基于百科语料的中英文双语词典提取
2021-03-18单力秋于济凡陶明阳
王 星,单力秋,侯 磊,于济凡,陈 吉,陶明阳
(1. 辽宁工程技术大学 电子与信息工程学院,辽宁 葫芦岛 125105;2. 清华大学 计算机科学与技术系,北京 100084;3. 清华大学 人工智能研究院知识智能研究中心,北京 100084;4. 清华大学 北京信息科学与技术国家研究中心,北京 100084)
0 引言
随着信息技术的飞速发展,不同国家和地区之间的交流日趋频繁,这使得跨语言自然语言处理显得愈发的有价值。在跨语言自然语言处理中,双语词典是一项非常重要的资源,其可以提供词汇语义的跨语言等价信息[1],对许多跨语言自然语言处理任务很有帮助,例如,跨语言信息检索[2]、机器翻译[3]、跨语言标注投射[4]等。
随着社会的发展,新的概念、术语层出不穷,专业领域新词不断涌现,手工编纂双语词典的方法已经无法及时满足需求[5]。近年来,使用计算机技术自动提取双语词典的方法得到了许多研究人员的关注[6]。一般来说,使用计算机技术自动提取双语词典的方法按照语料库的不同分为基于平行语料库的方法和基于可比语料库的方法[7]。但是这两种方法往往会因为没有足够多对应的双语语料,以至于无法提取出新词或者某些技术术语[8-9]。Nagata等人[9]在2001年指出,对于某些技术术语,可以从部分双语数据中获得其双语信息。例如,在日语中,当引入众所周知的词(如技术术语或名称)时,通常在第一次使用后在括号中添加与之等价的英文。不仅仅是日语,在中文中也常会出现这种情形,例如,在“姚明”的百科信息中,就存在“姚明(Yao Ming),男,汉族”的信息,名词“姚明”的后面就是括号和姚明的英文。基于此,Francis Bond[8]在2008年提出了一种在部分双语语料中提取双语术语的方法,但由于该方法的语料库为论文集、期刊文章以及IT新闻中的文本,故该方法缺少对文本内容以外部分的提取。
针对此类不足,本文以中英文两种语言为例,提出了一种基于百科语料的中英文双语词典提取方法。网上的资源丰富、种类繁杂,而且更新很快,几乎所有新出现的概念或术语都会在网上有所论述[10],而在线百科是对这些资源的汇总,故对在线百科进行专门的双语词典提取能够提取出新词和技术术语。本方法在一定程度上弥补了基于平行语料库和基于可比语料库两种方法的不足,同时相比于只从部分双语语料文本内容里提取双语信息的方法,本方法结合了在线百科特有的结构特点,多提取到了一倍多的双语信息。但也由于在线百科是不断更新的,我们的语料库是离线的源代码,可能会出现术语覆盖不全面的情况,因此我们的语料库也需要定期的更新。
本方法一共分为两大模块,分别对百科语料进行了五种不同的提取方法,其中第一模块的三种提取方法的成功率都达到了98%以上,五种提取方法提取到的双语信息进行综合查重后的数量为969 308条。与其他方法不同,由于本方法所使用的语料库是其他方法没有使用过的百科语料,故本方法的评价指标是总的提取数量和提取的成功率。综上所述,本文的贡献主要体现在以下三点: 一是本文提出了一种对新词和技术术语有很好的提取效果的双语词典的提取方法;二是首次直接使用了百科语料作为语料库进行双语词典的提取;三是本方法相比基于部分双语语料文本内容的方法、在百科语料的数据集上对双语信息的提取效果有显著提升。
1 相关研究
目前,提取双语词典的方法有基于平行语料库的方法、基于可比语料库的方法和基于部分双语语料的方法。
基于平行语料库的方法是利用平行语料库中的高质量的双语文档对齐信息来进行双语词典提取的[11-12]。这种方法以孙乐等人[11]在2000年完成的基于中英文平行语料库的双语词典自动抽取的工作为代表,他们首先对平行语料进行句子对齐,其次对英语语料进行词性标注,对中文语料进行切分并做词性标注,统计名词和名词短语生成候选术语集、计算中英文的翻译概率,最后通过设定阈值来选取中文翻译,得到双语词典。平行语料库是由同一个文件的两种或者多种不同的语言表达所产生的语料组成,所以利用该方法来构建双语词典具有很好的提取效果。但平行语料库的构建比较困难,仅存于少数语种和少数的领域之中,不利于该方法的推广使用。相比之下,基于可比语料库的方法则解决了这一问题。
基于可比语料库的方法是利用可比语料库中大量交叉但不是严格互相翻译的双语信息进行双语词典的提取[13-14],这些互译的双语信息词语基本出现在内容、语域、交际环境等方面相近的不同语言文本上下文环境中。1995年,Rapp[15]发现: 在单语种文本中,一个单词会出现在不同的文本中,而且与这个单词共同出现的单词集合是基本一样的,说明单词的共现关系具有稳定性,这种规律也被推广到了多语言中。基于此,Rapp[16]在1999年提出了基于词语关系矩阵从可比语料库中提取双语词典的方法;张永臣等人[17]在2006年提出了基于Web数据的特定领域双语词典抽取。近年来,基于神经网络的方法得到的词向量[18]被广泛应用于各个领域,这种词向量表示也为双语词典构建的方法打开了新思路。一部分基于词向量的方法首先把两种语言的每个词表示成词向量[19-25],然后为两种语言的向量空间建立联系,得到共有的双语词向量空间;另一部分基于词向量的方法是直接训练神经网络模型得到共有的双语词向量空间[26-29],这些方法的共同点是在得到共有的双语词向量空间之后,在双语词向量空间中进行查找,获取双语词典。与平行语料相比,可比语料更容易获得,且存在于大量的语种和领域中,便于推广使用。但是这两种方法在提取新词或者某些技术术语时都存在双语资源匮乏的问题,对此,衍生出来了一种基于部分双语语料的方法。
基于部分双语语料的方法可以从部分双语数据(又称“主要使用一种语言的数据”)中提取出双语词典。Nagata等人[9]指出,对于某些技术术语,可以从部分双语数据中获得双语信息,这种部分双语数据通常是来自新闻或者一些领域内的文章,故此类方法对新词和一些技术术语的双语信息有很好的提取效果。这种方法主要以Francis Bond[8]的工作为代表,其方法是通过使用部分双语数据中明确的提示(括号中的单词)来提高精度,查找出所有出现的“词(翻译)”,并将其编译为词典;Cao等人于2018年提出了一种基于超链接的半监督双语词典提取方法[30],这两种方法给我们提供了启发。
2 方法描述
为提取到所有新词和技术术语,本方法对所有的百度百科词条源代码进行了提取。在Francis Bond[8]的思想基础上,本方法融合了基于在线百科特有的基本信息框提取和基于Web标签特有的超链接提取,在一定程度上提高了双语词典的提取效果。
本方法的原理框图如图1所示,首先对百度百科词条的源代码进行预处理,并把百度百科词条分成三个部分,分别是词条摘要、基本信息框和正文内容;然后分别对这三个部分进行对应的五种不同方法的提取,得到对应的提取结果;最后进行综合查重,把这五种提取方法的提取结果按照不同的权重综合到一个双语词典之中。

