关系数据库中聚合代数约束的高效发现算法
——AAC-Hunter
2021-03-18,2,2*,2
,2 ,2* ,2
(1.浙江大学计算机科学与技术学院,杭州 310027;2.浙江省大数据智能计算重点实验室(浙江大学),杭州 310027)
0 引言
给定一个关系数据库,聚合代数约束(Aggregation Algebraic Constraint,AAC)是一个定义在该数据库中两列的聚合运算结果之间的模糊代数约束。聚合代数约束仅约束数据库中的大多数而非全部记录。
本文研究如何从关系数据库中自动发现聚合代数约束。该技术在智慧审计领域具有广泛的应用前景。考虑一个简化的报销数据表,该表包含5个字段:(员工,部门,交通费,住宿费,杂费),表中每一条记录是包含上述5 个字段信息的报销记录。审计员希望从该表中找出违规的报销记录,该审计过程能够顺利实施的关键在于审计员能否发现报销数据表中存在的模糊约束,即作用于数据表中的大多数而非全部记录之间的约束。如果模糊约束的逻辑较简单,则一般可以通过专家经验给出。例如,如果审计员通过先验知识得知大多数正常的报销记录满足如下约束:交通费+住宿费<1 000,那么该审计员可以通过标准的结构化查询语言(Structured Query Language,SQL)找出违反上述约束关系的记录集,然后逐一检查该记录集每一条记录是否是违规报销。
然而,如果报销数据表存在聚合代数约束,由于聚合代数约束中包含聚合运算且和数据表中数据的分布高度相关,审计员很难通过通用的先验知识发现该约束。报销数据表中的一个聚合代数约束c1如下所示:

该聚合代数约束表明,按照部门字段对报销记录进行分组,大多数部门的平均住宿费和平均杂费之和在特定的区间[1000,2 000]以及[3 000,5 000]内。根据上述c1约束,审计员应该审计那些平均花费不在上述区间的部门的报销记录。类似c1的聚合代数约束很难通过先验知识获得,这是因为这些聚合代数约束涉及两列聚合运算结果(c1中为住宿费和杂费的聚合运算结果)之间的关系,该关系通常和数据分布高度相关。审计员需要采用数据驱动的方法从数据库中自动发现聚合代数约束。
本文提出了一个从关系数据库中高效地发现聚合代数约束的算法AAC-Hunter(Aggregation Algebraic Constraints Hunter)。在大数据时代,随着数据体量越来越大,数据之间的约束关系变得越来越复杂。研究者们逐渐从以专家经验为主的约束发现,转向以数据驱动为主的约束发现,提出了一系列从数据库中自动发现不同类型的约束关系的技术,以及根据约束维护数据一致性的技术,如:函数约束[1-4]、条件函数约束[5-8]、否定约束[9-12]、模式约束[13-14]、唯一约束[15]、代数约束[16]和时效规则[17-18]。然而,本文是第一项研究如何自动发现聚合代数约束的工作。AAC-Hunter 分两步生成聚合代数约束:第一步,AAC-Hunter 根据数据模式信息,生成由全体候选聚合代数约束组成的候选集合。候选聚合代数约束中参与聚合运算的两列可以来自同一张数据表,也可以来自不同的数据表。如果两列来自不同的数据表,AAC-Hunter 自动决定两张数据表的连接方法。示例聚合代数约束c1对应的候选聚合代数约束为(Avg(住宿费)+Avg(杂费))GroupBy(部门)。第二步,AAC-Hunter 为每条候选聚合代数约束计算一个值域集合,使该值域集合覆盖数据库中的大多数记录,并将该候选聚合代数约束与计算出的值域集合输出为最终的聚合代数约束 。AAC-Hunter 为c1计 算 出 的 值 域 空 间 为[1000,2 000]∪[3 000,5 000]。
从海量数据库中自动发现聚合代数约束存在两方面的性能挑战:1)全体候选聚合代数约束组成的候选集合的规模巨大,难以在有限的时间内处理该候选集合中的每一条候选聚合代数约束;2)计算候选聚合代数约束的值域集合涉及表连接、聚合运算等耗时的数据库操作,代价高昂。AAC-Hunter提出了一系列优化技术克服了上述两个挑战。本文的核心贡献如下:
