基于灰色经济计量学模型的中国教育水平影响因素研究
2021-03-18刘媛华
陈 昕, 刘媛华
(上海理工大学 管理学院, 上海 200082)
教育问题一直是国家和社会关注的热点问题,影响着中国未来经济和政治发展。中外学者关于教育水平的问题做了一些重要研究,很多学者都热衷于从微观层面研究教育水平的相关问题。周燕芬和刘小瑜[1]首次把研究对象分成5个教育等级,从家庭角度探究了教育水平不平等对收入的影响程度,发现城乡二元化是造成收入不平等的主要原因,这一结论在受教育水平较高的家庭更加突出。Kazuya和Muhammad[2]考虑到样本的异质性,从城市子样本和农村子样本两个方面研究了不同背景下受教育年限对宗教、投票行为以及对于其他宗教的态度的影响机制,结果表明一个促使伊斯兰国家教育成就的项目可能会对个人的宗教信仰和国家政治经济产生重要的影响,且在城市子样本中,其统计意义上更加显著。2020年新冠疫情的爆发给中国的教育也带来一定的挑战,相较于边远地区的学生,居住于城市的学生更容易接受较为优质的教育资源[3]。黄岚等[4]重新定位研究对象——科技拔尖人才,发现了大学教育对尖子生的影响主要体现在知识结构与学习能力等方面上。
从文献回顾上可以看出,学者们从微观上对于教育水平的研究较为丰富,多是分为城乡区域分别去比较教育水平的差异,或者是只关注部分受教育群体。但是,这一研究结果对于整体来说不具有代表性;同时,在对相关问题进行研究时并未考虑到国家层面的影响因素,所以可能存在遗漏变量问题;最后,由于不同国家的国情与政策不同,国外学者得出的建议并不一定完全适用于中国。
“科技兴则民族兴,科技强则国家强。”党的十八大以来,习近平总书记高度重视科技创新,把创新摆在国家发展全局的核心位置。党的十九大报告明确提出,坚定实施科教兴国战略,人才强国战略。青少年作为祖国和民族未来科技创新的希望,科学素养是青少年全面发展的核心要素之一。同时,在此次报告中,习近平总书记指出,“建设教育强国是中华民族伟大复兴的基础工程。”在全国教育大会上,习总书记又进一步提出了“加快推进教育现代化、建设教育强国”的新要求,由此可见,教育对于科技发展的重要性,加快教育强国的建设是社会主义现代化强国和实现中华民族伟大复兴中国的必然要求。因此,对教育进行研究,也是为了更好地促进科技的发展。
依托上海理工大学科技发展项目,以中国为例,采用灰色计量经济学模型对教育水平相关影响因素的资料统计分析可筛选出显著的解释变量。该方法解决了观测数据的随机波动和误差给分析结果带来的影响,在不影响解释力度的情况下使模型大大简化,同时还可以在一定程度上避免引入过多解释变量带来的多重共线性问题;然后,结合夏普利值分解法得出各个变量对教育水平的贡献率排序,可为今后中国教育改革提供方向,提高教育改革效率,进而促进中国经济政治的发展。
1 建模方法介绍
1.1 改进的灰色模型——灰色经济计量学模型
灰色系统理论由邓聚龙教授在1982年提出的,它是部分信息已知,部分信息未知的“贫信息”不确定系统[5]。该理论在很多方面都有应用,如灰色经济学[6]、灰色水文学[7-8]、灰色地质学[9]、灰色育种学[10]、灰色医学[11-12]等。但是,传统的灰色模型的预测精度一直存在争议,很多学者通过对灰色模型的原始时间序列数据[13-14]、背景值[15]进行了改进来提高模型的解释能力。
设序列X(0)=[x(0)(1),x(0)(2),…,x(0)(n)],它的背景值为
Z(1)=[z(1)(2),z(1)(3),…,z(1)(n)]
(1)

x(0)(k)+az(1)(k)=b
(2)
为GM(1,1)模型的均值形式(EGM),EGM模型是邓聚龙教授首次提出的灰色预测模型。其白化微分方程(影子方程)表示为
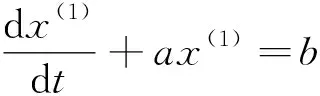
(3)

