使用虚拟图片作为目标检测训练集
2021-03-18李政谦李志强
李政谦, 王 娟, 李志强
(北京华电天仁电力控制技术有限公司, 北京 100039)
随着深度学习的不断发展,一系列重要成果将工业界和研究界的关注点转移到产生有价值的数据,并从中训练学习算法,使基于深度学习的各种应用能够获得越来越高的准确度。想要将这些应用在现场大规模部署,必须有一个能够泛化的检测模型,因此除了算法本身性能外,还需要数以十万计的高质量数据作为训练集。一些场景容易获得数据集,如微博上的用户观点、股票的各项数据等。但同时有一些场景很难获得大规模训练集用来训练高泛化能力的模型,如武器检测、设备异常检测、安全帽检测等。同时为了能够正确识别这些图片,必须手动修改数据(如对图片进行标注),这需要付出相当大的人力成本。
选择安全帽检测作为研究对象的原因一是因为安全帽检测领域没有公共训练集,且对环境、遮挡、人物姿态、实时性等方面要求较高,这可以使用虚拟引擎来模拟复杂环境并生成大量图片;二是网络上现有五千张左右适用于安全帽检测的图片,数量适中,可以通过调整数据集数量来研究使用虚拟图片对不同规模数据集的影响。
在本研究中,使用专业的游戏引擎Unity3D来解决该领域训练图片较少的问题并对获取的图片进行自动标注。首先创建一个虚拟训练集,包括室内控制室、室外现场等不同场景,晴天、雨天、阴天等不同天气条件,明暗等不同光线情况,虚拟人物存在胡须、眼镜等不同特征,并设置正面、背面、侧面、跑动、低头等不同姿态。同时使用真实图片作为测试集,以主流算法Yolov3作为检测算法。实验结果表明,虚拟图片不能完全代替实际图片,在用来训练的实际图片较少的情况下,增加虚拟图片能够有效提高系统检测精度。
简述了现有安全帽检测领域及虚拟数据的各项相关研究,描述虚拟引擎及训练集的制作过程,概述了检测方法并讨论了实验结果,最后进行总结。
1 相关工作
1.1 安全帽检测相关研究
对于基于深度学习的安全帽检测,近年来研究人员做了很多研究工作。FU等[1]使用Faster R-CNN[2]+ZFNet[3]的组合搭建了安全帽检测系统,该系统能够实时识别监控视频中的人员和安全帽,较原方法提升了检测精度。方明等[4]通过在以YOLOv2[5]为基础的模型中加入密集块,使模型的大小缩减为原来的1/10,增加了模型的可用性。Oviedo等[6]使用了EspiNet V2模型,改进了Faster R-CNN的CNN部分,获得了一个6层(4卷积)的简单CNN网络,减少了一定的参数量。该模型能够从低角度和移动摄像机拍摄且存在一定遮挡的情况下获得较高的mAP(mean average precision,平均准确率均值)。