图1 基于百科语料的中英文双语词典提取原理框图把百度百科词条分成词条摘要、基本信息框和正文内容三个部分,分别对这三个部分进行对应的五种不同方法的提取,对提取结果进行综合查重并融合到一个双语词典之中,其中基于词条摘要、基于基本信息框和基于词条正文的三种提取方法组成了基于单百科词条的双语词典提取模块,基于超链接和基于正则匹配括号的两种提取方法组成了基于多百科词条的双语词典提取模块。
根据使用百科词条数量的不同,本方法分为基于单百科词条的双语词典提取和基于多百科词条的双语词典提取两大模块,一共五种提取方法,其中: ①基于基本信息框的提取方法利用了基本信息框中结构化的数据,因结构化的数据置信度高,数据的质量也比较可靠[31],所以非常适合提取双语信息;②基于超链接的提取方法利用了Web标签的性质,每一条超链接都有可能代表着一个新词或者技术术语;③基于词条摘要、基于正文及基于正则匹配括号这三种提取方法,由于语料均可以视为部分双语语料的文本内容,故用到了Francis Bond[8]的提取思想,即利用部分双语语料中的特殊字符进行提取,比如在文本中提到某些新词或者技术术语时,有的会有一个括起来的英语解释,这种提取方法就是利用此线索来提取出双语信息,不同的是,百度百科中括号里面可能会有部分中文信息,例如,“英文: ”“英语: ”“学名: ”等,本文方法是在匹配到这些中文信息之后先将中文信息剔除,再进行英文信息提取。
2.1 基于单百科词条的双语词典提取模块
单个百度百科词条的内容通常由三个部分组成,分别是词条摘要(词条简介)、基本信息框和词条的正文部分,所以基于单百科词条的双语词典的提取模块分别对这三部分进行提取。首先对百度百科源代码进行预处理,取出词条名称、词条摘要和词条正文的文字部分,对词条摘要和词条正文进行词条名称的正则匹配,做对应的基于部分双语语料的提取,对于基本信息框部分则保留其原本的代码形态,我们可以使用专门的方法来对其进行提取。
2.1.1 基于词条摘要的双语词典提取方法
有些词条的词条摘要部分会出现该词条的名称及其对应的英文,并会用全角或者半角的小括号括起来。例如,如图2所示,“数据挖掘”的百度百科词条中,词条摘要的第一句话就是“数据挖掘(Data mining)又译为资料探勘、数据采矿。”我们可以用正则来检索词条摘要里是否有词条名称“数据挖掘”和其后面是括号英文,如果有再用正则提取出括号里的内容,从这个词条摘要中我们就抽取出来了“数据挖掘”及英文“Data mining”这一对双语信息。