1)提出并形式化了一种新的数据库模糊约束——聚合代数约束(第2.1节)。
2)提出了一个从数据库中自动发现聚合代数约束的算法AAC-Hunter(第2.2节)。该算法采用一组启发式规则减小候选聚合代数约束集合的规模(第3 章),并提出了两项优化技术加速候选聚合代数约束值域集合的计算(第4章)。
3)在TPC-H 数据集和European Soccer 数据集上与基线算法的性能对比实验验证了所提出优化技术的有效性(第5章)。
1 相关工作
与本文相关的工作归于基于数据驱动的约束发现。依据发现的约束关系的不同,相关工作分为:函数约束发现[1-8]、否定约束发现[9-12]、复杂模式约束发现[13-14]、唯一性约束发现[15]、简单代数约束发现[16]和时效规则[17-18]。这些已有工作与本文工作的区别在于发现的约束关系不同。已有工作专注于发现数据库中记录之间或者列之间的各种约束关系,而本文工作研究的是两列聚合运算结果之间的代数约束关系而非直接作用于数据库两列之间的代数约束关系。进一步,本文研究的聚合代数约束的候选集合在规模上也比现有工作研究的约束候选集大很多,需要新的剪枝和优化技术来处理。
2 发现聚合代数约束
2.1 聚合代数约束
聚合代数约束如定义1所示。
定义1给定关系数据库D,聚合代数约束是一个作用于D中部分记录上的八元组:

其中:a1、a2是D中的两个属性字段,可以来自同一张数据表,也可以来自两张不同的数据表;f1、f2是分别施加在属性a1、a2上的聚合函数,本文考虑5 种聚合函数:Count、Sum、Avg、Max和Min;二元运算符⊕是f1(a1)和f2(a2)间的代数运算符,包括+、-、×和/;I=I1∪I2∪…∪Ik为f1(a1)⊕f2(a2)的值域集合,其中Ii∈I是一个实数闭区间[a,b],且I中任意两个区间Ii、Ij满足Ii∩Ij=∅;如果a1、a2来自不同数据表,配对规则p指定数据表间的连接条件;g是分组规则,语义上等同于SQL的Group By 语句,指定与聚合运算相关的分组字段列。定义1 形式化地表明聚合代数约束是a1、a2在条件p、g下,使用函数f1、f2进行⊕运算后产生的值域集合I约束。式(2)进一步表示聚合代数约束中各因子间的关系:

其中:若a1、a2来自同一张表r,则配对规则p为平凡规则(即不需要表连接),记为p=∅r;若a1、a2分别来自两张表r和s,配对规则p指定r和s的连接条件,即其中cols1与cols2分别为表r、s上的连接字段;分组规则g=d1,d2,…,dn指定分组字段列。图1 描绘了式(2)的运算流程。
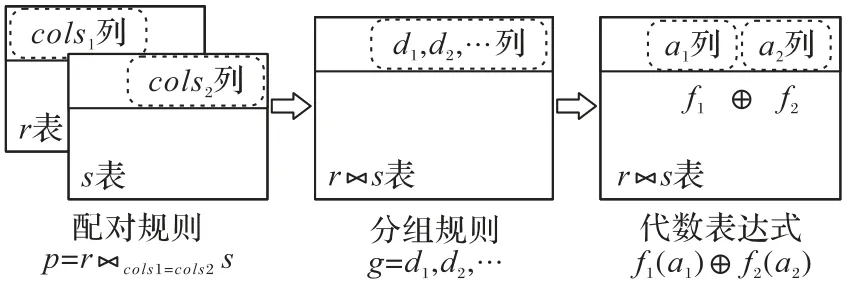
图1 聚合代数约束运算流程Fig.1 Calculation flow of aggregation algebraic constraint
为了更好地解释聚合代数约束的含义,此处使用引言中的约束c1和另一个例子作进一步解释。关系数据库D1中存在报销表(员工,部门,交通费,住宿费,杂费),使用定义1 中的符号规范表示约束c1,各元素如下所示:a1=住宿费,a2=杂费,f1=f2=Avg,p=∅报销表,g=部门,⊕为+(即加法运算),I=[1000,2 000]∪[3 000,5 000]。聚合代数约束c1表示了各部门报销记录中平均住宿费和平均杂费的和所符合一定的值域集合。关系数据库D2储存了某工厂检验生产工件的记录,存在工件表(工件号,生产批次,仓储位置)和检验表(工件号,外径,内径),一条聚合代数约束c2的元素如下所示:a1=外径,a2=内径,f1=f2=Avg,p=工件表⋈工件号=工件号检验表,g=生产批次,⊕为/(即除法运算),I=[3.123,3.127]。聚合代数约束c2描述了这个工厂生产的不同批次工件,各批次平均外径和平均内径的比值满足一定的值域集合限制。由c1、c2可知,聚合代数约束描述了数据记录根据某个属性分组后,含统计特征的聚合代数运算结果具有一定的值域限制。