刘君等[7]设计了一种改进的YOLO[8]网络结构,将RPN算法融入YOLO算法中,并借鉴R-FCN[9]算法,去掉一个全连接层,在卷积层上进行滑动窗口操作,采用先池化再卷积的方法,以减少图片特征丢失。该模型在准确率与检测速度上都取得满意的结果。Fu等[10]将深度残差网络技术与基于YOLOv3[11]检测算法的多尺度卷积特征相结合,结合多尺度检测训练,调整训练过程中的损失函数。该改进提高了安全帽佩戴检测精度。但这些检测工作使用的都是数量不多的网络图片或固定场景的视频图片,不具备较强的泛化能力。
1.2 虚拟数据相关研究
随着对海量数据的需求,虚拟生成的数据集最近获得了研究人员的极大兴趣。虚拟数据在计算机视觉领域很早就有了成功的历史。Taylor等[12]利用计算机游戏《半条命》(Half-Life)创建了一个监控系统中的跟踪评估系统。Marin等[13]使用虚拟场景的公开数据集用于行人检测基准测试,在没有特别选择虚拟样本的情况下,基于虚拟和真实的训练所产生的分类器的性能相似。Aubry等[14]使用计算机生成的图像来研究训练的卷积神经网络,通过改变对物体风格、视角和颜色等因素的网络刺激,对深度特征进行定性和定量分析。Hong等[15]探讨了将在模拟虚拟世界中训练的深度神经网络模型转移到现实世界中进行基于视觉的机器人控制的问题。在类似的场景下,Luo等[16]开发了一种在虚拟环境中训练的端到端主动跟踪器,可以适应现实世界机器人的设置。Bewley等[17]训练了一个深度学习模型,在模拟环境中驾驶,并根据现实世界中经历的视觉变化对其进行了适配。
在游戏引擎的选择上,一些研究人员选择流行的引擎虚幻引擎4(UE4),Qiu W通过该引擎创建了一个开源插件UnrealCV1。在此基础上得到数据集并将Caffe与虚拟世界连接起来,以测试深度网络算法[18]。Lai等[19]提出了一个新的视觉深度学习虚拟环境(VIVID),它可以提供大规模的室内和室外多样化的场景并模仿人类动作,通过对深度学习的验证,展示了该系统的能力和优势。
也有很多研究人员使用《侠盗猎车手》(GTA-V)等开放世界游戏,其特点是世界范围广、高度逼真。它们的逼真度不仅体现在材料的高逼真度上,还体现在游戏中的及其真实的外观和高度的自由化上。Richter等[20]提出了一种使用GTA-V创建大规模的像素精确的地面真实数据准确语义标签图的方法,用来训练语义分割系统。Martinez等[21]与Filipowicz等[22]均使用GTA-V进行自动驾驶汽车的训练,通过游戏内的图像创建了大规模训练集,并训练一个用于识别图像中的停车标志并估计其距离的分类器。Fabbri等[23]创建了一个从GTA-V中获取图像的数据集,并证明在真实人物跟踪和姿势估计等任务上可以达到很好的效果。Johnson-Roberson等[24]使用GTA-V进行车辆检测,主要的检测方法是Faster-RCNN,并在KITTI数据集上验证了他们的结果。
