓶颈问题,单纯从特征设计和后处理技巧入手势必低效,应该考虑篇章分析基础框架和模式。
另一方面,分层次处理的篇章成分分析框架具有启发性。Joty等[8]分别使用两个动态条件随机场建立句子内部的篇章成分分析树和句子之间的篇章成分分析树,选择CKY算法进行全局最优解码,并为句内分析和句间分析分别引入丰富且有差异性的特征集进行实验。Liu等[9]同样分层次地进行句子内和句子间的篇章成分分析,分别用两个线性链条件随机场来建模篇章结构和关系。采用贪心策略自底向上的建立篇章成分分析树。他们利用长短时记忆模型(Long Short-Term Memory, LSTM)[10]来建模EDU和句子的特征,并在句间篇章分析场景引入更能体现结构化特征的递归神经网络来表达上下文信息。
上述两个层次化的篇章成分分析工作都取得了不错的实验效果。因此,本文给出了层次化的篇章依存分析方法。这种分析方法不再一次性分析篇章中的所有分析单元,而是分层次地进行篇章分析。首先,建立句子内以EDU为叶子节点的篇章分析子树;然后建立句子间以句子为叶子节点的篇章分析树。最后,整合两层分析结果,形成整篇文章的篇章依存分析树。分层次的方式可以避免一次性分析篇章中的所有EDU,减少了篇章依存分析器所需面对长距离依赖对的数目,从而缓解了长距离依赖这一性能瓶颈问题。另一方面,该方式还带来了可以根据不同层次的特点、设计更有针对性的分析策略的好处。与此同时,本文选取改进的长短时记忆模型,结合注意力机制来获得分析单元的表示,避免特征提取。在RST篇章树库上进行实验,结果表明,本文基于LSTM的层次化篇章依存分析方法避免了耗时的特征设计,且实验效果超越了同类深度学习模型。
1 如何分层次建立篇章依存分析树
本文利用层次化的依存分析方法,为整个篇章建立一棵篇章分析树,其过程分为三个阶段。
(1) 句内层次篇章依存分析: 针对每个句子,将句子中的EDU依次输入到B中,建立句子级别的、以EDU为叶子节点的篇章分析子树,如图1所示。

图1 句内篇章依存分析示例
(2) 句间层次篇章依存分析: 针对整个篇章,将句子作为一个篇章分析单元,将其向量表示依次输入B中,建立以句子为叶子节点的篇章分析树,如图2所示。
图2 句间篇章依存分析示例
(3) 整合分析结果: 用句内层所预测的句子级别的篇章分析子树的根节点标号代表句间层中的句子节点,整合两层的预测结果,得到整个篇章以EDU为叶子节点的篇章分析树,即最终篇章依存分析结果,如图3所示。
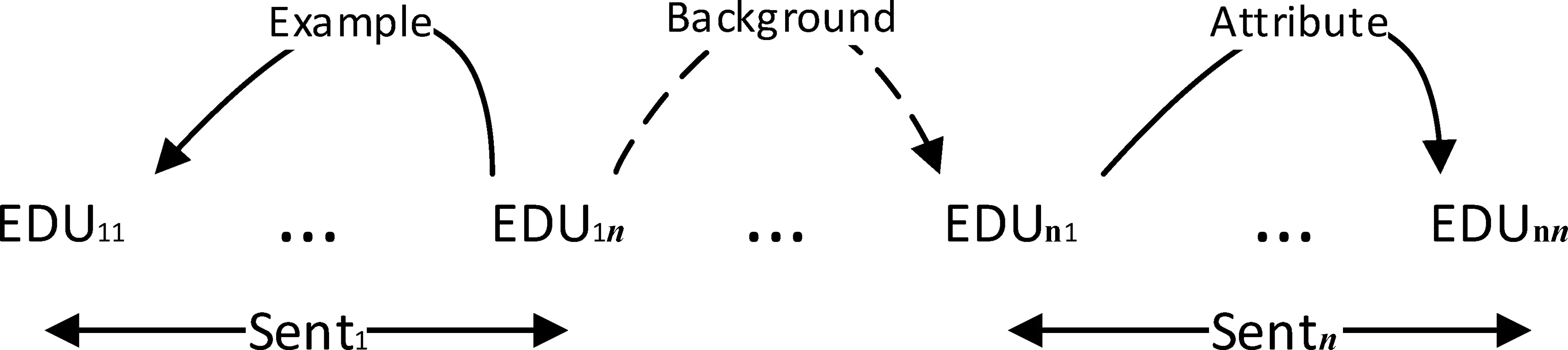
图3 整合句内和句间篇章依存分析结果
2 基于LSTM的层次化篇章依存分析模型
2.1 长短时记忆模型
Sepp Hochreiter于1997年设计了长短时记忆模型(LSTM)缓解了长期困扰循环神经网络(Recurrent Neural Network, RNN)[12-14]的梯度消失或梯度爆炸问题。经典的LSTM包含输入门、输出门、遗忘门三种门控和一个记忆单元。长短时记忆模型具有多种改进形式。例如,双向LSTM、树形LSTM、多层LSTM等。本文选择双向LSTM来提供篇章分析单元的向量表示,具体表示方法在2.4节中详述。
2.2 基于转移的分析方法
本文采用Arc-eager模式的基于转移的篇章分析方法来生成篇章分析树。Arc-eager转移模式改进了Arc-standard[15]转移方法的限制条件。树节点无需找到其所有子节点就可以连接其头节点。该分析方法包括Shift、Left-Arc、Right-Arc、 Reduce等四种转移动作,动作转移过程如表1所示。以本文基于RST语料的篇章依存分析为例,表1中B、S和A分别用于保存输入的篇章分析单元序列、转移过程中形成的子树表示以及转移状态。x和y表示B和S的头节点。Shift操作将B的头节点转移到S的头元素位置;Reduce操作将S中的头节点弹出。Left-Arc根据所预测的依存关系在S和B的头节点之间建立依存弧,其中B的头节点为核心节点,S的头节点为附属节点。动作执行后S中的头节点被弹出,将转移状态保存到A中。相应地,Right-Arc根据所预测的依存关系在S和B的头节点之间建立依存弧,其中S的头节点为核心节点,B的头节点为附属节点。动作执行后B中的头节点被推入S中,将转移状态保存到A中。

