基于命名实体敏感的分层新闻故事线生成方法
2021-03-18樊笑冰李睿祥刘旭辉
樊笑冰,饶 元,王 硕,李睿祥,刘旭辉
(1. 西安交通大学 软件学院 社会智能与复杂数据处理实验室,陕西 西安 710049;2. 西安交通大学 深圳研究院,广东 深圳 518057)
0 前言
社会网络的迅速发展为人们高效地获取新闻信息提供了便捷途径,但这些信息海量、无序且碎片化的特征,给人们从中完整地获取一个新闻事件的发展动态带来了一定难度。尤其是新闻事件往往具有层次化的特征,如针对“汶川地震”事件的新闻报道中,包括了实时灾情、各方捐助、英雄事迹等不同层次的信息。单纯获取事件相关新闻,无法准确有效把握新闻事件的线索和发展脉络。另外,新闻要素可能是新闻报道的核心,如在“汶川地震”事件中英雄事迹相关的报道是围绕人物进行展开介绍的,若以事件为线索构建故事线可能会造成主次倒置。因此,在挖掘细粒度事件的特征中,突出新闻要素的重要性,从多视点构建故事线,帮助人们全方位理解事件的发展脉络具有重大的研究价值。
近年来,针对故事线生成的相关问题与核心技术已存在大量研究。其中,Guo等[1]提出了Crowd Story模型,通过文本相似性和时间相似性将事件划分为几个方面,有效体现出事件的层次化特性。Yuan 等[2]引入一种基于地理信息的聚类方法,从空间角度构建故事线。Huang等[3]提出一种检索与特定事件相关的新闻文章并生成故事情节的新方法(UNEE),依靠人工检索获取事件,依赖于命名实体共现关系划分子事件,强调了命名实体的作用。然而,这些工作依然存在以下明显的缺陷: ①部分事件检测依赖人工,无法实现完全无监督的自动化过程;②现存社会网络中新闻故事线生成方法主要尝试在海量数据中获取结构单一的新闻事件,但受到挖掘粒度的影响,事件往往表现出层次化的特性;③命名实体属于新闻的核心要素,事件的主题在很大程度上依赖命名实体,事件的脉络也大多以命名实体为导向,但传统的故事线生成方法对其利用并不充分。
为解决上述问题,本文提出将新闻主题信息与文本信息相结合的主题事件抽取方法,可以在无人工干预的情况下从大量新闻数据中检测到主题相关的新闻报道的集合;在此基础上,充分挖掘新闻的文本信息、要素信息等多维语义信息来构建多视点属性图(MVAG),并利用社区发现算法划分MVAG来获得主题事件下的不同子事件;通过求解无向图的最大生成树问题实现故事线的构造;最后,从参与者和地址两个角度来构建事件的发展脉络。本文的主要贡献总结如下:
(1) 将层次化的事件分解为事件与不同主题下的子事件。提出基于事件主题信息与隐式语义信息相结合的主题事件检测方法,并提出一个基于多维语义的社区检测算法划分子事件;
(2) 识别命名实体,充分抽取新闻多维语义信息,据此划分主题事件下的不同粒度的子事件;
(3) 提出了一种基于多维度与多层次信息的故事线构造方法,以命名实体为导向实现多视点故事线的构建。
1 相关工作
