基于LDA模型的测试用例复用方法*
2021-03-16
(江苏自动化研究所 连云港 222061)
1 引言
军用软件大多采用基于构件的设计方法,同一类型的军用软件具有很大的相似性,彼此之间具有很高的关联性和继承性[1~6]。因此,针对当前军用软件测试存在的困难,可以从对测试用例的复用方面进行考虑[7]。测试用例的复用不仅解决了测试人员经验不足的问题,又能节省测试用例开发的时间、精力和财力,从而能够最大限度的提高测试用例的使用效率,降低测试时间,提高测试效率。
文献[8]提出一种根据用户行为计算已有测试用例的复用能力方法。张娟等提出了一种基于测试用例套的复用度量计算方法,并实现计算过程的自动化[9]。路晓丽等构建了一个支持测试用例共享和复用的测试用例资产库[10]。陈平等提出一种从软件测试需求层面提取测试用例的方法[11]。文献[12]和[13]提出基于案例推理的测试用例复用机制,并使用类比推理的方法进行测试用例的复用。以上文献有关软件测试用例复用的研究主要局限在某一个方面,缺乏复用过程的系统研究,而且,测试用例复用的准确率不高。基于这些局限和军用软件系统的特点,本文研究潜在语义的测评文档生成算法,并在此基础上提出一种系统的测试用例复用策略,从语义层次对测试用例进行检索复用。
2 被测软件及测试用例的描述模型
2.1 被测软件的描述模型
本文从军用软件的描述、所属行业、所属领域、运行平台、开发语言、测试需求及需求对应的测试用例角度对被测软件进行形式化描述。为了方便测试用例的复用,本文建立测试需求和测试用例的映射关系。在测试用例复用时,可以根据软件之间测试需求的相似度而计算出测试用例的可复用性,从而建立从软件到测试需求,从测试需求到测试用例的复用关系。
在表1列出的军用软件属性信息集合中,软件概述和查询索引是测试复用阶段较为重要的两个信息。其中,软件概述主要是对军用软件的功能、目标等进行描述。本文用软件体系结构中提到的REBOOT模型对软件概述进行抽象描述[14]。该模型用有限维信息空间的术语组合从若干刻面的综合角度来刻画一个软件。查询索引主要使用软件的标签或能表示软件的关键字。本文用一个五元组(标签1,标签2,标签3,标签4,标签5)来描述软件的查询索引。另外,附件信息描述了软件所对应的测试说明文档的路径。如果在测试用例复用阶段,有相似度极高的软件,可以直接进行测试说明文档复用。这样,既节省了复用的时间,而且复用程度极高。

表1 典型军用软件属性信息集合
2.2 测试用例的描述模型
对已存在军用软件测试用例描述时,将军用软件的功能进行细化,这样有利于功能点对应的测试用例的充分表示。本文首先从军用软件到配置项,从配置项到功能模块的思路对军用软件的功能进行细分。每一个功能可以表示为多个功能点。为了提高测试用例复用的准确率及效率,本文将功能点用通用的自然语言进行规范化描述,从而使每一个功能点均能准确、完整地表示出软件的功能,这样,也有利于提高测试需求到测试用例的匹配。在实际软件测试过程中,一个功能点对应多个测试用例,一个测试用例也可以对应多个功能点,在测试用例规范化时,尽量保证可复用测试用例之间的独立性。这样,有利于提高测试的复用程度。对测试用例进行规范化时,一个可复用测试用例按照表2所列的测试用例数据属性描述。功能点描述和查询索引是测试用例检索机制重要的两个信息。在对军用软件的功能点进行描述时,本文通过一个三元组(所属软件,功能模块,功能点)来描述功能点。查询索引主要使用相关软件功能点的关键词来表示,也可以说是相关软件的标签。本文用一个多元组(标签1,标签2,标签3,标签4……标签n)来描述查询索引,这样,在测试用例复用时,可根据功能点描述与查询索引相结合进行测试用例匹配。