表1 Arc-eager模式分析方法转移状态
2.3 层次化篇章分析模型
2.3.1 模型结构
本文基于LSTM的Arc-eager模式篇章分析框架如图4所示。将输入的篇章分析单元依次存入B中。在初始状态下,使篇章中的第一个分析单元处于B的头元素位置,连接B中的前两个元素来获得输入序列B的向量表示;将分析过程中产生的中间子树结构存入S中,用S的头元素构造其向量表示;对于S和B而言,这里的“元素”在句内篇章分析层次为基本篇章分析单元,在句间篇章分析层次是指句子。A用于存放篇章分析过程中产生的历史转移状态,包括转移动作和元素对之间的依存关系。连接A中的前三个转移状态的向量表示来构造模型的历史转移状态表示。本文句内层次的篇章依存分析和句间层次的篇章依存分析都依照此模型结构进行实验,句内和句间层次的篇章分析的输入信息有所不同,将在2.4节中详述。图4中,SH代表转移动作为Shift,RA(Li)表示转移动作为Right-Arc,依存关系为List。
整个样品前处理过程不需要样品转移就能得到经皂化、萃取、干燥、过滤后的待分析试液,大大简化了检测操作过程中的样品前处理步骤,有可能引入误差的环节也相应减少,分析结果的精密度得到明显改善。在实际操作时,可把样品管放到配套的试管架上,将放置有样品管的试管架一起放入超声振荡器中皂化、萃取,有利于批量样品的处理。笔者等建立的烟草中茄尼醇高通量分析检测方法和GB/T 31758-2015方法相比,日样品处理量可提高5倍以上,大大提高了样品分析检测效率。
将S、B、A三部分的向量表示连接起来,经过一个ReLU变换和两个用ReLU作为激活函数的全连接层处理后,得到pt,即t时刻的篇章分析状态。将pt进行仿射变换后,输入到softmax多分类器中,预测各个转移状态的概率,取概率最大的转移状态为当前时刻的模型预测结果。本实验采用贪心策略进行解码,交叉熵作为损失函数。

图4 篇章依存分析模型结构
2.3.2 模型分析过程
本节以RST语料库中的篇章wsj_0609为例,来说明本模型的篇章依存分析过程(这里以不分层次的传统分析方法为例,即一次性处理篇章中的所有EDU,直接得到整篇文章以EDU为叶子节点的分析树)。该篇章包含185个EDU。这里给出其中前4个EDU所构成片段([PresidentBushinsists]E1[itwouldbeagreattool]E2[forcurbingbudgetdeficit]E3[andslicingthelardoutofgovernmentprograms.]E4)的依存分析过程。表2列出了执行完每一个转移状态后,A、S和B中的内容和状态更新。状态0代表篇章分析的初始状态,此时A和S为空,B中存放了所有输入EDU,从第一个EDU开始顺序分析。根据当前S、B和A的状态表示,预测转移状态并存入A中,即更新A的状态。根据转移状态执行相应动作,并建立依存关系(Arc-eager模式),从而更新S和B中的内容;更新后的S、B和A构成了下一次预测的状态表示基础。直到B为空,A包含了分析整篇文章的所有转移状态,S中即为整篇文章的篇章依存分析树。A中粗体转移状态即为根据前一状态的向量表示所预测的转移。