目前,针对新闻故事线生成主要研究工作大致可以分为以下三类: 一阶段法尝试采用一个统一的模型提取出故事线的结构化表示;二阶段法将问题分解为事件检测与故事线构造两阶段分别解决;三阶段法是在二阶段法的基础上,将事件检测划分为更为细粒度的子事件抽取,实现事件的层次化生成后,再进行故事线的构造。
1.1 一阶段法
为提取故事线的结构化表示和演化模式,Zhou等[4]提出一种无监督贝叶斯模型——动态故事线检测模型(DSDM),并将每个故事线建模为命名实体和主题的联合分布。Zhou等[5]提出了一个非参数生成模型(DSEM),实现了故事线的结构化表示和演化模式的同步抽取,同时将每个故事线细分为位置、组织、人员、关键词和主题的联合分布,在不需要人工干预的情况下自动确定故事线的数量。考虑到新闻文章的标题和核心主题往往可以共享相似的故事线分布,同时,在相邻时间段内,描述相似的文档往往也可以共享相似的故事线分布,因此,Zhou等[6]基于以上两种假设提出了一种新的基于神经网络的方法(NSEM),并实现了故事线的结构化表示和演化模式的自动提取。Hua T等[7]将故事线、事件类型和话题逐层细化为三层,提出一种自动生成故事情节的层次贝叶斯模型(ASG),实现从大量Twitter文档中有监督地生成故事情节。
1.2 二阶段法
Zhou等[8]提出一个双层故事情节生成框架(TexSL),该框架第一层利用最小支配集算法和整数线性编程方法生成灾难事件的全局故事情节,第二层结合最小支配集和斯坦纳树方法得到受灾害影响的特定区域的故事情节。Zhou等[9]在上述工作的基础上提出一个改进框架(iTexSL),该框架通过基于地理信息的聚类方法将文档划分为不同的本地文档集,在第二层对每个局部文档集用嵌入字的方法构造MVAG,通过求解斯坦纳树问题得到局部区域的故事线。Wu等[10]构建了基于维基百科当前事件的知识库,将新闻编码到事件空间,通过相干性评分和KL散度建立事件相干性,使用梯度增强树建立事件连贯性,两者结合构造事件故事线。Zhou等[11]利用Single-pass和人工监控器来发现主题中的事件,提出一种基于词频逆事件频率(TF-IEF)和时间距离代价因子(TDC)相结合的新模型,实现事件演化关系的建模,并通过构建事件演化关系图来揭示事件发展脉络。
1.3 三阶段法
为了突出事件层次化,需要以细粒度挖掘子事件特征。Qian X 等[12]提出一种基于子事件的社交媒体的事件摘要框架,该框架首先对事件除噪保留相应原始信息,其次采用一种用户文本图像聚类方法(UTICC),联合用户属性信息、文本、图像等多模态数据来增强子事件聚类结果,最后识别具有代表性的文本和图像,形成事件的整体可视化总结。李莹莹等[13]首先利用HAOSPORT抽取微博的核心词,依据核心词的共现关系构建网络图,再利用社区检测将微博文本划分为多个细粒度事件,结合 DBSCAN 与LDA将含有相同主题的事件聚成簇,组装成故事,最后将事件树构成有向无环图,将该图的最大生成树作为事件脉络。
2 研究问题和系统框架