图2 “数据挖掘”百科词条中摘要部分出现了该词条的双语信息
2.1.2 基于基本信息框的双语词典提取方法
有些词条摘要的下面可能拥有该词条的基本信息框。如图3所示,“数据挖掘”的百度百科词条的词条摘要下面就存在这样的信息框,信息框中的外文名属性对应的属性值即为该词条的英文信息,从这个基本信息框的源代码中我们先检索属性是否为外文名,如果是就提取出它属性值里的文字,即“Data mining”这一英文信息,与词条名称结合,形成一对双语信息。

图3 “数据挖掘”百科词条中基本信息框部分出现了该词条的英文信息
2.1.3 基于词条正文的双语词典提取方法
有些词条的摘要部分可能不存在该词条的双语信息,但是其正文部分可能存在该词条的双语信息。例如,如图4(a)所示,“莲花滩乡”这个百度百科词条中,其摘要部分并没有该词条的双语信息,而图4(b)中,“莲花滩乡”百科页面中的正文部分却出现了“莲花滩乡(Lianhuatan Xiang)”这一双语信息,为了提高双语词典的提取效果,正文这部分的双语信息也要提取出来,其提取方法与词条摘要的提取方法类似,也可以用正则检索到词条正文里是否有词条名称并且其后面是括号英文,再用正则提取出括号里的内容,与词条名称结合,成为一对双语信息。
2.2 基于多百科词条的双语词典提取模块
在某词条的正文部分,可能会出现其他词条的双语信息,例如,在“数据挖掘”的百科词条的正文部分,就出现了如图5所示的内容,其中“分类(Classification)”“估计(Estimation)”等都不是该百度百科词条名称对应的双语信息,但却是各自对应的百度百科词条的双语信息,例如,“分类”就对应着如图6所示的百科信息,对于这种在某词条的正文部分出现的其他百度百科词条双语信息,也要提取出来备用。针对这一种情况,本方法进行了基于多百科词条(跨百度百科)的双语词典的提取,基于多百科词条的双语词典提取模块分为基于超链接和基于正则匹配括号这两种提取方法。