2.2 AAC-Hunter算法概述
AAC-Hunter分两步从数据库中发现聚合代数约束:
1)产生候选聚合代数约束集合C。根据数据模式信息生成所有形如c=(f1,a1,f2,a2,p,g,⊕)的候选聚合代数约束。全体候选聚合代数约束c组成集合C。
2)使用直方图技术,为C中的每一个候选聚合代数约束c计算值域集合I,并输出(c,I)作为发现的聚合代数约束。
上述算法简单、易实现,但两个原因使该算法无法应用于稍大规模的数据库:1)对于稍复杂的数据库,算法第一步将会产生海量规模的候选聚合代数约束集合,无法在有限的时间内处理该集合;2)计算I需要进行表连接和聚合运算操作,这些操作都非常耗时。本文在第3 章和第4 章引入一系列启发式优化技术,降低处理代价,提升AAC-Hunter算法的伸缩性。
3 产生候选聚合代数约束
AAC-Hunter 算法的第一步是产生候选聚合代数约束集合C。该步骤进一步分为3 个子步骤:1)产生配对规则;2)产生分组规则和3)产生包含聚合运算的代数表达式。AACHunter 在每一个子步骤中引入一些启发式剪枝规则,降低C的规模,本章详细介绍这些实现细节。
3.1 产生配对规则
AAC-Hunter 首先产生配对规则p,组成集合P。由定义1,若a1、a2分别来自不同的数据表r和s,则AAC-Hunter 需要产生配对规则p指定表连接的方法。本文考虑两种类型的表连接:1)若r、s之间存在外键约束,则按照外键约束连接两个表;2)若r、s之间不存在外键约束,则AAC-Hunter 将在r、s中找到类外键约束的组合字段对(cols1,cols2),并通过该组合字段对连接两表。第一种类型的表连接比较简单,本节详细介绍如何产生第二种类型的表连接。
对包含a1和a2的表对(r,s),AAC-Hunter在表对(r,s)中寻找所有可以连接的组合字段对(cols1,cols2),其中cols1⊂r,cols2⊂s,满足cols1和cols2长度一致(即,两个组合字段cols1和cols2包含相同数目的字段)且cols1和cols2组合字段中对应位置的字段具有相同的数据类型。为了更有目的性地寻找这种组合字段对,可以参考数据库中定义的索引字段,这些添加了索引的字段往往会被频繁查询且更加重要。这一步在最坏情况下将产生平方级别数量的组合字段对,为降低计算代价,AAC-Hunter引入以下两条剪枝规则:
1)排除两表均仅含有少量记录的配对规则。这样的配对规则无法通过后续计算分析得到有意义的值域集合。
2)排除由自增字段、NULL 值过多的字段组成类外键约束的配对规则。经验表明这些字段或者与数据库设计相关(即自增字段),或者与数据缺失相关(即NULL 值过多的字段)。这些字段并不存储具有审计价值的数据,不是理想的连接字段。
3.2 产生分组规则
产生配对规则p之后,AAC-Hunter 接着生成分组规则集合G。该集合中的每个分组规则g由一个字段序列d1,d2,…,dn构成。AAC-Hunter 只考虑将具有类别属性的字段(即,该字段只存储有限数量的离散值,如部门字段)加入g。
对于配对规则p,假定执行连接运算r⋈s后结果表含有m个类别字段h1,h2,…,hm,若从中选择i个字段(0 <i≤m)组成分组规则,此时产生Ci m种组合方式作为分组规则。这种朴素的方法将产生总计=2m-1 个符合条件的分组规则。显而易见,分组规则的产生数目随m增大而难以接受。AAC-Hunter使用以下方法来限制分组规则集合的规模:
1)引入分组序列长度最大值的超参数W以避免分组规则数过分增长。此步骤中,分组规则全集的数目至多为|G|=
