基于迁移学习和批归一化的菜肴图像识别方法
2021-03-16郭心悦胡沁涵刘纯平杨季文
郭心悦 胡沁涵 刘纯平 杨季文
(苏州大学计算机科学与技术学院 江苏 苏州 215006)
0 引 言
菜肴类App成为人们日常生活广泛使用的一类App,其中菜肴查询是这类App的一个基本功能。菜肴图像自动识别是提升这类App用户体验的必经之路。利用菜肴图像识别技术获取用户输入可以简化用户操作,减少手动输入偏差[1]。同时,众多学者为了研究如何提升菜肴图像识别的准确率发布了一些菜肴图像数据集,其中具有代表性的有UEC-Food100[2]、ETH Food-101[3]和VireoFood172[1]。
本文菜肴图像识别涉及到的菜肴包括主食、汤类、蔬菜、肉类等多个方面。鉴于菜肴图像识别属于细粒度识别[1],菜肴图像受拍摄角度、光照、位置和形状等不确定因素变化而影响图像关键细微差别,这将导致识别的难度大幅提升[4-5]。此外,不同的菜肴可能同时包括多种相同的食材,或是盛放菜肴的器皿相似,但由于菜肴食材的形状、颜色和盛放方式不同,同种菜肴在外观方面也存在很大的差异;这些因素都会给菜肴的识别带来相当大的难度。因此,SIFT[6](尺度不变特征变换)和HOG[7](方向梯度直方图)等传统手工提取特征的方法都难以在菜肴图像识别领域取得较高的准确率[1]。为了提升菜肴图像识别的准确率,研究者们将DCNN(深度卷积神经网络)与传统特征提取方法结合运用到菜肴图像识别中,并取得了突破性的进展。如Kawano等[8]将DCNN与传统手工提取特征的方法RootHoG-FV以及Color-FV结合,在UEC-Food100数据集[2]上准确率高于纯手工提取特征。但是该方法还是借助了传统特征提取的方法,识别过程中存在一定的局限性。
鉴于目前深度学习在菜肴图像识别中的问题,本文提出将迁移学习和批归一化相结合的深度学习框架,实现自动的菜肴识别。本文的主要贡献在于:
1) 借助已有的VGG-16预训练模型,将迁移学习应用到菜肴图像识别,把已在ImageNet1000级图像分类竞赛中发布的最终模型各项参数导入新模型中作为初始化参数,解决菜肴图像深度学习中存在的过拟合现象,获得更具有鉴别性的特征。
2) 对部分卷积层以及全连接层的输出结果做批归一化处理。该批归一化操作首先通过计算这批数据的均值及方差,再对这批数据做规范化处理,最终得到尺度变换和平移后的结果。
1 相关工作
与本文研究密切相关的工作是菜肴图像特征的自动提取和深度学习中梯度消失问题。
为了弥补特征提取过程中存在的不足,众多研究者将深度卷积神经网络应用到特征的提取中。这种模型自动提取特征的方式在细粒度图像分类问题上能够有更好的表现[9]。但是如果直接在相关数据集上进行训练可能会带来严重的过拟合现象。对此,引入了迁移学习从而一定程度上缓解过拟合。