图4 “莲花滩乡”百科词条的信息
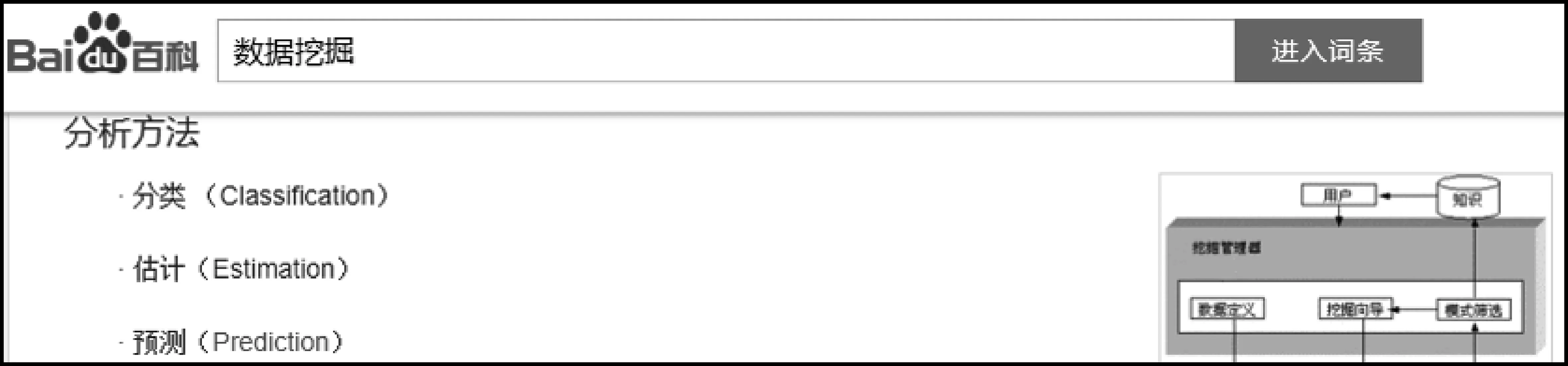
图5 “数据挖掘”百科词条中的正文部分出现了其他双语信息

图6 “分类”的百科词条的摘要部分信息
2.2.1 基于超链接的双语词典提取方法
跨百度百科进行提取最直观的方法就是查找词条全文所有的超链接,因为在所有在线百科词条的内容中,每一个超链接都对应着其他的百科词条,如果该超链接是图7中“统计”所示的可以点击的超链接,后面是“(Statistics)”这样的英文,这里就是一对双语信息,而且这种双语信息的准确率非常高,这里的提取方法利用了href标签的特性。

