基于深度残差网络的语音隐写分析方法
2021-03-18
(宁波大学信息科学与工程学院,浙江宁波 315211)
0 引言
随着互联网的快速发展,信息隐藏技术得到越来越多的关注。其中,数字隐写作为信息隐藏的重要分支,已成为信息安全领域的重要研究内容之一。隐写技术以常见的数字媒体(图像、音频等)作为载体,将秘密信息嵌入到公开的载体中,并通过载体的公开传输来达到信息隐秘传递的目的。隐写分析技术作为隐写技术的对抗技术,可视作模式分类问题,将可疑载体分类为原始载体或含密载体。
音频作为互联网中常见的数字媒体,是隐写的理想载体。目前提出的音频隐写分析方法大多基于机器学习[1],可分为3个步骤:1)数据预处理;2)特征提取;3)分类。在特征提取中,设计一个表征载体是否含有秘密信息的特征是隐写分析人员的重要研究工作。Kraetzer 等[2]提取语音的梅尔频率倒谱系数(Mel-Frequency Cepstrum Coefficient,MFCC)作为隐写分析的特征,利用支持向量机(Support Vector Machine,SVM)进行分类。Liu 等[3]通过实验发现对音频信号进行二阶求导可放大高频区域的隐写差异,并在此基础上提取的MFCC 特征(2D-MFCC)检测效果更佳;而在之后的工作[4]中,进一步提取了马尔可夫概率特征,并且分析了信号复杂度对隐写分析性能的影响。这项工作表明,相较原始音频信号,进行二阶求导所提取的特征(2D-Markov)更具表征能力。Luo 等[5]将马尔可夫概率特征与二阶导下的MFCC 结合作为融合特征,分别在不同的信号复杂度下利用集成分类器[6]进行分类训练。但是传统特征方法仍存在不足之处,其隐写分析性能依赖于特征工程,即结合隐写相关领域知识设计并提取具有有效表征能力的隐写分析特征。这要求研究人员本身具有一定的知识经验,并且设计新的特征费时费力。
近年来随着深度学习方法的快速发展,研究人员将其自主特征学习应用到隐写分析领域。在音频隐写分析领域上,Paulin 等[7]最早将深度置信网络(Deep Belief Network,DBN)应用到隐写分析任务中;但他们仅仅将DBN 用作分类器,并没有发挥出神经网络自主特征学习的能力。Chen等[8]首先提出基于卷积神经网络(Convolutional Neural Network,CNN)的端到端音频隐写分析模型(ChenNet)应用于检测LSBmatching(Least Significant Bit Matching)隐写方法,相较传统特征方法,该模型取得了比较理想的检测效果。在此基础上,Lin 等[9]的改进型隐写分析模型(LinNet)设置了四组高通滤波器作为固定卷积层对输入数据进行预处理,并且使用截断线性激活单元(Truncated Linear Unit,TLU)来对数据做截断操作,将处理后的数据输入到六组卷积模块堆叠而成的网络中进行分类训练。针对IP 语音(Voice over Internet Protocol,VoIP)语音流,文献[10-11]提出了基于长短期记忆(Long Short-Term Memory,LSTM)网络的隐写分析方法用于对抗量化指标调制方法(Quantization Index Modulation,QIM)隐写方法。在压缩域音频上,文献[12]提出了一个基于CNN 的MP3(Moving Picture experts group audio layer Ⅲ)音频隐写分析方法,并使用MP3 的量化改进离散余弦变换系数作为网络的输入。文献[13]提出了基于深度残差网络(Deep Residual Network,ResNet)的MP3 和AAC(Advanced Audio Coding)音频的隐写分析方法,并使用音频的频谱图数据作为网络的输入。