由此,可以得到EGM模型的累减还原式为

(4)
以上是传统GM(1,1)的建模过程。通过将EGM模型与计量经济学模型相结合的方法处理原始时间序列数据。灰色经济计量学模型主要分为以下4个步骤:①对理论模型进行设计;②建立均值GM(1,1)模型并获得模拟值;③对给出的模型进行参数估并对估计结果进行经济学意义和统计意义检验;④可以将模型应用于分析经济结构、预测经济发展等方面。
1.2 基于灰色经济计量学模型的夏普利(Shapley)值分解法
夏普利(Shapley)值分解法主要应用于经济活动中,研究收入不平等的贡献来源,使用此分解方法去研究教育水平方面的问题。该方法可以从两个角度——基于回归分析和基于可决系数进行分解。由于在对教育水平进行研究时,使用的方法是普通最小二乘回归,因此,采用基于回归分析分解法去研究各个因素对于教育水平的贡献率。其中,每个指标对被解释变量的贡献为

(5)
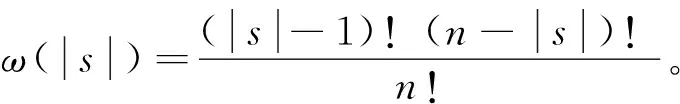
2 数据来源及变量描述
为了避免不同部门统计口径不一致带来的数据收集偏差,选取中国统计年鉴2000—2018年的时间序列数据作为初始样本。由于官网上2019年的统计数据不完整,导致很多变量的收集出现困难,故最后一年样本选取2018年的数据进行分析。
教育水平是指人们接受教育的程度,一般分初等教育、中等教育、高等教育3个等级。现有文献对于教育水平定义有以下两种。李昕东和赵翔[16]从个体出发,将教育层次换算成相应的教育受教育年限来定义教育水平;宋华盛和刘莉[17]从教育规模和教育承载力两方面来衡量中国的教育水平。基于以上研究,选取各级各类在校学生总数(edu)为被解释变量来衡量中国的教育水平。
通过对阅读的文献中教育水平的影响因素进行总结[18-20],同时为了避免遗漏变量偏差的影响,从以下4个方面选取解释变量。从人口结构特征上看, 人口性别比例、人口老龄化程度、城镇人口占比可能会对教育水平有一定的影响,所以本文选取女性占比(sex)、城镇人口比重(urate)、65岁及以上人口数(old)作为解释变量;从国家层面上看,选取国内生产总值(GDP)、国家财政支出(fin)作为一部分影响因素;从人民生活水平上看,选取文教娱乐居民支出占比(edu_rate)、城镇居民人均可支配收入(income)作为另外的解释变量;从社会层面上看,选取城镇基本医疗保险年末参保人数(insurance)度量社会基本保障程度、选择公共图书馆业机构数(library)、师资力量(teach)、各级各类学校总数(sch)、研究与试验发展经费支出(res)作为衡量学校教育质量的重要解释变量。具体的变量定义和符号说明见表1。

表1 教育水平相关变量的定义与符号说明
对表1的各个变量进行描述性统计分析,得到表2。由表2可知,所收集的2000—2018年各个变量的原始数据均无缺失,每个变量的观测数据个数(obs)为19;女性占比和文教娱乐居民支出占比的标准差较小,数据波动小;其中,国家财政支出fin最小值是15 886.5亿元,最大值达却到221 000亿元,研究对象的国家财政支出的初始年和末年数值差异大,这可能是由于近些年来政府加强了对经济的干预,也侧面反映了国家经济方面的飞速发展。促进财政支出的增长是发展中国家的首要目标,就发展中国家整个经济发展过程来说,财政始终发挥着经济发展助推器的作用。2000年至今,中国平均在校学生数达到2.5亿人之多。
图1为2000—2018年中国教育人口的时间趋势图。由此可以发现,在2001年、2012年、2013年,各级各类在校学生总数出现了下降的趋势,表明这几个时期中国的教育水平在下降。2013年的在校学生数出现严重的低谷值,但在2014年,各级各类在校学生总数迅速回升并出现前所未有的增长速度。2014年作为全面深化改革的开局之年,在这一年中,不管是社会领域的全面改革还是教育领域的专项改革都对中国的教育事业产生了重大影响。比如,国家出台了《关于进一步推进户籍制度改革的意见》,这一举措保证了随迁子女地平等受教育权力,有利于提高中国的受教育水平。从图1的时序图可以看出这其中很大一部原因是国家政府的积极应对,因地制宜。