图7 “数据挖掘”百科词条的正文部分的超链接出现了双语信息
2.2.2 基于正则匹配括号的双语词典提取方法
没有超链接的词语也有可能是其他百度百科的词条名称,如图5中的“分类(Classification)”,没有超链接,但却是百度百科词条的双语信息。而且网络上的词语更新速度非常快,现在不是百科词条名称的词语以后也有可能成为百科词条名称,所以也要把这些双语信息提取出来。对此本文提出一种基于正则匹配括号的提取方法,该方法首先对百度百科的源代码进行预处理,取出全文的内容,然后把内容进行反向处理,再匹配反向全文的所有括号,提取出括号前的K个字符,并对这K个字符按顺序进行下面两种不同方法的提取。
(1) 首先在百科语料中提取出百度百科所有的词条名称,用文件的形式进行保存,然后用这个词条名称文件对这K个字符进行检索,如果检索出了词条名称且恰好该词条名称在K个字符的末尾,则意味着这个词条名称及其后面括号里的英文是一对双语信息,提取出这一对双语信息;若检索时发现多个词条名称都在这K个字符的末尾,则以长度更长的词条名称为主。此方法使用了Zhang等人快速匹配的方法[32],加快了程序运行的速度。
(2) 对于那些没有检索出词条名称或者检索出来了但没恰好在末尾的这K个字符,我们把它添加到一个列表中,若再遇到相同的情况且是相同的英文,也把它的前K个字符放入该列表中,最后对这个列表取公共的后缀,并提取出该公共后缀和这个英文,作为一对双语信息。实验中将K设置为25,在实验部分会详述这样设置的原因。
3 实验
3.1 实验语料及评估标准
本实验选择了中文和英文两个语种,实验中所使用的语料库为百度百科词条的源代码,该语料库可以通过爬虫爬取得到,本实验用到的百度百科词条的源代码一共9 133 651条。在基于正则匹配括号的提取方法中,使用了所有的百度百科词条的名称文件,这个文件需要对所有百度百科词条源代码进行对应提取才能得到,由于很多词条的名称是重复的,所以最终提取到的百度百科词条的名称一共8 169 135个。此外,并非所有的百度百科词条都拥有双语信息,故我们手动标注了以拥有基本信息框为主要条件的1 000个百度百科词条的源代码,用以测试各个提取方法的成功率。
本实验的实验评估标准为总的提取数量和提取的成功率,其中总的提取数量是所有提取方法的提取结果综合查重后的数量,提取成功率(extraction success rate,ESR)的计算方法如式(1)所示。
其中,SEN为成功提取的双语信息数量,TN为标注的总数量。
3.2 实验结果
通过对本方法提取出来的双语信息进行检查,我们发现这些双语信息中大部分的质量较高,但语料库中存在少量的噪声数据,例如,这五种提取方法都有可能提取出同一个中文的英文信息,但这些英文信息可能是不完全相同的,如表1中的“莲花滩乡”双语信息中,基于摘要和超链接的方法没有提取到双语信息,其余三种方法却找到了两种不同的信息。
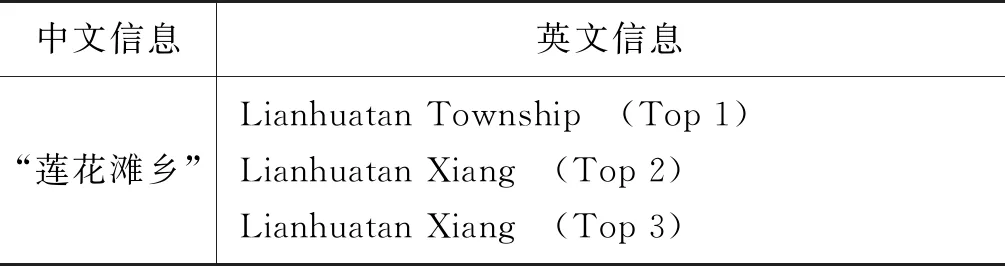
表1 “莲花滩乡”双语信息表
在百科语料中,基本信息框属于典型的结构化数据,结构化数据的置信度高,数据质量可靠,所以基于基本信息框方法提取下来的数据也作为了本次提取的双语词典的基础,即Top 1,然后依次是基于超链接、摘要、正文和正则匹配括号的四种方法,这四种方法提取出来的结果在基于基本信息框方法提取结果的基础上进行综合。
我们对每一种方法所提取到的双语词典进行了长度测量,各方法双语信息的数量如表2所示,对于1 000个手动标注的数据,标注的数量、各个提取方法实际提取到的数量和提取的成功率如表3所示,其中基于超链接和基于正则匹配括号的两种方法为基于多百科词条的方法,每个百科词条内容中可能会出现数个符合条件的词, 故其标注的数量可能会超过标注的数据数量。由表2、表3可知,基于基本信息框的提取方法比较适合在线百科语料库,也适合所有拥有基本信息框的语料,且该提取方法可以将大部分的双语信息提取出来。