目前在WAV 格式语音上进行嵌密的隐写方法主要为最低有效位(Least Significant Bit,LSB)类型,通过隐写算法把语音信号中的最低比特位替换成密信。近些年语音隐写分析工作相对较少,且以CNN 为主要结构。针对WAV 语音隐写分析的检测性能较低的问题,为提升隐写分析检测正确率,本文通过引入残差结构和加深网络层次来提升隐写分析性能,提出了基于深度残差网络的隐写分析模型。该模型通过卷积层和残差块的堆叠来构建深度网络,以提取深层次且更有效的特征。通过实验证明,在不同密信嵌入量下,本文提出的隐写分析方法相较之前的传统提取特征方法以及深度学习方法在检测效果上均有比较明显的提升。
1 相关工作
1.1 数据预处理
隐写分析任务与计算机视觉、图像分类等任务有所不同。隐写分析需要提取的特征并非来源于图像或音频样本本身的内容,而是来源于由密信嵌入载体所引起的隐写噪声。但隐写噪声极其微弱,若直接将样本原始数据作为网络的输入,隐写分析检测效果可能会受到原始内容所带来的负面影响。为解决这个问题,研究人员先对样本的原始数据进行预处理。例如在图像隐写分析工作[14-15]中,通常先对原始图像信号进行高通滤波处理,再对得到的残差信号进行特征提取或输入到神经网络中。其中,最令人熟知的是空间富模型(Spatial Rich Model,SRM)方法[14]设计了78 组高通滤波器,目的是从更多的残差信号中提取更加丰富的隐写特征。
音频隐写分析工作同样是先利用高通滤波器计算原始音频的残差信号,再进行特征提取。传统特征方法[3-4]中通过实验发现音频信号的二阶导数能够放大其音频区域的隐写差异。文献[8]同样为其隐写分析模型设计了一个二阶差分的滤波器,其参数固定为(-1,2,-1)。而文献[9]通过实验分析,差分阶数越高,隐写信号与原始载体之间的差异越明显。因此结合富模型思想,设计了一组基于混合阶数差分的预处理高通滤波层。该高通滤波层由4个1×5的卷积核组成,参数如下D1至D4所示:
D1=[1,-1,0,0,0]
D2=[1,-2,1,0,0]
D3=[1,-3,3,-1,0]
D4=[1,-4,6,-4,1]
这些工作都通过实验证明,先对原始音频信号进行数据预处理能明显提升最终的检测效果。本文沿用文献[9]提出的基于混合阶数差分高通滤波层用于对输入的音频原始信号作预处理,以提取更丰富的隐写噪声相关的信息。
1.2 残差网络
卷积神经网络随着网络深度提升存在梯度消失/爆炸或网络退化等问题。深度残差网络[16]引入快捷链接(shortcut connection)来解决退化问题。
如图1 所示,H(x)为CNN 中若干非线性网络层的目标映射,其中x为网络的输入。残差网络则需要去拟合残差映射F(x):

当残差模块输入与输出的维度相同时,通过捷径连接后的网络输出为:

从表达式来看,网络满足残差映射H(x)比直接映射更容易。因此,残差网络使模型参数进行参数优化更容易实现,并且网络检测效果可以随着网络层数的增加而提升。

图1 卷积模块与残差模块的结构Fig.1 Structures of convolutional unit and residual unit
隐写分析任务为了检测秘密信息的存在,需要正确区分目标音频x[17]:

其中:c为载体音频信号,0 为没有秘密信息;m表示嵌入密信引起的弱信号,且m属于(-1,0,1);cover 表示原始语音,stego表示嵌密语音。当音频信号输入到残差网络中,网络的残差映射F(x)满足小信号的0 或m,因此可以被残差模块有效建模。当通过多个堆叠的残差模块,隐写引起的弱信号可以被很好地保留和强化,这使残差网络非常适用隐写分析工作中。
图像隐写分析工作[18-19]提出基于残差网络的图像隐写分析模型,并且利用实验结果证明残差网络检测效果比卷积神经网络更优异。目前针对非压缩域音频的工作[8-9]中的隐写分析模型是基于卷积神经网络提出的。结合残差模块思想,该工作在隐写分析检测性能上仍具有进一步提升的空间。与卷积神经网络相比,利用残差模块构建更深的网络可以帮助提取相对更加丰富复杂的含隐写噪声的特征属性,从而提升隐写分析正确率,因此,基于深度残差网络的隐写分析方法其检测性能会更优异。
2 隐写分析模型