Yanai等[10]从ILSVRC 1000 ImageNet数据集[11]和ImageNet 21000数据集中抽取出1 000种食物相关的图像,将其合并组成预训练数据集。将在该预训练集上训练成熟的AlexNet模型[12]应用到UEC-Food100数据集和UEC-Food256数据集上,并再次取得了当时最好的分类结果。Szegedy等[13]提出的GoogleNet模型获得了ILSVRC冠军,之后又对其核心结构进行改进得到Inception V3模型[14]。Hassannejad等[15]将Inception V3模型应用到了菜肴图像识别领域,top1准确率在ETH Food-101、UEC-Food100和UEC-Food256这三个菜肴图像数据集上分别提升了17.87%、2.68%和8.6%。Chen等[1]注意到菜肴识别和菜肴对应的食材的识别是两个相互促进,并且会互相影响的过程,据此提出了一个多任务的深度学习神经网络。该方法偏重于识别食材和菜肴,而不是单一的菜肴图像识别。
以上三种导入预训练模型的方法都属于迁移学习在深度学习中的应用,可以适当缓解过拟合。但是这些方法忽略了数据分布变化而带来的梯度消失问题。在预处理过程中对数据做归一化处理可以让初始数据大多分布在梯度较大范围内,但是随着深度神经网络不断加深,每一层的数据分布不断变化,仍然会出现梯度消失问题。对此,Ioffe等[16]提出了批归一化处理数据的方法,可以在网络中的任意一层进行归一化操作,从而一定程度上减弱中间层数据发生改变的情况。
2 菜肴图像识别模型
为了自动提取菜肴图像中的具有鉴别性的特征和解决现有深度学习框架下菜肴图像识别训练过程中梯度消失问题,本文在VGG-16模型的基础上引入了迁移学习和批归一化处理方法提升模型的图像识别准确率。提出模型的框架如图1所示。
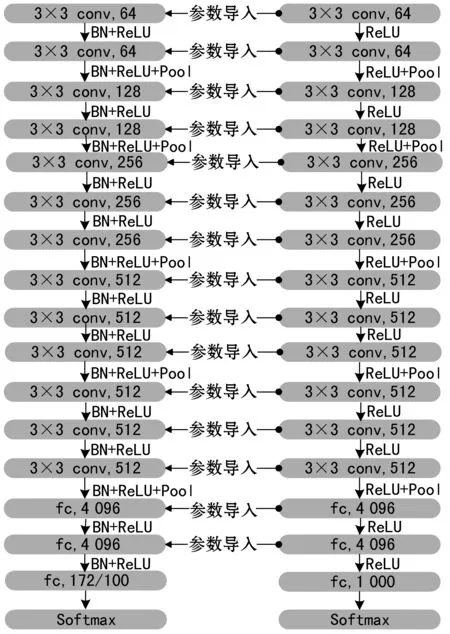
图1 基于VGG-16(ft+BN)菜肴图像识别模型框架
考虑到VGG-16是2014年ILSVRC竞赛的第二名,同时VGG-16在迁移学习中的表现优于当年的冠军GoogleNet模型,所以本文选用VGG-16作为基础模型。一方面,为了缓解过拟合现象,将已在ImageNet数据集[10]上完成预训练的VGG-16模型[17]中的卷积核参数和偏置项系数提取出来,并把这些系数导入到原始的模型中作为初始化参数;另一方面,对每一个卷积层和全连接层(除了最后一个全连接层)的输出都做批归一化处理[16]。最后,用激活函数来处理归一化结果,得到该层的最终输出。
2.1 迁移学习
目前,菜肴图像识别研究涉及的数据集包含的图像数量非常有限,如果采用随机方式初始化模型中的参数,然后直接在菜肴图像数据集上训练会导致过拟合[18]。
为了优化原始模型,将迁移学习应用到深度卷积神经网络中。与传统的机器学习不同,迁移学习的源域和目标域、源任务和目标任务均可不同[19]。所以,本文中使用的成熟神经网络模型为VGG-16,其已在2014年ILSVRC竞赛中使用的数据集上训练成熟。该数据集为ImageNet的子集,其数据集图像总量达到140万幅,共1 000个分类。在这样庞大的数据集上训练过的模型具有较强的泛化能力。