表2 模型状态转移过程
根据表2中的状态转移过程,篇章中的前4个EDU可以构成图5中的篇章依存分析子树。在此基础上,通过继续进行转移预测和状态更新得到整个篇章的依存分析树。

图5 篇章片段的依存分析子树结构
2.4 不同层次的篇章分析单元表示方法
如图4所示,采用双向长短时记忆模型结合注意力机制来表示B和S中的篇章分析单元。篇章分析单元在句内层为EDU,在句间层为句子。
具体来说,本文将篇章分析单元中的单词序列输入到双向LSTM中,使用注意力机制去捕捉词序列中的重点单词。将双向LSTM的顺序和逆序输出连接起来,构成篇章分析单元的词汇信息表示。采用GloVe词向量[16]初始化篇章分析单元中的单词的向量表示。本文通过斯坦福自然语言处理工具(Stanford CoreNLP Toolkit)[17]来获取篇章分析单元中单词的词性信息。与词汇信息的建模方式类似,本文同样采用双向长短时记忆模型结合注意力机制来获得篇章分析单元的词性信息表示。由于建模词汇信息和词性信息的网络结构相同,图4中省略了建模词性信息的网络结构。最后,将篇章分析单元的词汇信息和词性信息的向量表示连接起来构成了S和B中的篇章分析单元的向量表示。
3 实验与分析
3.1 实验语料
本文采用RST篇章树库进行实验,RST语料库包含385篇来自《华尔街日报》的新闻报道,包括超过176 000个单词。最长的篇章包括2 124个单词,平均每篇文章包含458.14个单词,56.59个EDU。平均每个EDU包含8.1个单词[3]。虽然RST篇章树库所包含的篇章数目不多,但是语料库中的篇章篇幅较长;并且包括财务报告、故事、商业新闻、文化评论和社论等多种题材,篇章结构关系丰富且复杂。因此,几乎所有针对英文的篇章成分分析和篇章依存分析工作都选用RST篇章树库进行实验。这也带来了实验结果公平、易于对比的优点。
RST篇章树库建立在修辞结构理论框架下,首先将篇章切分为基本篇章分析单元,然后通过修辞结构来标注EDU之间的结构和修饰关系,并按照EDU的作用和重要性将其分为核心(Nucleus)和附属(Satellite)两种成分。其中表达中心思想和主要信息的EDU作为核心,起到补充说明和修饰作用的EDU作为附属。本文选择Li等[7]的方式,将RST语料库中的成分分析树转换为依存分析树,同样选取其中380篇文章进行实验,包括训练集312篇,验证集30篇,测试集38篇。同时本文选取RST篇章树库中的111个细粒度关系进行实验。
3.2 评价指标
无标记正确率(Unlabeled Attachment Score, UAS)[18-19]和有标记正确率(Labeled Attachment Score, LAS)[20]是句法依存分析和篇章依存分析工作普遍采用的评测指标,便于比较各种同类工作的实验效果。本文即采用UAS和LAS作为篇章依存分析的评测标准。以RST篇章树库为例,无标记正确率是指测试集中找到正确的支配节点的EDU数目占该篇章中总EDU数的比例;有标记正确率是指测试集中找到正确的支配节点,并且EDU对之间的修辞关系也预测正确的EDU数占该篇章中总EDU数的比例。其中,支配节点指在修辞关系中占据核心和主导地位的节点即核心节点;相应地,附属节点指在修辞关系中充当附属成分的节点。
3.3 基线方法
本文将层次化的篇章分析模型和表3中的几种基线方法进行对比。①Basic[21]: 该方法同样为基于转移的篇章依存分析器,使用深度学习模型(LSTM)获得篇章分析单元的向量表示;但是,为达到较好的实验效果,该工作引入多种位置信息来获得篇章分析单元的向量表示,并且采用一次性处理文章中所有基本分析单元的方式进行篇章依存分析。②Hierarchical parser(no feature): 本文层次化的篇章分析法,在句内和句间的篇章分析过程中都不引入任何特征和位置信息,采用2.4节介绍的篇章分析单元表示法来建模EDU或句子;③Refined[21]: 在Basic方法的基础上,为缓解长距离依赖的篇章分析单元对间的结构和修饰关系难以捕捉的问题,该方法设计了一种记忆网络,自动地捕获篇章分析单元间的衔接性和话题线索,从而提高篇章依存分析效果。④Hierarchical parser: 本文层次化的篇章分析法。为发挥层次化的依存分析方法根据不同层次建模的优势,在2.4节的篇章分析单元表示方法基础上,在句间分析层次,引入待分析的句子对是否在同一段内的信息来反应篇章结构特点。⑤MST-full[7]: 该方法是目前效果最好的基于图模型的篇章依存分析器。