2.1 基本定义
本文提出的故事线具有层级化结构(图1),并以此为依据进行相关概念定义。

图1 故事层级结构示意图
定义1故事线storyline: 故事线指同一故事中按照时间顺序排列的事件。故事线由二元组
定义2事件event: 事件为一组社会参与者在特定时间段内就特定主题进行的信息流[14]。事件由四元组
定义3子事件subevent: 子事件为主题事件的不同方面。子事件由三元组
定义4新闻news: 由五元组
2.2 系统框架描述
命名实体敏感的故事线构造过程中存在两个关键性问题: ①将事件划分为主题事件与主题事件下子事件两个层面;②将命名实体作为子事件划分的重要依据,并以命名实体为向导构建事件发展脉络。针对上述问题,本文提出了一个系统的解决方案,其整体框架如图2所示,通过主题事件检测、子事件划分和故事线构造三个关键任务解决新闻故事线的生成问题。
2.2.1 主题事件检测
该任务旨在从新闻数据集中检测主题相关的新闻事件。具体步骤为: ①获取新闻的隐式语义信息;②获取新闻的主题信息;③采用基于隐式语义信息与主题信息相结合的方法对新闻进行聚类,得到主题事件。
2.2.2 子事件划分
该任务对主题事件进行更为细粒度的划分,得到主题事件下的不同子事件。对于一个主题事件,利用新闻文本语义信息、时间、地址集合、参与者集合和关键词集合计算新闻的相似度构建MVAG,再使用社区检测算法将该图划分为不同社区,一个社区即为一个子事件。
2.2.3 故事线构造
该任务针对主题事件,采用时序关系生成新闻故事线的主线;对于主题事件下的子事件,则利用地址信息和参与者关系来分析新闻的演变,生成新闻故事线的两条副线;主线和副线共同构成整个新闻故事线。
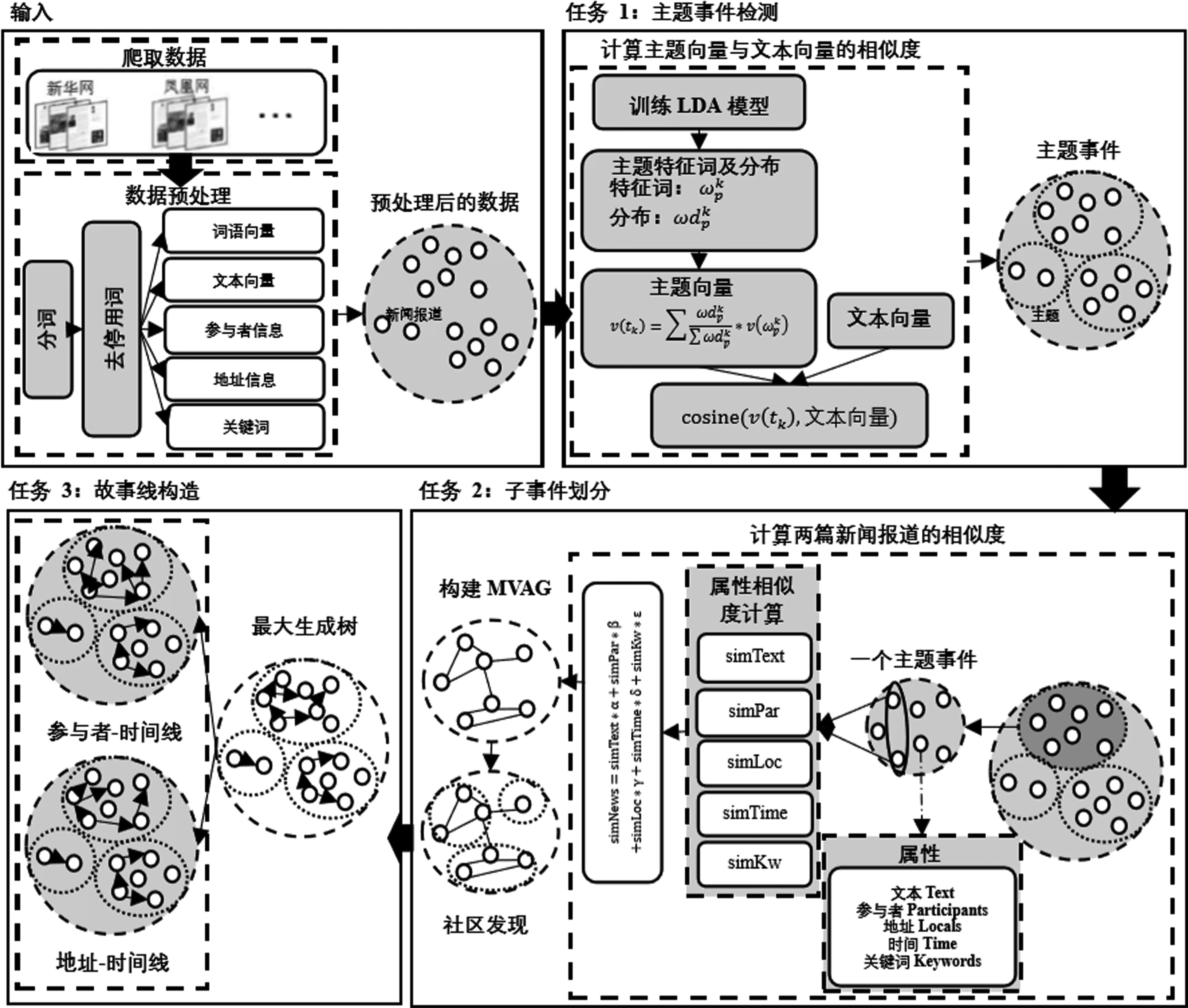
图2 系统整体框架示意图
3 模型框架
3.1 事件检测
3.1.1主题事件检测
构建新闻故事线的首要条件是从宏观上检测出同一主题下所有新闻报道的集合,即主题事件的检测。目前最常用的方法是利用LDA[15]主题模型来获取新闻报道的潜在主题信息,将不同主题的新闻报道聚集成簇,并加以区分。新闻文本通常为长文本,但也存在文本较短的新闻,对于这类短新闻,术语的低频性将导致所生成的矩阵过于稀疏,使得通过LDA得到主题特征词分布的结果无法达到预期效果。特别是LDA模型在统计主题特征词的分布时,仅关注特征词之间的共现关系,忽略了词语上下文信息,造成了上下文语义信息的缺失。Word2Vec等表示学习模型利用文本的上下文语境词来预测目标词的语义嵌入,能够获取文本的低维语义信息,并在一定程度上弥补了LDA的缺陷。因此,本文使用LDA与Word2Vec结合的方法(LW2V)对主题事件进行检测。
对于原始新闻数据集News={report1,report2,…,reportn},本文使用LDA挖掘事件隐式的主题信息,生成k个主题T={t1,t2,…,tk}的主题—特征词的分布,并选取前P个分布最高的特征词作为该主题的特征词代表。前P个主题—特征词及分布如式(1)所示。