迁移学习在VGG-16模型上的应用分为参数导入和输出节点修改两个部分。VGG-16模型由13个卷积层、3个全连接层和5个池化层组成,其分类器采用Softmax,所有卷积层和全连接层的激活函数采用ReLU函数,具体网络结构如图1右侧所示。每个全连接层后都添加了一层dropout层,以抑制过拟合[20]。将在ImageNet数据集上经过预训练的VGG-16模型的所有卷积层参数和前两个全连接层的参数导入到初始模型中。由于本文中使用的数据集分类个数与ILSVRC竞赛所用数据集分类个数不同,所以需要将模型最后一个全连接层(fc8)输出节点个数改为数据集分类个数(VireoFood172中为172,UEC-Food100中为100)。最后将这些导入的参数都设定为可训练参数。
2.2 批归一化处理
为了捕捉更多的图像特征信息,神经网络不断加深。在训练的过程中,由于浅层的神经网络参数不断变化,深层神经网络的输入信息的分布也随之不断变化。这导致在训练网络的过程中需要设置更加合理的初始可训练参数以及采用更小的学习速率以保证梯度能合理地传播[16]。事实上,这样调节超参数需要花费很多的时间和精力,并且存在很大的偶然性。
对此,本文将批归一化处理方法引入VGG-16模型中。在训练阶段批归一化处理分为归一化处理和线性变换两个步骤。
1) 经过式(1)的归一化处理后让每批数据整体都服从均值为0、方差为1的正态分布。
(1)
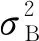
(2)
经过归一化处理,大部分数据都能被映射到[-2,2]区间中。在该区间内,激活函数(ReLU)的导数有一半概率为0,一半概率为1,从而一定程度上缓解了梯度消失问题。但是,对每批数据做简单的归一化操作可能会让数据丢失自己原来携带的信息,通过步骤2的仿射变换可以弥补部分丢失信息。
在训练的过程中,针对每一批训练数据求出样本均值和样本方差后再对单个样本做处理,使这批训练数据服从于(0,1)正态分布。然而在测试过程中,已经不存在“批”这个概念,同样也不存在这一批数据的样本均值和样本方差,因此,测试过程中需要先估算整体的均值和方差,再对输入数据进行批归一化处理。
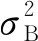
E[x]←EB[μB]
(3)
(4)
式中:m为该批次中图像数量。
2) 针对测试集数据xT,对其做与训练集数据相同的归一化处理。其中均值和方差是式(3)和式(4)中得到的无偏估计值。
(5)
(6)
3 实 验
本节主要展示实验的各项数据并分析实验结果。根据以上方法在VireoFood172和UEC-Food100数据集上进行了实验。结果表明,以上改进方法能有效提升图像识别的准确率。所有的实验均在Linux环境下进行,GPU为NVIDIA TITAN Xp,深度学习框架为TensorFlow。