表2 测试用例数据属性信息
3 基于潜在语义的测试用例复用
3.1 测试用例复用文本的预处理
在测试用例复用前,需要对测试文本进行预处理。在预处理阶段,首先将测试文本转化为测试文本-关键词矩阵。在采用中科院分词系统ICTCLAS进行分词时,在用户词典中添加一些测试相关术语、专业性词语等。当测试文本经过分词程序时,就会去除相关的停用词,然后统计各个关键词的词频并进行相关计算,最终将被测软件的测试需求向量 可 表 示 为R=R(T1,W1;T2,W2…Ti,Wi;… ;Tn,Wn),可简记为R=R(W1,W2…Wi…,Wn),其中1<i<n,Ti是被测软件的测试需求文本中第i个特征项,Wi为Ti的权重;可复用测试用例的测试需求向量可表示为CR=CR(T1,W1;T2,W2…Ti,Wi;…;Tn,Wn),其中1<i<n,Ti是可复用测试用例测试需求文本中第i个特征项,Wi为Ti的权重;可复用测试用例的查询索引向量可表示为CK=CK(T1,W1;T2,W2…Ti,Wi;…;Tn,Wn) ,其中1<i<n,Ti是可复用测试用例的查询索引中第i个特征项,Wi为Ti的权重。基于特征词的测试文本相似度计算公式见式(1)。
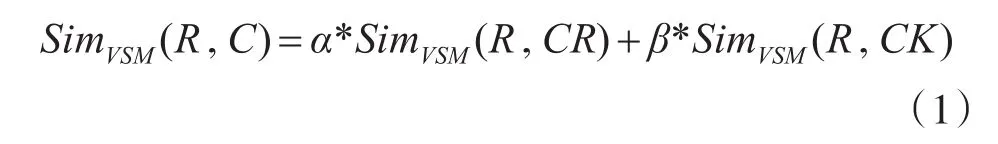
其中,α,β为调和参数,SimVSM(R,C)为被测软件的某一测试需求与测试用例基于关键字的相似度,SimVSM(R,CR)为被测软件的某一测试需求与可复用测试用例对应的功能点描述基于关键字的相似度,SimVSM(R,CK)为被测软件的某一测试需求与可复用测试用例查询索引基于关键字的相似度。
其次,将被测软件的测试需求文本-关键词矩阵、可复用测试用例的测试功能点描述文本-关键词矩阵及查询索引-关键词矩阵转化为被测软件的测试需求文本-主题矩阵、可复用测试用例的功能点描述文本-主题矩阵及查询索引-主题矩阵。本文主要利用测试文本的潜在语义进行相似度计算,所以,首要目标就是进行LDA建模。而LDA主题模型是一个分层的贝叶斯模型,其包含文本、主题和关键词三个层次结构,同时也是一种生成主题概率模型[15]。
在LDA建模时,LDA主题模型生成一个测试文本的算法如下。
Step1:针对测试数据集中的文本,根据Dirichlet分布Dir(α)得到文本中特征词对应主题的多项式分布参数θ;
Step2:根据泊松分布计算每篇测试文本中包含的特征词数量N=Poisson(ξ);
Step3:对于每一个主题z,根据Dirichlet分布Dir(β)的到主题对应的多项式分布参数φ~Dir(β);
Step4:针对数据集中每个文本中的特征词w:
1)根据多项式分布Multi(θ)得到特征词对应的主题zi;
2)根据多项式分布Multi(φ)生成单词w。
