基于日志结构合并树的轻量级分布式索引实现方法
2021-03-18
(哈尔滨工业大学计算学部,哈尔滨 150001)
0 引言
如今,随着移动互联网等技术的普及,数据量呈爆炸式增长。大规模数据对数据管理提出了迫切的需求,传统的数据库对于超大规模数据存取的效率低,难以支持高并发访问。为此,分布式数据库应运而生。但是这类数据库也存在着对数据查询访问不够灵活的缺点。分布式数据库系统通常根据主键按照一定规则将数据进行划分,将数据片段冗余地存储在集群中的计算节点上,同时在主键上构建索引,来支持高效的主键查询。而针对非主键属性列的查询,系统无法确定数据的分片信息具体存储在哪个计算节点上,只能通过全表扫描进行查询,效率较低。所以,如何提升非主键查询效率成为分布式数据库系统的亟须解决的问题。
现有的分布式索引方案都拥有各自独特的构建方式,大致可以分为三种类型:一是通过改造系统的源码,重新设计交互逻辑,实现二级索引(SecondaryIndex,https://github.com/Huawei-Hadoop/hindex)。这种方法对开发人员的要求很高,并且很难跟得上系统版本更新的速度,用户在使用时需要将自己的数据重新导入到索引系统中,用户体验性差;第二种是基于MapReduce 并行计算框架,为查询数据创建map 映射表,并在客户端实现对map 映射表的查询[1]。由于NoSQL 数据库在进行跨行的事务时,无法保证原子性,当系统写入数据后,索引尚未更新成功前,系统发生任何错误,都会造成索引和原始数据不一致的后果。但是现有的MapReduce方案没有考虑数据的更新情况,所以这种方案只能适用到一些离线应用中;第三种方案是预设好索引的结构,将索引表和数据表同时创建[2]。由于后续无法添加索引,所以初始索引要对所有的非主键列建索引,这样就会造成极大的空间开销,使用起来很不灵活。
综上,现有的方案无法同时满足这三点要求:针对已有的海量数据高效地创建索引;用户可以将方案快速地应用在自己的集群中;兼顾磁盘中基线数据索引构建和内存中随时发生的增量数据更新。
针对上述问题,提出一种基于LSM-Tree(Log Structured Merge-Tree)的轻量级分布式索引实现方法SIBL(Secondary Index Based LSM-Tree),将MapReduce 并行计算框架和LSMTree思想相结合,对非主键属性列建立索引,把复杂的非主键查询问题转化为主键查询问题。从而提高非主键属性的查询效率。
首先,LSM-Tree是非常优秀的数据检索引擎,由一个驻存在内存中的树结构和多个位于磁盘上的树结构组成。分布式数据库采用这种分层的思想,将数据分成两部分来存储,内存中的数据memStore 相当于LSM-Tree 中的C0Tree,磁盘中的数据StoreFile 相当于LSM-Tree 中的C1Tree 和C2Tree,当内存中的数据量到达阈值后顺序写入磁盘,数据更新只发生在内存中;磁盘中的数据会定期地整合,避免不必要的I/O,可见基于LSM-Tree 的索引方法可以极大提高系统的写入性能,同时让索引更高效。
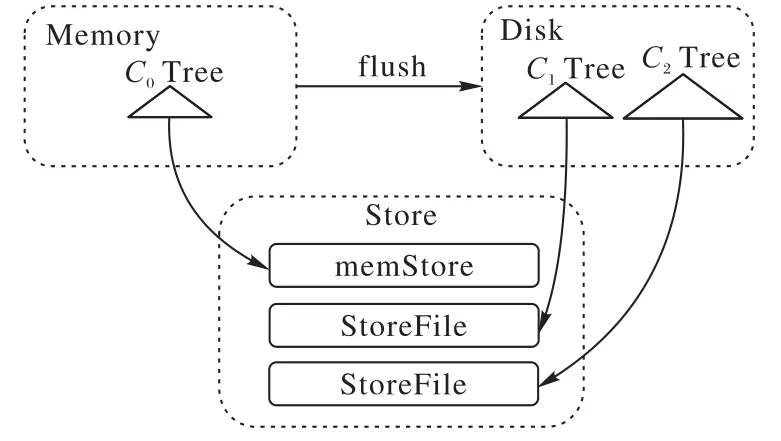
图1 LSM-Tree与Store结构对应图Fig.1 Structure correspondence between LSM-Tree and Store
SIBL 采用MapReduce 框架的并行计算快速地对数据进行批量构建。通过调用系统接口,创建索引表,将原数据表的非主键列映射到索引表的主键,查询频率较高的列附加在索引表的value 中,同时提供单列索引和联合索引两种构建方式。用户还可以根据需求自由选择索引构建方案:对已有数据构建索引或者将索引和原数据表同时构建。
本文的主要贡献如下:
1)设计了通用的SIBL 索引结构,及分布式索引构建算法,在不侵入分布式系统源码的前提下实现轻量级索引方案,满足用户既可以在生成用户表的阶段同时创建索引,又可以对现有用户表构建索引的需求。
2)针对分布式索引区间的划分,提出基于等距取样的索引区间划分算法,实现索引的均匀分布;优化了索引的查询算法,避免回表查询,支持多个非主键属性列联合查询,提高查询效率。
3)在HBase数据库上与华为HIndex方案进行多组对比实验,结合实验数据,验证了本文所有算法的有效性和正确性。
1 相关工作
为了使分布式数据库支持更丰富的查询功能,提高数据库存储数据的查询效率,国内外对分布式数据库的索引技术开展了大量的研究。目前,绝大多数分布式数据库是采用key-value 存储模型来存储数据,所以典型的分布式索引方式是以主键索引为主,常见的有Hash 索引、B+树索引[3]等,为了提供更丰富的查询能力,一些数据库建有二级索引。
HIndex方案是2012年华为公司在HBTC2012上公布的二级索引方案。整套方案基于HBase-0.94.8 系统实现,对HBase 系统的源码进行改进。由于版本的限制,用户很难将HIndex 方案整合到自己的集群中,并且,HIndex 是在系统创建用户表的同时创建索引表,故不支持动态的添加或删除索引,用户无法为已经存在的数据表创建索引。同时,为了确保索引和数据能够始终存储在同一个节点上,HIndex 禁止了局部索引文件的操作,因此,HIndex无法满足整个系统的负载均衡策略,并且没有良好的可扩展性,而这些特性正是分布式系统所必须拥有的。在查询数据时,系统需要访问所有的Region,耗费资源,严重降低系统的查询性能,而这正是本文在研究中考虑到的问题。
分片位图索引方案[4]利用局部索引来简化索引的维护,提高查询效率。实现方式是将过滤条件生成为条件位图,与所有计算节点维护的局部位图进行位运算,但由于查询时需要访问所有节点,也会造成了一定的资源浪费。用户在使用时需要为局部索引生成局部位图,大大增加了任务量。
CCIndex[5]是由中科院科研团队提出的全局索引方案。该方案将需要查询的数据的详细信息一同存入全局索引中,从而实现基于非主键属性列多维度范围查询索引。主要思想是设置数据的多个副本,根据每个副本上的不同非主键列建立聚簇索引,并将大量非主键查询中的随机读取转换为基于索引的顺序扫描,优势是可以极大提高数据的查询效率,缺点是多个副本的数据存储会造成很大的空间开销。
Diff-Index[6]是一种全局索引方案,致力于解决索引与数据一致性问题。作者认为在不同应用中对索引和数据的一致性的要求也不尽相同,应该允许索引和数据异步更新的情况存在。针对不同的一致性需求,Diff-Index 在HBase 上实现了不同级别的索引一致性维护方法。该方案忽略了对提升非主键属性列的查询性能的研究。
王文贤等[1]针对海量矢量空间数据的存储和查询问题,提出了一种利用MapReduce和压缩Hilbert R 树算法并行建立Hilbert R 树索引的方法,提高了空间矢量数据的检索效率。但这种方案仅在全文检索这种时效性要求不高的情况下适用,没有办法满足索引的实时构建。
Zhang 等[2]使用MapReduce 并行计算框架,对海量数据的KNN join 进行高效处理,在reduce 阶段利用R 树对局部数据构建索引,从而提高了KNN 连接的速度,但这种方法由于没有全局索引,检索时会消耗部分搜索局部索引的时间。
2014 年,Alsubaiee 等[7]提出的基于LSM-Tree 的混合异构索引通过bulk-loading 方式可以兼顾基线数据和增量数据更新的问题,但是只能用于AsterixDB[8]系统,并且bulk-loading方式的索引组件由多种数据结构组成,大大增加了索引维护和系统负载均衡的难度。
2 基于LSM-Tree的分布式索引的构建
2.1 索引的结构
针对非主键属性查询效率低的问题,构建辅助索引[9]是一个很好的解决方案。因而,本文基于LSM-Tree 架构的索引方法SIBL,通过建立辅助索引,并将索引数据表看作普通的数据表存储在数据库中,从而实现高可用性和高扩展性的目标。将需要查询的非主键属性列和原数据表的主键作为索引表的联合索引,同时可以添加一些附加列信息。
SIBL 索引信息和存储的原数据一样都是基于LSM-Tree存储架构的,所以当Mem-SI 的数量达到阈值时,会flush 到磁盘中的SST-SI进行保存,如图2所示。
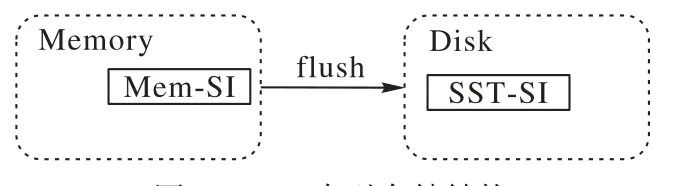
图2 SIBL索引存储结构Fig.2 SIBL index storage structure
之所以采用这种索引组织方式,因为其有以下三点优势:
1)继承分布式数据库的读写分离特性。在基线数据sst1…ssti构建SST-SI的过程中,原数据更新引发索引更新的操作维护在内存中的Mem-SI上,进而更好地维护数据和索引的一致性。
2)当数据发生更新时,只需要在内存中维护索引的增量,减少了更新索引造成的系统I/O。
3)索引数据和原数据表数据的存储管理保持一致,分布式数据库可以用原来管理原数据的方式来管理索引数据,使得索引的高可用性得以保证。
定义1通用的SIBL索引结构:

SIBL 索引由内存中的增量索引Mem-SI 和磁盘中的基线索引SST-SI 组成,增量索引和基线索引的主键是需要查询的列和原数据表的主键相结合的联合主键。Value 存储的是查询频率较高的列值。这样的结构可以将不同列的索引存放在HBase的同一张表中,减少了表的数量。
由于提出的算法最终要在HBase数据库上实现并验证其有效性,这里通过一个商品信息示例来分析SIBL索引结构的优势。
表1 描述的是一个商品信息的HBase 数据表,主键为Item Key,表2 给出了HBase 索引表示例,当需要根据商品名称查询价格时,可以将“name”列和原数据表的主键“Item Key”作为辅助索引表的联合主键。在实际应用的过程中,还可以将列名“name”映射到单个字母“n”。将需要查询的“price”作为附加信息存储在Value。
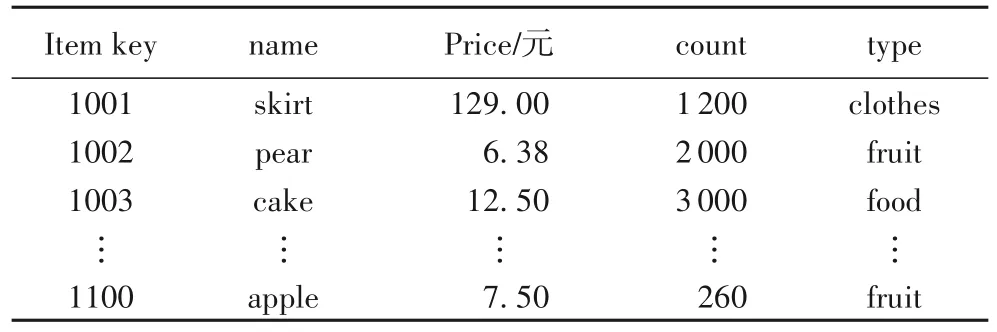
表1 HBase原数据表示例Tab.1 Example of HBase original data table