表2 教育水平相关变量的描述性统计
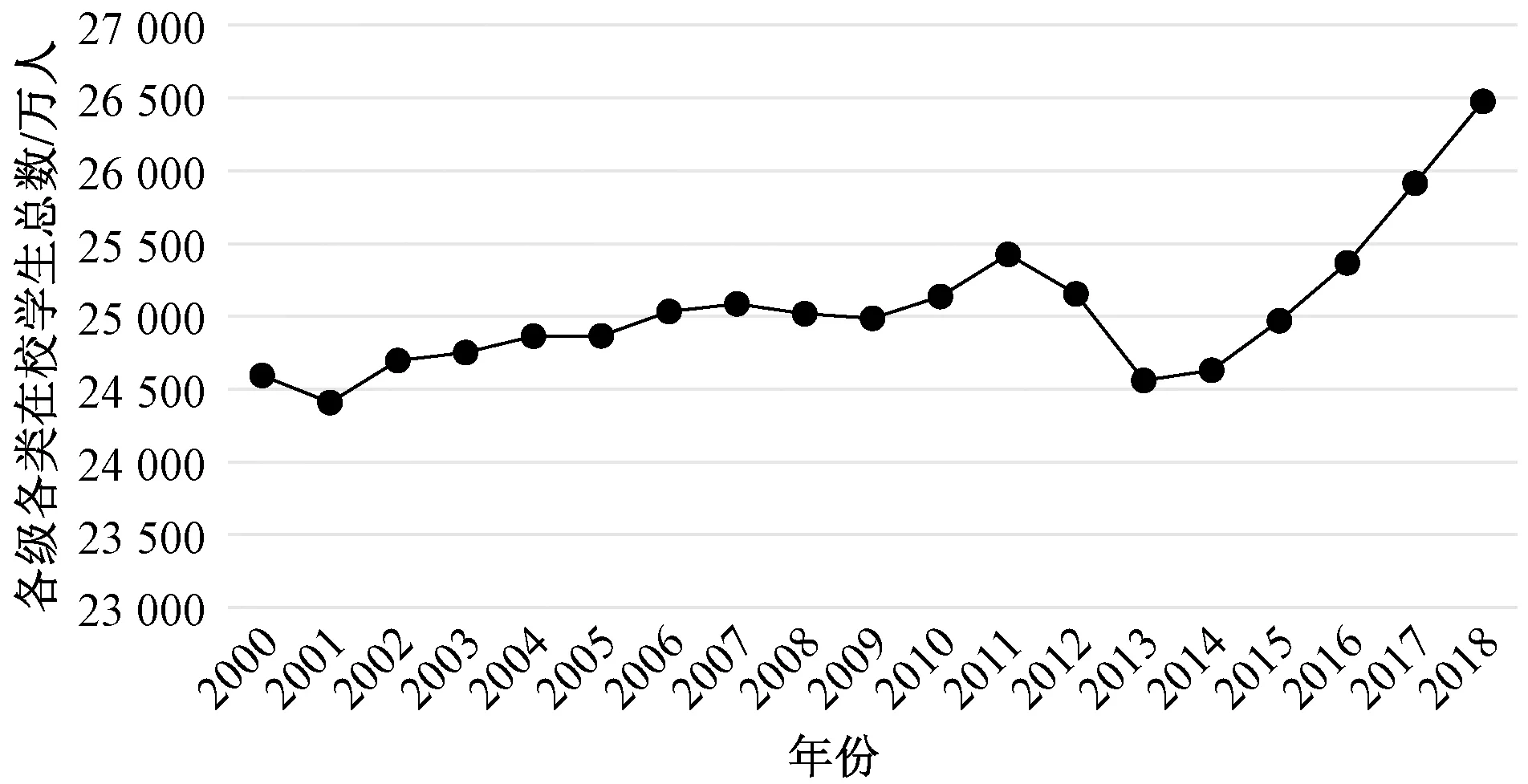
图1 2000—2018年中国受教育人口数趋势图
结果说明:虽然从2000年至今,在校学生总数量出现过几次下跌迹象,但是由于国家的及时应对,又很快回到正轨并且大体呈现上升的发展趋势。由此可以说明,全国的受教育水平越来越高,国民素质得到了显著提升。
3 实证分析
3.1 变量选取及灰色经济计量模型构建
为了准确衡量变量间的关联程度以便提高模型预测的效率,使用科学的灰色关联分析法筛选出对被解释变量edu影响较为显著的解释变量。该方法可以在不影响解释力的情况下使后续的经济计量学模型大大简化,同时还可以从一定程度上避免多重共线性问题。
表3使用灰色建模软件计算出了各变量与教育水平的绝对关联度、相对关联度和综合关联度,为了较为全面地表征序列之间的联系是否紧密,本研究将以灰色综合关联度作为标准筛选出对教育水平影响程度较大的重要解释变量。考虑到变量的多样性,选取合适的阈值0.55,剔除了与变量edu微弱关联的insurance、GDP和fin解释变量,说明insurance、GDP和fin因素在一定程度上不能解释中国教育水平的变化趋势,以往在研究此类问题未考虑国家层面的因素是可行的。