通过潜在语义分析,被测软件的测试需求主题向量可表示为RT=RT(t1,t2,…ti…,tn),其中1<i<n,ti是被测软件的测试需求文本对应的第i个主题;可复用测试用例的测试需求主题向量可表示为CRT=CRT(t1,t2,…ti…,tn),其中1<i<n,ti是可复用测试用例的测试需求文本对应的第i个主题;可复用测试用例的查询索引向量可表示为CKT=CKT(t1,t2,…ti…,tn),其中,ti是可复用测试用例的查询索引对应的第1<i<n i个主题。基于主题的测试文本相似度计算公式见式(2)。

其中,χ,φ为调和参数,SimLDA(R,C)为被测软件的某一测试需求与测试用例的主题相似度,SimLDA(R,CR)为被测软件的某一测试需求与可复用测试用例对应的功能点的主题相似度,SimLDA(R,CK)为被测软件的某一测试需求与可复用测试用例查询索引的主题相似度。
3.2 基于潜在语义的测试用例复用方法
基于潜在语义的测试用例复用框架如图1所示。使用2.1节被测软件描述模型及2.2节测试用例的描述模型对已测试的软件及其对应的测试用例进行规范化处理,并将这些数据收集到测试用例库,进行合理的分类、管理和维护。然后,依据测试用例库,采用测试用例复用检索机制层层递近,从总体到局部的策略进行测试用例复用。具体算法如下。
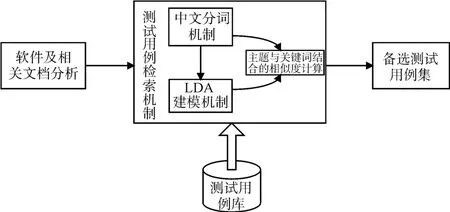
图1 测试用例复用框架
输入参数集:{被测软件的所属行业、所属领域、运行环境信息、被测软件查询索引、测试类型、被测软件的功能点描述、m、a、n、μ},其中m为可复用软件集1中的软件数量阈值,n为备选可复用测试用例的个数;
输出结果集:{被测软件测试需求对应的备选可复用测试用例}。
Step1:根据被测软件的所属行业、所属领域、运行环境过滤、生成已存在的可复用软件集合,其中所属行业、所属领域、运行环境的表示比较固定,匹配过程中采用字符串匹配技术即利用字符串的Contains(String str)方法。如果所属行业、所属领域、运行环境中至少两个匹配成功,就可以将可复用软件放到备选可复用软件集1中;
Step2:针对备选可复用软件集合1,根据被测软件的查询索引,将每一个软件的查询索引转化为矩阵表示,即软件-关键词矩阵,定义阈值a,然后利用余弦相似度公式计算被测软件与备选可复用软件的相似度,将相似度大于给定阈值的可复用软件放到备选可复用软件集2中;
Step3:针对备选可复用软件集2的每一个软件,根据被测软件所要复用的测试用例的测试类型,对每一个软件对应的测试用例进行过滤,得到可复用测试用例集1;
Step4:首先将被测软件的测试需求和可复用测试用例集1的每一个测试用例的功能点描述文本通过中文分词工具进行预处理,经过特征提取后构建特征空间即将测试需求文本和功能点描述转化为特征向量,其次将可复用测试用例集1的每一个测试用例的查询索引都转化为矩阵表示,即测试用例-关键词矩阵;
Step5:利用3.1节LDA主题模型测试文本生成算法,将被测软件的测试需求文本-关键词矩阵、可复用测试用例的测试功能点描述文本-关键词矩阵及查询索引-关键词矩阵转化为被测软件的测试需求文本-主题矩阵、可复用测试用例的功能点描述文本-主题矩阵及查询索引-主题矩阵。然后利用式(1)和式(2)相结合计算被测软件的测试需求与可复用测试用例的相似度,公式见式(3):