(1)
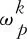
主题事件检测阶段旨在生成k个不同主题的聚簇Cluster={c1,c2,…,ck}。这可以通过计算主题向量与新闻报道向量的余弦相似度进行聚类得到,相似度取值最大的主题为该篇新闻报道的主题。新闻报道的向量表示如式(3)所示。

3.1.2 子事件划分
子事件划分阶段旨在从主题事件的新闻数据集中获取内容特征相关的不同子事件。该步骤将主题事件进行细粒度划分,不同的子事件反映了主题事件的不同层面,使得故事线具有层次化特性。
所有子事件均隶属于主题事件,因此同一事件内的不同子事件之间具有相似主题。依据新闻报道中所包含的时间、参与者、地址等个性化特征,本文提出一种基于多维语义信息的社区检测算法来划分子事件。该方法首先抽取新闻报道的多维语义特征,计算特征的相似度,构建多视点属性图,然后再利用社区检测算法对图进行划分得到新闻的子事件。具体方法包括如下两个步骤。
步骤1 主题事件下子事件的相似度计算方法
依据2.1节中定义4对新闻的定义,本文将新闻的文本text、参与者par_set、地址loc_set、时间t和关键词kw_set五部分的相似度组成子事件的相似度。
对于给定的两个新闻i和j,采用余弦相似度来度量文本相似性,如式(4)所示。
其中,vi和vj分别对应了新闻i和j内容的特征向量。本文采用Word2Vec模型对新闻内容特征向量进行语义嵌入表示。
新闻i和j的参与者相似度度量方式如式(5)~式(7)所示。
其中,par_seti和par_setj分别是新闻i和j抽取的一组参与者的集合。par_seti′为第i个新闻中的参与者集合与新闻i和j中的参与者的交集的差集;par_setj′为新闻j参与者集合与新闻i和j的参与者的交集的差集;f(par_seti′,par_setj′)为新闻i和j不共现参与者的相似度。
本文使用哈工大的命名实体方法进行参与者的识别。该命名实体识别采用BIOSE标注方法进行实体标注,为了更加反映现实情况的实体信息,本文将按照标注拼接的完整短语作为新闻实体信息,而不是划分出的独立的词语。基于此思想,本文提出的f(parset′i,parset′j),具体计算如算法1所示。

算法1: 非共现参与者相似度算法input: par_seti',par_setj'output: f1foreachparininpar_seti'2 parin' ← segment(parin)3 foreachparjminpar_setj'4 parjm' ← segment(parjm)5 v1,v2 ← vector(parin',parjm')6 f ← f+cos(v1,v2)7 end for8end for9f ← f /(len(par_seti')*len(par_seti'))10returnf