表2 每一种方法提取到的双语信息数量以及综合查重后的双语信息总数量

表3 每种方法的提取成功率
3.3 对比实验
为了验证本文方法的有效性,本文设计了对比实验,即基于部分双语语料文本内容的方法与本实验基于部分双语语料百科的方法进行了比较。表4为两种方法查重后的双语信息数量,由表4可知在百科语料库中本方法提取出来的双语信息数量远远超过基于文本内容的方法提取出来的双语信息数量;表5为两种方法提取出来的部分词语的英文信息, 由两种方法提取出来的双语信息情况的对比可知,本方法所提取出来的双语信息更加准确。

表5 两种方法提取出英文信息的对比
3.4 实验参数分析及错误分析
对于基于正则匹配括号的提取方法中的参数K=25,这里给予解释。图8显示了百度百科词条的名称中各个长度的数量,由图可知,当词条名称的长度超过25之后,名称的数量较少,长度在1~25之间的名称数量更是占据了总数量的99.5%;当参数小时,错误率会非常大;当参数大时,如图9所示,提取到的双语信息数量却又会下降,其原因是正则表达式在匹配的过程中,覆盖了想要提取的词。在使用基于正则匹配括号的提取方法中的第二个方法时,例如,原文本是“数据挖掘(Data mining)是数据库知识发现中的一个步骤,数据挖掘(Data mining)通常与计算机科学有关...”目标是提取出{‘数据挖掘’:Data mining},即把这个双语信息放在列表的第0位置。若取小参数,例如10,则可以正常提取,即列表的第0位置为“掘挖据数”;若取大参数,例如50,正则表达式会优先匹配第一个括号,而后指针向后挪动50位,这样就会覆盖住相同的信息,导致提取失败,这时列表的第0位置就变成了“掘挖据数,骤步个一的中现发识知库据数是)”,明显这不是我们所需信息。综合以上两点,最终确定了25为最后的参数。

图8 百科词条中各个名称长度所拥有的名称数量

图9 随机10 000条数据各个参数的提取数量
经过对各个提取方法出现的错误进行分析,我们总结出了以下三点:
(1) 超链接准确率低于95%,其原因是实验时所用的百度百科源代码是一年前爬取下来的,但是标注的时候使用的是现在的百度百科,超链接的更新很快,现在有很多以前所没有的超链接,这就降低了此模块的实际成功率,为反映真实情况,我们在爬取下来的部分源代码上进行了标注,如表3基于超链接方法的括号内容所示,其成功率达到了97.08%。
(2) 基于正则匹配括号的提取方法的成功率为54.46%,其主要原因是这种提取方法的特点是: 语料的数量越多,所能提取的双语信息的数量越多,而如果语料数量少则表现欠佳,为此我们提出了新的测量方式,即先用此方法在全部数据中匹配,再在结果中抽样进行人工判断,如表3基于正则匹配括号方法的括号内容所示,其成功率达到了63%。
(3) 基于词条摘要、基本信息框和正文的这三种提取方法的成功率比较高,错误可能是人工标注时的错误或者一部分百度百科的更新导致的。
4 结论与展望
双语词典是跨语言自然语言处理中一项非常重要的资源。随着社会的发展,新词以及具体的技术术语不断涌现,某些新词或技术术语可以通过基于部分双语语料的方法提取出来,而目前基于部分双语语料的方法主要集中在对文本内容的提取上。针对此不足,本文提出了一种基于百科语料的中英文双语词典的提取方法,本方法分为两大模块,共用五种不同的方法对百科语料进行提取,其中第一模块的三种提取方法的成功率都达到了98%以上,最终的结果是对这五种方法的提取结果进行综合查重后的双语词典,查重后双语信息的提取数量为969 308条。与以往的基于部分双语语料的方法不同,本方法在对文本内容的提取基础上融合了基于在线百科特有的基本信息框提取和基于Web标签特有的超链接提取,在一定程度上提升了双语词典的提取效果。
在实验过程中我们也发现了一些不足之处,例如存在选取大参数导致有些双语信息提取不出来以及成功率低的问题。因此,下一步的研究方向将集中在如何在参数选取最大值的情况下依然不干扰双语信息的提取上,并寻找方法解决第五种方法成功率低的问题,以提高最终的双语词典的提取效果。