其中,η,γ为调和参数,Sim(R,C)为被测软件的某一测试需求与测试用例的相似度,SimVSM(R,C)为被测软件的某一测试需求与可复用测试用例基于关键字的相似度,SimLDA(R,C)为被测软件的某一测试需求与可复用测试用例的主题相似度;
Step6:针对计算得到的被测软件测试需求与可复用测试用例的相似度值,采用选择排序算法对可复用测试用例进行排序。由于一个测试需求可能对应若干个测试用例,此时需要将排序前Top n的测试用例放到备选可复用测试用例集中,形成被测软件测试需求-备选可复用测试用例矩阵。通过测试用例复用检索算法得到被测软件测试需求-备选可复用测试用例矩阵后,然后,从被测软件需求对应的备选测试用例集人工选择相应测试用例,然后根据测试用例模板生成相应的测试用例。
4 实验及结果分析
4.1 实验评价方法
在测试用例复用过程中,根据被测软件的测试需求及查询索引,从测试用例库中选择相应的测试用例。而评价测试用例复用效果的是复用的准确率,即测试需求对应测试用例的有效性。所以本实验主要关注测试用例复用的准确率。
假设某一个软件有N个测试需求,如果在用例复用时,复用得到的总用例数为M个,第i个测试需求匹配到正确的用例数为ni个,则测试复用的准确率为
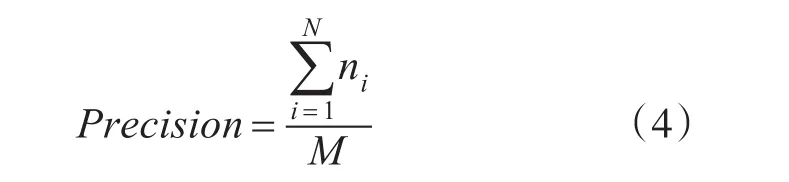
4.2 实验内容及结果分析
本文利用3.2节的基于潜在语义的测试用例复用方法进行仿真实验,实验的数据为已完成测评的相对独立的软件,分别为某专用网管系统、某作战指挥系统、某数字集群系统及某多功能航行器软件,每个软件对应的测试用例如表3所示。
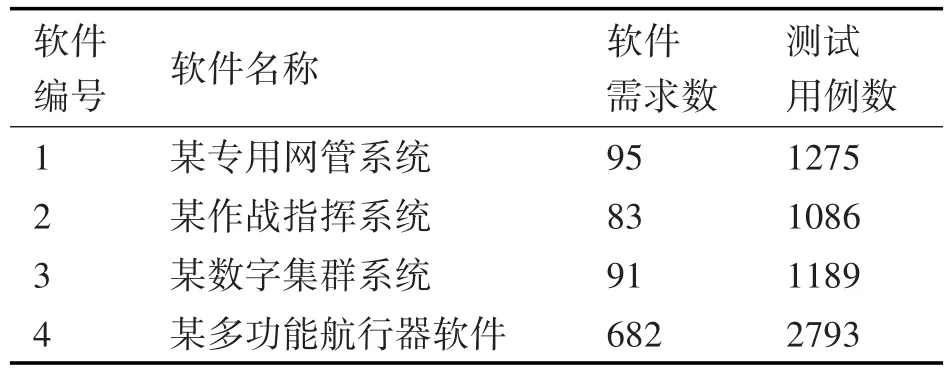
表3 软件对应的测试用例数
本实验利用基于VSM的测试用例复用方法和本文提出的基于潜在语义的测试用例复用方法进行仿真实验。为了保证实验的一致性,所有参数设置一致。分别将某专用网管系统、某作战指挥系统、某数字集群系统及某多功能航行器软件作为被测对象作用在两种测试用例复用方法上,实验结果如表4所示。

表4 对比实验结果
通过表4列出的实验结果和式(4)计算出两种方法在不同实验对象上的准确率,如图2所示。通过两种复用方法的对比试验,本文提出的方法的准确率明显高于传统的基于VSM的测试用例复用方法,而且通过表4可以看出,在测试用例召回数量方面,本文提出的基于潜在语义的测试用例复用方法比传统的基于VSM的测试用例复用方法分别多出354个、300个、269个、752个。通过实验结果验证了本文提出的测试用例复用方法在准确率和测试用例召回数量方面的有效性。

图2 不同测试用例复用方法匹配测试用例的准确率
5 结语
本文通过构建被测软件与测试用例的模型,建立测试需求与测试用例的关联性,从潜在语义的层面对测试需求和测试用例进行建模、解析,从而达到测试用例复用的目的,并通过仿真实验验证了本文提出的基于潜在语义的测试用例复用方法的有效性。总之,本文的研究在理论上具有创新性,在实际测试项目中具有可行性。但随着测试用例的积累,测试用例的数量级惊人,下一步考虑引入数据挖掘技术优化测试用例检索时间。