同理,新闻i和j的地址相似度度量方式,如式(8)~式(10)所示。
simloc(i,j)=

(8)
loc_seti′=loc_seti-|loc_seti∩loc_seti|
(9)
loc_setj′=loc_setj-|loc_setj∩loc_setj|
(10)
其中,loc_seti和loc_setj分别是新闻i和j抽取的一组地址信息。
不同事件的命名实体可能存在着明显差异,因此新闻参与者相似性和地理位置相似性对于评价新闻事件相似性往往是有效的。此外,同一事件内不同子事件中的实体通常具有某些特征的相似性,甚至在不同维度下的不同子事件中,实体之间也存在着一定的关系。本文采用哈工大命名实体工具包抽取参与者和地址,其中参与者包括人名和机构名。
新闻i和j时间相似度度量如式(11)所示。

(11)
其中,ti和tj分别是新闻i和新闻j的发布时间,H是整个语料库的时间范围,并且“|logH|”用来将事件相似度压缩到0~1的范围内。
新闻i和新闻j之间的关键词相似度度量如式(12)所示。
其中,kwi和kwj分别为从新闻i和新闻j中抽取的关键词集合。
上述五种相似度可独立分别计算,而面向新闻的相似性可以表示如式(13)所示。
simNews(i,j)=simText(i,j)*α+
simPar(i,j)*β+simloc(i,j)*γ+
simTime(i,j)*δ+simkw(i,j)*ε
(13)
其中,α、β、γ、δ、ε为不同相似度的系数,且α+β+γ+δ+ε=1,通过实验,当α∈(0.15,0.2)、β∈(0.2,0.25)、γ∈(0.2,0.25)、δ∈(0.15,0.2)、ε∈(0.1,0.15)时结果最好。
步骤2 新闻MVAG的构建以及社区的划分
针对主题事件下新闻的相似度simNews(i,j)计算方法,本文构造了一个MVAG来表示主题事件下新闻之间的联系。该图可以表示为一个无向图G=
本文将子事件划分任务转化为对MVAG进行社区检测的过程。本文使用社区检测算法[16]进行社区划分,所划分出的每一个社区即表示为一个事件。
3.2 故事线构造
故事线构造阶段的主要目标是为故事生成包含摘要和多视点的故事发展的线性可视化脉络。
故事线构造主要分为两个阶段: 主线构造与副线构造。其中主线以时间顺序为主,串连主题事件,利用TextRank算法生成的多文档摘要作为主题事件的描述。而对于副线的构造,本文提出一种有限制的最大生成树算法。
有限制的最大生成树算法的核心是求解无向图中的最大生成树,其结果是生成覆盖无向图所有点的代价最大的树结构。故事线旨在向人们展示事件发展的脉络,对于报道较多的事件,直接使用最大生成树算法计算过于复杂。因此,本文在计算过程中,在满足最大生成树的基础上,将同时满足图中目标新闻与邻居新闻边的权重大于阈值ζ的点划分到用于构造最大生成树的新闻集合中。具体步骤如算法2所示。

算法2: 有限制的最大生成树算法Input: G=