2)分组规则中排除自增字段、NULL值过多的字段。
3)分组规则排除存在唯一性约束的字段。
4)分组规则排除由事实唯一字段(即,值几乎各不相同的字段)组成的规则。
3.3 产生代数表达式
本节构造形如fi(ai)⊕fj(aj)的代数表达式。在配对规则p描述的连接运算结果中,AAC-Hunter 首先寻找可进行代数运算的字段作为ai,接着生成与ai的数据类型相兼容的聚合函数fi。本文考虑如下两条类型兼容规则:1)对日期类型的ai,其兼容的聚合函数为Max、Min 和Count;2)对数值类型的ai,其兼容的聚合函数为Count、Sum、Avg、Max和Min。
对于按照上述过程产生的fi(ai),枚举二元组(fi(ai),fj(aj)),并选取语义正确的⊕产生代数表达式fi(ai)⊕fj(aj)。在选取⊕时,AAC-Hunter 考虑如下语义约束:1)日期与日期之间仅能做减法运算;2)日期和整数型数据可以做加减法运算;3)Count函数无需明确属性字段且只做乘法运算或者除法运算。作为特例,枚举仅含单个计算属性的情况形成代数表达式fi(ai)。
假定配对规则p产生的结果表中有l个字段可作为ai,则上述枚举方案至多产生个代数表达式。AACHunter引入剪枝规则以减小代数表达式空间大小:
1)排除主键字段、自增字段、外键字段,以及配对规则p、分组规则g中涉及的字段。
2)排除分组规则和代数表达式相同,但配对规则不同的冗余的候选聚合代数约束。对于包含相同分组规则g=d1,d2,…,dn以及相同代数表达式fi(ai)⊕fj(aj)的多个候选聚合代数约束,AAC-Hunter 保留包含平凡配对规则p=∅r的候选聚合代数约束,排除包含非平凡配对规则p=r⋈s的候选聚合代数约束。
4 产生候选聚合代数约束的值域集合
本章介绍如何产生候选聚合代数约束的值域集合I。AAC-Hunter 采用中间结果复用和消除平凡候选聚合代数约束两项技术来加速处理候选聚合代数约束中的代数表达式计算,计算流程和加速技术的应用如图2 所示。本章首先介绍这两项技术,然后介绍如何从代数表达式的结果生成I。

图2 计算流程与加速技术示意图Fig.2 Schematic diagram of calculation process and acceleration techniques
4.1 复用中间结果
从前文论述中可以推知候选聚合代数约束集合C中大量候选聚合代数约束存在公共子操作。例如,如果两条候选聚合代数约束中a1和a2都来自相同表对(r,s) 并进行运算,那么该连接运算就是这两条候选聚合代数约束的公共子操作。类似地,如果两条候选聚合代数约束包含相同的分组规则,那么分组操作就是公共子操作。为加速计算候选聚合代数约束中的代数表达式,AAC-Hunter 将候选聚合代数约束分类,并从每个分类中抽取公共连接和公共分组两类公共子操作。对于公共子操作,AAC-Hunter 只计算一次,然后反复重用这些公共操作的结果,快速计算每条候选聚合代数约束的代数表达式。
AAC-Hunter 按照如下步骤对所有候选聚合代数约束进行归类:1)将使用相同配对规则pi的候选约束归类,记作2)将使用相同分组规则gj的候选约束归类,记作;3)分析候选约束组,收集涉及到的所有分类字段和计算属性,分别记作。归类效果如图3所示。
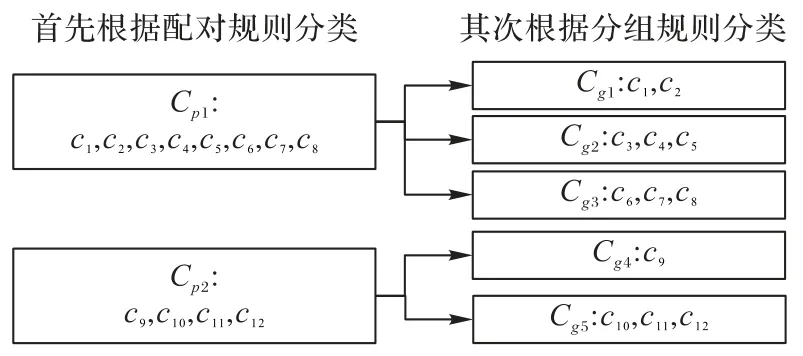
图3 基于归类的中间结果复用示意图Fig.3 Reusing intermediate results based on classification
AAC-Hunter 采用的中间结果复用技术可以极大地降低计算代数表达式的成本。分析如下,不采用中间结果复用的计算总成本上限为:

其中:n为表的数目,m为连接结果表平均的分类字段数目,l为连接结果表平均的计算属性数目,k1为配对规则描述的连接计算成本系数,k2为分组运算和代数表达式的计算成本系数,kp为产生配对规则数量相关的系数,W为限制分组规则序列长度的超参数。复用中间结果之后,总成本上限降为:

显而易见,中间结果复用后计算成本得到大幅降低。
4.2 消除平凡候选聚合代数约束
生成聚合代数约束的最终目的是为审计应用服务,因此,生成的聚合代数约束必须具有代表性,即覆盖了数据库中绝大多数记录;然而,有的候选聚合代数约束中配对规则描述的连接条件过于苛刻,以至于只有很少的记录才能进入连接结果,无法覆盖大多数记录。类似地,有的候选聚合代数约束中分组规则的字段序列选择不合适,使得结果集或者仅包含少数几个分组且每个分组包含大量记录,或者产生大量分组,但每个分组只有个别记录,从而使结果集失去了统计意义。
本文称至少满足上述两个条件(配对规则不合适、分组规则不合适)之一的候选聚合代数约束为平凡候选约束。AACHunter引入启发式规则来跳过这些平凡候选约束的计算。
对于配对规则pi,若发现连接运算的结果记录数较少,或远低于参与连接的两表记录数,则意味着pi不是一条合适的配对规则。算法将终止接下来的计算,并从剩余候选约束中剔除所有候选约束组。如图4(a)所示,假若配对规则p1不合适,则与其相关的候选约束组中所有候选约束均不再继续计算。
对于分组规则gj而言,检验分组字段组合值的占比,仅计算占比满足以下公式的分组规则:
1.2.1 发病规律调查 2015~2017年在试验地对1~3年生青杨苗木的病害发病规律进行系统调查。采取标准地调查和线路调查2种方法,每年6月中旬开始,根据青杨病害历年发生情况、扦插密度、树龄、地形地貌、坡向、交通和管理等条件确定7个固定标准地,每个标准地选有代表性的青杨苗木15株,每株树固定调查3~5个枝条,50~100片叶,每5d观察1次病害发生情况,做好记录。线路调查每10d进行1次,根据目测情况,每点调查20株,每株树调查3~5个枝条,50~100片叶,借助80倍解剖镜观察叶片病斑发生情况。
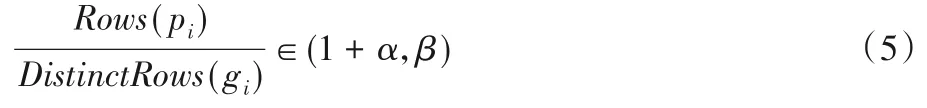
其中:pi=r⋈s为对应配对规则的连接结果表,α为大于0 的参数,β为表示分组内最大记录数量的参数。
若比值不满足式(5)的要求,则意味着分组规则的组内记录太多,或者分组字段序列的值有事实唯一的特性。若检验出分组规则gj无效,则意味着所有包含该分组序列的分组规则也都是无效的,那么将包含这些分组规则的平凡约束也一并剔除。如图4(b)所示,假若分组规则g2失当,同时分组规则g3、g5与其共享相同的分组字段,那么它们对应的所有候选约束均被消除。
上述流程以一次计算成本为代价实现对大量平凡候选聚合代数约束的排除,这极大地弥补了发现候选约束阶段带来的计算空间爆炸的缺陷,减小与候选约束数量相关的成本:

其中:q为数据集实际存在的连接关系数量,且q≤kpn;u为代数表达式组的执行次数,一般u≪;k3表示检验每个分组规则字段组合值占比的平均成本,且k3≪k2;v表示查询分组规则字段占比的次数,显然v≥u。

图4 消除平凡候选聚合代数约束示意图Fig.4 Schematic diagram of eliminating trivial candidate AACs
4.3 生成有效值域集合
完成候选约束的代数表达式计算之后,AAC-Hunter 对结果进行离群值分析,得到正常和异常的值域集合。聚合代数约束作用于大多数记录(指接下来被认定为是正常的记录)而非全部记录的模糊约束特性在此得以体现。