表2 HBase索引表示例Tab.2 Example of HBase index table
1)将列名“name”映射到单个字母“n”,可以大大减少系统存储索引表的主键的空间开销,实现轻量级的索引。
2)将Item key 存储到索引表的主键中有两个作用:一是保证了索引表主键的唯一性原则,避免因为主键重复而丢失数据;二是为用户提供了被索引记录的地址信息,方便用户获取被索引列的整条记录。
3)用户在查询“price”时,可以在辅助列中直接获取信息,进一步提高了辅助索引的查询性能。
2.2 索引构建算法
LSM-Tree[9]的显著特点就是读写分离、批量更新。基于这种思想,本文将分布式系统中的数据划分为两部分:存储在内存中的增量数据和存储在磁盘中的基线数据。提出一种先合并数据后构建索引的策略。内存中的数据增量会批量地写入磁盘中,与基线数据合并。在基线数据和增量数据合并完成后,再构建基线数据的索引。在数据合并的时间段内,在内存中对数据的增量构建索引。轻量级的分布式索引构建采用了MapReduce 框架,将原数据表的信息作为map输入,接下来为每个输入按照SIBL 索引结构格式生成对应的索引数据,将索引数据存储在系统中。为了提高创建速度,可以同时创建多个线程并发的执行。
如算法1 所示,SIBL 索引构建算法可以划分为3 个步骤:数据批量更新、局部索引构建和索引区间划分。首先启动批量更新过程(第1)~4)行),内存中的增量数据不断地合并到磁盘中,生成新的基线数据sst(S,V1)。需要注意的是,增量索引不做批量更新。数据批量更新结束后,反馈给主节点,数据更新后的版本记为V1。然后进行局部索引构建阶段(第5)~8)行),同样将信息反馈给主节点。生成的索引集合记为:F′(I) →{I1,I2,…,IK}。最后是索引区间的划分阶段(第9)行),将在2.3节详细讨论。
算法1 SIBL索引——整个构建过程的算法。
输入:表T的数据集S;
输出:索引I。