近两年,unity3D凭借其容易上手,所见即所得,功能齐全,缩短开发时间;一次开发,多平台发布等优点逐渐被研发人员关注。Lee等[25]在Unit3yD中使用深度学习开发手写识别:使用卷积神经网络和神经网络算法中的EMNIST数据集设计学习数据,并使用Unity3D游戏引擎构建整个系统。该系统已经开发了一种使用游戏引擎的人工智能系统,简化了处理过程,提高了兼容性。Martinez等[26]使用视频游戏引擎Unity开发,以重现罕见但关键的转角案例,可用于重复训练和增强机器学习模型,了解目前自动驾驶车型的局限性。Hossain[27]通过使用Unity 3D,让嵌入式设计的汽车在3D环境中检查和试验新的轨道、参数和计算。在虚拟环境中模拟真实汽车的活动,并利用Unity 3D将嵌入式设计的汽车融入到测试环境中,实现任意自主驾驶、转向预测、深度学习和端到端的学习算法。Wood等[28]提出了一种快速合成大量可变眼区图像作为训练数据的新型方法UnityEyes。使用虚拟图像用来在复杂的场景、甚至在极端角度也可以用来预测。实验表明该方法在数据集上展示了具有高准确率的预测结果。Wang等[29]提出了一种用于训练车辆检测器的合成图像的方法。在此方法中,考虑了许多因素来增加更多的变异,并扩展了训练数据集的领域,开发了一种转移学习的方法来提高作者的车辆检测器的性能,该方法只用一些人工标注的真实图像来提高作者的车辆检测器的性能。
从以上关于虚拟世界用在深度学习中的研究可知,研究人员习惯于使用虚拟场景进行自动驾驶的训练,而进行目标检测方面相对较少,更是很少有研究人员使用基于unity3D虚拟引擎搭建虚拟环境获得虚拟图片进行安全帽检测相关工作,这也是我们工作的创新点之一。
2 虚拟训练集的建立
普通的目标检测可以在庞大的通用注释数据集上进行训练,如ImageNet[30]、MS COCO[31]、Pascal[32]或OpenImages v4[33]等,这些数据集从网络上收集了数以十万计的图片,并已进行标注。而安全帽检测领域由于没有通用数据集,网络图片又十分有限,因此难以生成泛化性强的模型,选择unity3D建立虚拟数据集帮助训练。Unity3D是由Unity Technologies开发的一个让使用者轻松创建诸如三维视频游戏、建筑可视化、实时三维动画等类型互动内容的多平台的综合型游戏开发工具,是一个全面整合的专业游戏引擎。其提供了编辑器、beast渲染器、tree creator等大量的辅助工具,支持Javascript、C#、Boo等3种脚本语言,通过Mono实现了.Net代码的跨平台应用,从而完美解决了对数据库、xml、正则表达式等技术的支持。在图像渲染方面其支持100多种光照材质shader,20多种后期处理效果。和同类引擎相比,Unity的优势在于轻量级,安装容易,学习门槛较低,使用方法简单,友好的可视化编辑界面功能强大,编写方便,极易上手。功能齐全及完美的工作流程,缩短开发时间,提高工作效率。