3.1 实验数据集
VireoFood172数据集由Chen等发布,包含172种中式菜肴。这172种菜肴可分为蔬菜、汤类、豆制品、鸡蛋、肉类、海鲜、鱼类和主食八大类,各类具体菜肴数量在表1中展示。数据集中图像原始分辨率为256×256,共计110 241幅,平均每种菜肴大约有641幅图像。数据集发布者将各类菜肴按照6 ∶3 ∶1的分割方式将数据集划分为训练集、测试集和验证集。

表1 VireoFood172数据集菜肴分类
UEC-Food100数据集由Matsuda等发布,其涵盖了100种日式菜肴,共计9 060幅。每种菜肴都有至少100个样本。与VireoFood172不同,UEC-Food100数据集中,所有菜肴都有一个标注框记录目标菜肴在图片中的准确位置,并且一幅图片中可能包含多个菜肴。对此,按照数据集提供的标注框,将目标菜肴从原始图像中切割,然后利用抗锯齿算法重新调整大小,使其分辨率变为256×256。最后将重新调整大小后的图片用顺序编号作为文件名,以.jpg格式保存到各个分类的文件夹中。具体操作流程在图2中展示。将最后得到的各类菜肴图像随机地分为训练集和测试集,比例为8 ∶2。

图2 UEC-Food100数据集图像处理流程
3.2 迁移学习实验结果
迁移学习的相关实验在VireoFood172和UEC-Food100数据集上进行。训练过程中以验证集准确率和loss作为评价标准对比两种方法。VGG-16表示原始模型,VGG-16(ft)表示导入预训练模型参数的网络。
(1) VireoFood172数据集结果。对VireoFood172数据集中的图像做如下操作:在开始训练之前,对训练集中图像做随机水平翻转、随机剪切(将256×256格式的图片随机剪切成224×224)等数据增强操作,并将从.tfrecords文件中读取得到的训练数据打乱。以上操作可以使得模型的泛化能力增强,减少过拟合。
VireoFood172数据集实验中各项参数如下:每批64幅图片,初始学习率设定为0.000 1,每8 000次迭代衰减为之前学习率的十分之一,优化方法为Adam。由于超过25 000次迭代验证集的准确率趋于稳定,并且loss不再下降,将迭代次数设定为27 000。根据经验,将L2正则化系数设定为0.002效果最好。
图3为训练过程中验证集loss变化趋势图,其中:loss(raw)曲线代表未导入预训练模型的VGG-16网络的loss变化趋势;loss(ft)曲线代表导入预训练模型的VGG-16网络变化趋势。
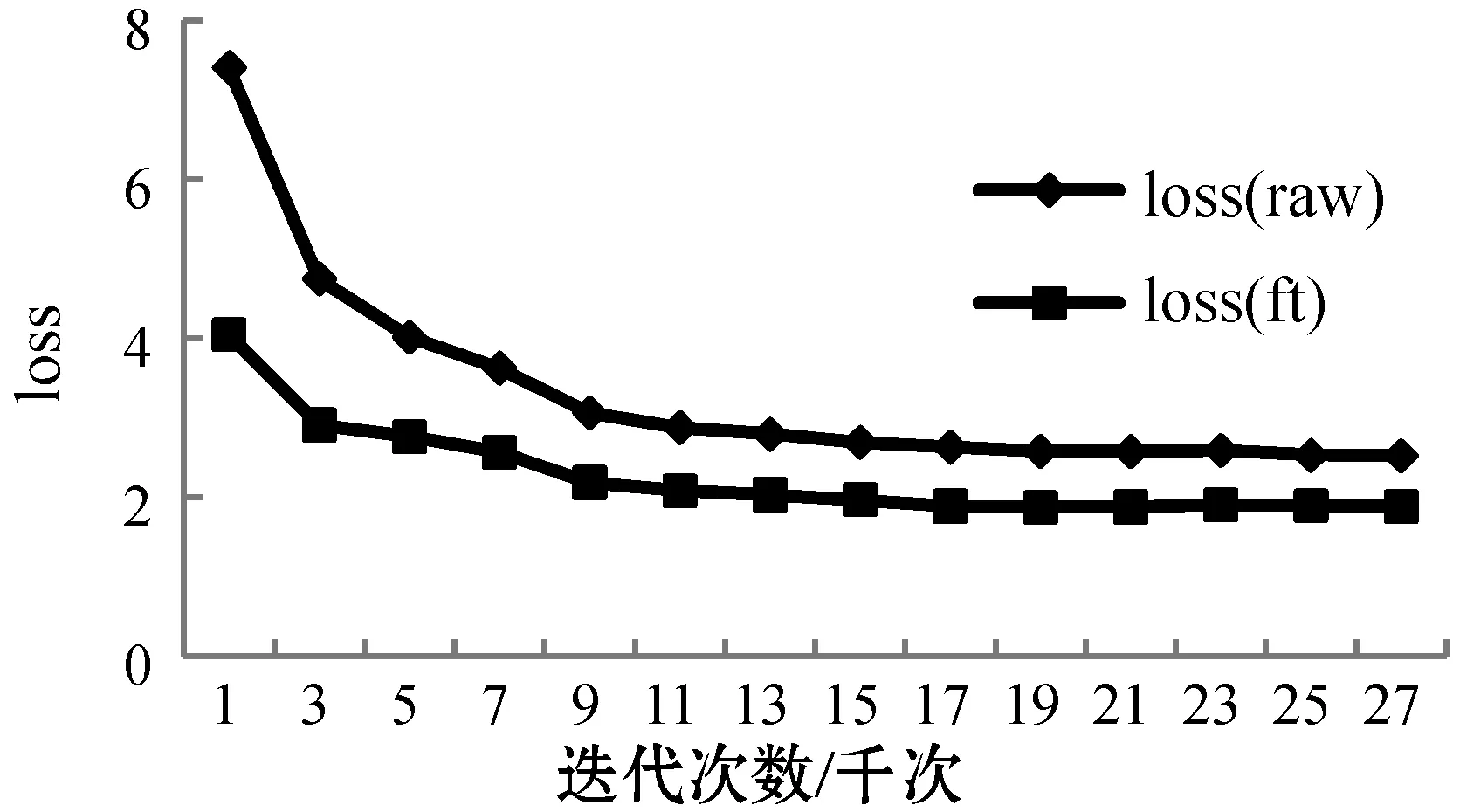
图3 VGG-16与VGG-16(ft)在VireoFood172上loss走势
可以看出,同等情况下,与未导入预训练模型数值相比,导入预训练模型参数值的网络loss下降更快,并且最终趋于稳定的值比前者更小。