依据以上算法得到最大生成树新闻集合,为使故事线有更好的可理解性,本文用每篇新闻报道的实体,将副线的生成分为以下两种: ①以时间—参与者为序生成的故事线;②以时间—地址为序生成的故事线。最终生成的故事线如图3所示。
4 实验与结果
4.1 数据集
目前,以故事为导向的数据集较少,且数据集也未公开,因此本文从凤凰网的资讯专题下(1)http://news.ifeng.com/special/index.shtml选取10个热门新闻事件专题报道,共爬取5 285条数据。通过预处理去除重复新闻报道和信息缺失的新闻,剩余4 886条新闻作为最终数据集,数据统计信息如表1所示。

图3 本文方法生成的故事线

表1 以事件为导向的新闻数据集
4.2 事件检测参数选择与对比算法分析
主题事件检测阶段,主要参数为主题个数K与LDA模型迭代次数。本文利用困惑度[15](perplexity)来判断主题个数,计算如式(14)所示。
其中,Nn为每条新闻报道的词语个数;p(wn)为新闻词语的分布,具体到LDA模型如式(15)所示。
在评价主题事件检测结果时,本文假设新闻事件分类结果已知,分别以: 查准率(P),针对实验检测结果,有多少新闻分类正确;查全率(R),针对原本的事件分类结果,多少新闻被正确检测;以及F值作为评价标准。
在本文数据集上计算不同主题个数下困惑度得分(图4)时发现,当K=10时困惑度最低。而在相同主题个数(K=10)计算不同迭代次数下困惑度得分(图5)时,迭代次数为400时困惑度最低。
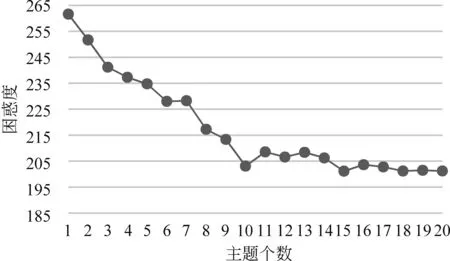
图4 不同主题个数的困惑度得分
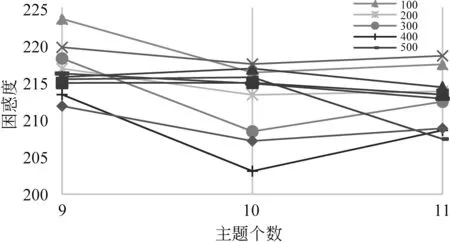
图5 主题10在不同迭代次数下困惑度得分
通过对比下列算法进行实验性能的比较:
(1)LDA该方法用主题模型LDA生成文档—主题的分布,并对应于文档与主题,得到最终聚类结果。
(2)k-means将k个点作为初始聚簇质心,基于划分的思想,将剩余节点划分至与其最邻近质心所在的聚簇,更新质心坐标。迭代进行上述工作,直至划分结束。
(3)LDA+k-means[17]该方法将LDA主题模型生成文档—主题分布作为k-means的输入,最终通过k-means方法得到不同的聚类结果。
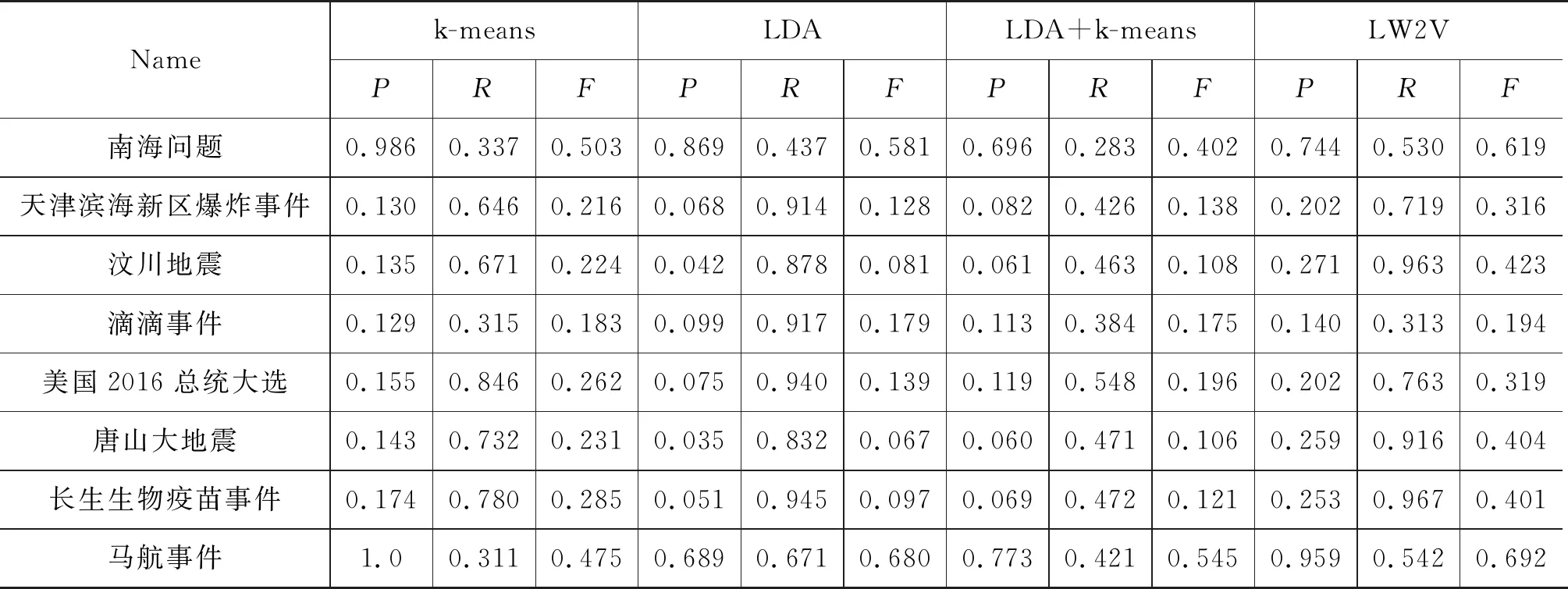
四种不同的算法针对10个主题事件的判别结果如表2所示。对于这10个事件,LW2V的实验结果明显高于其他方法,这说明本文方法性能良好。在事件“2014巴西世界杯”中,由于其区分度较高,其他方法在该事件上也取得了较好的结果。k-means方法将文本表示为高维度的空间向量,存在“维度灾难”的问题;LDA+k-means虽降低了文档向量维度,但也因此缺失了部分信息,导致最终效果不理想。而本文的LW2V将传统LDA与深度语义信息相结合,拥有更好的性能。

表2 主题事件检测实验结果