为了将残差网络应用到音频隐写分析工作中,本文根据音频隐写分析的相关过程设计了对应的网络结构。本章将详细介绍隐写分析模型的结构以及其他结构设计的相关细节。
2.1 总体结构
本文提出的隐写分析模型具体如图2所示,实现了端到端的音频隐写分析检测。其中,卷积层中的参数分别代表该层输出的通道数、卷积核的尺寸以及该层所使用的激活函数。而在ResBlock中的参数代表该残差模块内的卷积层F的数量(F见图3)。输入音频信号长度为16 000×1,“size:m×n”代表该层输出的维度。该模型首先利用高通滤波层对输入音频进行卷积操作得到残差信号,该高通滤波层由一至四阶差分组成且参数已固定。紧接着,利用TLU激活函数对得到的残差信号进行截断处理,再输送到中间网络层进行特征提取。然后,通过全局平均池化层将输入的特征数据转换成特征向量。最后,送入二值分类器中并输出概率,该分类器由一个全连接层与Softmax层组成。

图2 基于深度残差网络的隐写分析模型Fig.2 Steganalysis model based on deep residual network
其中,中间网络层分为三个部分:第一部分由三层纯卷积层组成,不设置激活函数与池化层,因为过早使用激活函数会屏蔽残差信号中的部分隐写噪声;第二部分由带有激活函数的残差块ResBlock1 组成,仍不设置池化层;第三部分则由带有激活函数与池化层的残差块ResBlock2 组成。池化操作属于低通滤波,隐写分析任务与图像识别等不同,池化可以增强数据本身内容同时也会抑制隐写噪声,过早使用池化层对隐写分析是有危害的。为了避免隐写噪声损失,只有ResBlock2设置了池化层。
2.2 卷积层设置
本文模型包含两种卷积层,卷积核的大小分别为1×3 和1×1。所有卷积层的卷积核的大小与数量在图1 有所标识。除图2 的ResBlock2 中已标明的步长,其余卷积层步长均设置为1。为避免卷积使矩阵的尺寸发生变化,在矩阵边缘进行全0填充。
为了卷积和池化操作能保留更多的特征信息,引入金字塔模型来设置卷积层的核数量。当神经网络设计过深,如本文设计的残差网络所需要的参数过于庞大,利用1×1 卷积核代替1×3 来扩增数据通道数,可以有效降低网络参数并且避免参数过多引起的训练过拟合。
2.3 残差模块
本文模型中包含两种残差模块,其区别在于模块输入和输出的维度是否相同,因此存在两种捷径连接方式——恒等捷径映射(Identity Shortcut)和目标捷径映射(Projection Shortcut)——分别对应图3 的ResBlock1 与ResBlock2。在ResBlock1 中,经过两层卷积操作后,输入与输出维度仍然相同,直接利用恒等捷径连接将输入的映射与输出结果相加。数据维度m×n的特征数据经过ResBlock2 卷积以及池化操作后变成m/2 × 2n,则需要通过目标捷径映射将输入的维度映射成与输出维度相同。
ResBlock1包含两个卷积层,卷积核大小皆为1×3,并利用捷径连接直接构成残差模块;而ResBlock2利用1×1卷积层与平均池化层使数据维度发生改变。因此在捷径连接中加入一个卷积层,使通过捷径连接的数据维度与残差映射的数据维度相同。该卷积核大小设为1×1,步长为2。实验中同样在表1展示了目标捷径连接1×3卷积核的比较效果。
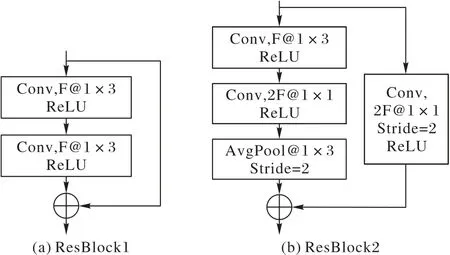
图3 ResBlock1与ResBlock2的结构Fig.3 Structures of ResBlock1 and ResBlock2
2.4 激活函数
激活函数是向神经网络中引入非线性因素的。神经网络通过加入激活函数,可以拟合出各种曲线,来提升复杂特征的表征能力。常用激活函数有Sigmoid、Tanh、ReLU(Rectified Linear Unit)等。此模型所有激活函数设置为ReLU,同样在表1 中比较了ReLU 与Tanh 激活函数的检测效果。设输入为x,则激活函数Tanh如式(4)所示,ReLU如式(5)所示:

但是音频信号与图像存在一定差别。音频信号中存在一定的负值数据,秘密信息通过隐写算法同样会嵌入在此负值信号内。而根据ReLU 激活函数的公式可知,该激活函数恰恰抑制了音频信号中的负值数据。这导致存在于负值数据中的隐写噪声丢失,影响检测性能,因此网络第一部分并不设置激活函数。为此代替性地引入了截断线性激活函数[16],定义如式(6)所示,并将其设置在高通滤波层后的第1 个卷积层中,目的是更好地保留隐写噪声相关信息,并且能抑制残差信号中影响隐写分析性能的数据。
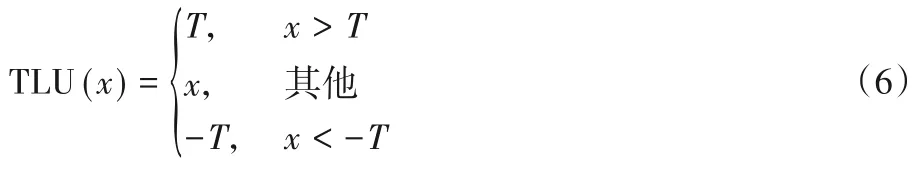
其中:T表示设定的阈值,且T>0。此实验中T设为3。
2.5 其余部分结构设置
为减少计算资源和神经网络所需要的参数,通常在卷积层后加入池化层来减小先前特征映射的空间,这可以保留特征数据的主要属性并且降低网络训练的参数。池化层通常有最大池化层与平均池化层。本文模型在ResBlock2 中设置平均池化层,用于特征数据的降维并提取足够的统计特性。在最后的卷积层设置全局平均池化层(Global Average Pooling),可以将输入大小为1 000×512的特征数据采样至1×512。
全连接层功能与残差模块的捷径连接相似,有助于模型收敛,并减少模型需要学习的参数,并且全连接层起到将学到的特征映射到样本标记空间的作用;但设置多层全连接层会因为所需参数过多,训练时导致模型过拟合。因此本文模型只单独设立一层全连接层,并与Softmax 函数组合成模型最后的分类器。
3 实验及结果分析
3.1 实验设置
本文实验所使用的音频数据均来源于TIMIT 语音库[20],该语音库由630 个不同说话人的6 300 段语音组成。语音格式为WAV,采样频率为16 kHz,量化精度为16 bit。考虑计算能力的限制,实验中将音频分割成时长为1 s的音频片段数共计15 000。然后采用两种隐写方法Hide4PGP(Hide 4 Pretty Good Privacy)隐写工具[21]与LSBmatching[22]隐写算法将随机生成的密信嵌入到原始样本中,嵌入率为1、0.5、0.2、0.1 bps(bit per sample)。
实验过程中所有网络使用基于TensorFlow 后端的Keras深度学习框架,并配置了NVIDIA GTX1080Ti。训练之前,将样本随机划分成三部分,其中,12 000个载体/载密对数据作为训练集,1 500 对作为验证集,剩余1 500 对作为测试集。实验中网络所有参数权重为Xaiver 初始化,使用Adam 优化器,学习率初始化设为1E-4,批处理大小设为64,并使用二元交叉熵作为损失函数。为评估模型的检测性能,本文采用测试集数据上多次相关实验的平均正确率(Accuracy)作为评价标准。
训练过程中,每经过一个训练循环(epoch),即每完整训练完一次训练集,就会将训练集数据的次序打乱一次;并且使用早停策略,监测验证集损失,若迭代2 个周期损失没有减少,则当前学习率减半;若迭代5 个周期仍未减少,则停止网络,并保存最优训练模型。
3.2 不同网络变体的性能比较
为了使设计的模型获得最优的效果,在实验过程中对网络结构做了大量的实验与调整。在Hide4PGP 嵌入率为1 bps的情况下,表1 展示了不同网络结构的隐写分析正确率。其中,#1 是本文提出的网络结构,#2 至#7 分别是不同的结构调整。从表1 结果可知,本文提出的网络结构能达到最优的隐写分析性能,检测正确率达到91.75%。
#2、#3、#4 属于基础的网络调整,本文提出的网络结构与之相比都能有4~6 个百分点的检测正确率提升。另外,#5 结果证实目标捷径连接中使用1×1 卷积核的效果比1×5 卷积核的检测效果要好,并且还能降低捷径连接的参数。#6 证实引入截断线性激活函数是一个正确的选择。批标准化层(Batch Normalization,BN)在图像相关的网络结构中被广泛使用,因此在实验中同样在每个卷积层后添加了BN层进行对比实验。经实验发现,BN层能加速网络训练,使模型迅速收敛,但是#7的网络结构中引入BN 层在检测效果上并没有很大的提升。综上所述,本文最终选用的是图2所示的网络结构。