图4为训练过程中验证集上top1准确率变化趋势图,其中:accuracy(raw)曲线代表未导入预训练模型的VGG-16网络的准确率变化趋势;accuracy(ft)曲线代表导入预训练模型的VGG-16网络准确率变化趋势。

图4 VGG-16与VGG-16(ft)在VireoFood172上准确率走势
可以看出,导入预训练模型参数后,模型的准确率提升速度更快,并且最终验证集的准确率与未使用迁移学习的模型相比提升了大约30%。
最终测试集的各项结果如表2所示。top1准确率和top5准确率均有大幅提升,而损失也下降了约0.7。表2中实验结果可以证明将迁移学习应用到VGG-16模型中能有效地缓解VireoFood172数据集上存在的过拟合问题,从而提升图像识别准确率。
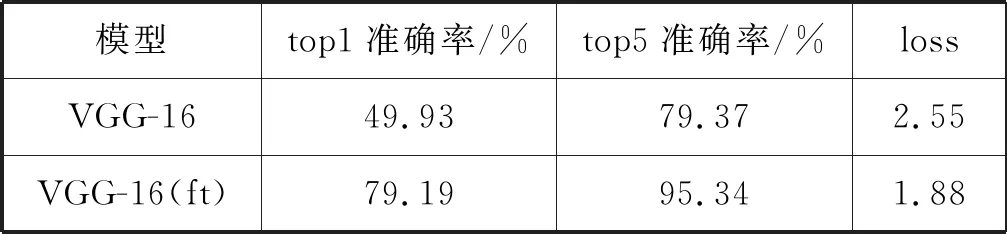
表2 迁移学习在VireoFood172数据集结果
(2) UEC-Food100数据集结果。类似地,在UEC-Food100数据集上,对菜肴图像做与VireoFood172数据集上相同的数据增强操作。
由于UEC-Food100数据集较小,很多分类的图像数据只有100条左右,所以在迁移学习的过程中冻结卷积层部分参数(即VGG-16中conv1_1-conv3_3),仅训练之后两个卷积层和全连接层参数。超过10 000次迭代后验证集的准确率趋于稳定,所以将迭代次数设定为13 000,每3 000次学习速率衰减为之前的一半。
图5为训练过程中验证集loss变化趋势图,其中:loss(raw100)曲线代表未导入预训练模型的VGG-16网络在验证集上loss变化趋势;loss(ft100)曲线代表导入预训练模型的VGG网络在验证集上变化的趋势。
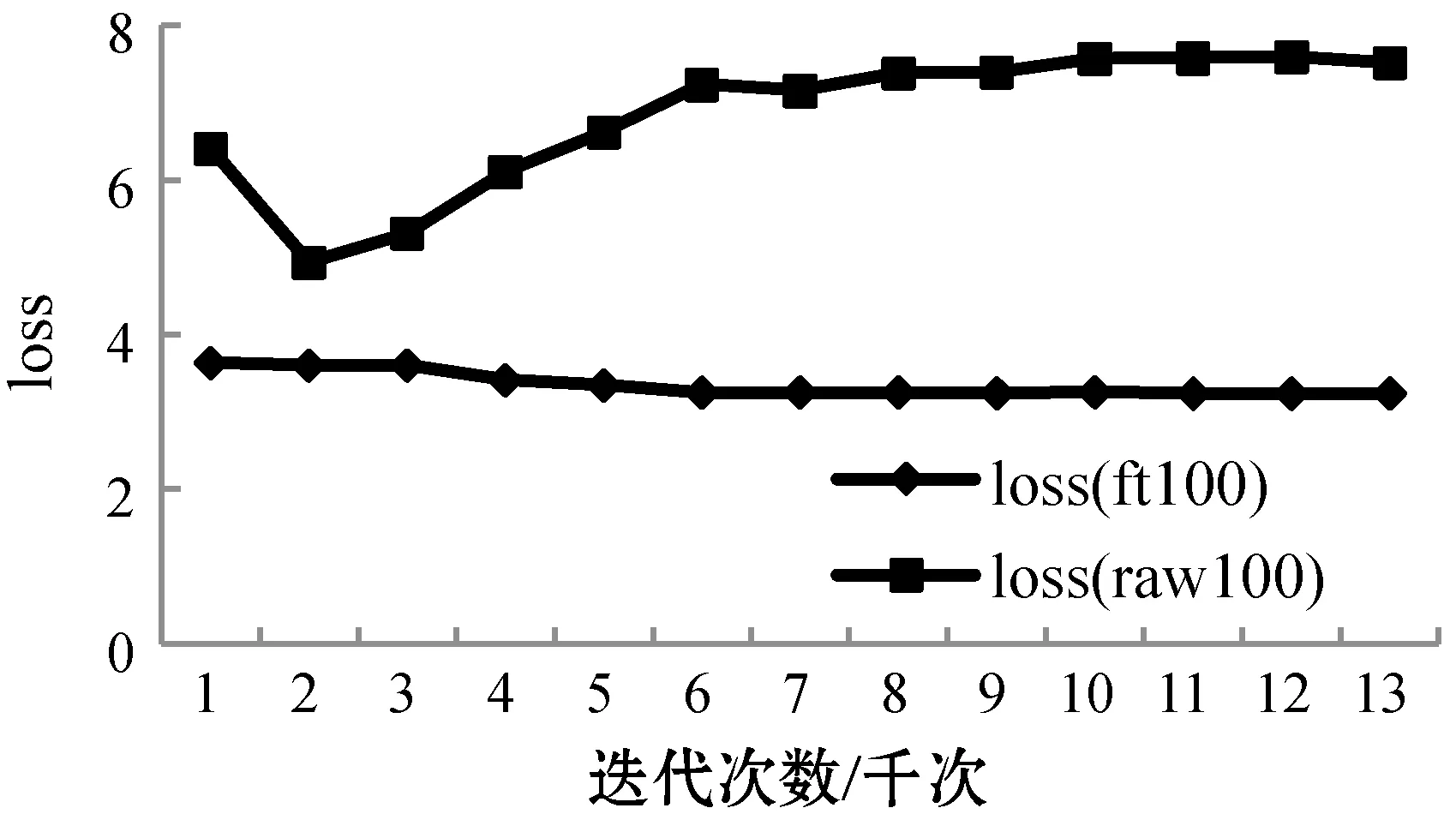
图5 VGG-16与VGG-16(ft)在UEC-Food100上loss走势
未导入预训练模型的参数网络的loss整体呈上升趋势,最终稳定在数值较大的区间,与训练集的loss差距较大。而loss(ft100)与loss(raw100)相比初始下降幅度较大且整体呈下降趋势,并最终稳定在3附近。最终,loss(ft100)比loss(raw100)稳定值小4.5左右。
图6为训练过程中验证集上top1准确率变化趋势图,其中accuracy(raw100)曲线代表未导入预训练模型的VGG-16网络的准确率变化趋势,accuracy(ft100)曲线代表导入预训练模型的VGG-16网络准确率变化趋势。
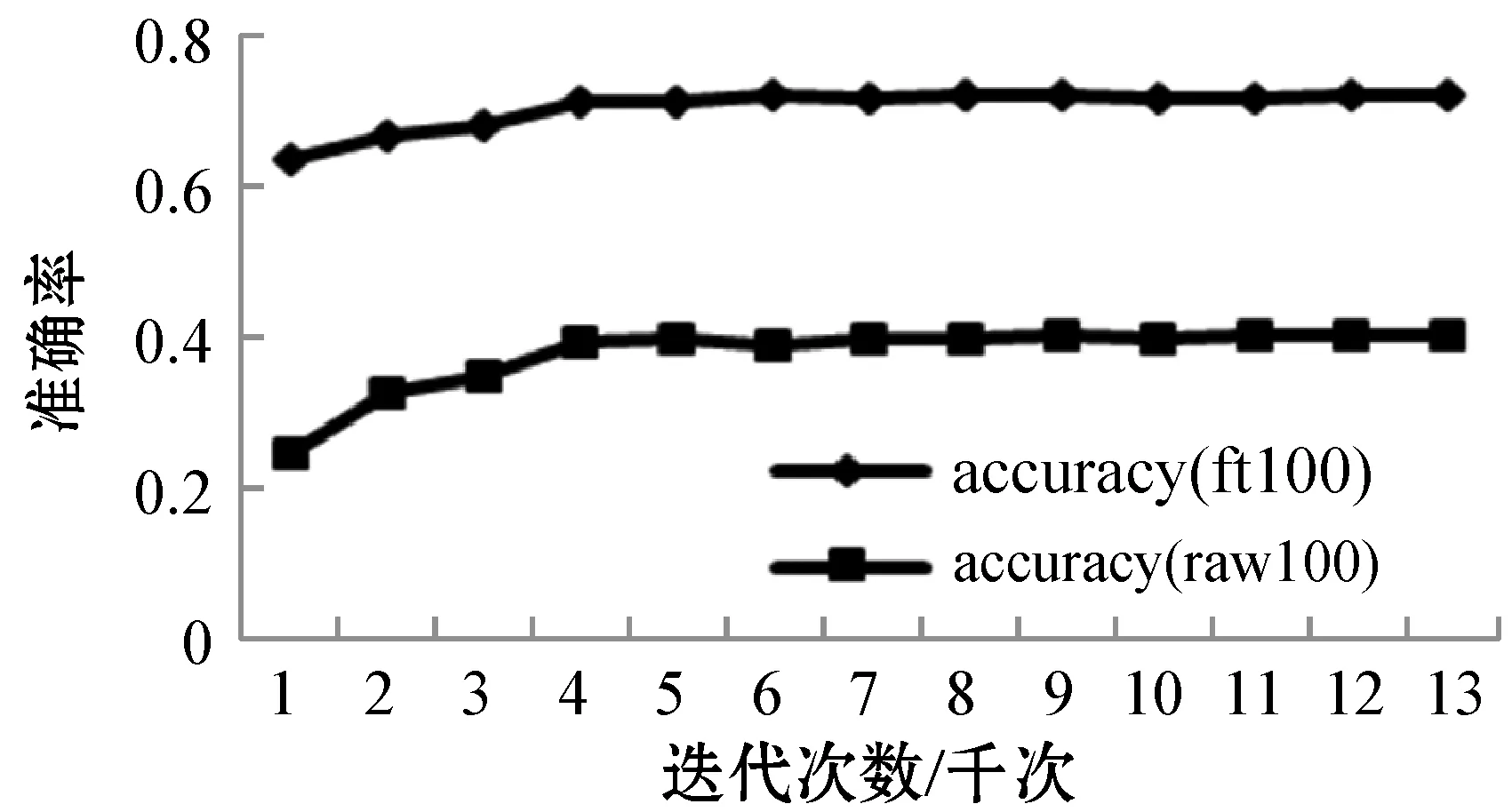
图6 VGG-16与VGG-16(ft)在UEC-Food100上准确率走势
accuracy(ft100)曲线与accuracy(raw100)曲线均呈上升趋势,但accuracy(ft100)初始上升幅度更大,并最终稳定在数值相对较高的区间。