算法2 描述了局部索引的构建过程。对sst(S,V1)中的每一行数据执行一次map 操作(第3)行),将原数据表的主键映射成由非主键属性列和原数据表主键相结合在一起的新主键。即(k1,k2,…,ki,r1,r2,…,rj),i=1,2,…,j=1,2,…映射成(rm,k1,k2,…,ki),i=1,2,…,1 ≤m≤j。然后对索引主键进行排序(第4)行),最后将排序好的索引写入磁盘,成为局部索引local_index(第6)行)。
算法2 SIBL索引——构建局部索引过程的算法。

2.3 基于等距取样的索引区间划分算法
索引区间的划分决定着索引在系统中分布是否均匀,影响着整个系统的负载均衡和查询效率。划分索引区间的首要条件是要获取到全部的索引信息,一个直接的方法是将索引数据全部存在一个节点上进行排序,再将排序结果平均分配到其他节点,来保证每个索引分片的大小基本相等。但是在实际应用中,索引的数据量十分庞大,单单靠一个计算节点是无法完成排序工作。可见,索引区间划分的难点在于无法获取全部的索引信息。为了解决这个问题,本文提出了一种基于等距取样的索引区间划分算法,来计算索引表划分的范围区间。
等距取样的思想是对于已经排好序的局部索引数据,每间隔一定的距离d,就执行取样操作,把取样结果写入结果集。基于等距取样的索引区间划分算法一共有两次取样过程。第一次在索引数据上进行取样,并将结果返回给主节点,经主节点排序后,对排序结果执行第二次取样操作,得到划分区间的序列并生成索引区间,然后根据局部索引和划分区间序列的交集尽可能多的规则,将索引数据分配给合适的节点。这样做代替了将索引数据全部存在一个节点上进行排序再划分的方法,即使数据量非常大,也可以高效地实现索引区间的划分,使索引数据均匀分布,满足系统的负载均衡策略。
定理1记数据分片数量N,索引的分片数量N′,每个数据区间长度为L,当参数Q←N′-1 时,取样的距离也为d←N′-1。
下面展示推导过程:
第一次等距取样后得到的结果个数为:

第二次等距取样后得到的结果个数为:

由式(1)和(2):

根据定理1,基于等距取样的索引区间划分算法的伪代码如算法3 所示,4)~7)行描述的是第一次取样阶段,对于所有局部索引,按照间隔d取样,将取样结果返回到major 节点并排序;8)~12)行描述的是第二次取样阶段,对于主节点排序好的结果,按照参数Q进行取样,得到s1,s2,…,sP序列;第13)行使用s1,s2,…,sP序列将索引数据切分成索引区间;伪代码第14)行将索引区间分配给合适的节点;15)~19)行描述的是分配策略,如果索引区间和节点保存的局部索引有交集,则把这个区间分配给该节点。
算法3 基于等距取样的索引区间划分算法。