续表
4.3 主题事件下子事件的划分算法对比分析
主题事件下子事件的划分属于无监督聚类过程,为判断该过程是否有效,通常使用外部评价标准和内部评价标准相结合的方式。一般地,外部评价标准需要提供参考标准,而子事件划分阶段无评价标准,因此本文采用内部评价标准轮廓系数[18](Silhouette coefficient)和CH指标(calinski-harabasz index)来评价实验结果。
其中,CH指标通过计算类中各点与类中心的距离平方和来度量类内的紧密程度, 通过计算各类中心点与数据集中心点距离平方和来度量数据集的分离程度,分离程度与紧密程度的比值即为CH指标。具体计算如式(16)所示。
其中,m为样本数,k为类别个数,tr为矩阵的迹,Bk为类别之间的协方差矩阵,Wk为类别内部的协方差矩阵。
本文选取以下三个算法作为实验对比方法。
(1)DBSCAN[19]: 该方法主要有eps扫描半径和min_samples最小样本数两个参数。通过实验,当eps取值范围在0.5~0.6,min_samples取值范围在5~12时,聚类个数适当且轮廓系数和CH指标达到最优。
(2)UNEE: 利用该方法计算权重划分的子事件结果与本文结果做对比。调节阈值在0.005~0.03范围内时有适当的聚类个数,且轮廓系数和CH指标达到最优。
(3)Ours: 当本文方法的阈值设置在0.25~0.37范围内时,聚类个数合适且各项指标取值较高。
模块度[20]可以评估网络划分的质量,以主题事件“马航事件”为例进行实验,计算不同聚类个数下模块度得分,结果如图6所示。
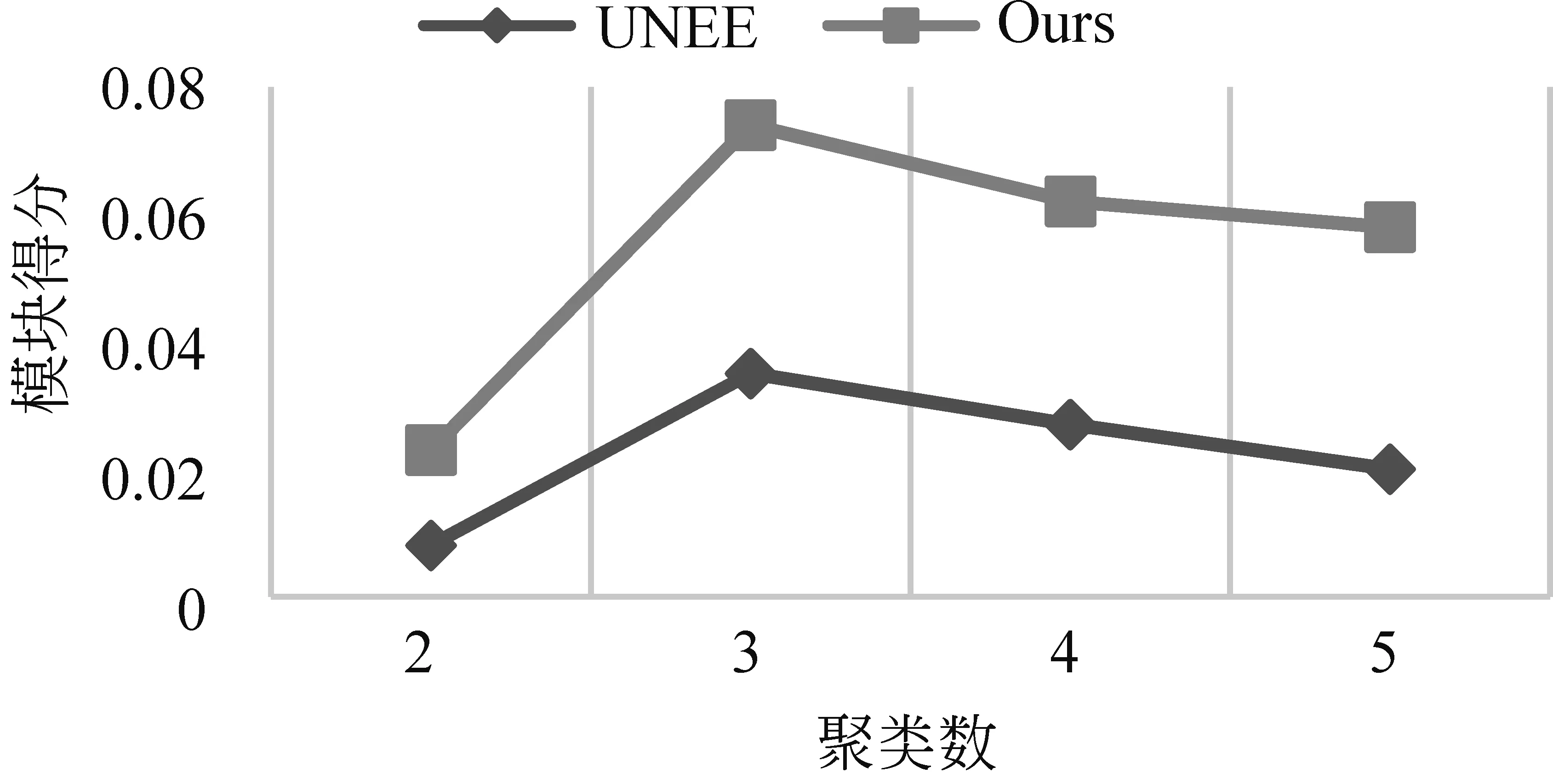
图6 不同聚类个数下模块度得分
可看出本文方法模块度得分高于对比实验方法,且在聚类个数为3时,模块度最大。因此,本文认为“马航事件”划分为3个子事件最合适。在图7中,结合DBSCAN参数调节的结果以及本文方法模块度结果,实验对比四个不同聚类个数下结果: 其中DBSCAN方法仅将Word2Vec训练的向量作为语义表示,在同一主题事件下进行划分,无法进行有效区分;UNEE强调了新闻的时间与命名实体,相比DBSCAN有了很强的区分度;在UNEE的基础上,本文对实体细粒度进行划分,并且将关键词作为新的语义特征,增强了语义表达,因此在两个评估方法下都取得了最优结果。
4.4 故事线构造实验结果及分析
故事线构造阶段主要评价故事线生成的性能。以“马航事件”为例,依据划分子事件结果,本文对3个子事件分别进行故事线构造。实验将Timeline[21]和UNEE方法作为对比方法。

图7 不同聚类个数轮廓系数和CH指数的得分
(1)Timeline: 该方法基于时序关系关联事件;
(2)UNEE: 该方法将子事件中结点v与其余结点之间最短路径集合与子事件任意两点之间自事件集合的比值作为中心度,选取中心度最高的文章,并生成故事线。
本文主要评价的三个子事件为:
子事件1马来西亚航空公司的一架波音777客机17日在靠近俄罗斯边界的乌克兰东部地区坠毁,马来西亚航空公司MH17号航班被击落坠毁时,乌克兰东部领空并未受限,尽管已有多家航空公司收到飞行危险警告。一些传言称客机系遭导弹击落,目标其实是俄总统弗拉基米尔·普京的专机。联合国安理会一致通过决议,强烈谴责马航MH17客机坠毁事件,同时要求相关武装组织允许国际调查人员“安全、有保障、完全不受限制”地进入坠机现场。
子事件2马来西亚航空公司MH17航班于当地时间17日在乌克兰东部与俄罗斯交界处坠毁,有消息指飞机失事原因是被导弹击落。2014年7月,乌克兰政府军和亲俄罗斯分离主义叛军战况激烈时,马航MH17客机从荷兰阿姆斯特丹飞往吉隆坡途中,在乌克兰东部区被俄罗斯制的导弹击落,机上298人全数罹难。美欧分别宣布对俄罗斯实施更大规模制裁,市场对俄乌之间紧张局势可能导致原油供应受到干扰的担忧升级,而马航客机在乌克兰境内失事的消息更强化了这一趋势。
子事件3马来西亚航空MH17航班空难发生三周年之际,一处缅怀遇难者的纪念碑17日在荷兰阿姆斯特丹史基浦机场附近揭幕。7月18日,在荷兰阿姆斯特丹,人们在纪念碑旁缅怀遇难者。
为更好地验证本文生成的故事线,本文采用基于用户体验的方式来进行性能的评价。实验招募20名志愿者,在未告知生成方法的情况下,将三种故事线交志愿者打分,其打分指标为: 可理解性(comprehensive),是否更易把握事件整体内容;概括性(generality),是否具有更好抽象效果;准确性(accuracy),是否真实反映事件发展。评分标准为最好5分,最差1分。
基于用户体验的故事线构建的性能评价结果如表3所示。本文方法在可理解性、概括性和准确性指标上比UNEE分别平均高出0.44、0.11和0.50。对3个不同子事件构造故事线,在子事件3上,本文方法与UNEE方法获得了相同的结果,但比Timeline高出了1.21,进一步分析发现子事件3中的新闻报道数量过少,导致了最短路径方法与本文生成的事件脉络大致相同。而对于子事件1和子事件2,本文方法构造的故事线得分明显高于其他两个对比方法,这说明志愿者更加倾向于本文方法的构造结果。

表3 基于用户体验的故事线构建实验结果
5 总结
针对海量和碎片化的新闻数据以及社交网络数据,深入挖掘事件和分析事件演变关系,并对其构造故事线是一个极具挑战的工作。本文提出基于事件主题信息与隐式语义信息相结合的方法检测主题事件和基于多维语义的社区检测算法获取子事件,使得所获取的事件更具层次化和细粒度的特征,经过多种实验结果的对比,证明本文方法能够更好地划分事件。本文强调了命名实体对划分子事件的影响程度,并提出基于多维度信息的事件脉络构造方法,从多个维度构建故事线,提高了故事线的理解性。
目前,基于深度学习的方法体现出巨大的优势与应用前景,如何结合主题信息进行深度聚类是接下来需要进一步考虑的关键问题;同时,在故事线构造阶段,如何精准分析新闻逻辑演变关系也为下一步工作提出了新的挑战。