最终在测试集上各指标结果如表3中所示。与VireoFood172数据集的结果类似,top1和top5准确率均有大幅提升,损失下降。实验结果表明,将迁移学习应用到VGG-16模型中能提升在UEC-Food100数据集上图像识别的准确率。

表3 迁移学习在UEC-Food100数据集结果
通过在VireoFood172和UEC-Food100数据集上的实验结果可以证明,在原模型的基础上使用迁移学习,即导入预训练模型可以缓解过拟合现象并大幅提升测试集上的准确率。
3.3 批归一化实验结果
按照3.2节中的方法将训练成熟模型的参数导入初始模型中,并将这些导入的参数设定为可训练的,数据增强操作与3.2节中相同。训练过程中以验证集准确率作为评价标准对比两种方法。VGG-16(ft+BN)表示不仅对原始VGG-16模型做了微调,并且加入了批归一化层。
(1) VireoFood172数据集结果。在VireoFood172数据集上训练时,除了最后一层全连接层(fc8),在所有卷积层和全连接层中都添加了批归一化处理。由于加入批归一化层后参数变多以及显卡存储量的限制,所以将每批处理的图像数量调整为32幅。使用批归一化层后,训练速度明显变快,所以设定学习速率每2 000次衰减为之前的一半,迭代次数设定为25 000。其余各项参数设定及数据增强方式不变。
图7展示了加入BN层和未加入BN层训练过程中验证集准确率变化趋势,accuracy(ft)代表未添加BN层的模型验证集上准确率变化曲线;accuracy(ft+BN)代表添加BN层后模型的在验证集上准确率变化曲线。在添加BN层后,准确率最终会稳定在一个更高的值附近。最终,在其他各项参数相同的情况下,得到了如表4所示的各项数据。
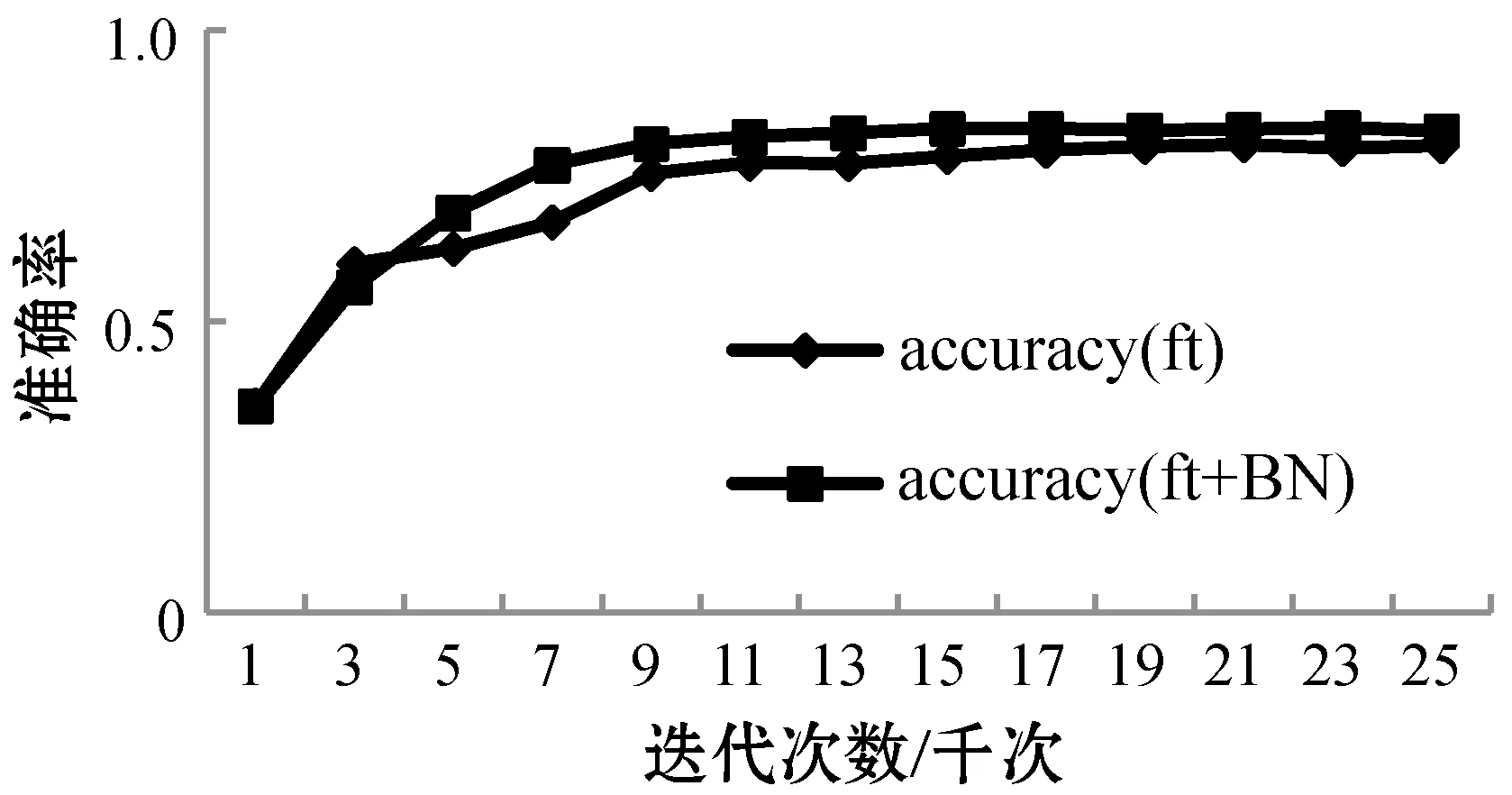
图7 VGG-16(ft)与VGG-16(ft+BN)在VireoFood172上准确率走势
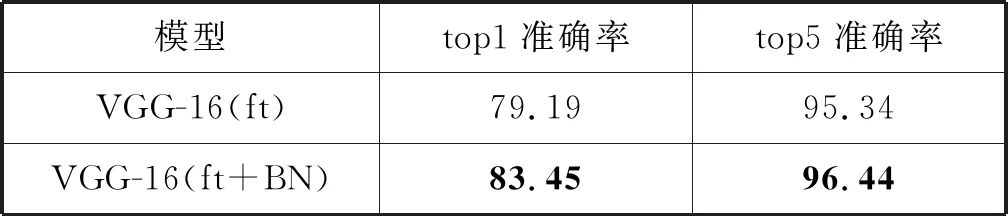
表4 批归一化在VireoFood172数据集结果 %
可以看出,使用批归一化的模型的准确率达到了83.45%,与未使用批归一化层的模型相比提升了4.26个百分点。
(2) UEC-Food100数据集结果。与3.2节中训练方法类似,仅训练全连接层部分参数,并且仅在每个卷积块最后一层和全连接层中第二层(fc7)添加批归一化层。每批处理64幅图像,每3 000次迭代后学习速率衰减为之前的一半,迭代总次数设为13 000。其余各项参数设定及数据增强方式不变。
图8为使用批归一化前后验证集上图像识别准确率变化趋势。其中:accuracy(ft100)代表未添加BN层的模型在验证集上准确率变化曲线;accuracy(ftBN100)代表添加BN层后模型的在验证集上准确率变化曲线。添加批归一化后准确率明显有所提升,最终得到表5中相应的结果。
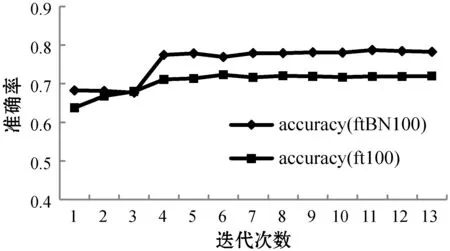