表3 教育水平相关变量间的关联度
同时,多重共线性是多元线性回归模型中最容易出现的建模问题,常常有两种表现形式。①回归方程的可决系数较大,拟合效果好,模型也通过了显著性检验,但是解释变量却出现了显著性不通过的问题;②对解释变量的个数进行改变后,其估计值波动较大,甚至可能出现回归系数的符号正负发生变化的现象。由此可知,在研究问题时,多重共线性对于结果的影响是不容小觑的。
为了避免该问题对于模型精确度的影响,模型将对被保留的变量通过研究它们之间的相似性进行重新分类,在给定阈值为0.7后发现ρ(urate,teach)=0.740 7、ρ(library,edu_rate)=0.713 7、ρ(library,teach)=0.822 6、ρ(income,old)=0.706 2、ρ(income,res)=0.860 1、ρ(edu_rate,sch)=0.715 4和ρ(old,res)=0.720 5均大于阈值,而变量sex与其余变量的相关性较弱(表4)。由表4的综合关联度将上述的9个变量分为了以下4个子类:{sex}、{urate, teach}、{library, edu_rate, sch}、{income,old,res},同时综合表3的结果,分别选择sex、teach、library和old作为代表元进入模型,分类结果表明,在消除了多重共线性和遗漏变量的影响后,人口特征(人口性别特征,人口年龄特征),师资力量与公共图书馆业机构数对中国教育水平的影响尤为显著。
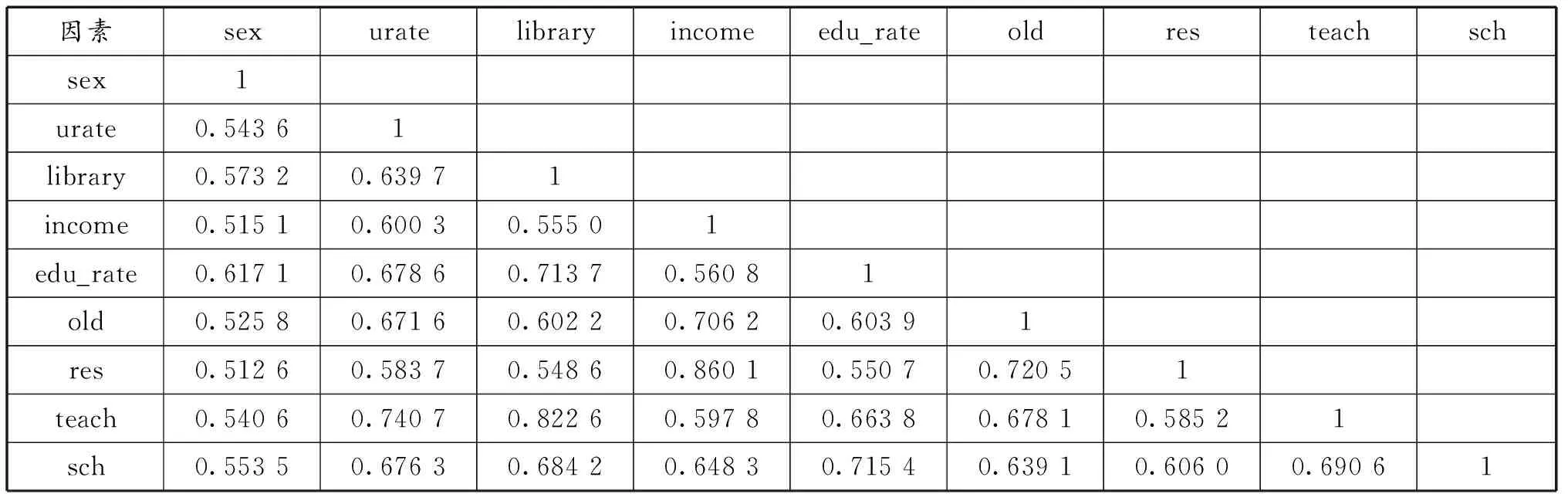
表4 教育水平影响因素间的综合关联度分析
使用均值GM(1,1)模型对筛选后的变量原始数据进行处理,用保留下来的变量的原始数据分别建立EGM(1,1)模型,将模拟值作为基础数据进入模型估计参数。解释变量的时间响应式如下:
e-0.002 4)e0.002 4(k-1)
(6)
e-0.000 5)e0.000 5(k-1)
(7)
e-0.011 7)e0.011 7(k-1)
(8)
e-0.036)e0.036(k-1)
(9)
e-0.019 5)e0.019 5(k-1)
(10)
一般情况下,最常用的指标是相对误差检验指标。表5表示各变量的平均相对误差结果。各变量的平均相对误差分别为0.010 0、0.001 0、0.011 6、0.018 8和0.009 0都在一级指标值0.01附近。所以可以判断使用EGM模型得到的模拟值精确度为一级,模拟效果非常好。变量模拟值edu1、sex1、library1和teach1适合进入计量经济学模型进行模拟。