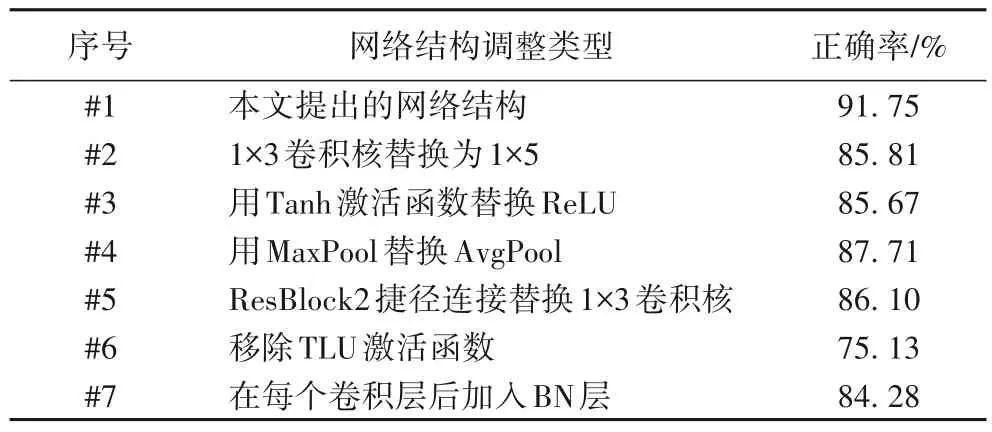
表1 不同网络结构的检测正确率Tab.1 Detection accuracies of different network structures
3.3 不同隐写分析方法比较
在此实验中,共有4 种隐写分析方法作比较,包括传统特征方法2D-MFCC[3]、2D-Markov[4],以及最近的基于卷积神经网络的方法ChenNet[8]、LinNet[9]。这些隐写分析方法在不同嵌入率下的检测结果如表2所示。

表2 不同隐写分析方法的检测结果比较Tab.2 Comparison of detection results of different steganalysis methods
在两种隐写方法的不同嵌入率下,本文模型检测性能均有最佳的表现,检测正确率比LinNet 提升了近3 个百分点,相比其他方法提升效果尤为明显。在Hide4PGP 0.1 bps嵌入率下,虽然检测正确率由于密信嵌入引起的改动太小只有67.21%,但比LinNet 提高了7 个百分点。从实验结果可以看出,利用残差模块构建更深层次的网络结构相较基于CNN 的隐写分析模型具有更好的检测性能。
为了更直观地评价本文提出的隐写分析模型的检测效果,图4 给出了Hide4PGP 和LSBmatching 隐写方法在0.5 bps嵌入量下的受试者工作特征曲线(Receiver Operating Characteristic curve,ROC),并计算了ROC 曲线下面积(Area Under Curve,AUC)。ROC 有助于比较不同分类器的相对性能,曲线越靠近左上角,AUC 值越接近于1,说明分类模型的性能越好。从图4 中可以看出,本文提出模型的ROC 曲线最接近左上角,其AUC 值大于LinNet与ChenNet的,进一步证明了本文模型隐写分析性能的优异。图4中random 表示模型随机猜测,没有预测价值。
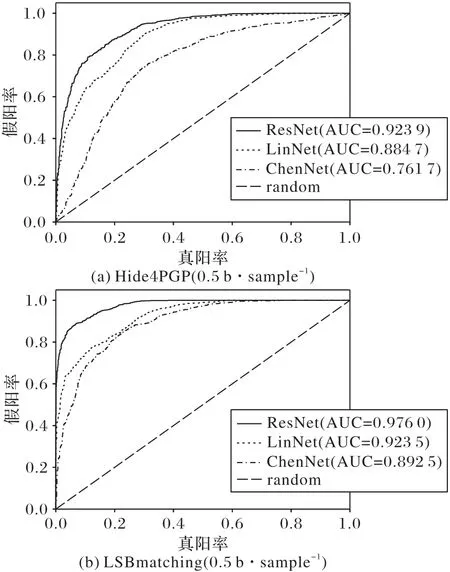
图4 三种隐写分析方法的ROC曲线Fig.4 ROC curves of three steganalysis methods
为了进一步评估本文提出的模型与LinNet 的性能,图5给出了二者在0.5 bps LSBmatching 训练过程中的训练集以及验证集的正确率曲线。从图5 中可以看出,本文提出模型网络结构层次更深且包含更多参数,训练前期也能够快速收敛,与LinNet保持一致;并且,随着epoch的增加,两个网络的训练正确率都在稳步提升;当epoch 达到60 时,LinNet 的训练曲线趋于平稳,而本文模型仍有上升趋势,最终的检测效果要优于LinNet。

图5 本文模型与LinNet的训练与验证正确率曲线Fig.5 Training and validation accuracy curves of the proposed method and LinNet
4 结语
目前语音隐写分析工作的检测准确率较低,本文结合深度残差网络提出了一个端到端的语音隐写分析模型。实验结果表明,在检测不同嵌入率的Hide4PGP 与LSBmatching 隐写方法时,同传统方法2D-MFCC、2D-Markov 和基于卷积神经网络的音频隐写分析方法ChenNet、LinNet 相比,本文所提出的隐写分析方法在检测正确率都有明显提升。以此证明通过残差模块构建更深的网络层次可以提升隐写分析性能。但本文模型仍有不足,TLU 函数也抑制了语音信号中幅值超过阈值的部分隐写痕迹,损失部分检测精度;且针对存在于语音高幅值区域的隐写痕迹,CNN 又难以有效处理数据并提取特征。希望在未来的工作中进一步改善模型,提升语音在低嵌入率下的检测正确率。