图8 VGG-16(ft)与VGG-16(ft+BN)在UEC-Food100上准确率走势
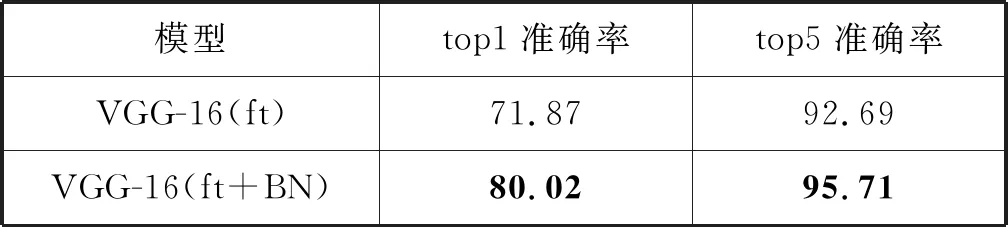
表5 批归一化在UEC-Food100数据集结果 %
可以看出,VGG(ft+BN)模型top1准确率达到80.02%,与VGG-16(ft)相比,在UEC-Food100数据集上提升了8.15个百分点。
通过在两种菜肴图像数据集上的结果可以证明,批归一化处理可以有效提升模型的稳定性和识别的准确率,并且VGG-16(ft+BN)无须经过繁杂的调参过程就可以取得优于普通卷积神经网络的准确率。
3.4 可视化结果
为了能够更加直观地展示实验结果,引入了其他三种深度学习方法作为对比实验展示可视化实验对比结果。
(1) VireoFood172数据集结果。在VireoFood172数据集上采用AlexNet[11]、VGG-16[17]和Arch-D[1]模型作为对比。AlexNet是2012年ImageNet竞赛冠军获得者,与传统的机器学习方法相比识别率有大幅提升。VGG-16与AlexNet相比拥有更多的卷积层,在ImageNet数据集上图像识别准确率也有了大幅提升。Arch-D算法在VGG-16的基础上略做调整,使得该模型可以同时识别菜肴和食材。表6第1列展示了5道具有代表性的菜肴图像以及菜肴对应的名称,第2-5列罗列了以上提及的三种模型以及本文中的模型对第1列图像识别概率最高的5个结果及其对应的概率值。
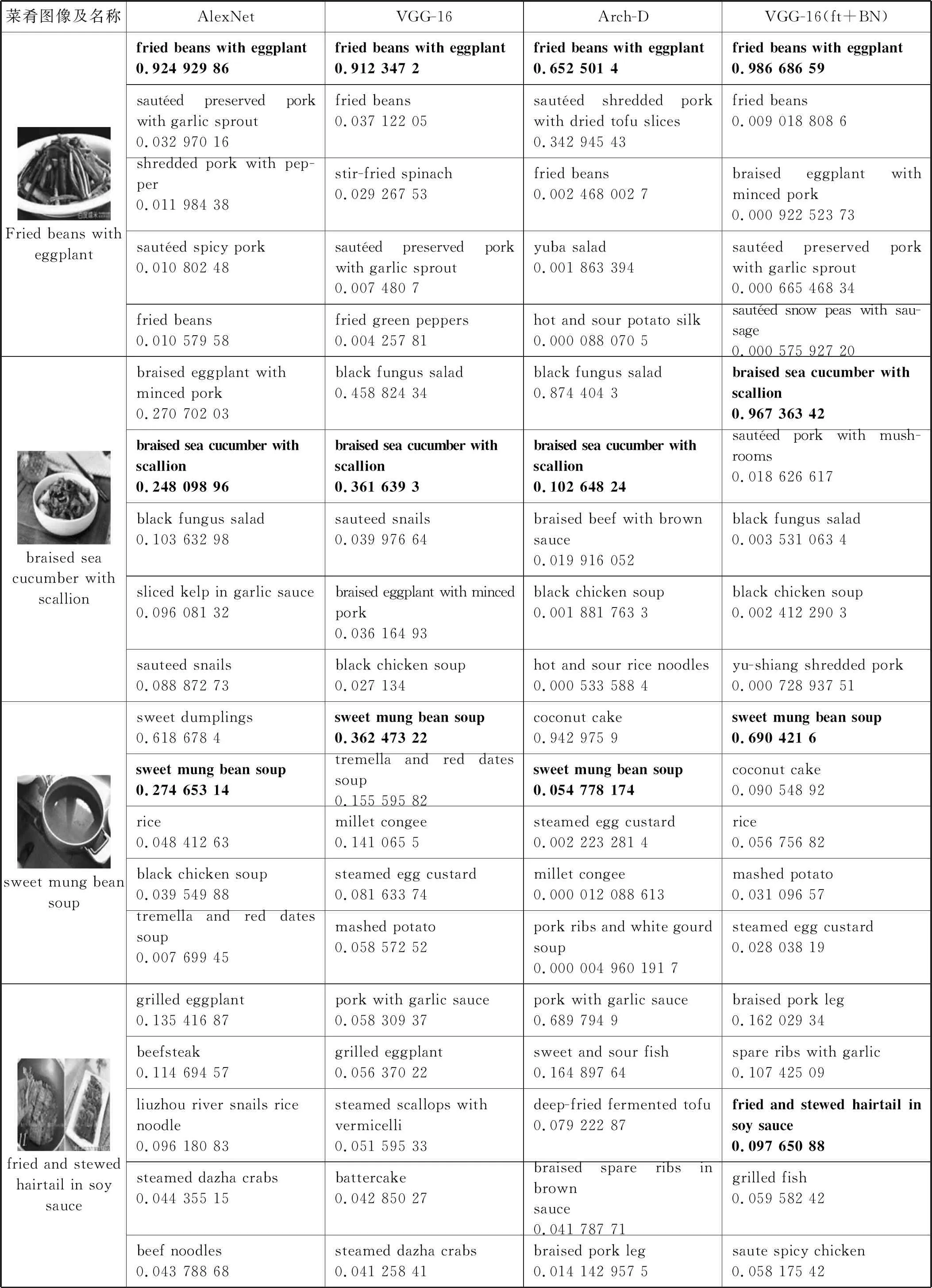
表6 各模型在VireFood172数据集上可视化结果

续表6
所有神经网络在识别较为清晰并且干扰较少的菜肴图片时都能较为准确地给出菜肴的正确标签。如表6中“fried beans with eggplant”标签对应的图像,所有的网络都能准确地识别出该菜肴,在正确分类上除Arch-D算法外均取得较高的概率。图像中有少许干扰项或是图像中关键部分被遮挡,部分算法将不能十分准确地识别菜肴。表6中除了VGG-16(ft+BN)算法可以将“braised sea cucumber with scallion”以较高的准确率识别,其他算法均不能将正确标签以top1识别出。同样,Arch-D算法和AlexNet未能以top1识别“sweet mung bean soup”;VGG虽然以top1识别出该菜肴,但是概率只有0.36;只有VGG(ft+BN)以相对较高的概率识别出该标签,概率值为0.69。如果图像中存在较多干扰因素,或是菜肴只占据图像中极小部分,那么网络将很难识别这些图像。除VGG(ft+BN)模型在top5中识别出“fried and stewed hairtail in soy sauce”对应的菜肴图像,其他模型均未在top5中识别出该菜肴。由于拍摄角度、光线和图中其他干扰信息的影响,所有网络均未能对最后的“deep fried lotus root”在top5中进行正确分类。