表3 篇章依存分析效果对比
3.4 实验结果分析
本文在表3中列出了篇章依存分析结果。通过比较可以发现,使用LSTM获取篇章分析单元的向量表示的Basic方法依然无法避免各种特征提取。采用本文层次化的篇章分析方法(Hierarchical parser(no feature)),即使在不引入任何手工或外部工具提取的特征的前提下,实验效果在UAS和LAS上都高于Basic方法。这说明通过层次化的方式减少篇章分析器所需处理长距离依赖的数目,确实能够提升篇章分析效果。但是,和Refined方法相比,Hierarchical parser(no feature)效果稍逊。主要原因是Refined方法不仅需要抽取多种特征,而且该方法设计了一个记忆网络,将篇章中在向量空间上相似的篇章分析单元聚类到相同的记忆槽中,再将记忆槽的向量表示加入到篇章分析单元的向量表示中。这样,为每一个篇章分析单元标记了其话题线索,这种话题线索反应了篇章的结构信息和分析单元对间的依存关系。为此,在Hierarchical parser中,在句间层次,本文引入待分析的篇章分析单元对(句子对)是否在同一段内的简单位置信息来反应篇章中浅层的结构信息。虽然加入段落信息的方式比使用记忆槽捕捉话题线索的方式简单粗略,但是,Hierarchical parser的篇章依存分析效果依然在UAS和LAS上都超过了Refined分析方法。并且,Hierarchical parser只在句间层次引入句子对是否在同一段这一种位置信息来标记篇章浅层结构,并没有引入任何其他特征;而Refined方法中运用了多种不同特征,例如,用EDU在句子内、段落内和文章中的位置来表示篇章分析单元;还引入了EDU之间是否在一句内、是否在一段内、以及距离信息来表示EDU对之间的位置关系。Hierarchical parser所引入的结构信息远少于Refined方法。可见,层次化的篇章依存分析模式本身较传统的整篇文章一次性处理完成的篇章依存分析模式更有优势。
由于现存的篇章依存分析工作较少,依存分析树又不能一一对应的转换为成分分析树,因此本模型难以和其他篇章成分分析工作公平的对比实验结果。本实验采取同样的实验设置和目前效果最好的篇章依存分析实验MST-full进行对比,虽然效果还有差距,但是MST-full运用了6个复杂特征集,包括词汇、词性、长度信息、位置信息、语义相似度特征、句法分析结果等。其中语义相似度和句法分析结果等特征需要引入外部资源和工具才能获得;另外,MST-full是基于图模型的篇章分析方法,不需要按照某个顺序去判断篇章分析单元之间的结构关系,可以搜索全局最优解。但图模型的篇章分析方法(O(n3))具有比本文基于转移的分析法(O(n))更高的时间复杂度。
为更好地说明分层次的篇章依存分析模型在不同细粒度关系上的分析效果,本文对表3中的Hierarchical parser(ID 为4)的实验结果进行细化,在表4中给出语料中数量最多的前8种细粒度关系和两种数量较少的典型关系(example和background)的UAS和LAS分析结果,并标记了这些关系在语料库和测试集中出现的次数。可以发现,除了elaboration-additional和List两种关系之外,语料库中数量较多的关系,由于训练数据丰富,实验效果通常更好。关系elaborate-additional在语料库中的总数量较多,但分析效果不理想的主要原因是: elaborate-additional(此关系表示附属成分是核心成分的细化或附加详尽说明)在关系含义上和elaboration-additional-e(当附属成分是嵌套结构elaborate-additional变为elaboration-additional-e)以及elaboration-object-attribute-e(不同于elaboration-additional-e之处在于附属成分是其所修饰的核心成分的本质属性)十分相似,容易混淆。并且elaborate-additional在句内和句间层次的分布不均匀,句内层次分布较少。与其相似的elaboration-object-attribute-e在句内篇章分析层次出现了超过 2 000 次,导致篇章分析器因为“从众”倾向,做出误判。List关系通常标识并列语义或者结构,不同于其他关系,List关系的跨度通常较长,因此判断难度更大。

表4 不同细粒度关系的分析效果
4 结束语
本文提出了一种层次化的篇章依存分析方法,该方法通过长短时记忆模型处理篇章分析单元中的序列信息,获得篇章分析单元的向量表示,避免了特征提取。在RST篇章树库上进行实验,结果表明,层次化的篇章依存分析方法的实验效果超过了不分层次、但提取了必要特征的同类深度学习模型。这说明分层次建立依存分析树的方式,通过减少篇章分析器所需处理长距离依赖对的数量,缓解了长距离依赖分析效果差这一依存分析的性能瓶颈问题。实验效果证明,这种层次化的篇章依存分析框架是一种提高篇章依存分析性能的有效途径。