3 分布式索引SIBL的应用
用户在使用索引SIBL 时只需要两步即可配置完成:第一步将分布式集群的配置文件添加到index.properties 文件中,以HBase数据库为例,从配置文件中获取zookeeper地址,添加到index.properties 中;第二步将Maven 项目编译打包上传到集群中运行,即可成功创建索引文件,执行相应的查询操作。
在普通索引方案中,当需要以非主键索引列sk 为查询条件查询记录A时,如果该属性列已经建立过索引,则直接对相应的索引表进行的前缀查询,得到对应的pk,再根据pk返回到原数据表查找与之对应的整条记录A[10]。需要进行两次远程调用(Remote Procedure Call,RPC)协议通信,而本文提出的基于冗余列的查询方法就是在建立索引文件时,可以将一些用户自主设定的查询比较频繁的列附加在索引文件内,称作冗余列。在通过非主键属性列sk 进行查询时,如果该属性列已经建立过索引,直接在对应的索引文件中查询到相应的索引行,要查询的信息如果直接在冗余列中,则直接读取并返回结果集。虽然冗余列会占用存储空间,但是对于高可扩展性的分布式集群来说,用存储的开销来换取查询性能的提升,是很值得的[11-12]。在实际应用的过程中,可以根据具体情况来自主选择冗余列[13]。
查询处理算法的伪代码如算法4 所示,第1)行描述的是通过在索引表查询非主键属性sk,将得到的一些结果保存为tmp_result;第2)行描述的是对tmp_result中的每一条数据执行下面的if操作;第3)~6)行中,如果查询的列在冗余列中,就把该列值添加到结果集result_set中,返回给客户端。
算法4 基于冗余列的查询算法。

4 实验与结果
4.1 实验环境和数据集
实验环境搭建在三台本地电脑的虚拟机中,通过ssh 通信,完成HBase分布式系统的搭建[14-15]。
硬件配置:本地电脑CPU Intel Core i7-8565U 1.8 GHz;内存8.00 GB。在环境搭建的过程中要充分考虑软件版本的兼容性。软件版本的选择如下:虚拟机VMware workstation 15、Linux centos 7 64 位、Java 1.8.0_131、Hadoop-1.1.0、HBase-0.94.8、Zookeeper-3.4.10、连接工具-X shell 6、实验的数据集采用某电商网站对不同年龄不同职业等因素对的购买力影响程度脱敏后的调查数据。整个数据集共有1 040 000 条,包含10 个不同的属性,ID(脱敏过的用户编号)、Name(姓名)、Gender(性别)、Age(年龄)、Occupation(职业)、City_level(生活的城市水平)、Consumption_level(消费档次)、Shopping_level(购物深度)、cms_segid(电商网站的微群ID),其中ID为主键。系统构建索引分两种情况。一种是单列索引,另一种是组合索引。该数据集主要用来评估这两种情况下索引的查询性能。同样与华为HIndex 二级索引方案进行多组对比实验,得出实验数据,进行分析。
4.2 结果与分析
4.2.1 索引构建性能
本文提出的SIBL方法实现了两种构建索引的途径:第一种是在用户表创建时,针对相应的非主键属性列构建对应的索引表;另一种,是对已经存在的用户表,后续增加相应的索引表,即运行IndexBuilderFromFile 类为已经存在的用户表创建索引表。这里对索引的构建性能进行评估,即评估索引构建需要的时间开销和空间开销。这里采用YCSB测试工具,在集群上运行如下指令,bin/ycsb load hbase094-P workloads/workloada-p threads=10-p table=testtable-p columnfamily=family-p recordcount=7 000 000-s,生成7 000 000行测试数据,数据集大小为0.9 GB。每条数据由非主键列field0~field9组成。然后采用IndexBuilderFromFile 类为非主键属性列field4构建索引,并导入HBase 的索引表test_idx_field4 中,记录导入时间。重复以上操作,将recordcount更改为11 000 000行和12 400 000行,构建对应的非主键属性列field4索引表,分别记录数据集的大小、用户表导入HBase的时间与构建索引时,索引表和用户表同时导入HBase中的时间。