AAC-Hunter 使用时间复杂度为O(n)的直方图法分析代数表达式的结果,将正常值域集合作为候选聚合代数约束的值域集合I。理想情况下,数据应是完全无错的,所形成的约束值域集合应当是代数表达式结果的全域;然而,即便通过合法渠道进行数据持久化,也会产生异常数据(如表模式变更、实际业务的复杂性原因等),此时约束的值域集合应当剔除异常的部分,保留有效的大多数的部分。如图5 所示,AACHunter 统计数值出现的频度,按分布情况设定图中横线所示的阈值(阈值t=Rows(results) ×φ,超参数φ为留取比例),频数大于阈值的区间被认定为有效区间,其他区间为无效区间,体现适用大多数而非全部记录的模糊约束的性质。AACHunter 判定图中结果序列的值域为I=[11,30]∪[35,36]。至此,AAC-Hunter完成发现一条聚合代数约束的流程。

图5 基于直方图的运算结果分析Fig.5 Histogram analysis for calculation results
仅从数据角度看来,AAC-Hunter 所发现的聚合代数约束由数据驱动产生,具有模糊约束的特征(即仅约束数据库中的大多数而非全部记录),通常难以使用专家知识构造,是准确有效的;然而,并非任意聚合代数约束都能成为满足现实业务逻辑的审计规则,其原因在于,算法既无法通过降维后的数据还原实际业务的场景,又无法准确判别聚合代数约束是否能够作为审计规则使用。因此,在程序结束后,审计员可以使用领域知识人工筛选有意义的聚合代数约束,并对值域结果做调整,使之成为审计规则。若认为图5 柱形图右侧柱形区间[35,36]有异常的嫌疑,则可以在此程序结果上作进一步调整。
5 实验
本文用Python 和SQLite 实现了AAC-Hunter 算法。本章介绍实验结果。实验在CPU 为AMD Ryzen 5 1400、内存为8 GB 的工作站上进行。实验采用TPC-H 数据集(http://www.tpc.org/tpch)和European Soccer 数据集(https://www.kaggle.com/hugomathien/soccer),验证AAC-Hunter的各种优化技术。
5.1 实验设计与数据集
实验流程如下:首先加载数据库定义,然后产生候选聚合代数约束,最后产生候选聚合代数约束值域集合。根据经验设计如下的超参数:实验剪枝记录数不超过200 条的表(认为记录数少于200 条的表无发现聚合代数约束的价值),分组规则字段列长度上限参数W设定为3(即1条配对规则至多产生7 条分组规则),字段NULL 值比率需低于5%。若执行连接运算后表记录数低于100 条或低于原表记录数90%,认为该连接运算涉及的约束是平凡候选聚合代数约束的,则放弃对应配对规则。若检查分组规则时发现组内平均记录数低于2 条或大于100 条,认为该分组运算涉及的约束是平凡候选聚合代数约束,则放弃该分组规则。
鉴于AAC-Hunter 算法不言而喻的正确性(即,算法所发现的聚合代数约束对于给定数据一定是正确的,但无法判别在现实业务场景下的正确性),实验关注AAC-Hunter 各种优化技术的实际效果,并不考虑所发现约束的现实意义。实验在TPC-H、European Soccer 两组广泛使用的数据集上评估效果。TPC-H 是一种用于评估数据库系统决策支持能力的数据集和执行标准,提供了商业销售场景的表模式和数据,广泛运用于数据库系统的测试。鉴于AAC-Hunter 对表模式敏感,对记录数量并不敏感(由记录数量引入的复杂性本质上是对数据库系统的性能校验而非对AAC-Hunter 的优化技术效果校验),实验使用0.01的规模因子产生数据,整个数据集共计12个离散型分类字段。European Soccer 是一种收集于电子游戏的数据集,记录了欧洲国家足球赛事、队伍、球员等详细信息,数据库文件大小为300 MB。它包含了队伍特征和球员属性两张宽表(具有较多数值类型字段),以及五张普通表(具有少量文本和数值类型字段),其中球员属性表的记录数多达18万条,整个数据集共计20个离散型分类字段。
5.2 评估产生候选聚合代数约束效果