表5 教育水平显著变量的平均相对误差
表6为灰色系统模拟值的回归结果。首先,在5%的显著性水平下P=0.000,灰色计量经济学模型通过了统计意义上的检验,经过优化后的模型BIC减少到-90.803,说明后者的模型拟合优度更高,实际值和模拟值拟合效果非常好,模型有效。在t检验中,在相同的显著性水平下,自变量也都通过了显著性检验。其中,发现65岁以上老年人系数是0.039,说明接下来的几十年里,虽然老龄化程度会大大提高,但是老龄化程度对在校学生数量的却有正向的影响而非负面影响,并且对教育水平的增长幅度改变较小。模型的回归方程可以表达为
edu1=527.668sex1+4.042library1+0.039old1-3.145teach1+ε
(11)

表6 GM模拟值的回归结果
由该模型很容易预测出2019年中国的受教育人口数(教育水平)为2.57亿人。相比较前几年的数据,可以看出中国在教育方面呈现出了更高的水平,总体看来,中国未来的教育水平也将会呈现上升的发展趋势。
3.2 模型的稳健性检验
为增强结果的稳健性,选取广义矩估计法(GMM)对灰色经济计量学模型进行稳健性检验。对于GMM方法,它具有不受模型假定的限制、所得到的参数估计值和实际值更接近的优点,相比较常用的普通最小二乘估计法(OLS),应用更为广泛,对原始数据的分布形式要求更低。为了方便计算,选取4个自变量的一阶滞后项以及时间t5个变量作为工具变量,数据的处理结果如表7所示。显然,结果与前文结论基本一致,各个变量对教育水平都有显著性影响,模型在10%的显著性水平下依旧通过了F检验。综上所述,本文的结论通过了稳健性检验,研究结论具有可靠性。

表7 灰色经济计量学模型的稳健性检验结果
3.3 基于灰色经济计量学模型的夏普利(Shapley)值分解法的应用
原始时间序列数据已经通过灰色经济计量学模型的处理,可知人口性别结构、公共图书馆数、人口老龄化和师资力量对中国在校学生数都有显著性影响。但是各个影响因素的相对权重(relative weight)较为模糊。使用Shapley值分解法来对各个变量的解释力度做更为精确的判断,以便于今后国家明确教育改革方向,提高改革的实施效率,结果如表8所示。从表8可以看出,各个变量对于教育水平的贡献率大致相同。各个变量的影响效果大小排序为library1>teach1>old1>sex1。由此可以知道,图书馆的数量和师资力量对在校生的数量相对重要的影响,将作为最显著的自变量。其中,人口结构(人口性别结构和人口年龄结构)对教育水平的解释力度稍弱。

表8 基于灰色计量学模型的Shapley值法分解结果
4 结论
教育本身是社会大系统的重要组成部分,它的发生和发展受到了社会政治经济制度、社会生产力水平、科技水平等因素的影响,同时也反作用于这些因素。中国的发展战略从“科技兴国”到“科教兴国”这一变化可以看出,教育对于科技发展有着重要影响。在科技发展过程中,教育为其提供了知识积累,同时为其培养了研究所需的人才。所以,要想发展好科技,教育因素的影响不可小觑。
研究结果进一步为中国今后的教育改革提供了启示。针对中国的教育水平现状,同时基于本文的分析结果,由此提出了以下建议:
1)当通过各变量贡献率进行研究时,发现公共图书馆的数量对在校学生数量影响力度最大。今后,在政府及学校有限的教育投入条件下,增加图书馆数量、改善图书馆服务水平相较其他提升教育质量的方式能吸引更多的学生,因此建议优先提升图书馆服务;国家还可以适当给予政府补贴,鼓励各地方政府投身于文化事业的建设。
2)由于以前学者在对研究教育水平时,并未考虑到国家层面的影响因素,本文对此进行改进,引入了相关影响因素后发现,它们由于与教育水平相关性不强而被剔除,说明国家层面的影响因素并不是关键变量。
3)本文的原始数据均来自中国统计年鉴,鉴于国情不同,所建立的模型可能会具有一定的局限性,人口性别特征、公共图书馆数量、老龄化程度和师资力量对教育水平的影响不一定可以推广到其他国家,所以国外学者在实践前还需选择合适的模型深入研究。