表4 构建索引前后导入时间对比Tab.4 Comparison of importing time before and after index construction
分析表中数据可以得出,索引表和用户表同时导入时间分别是单独用户表导入时间的1.47 倍,1.28 倍和1.60 倍。因为在构建索引时采用了MapReduce 框架来并行执行,并行地将索引数据插入到索引表中,通过该实验结果表明,SIBL方法构建索引的时间开销是可接受的。
索引的空间开销评估即是对HBase系统内存占用情况的评估,通过对原始用户表在HBase上占用的内存和构建索引后,用户表和索引表占用的总内存进行比较。实验结果如表5所示。
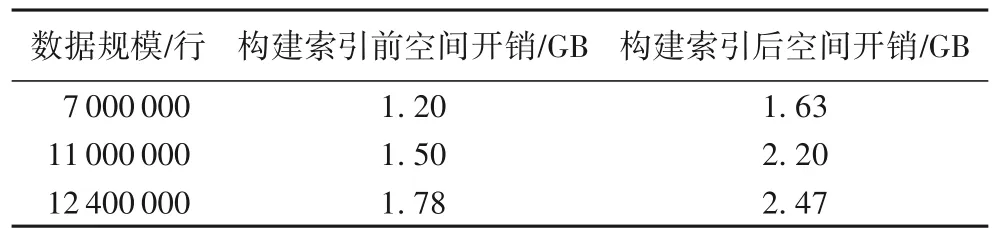
表5 构建索引前后空间开销对比Tab.5 Comparison of space overhead before and after index construction
4.2.2 索引查询性能
索引的查询性能就是对非主键进行查询时的响应时间,本文使用三种系统来对数据集的四种查询进行评估。这三种系统依次为华为HIndex系统、本文提出的SIBL方法以及原始的HBase系统。图3给出的是4组测试用例、三种系统的非主键索引查询性能对比情况。图中以查询所得的记录条数为横坐标,查询响应时间为纵坐标。

图3 非主键索引的查询性能对比Fig.3 Non-primary key index query performance comparison
综合上面的实验数据可以发现,除了查询所得记录条数过少或过大的极端情况,一般而言,SIBL 方法的查询性能相较于华为HIndex 提升了2 倍左右,随着查询结果规模的不断增大,相较华为HIndex 的性能提升逐渐缩小;SIBL 方法的查询性能相较于原始HBase 查询,提升了50 倍左右。当查询结果集过小时,相较原始HBase查询的性能提升效果最显著,达到了200 倍。这是因为原始HBase 只针对主键构建索引,在进行非主键查询时,无论查询结果集有多小,都需要全表扫描,遍历所有的用户表数据;而SIBL 方法则可以快速地定位到想查询的非主键信息。从实验数据中还可以发现,无论是华为HIndex,还是本文提出的SIBL 方法,查询响应时间都随着查询结果集条数的增加而不断增大。
4.2.3 负载均衡和可扩展性
索引构建完毕后,通过HBase 的Web-UI 可以查看到索引文件在HRegionServer 中的分布情况。索引文件的51.57%存储在hbase02 服务器上,48.43%存储在hbase03 服务器上,满足系统的负载均衡策略。
采用YCSB 测试工具进行测试,根据不同数据规模下单点查询和范围查询的查询响应时间来判断索引是否具有可扩展性。从实验数据图4可以看出,数据规模从500万条扩展到3 500 万条时,单点查询的查询响应时间保持着线性增长;长度为10 的范围查询也保持着线性增长。这表明SIBL 方法具有良好的可扩展性。随着数据规模的不断增大,索引数据的规模也随之增大,查询响应时间和数据规模成正比。

图4 在数据规模增大时SIBL方法的查询响应时间对比Fig.4 Query response time comparison of SIBL method when data size increases
5 结语
基于LSM-Tree 的轻量级分布式索引实现方法SIBL 采用MapReduce 框架并发地为磁盘和内存中的基线数据和增量数据分别构建索引,可以在不侵入分布式系统源码的前提下,让用户轻松地集成到自己的集群中,极大地提高索引的构建速度;设计的基于等距取样的索引区间划分算法,维护了系统的负载均衡。提出的基于冗余列查询方法,进一步提高了非主键索引的查询效率。提出的算法都在HBase 中得到了验证,通过实验结果看出,本文提出的SIBL 方法对非主键查询性能优于华为HIndex和原始HBase查询。分布式数据库的种类繁多,不同数据库的实现细节不尽相同,接下来计划在不同的分布式数据库上开展更多测试,不断优化索引的性能。