实验统计了各数据集产生候选约束的效果。结果如表1所示,其中PR_TBL 表示产生配对规则阶段剪枝两表均仅含有少量记录的配对规则,PR_INC、PR_NUL分别表示产生配对规则阶段剪枝由自增字段、NULL值过多的字段组成类外键约束的配对规则,GR_INC、GR_NUL 分别表示产生分组规则阶段剪枝由自增字段、NULL 值过多字段组成的分组规则,GR_IDX 表示产生分组规则阶段剪枝由唯一性约束的字段组成的分组规则,GR_ATTR 表示剪枝分组字段由事实唯一字段组成的分组规则。OP_FAKE 表示代数表达式无效的剪枝,OP_RE 表示冗余候选聚合代数约束的剪枝。从表1 可以看出,一条候选约束可命中多条剪枝规则,剪枝规则间效果差异巨大,这与数据集特征密切相关。

表1 不同剪枝规则效果Tab.1 Effect for different pruning rules
各阶段剪枝规则产生效果对比如表2 所示。在不剪枝时朴素的枚举算法生成了数量庞大的结果,使用剪枝规则时大幅缩小了候选约束集合规模。在表2 中,剪枝后的分组规则数比配对规则数量更少,是由部分配对规则无法产生有效分组规则导致的。由表可知,即便European Soccer 数据集具有更多的列,但是其列大多数具有唯一性约束或列值具有事实唯一的特征,因此剪枝后的约束数量并未多于TPC-H 数据集的数量。此外,分组规则对配对规则的扩张并不明显,但候选约束对分组规则的扩张十分显著,如含有宽表的European Soccer 数据集枚举代数表达式时产生了更多倍数的结果,使用剪枝规则可以收束各阶段产生规则的放大效应。

表2 各阶段产生候选约束结果数量对比Tab.2 Result number comparison for candidate constraint production at different stages
5.3 评估产生候选聚合代数约束值域集合效果
在第3 章介绍的所有剪枝规则产生候选聚合代数约束集合的基础上,实验对比了不使用任何优化策略(简记为baseline)、仅复用中间结果(简记为RE,4.1 节)以及同时复用中间结果和消除平凡候选聚合代数约束(简记为RE+EL,4.1节和4.2节)三种执行方案的效果。
各方案运行耗时结果如表3 所示。可以直观地看出,AAC-Hunter 算法设计的方案大幅提高了程序的执行速度,RE+EL 方案相对于baseline 方案在TPC-H 和European Soccer数据集上分别减小了95.68%和99.94%的约束发现空间,缩短了96.58%和92.51%的运行时间。通过baseline 和RE 方案实验结果的对比,RE方案明确可以在不改变结果数量的前提下提升值域集合计算的效率,这符合复用中间结果技术的消除公共子操作效果。

表3 不同执行方案的运行耗时、结果数量对比Tab.3 Running time and result number comparison of different execution schemes
值得一提的是,表3 中European Soccer 数据集中仅使用RE 方案却比使用RE+EL 复合方案略微高效,是由于该数据集计算约束值域集合的过程并未受益于可能减少结果数的RE+EL 方案(表3 中RE+EL 方案、RE 方案的相同结果数说明了这一点),这符合式(6)所表达的含义。对于消除平凡候选聚合代数约束技术而言,既会因为检查规则有效性而进行额外计算,又可能通过消除平凡候选约束间接减少更为耗时的值域集合计算,通常收益远大于代价;然而即便应用消除平凡候选聚合代数约束技术未有收获,从结果可以看出,其代价并非难以接受。
6 结语
本文提出了AAC-Hunter,一个从关系数据库中高效地发现聚合代数约束的算法。AAC-Hunter 采用一系列启发式规则减小了候选聚合代数约束集合的大小,并优化了候选聚合代数约束的值域集合计算。AAC-Hunter 与基线算法的对比实验表明,提出的优化技术显著缩短了发现聚合代数约束所需的计算时间。