为了生成训练场景,使用自制的电厂现场模型以及一些网络上的场景模块作为检测场景,一共25个不同的场景;通过在unity3D中使用材质球(Materials)、粒子系统(Particle system)并调整渲染模式将每个室外场景设置了晴天、阴天、雨天等3种不同的天气条件,对于室内场景,在每个室内空间使用了spotlight点光源,调整光源的亮度来改变图片的色彩;在每个场景部署一系列有安全帽和没有安全帽的头部特征各异且姿态不同的人员,并使用Animation动画功能使他们能够在场景内自由活动,生成多种不同的图片;通过鼠标调整摄像头视角,获得全方位多角度的数据集。最终能够使用75个不同场景获取训练集,每个场景截取100张图片,一共获得约7 500张虚拟图片。不同场景图片如图1所示。

图1 各场景图片示例
对于数据集注释的自动生成,场景内布置的人员如图2所示,他们的头部设有三维识别框,对三维识别框的每个顶点进行Camera.WorldToScreenPoint(unity3D中三维坐标转屏幕坐标方法)函数处理,获得其在二维图像上的位置,计算其变换后的三维边界框的尺寸,选择三维识别框中8个顶点映射到二维图片上x、y坐标的极大值与极小值作为标注框的4个顶点,即voc标注格式中bndbox值。然后通过可见性判断此框是否被遮挡,可见性是通过测试截图的视线射线对框体中一定量的固定点的遮挡来检查可见度,如果至少有一条射线没有被遮挡,则认为该物体是可见的。当点击截图按键时,会同时保存图内人员头部的矩形框及相应属性和位置,自动建立数据集的注释,保存格式如图3所示。

图2 虚拟图像的头部三维识别框

图3 生成的VOC格式标注文件
3 实验及结果分析
3.1 Yolov3网络介绍
基于深度学习目标检测算法可分为基于分类的目标检测算法和基于回归的目标检测算法。基于分类的目标检测算法也称为两阶段目标检测(two-stage),首先针对图像中目标物体位置,预先提出候选区域,然后微调候选区并输出检测结果。其代表有R-cnn[34]、Fast R-CNN[35]、Faster R-CNN、FPN[36]、R-FCN、MASK R-CNN[37]等。由于两阶段检测存在提取候选区域的过程,检测速度难以满足部分现场需求,因此研究人员开发出单阶段(one-stage)算法,将整个检测过程简化为一次端对端的检测。其代表有YOLO系列、RetinaNet[38]、M2Det[39]、EfficientDet[40]等。选用当前的主流模型Yolov3作为测试模型,以增加实验的普适性。