最终各网络在VireoFood172数据集上的识别准确率如表7所示。VGG-16(ft+BN)拥有最高的top1识别率和最高的top5识别准确率。比VireoFood172数据集的发行者Chen提出的Arch-D算法在top1准确率上高出1.39个百分点,top5准确率上高出0.56个百分点。

表7 各模型在VireFood172数据集上结果 %
(2) UEC-Food100数据集结果。在UEC-Food100数据集上采用AlexNet[11]、VGG-16[17]和DCNN-FOOD(ft2)[12]方法做对比实验。部分图像识别结果如表8所示。与VireoFood172数据集不同,由于UEC-Food100数据集中所有的菜肴图像都包含标注框,所以图像中包含的干扰信息较少,但是UEC-Food100数据集中各类菜肴之间相似度更高,并且同类菜肴在外形方面差距较大。与VireoFood172数据集类似,表8第1列展示了UEC-Food100数据集中五道具有代表性的菜肴,第2-5列是各个模型对相应图像识别概率最高的5道菜肴名称及其对应的概率值。表8中“rice ball”标签对应的图像和训练集中的图像在颜色和形状方面差距大,所以四种模型均未能在top5中给出正确标签。“beef steak”图像中主食被其他食材遮挡,导致除VGG-16(ft+BN)以外的模型未能在top5中识别。由于“fried shrimp”和“stew”中用到的食材和其他菜肴中相似度很大,VGG-16(ft+BN)以外的模型虽然在top5中将标签识别但并未以top1识别图像。“tensin noodle”中包含的各类食材都已经清晰地陈列在图像中,所有模型均以较高的准确率将标签以top1识别出,VGG-16(ft+BN)拥有最高的识别概率。

表8 各模型在UEC-Food100数据集上可视化结果

续表8
最终各网络在UEC-Food100数据集上的识别准确率如表9所示。VGG(ft+BN)拥有最高的top1识别率和最高的top5识别准确率,并且比UEC-Food100数据集发布者之一Yanai等在文献[12]中的top1准确率高1.25个百分点,top5准确率高0.56个百分点。
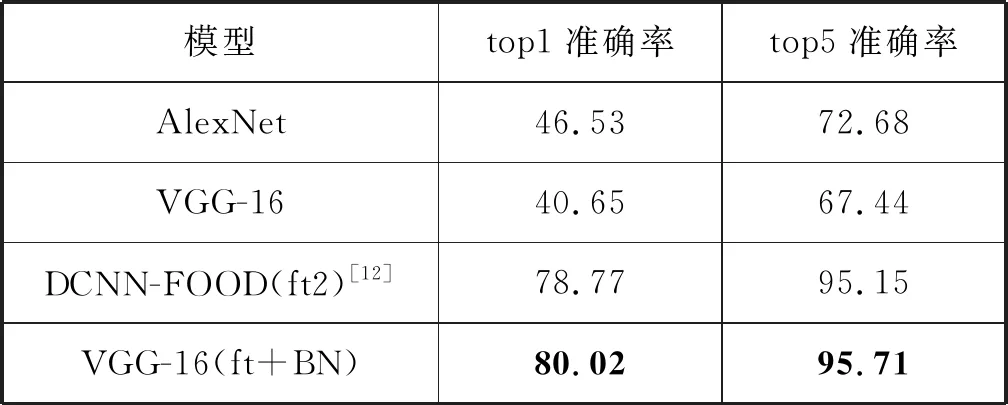
表9 各模型在VireFood172数据集上结果 %
4 结 语
本文提出一种基于迁移学习和批归一化处理的菜肴图像识别方法。为了缓解过拟合现象,将2014年ILSVRC竞赛数据集上训练成熟的VGG-16模型的各项参数导入初始模型中从而大幅提升了识别的准确率,同时又将批归一化处理数据的方法引入VGG-16中缓解梯度消失的问题。在VireoFood172和UEC-Food100数据集上top1准确率分别提升了1.39个百分点和1.25个百分点。