Yolov3采用残差网络模型Darknet-53网络结构代替了YOLOv2的Darknet-19,通过53个卷积层和5个最大池化层来提取特征,使用批量归一化和dropout去除操作来防止过拟合,损失函数使用logistic代替了softmax,等等。YOLOv3预检测系统采用了多尺度训练,使用分类器多次执行检测任务,将模型应用于图像的多个位置和比例,例如输入为416×416像素时会融合13×13,26×26,52×52像素3个特征层。因此YOLOv3适用于小目标检测,其结构图如图4所示。
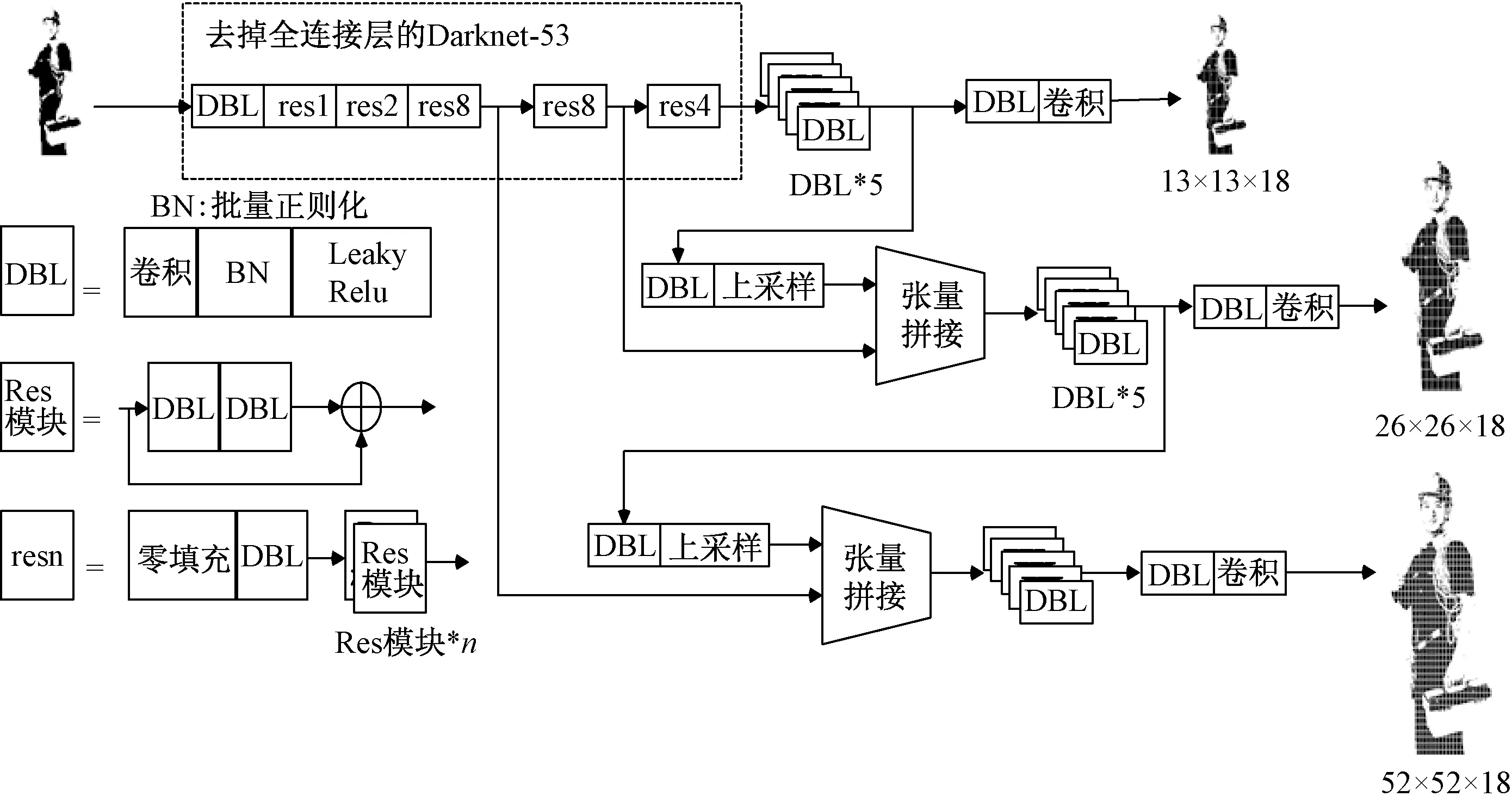
图4 Yolov3网络结构图
3.2 评价指标
1)检测速度(frames per second,FPS):每秒能够检测的图片数量。
2)交并比(intersection over union,IOU):预测边框与实际边框的交集和并集的比值。
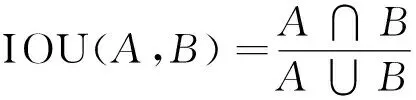
(1)
式中:A为预测边框;B为实际边框。
3)泛化交并比(generalized intersection over union,GIOU):一个优化的交并比[41]。
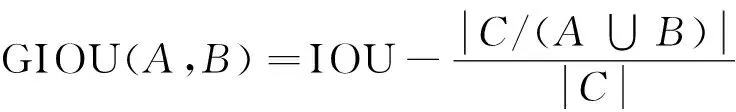
(2)
式中,C为A与B两个框的最小闭包区域面积。
4)准确率P(precision):
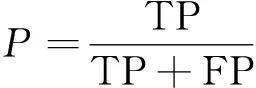
(3)
式中:TP为预测正确的正样本的数量;FP为将负样本预测成正样本的数量。
5)召回率R(recall):

(4)
式中,FN为将正样本预测为负样本的数量。
6)平均准确率(average precision,AP):
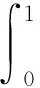
(5)
式中,t为在不同IOU下曲线的召回率,如当t=0.7时,只有IOU≥0.7才被认为是正样本。
7)平均准确率均值(mean average precision,mAP):
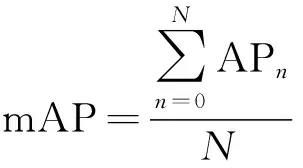
(6)
式中,N为种类数量。
3.3 模型训练过程
实验仿真在 PyTorch框架下进行,训练及测试的计算机硬件配置 CPU 为 i9-9900X处理器,32GB内存,GPU 为 Nvidia GeForce GTX 1080Ti,CUDA版本号为10.2.120,操作系统为Ubuntu 19.04。
设计进行三轮训练进行对比,第1轮使用300张真实图片、300张虚拟图片、300张真实图片加300张虚拟图片作为训练集,第2轮将真实与虚拟图片的数量增到1 000张,第3轮将真实与虚拟图片的数量增到4 000张,3轮的测试集均为1 000张真实图片,用来评定只使用虚拟图片的效果以及真实图片与虚拟图片搭配真实图片的效果。同时采用图像翻转、裁剪、变化颜色、修改亮度、对比度、饱和度等多方式进行图像增广。
训练中每一批次包含32张图片,优化器选择adamW[42],损失函数选择Focal Loss,其中α=0.25,γ=1.5,初始学习率为0.1,在完成3代训练后调整学习率至0.000 1,连续50代未获得更优模型则在当前学习率乘以系数0.3得到新的学习率,每次训练迭代3 000代。总体结果见表1。
3.4 结果分析
通过实验结果对比可以看到:
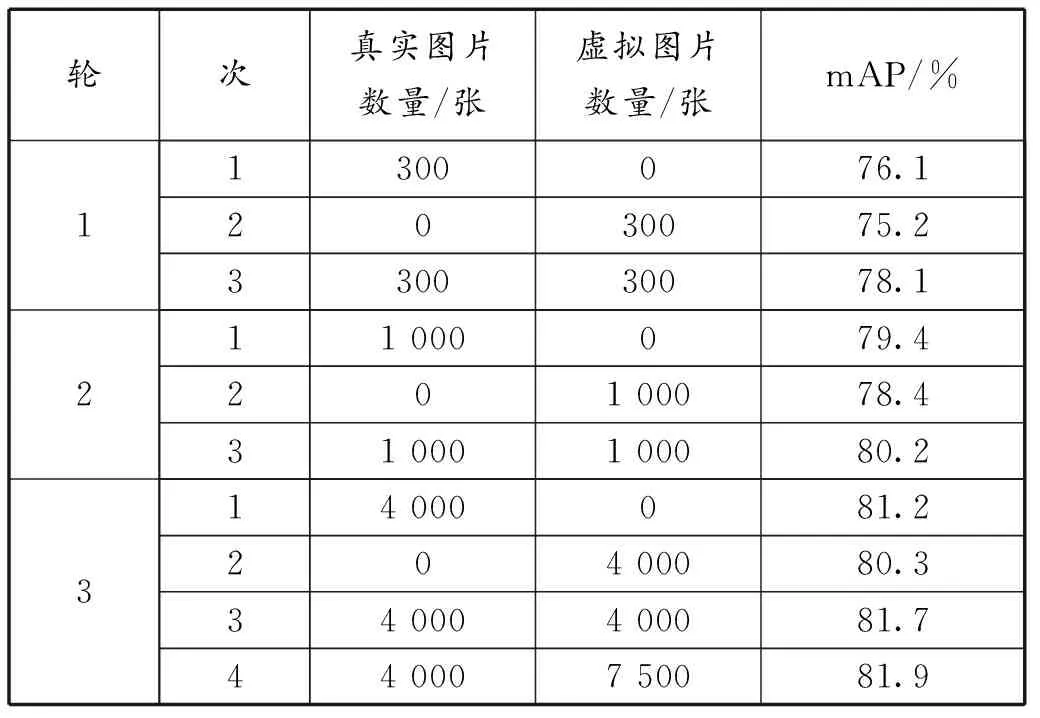
表1 实验结果对比
1)由结果可知,使用虚拟图片训练的模型比使用真实数据训练的模型loss值更低,但同时mAP也略低于真实图片,说明:①使用虚拟图片训练后的模型能够较为准确地识别真实世界的检测目标。②虚拟图片还无法完全达到真实图片的复杂度,在训练时相对容易识别检测目标,而测试集使用的是真实图片,模型训练的复杂度不够高,因此会出现loss值低的同时mAP也低的情况。
2)由表1中每轮的1、3次对比可知,使用虚拟图片与真实图片的联合训练集比只使用真实图片的训练集所训练出的模型mAP高,说明:①虚拟数据集的加入能够在一定程度上提升训练后模型的泛化能力;②随着真实数据的增加,虚拟数据集对mAP提升的效果逐渐降低;③对于拥有几千张网络图片的安全帽检测,虚拟数据集对最终mAP有提升效果;④对于真实训练集较少的研究,适合采用虚拟图片扩充数据集。
3)由表1中第3轮的3、4次对比可知,增加更多场景的虚拟图片仍然能够小幅提升模型mAP。
4 结束语
提出了使用虚拟图片作为可用真实图片少的目标检测模型的训练集,通过使用unity3D制作了大量的带有头部三维识别框的人物模型及场景模型,混合搭配这些模型并在动画中自动截图生成虚拟安全帽检测训练集及其标注数据集,进行实验对比发现使用虚拟图片作为训练集能够较为准确的识别真实世界的检测目标,但检测效果比真实图片略差;真实图片与虚拟图片组成的联合数据集能够提升安全帽检测的mAP;对于训练数据较少的研究来说,适合采用虚拟图片扩充数据集。
本研究之后首先将着力于提升虚拟世界的模型真实度,力争进一步接近真实图片;其次研究unity3D的时间及场景自动切换,人物自由行动等功能,在自动标注的基础上减少布置场景的工作量;最后由于武器检测领域的可用真实图片远远少于安全帽检测,而各类游戏中武器模型已栩栩如生,在此领域制作虚拟训练集也会很有意义。
